







AlexNet网络结构及代码
AlexNet网络结构
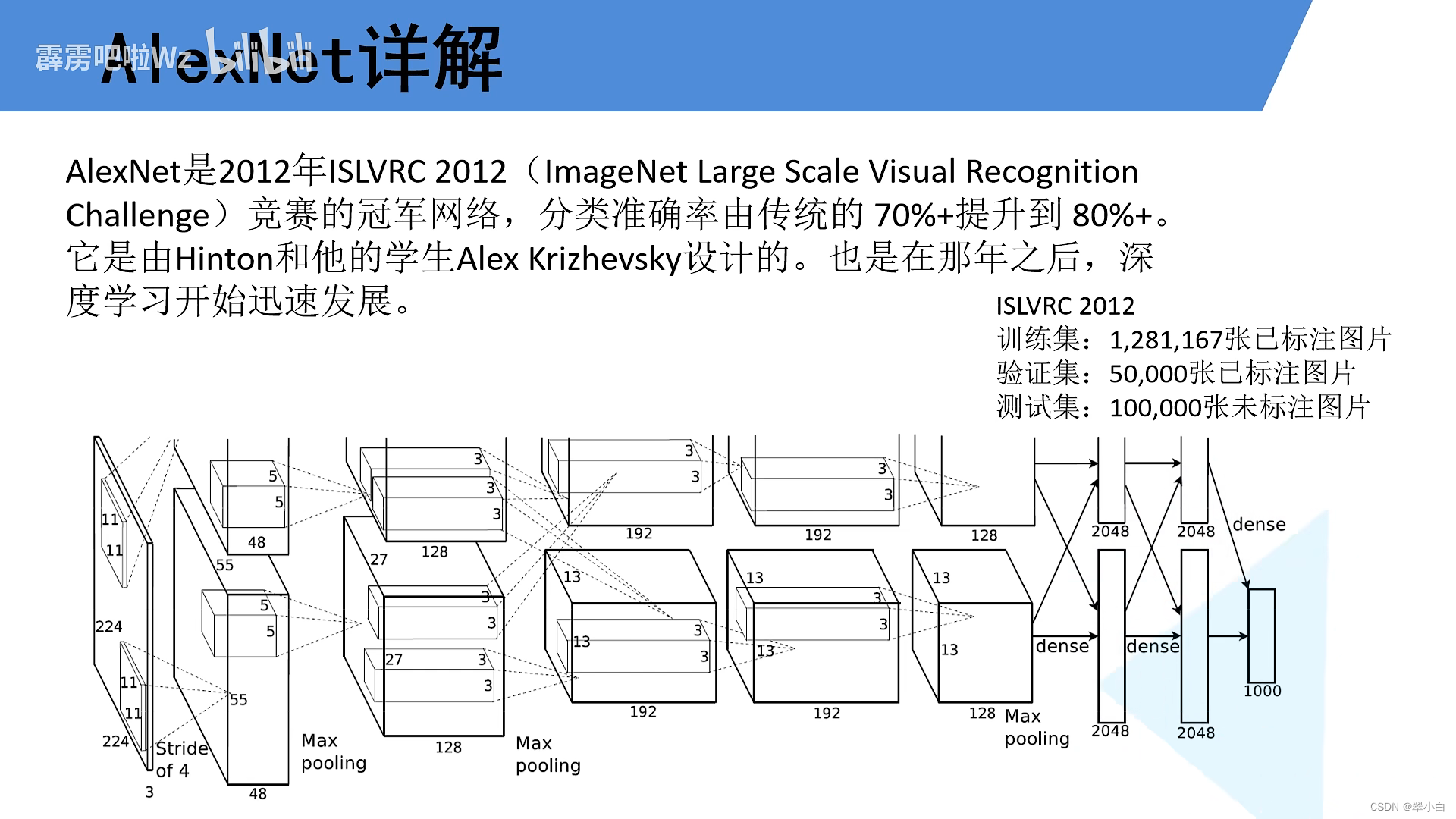

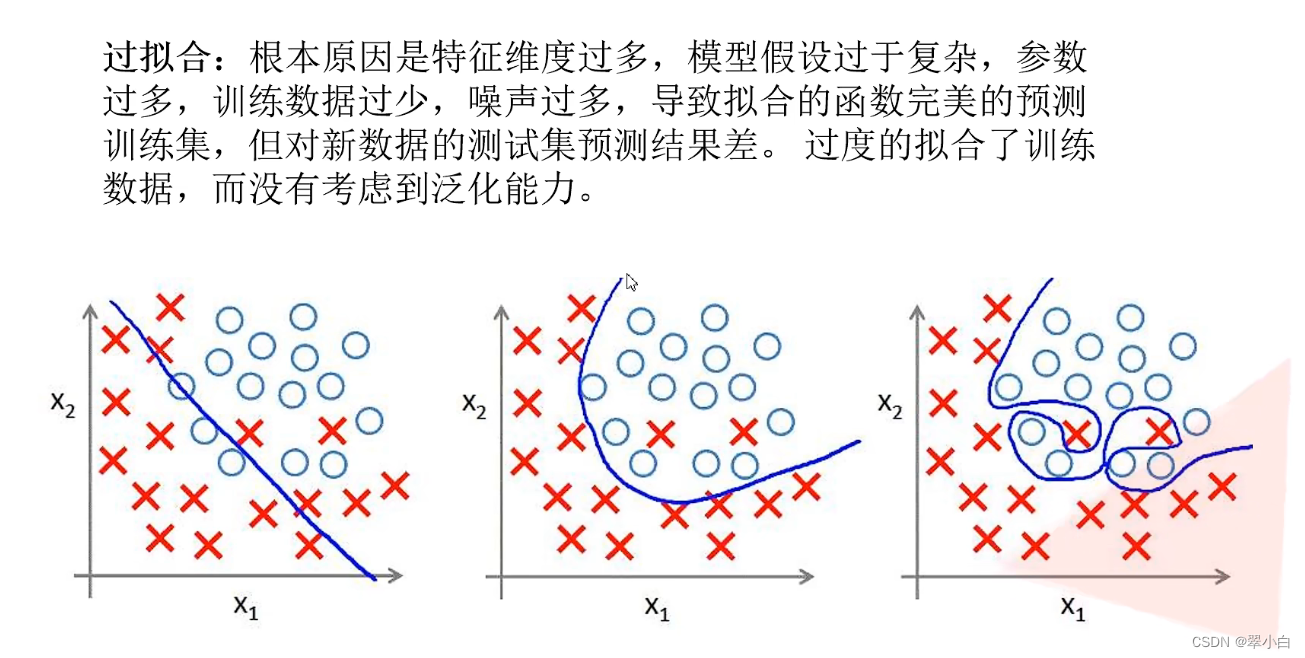
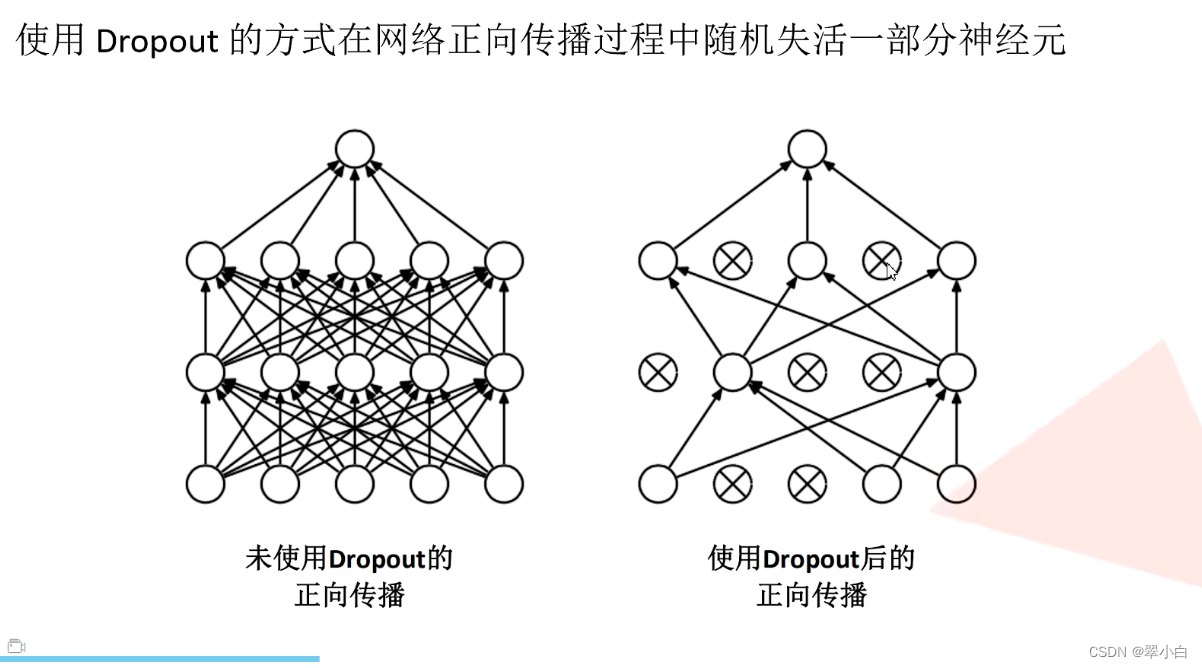

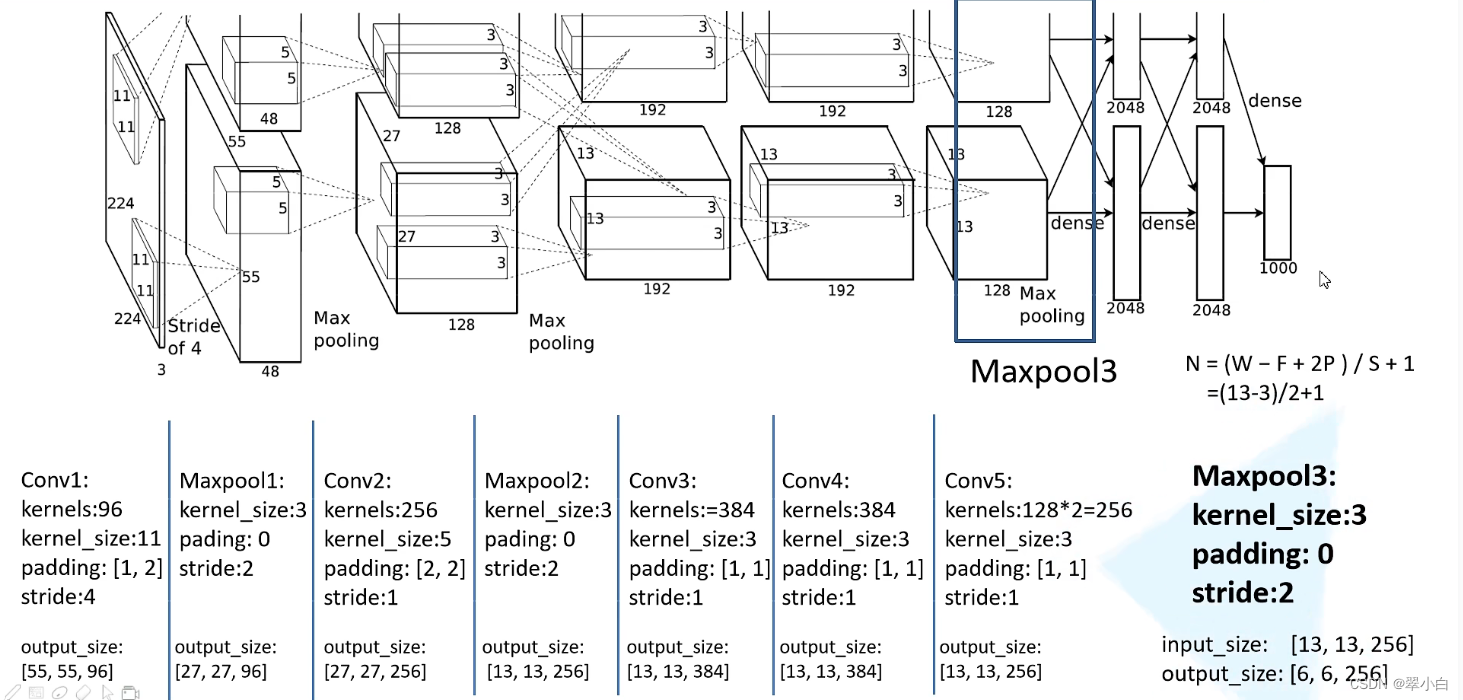

AlexNet网络构建代码
模型构建
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential( # 由于自己数据集较小,讲卷积核个数设置为原论文卷积核个数的一半
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def _initialize_weights(self):
# r"""Returns an iterator over all modules in the network.
for m in self.modules(): # self.modules()继承父类Module,会迭代定义的每一个层结构
if isinstance(m, nn.Conv2d): # 判断层结构是否是我们给定的一个卷积层
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') # 对w进行初始化
if m.bias is not None: # 如果偏置不为空的话
nn.init.constant_(m.bias, 0) # 偏置设置为0
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
训练网络
import os
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
# 定义数据预处理函数
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 获取数据集所在的根目录,os.getcwd()获取当前文件所在的目录,..代表返回上一层目录,../..代表返回上上层目录
# os.path.abspath取决于os.getcwd,如果是一个绝对路径,就返回,如果不是绝对路径,根据编码执行getcwd/getcwdu.然后把path和当前工作路径连接起来.
# >>> os.getcwd()
# 'C:\\Users\\86136'
# >> > data_root = os.path.abspath(os.path.join(os.getcwd(), "../.."))
# >> > data_root
# 'C:\\'
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), # ImageFolder数据加载器,加载数据集
transform=data_transform["train"])
train_num = len(train_dataset) # 3306
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
flower_list = train_dataset.class_to_idx # 获取分类名称所对应的索引 class_to_idx (dict): Dict with items (class_name, class_index).
cla_dict = dict((val, key) for key, val in flower_list.items()) # # {0:'daisy', 1:'dandelion', 2:'roses', 3:'sunflower', 4:'tulips'}
# write dict into json file
json_str = json.dumps(cla_dict, indent=4) # 将字典编码为json格式
with open('class_indices.json', 'w') as json_file: # 保存在json文件中
json_file.write(json_str)
batch_size = 32 # batchsize:批大小。在深度学习中,一般采用SGD训练,即每次训练在训练集中取batchsize个样本训练;
# 加载数据
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=0)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset) # 364
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=0)
print("using {} images for training, {} images for validation.".format(train_num,
val_num))
# 如何查看数据集
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=5, init_weights=True)
net.to(device) # 将网络指定到规定的设备上
loss_function = nn.CrossEntropyLoss() # 损失函数,交叉熵损失函数
# pata = list(net.parameters())
optimizer = optim.Adam(net.parameters(), lr=0.0002) # 优化器
epochs = 10
save_path = './AlexNet.pth' # 保存权重的路径
best_acc = 0.0
train_steps = len(train_loader) # 104
for epoch in range(epochs):
# train
net.train() # 启用dropout方法,因为我们希望在训练时使用dropout方法,在验证时关闭
running_loss = 0.0
train_bar = tqdm(train_loader)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad() # 清空梯度信息
outputs = net(images.to(device)) # 正向传播,训练图像也指定到我们的设备当中
loss = loss_function(outputs, labels.to(device)) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新每个节点的参数
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
net.eval() # 关闭dropout方法
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad(): # 禁止pytorch对我们的参数进行跟踪,即在验证过程中不计算损失梯度
val_bar = tqdm(validate_loader)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item() # 验证正确样本数
val_accurate = acc / val_num # 测试集准确率:验证正确样本数/总数
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path) # 保存当前权重
print('Finished Training')
if __name__ == '__main__':
main()
预测代码
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 图片预处理
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "./tulip.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0) # 扩充一个维度[B, C, H, W]
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file) # 加载字典文件解码
# create model
model = AlexNet(num_classes=5).to(device)
# load model weights
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path)) # 加载模型权重
model.eval() # 关闭dropout
with torch.no_grad():
# predict class torch.squeeze(
output = torch.squeeze(model(img.to(device))).cpu() # 维度压缩,将batch的维度压缩掉,输出值:tensor([-2.2252, -2.5373, 0.9758, -0.0364, 2.3477])
# 也可以不压缩维度,改一下predict = torch.softmax(output, dim=1),使dim=1
# output = model(img.to(device)).cpu()
predict = torch.softmax(output, dim=0) # 概率分布 tensor([0.0076, 0.0055, 0.1860, 0.0676, 0.7333])
predict_cla = torch.argmax(predict).numpy() # 获取概率最大的所对应的索引值 array(4, dtype=int64)
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
以上代码里面都有详细的注释,希望能给大家带来一些帮助
视频地址:https://www.bilibili.com/video/BV1p7411T7Pc?spm_id_from=333.999.0.0














 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









