






来源:3DCV
「3D视觉从入门到精通」知识星球,星球内凝聚了众多3D视觉实战问题,以及各个模块的学习资料:近20门独家秘制视频课程、最新顶会论文、计算机视觉书籍、优质3D视觉算法源码等。想要入门3D视觉、做项目、搞科研,欢迎加入!
0. 这篇文章干了啥?
近年来,同时定位与地图构建(SLAM)技术取得了显著进展,特别是在未知环境中的实时3D重建和定位方面。由于其能够实时估计姿态和重建地图,SLAM已成为各种机器人导航任务中不可或缺的技术。定位过程为机器人的机载控制器提供了关键的状态反馈,而密集的3D地图则提供了关键的环境信息,如自由空间和障碍物,这对于有效的轨迹规划至关重要。彩色地图还携带了大量的语义信息,能够生动地表示现实世界,从而开辟了广阔的应用潜力,如虚拟和增强现实、3D建模以及人机交互。
目前,已有多种基于单一测量传感器的SLAM框架成功实现,主要是相机或激光雷达。尽管视觉和激光雷达SLAM在各自领域展现出了前景,但每种方法都有其固有的局限性,这些局限性限制了它们在不同场景下的性能。
视觉SLAM利用成本效益高的CMOS传感器和镜头,能够建立准确的数据关联,从而实现一定程度的定位精度。丰富的颜色信息进一步丰富了语义感知。进一步利用这种增强的场景理解能力,深度学习方法被用于稳健的特征提取和动态对象过滤。然而,视觉SLAM中缺乏直接的深度测量,需要通过三角测量或深度滤波等操作同时优化地图点,这引入了显著的计算开销,往往限制了地图的准确性和密度。视觉SLAM还面临许多其他限制,如不同尺度下的测量噪声变化、对光照变化的敏感性以及无纹理环境对数据关联的影响。
激光雷达SLAM利用激光雷达传感器直接获得精确的深度测量,与视觉SLAM相比,在定位和建图任务中提供了更高的精度和效率。尽管有这些优势,但激光雷达SLAM也存在几个显著的缺点。一方面,它重建的点云地图虽然详细,但缺乏颜色信息,从而降低了信息尺度。另一方面,激光雷达SLAM在几何约束不足的环境中(如狭窄隧道、单一且延长的墙壁等)的性能往往会下降。
随着智能机器人在现实世界中运行的需求不断增长,特别是在经常缺乏结构或纹理的环境中,很明显,现有的依赖单一传感器的系统无法提供所需的准确且鲁棒的姿态估计。为了解决这个问题,激光雷达、相机和IMU等常用传感器的融合正受到越来越多的关注。这一策略不仅结合了这些传感器的优势以提供增强的姿态估计,还有助于在单个传感器性能下降的环境中构建准确、密集且彩色的点云地图。
高效且准确的激光雷达-惯性-视觉里程计(LIVO)和地图构建仍然是具有挑战性的问题:1)整个LIVO系统需要处理激光雷达测量数据,这些数据每秒包含成百上千个点,以及高频率、高分辨率的图像。在有限的车载资源下,如何充分利用如此庞大的数据量,对计算效率提出了极高的要求;2)许多现有系统通常包括激光雷达-惯性里程计(LIO)子系统和视觉-惯性里程计(VIO)子系统,这两个子系统分别需要从视觉和激光雷达数据中提取特征以减少计算负载。在缺乏结构或纹理的环境中,这一提取过程往往导致特征点有限。此外,为了优化特征提取,必须针对激光雷达扫描模式和点密度的变化进行大量的工程调整;3)为了降低计算需求并实现相机与激光雷达测量之间的更紧密集成,需要一种统一的地图来同时管理稀疏点和高分辨率图像测量。然而,考虑到激光雷达和相机的异质性测量,设计和维护这样的地图尤其具有挑战性;4)为确保重建的有色点云的准确性,姿态估计需要达到像素级精度。满足这一标准带来了相当大的挑战:包括适当的硬件同步、激光雷达与相机之间外部参数的严格预校准、曝光时间的精确恢复,以及能够达到像素级实时精度的融合策略。
针对这些问题,我们提出了FAST-LIVO2,这是一个高效的LIVO系统,它通过顺序更新的误差状态迭代卡尔曼滤波器(ESIKF)紧密集成了激光雷达、图像和IMU测量。在IMU传播的先验信息基础上,系统状态按顺序首先通过激光雷达测量进行更新,然后通过图像测量进行更新,两者都基于单一的统一体素地图采用直接方法。具体来说,在激光雷达更新中,系统将原始点注册到地图中以构建和更新其几何结构;在视觉更新中,系统重用激光雷达地图点作为视觉地图点,而无需从图像中提取、三角测量或优化任何视觉特征。在地图中选择的视觉地图点与先前观察到的参考图像块相关联,然后投影到当前图像上,通过最小化直接光度误差(即稀疏图像对齐)来调整其姿态。为了提高图像对齐的准确性,FAST-LIVO2动态更新参考图像块,并使用从激光雷达点获得的平面先验。为了提高计算效率,FAST-LIVO2使用激光雷达点来识别当前图像中可见的视觉地图点,并在没有激光雷达点的情况下进行按需体素射线投射。FAST-LIVO2还实时估计曝光时间以处理光照变化。
下面一起来阅读一下这项工作~
1. 论文信息
标题:FAST-LIVO2: Fast, Direct LiDAR-Inertial-Visual Odometry
作者:Chunran Zheng, Wei Xu, Zuhao Zou, Tong Hua, Chongjian Yuan, Dongjiao He, Bingyang Zhou, Zheng Liu, Jiarong Lin, Fangcheng Zhu, Yunfan Ren, Rong Wang, Fanle Meng, Fu Zhang
机构:University of Hong Kong、Information Science Academy of China Electronics Technology Group
Corporation
原文链接:https://arxiv.org/abs/2408.14035
代码链接:https://github.com/hku-mars/fast-livo2
2. 摘要
本文提出了FAST-LIVO2:一种快速、直接的激光雷达-惯性-视觉里程计框架,旨在在SLAM任务中实现准确且鲁棒的状态估计,并为实时、机载机器人应用提供巨大潜力。FAST-LIVO2通过扩展卡尔曼滤波器(ESIKF)高效地融合了IMU、激光雷达和图像测量数据。为了解决异构激光雷达和图像测量数据之间的维度不匹配问题,我们在卡尔曼滤波器中采用了顺序更新策略。为了提高效率,我们对视觉和激光雷达融合都采用了直接方法,其中激光雷达模块在不提取边缘或平面特征的情况下注册原始点,而视觉模块在不提取ORB或FAST角点特征的情况下最小化直接光度误差。视觉和激光雷达测量的融合基于一个统一的体素图,其中激光雷达模块构建用于注册新激光雷达扫描的几何结构,而视觉模块将图像块附加到激光雷达点上。为了提高图像对齐的准确性,我们利用体素图中激光雷达点的平面先验(甚至细化平面先验),并在新图像对齐后动态更新参考块。此外,为了提高图像对齐的鲁棒性,FAST-LIVO2采用按需光线投射操作,并实时估计图像曝光时间。最后,我们详细介绍了FAST-LIVO2的三个应用:无人机机载导航,展示了系统在实时机载导航中的计算效率;机载测绘,展示了系统的测绘精度;以及基于网格和NeRF的3D模型渲染,强调了我们重建的密集地图对后续渲染任务的适用性。我们在GitHub上开源了我们的代码、数据集和应用,以造福机器人社区。
3. 效果展示


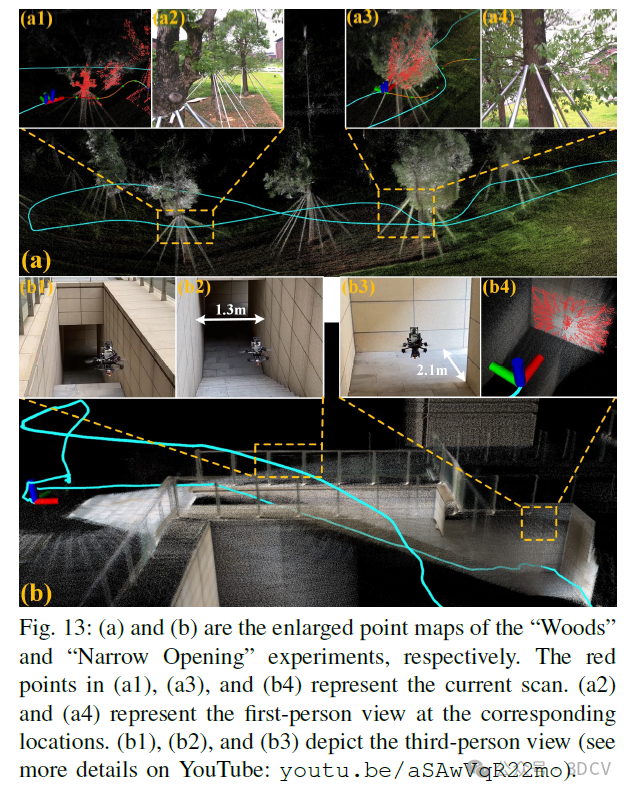
4. 主要贡献
FAST-LIVO2是在我们之前的工作中首次提出的FAST-LIVO的基础上开发的。与FAST-LIVO相比,新的贡献如下:
1)我们提出了一个高效的ESIKF框架,通过顺序更新解决了激光雷达和视觉测量之间的维度不匹配问题,提高了使用异步更新的FAST-LIVO的鲁棒性。
2)我们使用(甚至细化)来自激光雷达点的平面先验以提高准确性。相比之下,FAST-LIVO假设一个块中的所有像素具有相同的深度,这是一个大大降低了图像对齐中仿射扭曲准确性的假设。
3)我们提出了一种参考图像块更新策略,通过选择高质量的内点参考图像块(具有大视差和足够的纹理细节)来提高图像对齐的准确性。FAST-LIVO根据与当前视图的接近程度选择参考图像块,这往往导致低质量的参考图像块降低准确性。
4)我们进行在线曝光时间估计以处理环境光照变化。FAST-LIVO没有解决这个问题,导致在光照变化显著的情况下图像对齐收敛性差。
5)我们提出了按需体素射线投射,以增强在激光雷达点测量缺失(由激光雷达近距离盲区引起)时系统的鲁棒性,这是FAST-LIVO未考虑的问题。
我们对上述每一项贡献都进行了全面的消融研究,以验证其有效性。我们将提出的系统实现为实用的开源软件,并针对Intel和ARM处理器进行了精心优化以实现实时运行。该系统具有多功能性,支持多线旋转激光雷达、具有非传统扫描模式的新型固态激光雷达,以及针孔相机和各种鱼眼相机。推荐学习:PCL点云处理库-QT-VTK高阶实践班
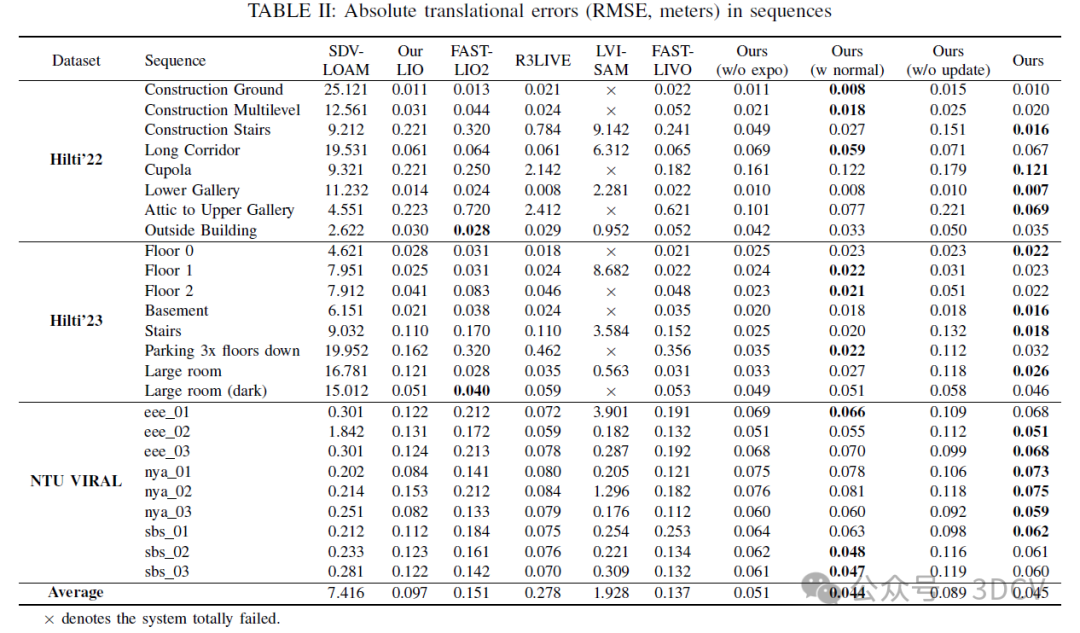
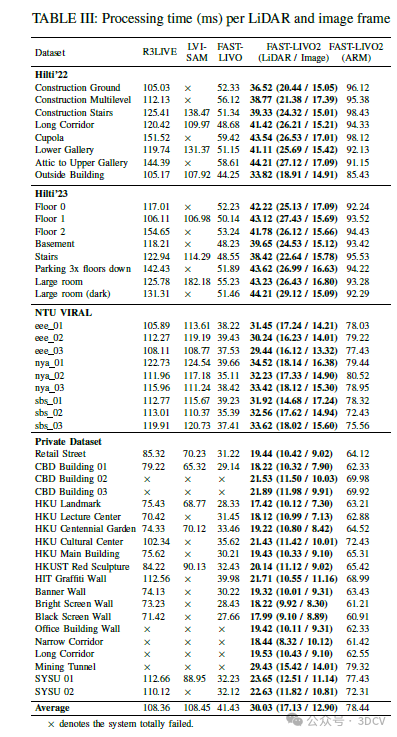
此外,我们在25个公共数据集序列(即Hilti和NTU-VIRAL数据集)以及各种具有代表性的私有数据集上进行了广泛的实验,以便与其他最先进的SLAM系统(如R3LIVE、LVI-SAM、FAST-LIO2等)进行比较。定性和定量结果均表明,我们提出的系统在准确性和鲁棒性方面显著优于其他同类系统,同时降低了计算成本。
为了进一步强调我们系统的实际应用性和多功能性,我们部署了三个不同的应用。首先,完全机载的自主无人机导航展示了系统的实时能力,开创了使用激光雷达-惯性-视觉系统进行真实世界自主无人机飞行的先河。其次,机载测绘展示了系统在实际使用中在无结构环境下的像素级精度。最后,高质量生成网格、纹理和NeRF模型证明了系统适用于渲染任务。我们将代码和数据集发布在GitHub上。
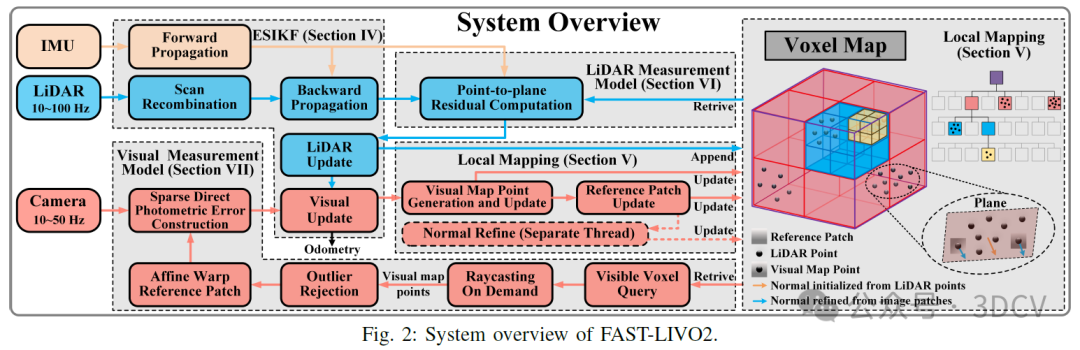
5. 基本原理是啥?
我们系统的概述如图2所示,包含四个部分:扩展状态增量卡尔曼滤波器(ESIKF)、局部地图、激光雷达测量模型和视觉测量模型。
首先,通过扫描重组将异步采样的激光雷达点重新组合成相机采样时间下的扫描。然后,我们通过具有顺序状态更新的ESIKF紧密耦合激光雷达、图像和惯性测量,其中系统状态首先通过激光雷达测量进行更新,然后通过图像测量进行更新,两者都基于单一的统一体素地图使用直接方法。为了构建ESIKF更新中的激光雷达测量模型,我们计算帧到地图的点到平面残差。为了建立视觉测量模型,我们从地图中提取当前视场(Field of View, FoV)内的视觉地图点,利用可见体素查询和按需光线投射;提取后,我们识别并丢弃异常的视觉地图点(例如,被遮挡或表现出深度不连续的点);然后,我们计算用于视觉更新的帧到地图的图像光度误差。
视觉和激光雷达更新所用的局部地图是一个体素地图结构:激光雷达点构建并更新地图的几何结构,而视觉图像则将图像块附加到选定的地图点(即视觉地图点)上,并动态更新参考图像块。在单独的线程中,进一步细化更新后的参考图像块的法线向量。
6. 实验结果
7. 总结 & 未来工作
本文提出了FAST-LIVO2,这是一个直接的LIVO框架,能够在实时重建地图的同时实现快速、准确且鲁棒的状态估计。FAST-LIVO2能够在严重激光雷达和/或视觉退化的情况下实现高精度定位,并具备鲁棒性。
速度上的提升得益于在高效的ESIKF(Extended State Implicit Kalman Filter,扩展状态隐式卡尔曼滤波器)框架下,使用原始的激光雷达、惯性传感器和相机测量值进行顺序更新。在图像更新中,进一步采用了基于稀疏块的逆组合图像对齐公式以提高效率。
准确性上的提升得益于利用(甚至细化)来自激光雷达点的平面先验来提升图像对齐的准确性。此外,还使用了一个统一的体素地图来同时管理地图点和观察到的高分辨率图像测量值。本文开发并验证了支持几何构建和更新、视觉地图点生成和更新以及参考块更新的体素地图结构。
鲁棒性上的提升得益于实时估计曝光时间,从而有效应对环境光照变化,以及按需进行体素光线投射以应对激光雷达的近距离盲区。
在广泛的公共数据集上对FAST-LIVO2的效率和准确性进行了评估,而在私有数据集上对每个系统模块的鲁棒性和有效性进行了评估。此外,还展示了FAST-LIVO2在无人机导航、3D建图和模型渲染等现实世界机器人应用中的应用。
作为里程计,FAST-LIVO2在长距离行驶时可能会出现漂移。未来,我们计划将回环闭合和滑动窗口优化集成到FAST-LIVO2中,以减轻这种长期漂移。此外,还可以利用准确且密集的彩色点图来提取语义信息,以实现对象级语义建图。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~
本文仅做学术分享,如有侵权,请联系删文。
25个顶会论文的课题如下:
1、SLAM/3DGS/三维点云/医疗图像/扩散模型/结构光/Transformer/CNN/Mamba/位姿估计 顶会论文指导
2、基于扩散模型的跨域鲁棒自动驾驶场景理解
3、基于环境信息的定位,重建与场景理解
4、轻量级高保真Gaussian Splatting
5、基于大模型与GS的 6D pose estimation
6、在挑战性遮挡环境下的GS-SLAM系统研究
7、基于零知识先验的实时语义地图构建SLAM系统
8、基于3DGS的实时语义地图构建
9、基于文字特征的城市环境SLAM
10、面向挑战性环境的SLAM系统研究
11、特殊激光传感器融合视觉的稠密SLAM系统
12、多传感器融合的单目深度估计系统研究
13、多帧融合的单目深度估计系统研究
14、复杂天气条件下的单目深度估计系统研究
15、高精度的单目深度估计系统研究
16、基于大模型的单目深度估计系统研究
17、高精度的光流估计系统
18、挑战场景下2D-2D,2D-3D或3D-3D配准问题
19、未知物体同时重建与位姿估计问题
20、类别级或开放词汇位姿估计问题
21、位姿估计中的域差距问题
22、基于图像或点云的 3D Object Detection、Semantic Segmentation、Occupancy Prediction(主要是面向自动驾驶的感知任务,单模态和融合)
23、医疗图像分割任务的模型结构设计
24、可形变对象(软体)的实时三维重建与非刚性配准
25、机器人操作可形变对象建模与仿真


















 3674
3674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









