







pycaret有多神,文檔就有多潦草 – pycaret 如何查看setup之後的數據
背景
最近在用Pycaret做一些機器學習的快速實驗,的確是非常强大的一個低代碼機器學習包~
基本上對標autoML,datarobot等功能。只要幾行代碼就能對比十幾種算法的結果,還能迅速調出各種不同計算方法的feature importance(例如 之前寫過的一篇permutation feature importance 【机器学习】用特征量重要度(feature importance)解释模型靠谱么?怎么才能算出更靠谱的重要度? )甚至還能出SHAP圖~!總之非常强大!
但是,pycaret的文檔實在做的不怎麽樣,什麽都找不太到,外網上也是怨聲載道。
這次遇到的問題在於做完數據setup之後,不知如何查看transform之後的數據是什麽樣
Pycaret調用方法
先准備個數據
from pycaret.datasets import get_data
data = get_data('diabetes')
1. 數據前處理 setup (包括補充缺損,one-hot encoding, 正規化數據等)
pycaret的數據前處理叫做setup,就這一行,基本可以實現所有需要的前處理。
from pycaret.classification import *
s = setup(data, target = 'Class variable', session_id = 123)
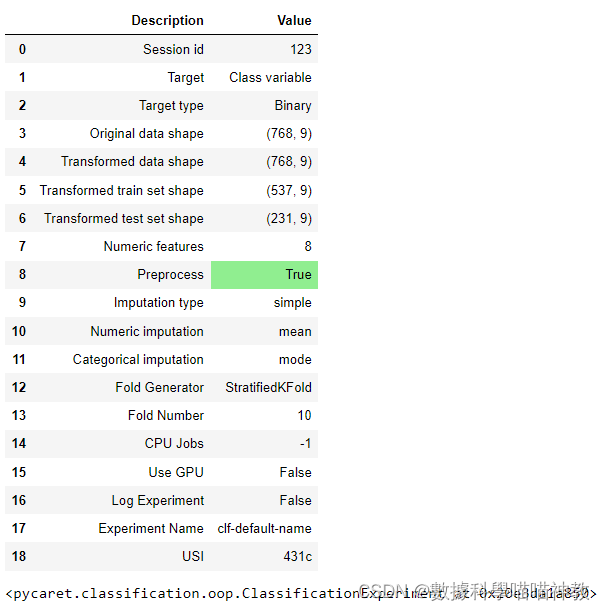
這個預處理結果可以看到這個setup對數據做了哪些事情。
比如缺損值是用什麽方式補充的,numeric是mean, categorical feature是mode(次數最多值),train test是怎麽分的(這裏是10 stratified KFold)等等。
但是文檔裏也沒寫我們如何查看它transform之後的數據是不是和我們預想的一樣。
重點來了!!!!
用 get_config('X_transformed') 可以查看處理完的數據
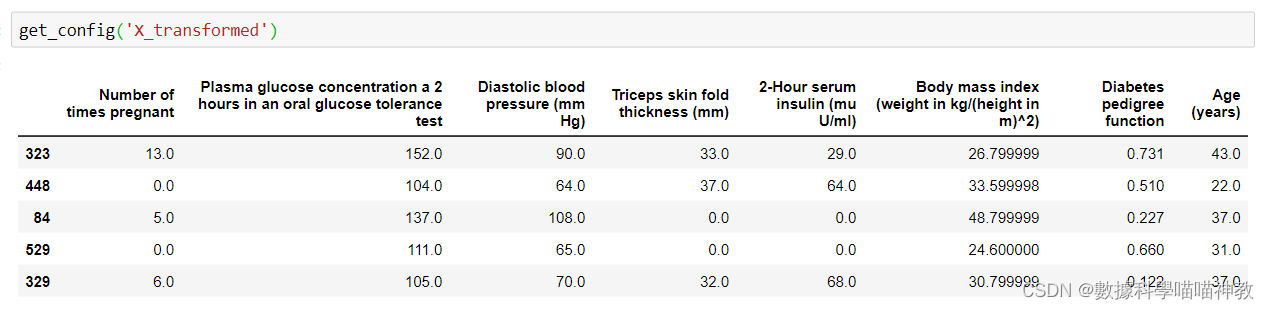
還可以用來看以下内容:
get_config('input from below list')
{‘USI’,
‘X’, # 我猜是原始數據features
‘X_test’,# 爲了crossvalidation分好的test features
‘X_test_transformed’,# test的處理完數據 features
‘X_train’,# 爲了crossvalidation分好的train features
‘X_train_transformed’,# train的處理完數據features
‘X_transformed’, # 處理完的數據features
‘_available_plots’,
‘_ml_usecase’,
‘data’,
‘dataset’,
‘dataset_transformed’,
‘exp_id’,
‘exp_name_log’,
‘fix_imbalance’,
‘fold_generator’,
‘fold_groups_param’,
‘fold_shuffle_param’,
‘gpu_n_jobs_param’,
‘gpu_param’,
‘html_param’,
‘idx’,
‘is_multiclass’,
‘log_plots_param’,
‘logging_param’,
‘memory’,
‘n_jobs_param’,
‘pipeline’,
‘seed’,
‘target_param’,
‘test’,
‘test_transformed’,
‘train’,
‘train_transformed’,
‘variable_and_property_keys’,
‘variables’,
‘y’,
‘y_test’, # 以下是對應的target部分
‘y_test_transformed’,
‘y_train’,
‘y_train_transformed’,
‘y_transformed’}
2. 訓練模型
best = compare_models()
對,就這一句,幫你比較10種以上算法結果
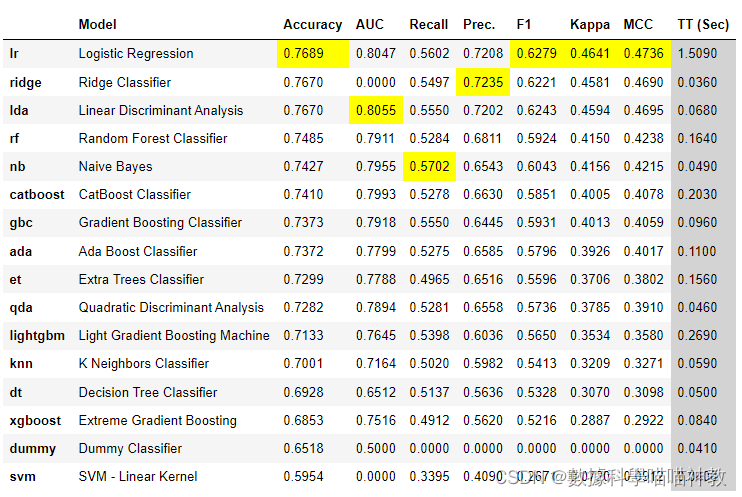
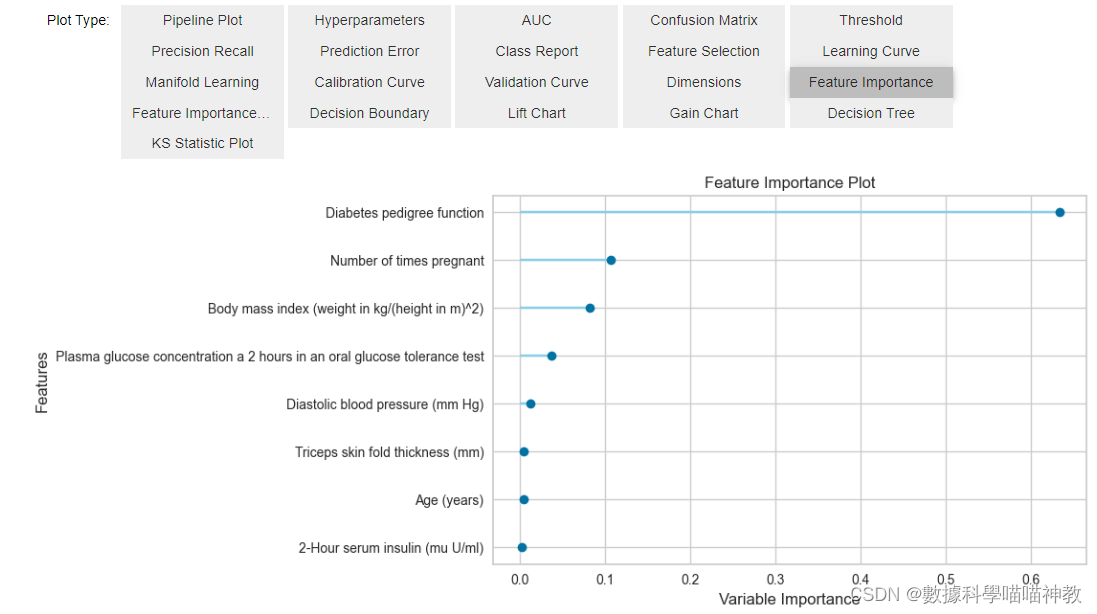
3. 查看best模型的特徵重要度
evaluate_model(best)
也可以調出permutation feature importance(【机器学习】用特征量重要度(feature importance)解释模型靠谱么?怎么才能算出更靠谱的重要度? )
像這樣:
interpret_model(model, plot = 'pfi')
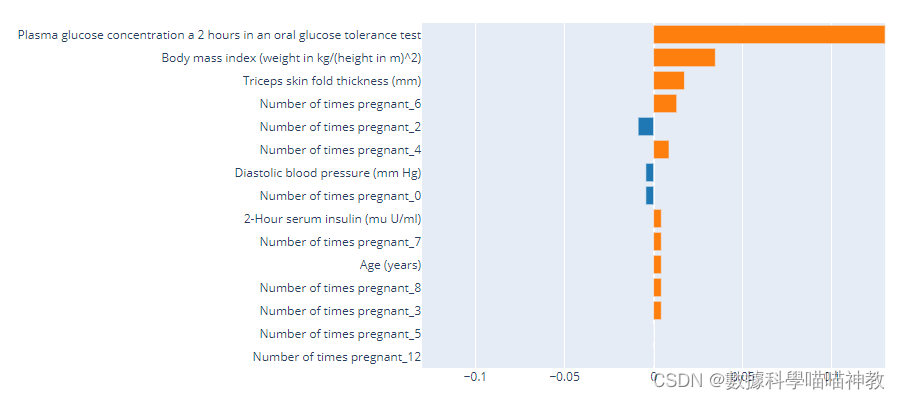
本篇文章就到這裏~ 歡迎提問交流♥
如果大家看了覺得有用,參考到了,請不要吝嗇 點贊,收藏與關注~~
如果大家對pycaret感興趣,之後會陸續給大家出更詳細的教程~ 包括如何出SHAP圖~ 各種圖的理解等~
參考文獻
pycaret document quick start
pycaret analyze
【机器学习】用特征量重要度(feature importance)解释模型靠谱么?怎么才能算出更靠谱的重要度?















 2183
2183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









