






前言
self-attention 上
一、Self-attention想解决的问题
之前问题的输入都可以看做一个向量,输出一个数值或者类别。
可如果输入的是一排向量或者向量的数量是可以改变的,如文字处理,把每个单词表示为一个向量,句子中的单词数量不一定是相同的。最简单的方法是one-hot encoding,开一个向量,长度和世界上所有词汇的量相等。
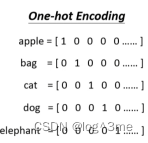
这个方法的问题在于,这是假设所有词汇之间没有关系,比如cat和dog都是动物,比较接近;cat和apple一个动物一个植物,不相近。同样可以当做向量的,还有音频、图像、分子(一个原子,可以做当一个向量,用one-hot vector表示)。
在输出的情况上,有输入n个输出n个label,输入n个输出1个label,输入n个向量输出未知个label。
输入和输出一样多的情况(sequence labeling),直觉的想法是每个向量输入到fully-connected network里面,产生输出。但是这个方法有一个问题,如果是词性分析时,如果一个词有两个词性,那么输入相同的时候不会产生两个结果。
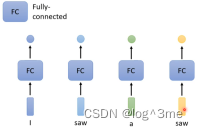
那么就需要fully connected network考虑更多比如上下文,把一个向量的前后几个都输入同一个network。
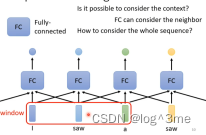
给FC一整个window的向量。
这样还会有一个问题,如果当一个window无法解决时,需要考虑整个序列时(序列有长有短,如果需要让一个window把所有都装下,就需要算出训练资料中最长的,让window比最长的还长,但是这样FC需要非常多的参数,不仅运算量大还容易overfitting)。
二、Self-attention(上)
所有向量经过Self-attention后会输出同样数量的向量,这些向量都是考虑一整个序列后输出的。
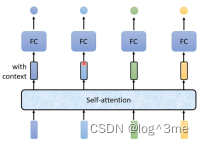
Self-attention可以用很多次,和fully-connected交替使用。
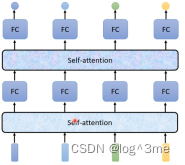
Self-attention处理整个序列的资讯,fully-connected专注于处理一个。
Self-attention是如何运作的
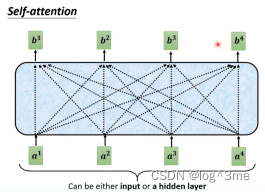
Self-attention的输入是一串向量,他的输出(bi)是考虑所有输入的(ai)
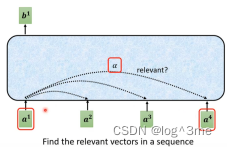
如何产生b1,首先根据a1找出序列中和a1相关的向量,相关程度用ɑ表示。
ɑ的计算方法:(最常用的方法,也是用在transformer里面的方法)
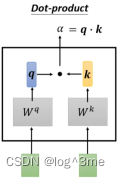
把输入的两个向量,分别乘上两个不同的矩阵得到向量q和向量k,让q和k做点乘再加起来为ɑ。
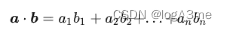
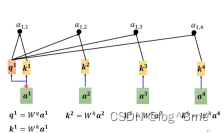
在实际中,a1也会和自己计算关联性。
计算出关联性后,通过soft-max(ReLU也可以)。
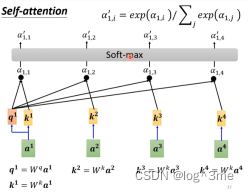
得出哪些向量和a1有关联性后,就要抽取出重要的资讯。将ai乘上一个新的向量Wv得到新的向量v1~ v4,将v1~ v4都乘上attention的分数ɑ’,在把他们加起来,就得到b1。
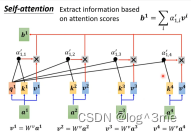
如果a1和谁的关联性更大,那么b1就会比较接近谁。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7/?p=10&spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 409
409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









