






0. 论文信息
标题:CNN Mixture-of-Depths
作者:Rinor Cakaj, Jens Mehnert, Bin Yang
原文链接:https://arxiv.org/abs/2409.17016
1. 摘要
我们为卷积神经网络(CNN)引入了深度混合(MoD ),这是一种新的方法,通过基于通道与当前预测的相关性选择性地处理通道来提高CNN的计算效率。该方法通过在卷积块(Conv块)内动态选择用于集中处理的特征图中的关键通道来优化计算资源,同时跳过不太相关的通道。与需要动态计算图的条件计算方法不同,CNN MoD使用具有固定张量大小的静态计算图,这提高了硬件效率。它加速了训练和推理过程,而不需要定制CUDA内核、独特的损失函数或微调。CNN MoD要么以减少的推理时间、GMAC和参数匹配传统CNN的性能,要么在保持相似的推理时间、GMAC和参数的同时超过它们的性能。例如,在ImageNet上,ResNet86-MoD的性能比标准ResNet50高出0.45%,CPU和GPU的加速分别提高了6%和5%。此外,ResNet75-MoD实现了与ResNet50相同的性能,在CPU上加速25%,在GPU上加速15%。
2. 引言
近年来,卷积神经网络(CNNs)在多种计算机视觉应用中取得了显著进展,如图像识别、目标检测和图像分割。尽管它们表现出色,但CNNs通常需要大量的计算能力和广泛的内存使用,这在将高级模型部署到计算资源有限的设备上时带来了巨大挑战。
为了解决这些挑战,剪枝技术被广泛应用,通过根据既定标准移除冗余权重或滤波器来减小CNN的模型大小和计算需求。然而,这些方法对所有输入进行统一处理,无法根据不同输入的不同复杂性进行调整,这可能导致性能下降。
另一种方法是动态计算或条件计算,它根据输入的复杂性调整计算资源以提高效率。然而,由于这些方法依赖于动态计算图,而动态计算图通常与针对静态计算工作流优化的系统不兼容,因此将它们集成到硬件中具有挑战性。例如,Wu等人报告称,当通过单独的策略网络有条件地执行层时,处理时间会增加。尽管在理论上减少了计算需求,但在GPU或FPGA等硬件上的实际收益有限,因为非统一任务会干扰标准卷积操作的效率。此外,Ma等人表明,浮点运算(FLOPS)不足以估计推理速度,因为它们经常排除逐元素运算,如激活函数、求和和池化。
为了将动态计算的性能优势与静态计算图的操作效率结合起来,我们受Transformer的深度混合(Mixture-of-Depths)方法的启发,提出了CNN的深度混合(MoD)。CNN MoD的基本原理是,在网络的给定层中,只有特征图内选定的一部分通道对于有效的卷积处理至关重要。通过关注这些关键通道,CNN MoD在不降低网络性能的情况下提高了计算效率。
接下来,通道选择器使用顶部k选择机制根据计算出的重要性分数识别出最重要的k个通道。这些通道被发送到Conv-Block,该Conv-Block设计为在降低的维度上操作,从而提高计算效率。为了确保来自处理输出\hat {X}的梯度有效地优化通道选择过程,将处理后的通道按其各自的重要性分数进行缩放。这允许梯度流回通道选择器,从而在整个训练过程中学习通道的重要性。
最后一步是融合操作,将处理后的通道添加到原始特征图的前k个通道中。这种融合不仅保留了特征图的原始维度,还通过结合处理过和未处理过的通道来增强特征表示。推荐课程:全搞定!基于TensorRT的部署+CUDA加速。
Conv-Block内处理通道数量的减少由一个超参数控制,其中k定义了要处理的通道数。这里,C是Conv-Block中输入通道的总数。例如,在典型的ResNet架构中,通常处理1024个通道的瓶颈块在c=64时仅处理16个通道(k=16)。这种选择性处理通过关注较小的通道子集显著降低了计算负载。此外,Conv-Block内核的大小也根据输入通道数量的减少进行了调整。
经验评估表明,在CNN架构中最佳地集成MoD涉及将其与标准Conv-Block交替排列。在ResNets或MobileNetV2等架构中,Conv-Block被组织成包含多个相同类型Conv-Block(即具有相同数量输出通道)的模块。每个模块以一个标准块开始,后跟一个MoD块。这种交替排列基于Transformer的深度混合原则。这并不意味着在现有序列中添加额外的MoD块,而是将原始架构中每第二个Conv-Block替换为MoD块,以确保架构的总体深度保持不变。
3. 效果展示
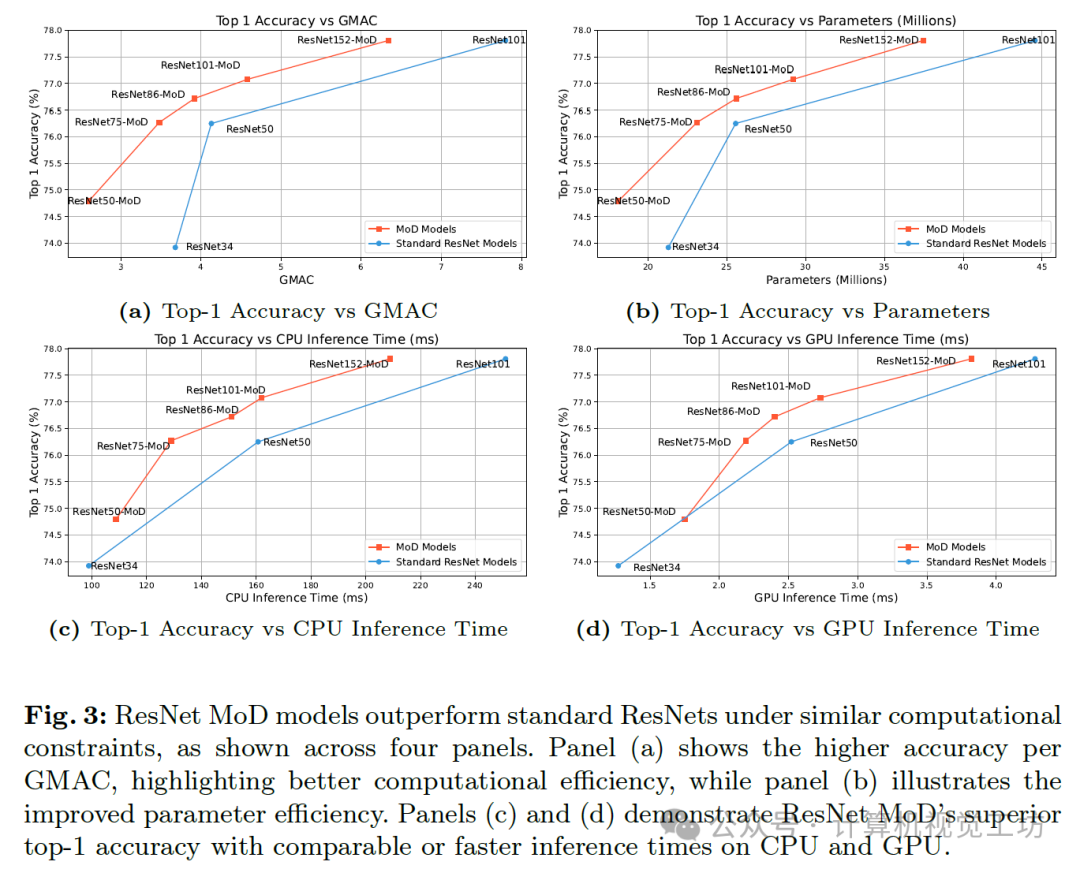
如图中的四个面板所示,在类似的计算约束下,ResNet MoD模型的表现优于标准ResNet。面板(a)展示了每GMAC(每秒十亿次乘积累加运算)的更高精度,突出了更好的计算效率,而面板(b)则说明了参数效率的提高。面板(c)和(d)则展示了ResNet MoD在CPU和GPU上具有可比或更快的推理时间的同时,实现了更高的top-1精度。
4. 主要贡献
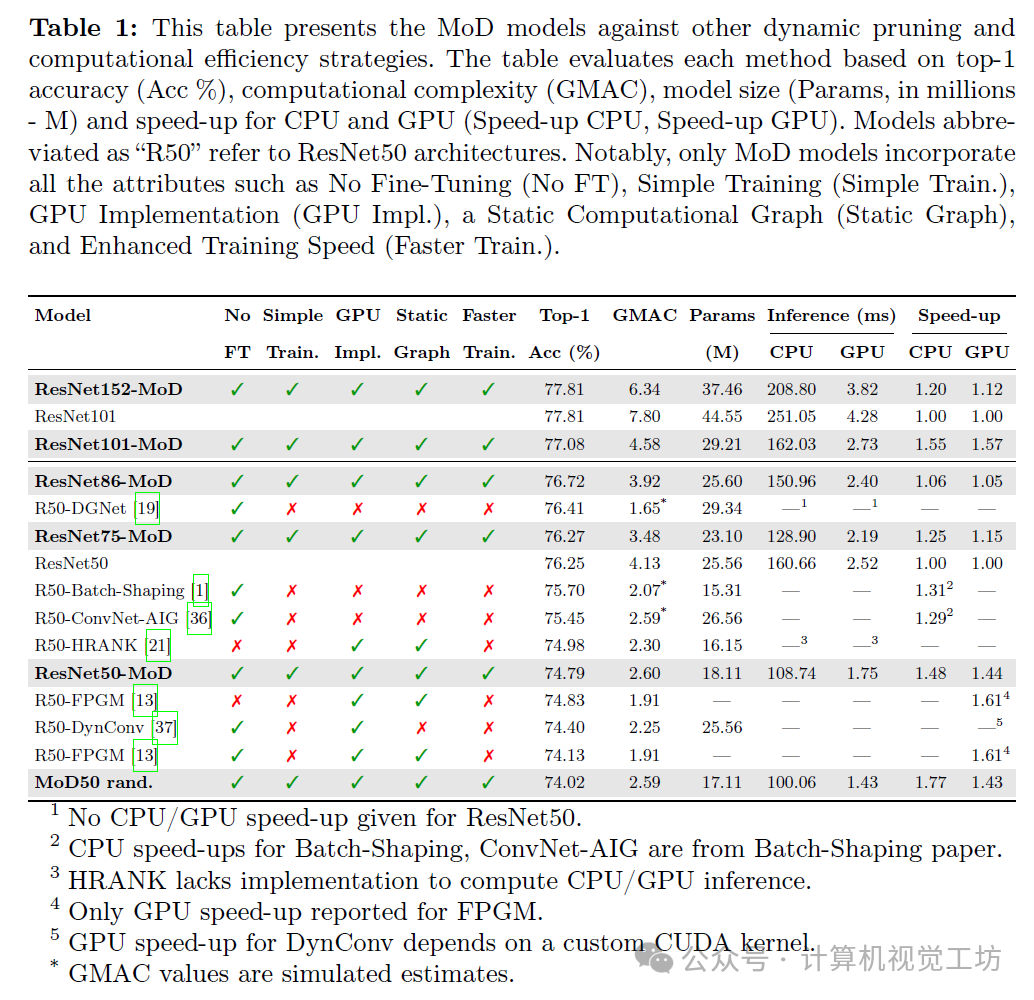
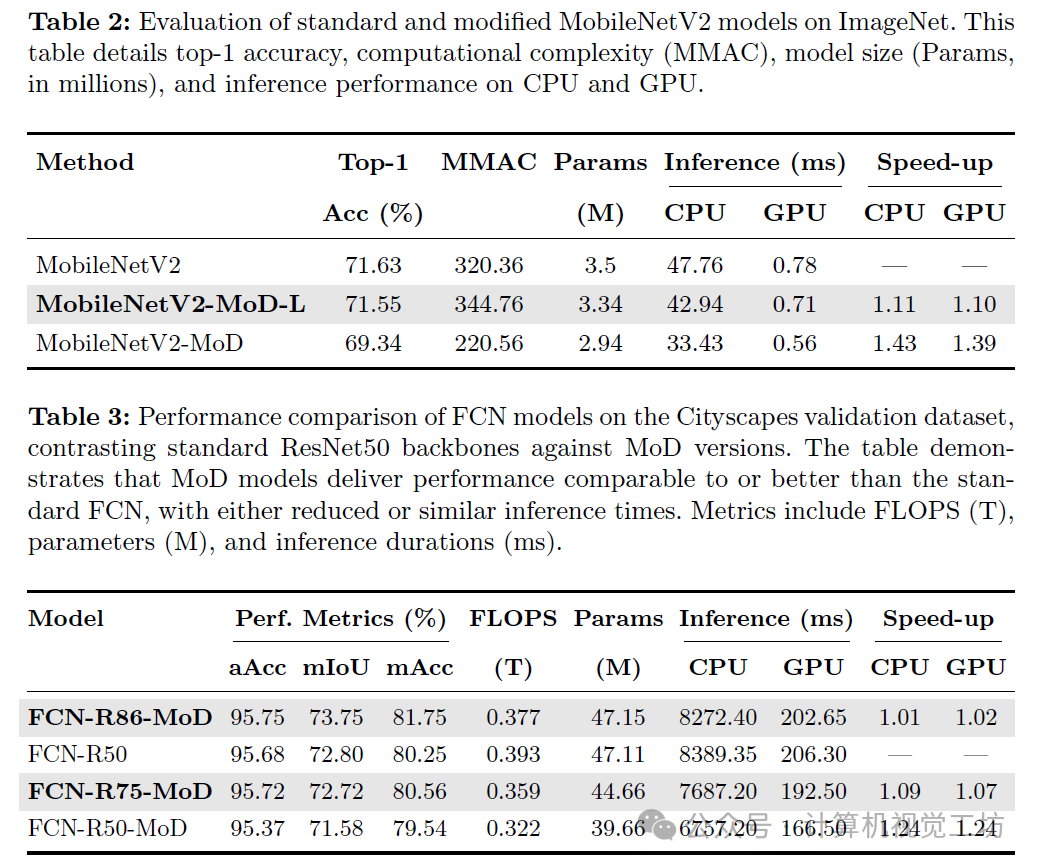
CNN MoD实现了与传统CNNs相当的性能,但具有更短的推理时间、更少的GMACs和参数,或者在保持相似推理时间、GMACs和参数的同时超越它们。在ImageNet数据集上,我们的ResNet75-MoD与标准ResNet50的准确率相当,并在GPU上提供15%的速度提升,在CPU上提供25%的速度提升。在语义分割和目标检测任务中也可以实现类似的结果。
5. 方法
如图1所示,MoD机制通过动态选择Conv-Block内用于聚焦计算的最重要通道来增强CNN特征图处理。
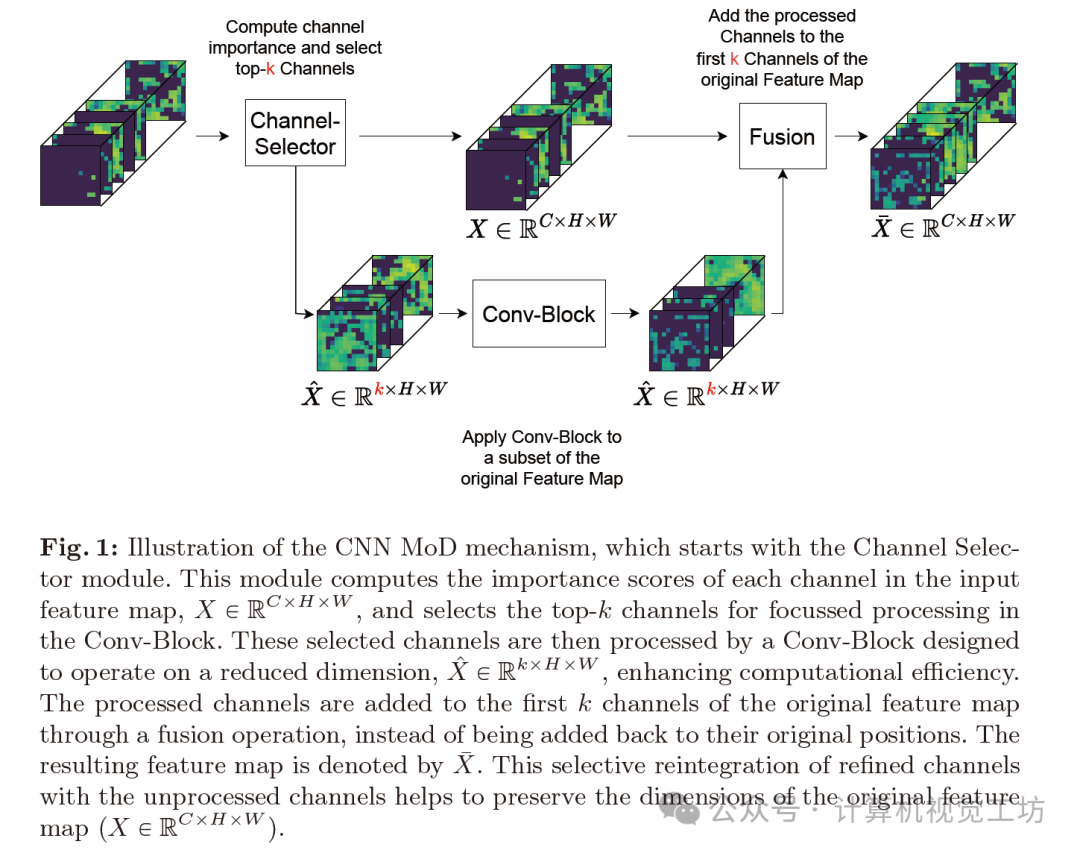
MoD始于通道选择器(Channel Selector),如图2所示,其设计类似于Squeeze-and-Remember块。它评估输入特征图X,然后通过具有瓶颈设计的两层全连接神经网络进行处理。Sigmoid激活函数生成分数,指示每个通道的重要性。

6. 实验结果
7. 总结 & 未来工作
在本研究中,我们提出了CNN MoD方法,该方法受启发于为Transformer开发的深度混合(Mixture-of-Depths)方法。该技术将静态剪枝和动态计算的优势结合于同一框架内。它通过动态选择特征图中的关键通道,在Conv-Blocks内进行有针对性的处理,同时跳过相关性较低的通道,从而优化计算资源。
它保持了一个静态的计算图,无需定制CUDA内核、额外的损失函数或微调,即可优化训练和推理速度。这些特性使MoD区别于其他动态计算方法,极大地简化了训练和推理过程。CNN MoD在图像识别、语义分割和对象检测中实现了与传统CNN相当的性能,但减少了推理时间、GMACs和参数数量,或者在保持相似推理时间、GMACs和参数数量的同时超越了传统CNN。例如,
在ImageNet上,ResNet86-MoD以CPU上6%和GPU上5%的速度提升,超越了标准ResNet50的性能0.45%。此外,ResNet75-MoD在CPU上实现25%和GPU上实现15%的速度提升,同时达到了与ResNet50相同的性能。
虽然当前的融合操作已经实现了显著的效率提升,特别是在ImageNet等高维数据集和Cityscapes、Pascal VOC等实际任务中,但进一步优化切片操作可能会带来更大的改进。未来的工作将探索优化这一组件的方法,可能通过定制CUDA内核来实现。此外,进一步研究层内处理通道的最优数量对于优化性能也颇具前景。
对更多实验结果和文章细节感兴趣的读者,可以阅读一下论文原文~


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









