






1.背景介绍
热点聚焦:DeepSeek-R1 & V3 引爆全球关注!
自从深度求索团队开源了 DeepSeek-R1 和 DeepSeek-V3,这两款模型迅速成为AI领域的焦点,引发了全球范围的热议!它们不仅是人工智能技术的重大突破,更是深度求索团队献给全人类的一份重磅科技大礼 。
| 模型名称 | 简介 |
|---|---|
| DeepSeek-V3 | DeepSeek-V3 是一款拥有 6710 亿参数的混合专家(MoE)语言模型,采用多头潜在注意力(MLA)和 DeepSeekMoE 架构,结合无辅助损失的负载平衡策略,优化推理和训练效率。通过在 14.8 万亿高质量tokens上预训练,并进行监督微调和强化学习,DeepSeek-V3 在性能上超越其他开源模型,接近领先闭源模型。 |
| DeepSeek-R1 | DeepSeek-R1 是一款强化学习(RL)驱动的推理模型,解决了模型中的重复性和可读性问题。在 RL 之前,DeepSeek-R1 引入了冷启动数据,进一步优化了推理性能。它在数学、代码和推理任务中与 OpenAI-o1 表现相当,并且通过精心设计的训练方法,提升了整体效果。 |
| DeepSeek-R1-Distill-Llama-8B | DeepSeek-R1-Distill-Llama-8B 是基于 Llama-3.1-8B 开发的蒸馏模型。该模型使用 DeepSeek-R1 生成的样本进行微调,展现出优秀的推理能力。在多个基准测试中表现不俗,其中在 MATH-500 上达到了 89.1% 的准确率,在 AIME 2024 上达到了 50.4% 的通过率,在 CodeForces 上获得了 1205 的评分,作为 8B 规模的模型展示了较强的数学和编程能力-、 |
| DeepSeek-R1-Distill-Llama-70B | DeepSeek-R1-Distill-Llama-70B 是基于 Llama-3.3-70B-Instruct 经过蒸馏训练得到的模型。该模型是 DeepSeek-R1 系列的一部分,通过使用 DeepSeek-R1 生成的样本进行微调,在数学、编程和推理等多个领域展现出优秀的性能。模型在 AIME 2024、MATH-500、GPQA Diamond 等多个基准测试中都取得了优异的成绩,显示出强大的推理能力 |
| DeepSeek-R1-Distill-Qwen-1.5B | DeepSeek-R1-Distill-Qwen-1.5B 是基于 Qwen2.5-Math-1.5B 通过知识蒸馏得到的模型。该模型使用 DeepSeek-R1 生成的 80 万个精选样本进行微调,在多个基准测试中展现出不错的性能。作为一个轻量级模型,在 MATH-500 上达到了 83.9% 的准确率,在 AIME 2024 上达到了 28.9% 的通过率,在 CodeForces 上获得了 954 的评分,显示出超出其参数规模的推理能力 |
| DeepSeek-R1-Distill-Qwen-7B | DeepSeek-R1-Distill-Qwen-7B 是基于 Qwen2.5-Math-7B 通过知识蒸馏得到的模型。该模型使用 DeepSeek-R1 生成的 80 万个精选样本进行微调,展现出优秀的推理能力。在多个基准测试中表现出色,其中在 MATH-500 上达到了 92.8% 的准确率,在 AIME 2024 上达到了 55.5% 的通过率,在 CodeForces 上获得了 1189 的评分,作为 7B 规模的模型展示了较强的数学和编程能力 |
| DeepSeek-R1-Distill-Qwen-14B | DeepSeek-R1-Distill-Qwen-14B 是基于 Qwen2.5-14B 通过知识蒸馏得到的模型。该模型使用 DeepSeek-R1 生成的 80 万个精选样本进行微调,展现出优秀的推理能力。在多个基准测试中表现出色,其中在 MATH-500 上达到了 93.9% 的准确率,在 AIME 2024 上达到了 69.7% 的通过率,在 CodeForces 上获得了 1481 的评分,显示出在数学和编程领域的强大实力 |
| DeepSeek-R1-Distill-Qwen-32B | DeepSeek-R1-Distill-Qwen-32B 是基于 Qwen2.5-32B 通过知识蒸馏得到的模型。该模型使用 DeepSeek-R1 生成的 80 万个精选样本进行微调,在数学、编程和推理等多个领域展现出卓越的性能。在 AIME 2024、MATH-500、GPQA Diamond 等多个基准测试中都取得了优异成绩,其中在 MATH-500 上达到了 94.3% 的准确率,展现出强大的数学推理能力 |
⚡ Alaya NeW算力云:让DeepSeek部署更简单!
借助 Alaya NeW算力云服务 提供的强大GPU资源,您可以轻松实现DeepSeek模型在云端的推理服务部署,并根据实际需求灵活使用算力,为技术创新与科研探索提供高效支持!
三步搞定一键部署,快速上手DeepSeek!
不想被复杂的配置流程困扰?别担心!只需三步,您就能轻松完成DeepSeek大语言模型的一键部署。立即行动起来吧!
体验地址:
https://docs.alayanew.com/docs/documents/newActivities/deepseekrdeploy/
2.前置条件
本教程假定您已经具备以下条件:
开通了Alaya NeW弹性容器集群,具体步骤参考:开通弹性容器集群
在您的系统上安装了kubectl,具体步骤参考:快速开始。
在您的系统上安装了Helm,具体步骤参考:helm的使用。
部署私有应用市场,具体步骤参考:部署私有应用市场
3.一键部署DeepSeek模型
3.1模型资源需求建议
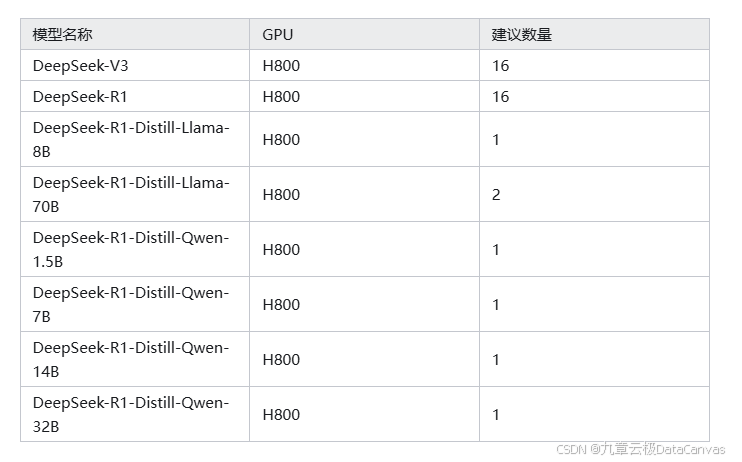
3.2访问私有应用市场
请参考私有应用市场-开始使用
3.3部署应用
请参考私有应用市场-部署应用
在部署DeepSeek应用时,不同的模型需要修改的values.yaml文件内容(下图的右侧可编辑部分)不同。
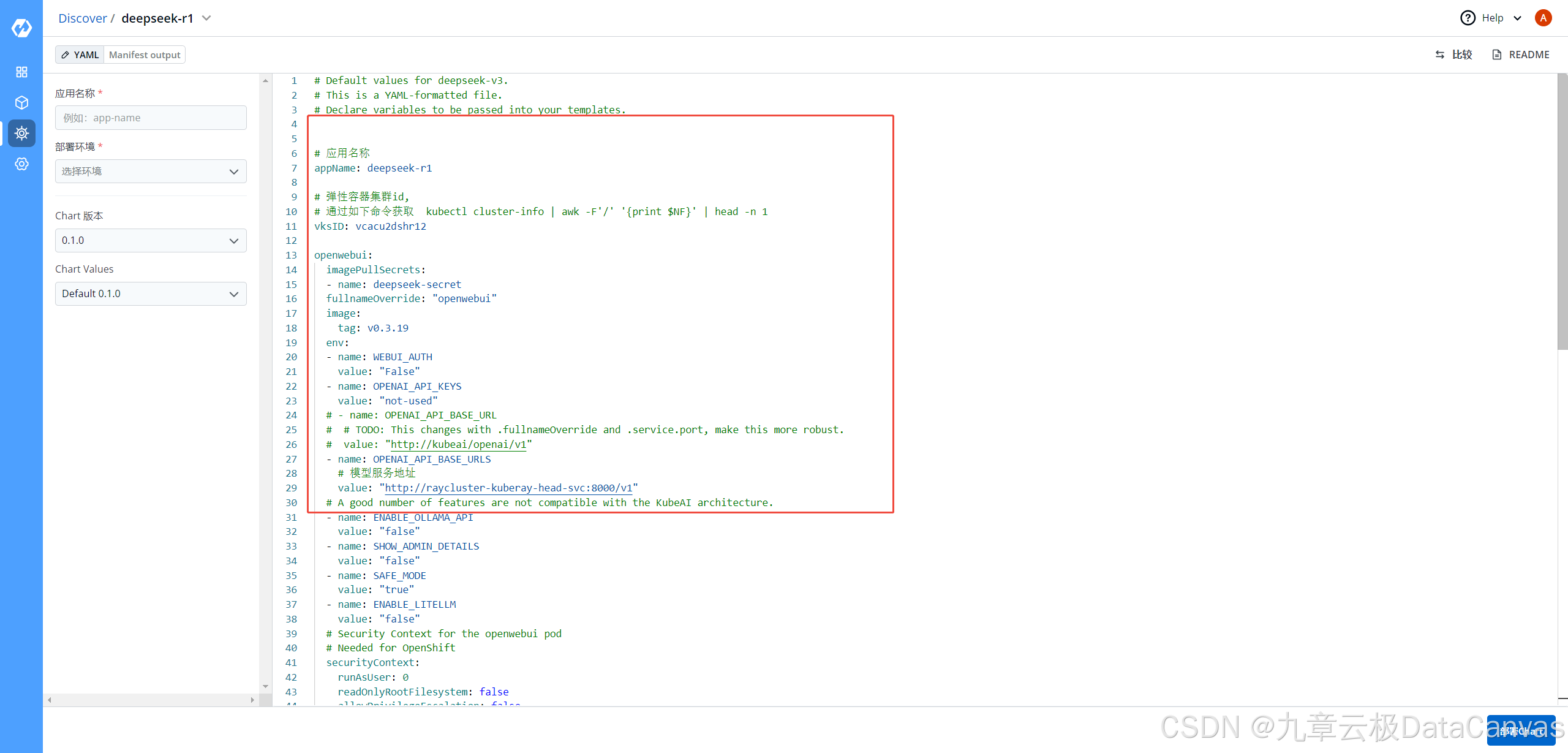
提示 values.yaml文件内容一般无需修改,如要修改可修改如下参数
vksID: DeepSeek所有模型,都要修改成自己集群的ID,获取方式 kubectl cluster-info | awk -F’/’ ‘{print $NF}’ | head -n 1
modelName: 可以自定义模型名称
openwebui:只允许修改env列表中的OPENAI_API_BASE_URLS属性的值,DeepSeek-R1和DeepSeek-V3不要修改,DeepSeek其他模型,要跟modelName保持一致
资源需求: requests 和 limits GPU的需求量参考上面资源需求建议表。 cpu和memory的配置按GPU数量成比例增加参考GPU使用
vllm: 可调整和新增vllm启动参数
3.4访问模型
部署成功以后,通过网页访问模型,也可以通过接口访问模型
网页访问
拼接openwebui地址
地址模板: https://openwebui-x-{namespace}-x-{vksID}.sproxy.hd-01.alayanew.com:22443
{namespace}: 替换成您实际的命名空间
{vksID}: values.yaml中的vksID
如下是namespace=deepseek, vksId=vcacu2dshr12的openwebui地址
https://openwebui-x-deepseek-x-vcacu2dshr12.sproxy.hd-01.alayanew.com:22443
通过Notes.txt直接访问
进入私有私有应用市场,点击我的应用,列出应用列表,如下图:

选择部署的应用,进入应用详情,如下图:
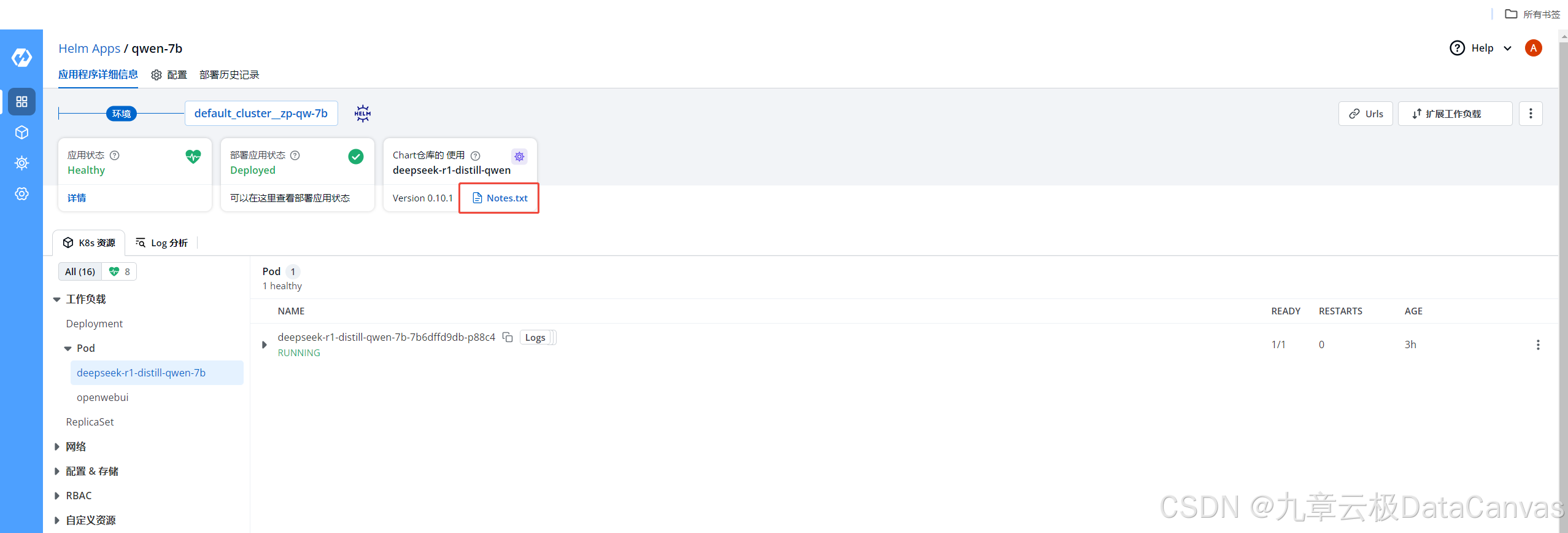
点击Notes.txt,可以显示模型网页访问地址,如下图:
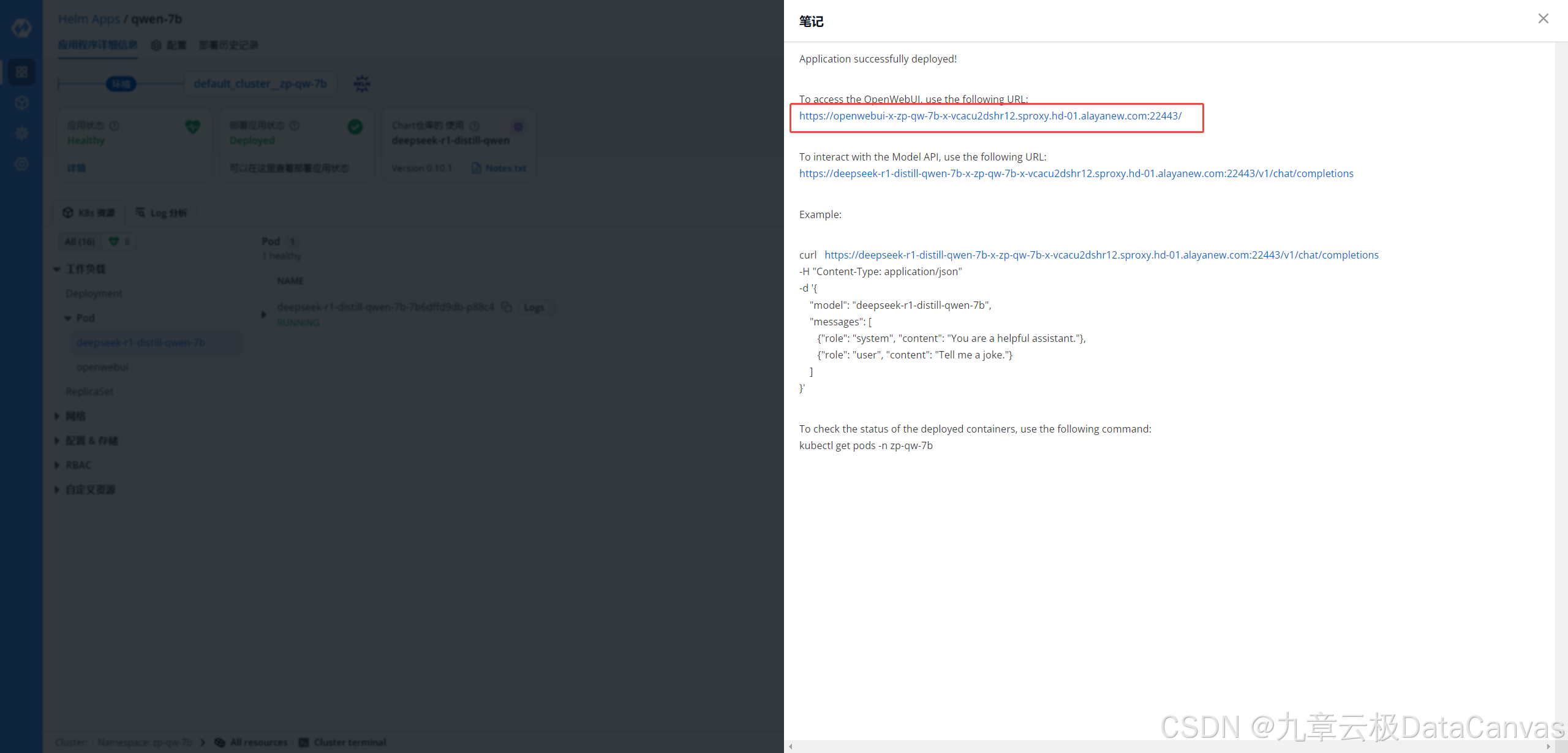
访问模型,并对话,如下图:
接口访问
接口url地址参数替换
{namespace}: 替换成您实际的命名空间
{vksID}: values.yaml中的vksID
{modelName}: DeepSeek-V3 和 DeepSeek-R1 固定为:raycluster-kuberay-head-svc, 其他DeepSeek模型为values.modelName
https://{modelName}-x-{namespace}-x-{vksID}.sproxy.hd-01.alayanew.com:22443/v1/models
也可以通过Notes.txt获取接口地址,参考网页访问
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "https://raycluster-kuberay-head-svc-x-deepseek-x-vcw2y2htee7r.sproxy.hd-01.alayanew.com:22443/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="/model/deepseek-ai/DeepSeek-R1",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "讲个笑话."},
],
stream=True
)
输出:
<think>
嗯,用户让我讲个笑话。首先,我得确定他想要什么类型的笑话。是冷幽默、双关语,还是有情节的小故事笑话?不同的用户可能有不同的喜好。还要考虑是否适合所有年龄层,有没有可能冒犯到别人的内容。比如政治、宗教或者性别相关的笑话可能不太合适,所以最好避开这些敏感话题。
然后,我需要回忆一些经典的笑话结构,比如医生和病人的对话、动物笑话,或者日常生活中有趣的情境。医生和病人的笑话比较常见,容易引发共鸣,而且通常比较安全,不会有冒犯内容。比如那个经典的笑话:“医生,我放屁没声音但是很臭怎么办?”接下来需要想一个巧妙的回答,既出乎意料又带点幽默感。这里可以联想到声音和气味的关系,比如检查听力,这样既合理又搞笑。
另外,要注意笑话的长度不要太长,简短有力更容易让人记住和发笑。同时,检查语言是否口语化,有没有自然的笑点。避免使用复杂的词汇,保持轻松愉快的氛围。可能还要考虑笑话是否带有积极正面的情绪,让用户听了之后心情更好。
还要确保笑话的结构清晰,有铺垫和转折。比如,开头设置一个常见的情景,然后通过意想不到的转折制造笑料。比如病人描述问题,医生给出一个表面上不相关但逻辑上相关的建议,这种反差会产生幽默效果。
有没有可能这个笑话已经被广泛传播过了?用户可能听过类似的,所以需要稍微调整细节,增加新意。比如,把放屁的问题和听力检查结合起来,这样的组合比较少见,能带来新鲜感。另外,结尾的台词要干脆,留有余地让人回味,比如“您还是先检查一下听力吧!”,既点明了笑点,又不会拖沓。
最后,检查笑话是否符合文化差异,避免特定地区的梗或双关语。需要确保不同背景的人都能理解。比如提到的“放屁”是普遍现象,听力检查也是常见的医疗行为,所以跨文化传播不会有障碍。
总之,这个笑话应该简单易懂,安全无害,结构紧凑且有出人意料的转折,能够有效引发笑声。
</think>
好的,我来分享一个轻松的小笑话:
医生对病人说:“以后尽量少吃宵夜。”
病人紧张地问:“是因为会消化不良吗?”
医生摇摇头:“不,主要是我每次半夜刷朋友圈,看见你发烤串火锅小龙虾的照片…真的很难专心值班。”
(希望这个小幽默能让你会心一笑~ )


















 1151
1151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









