









论文解析
- 论文题目:Deep One-Class Classification
- 论文链接:https://proceedings.mlr.press/v80/ruff18a.html
- 代码链接:https://github.com/lukasruff/Deep-SVDD-PyTorch
背景
论文翻译
尽管深度学习在许多机器学习问题上取得了巨大进步,但用于异常检测的深度学习方法相对缺乏。那些确实存在的方法涉及经过训练以执行异常检测之外的任务的网络,即生成模型或压缩,这些网络又适用于异常检测;他们没有接受过基于异常检测目标的培训。在本文中,我们介绍了一种新的异常检测方法——深度支持向量数据描述——该方法是在基于异常检测的目标上进行训练的。对深层机制的适应需要我们的神经网络和训练程序满足某些属性,我们在理论上证明了这一点。我们展示了我们的方法在 MNIST 和 CIFAR-10 图像基准数据集以及 GT SRB 停车标志的对抗性示例检测上的有效性。
背景
- 这篇论文是德国柏林洪堡大学的Lukas Ruff发表在ICML2018上的工作。柏林洪堡大学已诞生57位诺贝尔奖获得者,实力惊人。这篇论文主要的工作是提出了Deep Support Vector Data Description(Deep SVDD),该方法可以直接基于异常目标函数对单类别数据进行训练,区别于以往的先在大规模数据集训练再在单类别数据集上微调的做法。
如异常检测,正常的数据服从高斯分布,异常的数据不服从高斯分布,模型训练的目标就是准确表征“正常”,与模型偏差较大的即异常点。只有正常类别的数据做训练,因此也可以看做单分类问题One-Class Classification。
对于图像数据,其维度通常较大,传统的单分类方法如One-Class SVM和Kernel Density Estimation很难取得理想的效果,且还需要先对数据做大量的特征工程的工作。
Deep SVDD通过寻找一个最小球面,使该最小封闭球面包围数据的网络表征, 来训练一个神经网络模型。最小化训练数据表征的封闭球面可以使网络提取出变化数据中的共同特征。
1.简介
- 异常检测(AD)(Chandola et al., 2009; Aggarwal, 2016)是识别数据中异常样本的任务。通常,这被视为无监督学习问题,其中异常样本事先未知,并且假设大多数训练数据集由“正常”数据组成(此处和其他地方的术语“正常”意味着不异常)并且与高斯分布无关)。目标是学习一个准确描述“常态”的模型。与此描述的偏差将被视为异常。这也称为一类分类(Moya 等人,1993)。 AD 算法通常根据机器或监控系统正常运行状态期间收集的数据进行训练(Lavin & Ah mad,2015)。其他领域包括网络安全入侵检测(Garcia-Teodoro 等人,2009)、欺诈检测(Phua 等人,2005)和医疗诊断(Salem 等人,2013;Schlegl 等人,2017)。与许多领域一样,这些领域的数据在大小和维度上都在快速增长,因此我们需要有效且高效的方法来检测大量高维数据中的异常。
- 经典的 AD 方法,例如单类 SVM (OC SVM)(Scholkopf 等人,2001 年)或核密度估计(KDE)(Parzen,1962 年),在高维、数据丰富的场景中经常会因性能不佳而失败。计算可扩展性和维数灾难。为了有效,这种浅层方法通常需要大量的特征工程。相比之下,深度学习(LeCun 等人,2015;Schmidhu ber,2015)提出了一种自动学习相关特征的方法,比经典方法取得了巨大的成功(Collobert 等人,2011;Hinton 等人,2012),尤其是在计算机视觉领域(Krizhevsky et al., 2012; He et al., 2016)。然而,如何将深度学习的优势转移到 AD 上还不太清楚,因为找到正确的无监督深度目标很困难(Bengio 等,2013)。目前的深度 AD 方法已显示出可喜的结果(Hawkins 等人,2002 年;Sakurada 和 Yairi,2014 年;Xu 等人,2015 年;Erfani 等人,2016 年;Andrews 等人,2016 年;Chen 等人,2017 年) ),但这些方法都不是通过优化基于 AD 的目标函数来训练的,并且通常依赖于基于重建误差的启发式方法。
- 在这项工作中,我们引入了一种新颖的深度 AD 方法,其灵感来自于基于内核的一类分类和最小体积估计。我们的方法“深度支持向量数据描述”(Deep SVDD) 训练神经网络,同时最小化包围数据网络表示的超球面的体积(见图 1)。最小化超球体的体积迫使网络提取变化的共同因素,因为网络必须将数据点紧密地映射到球体的中心。
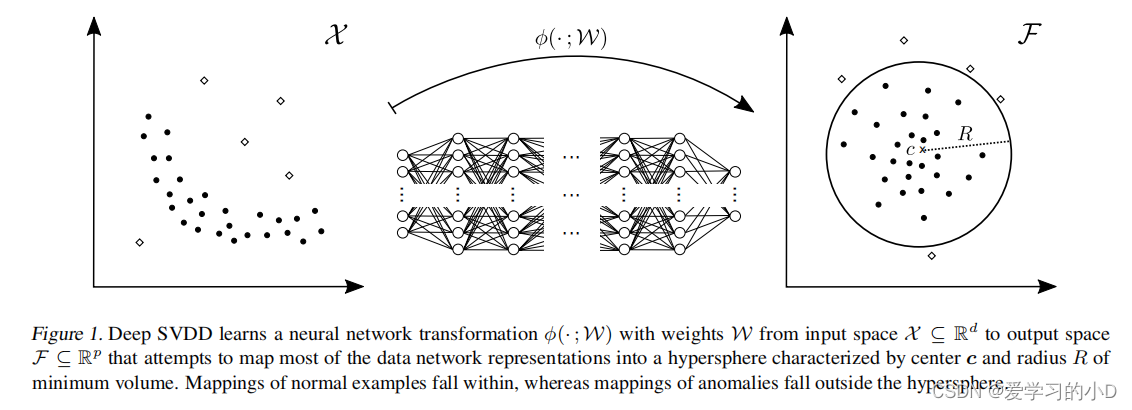
2. 相关工作
在介绍 Deep SVDD 之前,我们简要回顾一下基于内核的一类分类,并介绍现有的 AD 深度方法。
2.1.基于核的单分类方法
训练数据 X 训练数据X 训练数据X:所属的空间表示为: X ⊆ R d X ⊆ R^d X⊆Rd
k k k:表示正定核(
PSD kernel)F k F_k Fk:数据的联合再生希尔伯特空间(Reproducing kernel Hilbert space)
RKHSϕ k : \phi_k: ϕk:表示为数据特征的映射
- 最常用的单分类方法可能是One-Class SVM,其在数据的特征空间中寻找最大间距超平面。
- SVDD(Support Vector Data Description)与OC-SVM类似,但SVDD是通过学习一个超球面而非像SVM那样学习一个超平面。SVDD的目标是寻找一个中心为 c , c ∈ F k c,c\in \mathcal{F}_k c,c∈Fk,半径为 R , R > 0 R, R\gt0 R,R>0的最小超球面,使其在特征空间 F k \mathcal{F}_k Fk中包围大部分数据。在超球面之外的数据就是异常数据。
- 常规的SVDD和OC-SVM需要对数据先进行特征工程处理,且基于核的方法计算扩展性差。
-
设 X ⊆ R d X ⊆ R^d X⊆Rd 为数据空间。令 k : X × X → [ 0 , ∞ ) k : X × X → [0, ∞) k:X×X→[0,∞)为 PSD 核, F k F_k Fk 与 RKHS 相关,而 φ k : X → F k φ_k : X → F_k φk:X→Fk与特征映射相关。所以 k ( x , x ^ ) = < φ k ( x ) , φ k ( x ^ ) > F k k(x, \hat x) = <φ_k(x), φ_k(\hat x)>_{F_k} k(x,x^)=<φk(x),φk(x^)>Fk 对于所有 x , x ^ ∈ X x,\hat x ∈ X x,x^∈X其中 < ⋅ , ⋅ > F k <· , ·>_{F_k} <⋅,⋅>Fk 是希尔伯特空间 F k F_k Fk 中的点积 (Aronszajn, 1950)。
-
我们回顾了 AD 的两种内核机器方法。基于内核的一类分类方法最突出的例子可能是一类 SVM (OC-SVM)(Scholkopf 等人,2001)。 OC-SVM 的目标是在特征空间中找到最大边缘超平面 w ∈ Fk,它将映射数据与原点最好地分开。给定数据集 D n = x 1 , . 。。 , x n 且 x i ∈ X D_n = {x_1, . 。 。 , x_n} 且 x_i ∈ X Dn=x1,.。。,xn且xi∈X ,OC-SVM 解决了原始问题
m i n w , ρ , ξ 1 2 ∣ ∣ w ∣ ∣ F k 2 − ρ + 1 v n ∑ i = 1 n ξ i s . t . < w , ϕ k ( x i ) > F k ≥ ρ − ξ i , ξ i ≥ 0 min_{w,\rho,\xi}\ \ \frac{1}{2}||w||^2_{F_k}-\rho+\frac{1}{vn}\sum_{i=1}^n \xi_i \\ s.t. <w,\phi_k(x_i)>_{F_k} \geq \rho -\xi_i ,\xi_i\geq 0 minw,ρ,ξ 21∣∣w∣∣Fk2−ρ+vn1i=1∑nξis.t.<w,ϕk(xi)>Fk≥ρ−ξi,ξi≥0 -
这里 ρ ρ ρ是原点到超平面 w w w的距离。非负松弛变量 ξ = ( ξ 1 , . . . , ξ n ) T \xi = (\xi_1, . . . , \xi_n)^T ξ=(ξ1,...,ξn)T允许软裕度,但违规 ξ i \xi_i ξi 会受到处罚。 ∣ ∣ w ∣ ∣ F k 2 ||w||^2_{F_k} ∣∣w∣∣Fk2 是超平面 w w w上的正则化项,其中 ∣ ∣ ⋅ ∣ ∣ F k ||·||_{F_k} ∣∣⋅∣∣Fk 是由 < ⋅ , ⋅ > F k <· , ·>_{F_k} <⋅,⋅>Fk 导出的范数。超参数 ν ∈ ( 0 , 1 ] ν \in (0, 1] ν∈(0,1]控制目标中的权衡。将数据与特征空间中的原点分离转化为找到一个半空间,其中大部分数据位于该半空间中,并且点位于该半空间之外,即 < w , φ k ( x ) > F k , < ρ <w, φ_k (x)>_{F_k}, \lt ρ <w,φk(x)>Fk,<ρ, 被认为是异常的. 支持向量数据描述 (SVDD) (Tax & Duin, 2004) 是一种与 OC-SVM 相关的技术,其中使用超球体而不是超平面来分离数据. SVDD 的目标是找到中心 c ∈ F k c ∈ F_k c∈Fk 且半径 R > 0 R \gt 0 R>0 的最小超球面,该超球面包含特征空间 F k F_k Fk 中的大部分数据。SVDD 原始问题由下式给出
m i n R , c , ξ R 2 + 1 v n ∑ i ξ i s . t . ∣ ∣ ϕ k ( x i ) − c ∣ ∣ F k 2 ≠ R 2 + ξ i , ξ i ≤ 0 min_{R,c,\xi} R^2+\frac{1}{vn}\sum_i \xi_i \\ s.t. ||\phi_k(x_i)-c||^2_{F_k} \neq R^2+\xi_i, \xi_i \leq0 minR,c,ξR2+vn1i∑ξis.t.∣∣ϕk(xi)−c∣∣Fk2=R2+ξi,ξi≤0 -
同样,松弛变量 x i i ≥ 0 xi_i ≥ 0 xii≥0允许软边界,超参数 ν ∈ ( 0 , 1 ] ν \in (0, 1] ν∈(0,1]控制惩罚 x i i xi_i xii 和球体体积之间的权衡。落在球体之外的点,即 ∣ ∣ φ k ( x ) − c ∣ ∣ F k 2 > R 2 ||φ_k(x) − c||^2_{F_k} \gt R^2 ∣∣φk(x)−c∣∣Fk2>R2 ,被视为异常。OC-SVM 和 SVDD 密切相关。两种方法都可以通过各自的对偶来求解,这些对偶是二次规划,可以通过多种方法求解,例如顺序最小优化(Platt,1998) ). 在广泛使用的高斯核的情况下,这两种方法是等价的,并且是渐近一致的密度水平集估计器(Tsybakov, 1997; Vert & Vert, 2006)。用超参数 ν ∈ ( 0 , 1 ) ν \in (0, 1) ν∈(0,1) 公式化原始问题(1) 和 (2) 中的 ] 是参数化的便捷选择,因为 ν ∈ ( 0 , 1 ] ν \in (0, 1] ν∈(0,1] 是 (i) 异常值分数的上限,以及 (ii) 支持向量分数的下限(边界上或边界外的点)。此结果称为 ν ν ν 属性(Scholkopf 等人,2001),并允许人们合并关于训练数据中存在的异常值比例的先验信念进入模型。除了需要执行显式特征工程(Pal & Foody,2010)之外,上述方法的另一个缺点是由于内核矩阵的构造和操作而导致计算规模较差。
-
除非使用某种近似技术,否则基于内核的方法至少会在样本数量上成二次方缩放(Vempati 等人,2010)(Rahimi 和 Recht,2007)。此外,使用核方法进行预测需要存储支持向量,这可能需要大量内存。正如我们将看到的,Deep SVDD 不会受到这些限制。
2.2.深度学习方法在异常检测中的应用
深度学习在异常检测Anomaly Detection DeepAD上的应用方式可以分成两种,
- 一种是混合式的,数据的特征表征先单独学习,然后再使用提取的特征在OC-SVM等浅层的方法上实现分类。
- 另外一种是全深度学习的方法,直接基于异常检测的目标函数进行表征学习。
Deep SVDD提出了一种全深度学习的方法用于无监督异常检测。Deep SVDD通过最小化网络输出的超球面体积来训练神经网络以提取数据分布中的公共特征。
- 深度学习(LeCun et al., 2015; Schmidhuber, 2015)是表示学习(Bengio et al., 2013)的一个子领域,它利用具有多个处理层的模型架构来学习具有多个抽象级别的数据表示。多个抽象级别允许以非常紧凑和分布式的形式表示丰富的特征空间。深度(多层)神经网络特别适合学习本质上分层的数据表示,例如图像或文本。
- 我们将尝试利用深度学习进行 AD 的方法分为“混合”或“完全深度”。在混合方法中,表示是在前面的步骤中单独学习的,然后将这些表示输入到经典(浅层)AD 方法(如 OC-SVM)中。相比之下,全深度方法直接采用表示学习目标来检测异常。
- 通过 Deep SVDD,我们引入了一种新颖的、完全深度的无监督 AD 方法。 Deep SVDD 通过训练神经网络将网络输出拟合到最小体积的超球面来学习提取数据分布变化的共同因素。相比之下,几乎所有现有的深度 AD 方法都依赖于重建误差——无论是仅用于学习表示的混合方法,还是直接用于表示学习和检测。
- 深度自编码器(各种类型)(Hinton & Salakhutdinov,2006)是用于深度 AD 的主要方法。自动编码器是一种神经网络,它尝试学习恒等函数,同时将降维的中间表示(或一些稀疏正则化)作为瓶颈,引导网络从某些数据集中提取显着特征。通常,这些网络经过训练以最小化重建误差,即 ∣ ∣ x − x ^ ∣ ∣ 2 ||x − \hat x||^2 ∣∣x−x^∣∣2 。因此,这些网络应该能够从正常样本中提取出共同的变异因素并对其进行准确的重建,而异常样本不包含这些共同的变异因素,因此无法准确地进行重建。通过将学习到的嵌入插入到经典的 AD 方法中,这允许在混合方法中使用自动编码器(Xu 等人,2015;An Draws 等人,2016;Erfani 等人,2016;Sabokrou 等人,2016) ods,但也可以在完全深度的方法中,通过直接使用重建误差作为异常分数(Hawkins et al., 2002; Sakurada & Yairi, 2014; An & Cho, 2015; Chen et al., 2017)。
- 用于 AD 目的的自动编码器的一些变体包括去噪自动编码器 (Vincent et al., 2008; 2010)、稀疏自动编码器 (Makhzani & Frey, 2013)、变分自动编码器 (VAE) (Kingma & Welling, 2013) 和深度卷积自动编码器 (DCAE) (Masci et al., 2011; Makhzani & Frey, 2015),其中最后一个变体主要用于具有图像或视频数据的 AD 应用 (Seeběck et al., 2016; Richter & Roy, 2017)。自动编码器的目标是降维,并不直接针对AD。将自动编码器应用于 AD 的主要困难在于选择正确的压缩程度,即降维。如果没有压缩,自动编码器只会学习恒等函数。在信息减少到单个值的另一种边缘情况下,平均值将是最佳解决方案。也就是说,数据表示的“紧凑性”是一个模型超参数,由于无监督的性质以及数据的内在维度通常难以估计,因此很难选择正确的平衡(Bengio et al., 2013)。相比之下,我们通过最小化数据封闭超球面的体积,将表示的紧凑性纳入我们的 Deep SVDD 目标中,从而直接针对 AD。
- 除了自动编码器之外,Schlegl 等人。 (2017) 最近提出了一种基于生成对抗网络 (GAN) 的新型深度 AD 方法(Goodfellow 等人,2014),称为 AnoGAN。在该方法中,首先训练 GAN 根据训练数据生成样本。给定一个测试点,AnoGAN 尝试在生成器的潜在空间中找到生成最接近所考虑的测试输入的样本的点。直观上,如果 GAN 捕获了训练数据的分布,那么正常样本(即分布中的样本)应该在潜在空间中具有良好的表示,而异常样本则不会。为了找到潜在空间中的点,Schlegl 等人。 (2017) 在潜在空间中执行梯度下降,保持生成器的学习权重固定。 AnoGAN 最终也通过重建误差定义了异常分数。与自动编码器类似,这种生成方法的主要困难是如何规范生成器以实现紧凑性。
3. Deep SVDD
在本节中,我们介绍 Deep SVDD,一种深度一类分类方法。我们介绍 Deep SVDD 目标、其优化和理论特性。
3.1.目标函数
与单分类目标一起同时学习数据的表征,使用两个神经网络的联合训练以把数据映射到最小包围超球面上。
- 输入空间: X ∈ R d X\in R^d X∈Rd
- 输出空间: F ⊆ R p \mathcal{F} \subseteq \mathbb{R}^p F⊆Rp
- 从 X \mathcal{X} X到 F \mathcal{F} F的映射神经网络: ϕ ( ⋅ ; W ) : X → F \phi(\cdot;\mathcal{W}):\mathcal{X}\rightarrow\mathcal{F} ϕ(⋅;W):X→F,有 L ∈ N L\in\mathbb{N} L∈N个隐含层,权重分别为 W = { W 1 , . . . , W L } \mathcal{W}=\{W^1,...,W^L\} W={W1,...,WL}, W l W^l Wl表示 l ∈ [ 1 , . . . , L ] \mathcal{l}\in [1,...,L] l∈[1,...,L]层的权重。
- Deep SVDD的目标是同时学习网络参数以求得输出空间 F \mathcal{F} F中半径为 R R R中心为 c c c的最小体积包围圆。
- 有 X \mathcal{X} X上的训练数据 D n = { x 1 , . . . , x n } \mathcal{D}_n=\{x_1,...,x_n\} Dn={x1,...,xn}可定义Deep SVDD的soft-boundary目标函数:
- $ J_{soft}(\mathcal{W},R)=\min\limits_{R,\mathcal{W}}R2+\frac{1}{\mathcal{v}{n}}\sum\limits_{i=1}{n}max{0,||\phi(x_i;\mathcal{W})-c||2}+\frac{\lambda}{2}\sum\limits_{\mathcal{l}=1}{L}||\mathcal{W}{\mathcal{l}}||_F2$
- 上式中,最小化 R 2 R^2 R2就能最小化超球面,第二项是对超球面外的点的惩罚,超参数 v ∈ ( 0 , 1 ] \mathcal{v}\in(0,1] v∈(0,1]控制着球的体积与边界的松弛程度,类似SVM中的松弛变量,最后一项是训练参数的正则损失。
- 当训练数据中即有正样本又有负样本时,可以使用上述的损失函数进行训练,但若训练数据中仅有一个类别,对训练数据做单分类的时候,可以将上述损失函数简化为:
- J O C ( W ) min W 1 n ∑ i = 1 n ∣ ∣ ϕ ( x i ; W ) − c ∣ ∣ 2 + λ 2 ∑ l = 1 L ∣ ∣ W l ∣ ∣ F 2 J_{OC}(\mathcal{W})\min\limits_{\mathcal{W}}\frac{1}{\mathcal{n}}\sum\limits_{i=1}^{n}||\phi(x_i;\mathcal{W})-c||^2+\frac{\lambda}{2}\sum\limits_{\mathcal{l}=1}^{L}||\mathcal{W}^{\mathcal{l}}||_F^2 JOC(W)Wminn1i=1∑n∣∣ϕ(xi;W)−c∣∣2+2λl=1∑L∣∣Wl∣∣F2
- 测试时网络输出的应用:
- s ( x ) = ∣ ∣ ϕ ( x ; W ∗ ) − c ∣ ∣ 2 s(x)=||\phi(x;\mathcal{W^*})-c||^2 s(x)=∣∣ϕ(x;W∗)−c∣∣2
- 计算网络的输出与训练数据上的中心点c cc之间的距离,当小于某个阈值s ss时认为是符合同一个类别的,否则为其他类别。
-
对于深度 SVDD,我们通过找到最小尺寸的数据封闭超球体,建立在基于内核的 SVDD 和最小体积估计的基础上。然而,通过 Deep SVDD,我们可以学习数据的有用特征表示以及一类分类目标。为此,我们采用了一个经过联合训练的神经网络,将数据映射到最小体积的超球面。
-
对于某些输入空间 X ⊆ R d X ⊆ R^d X⊆Rd 和输出空间 F ⊆ R p F ⊆ R^p F⊆Rp,设 φ ( ⋅ ; W ) : X → F φ(· ; W) : X → F φ(⋅;W):X→F是一个神经网络,具有 L ∈ N L ∈ N L∈N隐藏层和一组权重 W = { W 1 , . 。。 , W L } W = \{W^1 , . 。 。 ,W^L\} W={W1,.。。,WL} 其中 W W W
是层∈ {1,… 的权重。 。 。 ,L}。也就是说, φ ( x ; W ) ∈ F φ(x; W) \in F φ(x;W)∈F 是由带有参数 W W W的网络 φ φ φ 给出的 x ∈ X x \in X x∈X的特征表示。Deep SVDD 的目标是联合学习网络参数 W 并最小化数据量 -将超球面封闭在输出空间 F 中,其特征是半径 R > 0 R \gt 0 R>0 且中心 c ∈ F c \in F c∈F(我们现在假设已给出)。给定一些训练数据 D n = x 1 , . 。。 , x n D_n = {x_1, . 。 。 , x_n} Dn=x1,.。。,xn在 X X X 上,我们将软边界 Deep SVDD 目标定义为
m i n R , w R 2 + 1 v n ∑ i = 1 n m a x { 0 , ∣ ∣ ϕ ( x i ; W ) − c ∣ ∣ 2 − R 2 } + λ 2 ∑ l = 1 L ∣ ∣ W l ∣ ∣ F 2 min_{R,w} R^2 + \frac{1}{vn}\sum_{i=1}^n max\{0,||\phi(x_i;W)-c||^2 -R^2\} + \frac{\lambda}{2}\sum_{l=1}^L ||W^l||^2_F minR,wR2+vn1i=1∑nmax{0,∣∣ϕ(xi;W)−c∣∣2−R2}+2λl=1∑L∣∣Wl∣∣F2 -
与内核 SVDD 一样,最小化 R 2 R^2 R2 可以最小化超球面的体积。第二项是对通过网络后位于球体外部的点的惩罚项,即如果其到中心的距离 ∣ ∣ φ ( x i ; W ) − c ∣ ∣ ||φ(x_i; W) − c|| ∣∣φ(xi;W)−c∣∣ 大于半径 R。 超参数 ν ∈ ( 0 , 1 ] ν \in (0, 1] ν∈(0,1]控制球体体积和违反边界之间的权衡,即允许将某些点映射到球体之外。我们在第 3.3 节中证明, ν − p a r a m e t e r ν-parameter ν−parameter实际上允许我们控制球体中异常值的比例模型类似于前面提到的核方法的 ν-property。最后一项是网络参数 W 的权重衰减正则化器,超参数 λ > 0,其中 ∣ ∣ ⋅ ∣ ∣ F || · ||_F ∣∣⋅∣∣F 表示 Frobenius norm。
-
优化目标 (3) 让网络学习参数W使得数据点紧密映射到超球面的中心c。为了实现这一点,网络必须提取数据变化的共同因素。因此,数据的正常示例紧密映射到中心c,而异常示例被映射到远离超球面中心或外部的位置。通过这个我们获得了普通类的紧凑描述。最小化球体的大小可以强化这一学习过程。
-
对于我们假设大部分训练数据 D n D_n Dn 是正常的情况(一类分类任务中经常出现这种情况),我们提出了一个额外的简化目标。我们将一类深度 SVDD 目标定义为
m i n W 1 n ∑ i = 1 n ∣ ∣ ϕ ( x i ; W ) − c ∣ ∣ 2 + λ 2 ∑ l = 1 L ∣ ∣ W l ∣ ∣ F 2 . min_W \frac{1}{n}\sum_{i=1}^n||\phi(x_i;W)-c||^2+\frac{\lambda}{2}\sum_{l=1}^L||W^l||_F^2. minWn1i=1∑n∣∣ϕ(xi;W)−c∣∣2+2λl=1∑L∣∣Wl∣∣F2. -
One-Class Deep SVDD 只是采用二次损失来惩罚每个网络表示 φ ( x i ; W ) 到 c ∈ F φ(x_i; W) 到 c \in F φ(xi;W)到c∈F 的距离。第二项又是超参数 λ > 0 λ \gt 0 λ>0 的网络权重衰减正则化器。我们可以也可以将 One-Class Deep SVDD 视为寻找以 c 为中心的最小体积的超球面。但与软边界 Deep SVDD 不同的是,在软边界 Deep SVDD 中,超球体通过直接惩罚半径和落在球体之外的数据表示来收缩,One-Class Deep SVDD 通过最小化所有数据表示到中心的平均距离来收缩球体。同样,为了将数据(平均)映射到尽可能接近中心 c,神经网络必须提取变异的共同因素。惩罚所有数据点的平均距离而不是允许某些点落在超球面之外,这与大多数训练数据来自一个类的假设是一致的。
-
对于给定的测试点 x ∈ X x \in X x∈X ,我们可以自然地通过该点到超球面中心的距离来定义 Deep SVDD 的两种变体的异常分数 s,即
s ( x ) = ∣ ∣ φ ( x ; W ∗ ) − c ∣ ∣ 2 s(x) = ||φ(x; W*) − c||^2 s(x)=∣∣φ(x;W∗)−c∣∣2 -
其中 W 是训练模型的网络参数。对于软边界 Deep SVDD,我们可以通过减去训练模型的最终半径 R ∗ R^* R∗ 来调整此分数,使得异常(具有球体外部表示的点)具有正分数,而内点具有负分数。请注意,网络参数 W*(和 R*)完全表征了 Deep SVDD 模型,无需存储任何数据进行预测,从而使 Deep SVDD 具有非常低的内存复杂性。这还允许通过简单地在某个测试点 x ∈ X 处用学习参数 W ∗ W^* W∗ 评估网络 φ 来进行快速测试,这通常只是简单函数的串联。我们在以下两小节中讨论深度 SVDD 优化和超球面中心 c ∈ F c ∈ F c∈F 的选择。
3.2.Deep SVDD 的优化
- 我们使用随机梯度下降(SGD)及其变体(例如Adam(Kingma & Ba,2014))使用反向传播来优化两个深度SVDD 目标中神经网络的参数W。训练一直进行到收敛到局部最小值为止。使用 SGD 允许 Deep SVDD 很好地扩展大型数据集,因为其计算复杂性随训练批次数量线性扩展,并且每个批次可以并行处理(例如,通过在多个 GPU 上处理)。 SGD 优化还支持迭代或在线学习。
- 由于网络参数 W 和半径 R 通常存在于不同的尺度上,因此使用一种通用的 SGD 学习率对于优化软边界 Deep SVDD 可能效率不高。相反,我们建议以交替最小化/块坐标下降方法交替优化网络参数 W 和半径 R。也就是说,我们在半径 R 固定的情况下训练一些 k ∈ N epoch 的网络参数 W。然后,在每第 k 个周期之后,我们使用最新更新的网络参数 W 求解给定网络数据表示的半径 R。 R 可以通过线搜索轻松求解。
3.3.Deep SVDD 的属性
命题1:零值权重解, W 0 \mathcal{W}^0 W0表示网络权重都为 0 0 0,对于 0 0 0值权重,网络对于任何输入都会有相同的输出 c 0 c_0 c0,即 ϕ ( x ; W 0 ) = ϕ ( x ~ ; W 0 ) = : c 0 ∈ F \phi(x;\mathcal{W}_0)=\phi(\tilde{x};\mathcal{W}_0)=:c_0\in \mathcal{F} ϕ(x;W0)=ϕ(x~;W0)=:c0∈F,根据前面的推导可以知道当 c = c 0 c=c_0 c=c0时,目标函数有最优解,此时 W ∗ = W 0 且 R ∗ = 0 \mathcal{W}^*=\mathcal{W}_0且R^*=0 W∗=W0且R∗=0 。
- 因此,在优化目标函数时不能将超球面的中心当做优化变量,否则将导致零值权重,此时超球面半径为零,也称这种现象为超球面塌陷。在训练网络时,超球面中心可通过以下方式指定:取在初始网络权重上训练数据输出的均值。
命题2:不能有偏置项,对于选择的超球面中心 F \mathcal{F} F,如果网络的隐含层有偏置项,将会导致目标函数 J s o f t 和 J O C J_{soft}和J_{OC} Jsoft和JOC的最优解为 R ∗ = 0 , ϕ ( x ; W ∗ ) = c R^*=0,\phi(x;\mathcal{W^*})=c R∗=0,ϕ(x;W∗)=c,同样导致超球面塌陷。网络的某个隐含层可表示为 z l ( x ) = σ l ( W l ∗ z l − 1 ( x ) + b l ) z^{l}(x)=\sigma^{l}(\mathcal{W^l}*z^{l-1}(x)+b^l) zl(x)=σl(Wl∗zl−1(x)+bl) ,网络的参数 W ∗ = 0 \mathcal{W}^*=0 W∗=0时, z l ( x ) = σ ( b l ) z^{l}(x)=\sigma{(b^l)} zl(x)=σ(bl),对于任意的输入都有相同的输出,因此可以选择 b l b^l bl使得 ϕ ( x ; W ∗ ) = c \phi(x;\mathcal{W^*})=c ϕ(x;W∗)=c,这时将同样导致 R ∗ = 0 R^*=0 R∗=0,造成超球面塌陷。
命题3:不能使用有界的激活函数,假设有上界的激活函数, B : = s u p z σ ( z ) ≠ 0 B:=sup_z\sigma(z)\neq0 B:=supzσ(z)=0,特征k kk对于所有的输入数据都为正,即 z i ( k ) > 0 z_i^{(k)}\gt0 zi(k)>0,对于 i = 1 , . . . , n i=1,...,n i=1,...,n,那么对于任意的 ϵ > 0 \epsilon>0 ϵ>0都存在$ \mathcal{w_k} 使得 使得 使得sup_i|\sigma(\mathcal{w_k}z_i^{(k)})-B|\lt\epsilon 。对于选定的超球面中心 。对于选定的超球面中心 。对于选定的超球面中心c$由与激活函数的有界性将同样会导致特征k kk上超球面的半径为r rr,导致超球面塌陷。
命题4:松弛变量 v v v的性质,对于 J s o f t J_{soft} Jsoft目标函数中的超参数 v ∈ ( 0 , 1 ] v\in(0,1] v∈(0,1],其反映了对异常点的容许上界和对正常样本数据的容许下界。
-
对于不正确制定的网络或超球面中心 c c c,Deep SVDD 可以学习琐碎的、无信息的解决方案。在这里,我们从理论上证明了一些网络属性关系,这些关系将产生微不足道的解决方案(因此必须避免)。然后我们证明软边界深 SVDD 的 $ν-property。
-
下面让 J s o f t ( W , R ) 和 J O C ( W ) J_{soft}(W, R) 和 J_{OC}(W) Jsoft(W,R)和JOC(W) 为软边界和One-Class SVDD 目标函数,如 (3) 和 (4) 中定义。首先,我们表明,将超球面中心 c ∈ F c ∈ F c∈F 作为自由优化变量会导致两个目标的简单解决方案。
-
Proposition 1 (All-zero-weights solution). 。令 W 0 W_0 W0 为全零网络权重的集合,即对于每个 W l ∈ W 0 , W l = 0 W^l \in W_0,W^l = 0 Wl∈W0,Wl=0。对于这种参数选择,网络将任何输入映射到相同的输出,即,对于任何 x, φ ( x ; W 0 ) = φ ( x ^ ; W 0 ) = : c 0 ∈ F , x , x ^ ∈ X φ(x; W_0) = φ(\hat x; W_0) =: c_0 \in F,x,\hat x \in X φ(x;W0)=φ(x^;W0)=:c0∈F,x,x^∈X 。那么,如果 c = c 0 ,则 D e e p S V D D 的最优解由 W ∗ = W 0 和 R ∗ = 0 c = c_0,则Deep SVDD的最优解由W^* = W_0和R^* = 0 c=c0,则DeepSVDD的最优解由W∗=W0和R∗=0给出。
- Proof。对于每个配置 ( W , R ) (W, R) (W,R),我们分别有 J s o f t ( R , W ) ≥ 0 和 J O C ( W ) ≥ 0 J_{soft}(R, W) ≥ 0 和 J_{OC}(W) ≥ 0 Jsoft(R,W)≥0和JOC(W)≥0。由于全零权重网络 φ ( x ; W 0 ) φ(x; W_0) φ(x;W0) 的输出对于每个输入 x ∈ X x ∈ X x∈X都是恒定的(每个网络单元中的所有参数都为零,因此每个网络单元中的线性投影将任何输入映射为零),并且超球面的中心由 c = φ ( x ; W 0 ) c = φ(x; W_0) c=φ(x;W0) 给出,目标的经验和中的所有误差都为零。因此, R ∗ = 0 和 W ∗ = W 0 R^* = 0 和 W^* = W_0 R∗=0和W∗=W0 是最优解,因为在这种情况下 J s o f t ( W ∗ , R ∗ ) = 0 且 J O C ( W ∗ ) = 0 J_{soft}(W^* , R^*) = 0 且J_OC(W^* ) = 0 Jsoft(W∗,R∗)=0且JOC(W∗)=0。
- 不太正式地说,命题 1 意味着如果我们将超球面中心 c 作为 SGD 优化中的自由变量,深度 SVDD 可能会收敛到平凡解 ( W ∗ , R ∗ , c ∗ ) = ( W 0 , 0 , c 0 ) (W^*, R^*, c^*) = (W_0, 0, c_0) (W∗,R∗,c∗)=(W0,0,c0)。我们将这样的解决方案称为“超球面塌陷”,其中网络学习权重,使得网络产生映射到超球面中心的恒定函数,因为超球面半径塌陷到零。命题 1 还意味着,当在输出空间 F 中固定 c 时,我们需要 c ≠ 0 c \neq 0 c=0,因为否则超球面塌陷将再次成为可能。例如,对于具有 ReLU 激活函数的卷积神经网络 (CNN),这需要 c ≠ 0 c \neq 0 c=0。根据经验,我们发现将 c 固定为对某些训练数据执行初始前向传递所产生的网络表示的平均值样本是一个很好的策略。尽管我们在实验中对 c 的其他选择(确保 c ≠ c 0 c \neq c_0 c=c0)获得了类似的结果,但我们发现将 c 固定在初始网络输出的邻域内可以使 SGD 收敛更快、更稳健。
-
接下来,我们确定两个网络架构属性,这也将实现简单的超球体崩溃解决方案。
-
Proposition 2 (Bias terms).。令 c ∈ F c ∈ F c∈F 为任何固定的超球面中心。如果网络中存在任何隐藏层 φ ( ⋅ ; W ) : X → F φ(· ; W) : X → F φ(⋅;W):X→F 具有偏置项,则存在具有 R 的 Deep SVDD 目标 (3) 和 (4) 的最优解 ( R ∗ , W ∗ ) (R^*, W^*) (R∗,W∗)对于每个 $x ∈ X , ∗ = 0 且 φ(x; W* ) = c 。
-
证明。假设层 $ l \in {1, . … , L} $与权重 W l W^l Wl 也有一个偏置项 b l b^l bl 。对于任何输入 x ∈ X ,层 的输出由
-
z k ( x ) = σ l ( W l z ˙ l − 1 ( x ) + b l ) z^k(x)=\sigma^l(W^l\dot z^{l-1}(x)+b^l) zk(x)=σl(Wlz˙l−1(x)+bl)
-
给出,其中 “ ⋅ ” “·” “⋅”表示线性算子(例如、矩阵乘法或卷积), σ l ( ⋅ ) σ^l (·) σl(⋅) 是层 l l l的激活,前一层 l − 1 l−1 l−1 的输出 z l − 1 z^{l-1} zl−1 取决于前一层串联的输入 x x x。然后,对于 W l = 0 W^l = 0 Wl=0,我们有 z l ( x ) = σ l ( b l ) ,即层 l 的输出对于每个输入 x ∈ X z^l(x) = σ^l (b^l ),即层 l 的输出对于每个输入 x ∈ X zl(x)=σl(bl),即层l的输出对于每个输入x∈X 都是恒定的。因此,可以选择偏置项 b l b^l bl(以及后续层的权重),使得对于 每个 x ∈ X , φ ( x ; W ∗ ) = c 每个 x ∈ X , φ(x; W^* ) = c 每个x∈X,φ(x;W∗)=c(假设 c 在网络图像中作为 b l b^l bl 的函数) 以及后续参数 W l + 1 , . . , W L ) W^{l+1} , . . ,W^L) Wl+1,..,WL)。因此,以这种方式选择 W ∗ W^* W∗ 会导致经验项为零,而选择 R ∗ = 0 R^* = 0 R∗=0 会给出最优解(为了简单起见,忽略权重衰减正则化项)。
-
换句话说,命题 2 意味着具有偏差项的网络可以轻松学习任何常数函数,该函数独立于输入 x ∈ X 。由此可见,偏差项不应在具有 Deep SVDD 的神经网络中使用,因为网络可以学习直接映射到超球体中心的常数函数,从而导致超球体崩溃。
-
-
Proposition 3 (Bounded activation functions).。考虑具有单调激活函数 σ ( ⋅ ) σ(·) σ(⋅) 的网络单元,该函数的上(或下)界为 s u p z σ ( z ) ≠ 0 sup_z σ(z) \neq 0 supzσ(z)=0(或 i n f z σ ( z ) ≠ 0 inf_z σ(z) \neq 0 infzσ(z)=0)。然后,对于一组单位输入 { z 1 , . . . 。。 , z n } \{z_1,... 。 。 , z_n\} {z1,...。。,zn} 至少有一个对于所有输入都是正或负的特征,非零上确界(或下确界)可以在一组输入上统一近似。
- 证明。 Wlog 考虑 σ σ σ 的上限为 B : = s u p z σ ( z ) ≠ 0 B := sup_z σ(z) \neq 0 B:=supzσ(z)=0 且特征 k 对于所有输入均为正的情况,即对于每个 i = 1 , . . . , n , z i ( k ) > 0 。 i = 1,...,n,z_i^{(k)} \gt 0。 i=1,...,n,zi(k)>0。.然后,对于每个 ε > 0 ε \gt0 ε>0,我们总是可以选择足够大的第 k k k 个元素 w k w_k wk 的权重(将所有其他网络单元权重设置为零),使得 s u p i ∣ σ ( w k z i ( k ) ) − B ∣ < ε 。 sup_i |σ(w_k z_i^{(k)}) − B| \lt ε。 supi∣σ(wkzi(k))−B∣<ε。
- 命题 3 简单地说,具有有界激活函数的网络单元对于具有至少一个具有共同符号的特征的所有输入来说可以是饱和的,从而在后续层中模拟偏置项,这再次导致超球面崩溃。因此,在 Deep SVDD 中应首选无界激活函数(或仅以 0 为界的函数),例如 ReLU,以避免由于“学习”偏差项而导致超球面崩溃。
-
总结以上分析:超球体中心 c 的选择必须不是全零权重解,并且在 Deep SVDD 中只能使用没有偏置项或有界激活函数的神经网络,以防止超球体崩溃解。最后,我们证明 ν 属性也适用于软边界 Deep SVDD,它允许包含对训练数据中假设存在的异常数量的先前假设。
-
-
Proposition 4 (ν-property)。 (3) 中的软边界 Deep SVDD 目标中的超参数 ν ∈ ( 0 , 1 ] ν \in (0, 1] ν∈(0,1] 是离群值分数的上限,以及位于超球面外部或边界上的样本分数的下界。证明。定义 d i = ∣ ∣ φ ( x i ; W ) − c ∣ ∣ 2 , f o r i = 1 , . . . , n . d_i = ||φ(x_i; W) − c||^2 , for \ i = 1, . . . , n. di=∣∣φ(xi;W)−c∣∣2,for i=1,...,n. Wlog 假设 d 1 ≥ ⋅ ⋅ ⋅ ≥ d n d_1 ≥ · · · ≥ d_n d1≥⋅⋅⋅≥dn. 异常值的数量由下式给出: n o u t = ∣ i : d i > R 2 ∣ n_{out} = |{i : d_i \gt R^2}| nout=∣i:di>R2∣,我们可以将软边界目标
J s o f t ( R ) = R 2 − n o u t v n R 2 = ( 1 − n o u t v n ) R 2 J_{soft}(R) = R^2-\frac{n_{out}}{vn}R^2 = (1-\frac{n_{out}}{vn})R^2 Jsoft(R)=R2−vnnoutR2=(1−vnnout)R2- 也就是说,只要 n o u t ≤ ν n n_{out} ≤ νn nout≤νn成立,半径 R 就会减小。因此,$\frac{n_{out}}{n} ≤ ν 必须保持在最优值,即 必须保持在最优值,即 必须保持在最优值,即ν$ 是异常值比例的上限,并且对于最大 n o u t n_{out} nout 给出最佳半径 R ∗ R^* R∗,对于该不等式仍然成立。最后,我们有 R ∗ 2 = d i , i = n o u t + 1 R^{*2} = d_i,i = n_{out} + 1 R∗2=di,i=nout+1,因为在这种情况下半径 R 最小,并且边界上的点不会增加目标。因此,我们也有 ∣ i : d i ≥ R ∗ 2 ∣ ≥ n o u t + 1 ≥ ν n |{i : d_i ≥ R^{*2}} | ≥ n_{out} + 1 ≥ νn ∣i:di≥R∗2∣≥nout+1≥νn。
4. 实验
我们在著名的 MNIST (Le Cun et al., 2010) 和 CIFAR-10 (Krizhevsky & Hinton, 2009) 数据集上评估 Deep SVDD。对抗性攻击(Goodfellow et al., 2015)最近引起了很多关注,在这里我们研究使用异常检测来检测此类攻击的可能性。为此,我们将边界攻击(Brendel 等人,2018)应用于 GTSRB 停车标志数据集(Stallkamp 等人,2011)。我们将我们的方法与来自不同范式的各种最先进方法进行比较。我们使用图像数据,因为它们通常是高维的,而且允许人类观察者对检测到的异常谎言进行定性视觉评估。使用分类数据集创建一类分类设置,使我们能够在测试中使用真实标签,通过 AUC 测量来定量评估结果(参见 Erfani 等人,2016 年;Em mott 等人,2016 年)。当然,对于训练,我们不使用任何标签。
4.1. Competing methods
- Shallow Baselines
- (i) 具有高斯内核的内核 OC-SVM/SVDD。我们从 γ ∈ { 2 − 10 , 2 − 9 , . . . , 2 − 1 } γ ∈ \{2^{−10} , 2^{−9} , ... , 2^{−1}\} γ∈{2−10,2−9,...,2−1} 通过网格搜索,使用小保留集(随机抽取的测试样本的 10%)上的性能。这使得浅层 SVDD 具有较小的监督优势。我们对 ν ∈ { 0.01 , 0.1 } ν ∈ \{0.01, 0.1\} ν∈{0.01,0.1} 运行所有实验并报告更好的结果。
- (ii) 核密度估计(KDE)。我们从 h ∈ { 2 0.5 , 2 1 , . . . 2 5 } h ∈ \{2^{0.5}, 2^1 , ... 2^5\} h∈{20.5,21,...25} 通过使用对数似然得分的 5 倍交叉验证。
- (iii) 隔离森林 (IF)(Liu 等人,2008)。我们将树的数量设置为 t = 100 t = 100 t=100,将子采样大小设置为 ψ = 256 ψ = 256 ψ=256,正如原始工作中所建议的那样。我们不与惰性评估方法进行比较,因为此类方法没有训练阶段并且不学习正态性模型(例如局部离群因子(LOF)(Breunig 等人,2000))。对于所有三个浅基线,我们通过 PCA 降低数据的维数,其中我们选择最小数量的特征向量,以便保留至少 95% 的方差(参见 Erfani 等人,2016)。
- Deep Baselines and Deep SVDD深度基线和深度 SVDD 我们将深度 SVDD 与第 2.2 节中描述的两种深度方法进行比较。由于我们的实验是在图像数据上进行的,因此我们从各种自动编码器中选择 DCAE。对于 DCAE 编码器,我们采用与 Deep SVDD 相同的网络架构。然后对称地创建解码器,其中我们用上采样代替最大池化。我们使用 MSE 损失来训练 DCAE。对于 AnoGAN,我们将架构修复为 DCGAN(Radford 等人,2015),并将潜在空间维度设置为 256,遵循 Metz 等人的做法。 (2017),否则请遵循 Schlegl 等人。 (2017)。对于 Deep SVDD,我们删除了所有网络单元中的偏置项,以防止超球体崩溃,如第 3.3 节所述。在软边界 Deep SVDD 中,我们通过每 k = 5 e p o c h k = 5 \ epoch k=5 epoch 的线搜索求解 R。我们从 ν ∈ { 0.01 , 0.1 } ν ∈ \{0.01, 0.1\} ν∈{0.01,0.1} 中选择 ν 并再次报告最佳结果。如第 3.3 节所述,在执行初始前向传递后,我们将超球面中心 c 设置为映射数据的平均值。为了优化,我们使用 Adam 优化器(Kingma & Ba,2014)以及原始工作中推荐的参数,并应用批量归一化(Ioffe & Szegedy,2015)。对于竞争性深度 AD 方法,我们通过统一的 Glorot 权重(Glorot & Bengio,2010)来初始化网络权重,对于 Deep SVDD,使用经过训练的 DCAE 编码器的权重进行初始化,从而建立预训练过程。我们采用简单的两阶段学习率计划(搜索+微调),初始学习率为 η = 1 0 − 4 η = 10^{−4} η=10−4 ,随后为 η = 1 0 − 5 η = 10^{−5} η=10−5 。对于 DCAE,我们训练 250 + 100 e p o c h s 250 + 100 epochs 250+100epochs,对于 Deep SVDD 150 + 100。Leaky ReLU 激活与泄漏 α = 0.1 α = 0.1 α=0.1 一起使用。
4.2. MNIST 和 CIFAR-10 设置上的One-class classification
- **Setup:**MNIST 和 CIFAR-10 都有十个不同的类,我们从中创建十个一类分类设置。在每个设置中,其中一个类是正常类,其余类的样本用于表示异常。我们在实验中使用原始的训练和测试分割,并且仅使用来自相应正常类的训练集示例进行训练。对于 MNIST,训练集大小为 n ≈ 6 000;对于 CIFAR-10,训练集大小为 n = 5 000。两个测试集都有 10000 个样本,其中每个设置都包含来自九个异常类别的样本。我们使用 L1 范数对所有图像进行全局对比度归一化预处理,最后通过最小-最大缩放重新缩放到 [0, 1]。
- **Network architectures:**对于这两个数据集,我们都使用 LeNet 类型的 CNN,其中每个卷积模块由一个卷积层组成,后跟 Leaky ReLU 激活和 2 × 2 最大池化。在 MNIST 上,我们使用具有两个模块的 CNN:8×(5×5×1)-滤波器,后跟 4×(5×5×1)-滤波器,以及包含 32 个单元的最终密集层。在 CIFAR-10 上,我们使用具有三个模块的 CNN:32×(5×5×3)-滤波器、64×(5×5×3)-滤波器和 128×(5×5×3)-滤波器,接下来是 128 个单元的最终密集层。我们使用 200 的批量大小并将权重衰减超参数设置为 λ = 1 0 − 6 λ = 10^{−6} λ=10−6。
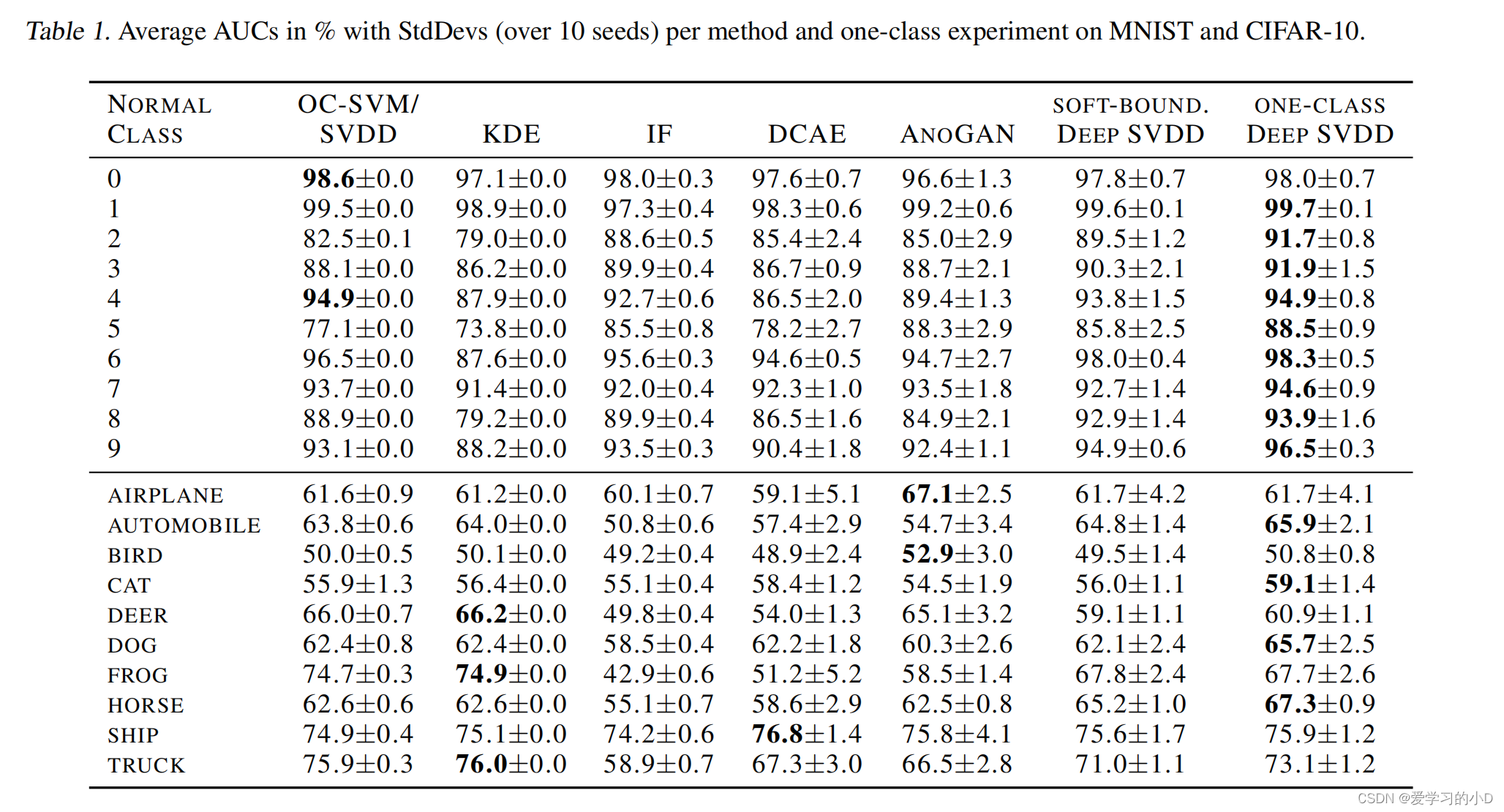
- **Results:**结果 结果如表 1 所示。深度 SVDD 在 MNIST 上明显优于其浅层和深层竞争对手。在 CIFAR-10 上,情况好坏参半。然而,Deep SVDD 表现出整体强劲的表现。有趣的是,在 10 个 CIFAR-10 类中的 3 个类中,浅层 SVDD 和 KDE 的表现优于深层方法。图 2 和图 3 分别显示了根据 Deep SVDD 和 KDE 的最正常和最异常的类内样本示例。我们可以看到 KDE 表现最好的类的正常示例似乎具有强大的全局结构。例如,卡车图像大多水平划分为街道和天空,而鹿和青蛙在全局上具有相似的颜色。对于这些类别,选择局部 CNN 特征可能会受到质疑。这些案例凸显了网络架构选择的重要性。值得注意的是,One-Class Deep SVDD 在两个数据集上的表现都比其软边界对应物稍好。这可能是因为训练数据中不存在异常的假设在我们的场景中是有效的。由于 SGD 优化,深度方法显示出更高的标准偏差。
4.3.针对 GTSRB 停车标志的对抗性攻击
- **Setup:**检测对抗性攻击对于自动驾驶等许多应用至关重要。在这个实验中,我们测试了 Deep SVDD 与其竞争对手在检测对抗样本方面的比较。我们考虑德国交通标志识别基准(GTSRB)数据集的“停车标志”类,我们使用边界攻击从测试集随机绘制的停车标志图像中生成对抗性示例。我们仅在正常停车标志样本上再次训练模型,并在测试中检查是否正确检测到对抗性样本。训练集包含 n = 780 个停车标志。测试集由 270 个正常样本和 20 个对抗样本组成。我们通过删除每个标志周围 10% 的边框来预处理数据,然后将每个图像的大小调整为 32 × 32 像素。之后,我们再次使用 L1 范数应用全局对比度归一化,并重新缩放到单位区间 [0, 1]。
- **Network architecture:**网络架构我们使用具有 LeNet 架构的 CNN,该架构具有三个卷积模块:16×(5×5×3)-滤波器、32×(5×5×3)-滤波器和 64×(5×5×3)-滤波器过滤器,然后是 32 个单元的最终密集层。由于数据集大小,我们使用较小的批量大小 64 进行训练,并再次设置超参数 λ = 1 0 − 6 λ = 10^{−6} λ=10−6。
- Results: 表2显示了结果。 One-Class Deep SVDD 再次展现出最佳性能。一般来说,深度方法表现更好。 AnoGAN 的 DCGAN 没有收敛,因为数据集大小对于 GAN 来说太小。图 4 显示了 One-Class Deep SVDD 检测到的最异常样本,这些样本要么是对抗性攻击,要么是被错误裁剪的奇怪视角的图像。我们参考补充材料以获取最正常图像和检测到的异常的更多示例。

5. 结论
我们在这项工作中引入了第一个针对无监督 AD 的Deep One-Class Classification目标。我们的方法 Deep SVDD 联合训练深度神经网络,同时优化输出空间中的数据封闭超球面。通过这个 Deep SVDD 从数据中提取常见的变异因素。我们已经证明了我们的方法的理论属性,例如 ν 属性,它允许合并对数据中存在的异常值数量的先前假设。我们的实验定量和定性地证明了 Deep SVDD 的良好性能。
代码分析
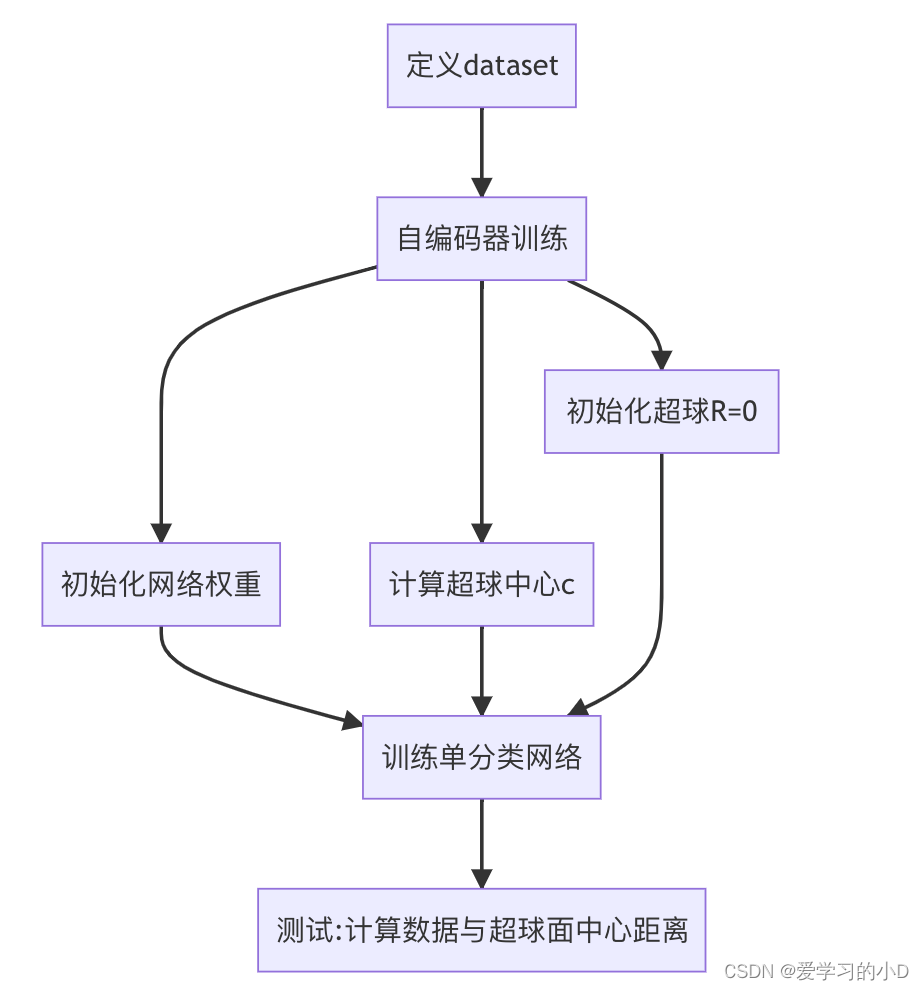
本文作者使用的数据集为MNIST和CIFA10,网络结构使用的是Lecun1998年提出的**LeNet**,包括两个卷积两个池化和一层全连接层。
网络结构
class MNIST_LeNet(BaseNet):
"""
因为有全连接层,所有不同的输入size导致fc的输入大小都不一样
故定义了`MNIST_LeNet`和`CIFA10_LeNet`
"""
def __init__(self):
super().__init__()
self.rep_dim = 32
self.pool = nn.MaxPool2d(2, 2)
self.conv1 = nn.Conv2d(1, 8, 5, bias=False, padding=2)
self.bn1 = nn.BatchNorm2d(8, eps=1e-04, affine=False)
self.conv2 = nn.Conv2d(8, 4, 5, bias=False, padding=2)
self.bn2 = nn.BatchNorm2d(4, eps=1e-04, affine=False)
self.fc1 = nn.Linear(4 * 7 * 7, self.rep_dim, bias=False)
def forward(self, x):
x = self.conv1(x)
x = self.pool(F.leaky_relu(self.bn1(x)))
x = self.conv2(x)
x = self.pool(F.leaky_relu(self.bn2(x)))
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
Deep SVDD定义了预训练的方法。其基于自编码器来实现,然后使用自编码器中对应的网络权重来初始化对应的网络参数。自编码器网络结构:
class CIFAR10_LeNet_Autoencoder(BaseNet):
"""
先将图片下采样,再上采样,恢复为原来尺寸
"""
def __init__(self):
super().__init__()
self.rep_dim = 128
self.pool = nn.MaxPool2d(2, 2)
# Encoder (must match the Deep SVDD network above)
self.conv1 = nn.Conv2d(3, 32, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.conv1.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d1 = nn.BatchNorm2d(32, eps=1e-04, affine=False)
self.conv2 = nn.Conv2d(32, 64, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.conv2.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d2 = nn.BatchNorm2d(64, eps=1e-04, affine=False)
self.conv3 = nn.Conv2d(64, 128, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.conv3.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d3 = nn.BatchNorm2d(128, eps=1e-04, affine=False)
self.fc1 = nn.Linear(128 * 4 * 4, self.rep_dim, bias=False)
self.bn1d = nn.BatchNorm1d(self.rep_dim, eps=1e-04, affine=False)
# Decoder
self.deconv1 = nn.ConvTranspose2d(int(self.rep_dim / (4 * 4)), 128, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.deconv1.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d4 = nn.BatchNorm2d(128, eps=1e-04, affine=False)
self.deconv2 = nn.ConvTranspose2d(128, 64, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.deconv2.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d5 = nn.BatchNorm2d(64, eps=1e-04, affine=False)
self.deconv3 = nn.ConvTranspose2d(64, 32, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.deconv3.weight, gain=nn.init.calculate_gain('leaky_relu'))
self.bn2d6 = nn.BatchNorm2d(32, eps=1e-04, affine=False)
self.deconv4 = nn.ConvTranspose2d(32, 3, 5, bias=False, padding=2)
nn.init.xavier_uniform_(self.deconv4.weight, gain=nn.init.calculate_gain('leaky_relu'))
def forward(self, x):
x = self.conv1(x)
x = self.pool(F.leaky_relu(self.bn2d1(x)))
x = self.conv2(x)
x = self.pool(F.leaky_relu(self.bn2d2(x)))
x = self.conv3(x)
x = self.pool(F.leaky_relu(self.bn2d3(x)))
x = x.view(x.size(0), -1)
x = self.bn1d(self.fc1(x))
x = x.view(x.size(0), int(self.rep_dim / (4 * 4)), 4, 4)
x = F.leaky_relu(x)
x = self.deconv1(x)
x = F.interpolate(F.leaky_relu(self.bn2d4(x)), scale_factor=2)
x = self.deconv2(x)
x = F.interpolate(F.leaky_relu(self.bn2d5(x)), scale_factor=2)
x = self.deconv3(x)
x = F.interpolate(F.leaky_relu(self.bn2d6(x)), scale_factor=2)
x = self.deconv4(x)
x = torch.sigmoid(x)
return x
-
可以看到网络中使用的激活函数是没有上界的leaky_relu
-
自编码器网络的损失函数是基于原图与自编码器的输出计算均方误差来实现的:
# src/optim/ae_trainer.py line:57-59
outputs = ae_net(inputs)
scores = torch.sum((outputs - inputs) ** 2, dim=tuple(range(1, outputs.dim())))
loss = torch.mean(scores)
自编码器预训练的权重会作为LeNet网络的初始化权重,见init_network_weights_from_pretraining方法:
# src/deepSVDD.py line:100-114
def init_network_weights_from_pretraining(self):
"""Initialize the Deep SVDD network weights from the encoder weights of the pretraining autoencoder."""
net_dict = self.net.state_dict()
ae_net_dict = self.ae_net.state_dict()
# Filter out decoder network keys
ae_net_dict = {k: v for k, v in ae_net_dict.items() if k in net_dict}
# Overwrite values in the existing state_dict
net_dict.update(ae_net_dict)
# Load the new state_dict
self.net.load_state_dict(net_dict)
初始化网络参数后,超球面的中心c的计算在src/optim/deepSVDD_trainer.py的train方法中,其计算方式为:
def init_center_c(self, train_loader: DataLoader, net: BaseNet, eps=0.1):
"""Initialize hypersphere center c as the mean from an initial forward pass on the data."""
n_samples = 0
c = torch.zeros(net.rep_dim, device=self.device)
net.eval()
with torch.no_grad():
for data in train_loader:
# get the inputs of the batch
inputs, _, _ = data
inputs = inputs.to(self.device)
outputs = net(inputs)
n_samples += outputs.shape[0]
c += torch.sum(outputs, dim=0)
c /= n_samples
# If c_i is too close to 0, set to +-eps. Reason: a zero unit can be trivially matched with zero weights.
c[(abs(c) < eps) & (c < 0)] = -eps
c[(abs(c) < eps) & (c > 0)] = eps
return c

















 4007
4007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









