






前言
transformer下(decoder)
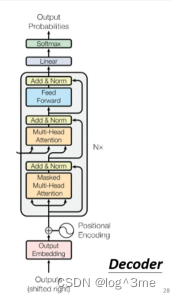
一、Decoder
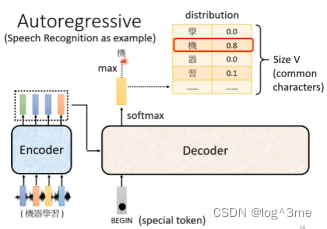
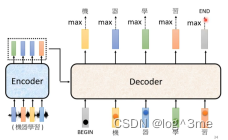
以语音辨识为例
Decoder先读进encoder的输出,先给decoder一个符号表示开始,这个开始符号也是用one-hot vector表示。之后decoder会输出一个向量,这个向量的长度结果可能输出的所有可能,比如中文语音辨识,这个向量的长度就是所有可能出现的所有汉字。输出这个向量之前会经过一个softmax,可能性相加=1,这些可能性最高的就是这个向量的输出。
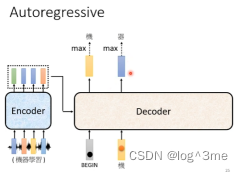
之后decoder会拿“机”作为输入,并在输出中选择数值最高的。
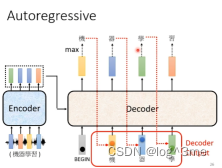
不断重复,decoder会把之前的输出当做接下来的输入。
Decoder中有一步masked self-attention。他和普通的self-attention的区别在于,self-attention会考虑所有a1-a4输出b1,而masked只会考虑左边的,b1考虑a1,b2考虑a1、a2,以此类推。
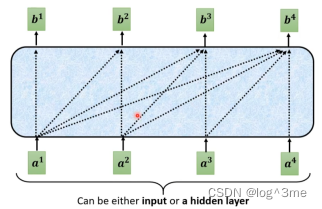
为什么只考虑前面的呢,因为decoder的输出是一个一个输出的,encoder是同时输出的,对于decoder而言,先有a1,才有a2,才有a3和a4,当计算b2的时候,是没有a3和a4的,所以没有办法把a3和a4放进来。
输出的序列长度是多少呢,也就是什么时候结束,这是希望机器学会的,所以要准备一个结束符号,表示停止。
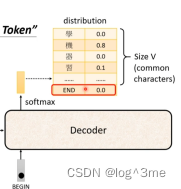
最后一个产生的向量里面结束的概率必须要是最大。
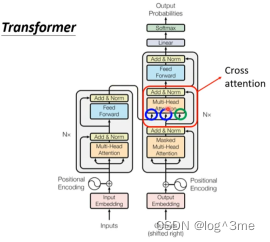
Decoder和encoder的差别主要在cross attention,cross attention的输入有两个来自encoder的输出。
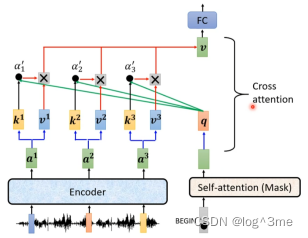
Begin经过self-attention(Mask)得到一个向量,这个向量乘一个矩阵得到q,q和k1 k2 k3计算attention的分数,再和v1 v2 v3加权,将他们加起来得到v。
训练
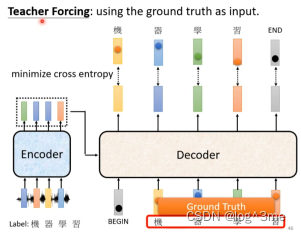
在训练的时候,decoder的输入每次都是正确的,期待decoder的输出和正确的cross entropy的和越小越好,同时也包括end的cross entropy。
一个问题是,在训练的时候decoder看到的永远是正确的,但是预测的时候,decoder可能会看到错误的,可能会一步错步步错。这个现象叫做exposure bias。一个可能的方法是,训练的时候给decoder加入一些错误的信息,这样可能处理的效果更好。
二、AT v.s. NAT
AT:autoregressive
NAT:non-autoregressive
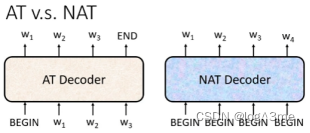
Nat是一次把整个句子产生出来,nat是给几个begin,产生几个。而如何知道有几个begin呢。一种做法是用一个另外的predictor输出数量。另一种做法是,给很多的begin(超过最大的可能的数量上限),看什么时候输出end,end后面的忽略。
Nat的好处:平行化,一次就可以输出,速度比at快。可以控制输出长度。
Nat缺点:效果不如at。
总结
视频学习地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=13&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









