







从2025年3月起,英伟达分阶段推出Llama-Nemotron家族的不同规格模型。Nano和Super版本在3月先行亮相,而Ultra版本作为旗舰型号于4月8日发布。Ultra版本的发布直接挑战了同期Meta的Llama 4系列,仅用三天时间便在多项基准测试中超越后者。
如需技术合作或业务咨询,请关注公众号:九章云极AlayaNeW
或者请移步个人vx: alayanew
原文阅读:https://mp.weixin.qq.com/s/HlMuViKehGc0A1CkYrpdxA
截至 2025 年 4 月,其旗舰模型 LN-Ultra 荣膺最 “智能” 开源模型称号。以253B参数(仅为DeepSeek-R1的1/3参数量)在 GPQA-Diamond(76.01分)、IFEval(89.45分)等关键基准中超过DeepSeek-R1,在单8xH100节点上的推理吞吐量达DeepSeek-R1的4倍。
5月5日,英伟达发布了技术报告,公开了模型从代码到数据集的一切,诚意满满:
完整模型权重:****三个尺寸任选择
训练数据集:****包含3300万条数学/代码/科学问答数据
全套工具链:****NeMo、Megatron-LM等开发神器
- 论文标题:Llama-Nemotron: Efficient Reasoning Models
- arXiv 地址:https://arxiv.org/pdf/2505.00949
- 代码地址:https://github.com/NVIDIA/NeMo
- 数据集:https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset
性能表现
实力惊艳行业
在权威机构 Artificial Analysis 截止2025年4月测评中,Llama-Nemotron 系列模型表现堪称惊艳(如图 1),超越DeepSeek R1,在开源模型中排到了第1。

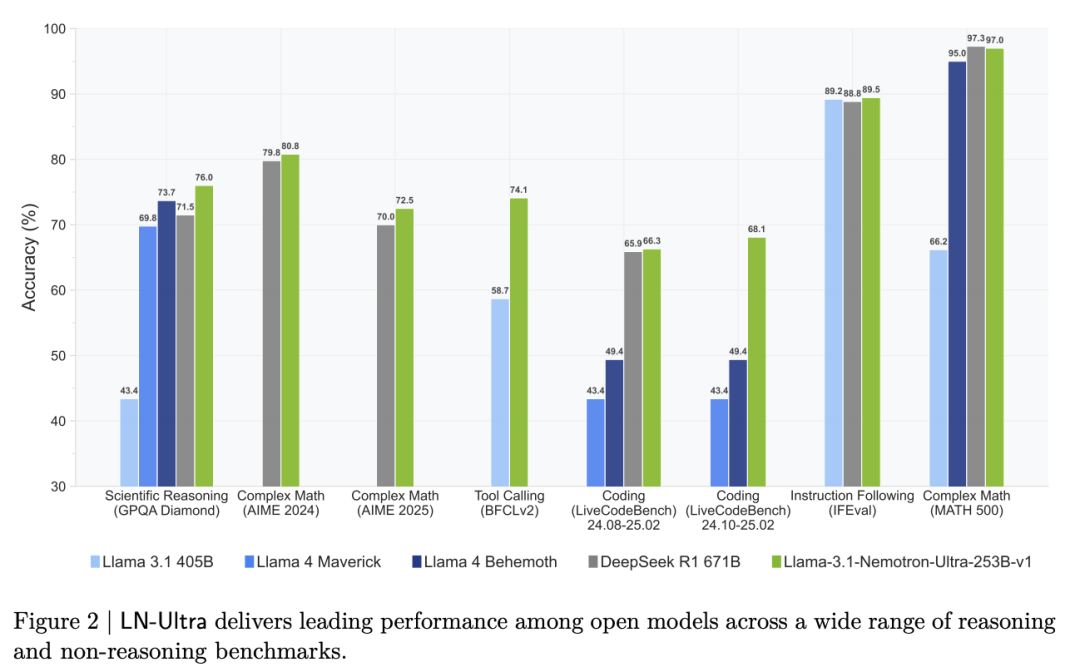
与其他顶尖推理模型相比,LN-Ultra 在多个推理和非推理基准测试中都能拔得头筹。像是在图 2 展示的科学推理(GPQA Diamond)、指令遵循(IFEval)、工具调用(BFCLv2)等测试场景下,LN-Ultra 的准确率远超同类开源模型,甚至比一些需要更高硬件配置的模型表现还要出色,彰显了它强大的实力。
高效推理
创新优化框架
为了实现高效推理,LN-Super 和 LN-Ultra 模型借助 Puzzle 框架进行了深度优化。Puzzle 框架是一种神经架构搜索(NAS)框架,它能在实际部署的约束条件下,将大语言模型转化为硬件高效的变体(参考图 3)。

它通过对 Llama 3 系列模型应用块级局部蒸馏,构建出可供选择的 transformer 块库。在这个过程中,一些块会去除注意力机制,减少计算量和内存消耗;同时,还会调整前馈网络(FFN)的维度,实现不同粒度的压缩。之后,利用混合整数规划(MIP)求解器,从块库中为每一层选择合适的块,组装成完整的模型,以达到在给定约束条件下的最优配置。
对于 LN-Ultra 模型,还引入了 FFN Fusion 技术。在 Puzzle 框架去除部分注意力层后,模型中会出现连续的 FFN 块,FFN Fusion 技术会将这些连续的 FFN 块替换为更少但更宽的 FFN 层,这些层可以并行执行,从而减少了顺序步骤,提高了计算利用率,显著降低了推理延迟。
经过一系列优化,LN-Super 和 LN-Ultra 在推理效率上有了极大提升。LN-Super 在单 NVIDIA H100 GPU(张量并行度为 1)上运行时,相比 Llama 3.3 - 70B-Instruct,吞吐量提升了 5 倍;LN-Ultra 针对 8 GPU 的 H100 节点进行优化,相比 Llama 3.1 - 405B-Instruct,延迟降低了 1.71 倍。
从图 4 可以直观地看到,在不同设置下,LN-Ultra 在 GPQA-Diamond 准确率和处理吞吐量上都优于 DeepSeek-R1 和 Llama 3.1 - 405B,在精度 - 吞吐量帕累托曲线上占据优势。

报告通过详实的表格与图表,展示了各模型在不同任务中的表现:
- LN-Nano(8B):手机都能跑,在推理和聊天基准上表现出色,尤其是在小数据集上;
- LN-Super(49B):全能选手,在推理和聊天基准上都具有竞争力,可以同时满足结构化推理和非结构化聊天的需求;
- LN-Ultra(253B):科研神器,在推理和聊天基准上均优于其他公开模型,8块H100显卡高效运行。
训练流程
复杂严谨、合成数据赋能
Llama-Nemotron 系列模型的训练过程复杂且严谨,主要分为五个阶段:
- 架构优化阶段:运用神经架构搜索(NAS)提升推理效率,并引入 FFN Fusion 技术;
- 知识强化阶段:通过知识蒸馏与持续预训练,增强块间兼容性,弥补架构优化带来的质量损失;
- 监督微调阶段:基于标准指令数据与强大教师模型(如 DeepSeek-R1)的推理轨迹进行训练,赋予模型多步推理能力,并学会依据 “detailed thinking on/off” 指令控制推理行为;
- 强化学习阶段:针对 LN-Ultra 模型,利用复杂数学和 STEM 数据集,通过 Group Relative Policy Optimization(GRPO)算法,进一步提升科学推理能力;
- 对齐优化阶段:聚焦指令遵循与人类偏好优化,完成模型的最后校准。
训练过程中,数据质量与多样性至关重要。团队精心构建合成数据集,覆盖推理与非推理数据。以数学推理数据为例,从 Art of Problem Solving(AoPS)社区论坛采集大量数学问题,经问题提取、分类、答案提取、基准净化等处理,再借助 DeepSeek-R1 和 Qwen2.5-Math-7BInstruct 等模型生成多种解决方案,经严格筛选后,确保数据的高质量与有效性。
推理切换
动态****满足多元需求
Llama-Nemotron 系列模型一大创新点是支持动态推理切换。用户在推理时,只需通过一个轻量级的系统提示 “detailed thinking on/off”,就能在标准聊天模式和推理模式之间自由切换。这一设计非常贴心,既满足了日常通用场景下的使用需求,又能在需要深度推理的任务中提供强大支持,而且无需使用不同的模型或架构,大大提高了模型的实用性和灵活性。
开源理念
开放许可,支持商业使用
NVIDIA 发布 Llama-Nemotron 系列模型时,采用开放许可,将模型权重与部分训练数据在 Hugging Face 平台公开,遵循 NVIDIA Open Model License 和 Llama 社区许可协议,支持商业使用。
如果你对****Llama-Nemotron系列模型有兴趣,欢迎到九章云极AlayaNeW平台进行体验!企业用户/教师注册即可免费享受价值约500元的25度算力包,让你体验极致高性能弹性算力。关注下方公众号点击用户注册即可。


















 1211
1211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









