






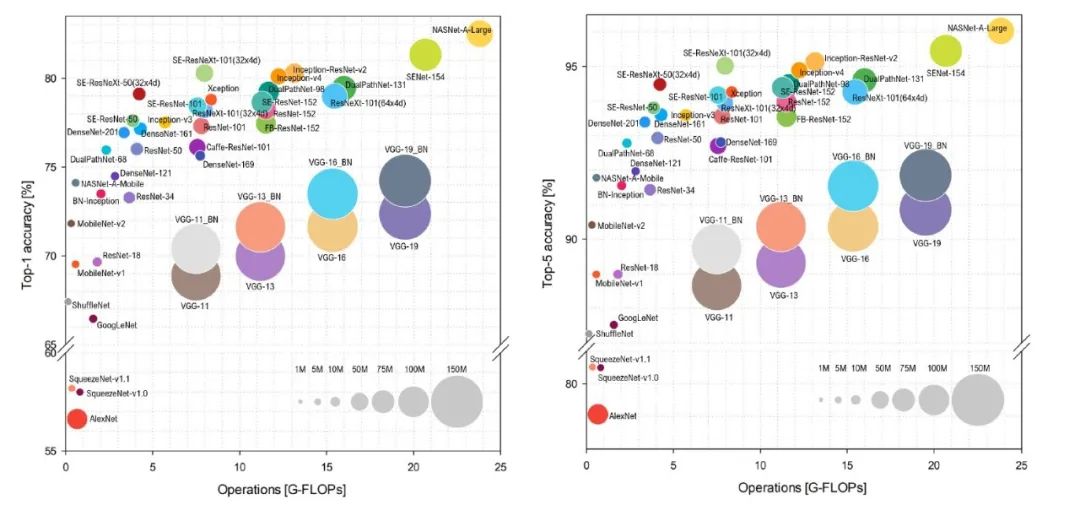
【导读】今天将主要介绍Inception的家族及其前世今生.Inception 网络是 CNN 发展史上一个重要的里程碑。在 Inception 出现之前,大部分 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。而Inception则是从网络的堆叠结构出发,提出了多条并行分支结构的思想,后续一系列的多分支网络结构均从此而来。总体来说,Inception系列网络在结构上相对比较复杂,工程性较强,而且其中通常使用很多tricks来提升网络的综合性能(准确率和速度)。目前Inception系列具体网络结构包括:
Inception v1
Inception v2
Inception v3
Inception v4
Xception
Inception Convolution with Efficient Dilation Search(CVPR2021 oral)
详细代码可查看:https://github.com/murufeng/awesome_lightweight_networks/tree/main/light_cnns/Inception
Going Deeper with Convolutions (GoogleNet)

论文地址:https://arxiv.org/abs/1409.4842
Inception-v1就是2014年ImageNet竞赛的冠军-GoogLeNet,它的名字也是为了致敬较早的LeNet网络。GoogLenet架构的主要特点是更好地整合了网络内部的计算资源,并且精心设计了一个新的Inception模块,该模块允许增加网络的深度和宽度,同时保持计算资源不变.原始的Inception模块如下图所示:
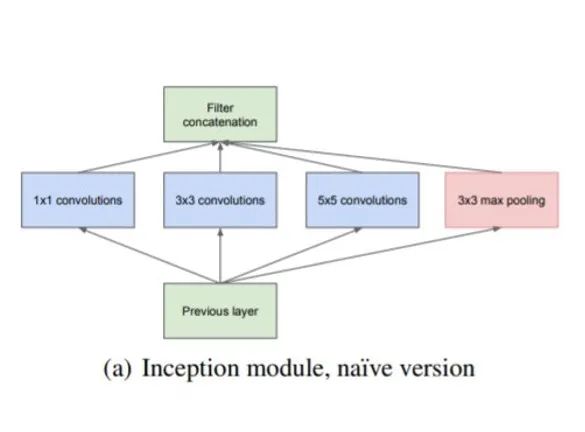 原始的Inception模块主要包含几种不同大小的卷积,即1x1卷积,3x3卷积和5x5卷积,还有一个3x3的max pooling层。这些卷积层和pooling层得到的特征concat在一起作为最终的输出,即下一个模块的输入。
原始的Inception模块主要包含几种不同大小的卷积,即1x1卷积,3x3卷积和5x5卷积,还有一个3x3的max pooling层。这些卷积层和pooling层得到的特征concat在一起作为最终的输出,即下一个模块的输入。
GoogLenet在Inception模块基础上进行改进。具体结构如下图所示:
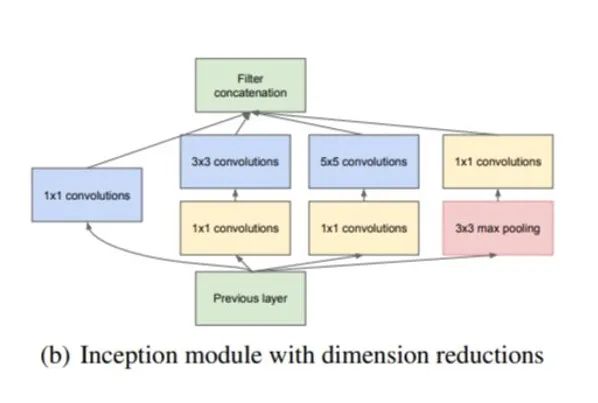
首先使用1x1的卷积来进行升降维,这样就巧妙地解决了针对采用较大的卷积核计算复杂度较大这一问题;然后再在多个不同尺度上运用不同大小的卷积核同时进行卷积,最后将特征进行聚合。
具体网络结构如下所示:
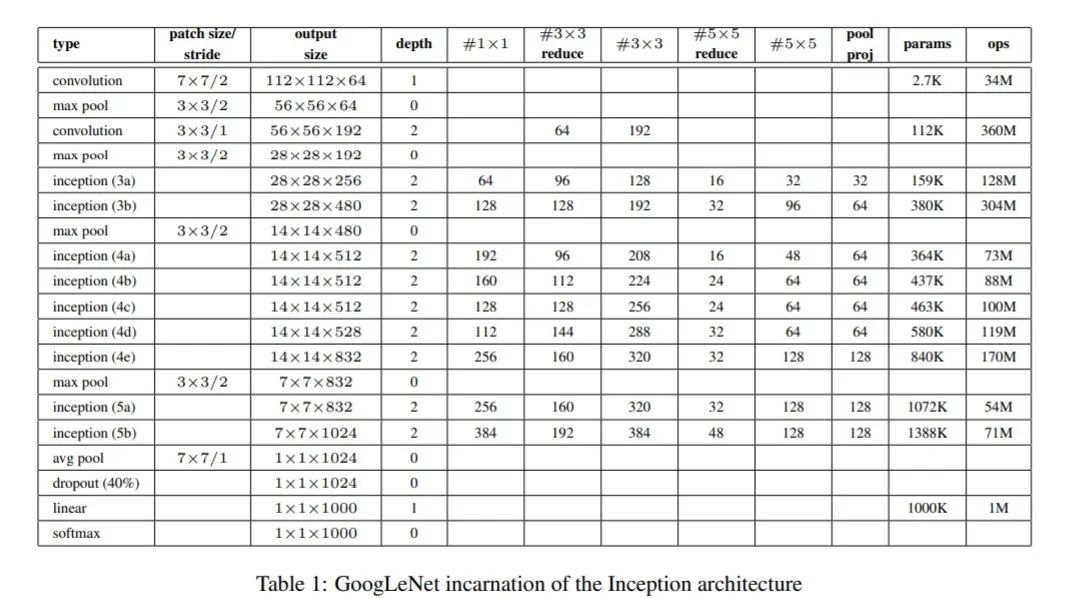
代码实现
import torch
from light_cnns import googlenet
model = googlenet()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Inception v2 & Inception v3

- 论文地址:https://arxiv.org/abs/1512.00567
Inception v2 和 Inception v3 均来自同一篇论文《Rethinking the Inception Architecture for Computer Vision》,作者提出了一系列能增加准确度和减少计算复杂度的修正方法。
Inceptionv2针对InceptionV1改进的点主要有:
引入了BN层来对中间特征进行归一化。使用BN层之后,可以加快收敛速度,防止模型出现过拟合.
使用因子分解的方法,主要包括:将 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度;将 n*n 的卷积核尺寸分解为 1×n 和 n×1 两个卷积.
扩展模型的宽度,来有效地解决表征性瓶颈问题。
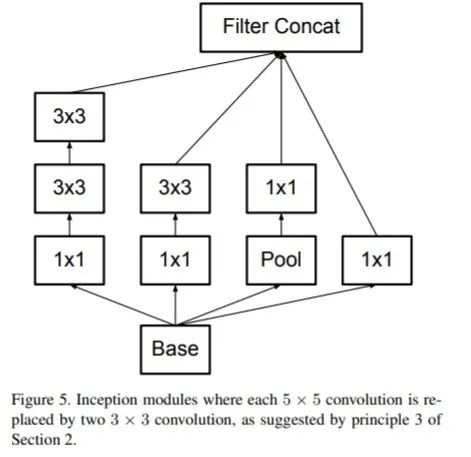
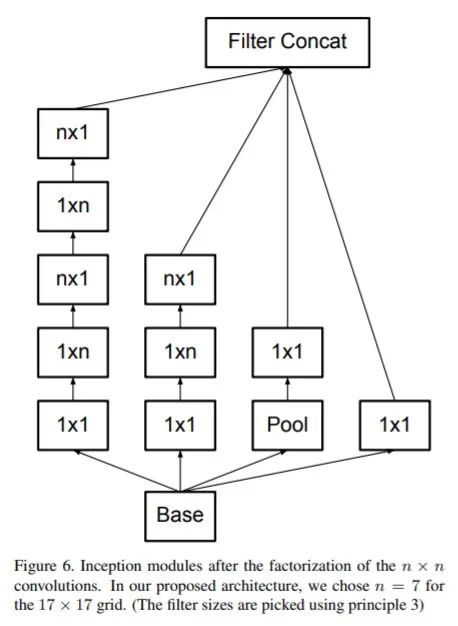
网络结构如下所示:
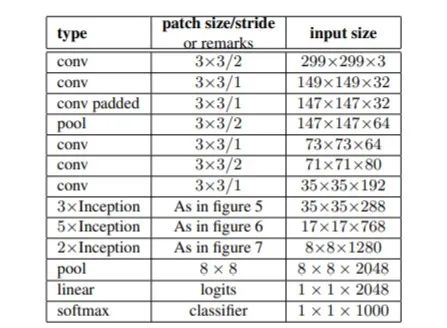
代码实现
import torch
from light_cnns import inception_v2
model = inception_v2()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Inception Net v3 整合了前面 Inception v2 的特点,除此之外,还包括以下5点改进:
不再直接使用max pooling层进行下采样,因为这样导致信息损失较大。一个可行方案是先进行卷积增加特征channel数量,然后进行pooling,但是计算量较大。所以作者设计了另外一种方案,即两个并行的分支,如下图所示,一个是pooling层,另外一个卷积层,最后将两者结果concat在一起。这样在使用较小的计算量情形下还可以避免瓶颈层,ShuffleNet中也采用了这种策略。
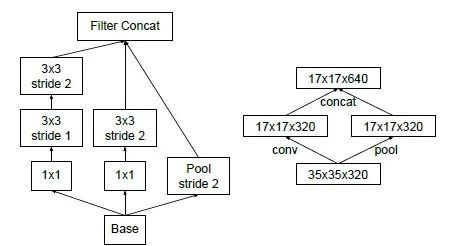
使用RMSProp 优化器;
Factorized 7x7 卷积;
辅助分类器使用了 BatchNorm;
使用了label smoothing;
代码实现
import torch
from light_cnns import inception_v3
model = inception_v3()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
论文地址:https://arxiv.org/abs/1602.07261
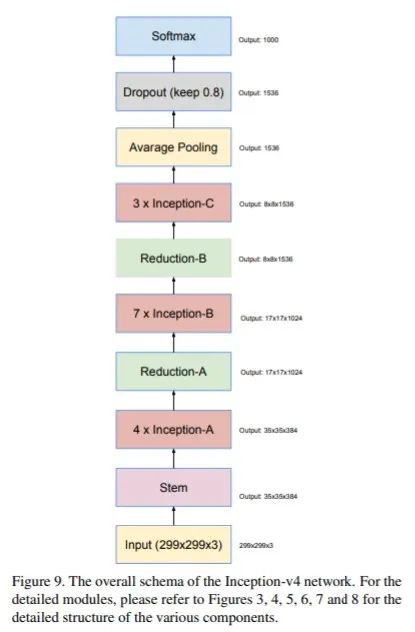
Inception v4主要的motivation则是 Inception 架构和残差连接结合起来会是什么效果?如何有效地结合残差连接来显著加速 Inception 的训练? 下面主要介绍一下Inception v4是如何来解决上述问题的。Inception v4主要提出了以下几种改进:
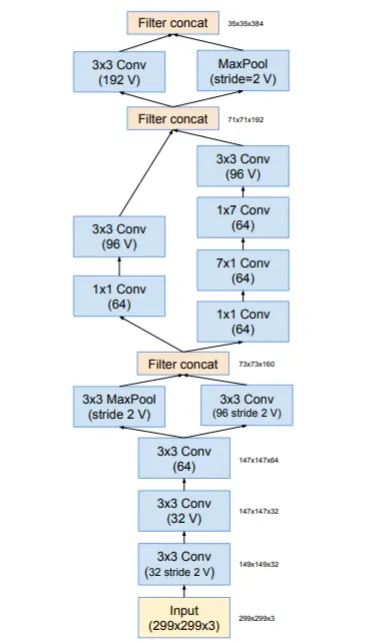
Inception v4 引入了一个新的stem模块,该模块放在Inception块之间执行。具体结构如下所示:
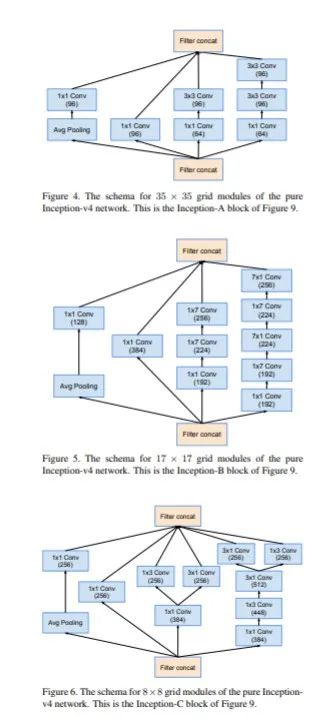
基于新的stem和Inception 模块,Inception v4重新提出了三种新的Inception模块分别称为 A、B 和 C
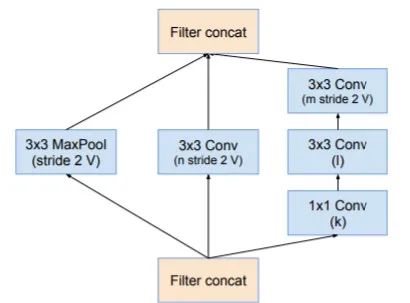
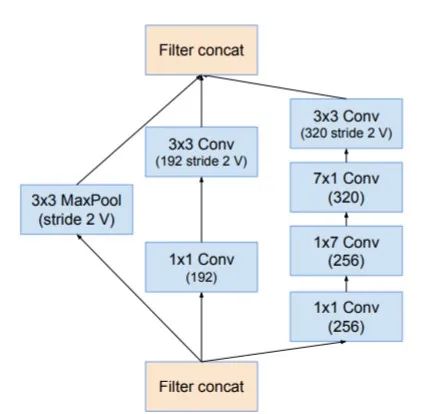
3.引入了专用的「缩减块」(reduction block),它被用于改变网格的宽度和高度。
网络结构如下所示:
代码实现
import torch
from light_cnns import inception_v4
model = inception_v4()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Xception: Deep Learning with Depthwise Separable Convolutions

论文地址:https://arxiv.org/abs/1610.02357
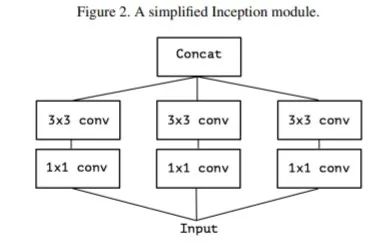
基于Inception的模块,一个新的架构Xception应运而生。Xception取义自Extreme Inception,即Xception是一种极端的Inception.它的提出主要是为了解耦通道相关性和空间相关性。由于Inception模块首先使用1 1的卷积核将特征图的各个通道映射到一个新的空间,在这一过程中学习通道间的相关性;再通过常规的3 3或5 5的卷积核进行卷积,以同时学习空间上的相关性和通道间的相关性。但此时,通道间的相关性和空间相关性仍旧没有完全分离。而Xception通过提出深度可分离卷积则成功实现了将学习空间相关性和学习通道间相关性的任务完全分离,具体操作如下:
将Inception模块简化,仅保留包含3*3的卷积的分支:
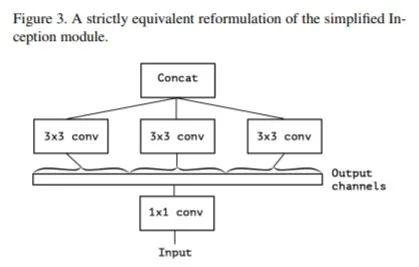
将所有11的卷积进行拼接.
进一步增加3 3的卷积的分支的数量,使它与1 1的卷积的输出通道数相等:
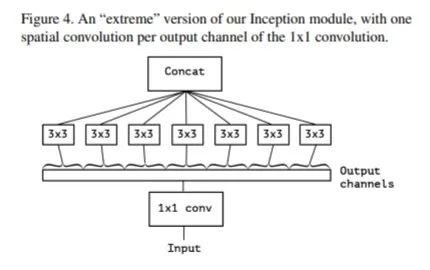
此时每个3 3的卷积即作用于仅包含一个通道的特征图上,作者称之为“极致的Inception(Extream Inception)”模块,这就是Xception的基本模块。事实上,调节每个3 3的卷积作用的特征图的通道数,即调节3 3的卷积的分支的数量与1 1的卷积的输出通道数的比例,可以实现一系列处于传统Inception模块和“极致的Inception”模块之间的状态。
网络结构如下所示:
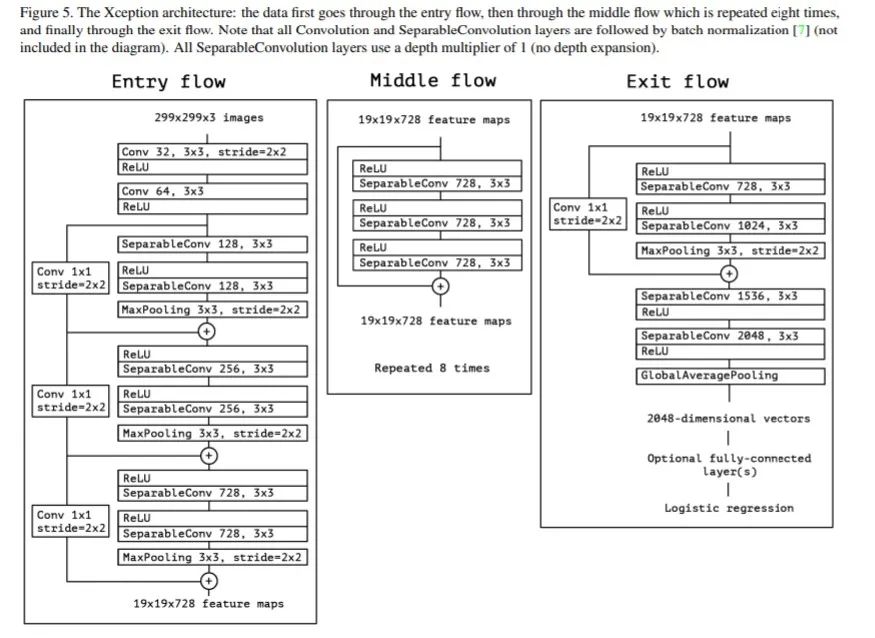
代码实现
import torch
from light_cnns import xception
model = xception()
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())Inception Convolution with Efficient Dilation Search(CVPR2021 oral)

论文地址:https://arxiv.org/abs/2012.13587
为了充分挖掘空洞卷积的潜力,本文主要结合一种基于统计优化的简单而高效(零成本)的空洞搜索算法(EDO,effective dilation search)提出了一种新的空洞卷积变体,即inception (dilated)卷积.具体做法如下:
构建一个更灵活的搜索空间,可以使得模型能够具备将ERFs拟合到不同数据集的能力。于是本文提出一种新的膨胀卷积突变体,即Inception卷积,它包含尽可能多的膨胀模式。在Inception卷积空间中,每个轴、每个通道和每个卷积层的膨胀都是独立定义的。Inception卷积提供了一个密集的ERF范围.
然后提出了一种简单而高效的膨胀优化算法(EDO)。在EDO中,超网络的每一层都是一个标准的卷积操作,其内核覆盖了所有可能的膨胀模式。EDO以一种非常简单的方式支持完全扩张域搜索空间进行高效的通道扩张优化。与基于传统搜索的方法相比,EDO的搜索代价几乎为零。
网络结构如下:
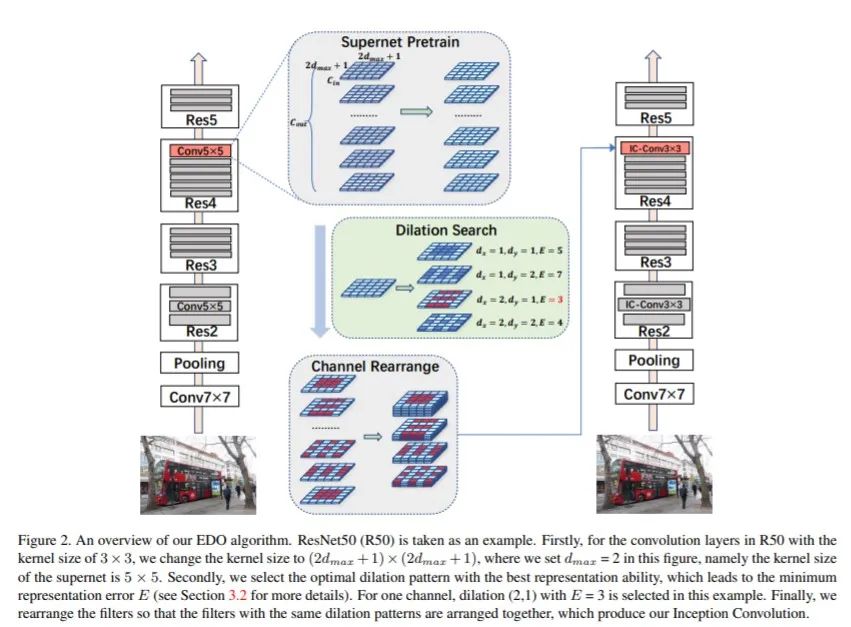
代码实现:
import torch
from light_cnns import ic_resnet50
patter = './pattern_zoo/detection/ic_resnet50_k9.json'
model = ic_resnet50(pattern_path=patter)
model.eval()
print(model)
input = torch.randn(1, 3, 224, 224)
y = model(input)
print(y.size())项目更多精彩内容,详见Github地址:https://github.com/murufeng/awesome_lightweight_networks
推荐阅读
欢迎大家加入DLer-计算机视觉&Transformer群!
大家好,这是计算机视觉&Transformer论文分享群里,群里会第一时间发布最新的Transformer前沿论文解读及交流分享会,主要设计方向有:图像分类、Transformer、目标检测、目标跟踪、点云与语义分割、GAN、超分辨率、视频超分、人脸检测与识别、动作行为与时空运动、模型压缩和量化剪枝、迁移学习、人体姿态估计等内容。
进群请备注:研究方向+学校/公司+昵称(如Transformer+上交+小明)

👆 长按识别,邀请您进群!















 1082
1082











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









