








GCN 网络系列
论文精讲部分
本专栏深入探讨图神经网络模型相关的学术论文,并通过实际代码实验来提高理解。读者可以根据个人需求选择感兴趣的内容进行学习。本章节详尽解读了“GCN模型”的原始论文,适合希望深入了解的读者。对于零基础或初学者,推荐阅读我编写的入门内容,它非常适合新手,点击这里查看易懂的GCN入门材料。在本章节中,大部分内容将直接引用原论文翻译,而对论文的理解和分析则以引用格式呈现,旨在清晰展示对当前研究主题的深入见解。考虑到相关资料相对稀缺,希望各位可以给个免费的点赞收藏。

😃如果您觉得内容有帮助,欢迎点赞、收藏,以及关注我们哦!👍
论文地址https://arxiv.org/pdf/1609.02907
0. 摘要
在阅读开始前提示下,如果阅读开始后你觉得看起来十分吃力,可以看下这个专栏下的针对于GCN的谱域频域精讲,这样才能很好的理解他说什么。好的咱们现在开始吧。
我们提出了一种基于图结构数据的半监督学习的可扩展方法,该方法基于高效的卷积神经网络变体直接操作图数据。我们通过图谱卷积的局部一阶近似来解释我们选择卷积架构的动机。我们的模型在图边数量上线性扩展,并学习隐藏层表示,这些表示编码了本地图结构和节点的特征。在一系列关于引用网络和知识图数据集的实验中,我们证明了我们的方法在显著程度上超越了相关方法。
首先说了下提出的网络模型,是一种针对于图结构数据的半监督学习方法,和CNN那种针对规则数据(欧几里得)的方法区别开来。但是其思想主要也是CNN一样的,聚合更新聚合更新,其次就是这种图卷积的由来主要是图谱理论下的一阶金丝,这里就需要大家看我的那个谱域图卷积的理解的博文了,主要就利用图结构更新每个节点的嵌入表示,然后实现的分类性能提升,剩下的就是常规操作,效果比较好。
1. 引言
我们研究图中节点(如文献)的分类问题(例如引用网络),其中仅有少部分节点的标签是可用的。
这里主要是引入问题的定义,在其他的论文中曾经阐述过这个问题,就是对一个网络中的节点进行分类,而这个数据就是引文网络数据集。基于图的半监督学习。所以文中大量讨论的方法就是对这个数据集中的节点进行分类,之所以是半监督就是引文仅仅在训练时候给标签了。
这一问题可归类为基于图的半监督学习。
下面坐着提到了几篇论文,我这里着重讲一下其想传达的意思,大家先看下原文:
其中通过某种明确的基于图的正则化形式(例如:Zhu 等人,2003 年;Zhou 等人,2004 年;Belkin 等人,2006 年;Weston 等人,2012 年),标签信息在图上进行平滑处理,比如在损失函数中使用图拉普拉斯正则项。
L
=
L
0
+
λ
L
reg
,
其中
L
reg
=
∑
i
,
j
A
i
j
∥
f
(
X
i
)
−
f
(
X
j
)
∥
2
=
f
(
X
)
T
Δ
f
(
X
)
.
L = L_0 + \lambda L_{\text{reg}}, \text{其中} L_{\text{reg}} = \sum_{i,j} A_{ij} \|f(X_i) - f(X_j)\|^2 = f(X)^T \Delta f(X).
L=L0+λLreg,其中Lreg=i,j∑Aij∥f(Xi)−f(Xj)∥2=f(X)TΔf(X).
这里,
L
0
L_0
L0表示图中标记部分的监督损失,
f
(
⋅
)
f(\cdot)
f(⋅)可以是类似神经网络的可微分函数,
λ
\lambda
λ是权重因子,而
X
X
X是节点特征向量
X
i
X_i
Xi的矩阵。
Δ
=
D
−
A
\Delta = D - A
Δ=D−A表示非归一化图拉普拉斯矩阵,它是无向图
G
=
(
V
,
E
)
G = (V, E)
G=(V,E)的图拉普拉斯,其中
N
N
N个节点
v
i
∈
V
v_i \in V
vi∈V,边
(
v
i
,
v
j
)
∈
E
(v_i, v_j) \in E
(vi,vj)∈E,邻接矩阵
A
∈
R
N
×
N
A \in \mathbb{R}^{N \times N}
A∈RN×N(二元或加权),度矩阵
D
i
i
=
∑
j
A
i
j
D_{ii} = \sum_j A_{ij}
Dii=∑jAij。方程(1)的公式基于这样的假设:图中相连的节点可能具有相同的标签。然而,这种假设可能限制了模型的表现能力,因为图边不一定需要编码节点相似性,而可以包含额外的信息。
首先,让我们详细审视下这个公式:
L = L 0 + λ L reg , 其中 L reg = ∑ i , j A i j ∥ f ( X i ) − f ( X j ) ∥ 2 = f ( X ) T Δ f ( X ) . L = L_0 + \lambda L_{\text{reg}}, \text{其中} L_{\text{reg}} = \sum_{i,j} A_{ij} \|f(X_i) - f(X_j)\|^2 = f(X)^T \Delta f(X). L=L0+λLreg,其中Lreg=i,j∑Aij∥f(Xi)−f(Xj)∥2=f(X)TΔf(X).
在这里, L 0 L_0 L0代表常规的损失项,而文中提到的图拉普拉斯正则化传达的思考与假设非常关键。这种正则化操作在图领域是一种常见的做法,通过拉普拉斯矩阵施加约束来增强模型对图结构的理解和适应。
直接考察公式中的 A i j A_{ij} Aij:这个元素非0即1,用以判断节点j是否是节点i的邻居。然后,模型通过一个函数处理中心节点和邻节点的特征提取,计算二者的欧几里得距离(二范数)。这一计算得出的值会被用作模型的一个额外损失项——例如,在采用交叉熵损失的地方添加这个正则化损失。
从直观上理解,如果中心节点i与其邻居节点的特征向量相近,那么这个正则化项得出的数值就较小。模型在训练过程中的梯度更新也会优先考虑减少这一正则化损失,从而鼓励图中相邻节点的特征表示趋于一致。
因此,作者的基本假设是:图中相邻的节点在特征表达上应当接近,这也隐含了一个更广泛的预设,即相邻节点的标签也应该相似。这种假设是图神经网络设计中的核心原则之一,关注于如何利用图的拓扑结构来改善学习效果和预测性能。这也就是作者要说的目的。
这种方法是图神经网络中常用的一种技术,它利用图的结构属性来帮助提高学习算法的性能,特别是在标签稀缺的情况下。
图拉普拉斯正则化深入解析
拉普拉斯矩阵 ( Δ \Delta Δ) 是图论中的一个核心概念,它表征了图的结构。具体到公式中:
- Δ = D − A \Delta = D - A Δ=D−A,其中 A A A是邻接矩阵, D D D是度矩阵(对角线上的元素是各个节点的度,即相连的边的数目)。
- 正则化项 L reg L_{\text{reg}} Lreg的作用是确保连通的节点在特征空间中尽可能接近。这基于以下直观理解:
- 如果节点 i i i和节点 j j j在图中是相邻的(即 A i j = 1 A_{ij} = 1 Aij=1),那么我们希望它们的特征向量 f ( X i ) f(X_i) f(Xi)和 f ( X j ) f(X_j) f(Xj)相似。
- 这种相似性通过计算 f ( X i ) f(X_i) f(Xi)和 f ( X j ) f(X_j) f(Xj)的欧几里得距离的平方(即二范数的平方)来度量,这就是为什么 L reg L_{\text{reg}} Lreg包含了 ∥ f ( X i ) − f ( X j ) ∥ 2 \|f(X_i) - f(X_j)\|^2 ∥f(Xi)−f(Xj)∥2。
通过这种方式,整体损失 L L L不仅包含了常规的监督学习损失 L 0 L_0 L0,还额外加上了由图结构驱动的正则化部分,这有助于模型利用未标记节点的信息,以便学到更加泛化和鲁棒的节点表示。
因此,这个方法背后的核心思想是利用图的结构信息来指导学习过程,使模型在损失最小化的同时,保持图结构的连续性和局部一致性,这是图神经网络中非常关键的一个特性。
在这项工作中,我们直接使用神经网络模型 f ( X , A ) f(X, A) f(X,A) 对图结构进行编码,并以所有带标签节点的监督目标 L 0 L_0 L0 进行训练,从而避免在损失函数中使用显式的基于图的正则化。将 f ( ⋅ ) f(\cdot) f(⋅) 基于图的邻接矩阵条件化,将允许模型从监督损失 L 0 L_0 L0 分配梯度信息,并将使其能够学习带标签和不带标签节点的表示。
这里直接阐述自己的工作,其设计的网络是直接利用了图结构进行编码 f ( X , A ) f(X, A) f(X,A),不是传统 f ( X ) f(X) f(X)直接分类.怎么理解呢??
在传统的神经网络中,模型通过函数 f ( X ) f(X) f(X)对特征集 X X X 进行处理,这个过程主要依赖于输入数据的特征信息,并不考虑数据之间可能存在的关系或结构。对于独立同分布的数据,这种方法非常有效。而前人做了什么呢就是,仅仅是利用了上文聊的这个拉普拉斯做了一个约束项目这样的假设去提升网络的性能。
然而在图数据上,节点往往不是独立的,节点间的连接关系(即图结构)包含了丰富的额外信息,这对于任务(如节点分类)至关重要。因此,在图神经网络中,函数 f ( X , A ) f(X, A) f(X,A)不仅处理节点的特征 X X X,还要考虑图的结构信息 A A A(邻接矩阵)。这种方法使得网络能够直接从图结构中学习和提取信息,使得节点的表示能反映其在图中的位置和邻域结构。这是图神经网络与传统神经网络的一个关键区别。
在GCN中,图结构 A A A 不仅是一个简单的约束项,而是作为数据的一部分直接输入到网络中,与节点特征 X X X一起决定每个节点的输出。这种结合使得GCN在执行任务如节点分类时,能够考虑到每个节点的局部网络环境,从而允许模型捕获和利用节点间的依赖关系。
我们的贡献有两个方面。首先,我们介绍了一个简单且行为良好的逐层传播规则,用于直接在图上操作的神经网络模型,并展示如何从频谱图卷积的一阶近似推导出来(Hammond等人,2011)。其次,我们演示了如何使用这种基于图的神经网络模型,用于图中节点的快速和可扩展的半监督分类。在多个数据集上的实验表明,我们的模型在分类准确性和效率(以墙钟时间衡量)方面都优于当前半监督学习的最先进方法。还是谦虚了,提出了一种新思路
2. 快速近似图卷积
在本节中,我们为一种特定的基于图的神经网络模型 f ( X , A ) f(X, A) f(X,A) 提供理论动机,该模型将在本文的余下部分中使用。我们在此考虑一个多层的图卷积网络(GCN),其按层传播的规则如下:
H ( l + 1 ) = σ ( D ~ − 1 2 A ~ D ~ − 1 2 H ( l ) W ( l ) ) 。 H^{(l+1)} = \sigma\left(\widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right)。 H(l+1)=σ(D −21A D −21H(l)W(l))。
这里, A ~ = A + I N \widetilde{A} = A + I_N A =A+IN 是无向图 G G G 的邻接矩阵,其中添加了自连接。 I N I_N IN 是单位矩阵, D ~ i i = ∑ j A ~ i j \widetilde{D}_{ii} = \sum_{j} \widetilde{A}_{ij} D ii=∑jA ij,而 W ( l ) W^{(l)} W(l) 是每层特定的可训练权重矩阵。 σ ( ⋅ ) \sigma(\cdot) σ(⋅) 表示激活函数,例如 ReLU 函数 ReLU ( ⋅ ) = max ( 0 , ⋅ ) \text{ReLU}(\cdot) = \max(0, \cdot) ReLU(⋅)=max(0,⋅)。 H ( l ) ∈ R N × D H^{(l)} \in \mathbb{R}^{N \times D} H(l)∈RN×D 是第 l l l 层的激活矩阵; H ( 0 ) = X H^{(0)} = X H(0)=X。在接下来的部分,我们将展示这种传播规则的形式是如何通过对图上局部化谱滤波器的一阶近似(由 Hammond 等人于2011年以及 Defferrard 等人于2016年提出)所启发。
这个直接明牌,这就是论文的所采用的卷积方式。H表示节点的嵌入表示W就是权重矩阵,做乘积就是在做特征提取操作,而度矩阵则是在进行归一化操作,和A矩阵进行乘积做邻居信息的聚合操。在此使用度矩阵进行归一化则是为了消除明星节点的影响,具体的这部分可以参考作我GCN详解的理解博文。最终激活更新全部节点的嵌入表示。
论文首先就对其基础的核心思想直接阐述,后面则是阐述其思想的由来。下面看不懂的需要参考我针对谱域图卷积的详解才能看懂,这个确实是比较难。
2.1和2.2的内容其具体涉及到的知识点太多了,我这里仅对其进行翻译,感兴趣的同学去看我对谱域图神经网络的博文,为什么这个公式的形态是这样的。从傅立叶到卷积操作。明确的着部分的同学可以直接看第三小节
2.1 频谱图卷积
我们考虑定义在图上的频谱卷积,即在傅里叶域中将信号 x ∈ R N x \in \mathbb{R}^N x∈RN(每个节点一个标量)与由参数 θ ∈ R N \theta \in \mathbb{R}^N θ∈RN 参数化的滤波器 g θ = diag ( θ ) g_\theta = \text{diag}(\theta) gθ=diag(θ) 相乘,即:
g θ ∗ x = U g θ U ⊤ x ( 3 ) g_\theta \ast x = U g_\theta U^\top x \quad (3) gθ∗x=UgθU⊤x(3)
其中, U U U 是归一化图拉普拉斯算子 L = I N − D − 1 2 A D − 1 2 = U Λ U ⊤ L = I_N - D^{-\frac{1}{2}} A D^{-\frac{1}{2}} = U \Lambda U^\top L=IN−D−21AD−21=UΛU⊤ 的特征向量矩阵, Λ \Lambda Λ 是其特征值的对角矩阵, U ⊤ x U^\top x U⊤x 是 x x x 的图傅里叶变换。我们可以将 g θ g_\theta gθ 视为 L L L 的特征值的函数,即 g θ ( Λ ) g_\theta(\Lambda) gθ(Λ)。评估方程 (3) 计算成本高昂,因为与特征向量矩阵 U U U 的乘法复杂度为 O ( N 2 ) O(N^2) O(N2)。此外,首次计算 L L L 的特征分解对于大型图可能代价过高。为了绕过这个问题,Hammond 等人(2011)建议可以通过 Chebyshev 多项式 T k ( x ) T_k(x) Tk(x) 至第 K K K 阶的截断展开来较好地近似 g θ ( Λ ) g_\theta(\Lambda) gθ(Λ):
g θ ′ ( Λ ) ≈ ∑ k = 0 K θ k ′ T k ( Λ ~ ) ( 4 ) g_{\theta'}(\Lambda) \approx \sum_{k=0}^{K} \theta'_k T_k(\widetilde{\Lambda}) \quad (4) gθ′(Λ)≈k=0∑Kθk′Tk(Λ )(4)
其中, Λ ~ = 2 λ max Λ − I N \widetilde{\Lambda} = \frac{2}{\lambda_{\text{max}}} \Lambda - I_N Λ =λmax2Λ−IN, λ max \lambda_{\text{max}} λmax 表示 L L L 的最大特征值。 θ ′ ∈ R K \theta' \in \mathbb{R}^K θ′∈RK 现在是 Chebyshev 系数向量。Chebyshev 多项式递归定义为 T k ( x ) = 2 x T k − 1 ( x ) − T k − 2 ( x ) T_k(x) = 2xT_{k-1}(x) - T_{k-2}(x) Tk(x)=2xTk−1(x)−Tk−2(x),其中 T 0 ( x ) = 1 T_0(x) = 1 T0(x)=1 和 T 1 ( x ) = x T_1(x) = x T1(x)=x。详细讨论这种近似方法可参考 Hammond 等人(2011)的研究。
回到我们对信号 x x x 与滤波器 g θ ′ g_{\theta'} gθ′ 的卷积定义,我们现在有:
g θ ′ ∗ x ≈ ∑ k = 0 K θ k ′ T k ( L ~ ) x ( 5 ) g_{\theta'} \ast x \approx \sum_{k=0}^{K} \theta'_k T_k(\widetilde{L}) x \quad (5) gθ′∗x≈k=0∑Kθk′Tk(L )x(5)
其中, L ~ = 2 λ max L − I N \widetilde{L} = \frac{2}{\lambda_{\text{max}}} L - I_N L =λmax2L−IN;可以通过验证 ( U Λ U ⊤ ) k = U Λ k U ⊤ (U\Lambda U^\top)^k = U\Lambda^kU^\top (UΛU⊤)k=UΛkU⊤ 来轻易证明这一点。注意,现在这个表达式是 K K K-局部化的,因为它是拉普拉斯算子的 K K K 阶多项式,即它只依赖于最多距中心节点 K K K 步远( K K K 阶邻域)的节点。评估方程 (5) 的复杂度是 O ( ∣ E ∣ ) O(|E|) O(∣E∣),即边数的线性。Defferrard 等人(2016)利用这种 K K K-局部化卷积定义了图上的卷积神经网络。
2.2 层级线性模型
基于图卷积的神经网络模型因此可以通过堆叠多个形式为方程 (5) 的卷积层来构建,每个层之后紧跟一个逐点非线性操作。现在,假设我们将层级卷积操作限制在 K = 1 K = 1 K=1(参见方程 5),即一个关于 L L L 线性的函数,因而是图拉普拉斯谱上的线性函数。通过这种方式,我们仍然可以通过堆叠多个这样的层来恢复丰富的卷积滤波器函数类别,但我们不限于例如 Chebyshev 多项式给出的显式参数化。我们直观上预期,这样的模型可以缓解在具有非常宽的节点度分布的图上,如社交网络、引文网络、知识图谱以及许多其他现实世界图数据集上的局部邻域结构过拟合问题。此外,对于固定的计算预算,这种层级线性公式允许我们构建更深的模型,这种做法在许多领域已知可以提高建模能力(He 等人,2016)。
在这种 GCN 的线性公式中,我们进一步近似 λ max ≈ 2 \lambda_{\text{max}} \approx 2 λmax≈2,因为我们可以预期神经网络参数会在训练期间适应这种规模变化。在这些近似下,方程 (5) 简化为:
g θ ′ ∗ x ≈ θ 0 ′ x + θ 1 ′ ( L − I N ) x = θ 0 ′ x − θ 1 ′ D − 1 2 A D − 1 2 x ( 6 ) g_{\theta'} \ast x \approx \theta'_0 x + \theta'_1 (L - I_N) x = \theta'_0 x - \theta'_1 D^{-\frac{1}{2}} A D^{-\frac{1}{2}} x \quad (6) gθ′∗x≈θ0′x+θ1′(L−IN)x=θ0′x−θ1′D−21AD−21x(6)
其中有两个自由参数 θ 0 ′ \theta'_0 θ0′ 和 θ 1 ′ \theta'_1 θ1′。滤波器参数可以在整个图上共享。这种形式的滤波器的连续应用实际上是在对节点的第 k k k 阶邻域进行卷积,其中 k k k 是神经网络模型中连续滤波操作或卷积层的数量。
在实践中,进一步限制参数数量可能有益于解决过拟合问题,并最小化每层的操作数量(如矩阵乘法)。这给我们留下了如下表达式:
g θ ∗ x ≈ θ ( I N + D − 1 2 A D − 1 2 ) x ( 7 ) g_{\theta} \ast x \approx \theta (I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}}) x \quad (7) gθ∗x≈θ(IN+D−21AD−21)x(7)
其中一个单一参数 θ = θ 0 ′ = − θ 1 ′ \theta = \theta'_0 = -\theta'_1 θ=θ0′=−θ1′。现在 I N + D − 1 2 A D − 1 2 I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} IN+D−21AD−21 具有范围 [0, 2] 的特征值。当在深层神经网络模型中使用时,重复应用这个算子可能导致数值不稳定和梯度爆炸/消失。为了缓解这个问题,我们引入如下重归一化技巧: I N + D − 1 2 A D − 1 2 → D ~ − 1 2 A ~ D ~ − 1 2 I_N +D^{-\frac{1}{2}} A D^{-\frac{1}{2}} \rightarrow \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} IN+D−21AD−21→D −21A D −21,其中 A ~ = A + I N \widetilde{A} = A + I_N A =A+IN,且 D ~ i i = ∑ j A ~ i j \widetilde{D}_{ii} = \sum_j \widetilde{A}_{ij} D ii=∑jA ij。
我们可以将这个定义推广到具有 C C C 输入通道(即每个节点一个 C C C-维特征向量)和 F F F 个滤波器或特征图的信号 X ∈ R N × C X \in \mathbb{R}^{N \times C} X∈RN×C 如下:
Z = D ~ − 1 2 A ~ D ~ − 1 2 X Θ ( 8 ) Z = \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} X \Theta \quad (8) Z=D −21A D −21XΘ(8)
其中 Θ ∈ R C × F \Theta \in \mathbb{R}^{C \times F} Θ∈RC×F 现在是滤波器参数的矩阵,而 Z ∈ R N × F Z \in \mathbb{R}^{N \times F} Z∈RN×F 是卷积信号矩阵。这种过滤操作的复杂度为 O ( ∣ E ∣ F C ) O(|E|F C) O(∣E∣FC),因为 A X AX AX 可以作为稀疏矩阵与密集矩阵的乘积高效实现。
如果抛开上面的谱图啥的下面的内容还是很简单的
3. 半监督节点分类
在前文中,我们引入了一个简单而灵活的模型 f ( X , A ) f(X, A) f(X,A),用于在图上有效地传播信息。
浅浅的回忆下之前聊的 f ( X , A ) f(X, A) f(X,A) 和 f ( X ) f(X) f(X) 的问题。现在又回到这个问题上。
现在,我们可以回到半监督节点分类的问题上来。如引言部分所述,通过将我们的模型 f ( X , A ) f(X, A) f(X,A) 同时依赖于数据 X X X 和邻接矩阵 A A A 的基础图结构,
本文涉及的模型时有两种输入一种是 X X X节点的特征,一种是用于表示图结果的邻接矩阵 A A A
我们可以放宽图基半监督学习中通常做出的一些假设。
这句话的意思就是不再使用那个拉普拉斯约束了,因为其确实还是太主观了。在实际的数据集下 这种假设还是太绝对了。下面说了删除这个约束后模型性能很给力。
我们期待在邻接矩阵包含数据 X X X 中不存在的信息的情况下,这种设置将特别有力,例如在引文网络中文件之间的引用链接或在知识图谱中的关系。整个模型——一个用于半监督学习的多层 GCN,如图 1 中示意性地展示。
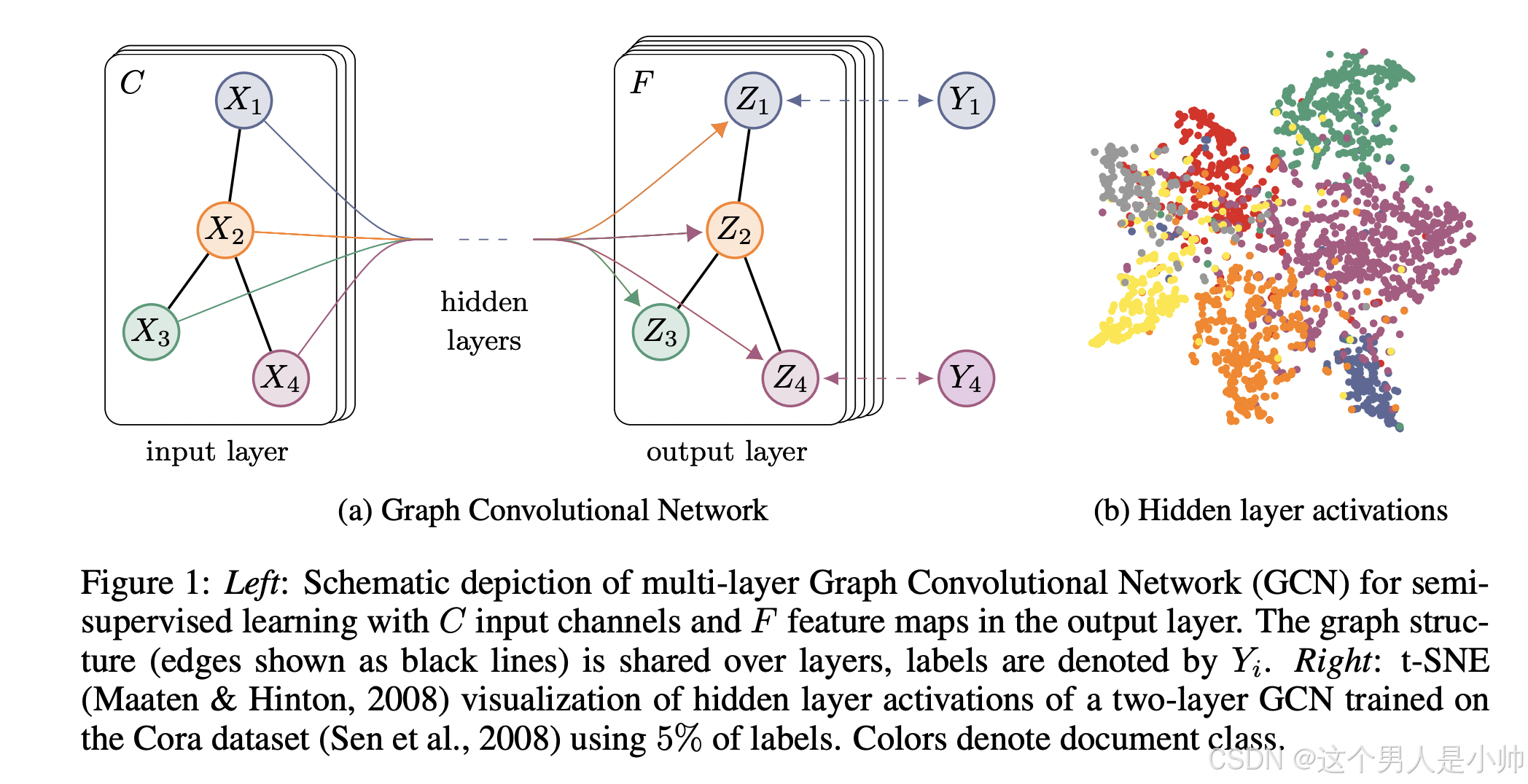
上图对初学者来说很难看懂,图卷积网络(GCN)的视觉表示与传统卷积神经网络(CNN)的视觉表示混合在一起可能会造成一定的困惑。让我们来深入理解并区分这两种网络在视觉表示和功能上的差异:
传统 CNN 的特征图
在传统的 CNN
中,输入通常是图像,这些图像在物理上由三个颜色通道(RGB)组成,对应于三张特征图。卷积操作通过多个卷积核在这些输入特征图上滑动,每个卷积核关注并提取输入图像的不同特征。因此,CNN
中的多张特征图可以看作是同一图像的不同表示,每个卷积核提取图像的不同视角或特征,如边缘、纹理等。GCN 的特征图
GCN 处理的是图数据,这类数据的结构本质上是由节点和边组成的网络,这与像素构成的图像有本质的不同。因此,GCN 的“特征图”与 CNN
的特征图在概念上有所不同:
- 节点特征: 在GCN中,每个节点都可以有多个特征,这些特征构成了一个特征向量。例如,一个社交网络中的个人节点可能包含如年龄、位置、职业等信息。
- 特征图解释: 在GCN中,一个“特征图”并不是指一个单独的视觉图像,而是指图中所有节点上某个特定特征的集合。如果一个节点的特征向量是十维的,那么在GCN中就可以看作是有十个“特征图”,每个“特征图”代表所有节点在该维度上的特征值。
- 卷积操作: 在GCN中,卷积操作涉及到的不是传统意义上的空间上的滤波器移动,而是在图的邻接结构上应用变换。这个变换基于节点的邻接关系,利用邻接矩阵和特征向量更新节点的特征。每层的输出依然保持图的结构,但特征向量的维度可能改变,这取决于卷积层的输出维度。
因此,左图每个节点代表数据集中的一个实体(如文档、用户等),边(黑线)展示了节点之间的连接,这些连接可能代表实体间的关系(如引文、朋友关系等)。每次聚合节点的特征都会更新。但是连接关系还是一样,仅仅是特征维度发生了变化。图中之所以这么画是因为收到了CNN中画图的启发,所以看起来有点奇怪。C的意思就是C个通道,换言之就是一个节点的特征维度是C不断的卷积输出特征通道被设定成了F。最终取出每一个节点的特征进行分类预测Y==右侧则是数据特征可视化的记过,表明成功将相同类别的数据映射到了同样的簇下,颜色相同类别一致用不同颜色表示不同的文档类别,通过颜色的聚集情况可以观察到模型对不同类别的文档进行区分的能力
。
有点绕,不理解的同学评论下我后续会修改,如果能听懂就更好了
3.1 示例
在接下来的内容中,我们考虑一个用于图上半监督节点分类的两层 GCN,该图具有对称的邻接矩阵 A A A(二元或加权)。
真实的GCN实际上就是两层,增加层数会导致性能下架很厉害。对称的邻接矩阵 A A A。就是无向图
我们首先在预处理步骤中计算 A ^ = D ~ − 1 2 A ~ D ~ − 1 2 \hat{A} = \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} A^=D −21A D −21。然后我们的前向模型采用下列简单形式:
Z = f ( X , A ) = softmax ( A ^ ReLU ( A X W ( 0 ) ) W ( 1 ) ) . ( 9 ) Z = f(X, A) = \text{softmax} \left( \hat{A} \text{ReLU} \left( A X W^{(0)} \right) W^{(1)} \right). \quad (9) Z=f(X,A)=softmax(A^ReLU(AXW(0))W(1)).(9)
这个就是GCN的卷积操作了很好理解。AXW,X是特征矩阵W就是神经网络的全连接权重,对全部节点进行特征选择, 然后在采用和邻接矩阵进行乘积的操作实现了特征的聚合。AX操作不理解的同学手动的推理下。仅仅是矩阵乘法简洁易懂。然后RWLU激活一下。在此重复下这个操作,进入到第二层的卷积操作将激活的结果进行W特征选择,然后使用一个带帽子的A进行聚合,这里还聚合了自身的特征。最后softmax输出概率。
这里,
W
(
0
)
∈
R
C
×
H
W^{(0)} \in \mathbb{R}^{C \times H}
W(0)∈RC×H 是输入到隐藏层的权重矩阵,用于一个具有
H
H
H 个特征图的隐藏层。
W
(
1
)
∈
R
H
×
F
W^{(1)} \in \mathbb{R}^{H \times F}
W(1)∈RH×F 是从隐藏层到输出层的权重矩阵。softmax 激活函数定义为,
softmax ( x i ) = exp ( x i ) ∑ i exp ( x i ) , \text{softmax}(x_i) = \frac{\exp(x_i)}{\sum_i \exp(x_i)}, softmax(xi)=∑iexp(xi)exp(xi),
逐行应用。对于半监督多类分类,我们然后评估所有已标记示例上的交叉熵误差:
L = − ∑ l ∈ Y L ∑ f = 1 F y l f ln z l f , ( 10 ) L = -\sum_{l \in Y_L} \sum_{f=1}^F y_{lf} \ln z_{lf}, \quad (10) L=−l∈YL∑f=1∑Fylflnzlf,(10)
这个还是很常见的交叉熵损失,多分类用的比较多。不解释这个了很常见各位搜集资料很容易。
其中 Y L Y_L YL 是拥有标签的节点索引集。
神经网络权重 W ( 0 ) W^{(0)} W(0) 和 W ( 1 ) W^{(1)} W(1) 通过梯度下降法进行训练。在这项工作中,我们采用了使用完整数据集的批量梯度下降法进行每一次训练迭代,只要数据集适合内存就是一种可行的选择。使用 A A A 的稀疏表示,内存需求为 O ( ∣ E ∣ ) O(|E|) O(∣E∣),即与边数成线性关系。训练过程中的随机性通过 dropout(Srivastava 等人,2014)引入。我们将留下使用小批量随机梯度下降进行内存高效扩展的未来工作。
3.2 实现
在实践中,我们使用 TensorFlow(Abadi 等人,2015)进行基于 GPU 的高效实现,通过稀疏-密集矩阵乘法实现方程 (9)。评估方程 (9) 的计算复杂度然后为 O ( ∣ E ∣ C H F ) O(|E|CHF) O(∣E∣CHF),即与图边数成线性关系。
官方给出的版本是tf但是现阶段用TF用的比较少,用的比较多的就是torch现阶段,我后面已经讲解忘了代码,各位一会可以看看,成熟的包有pyg和dgl各位酌情学习,直接调用,不用自己熬造轮子。
下面就是相关工作的讲解,但是看起来这个好像是3-4节的工作搞反过来了。应该是先第四节再第三节,当然不排除人家就是工作比较好想这么设计。
4. 相关工作
文献综述,论文太老了,各位酌情学习。可直接看实验部分
我们的模型从基于图的半监督学习领域和对图操作的神经网络的最新研究中汲取灵感。以下是这两个领域相关工作的简要概述。
4.1 基于图的半监督学习
近年来,使用图表示进行半监督学习的方法被广泛提出,这些方法主要分为两大类:一类是使用某种形式的显式图拉普拉斯正则化的方法,另一类是基于图嵌入的方法。显式图拉普拉斯正则化的著名例子包括标签传播(Zhu 等人,2003),流形正则化(Belkin 等人,2006)以及深度半监督嵌入(Weston 等人,2012)。最近,研究焦点转向了学习图嵌入的方法,这些方法受到skip-gram模型(Mikolov 等人,2013)的启发。DeepWalk(Perozzi 等人,2014)通过预测从图上的随机游走中采样的节点的局部邻域来学习嵌入。LINE(Tang 等人,2015)和 node2vec(Grover & Leskovec,2016)通过更复杂的随机游走或广度优先搜索方案扩展了 DeepWalk。然而,对于所有这些方法,一个包括随机游走生成和半监督训练的多阶段流程是必需的,每个步骤都需要单独优化。Planetoid(Yang 等人,2016)通过在学习嵌入的过程中注入标签信息来减轻这一问题。
4.2 图上的神经网络
早在Gori等人(2005);Scarselli等人(2009)的工作中,图上的神经网络已被引入作为一种形式的循环神经网络。它们的框架要求重复应用收缩映射作为传播函数,直到节点表示达到稳定的固定点。这一限制后来在 Li 等人(2016)的研究中得以缓解,他们将循环神经网络训练的现代实践引入到原始的图神经网络框架中。Duvenaud 等人(2015)在图上引入了类似卷积的传播规则和图级分类的方法。他们的方法需要学习特定于节点度的权重矩阵,这不适用于节点度分布广泛的大型图。相反,我们的模型在每层使用单一的权重矩阵,并通过适当规范化邻接矩阵来处理不同节点度(参见第3.1节)。
近期,Atwood & Towsley(2016)引入了一种基于图的神经网络进行节点分类的相关方法。他们报道了 O ( N 2 ) O(N^2) O(N2) 的复杂度,这限制了可能的应用范围。在一个不同但相关的模型中,Niepert 等人(2016)将图局部转换为序列,这些序列被送入传统的1D卷积神经网络,这需要在预处理步骤中定义一个节点排序。
我们的方法基于 Bruna 等人(2014)引入的谱图卷积神经网络,随后由 Defferrard 等人(2016)通过快速局部卷积进行了扩展。与这些工作不同,我们在这里考虑了在规模更大的网络中进行转导节点分类的任务。我们展示,在这种设置中,可以引入一些简化(参见第2.2节),改进了 Bruna 等人(2014)和 Defferrard 等人(2016)原始框架在大规模网络中的可扩展性和分类性能。
实验部分我使用黄色高亮提示大家注意哪些细节参数的设定
5. 实验
我们在一系列实验中测试了我们的模型:在引文网络中半监督文档分类,在从知识图谱中提取的二分图上进行半监督实体分类,各种图传播模型的评估,以及在随机图上的运行时间分析。
5.1 数据集
我们紧密遵循 Yang 等人(2016)的实验设置。数据集统计信息总结在表 1 中。在引文网络数据集——Citeseer、Cora 和 Pubmed(Sen 等人,2008)中, 节点是文档,边是引用链接。
数据集直接用的yang做的数据集进行的实验,tf版本使用的和torch版本用不会死一个数据集
标签率表示用于训练的已标记节点数除以每个数据集中节点总数的比例。NELL(Carlson 等人,2010;Yang 等人,2016)是从知识图谱中提取的二分图数据集,包括 55,864 个关系节点和 9,891 个实体节点。
表 1: Yang 等人(2016)报道的数据集统计
| 数据集类型 | 节点数 | 边数 | 类别数 | 特征数 | 标签率 |
|---|---|---|---|---|---|
| Citeseer | 3,327 | 4,732 | 6 | 3,703 | 0.036 |
| Cora | 2,708 | 5,429 | 7 | 1,433 | 0.052 |
| Pubmed | 19,717 | 44,338 | 3 | 500 | 0.003 |
| NELL | 65,755 | 266,144 | 210 | 5,414 | 0.001 |
5.2 实验设置
除非另有说明,我们按照第 3.1 节描述训练一个双层 GCN,并在包含 1,000 个已标记样本的测试集上评估预测准确性。我们在附录 B 中使用更深的模型进行额外的实验,这些模型最多有 10 层。我们选择与 Yang 等人(2016)相同的数据集拆分,并为超参数优化额外设置了一个包含 500 个已标记样本的验证集(涵盖所有层的 dropout 率、第一个 GCN 层的 L2 正则化因子和隐藏单元数)。我们在训练中不使用验证集标签。
对于引文网络数据集,我们仅在 Cora 上优化超参数,并将同一套参数用于 Citeseer 和 Pubmed。我们使用 Adam(Kingma & Ba, 2015)以== 0.01== 的学习率对所有模型训练最多 200 个周期(训练迭代),并使用== 10 的窗口大小进行早停== ,即如果验证损失在连续 10 个周期内没有下降,则停止训练。我们使用 Glorot & Bengio(2010)描述的方式初始化权重,并相应地(按行)规范化输入特征向量。在随机图数据集上,我们使用 32 个单位的隐藏层大小,并省略正则化(即不使用 dropout 也不使用 L2 正则化)。
这里要说下,如果你有早停机制你使用验证集可以,没早停其实没啥大用验证集。早停通过验证集损失进行要不要停止训练,如果你没早停机制,验证和测试类别分布差不多个人觉得没必要。并且其torch版本就没早停机制。
5.3 基准
我们与 Yang 等人(2016)使用的相同基准方法进行比较,即标签传播(LP)(Zhu 等人,2003),半监督嵌入(SemiEmb)(Weston 等人,2012),流形正则化(ManiReg)(Belkin 等人,2006)和基于 skip-gram 的图嵌入(DeepWalk)(Perozzi 等人,2014)。我们省略了 TSVM(Joachims,1999),因为它无法扩展到我们其中一个数据集中的大量类别。
我们进一步与 Lu & Getoor(2003)提出的迭代分类算法(ICA)进行比较,配合两个逻辑回归分类器,一个仅用于本地节点特征,另一个用于使用本地特征和聚合操作符的关系分类,正如 Sen 等人(2008)所描述的那样。我们首先使用所有标记的训练集节点训练本地分类器,然后使用它来引导未标记节点的类别标签以训练关系分类器。我们在所有未标记的节点上用随机节点顺序运行迭代分类(关系分类器)共 10 次迭代(使用本地分类器引导)。L2正则化参数和聚合操作符(计数与比例,参见 Sen 等人(2008))是基于每个数据集的验证集表现分别选择的。
最后,我们与 Planetoid(Yang 等人,2016)进行比较,在这里我们始终选择他们表现最佳的模型变体(传导性 vs. 归纳性)作为基准。
6. 结果
6.1 半监督节点分类
结果总结在表2中。报道的数字表示分类准确率的百分比。
对于 ICA,我们报告了100次具有随机节点顺序的运行的平均准确率。
ICA是自己测试的
其他所有基线方法的结果摘自 Planetoid 论文(Yang 等人,2016)。Planetoid* 表示他们论文中提出的各种模型中对应数据集的最佳模型。
表2: 分类准确率(百分比)结果总结
| 方法 | Citeseer | Cora | Pubmed | NELL |
|---|---|---|---|---|
| ManiReg [3] | 60.1 | 59.5 | 70.7 | 21.8 |
| SemiEmb [28] | 59.6 | 59.0 | 71.1 | 26.7 |
| LP [32] | 45.3 | 68.0 | 63.0 | 26.5 |
| DeepWalk [22] | 43.2 | 67.2 | 65.3 | 58.1 |
| ICA [18] | 69.1 | 75.1 | 73.9 | 23.1 |
| Planetoid* [29] | 64.7 (26s) | 75.7 (13s) | 77.2 (25s) | 61.9 (185s) |
| GCN (本文) | 70.3 (7s) | 81.5 (4s) | 79.0 (38s) | 66.0 (48s) |
| GCN (随机划分) | 67.9±0.5 | 80.1±0.5 | 78.9±0.7 | 58.4±1.7 |
我们进一步报告我们方法的收敛直到墙钟训练时间(以秒为单位,包括验证误差的评估)及 Planetoid 的数据。对于后者,我们使用了作者提供的实现,并在与我们的 GCN 模型相同的硬件(使用 GPU)上进行训练。我们在 Yang 等人(2016)中相同的数据集划分上训练和测试了我们的模型,并报告了100次具有随机权重初始化的运行的平均准确率。
100 次具有随机权重初始化的运行的平均准确率” 意味着在实验过程中,每次运行模型时,都使用了一个不同的随机数种子来初始化模型的权重。这样做可以确保实验结果的稳健性,并减少由特定初始化导致的偏差。这就是表中81.5的结果是100个随机数种子的计算均值
我们为 Citeseer、Cora 和 Pubmed 选择以下一套超参数:dropout率为0.5,L2正则化为5·10^(-4),隐藏单元数为16;对于 NELL:dropout率为0.1,L2正则化为1·10^(-5),隐藏单元数为64。
此外,我们还报告了我们模型在与 Yang 等人(2016)相同大小的10个随机抽取的数据集划分上的性能,标记为 GCN(随机划分)。在这里,我们报告了测试集划分预测准确率的平均值和标准误差(百分比)。
研究人员不仅在一个固定的数据集划分上评估了模型,而且还在 10 个随机生成的、与原始研究(Yang 等人,2016)中使用的大小相同的数据集划分上进行了测试。这样做可以更全面地评估模型对不同数据分布的适应性和稳定性。这就是随机分割呗,是最后一行数值的来源
6.2 传播模型评估
就是消融实验,从而判断每一个部分的有效性。
我们在引文网络数据集上比较了我们提出的各种逐层传播模型的变体。我们遵循前一节描述的实验设置。结果总结在表3中。我们原始 GCN 模型的传播模型由重归一化技巧(以粗体表示)表示。在所有其他情况下,两个神经网络层的传播模型都被替换为指定的传播模型。报告的数字表示100次重复运行的平均分类准确率,这些运行都使用随机权重矩阵初始化。如果每层有多个变量 Θ i \Theta_i Θi,我们对第一层的所有权重矩阵施加L2正则化。
表 3: 传播模型比较
| 描述 | 传播模型 | Citeseer | Cora | Pubmed |
|---|---|---|---|---|
| Chebyshev filter (Eq. 5), K = 3 K = 3 K=3 | ∑ k = 0 K T k ( L ~ ) X Θ k \sum_{k=0}^K T_k(\widetilde{L}) X \Theta_k ∑k=0KTk(L )XΘk | 69.8 | 79.5 | 74.4 |
| Chebyshev filter, K = 2 K = 2 K=2 | 69.6 | 81.2 | 73.8 | |
| 第一阶模型 (Eq. 6) | X Θ 0 + D − 1 2 A D − 1 2 X Θ 1 X \Theta_0 + D^{-\frac{1}{2}} A D^{-\frac{1}{2}} X \Theta_1 XΘ0+D−21AD−21XΘ1 | 68.3 | 80.0 | 77.5 |
| 单参数模型 (Eq. 7) | ( I N + D − 1 2 A D − 1 2 ) X Θ (I_N + D^{-\frac{1}{2}} A D^{-\frac{1}{2}}) X \Theta (IN+D−21AD−21)XΘ | 69.3 | 79.2 | 77.4 |
| 重归一化技巧 (Eq. 8) | D ~ − 1 2 A ~ D ~ − 1 2 X Θ \widetilde{D}^{-\frac{1}{2}} \widetilde{A} \widetilde{D}^{-\frac{1}{2}} X \Theta D −21A D −21XΘ | 70.3 | 81.5 | 79.0 |
| 第一阶项仅 (Eq.) | D − 1 2 A D − 1 2 X Θ D^{-\frac{1}{2}} A D^{-\frac{1}{2}} X \Theta D−21AD−21XΘ | 68.7 | 80.5 | 77.8 |
| 多层感知机 | X Θ X \Theta XΘ | 46.5 | 55.1 | 71.4 |
这种传播模型的比较有助于深入了解不同方法在特定数据集上的性能,为未来的优化和选择提供指导。
实验目的:
这部分实验的主要目的是比较不同的图卷积网络(GCN)传播模型在引文网络数据集上进行半监督节点分类任务的性能。这里使用的不同传播模型是对图卷积过程中节点信息传递方式的不同实现。实验设计:
数据集:实验中使用了三个引文网络数据集(Citeseer, Cora, Pubmed)和一个知识图谱数据集(NELL)。这些数据集包含文档(节点)和引用关系(边),每个节点有一个或多个类别标签。
传播模型:实验测试了几种不同的传播模型,包括:
- Chebyshev滤波器:这是一种基于Chebyshev多项式的近似图谱卷积方法。
- 第一阶模型:这种方法只考虑节点自身和直接邻居的特征。
- 单参数模型:使用单一参数简化节点特征的传播。
- 重归一化技巧:对邻接矩阵进行规范化以改善训练稳定性和模型性能。
- 多层感知机(MLP):作为基准,这种模型不考虑图结构,仅依赖于节点特征。
初始化和训练:每种模型在每个数据集上进行100次训练和测试,每次使用不同的随机初始化权重。这有助于得到关于模型性能稳定性的可靠估计。
实验结果:
- 结果在表3中总结,表明不同的传播模型在不同数据集上有不同的表现。
- 对于每种模型,报告了在三个引文网络数据集(Citeseer, Cora, Pubmed)上的平均分类准确度。
- 结果表明,重归一化技巧通常提供了较好的性能,其次是基于Chebyshev滤波器的方法。
- 传统的多层感知机在这些任务上表现不佳,说明在考虑图结构的情况下,节点分类性能会有显著提高。
重要性:
这部分实验重要的是它展示了在处理图数据时,选择合适的传播模型对提高性能有重要影响。这些结果可以帮助研究人员选择或设计更合适的模型架构来处理特定类型的图数据。
6.3 每个周期的训练时间
在这部分,我们报告了在模拟随机图上训练100个周期的每个周期平均训练时间(包括前向传递、交叉熵计算及反向传递),时间单位为秒(墙钟时间)。关于这些实验中使用的随机图数据集的详细描述,请参见第5.1节。我们比较了在GPU和仅使用CPU的TensorFlow(Abadi等人,2015)实现的结果。图2总结了这些结果。
表示内存溢出错误。
训练时间的影响因素:
- 硬件差异:使用GPU和CPU的实现差异可能导致显著的性能差异,GPU通常提供更快的处理速度,尤其是在可以并行处理的任务中,如神经网络的训练。
- 图的大小和复杂性:图的边数是影响训练时间的一个重要因素。随着边数的增加,计算需求增加,训练时间相应增长。
- 内存限制:对于非常大的图,如果内存不足以存储必要的数据和模型参数,可能会发生内存溢出错误。
实验设计的重要性:
- 数据集选择:随机图提供了一种方法来系统地控制图的大小和复杂性,从而研究它们如何影响模型训练时间。
- 实验重复:通过对每种设置重复100次实验并计算平均训练时间,可以得到关于训练性能的更稳健和可靠的估计。
7. 笔者总结
昨晚失眠,写这个写的我浑浑噩噩的。也算是完事了,要不然我总担心大家看我这个图神经网络精讲连一个原文详解都没有,其核心观点我都在空域和频域图卷积中进行了详细的讲解。大佬理解东西理解的很深刻。大佬就是大佬。感谢你的观看。如果您觉得还不错的话,可以奖励打赏小弟一杯咖啡钱,创作不易。如果你对GNN感兴趣,不妨点赞、收藏并关注,这是对我工作的最大支持和鼓励。非常感谢!如果有任何问题,欢迎随时私信我。期待与你的互动!




















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











