






前言
生成式对抗网络(三)
生成器效能评估与条件式生成
一、生成器效能评估
早期是通过人来判断一个generator产生的结果。一个方法是通过影像分类系统,把GAN产生的图片丢到分类系统里,分类系统输出一个概率分布,如果这个概率分布产生的越集中,说明产生的图片的类别就越确定(越好),如果概率很平均,表示产生的图片比较奇怪(四不像)。
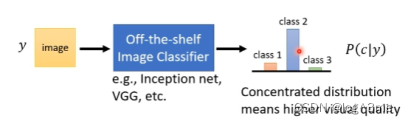
但只用这个方法可能会被mode collapse问题骗过去。

Mode collapse是训练的模型,单拿一张图片还可以,但来来回回就那么几张图片。如果一个点是discriminator的盲点,generator学会产生这个盲点的时候就永远可以骗过discriminator,discriminator无法判断这是一个产生的。就比如重复产生同一张图片多次。虽然通过了discriminator,但是无法说这是一个好的generator。虽然会产生mode collapse,但是这个问题还是可以侦测到的。

另一个问题是mode dropping,单看产生的资料不错,而且多样性可以,但是真实的资料多样性是更大的。这种问题更不容易被侦测到。

如何解决这个问题,一个做法是将生成的图片丢到图片分类器里,判断他被分为哪个种类,给出一个概率。把所有的概率平均,如果集中在一个分类,就表示多样性不够。
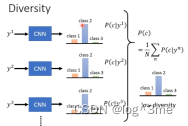
相反,如果比较平坦,就表示多样性就够得。

Quality和diversity看起来有点互斥,但是quality在评估的时候是只看一张图片的,diversity看一堆图片。
一个评估分数:Inception Score(IS),当quality高,diversity大,则IS的分数高。
另外一个FID:将softmax之前的hidden layer的输出(向量)代表一张图片(而不是一个类别)。把真实的图片和generator产生的图片,经过inception network产生的向量,计算这两类是否更接近。FID越小越好。FID需要大量的samples,这需要很大的计算量。
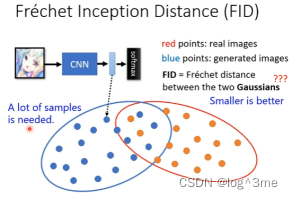
另一个问题
假设训练了一个generator产生的资料和真实资料一模一样,假设不知道真实资料样子,训练资料是很好的,计算出的FID一定很小。但问题是,产生的资料和资料库里面的一模一样,那为什么要训练,直接从资料库拿更好。这时候虽然FID很低,但是没有什么用,无法获得你没见过的图片。

二、Conditional Generation
之前的generator的输入都是一个随机的分布,现在想要操作generator的输出,给一个x,让generator根据x和z产生输出。这种方式的应用,可以是文字对图片的生成,这种需要文字和图片对应的资料,才能训练这种文字对图片的生成。
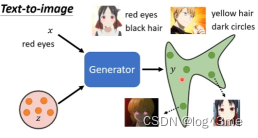
希望通过输入x,获得一个对应的输出,每次的输出都不一样,这取决于sample到怎样的z。
如何做conditional GAN。现在generator有两个输入一个x一个z,generator产生一张图片y,需要一个discriminator。之前的discriminator是输入一张图片,判断这张图片多像真实的。这样的discriminator无法解决conditional GAN的问题,应为如果这个discriminator只看y当做输入,generator学到的是产生可以骗过discriminator的图片,但是跟输入完全没有关系。
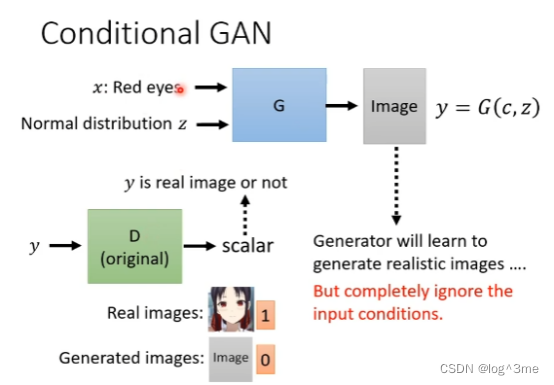
所以conditional GAN的discriminator不仅要y还要x,进而产生分数,只有当图片好,并且要x和y是相配的,discriminator才会给高分。训练这样的discriminator需要有标注的资料,看到相配的给1,文字和机器产生的图片给0,还需要图片是好的,但是和文字不匹配的给0。
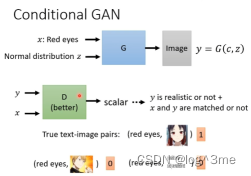
同样的应用还有通过图片生成图片,声音生成图片等等。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=16&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









