







本文将以一个特定领域的数据集——《网络安全法规》为例,教你准备微调的数据集。
《网络安全法规》数据集的原始资料来源于网络公开资源,涵盖了具有高度专业性的法律条文内容。
这类信息因其特殊的专业属性,在通用大模型预训练阶段通常不会被纳入训练材料之中。
因此,在面对需要利用大模型支持的专业应用场景时,对现有通用模型进行针对性微调便显得尤为必要。而这一过程的第一步便是精心准备用于微调的数据集。
如需技术合作或业务咨询,请关注公众号:九章云极AlayaNeW
或者请移步个人vx: alayanew
当前,一种较为简便快捷地创建此类数据集的方法是通过向大模型发送提示词,由大模型生成QA对形式的数据。然而,这种方法存在明显局限性:
- 生成的问题与答案往往过于简化;
- 受限于模型自身能力,所生成的数据集可能会出现截断现象。例如,当我们尝试使用 DeepSeek 上传一份原始文档并通过提示词让模型生成QA数据集时,可以观察到上述缺陷的存在:即使重复操作,基于相同输入文件生成的结果依旧保持一致且质量有限。


除了当前讨论的方法外,其他传统数据收集与处理方式也存在若干局限性:
- 人工标注
这一过程不仅成本高昂且耗时较长,通常需要专业人员的参与,从而显著增加了项目的总体开销。
- 特定领域数据获取
在某些专业性强的领域,如医疗健康或法律服务中,由于严格的隐私保护法规限制,公开可用的数据集相对稀缺,获取难度较大。
- 人工智能生成的数据
尽管AI生成数据的速度较快,但其质量往往不够稳定,可能存在准确性不足或细节缺失的问题。
为克服上述挑战,诸如Easy Dataset等工具应运而生。
在实战演示 Easy Dataset 的具体操作之前,先对其主要特性做一个简要介绍:
- 智能文档解析
将Markdown文件转换为结构化知识,便于管理。
- 自动化问题生成
从文本中提取关键信息并创建相关问题,准确度高。
- 自动答案生成
利用大型语言模型技术生成自然流畅的答案。
- 灵活编辑
允许用户随时调整问题或答案,并直观地重新组织内容。
- 多样化输出
支持Alpaca、ShareGPT及JSON/JSONL等多种格式。
- 广泛兼容
适用于大多数基于OpenAI架构的语言模型。
- 用户友好界面
简洁易用,适合非技术人员。
- 可配置系统提示
通过设定指导语句来优化回答。
接下来,我们就进入Easy Dataset 的实战环节:
0****1
实战前准备:Easy Dataset 的环境部署
1)安装本地客户端
- 下载地址:
https://github.com/ConardLi/easy-dataset/releases/tag/1.2.3

2)使用 NPM 安装
- 克隆仓库
git clone https://github.com/ConardLi/easy-dataset.gitcd easy-dataset
- 安装依赖
npm install
- 启动开发服务器
npm run buildnpm run start
- 打开浏览器并访问
<font style="color:rgb(31, 35, 40);">http://localhost:1717</font>
使用 Dockerfile 构建
- 克隆仓库
git clone https://github.com/ConardLi/easy-dataset.gitcd easy-dataset
- 构建 Docker 镜像
docker build -t easy-dataset .
- 运行容器
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-dataset
- 打开浏览器并访问
<font style="color:rgb(31, 35, 40);">http://localhost:1717</font>
注意:本文将使用第1种方式演示构建全过程。
02
实战操作:关键三步生成高质量数据集
下图是实践过程的具体步骤,整体流程划分为以下三个关键步骤:
拆分文本块:将原始文本分割成若干小段落或片段。
生成问题:针对每个文本片段设计并生成相关联的问题。
构建数据集:为上述生成后的问题,精心准备相应的解答。

1)准备原始文件
- 准备 Markdown 格式数据
Easy Dataset 目前仅支持 Markdown 格式,所以在此之前需要把行业数据转换成 MD 文件。这里选择的是PDF格式,推荐大家使用 MinerU 这款工具进行转换生成 MD 文件。
- 创建项目“网络安全法规”,本文以生成法律法规的领域数据为例。如图所示。

- 模型配置
项目创建完成后,进行模型配置,这一步可以根据各自情况配置,配置也非常简单,选择“项目设置” -> “模型配置”,如下图。

目前 Alaya NeW API 服务正在火热销售中,其体验版套餐没有 Token使用限制,用户只需支付 180 元,即可在 30 天内畅享该服务。
如果有需要可以到官网 https://www.alayanew.com/product/deepseek ****进行充值体验。
2)拆分文本
选择“文献处理”,上传准备好的行业数据MD文件。可以全部选择拆分后的文本,然后批量生成问题,如下图。

这里生成问题需要等待一段时间:

3)问题管理
选择“问题管理”,勾选生成的问题,选择“批量构造数据集”,过程仍需等待一段时间。

4)构建数据集
选择“导出数据集”,下载构建好的网络安全行业数据。

导出数据集时设置系统提示词“你是一位法律专家,擅长网络安全法”。
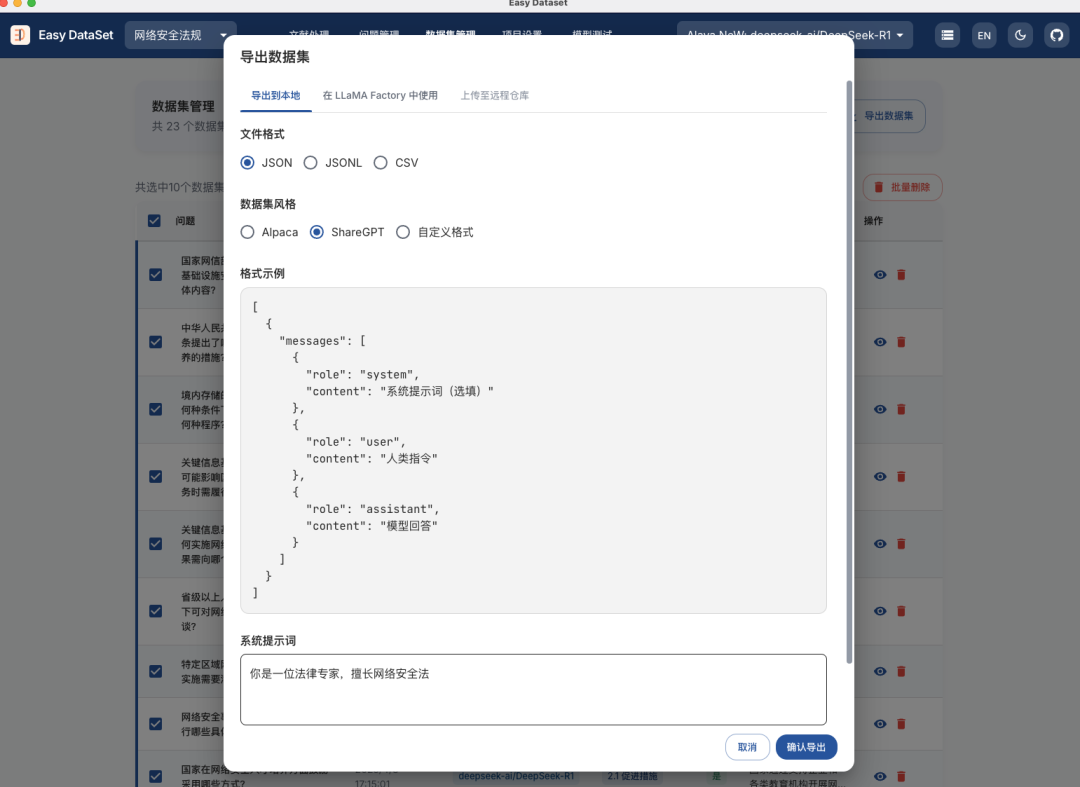
导出之后我们打开文件,可以看到导出的数据集案例。

至此,我们已利用 Easy Dataset 工具完成了“网络安全领域数据集” 的处理与生成。
虽然演示过程相对基础,但其过程充分展现了该工具的高度实用性:仅需执行三项核心操作,即可生成适用于微调的数据集。


















 1417
1417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









