









可参考链接:Python基础笔记(全)
关于 import
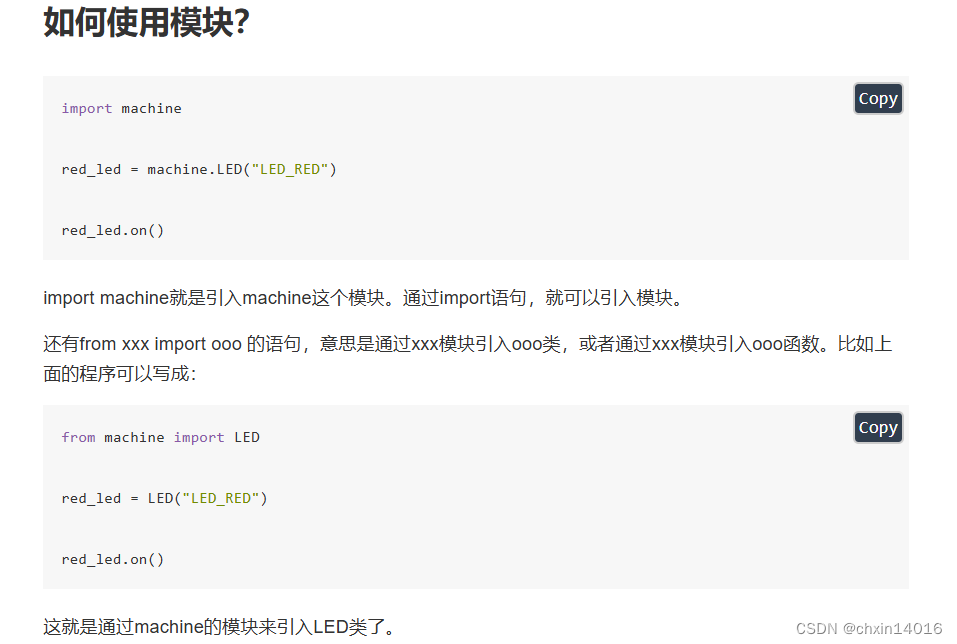
直接 import xxx 时,每次调用库里接口时都要在接口名前加个 xxx.接口名。
使用 from aaa import xxx 时,每次调用该接口时可直接 xxx 。
嵌套import
1)顺序嵌套
各个模块的 Local 名字空间是独立的。
例子:
本模块导入 A 模块(import A),
A 中又 import B,
B 模块又可以 import 其他模块……
对于上面的例子,本模块 import A 之后本模块只能访问模块 A,不能访问模块 B 及其他模块。虽然模块 B 已经加载到内存了,如果访问还要再明确的在本模块中 import B。(若要想访问 B 则需再写个 import B)
from . import
“.” 代表使用相对路径导入,即从当前项目中寻找需要导入的包或函数
使用 __init__.py 文件
在 Python 中,目录中的 __init__.py 文件可以作为模块导入。这意味着可以在目录中创建包含模块的子目录,并在子目录的 __init__.py 文件中导入这些模块。这有助于组织代码并保持模块的独立性。例如,假设在 my_module 目录中创建了一个名为 sub_module 的子目录,并在 sub_module 目录中创建了一个名为 __init__.py 的文件。在 __init__.py 文件中,可以导入子目录中的其他模块。然后,可以在其他模块中导入 my_module.sub_module 以访问子目录中的模块。
下面是一个例子:
# my_module/sub_module/__init__.py # 导入子目录中的其他模块 from . import module1 from . import module2 # 现在可以在其他模块中导入 my_module.sub_module 以访问 module1 和 module2# 其他模块 import my_module.sub_module # 现在可以使用 my_module.sub_module.module1 和 my_module.sub_module.module2
binascii 模块(用于十六进制形式的显示)
用处:主要用于二进制和ASCII互相转换(Convert between binary and ASCII );
bytearray.fromhex():将十六进制字符串转为字节数组
struct 模块(用于解析字节流)
用处:用于处理二进制数据和字节序列,在Python基本数据类型(Python中的值对象)和二进制数据(原生字节数据)之间进行转换。提供了将Python数据类型与C结构体类型进行转换的方法,从而实现对二进制数据的解析和打包操作。
主要应用场景:是把数值转换为字节流以供与外部源进行数据交换、数据传输使用。
通过struct模块,可以按照指定的格式读取、写入和操作二进制数据,例如网络通信、文件解析等场景。
参考链接:
(主要目的:是将一些数值对象打包 到字节流缓冲区通过串口发送出去,然后 将返回的字节数组按照协议解析成对应的值对象。要完成这个过程我们其实只需要
pack和unpack两个函数。)
Packing(打包)和Unpacking(解包)
Struct支持将数据packing(打包)成字符串,并能从字符串中逆向unpacking(解压)出数据。
1、pack()函数
#按照给定的格式(format),把数据封装成字符串(实际上是类似于C结构体的字节流)
pack(format,v1,v2,...)2、unpack()函数
#按照给定的格式(format),解析字节流string,返回解析出来的tuple
pack(format,string)3、calcsize()函数
#计算给定的格式(format)占用多少字节的内存。
#注:icc表示三个成员数据类型是interger, char, char。
size = struct.calcsize(’@icc’) 结果是6。
size = struct.calcsize(’@cic’) 结果是9。4、pack_into()函数
#按照指定的格式fmt,将v1,v2...打包到buffer中,其中偏移位置为offset
struct.pack_into(fmt, buffer, offset, v1, v2, ...)5、unpack_from()函数
#按照指定的格式fmt,从偏移位置offset开始解包,返回数据格式是一个元组(v1,v2...)
struct.unpack_from(fmt, buffer, offset=0)关于 None
最佳实践总结
用
None初始化变量: 在定义变量但不立即赋值的情况下,使用None进行初始化,明确表示变量的初始状态。使用
is进行None比较: 在条件语句中检查变量是否为None时,最好使用is运算符,确保准确比较对象的身份。避免频繁使用
None比较: 在代码中避免不必要的None比较,尽量使用其他方式表示缺失值或空。使用
None作为函数参数的默认值: 在函数定义中使用None作为参数的默认值,以便调用者能够根据需要传递具体值或使用默认值。明确
None的类型检查: 可以使用type()函数进行None的类型检查,以确保准确判断变量的类型。谨慎处理
None在迭代中的影响: 在迭代过程中注意处理None值,以避免对其进行不必要的操作。使用
None表示操作未返回有效结果: 在异常处理或某些函数返回值的情况下,使用None表示操作未返回有效结果,而不是引发异常或返回特殊值。在条件表达式中灵活使用
None: 在条件表达式中,可以使用None作为一种特殊值,根据条件为变量赋予不同的值。
关于 print
print("")#换行
print("===== resX,resY: [%f, %f] " % (resX,resY))
print(' curPix=',end="")#打印该内容后不换行,后接下一个打印内容打印十六进制:
print("Send :", sendData)
for i in sendData:
print('{:x}'.format(i))生成随机数
random.sample(range(1,N), k)
表示从[1,N]的范围内随机生成k个数,结果以列表返回
例子一:随机生成5个(1, 10)范围内的数字
import random for i in range(5): L1 = random.randint(1, 10) print(L1, end=' ') # 运行结果为:6 7 9 2 9例子二:随机生成5个(1, 10)范围内不重复的数字
import random L1 = random.sample(range(1, 10), 5) print(L1) # 运行结果为:[5, 1, 7, 2, 8]
(封装好的)获取不重复的随机数列表
#获取0~n-1范围内的num个不重复的随机数 #返回的 randLst 为获取到的随机数list def GetRansacRandomNum(n,num): randLst = [] rdm = random.randint(0,n-1) randLst.append(rdm) while True: sameFlag = False rdm = random.randint(0,n-1) for curRandNum in randLst: if curRandNum == rdm: sameFlag = True break if sameFlag == False: randLst.append(rdm) del sameFlag if len(randLst) == num: break return randLst
元组和列表之间的转换
- 使用
list函数可以把元组转换成列表(元组 ==》列表)
list(元组)
- 使用
tuple函数可以把列表转换成元组(列表 ==》元组)
tuple(列表)排序
冒泡排序(列表)
qq = [6,78,3,24,32,7,9,97,4,61,1,11,-3,0]
for i in qq: print(i)
for i in range(0,len(qq)):
for j in range(i+1,len(qq)):
if qq[i]<qq[j]:
qq[i],qq[j] = qq[j],qq[i]
print("降序排序后(冒泡):**************")
for i in qq: print(i)斜率、弧度、角度的转换
斜率、弧度、角度之间的转换:
import math
弧度 = math.atan(10) # 10为斜率
print("弧度:", 弧度)
angle = math.degrees(弧度)
print("角度:", angle)














 5156
5156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









