






近期,社群中不少小伙伴提出了想多了解一点大模型训练、微调、推理的相关知识,以及各个环节如何选择GPU,本文尝试对相关问题进行深度解析,本文介绍了大模型训练、微调、推理的基本原理及相关概念,以及它们之前的关系,大致介绍了训练、微调、推理的过程,以及主流大小GPU的相关参数,提出训练、微调、推理所采用的GPU的区别。
什么是大模型训练、微调、推理?
大模型训练是指利用大规模数据集对深度神经网络进行训练,以提升模型的表达能力和预测性能。训练过程中,模型通过调整网络中的权重和偏置,使得损失函数最小化,从而优化模型的性能。
1. 大模型训练:像建造全知图书馆

想象一下你是一位图书管理员,要为AI建造一座包含全人类知识的图书馆。训练好的模型就像整整齐齐装满知识的图书馆。
训练过程就是:
收集材料:把海量本书(如维基百科、小说、论文)堆进仓库
制定规则:教会AI识别词语关系(比如"猫追老鼠"中"追"代表动作关系)
反复练习:让AI猜下一句话是什么,猜错就调整记忆库(参数),直到能基本猜对(这个不同大模型准确率不一样,一般都会有评测)。
训练的本质:通过海量训练数据(tokens)调整模型参数(权重、偏置等),让模型学会语言规律和常识。
就像教婴儿认字——先看百万张图片,逐渐理解"猫"对应毛茸茸的动物。

大模型训练再细分的话分为预训练和后训练。
大模型预训练(Pre-training):模型在大规模通用数据上首先进行无监督或自监督训练,学习通用知识、语义和基本能力。
例如DeepSeek-V3-Base、DeepSeek-V2、DeepSeek-Coder V1未经过任何微调,是预训练大模型。
大模型后训练 (Post-training):是在预训练模型基础上,通过人类反馈(SFT/RL)优化行为,使其符合特定需求如人类偏好。
例如DeepSeek-V3、DeepSeek-R1系列、DeepSeek-Coder V2、DeepSeek-VL2都是后训练大模型。


预训练与后训练对比
2. 大模型微调:将博士生培养专科医生

微调其实也是模型后训练的一种方法。 只是后训练通常由模型提供商负责,会在出厂前进行预训练和后训练,以便把模型打造成可交付的状态,而微调这种后训练,一般由模型使用者(甲方自己的技术团队或技术厂商)进行,以便实现领域垂直大模型。
例如通用模型已掌握医学基础知识(如解剖学名词),但要做心脏手术还需专项训练:
定向输入:给模型海量心脏病例和手术记录(特定领域数据)
专家经验(示范):展示优秀医生的诊断思路(带答案的例题,即问答对)
模拟考核:让模型诊断病例并评分,重点纠正误诊(模型评价)
微调本质:在预训练模型上,用少量专业数据(如1%原数据量)调整部分参数。就像让全科医生专攻心血管科——保留基础能力(如问诊技巧),强化专科知识(如心电图解读)。
微调后的模型能像资深医生一样,根据症状精准判断病因 。
微调的方法有很多种,常用方法有:
(1) 全量微调(Full Fine-Tuning)
全量微调是在预训练模型的基础上,对所有参数进行微调。在参数修改方面,所有参数都会被更新。其优点显著,能够充分利用预训练模型的通用知识,同时针对特定任务进行优化,通常可以获得较好的性能。
然而,该方法也存在明显不足,计算资源需求较高,尤其是对于参数量非常大的模型来说,这一问题更为突出;训练时间较长,而且在数据量较少的情况下,可能会导致模型过拟合。
(2) 参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
参数高效微调的核心是只对模型的一部分参数进行微调,保持大部分参数不变,这使得它在资源利用上更加高效。
以下是几种常见的参数高效微调方法:
(a)LoRA(Low-Rank Adaptation)
LoRA 通过低秩分解来调整模型的权重矩阵,只训练少量的新增参数。这种方法的优点是计算资源需求低,训练时间短,并且保留了预训练模型的大部分知识。不过,其缺点是可能达不到全量微调的性能。
(b)Prefix-Tuning
Prefix-Tuning 在模型的输入端添加可训练的前缀,这些前缀参数在微调过程中被更新。它适用于自然语言生成任务,具有计算资源需求低、训练时间短的优点,但可能需要更多的调参经验。
(c)Adapter
Adapter 在模型的每一层或某些层之间插入可训练的适配器模块,这些适配器参数在微调过程中被更新。该方法计算资源需求低、训练时间短,还可以针对多个任务进行微调,不过同样可能需要更多的调参经验。
(d)BitFit
BitFit 只微调模型的偏置项(bias terms),而不改变权重。其最大优势是计算资源需求极低,训练时间非常短,但性能提升可能有限。
(3) 强化学习微调(Reinforcement Learning Fine-Tuning, RLHF)
强化学习微调使用强化学习方法,通过人类反馈或其他奖励信号来优化模型,模型参数会根据奖励信号进行更新。它的优点在于可以优化模型的交互行为,特别是在对话系统等交互式任务中,还能更灵活地调整模型的行为以满足特定的业务需求。但该方法实现复杂,需要设计合适的奖励机制,且训练过程可能不稳定,需要更多的调试和监控。
(4) 提示调优(Prompt Tuning)
提示调优通过冻结整个预训练模型,只允许每个下游任务在输入文本前面添加可调的标记(Token)来优化模型参数,仅更新提示部分的参数。它具有计算资源需求低、训练时间短的优点,适用于少样本学习任务。不过,其可能达到的性能可能略低于全量微调,且需要精心设计提示。
(5) 深度提示调优(Deep Prompt Tuning)
深度提示调优在预训练模型的每一层应用连续提示,而不仅仅是输入层,同样只更新提示部分的参数。这种方法可以在更深层次上优化模型,提高性能,适用于复杂任务,但实现复杂,需要更多的调参经验。
(6) 动态低秩适应(DyLoRA)
DyLoRA 在 LoRA 的基础上,动态调整低秩矩阵的大小,动态调整低秩矩阵的大小,只更新部分参数。它计算资源需求低,训练时间短,可以在更广泛的秩范围内优化模型性能,但实现复杂,需要更多的调参经验。
(7) 自适应低秩适应(AdaLoRA)
AdaLoRA 根据权重矩阵的重要性得分,自适应地分配参数规模,根据重要性动态调整参数规模,只更新部分参数。该方法计算资源需求低,训练时间短,可以更高效地利用参数,提高模型性能,但同样存在实现复杂、需要更多调参经验的问题。
(8) 量化低秩适应(QLoRA)
QLoRA 结合 LoRA 方法与深度量化技术,减少模型存储需求,同时保持模型精度,只更新部分参数,同时进行量化。它计算资源需求低,训练时间短,适用于资源有限的环境,但实现复杂,需要更多的调参经验。
3. 大模型推理:像侦探破解悬案
前面讲了大模型训练,它的过程是构建多维语义(向量)空间的过程,不同的Token在一个空间位置上,那推理就是依据提示词Token,在向量空间提取相关的Token,形成一个完整答案。
大模型推理好比"教AI玩解谜游戏"——就像你给一个拥有全人类知识库的AI玩家,让它通过拆解线索、组合逻辑碎片,最终拼出完整答案的过程。
当用户问"如何用大象称体重?",推理过程如同:

(1) 线索搜集:激活“大象-体重-称量”相关记忆(如阿基米德浮力原理)
(2) 逻辑推演:
• 第一步:回忆"曹冲称象"故事(类比迁移)
• 第二步:计算船排水量与浮力关系(数学推理)
• 第三步:设计具体操作步骤(工程思维)
(3) 验证优化:检查方案可行性(如大象是否配合),生成分步指导
推理本质:将输入问题拆解为知识图谱中的关联节点,通过Transformer架构的多层计算,最终输出逻辑连贯的答案。就像用千万块拼图(参数)组合出完整图案,过程中不断排除错误组合(如"用蚂蚁称大象"的荒谬方案)。
大模型训练、微调、推理阶段对比总结
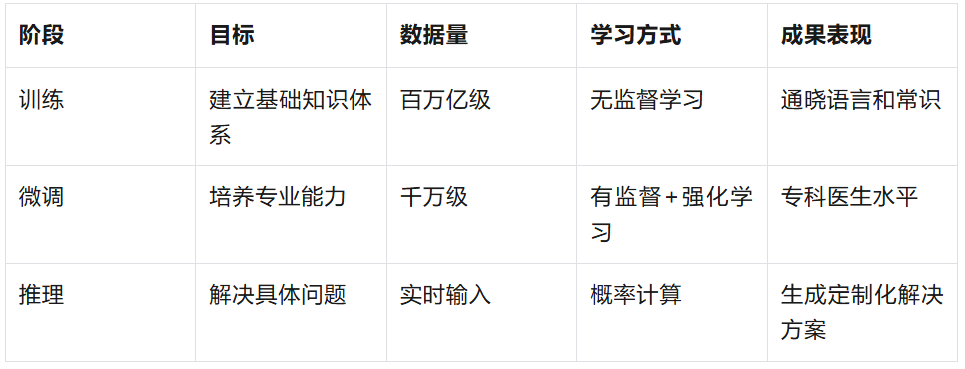
如果看到这里,对训练、微调、推理是什么还不明白的话,可以再做个类比。
这三个阶段如同教育体系——训练是义务教育打基础,微调是大学专业深造,推理则是职场实战应用。当前技术瓶颈在于如何让AI像人类一样,在少量微调后快速适应全新领域(如从医疗转向法律)。
4. 大模型训练、微调、推理如何选择GPU?
哪些GPU适合大模型训练?哪些适合推理呢?
以下是NVIDIA H100、A100、A6000、A4000、V100、P6000、RTX 4000、L40s、L4的主要性能指标参数表:

这个表格总结了每个GPU的架构、FP16/FP32计算性能、Tensor Core性能、显存大小、显存类型以及内存带宽,便于比较各个GPU在不同任务场景中的适用性。
按照架构来讲,越新的架构肯定性能相对更好,这些架构从旧到新依次是:
- Pascal(2016年发布)
- Volta(2017年发布)
- Turing(2018年发布)
- Ampere(2020年发布)
- Ada Lovelace(2022年发布)
- Hopper(2022年发布)
2023年后又出了A800、H800、H200、B100、B200、L40S(训推一体)。
更推荐用于训练(微调)的GPU(大卡):
H系列大卡 和 A100 曾是训练大规模模型(如GPT-3、GPT-4等)的最佳选择,但现在H200、B200性价比更高,或将成为未来大模型训练的主流GPU。
V100 仍然是中型模型训练的可靠选择,尤其适合在预算有限的情况下使用。
A6000 可以在工作站环境中进行中小型模型的训练。
更推荐用于推理的GPU:
A6000 和 L40s 是推理任务的理想选择,提供了强大的性能和显存,能够高效处理大模型的推理。
A100 和 H100 在超大规模并发或实时推理任务中表现优异,但由于其高成本,通常只在特定场景中使用。
A4000 和 RTX 4000 则适合中小型推理任务,是经济实惠的选择。
L4 非常适合高效推理场景,尤其是在图像、视频等应用中需要高效能推理的场景。它在性能和能效比之间达到了很好的平衡,成为性价比推理GPU的优秀选择。
还有很多的国产卡用于推理,如华昇腾910B/C、昆仑芯等。
以上只是一个当前主流的建议,实际要考虑技术发展与变革,以及各类卡的市场价格变动情况,毕竟性价比最重要嘛。
5. 大模型训练、微调、推理GPU显存需求计算
5.1 大模型训练GPU资源相关因素:
模型存储: 每个模型参数(权重和偏置项)都需要一定的存储空间。在训练过程中,这些参数会被更新,并且需要在显存中保存最新的值以便后续计算使用。
激活值存储: 在前向传播过程中,每一层的输出(激活值)也需要被暂时存储起来,以便在反向传播时用于计算梯度。这意味着除了模型参数外,还需要额外的空间来存储每一步的中间结果。
梯度存储: 在反向传播阶段,每个参数都会有一个对应的梯度,这些梯度也需要存储在显存中,直到它们被用来更新参数为止。
批处理大小: 训练时使用的批处理大小也会影响显存需求。较大的批处理可以提高训练效率,但会占用更多的显存,因为需要同时处理更多的样本数据。
优化器状态: 一些优化算法(如Adam或RMSprop)会在每个参数上维护额外的状态(如移动平均值等),这些状态同样需要存储空间。
其他开销: 除了上述主要因素之外,还有一些其他的开销,比如模型架构元数据、临时变量以及其他运行时需要的数据结构。
大模型训练近似计算公式如下:
大模型训练需要的算力究竟是怎么计算出来的呢?
OpenAI在Scaling Laws 论文(https://arxiv.org/pdf/2001.08361)中给我们提出了一个经验公式:
C = rT ≈ 6PD,这是一个简单计算方式,实际每一个大模型的情况不一样,会有一定的差别。
我们制作成了Excel计算公式,有需要的小伙伴入群后可以免费领取。

C:训练一个Transformer模型所需的算力,单位是FLOPS;
P:Transformer模型中参数的数量;
D:训练数据集的大小,也就是用来训练的tokens数;
r:训练集群中所有硬件总的计算吞吐,单位是FLOPS;
T:训练模型需要的时间,单位是秒。
系数6:Scaling Laws论文对这个公式做了简单推导,感兴趣的小伙伴可以查看论文原文。
在计算所需算力的时候,我们刚才都是使用 FLOPS这个单位(Floating Point Operations Per Second即每秒浮点运算次数),我们将其换算成天(day)更加直观。
以 Meta 开源的LLaMA-1模型为例。
其参数为65B,基于1.4T的tokens 数据集,使用了2048张A100 ,实际训练了21天,我们来复核计算一下时间。
1)该模型训练所需的算力计C算过程如下:
C = rT ≈ 6PD=665109*1.4*1012=546*10^21 FLOPS
2)我们查到A100 BF16 Tensor Core的算力为312 TFLOPS,实际上一块A100的算力一般在130-180 TFLOPS之间,我们取150,2048张卡的集群算力吞吐为:
r=20481501012=300*1015 FLOPS,即300PFLOPS
3)代入到上面提到的公式:C = rT,得出训练LLaMA-1模型所需时间为:
T=C/r=5461021/(300*1015)=1.8210^6 seconds ≈ 21 days
这一计算结果和 LLaMA-1 在论文中得出的实际训练时间基本一致。
这里要补充一下,随着大模型优化技术的不断发展,可能实际上的值会有不同,以上仅是一个估算。
5.2 大模型微调显存计算
要计算大型模型微调所需的显存,我们需要考虑训练过程中涉及的各种组成部分及其占用的显存。以下是根据给定内容总结的关键点:
微调显存组成部分
(1)模型权重:每个浮点数(float32)占用4字节的空间。
(2)优化器:不同的优化器需要的显存大小不同。
AdamW:对于每个参数,需要额外存储两种状态(动量和二阶矩),每个状态占用8字节,总计额外占用16字节,这说明优化器所占用的显存是全精度(float32)模型权重的2倍。
bitsandbytes优化的AdamW:每个参数需要额外存储的状态占用2字节,即全精度模型权重的一半。
SGD:优化器状态占用的显存与全精度模型权重相同。
(3)梯度:全精度(float32)模型权重所占用显存与梯度所占用显存相同。
(4)计算图内部变量(通常称为前向激活或中间激活):
这些变量在PyTorch、TensorFlow等框架中用于执行前向和后向传播,需要存储图中的节点数据,这部分显存需求在运行时才能确定。
示例计算:
假设一个7B参数的全精度模型,每个参数占用4字节,则模型权重占用 (710^94) 字节 = 28GB。
使用AdamW优化器时,优化器状态占用 (710^916) 字节 = 112GB。
梯度占用与模型权重相同的显存,即28GB。
因此,总显存需求大约为 (28 + 112 + 28) GB = 168GB。
但是,考虑到实际情况中的显存需求通常是模型权重的3-4倍,那么对于7B参数的模型,显存需求大约为 (283) GB 到 (284) GB,即78GB到104GB。
显存这么贵,如果想减少推理显存大小怎么办,一般就得优化相关算法了,例如:
量化:使用更少的位数表示权重和梯度,例如使用8位或更低精度的表示。
模型切分:将模型分割成多个部分,分别在不同的设备上进行计算。
混合精度计算:使用混合精度训练,例如FP16或BF16,以减少显存占用。
Memory Offload:将部分数据卸载到主内存或其他存储设备,减少显存占用。
主流的计算加速框架如DeepSpeed、Megatron等已经实施了上述的一些技术来降低显存需求。
5.3 大模型推理的显存计算
大模型推理所需显存=模型参数部分+激活参数部分+KV Cache部分
(1)模型参数部分=模型参数量 × 精度系数
(2)激活参数部分=激活参数量 × 精度系数
(3)KV Cache部分=并发数 × (输入Token数+输出Token数) × 2 × 层数 × hidden_size × Sizeof(精度系数)
示例:以FP8精度的满血版DeepSeek-R1 671B为例(MoE架构),假设batch size=30(并发30),isl=2048,out=2048,num_layers=61,
hidden_size=7168总的显存容量评估如下:=671×1GB+37x1G+30×(2048+2048)×2×61×7168×1Bytes=671 GB + 100.08GB=808.08GB
其中,MoE 层和非 MoE 层的 kv cache 计算公式不一样。
对于非 MoE 层, KV Cache 的计算公式为:
KV Cache=2(表示 Key 和 Value 两个矩阵)×Batch Size×Sequence Length×Hidden Size×精度(字节数) × 层数
对于 MoE 层,KV Cache 的计算公式为:
KV Cache =2×Batch Size×Sequence Length×激活专家数量×压缩维度×精度(字节数)× 层数。
Sequence Length=输入Token数+输出Token数。
推荐DeepSeek部署资源计算器:https://tools.thinkinai.xyz/#/server-calculator
由于篇幅所限,本文仅针对大模型的训练、微调和推荐,进行一次简单地介绍。本公众号发布了很多场景大模型部署、训练、微调、推理的实操文章。
感兴趣的朋友请关注我们,随时了解AI技术实战场景和算力最佳解决方案~


















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









