







引言
结巴分词用到的核心算法模型是隐马尔可夫模型。
一、HMM模型
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。我们下面举一个例子来理解HMM模型。

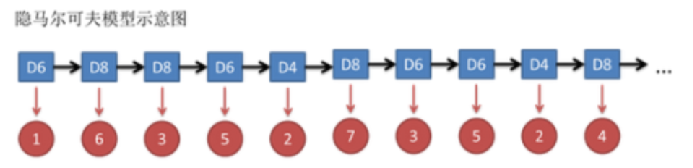
如果想详细了解HMM模型的推导,可以参考:nlp基础—7.隐马尔可夫模型(HMM算法)。
二、中文分词方法
1.基于规则
基于字典、词库匹配的分词方法,基于字符串匹配分词。将待分的字符串与一个充分大的机器词典中的词条进行匹配。
- 正向最大匹配:对输入的句子从左至右,以贪心的方式切分出当前位置上长度最大的词,组不了词的字单独划开。其分词原理是:词的颗粒度越大,所能表示的含义越精确。
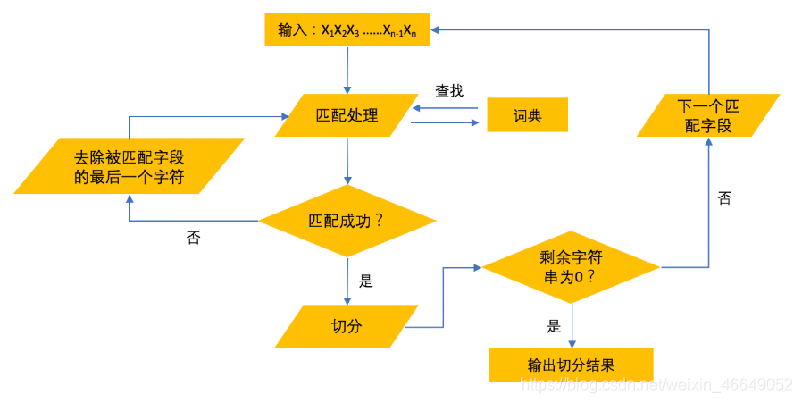
- 逆向最大匹配:原理与正向最大匹配相同,但顺序不是从首字开始,而是从末字开始,而且它使用的分词词典是逆序词典,其中每个词条都按逆序方式存放。在实际处理时,先将句子进行倒排处理,生成逆序句子,然后根据逆序词典,对逆序句子用正向最大匹配。
- 双向最大匹配:将正向最大匹配与逆向最大匹配组合起来,对句子使用这两种方式进行扫描切分,如果两种分词方法得到的匹配结果相同,则认为分词正确,否则,选取分词结果中单个汉字数目较少的那一组
输入:
研究生研究自然语言处理是一个不错的研究方向
正向:
[‘研究生’, ‘研究’, ‘
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









