









 本文运用Python爬虫技术抓取51job网站的大数据职位信息,进行数据清理、统计分析和可视化,揭示了大数据岗位的增长趋势、主要分布地区、行业及薪资水平。通过机器学习预测模型,为求职者提供薪资预期和行业动态参考。
本文运用Python爬虫技术抓取51job网站的大数据职位信息,进行数据清理、统计分析和可视化,揭示了大数据岗位的增长趋势、主要分布地区、行业及薪资水平。通过机器学习预测模型,为求职者提供薪资预期和行业动态参考。

需要本项目的可以私信博主!!!
在大数据时代背景下,数据积累导致大数据行业的人才需求快速上升,大量的招聘信息被发布在招聘平台上。深入研究这些信息能帮助相关人士更好地理解行业动态,并对其未来发展进行预测。本文主要通过分析51job网站上的大数据职位招聘信息,进行一次可视化的呈现。
本研究首先使用Python爬虫技术,抓取51job网站的所有大数据相关职位信息。接着利用Python的数据清理技术,处理数据的重复项和异常项。然后,我们使用Python的统计排序技术对数据进行分析,并通过Python数据可视化技术将分析结果呈现出来。最后,我们使用机器学习技术预测大数据相关职位的平均薪资。
根据51job的大数据职位招聘信息可视化结果,我们可以看到大数据招聘岗位正在持续增长,这意味着社会对大数据专业人才的需求也在持续增长。大数据职位主要集中在一线城市,大多数职位来自私企和上市公司,主要集中在计算机软件、房地产和互联网行业。同时,大数据职位的薪资和福利待遇一般都很优厚。这些信息为求职者提供了选择大数据职位的参考。
通过预测模型,求职者可以提前了解即将应聘的大数据职位的预期薪资,预测模型的准确率可高达99%。
基于网络爬虫技术实现51job网站上大数据专业相关招聘信息的爬取,主要利用的是网络爬虫技术中的xpath方法和谷歌浏览器的开发者工具实现。
首先利用谷歌浏览器登录51job网站,利用谷歌浏览器的开发者工具查看网页中的cookie、useragent等标识,并且通过网站的搜索功能和翻页功能查看url的变化。
图3-1 谷歌浏览器的开发者工具页面
在以上的一系列爬取操作之后,共爬取到54950条数据,主要获取了十二个字段的大数据专业相关岗位信息,具体的字段以及含义如下表。

图3-2 爬取数据运行结果
表3-1 字段的含义解释
| 字段 | 含义 |
| job_name | 职位名称 |
| company_name | 公司名称 |
| low_salary | 最低薪资(万/月) |
| High_salary | 最高薪资(万/月) |
| yaoqiu | 要求 |
| job_place | 工作地点 |
| company_nature | 公司性质 |
| job_content | 工作内容 |
| company_content | 公司详情 |
| release | 发布时间 |
| job_class | 职位类别 |
| fuli | 公司福利 |
首先是利用collections库的Counter函数对数据的重复值进行查看,这边主要是对岗位的url进行了统计查看,可以通过结果看出,每个url都只出现了一次,也就是说,每条数据都只出现了一次,并未出现重复值,因此,不用对数据进行去重操作。

图3-3 重复值统计结果
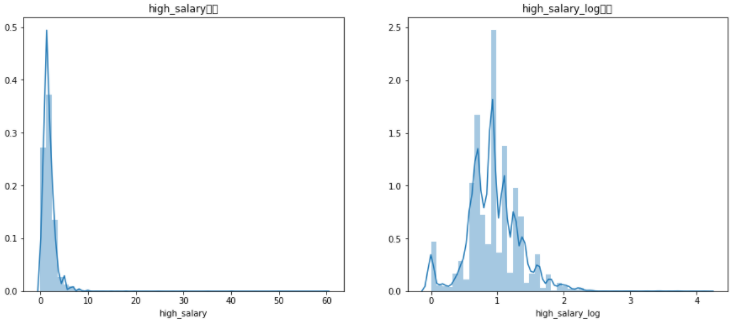
图3-4 最高薪资异常值处理前后对比图
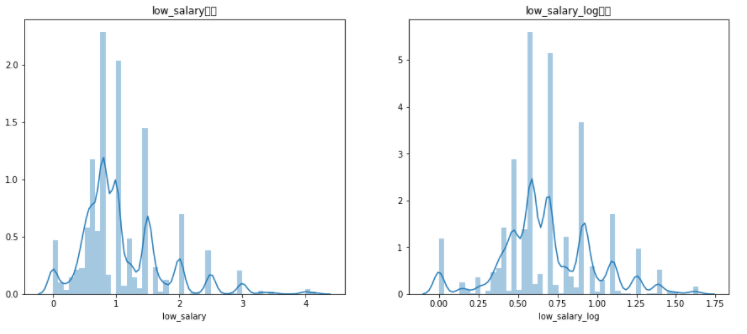 图3-5 最低资异常值处理前后对比图
图3-5 最低资异常值处理前后对比图
图3-6 最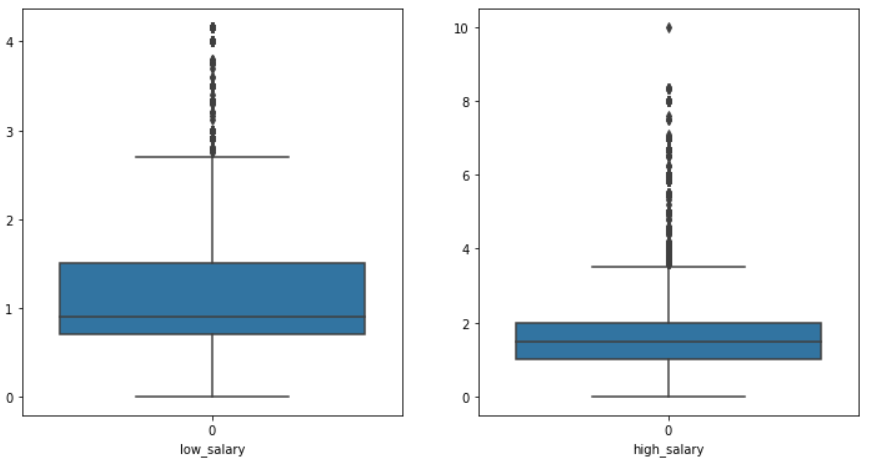 高薪资和最低薪资盒图
高薪资和最低薪资盒图

图3-7 占比率前十类别运行结果

图3-8 平均最高薪资前十类别运行结果

图3-9 平均最低薪资前十类别运行结果
从岗位信息来看,每个岗位所在的城市不同,而每个城市的发展水平有差异,

图3-10 大数据相关职位主要分布的前十城市运行结果
通过岗位信息对各个公司的大数据专业相关岗位数量进行统计分析。首先,通过列表将各个公司性质的大数据专业相关岗位进行统计,然后通过排序得出职位数量最多的前十个公司性质。

图3-11 公司性质前十运行结果
大数据专业相关岗位也分为很多种不同的岗位,

图3-12 数量前十的岗位运行结果
目前需求量最大的十个岗位,令求职者关注的应该是这些岗位的薪资,因此,对这十个岗位进行了平均最高薪资和平均最低薪资的分析。
 图3-13 前十岗位对应的最高和最低薪资运行结果
图3-13 前十岗位对应的最高和最低薪资运行结果
为了验证大数据专业相关岗位在当前社会的真实发展趋势,以及社会对该岗位的需求增长趋势,对每日发布岗位的数量进行分析。根据日期对发布的岗位数量进行统计。

图3-14 每日发布数量运行结果
根据职位类别的数量统计,对所有职位类别进行词云图呈现,从词云图可以看出计算机软件、互联网、电子商务、计算机服务等职位类别对大数据专业相关岗位的需求比较大,求职者在求职的时候可以先考虑这些岗位类别的招聘。

图3-15 职位类别的词云图展示
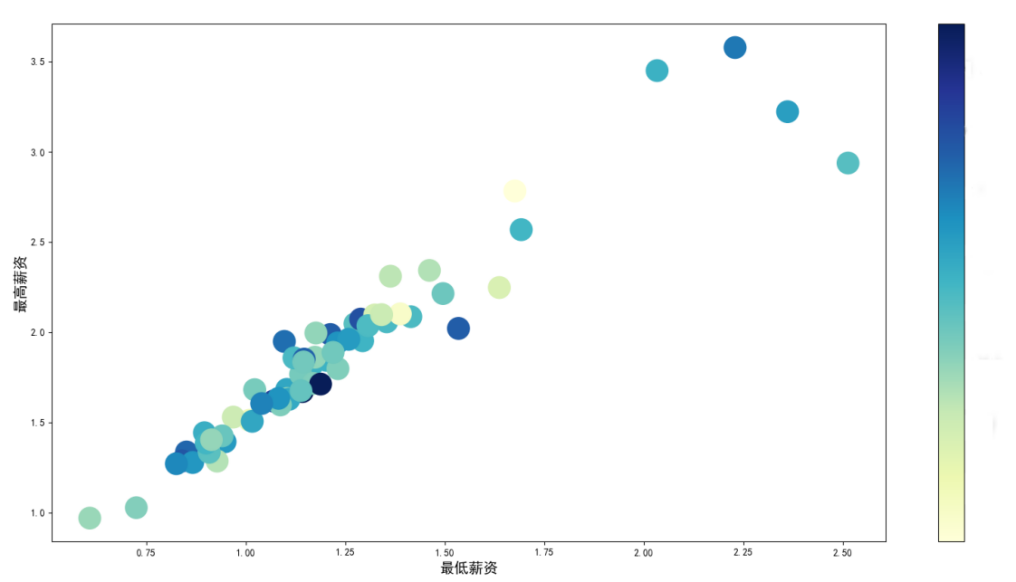
图3-16 职位类别的最高薪资和最低薪资的散点热力图展示
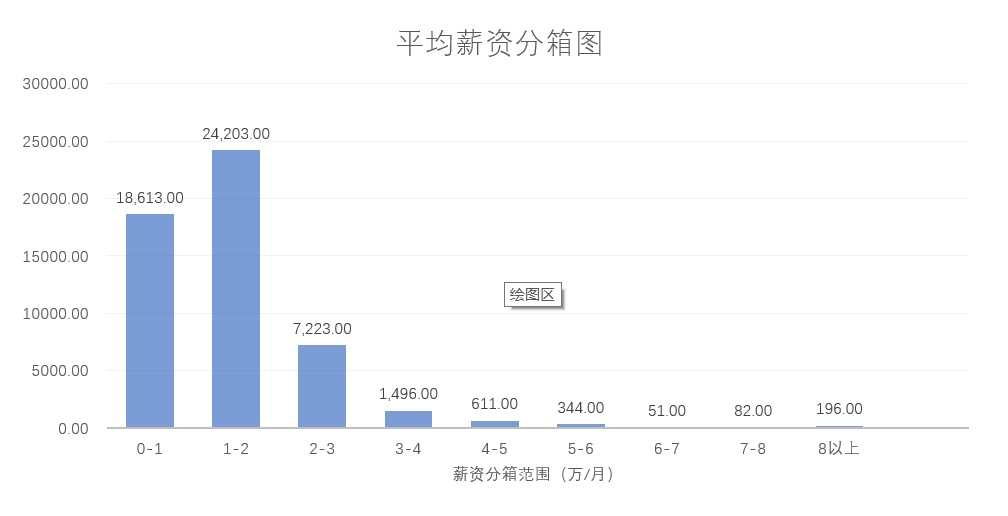
图3-17 各类别平均薪资的分箱图展示
根据占比率前十的职位类别统计,对职位类别进行环状扇形图的呈现。根据环状扇形形图可以看出,计算机软件、房地产、互联网/电子商务的职位占比是比较大的,如果求职者想要取得更多的就业机会,可以优先选择这三个职位类别。
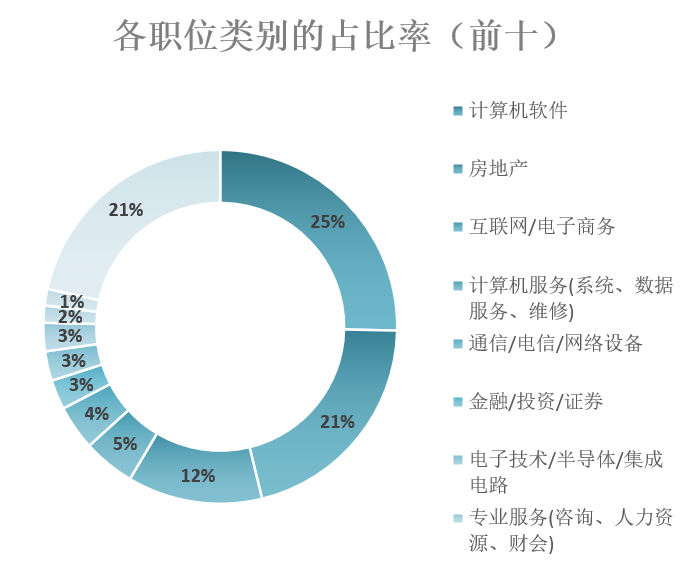
图3-18 占比率前十的职位类别环状扇形图展示
根据平均最低薪资前十和平均最高薪资的职位类别统计,对职位类别进行柱状图的呈现。根据柱状图,可以看到前十职位类别的平均最低薪资都在1.4万/月以上,前十职位类别的平均最高薪资都在2.2万/月以上。
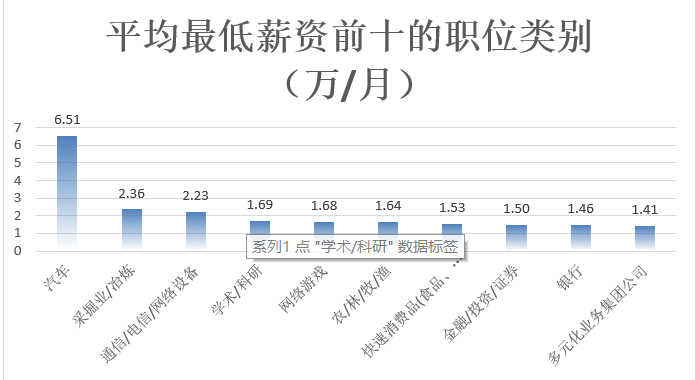
图3-19 最低薪资前十职位类别的柱状图展示
图3-20 最高薪资前十职位类别的柱状图展示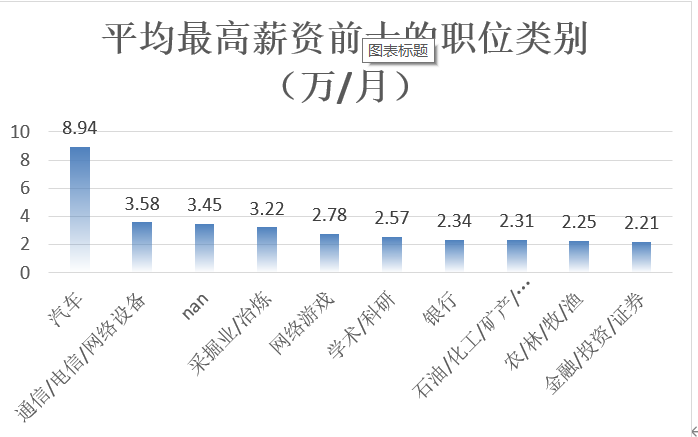
根据各城市的大数据专业相关岗位数量统计,对城市职位分布进行中国地图热力图呈现。从图中可以看出,上海是大数据专业相关岗位需求量最大的城市,其次是广东,第三梯队是北京、江苏,浙江、四川和湖北排在第四梯队。可以看出,北上广作为一线城市,对大数据专业相关岗位的需求是更为迫切的。

图3-21 各城市大数据岗位数量的中国地图热力图展示
根据前十公司性质的大数据专业相关岗位数量统计,对公司性质进行条形图呈现。从条形图可以看出,民营公司占比最大,占66.15%,其次是上市公司和国企。
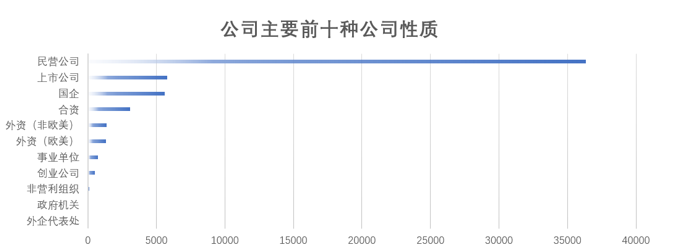
图3-22 岗位数量前十公司性质的条形图展示
根据各职位名称的数量统计,对职位数量进行条形图呈现和环状扇形图呈现。从条形图和环状扇形图可以看出,大数据开发工程师需求最旺盛,占比48%。其次是大数据分析工程师,占比15%。
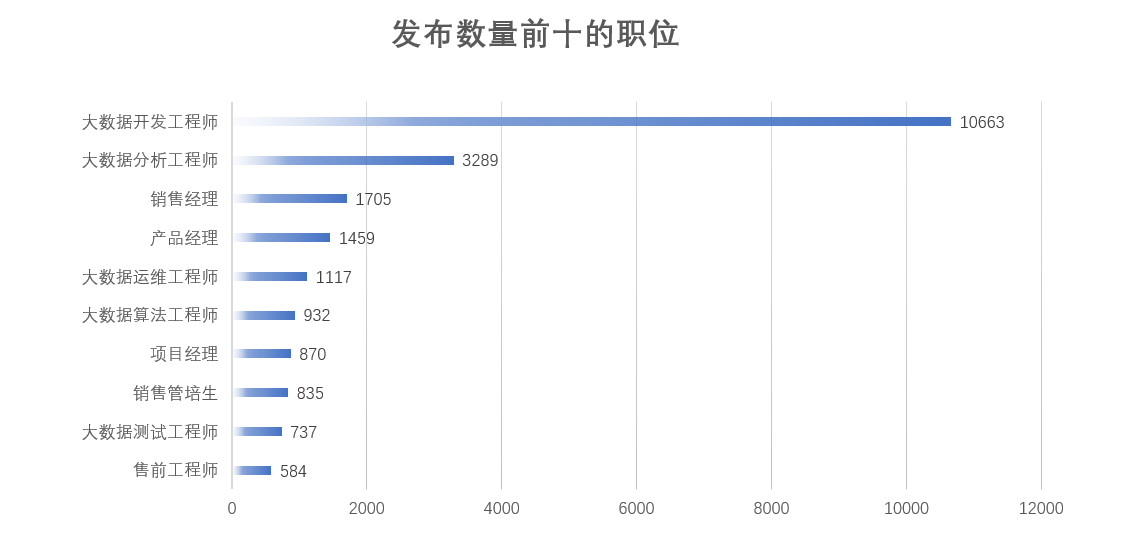
图3-23 发布数量前十岗位的条形图展示
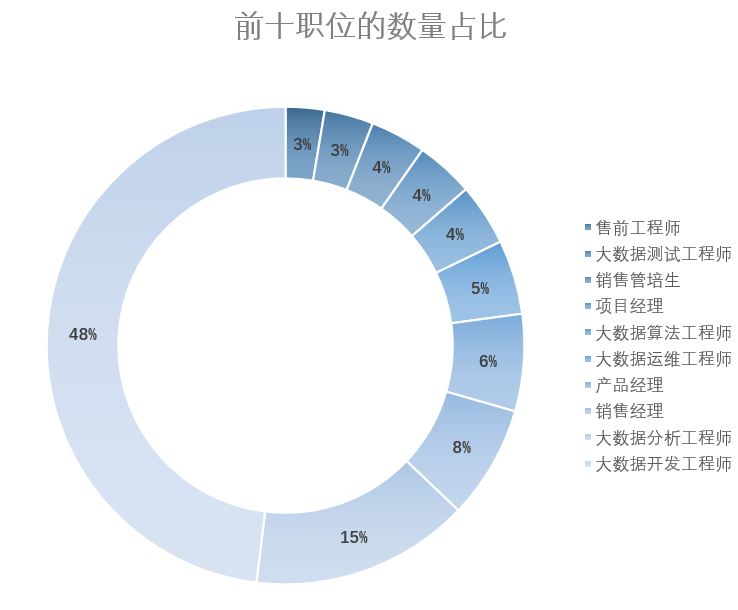
图3-24 发布数量前十岗位占比的环状扇形图展示
根据前十职位的平均最高薪资和最低薪资统计,对薪资进行双折线图进行呈现。从图中可以看出,这些薪资岗位的薪资都相对平均,十分稳定。
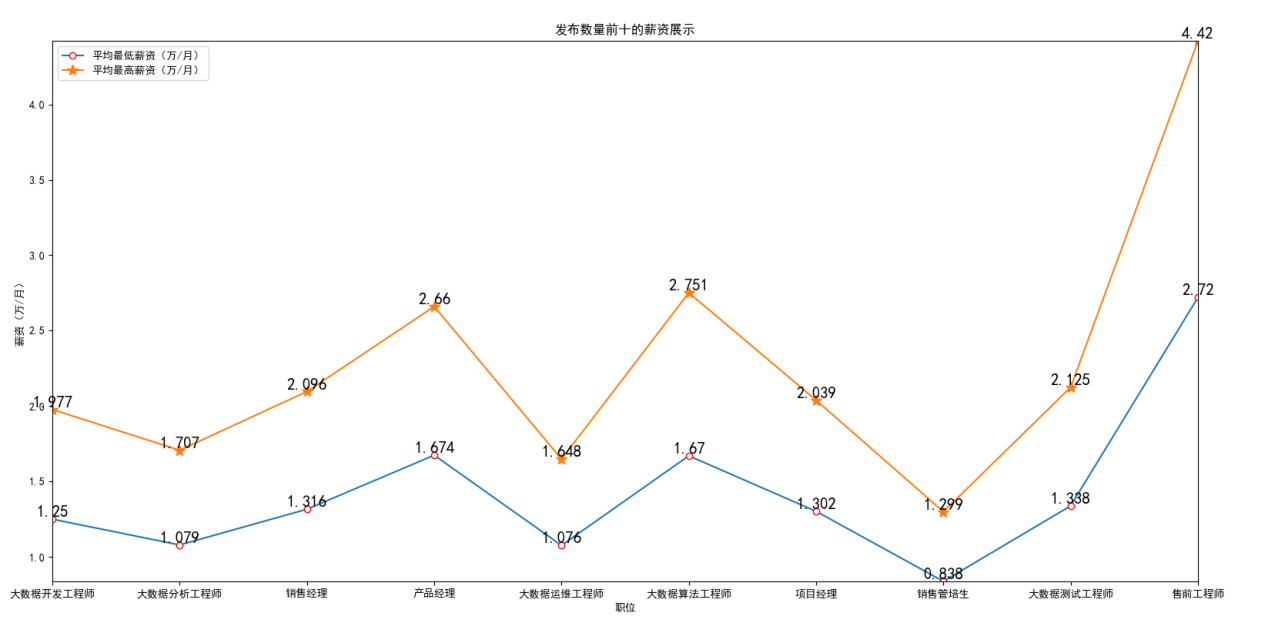
3-25 前十岗位的最高和最低薪资的双折线图展示
根据每日发布的职位数量统计
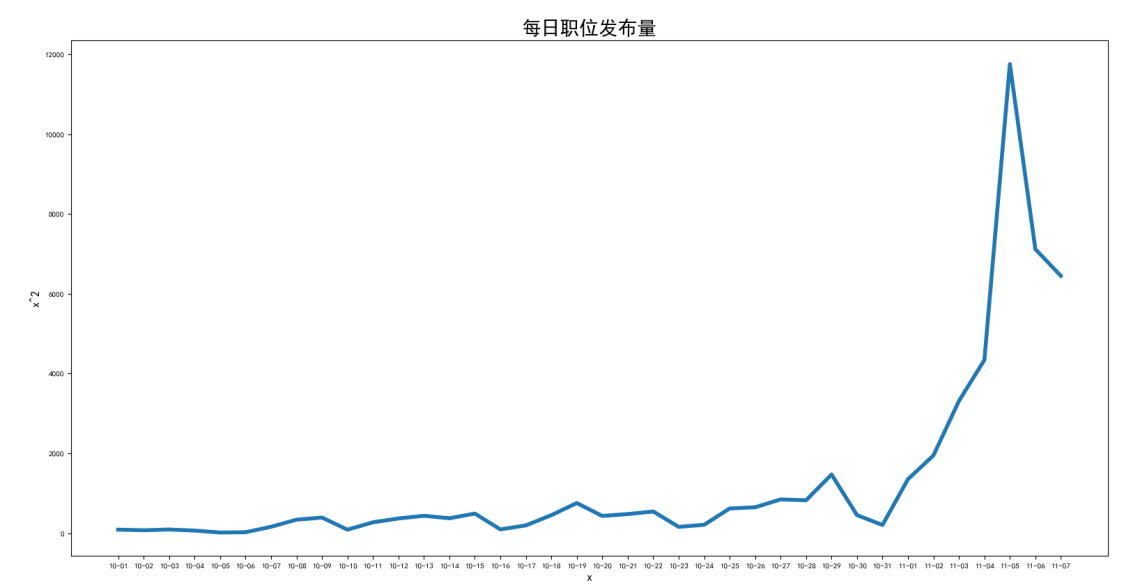
3-26 每日发布岗位数量的折线图展示
将数据中的福利字段(fuli)进行词云图呈现

3-27 岗位福利的词云图展示
图3-28 特征的相关性热力图展示
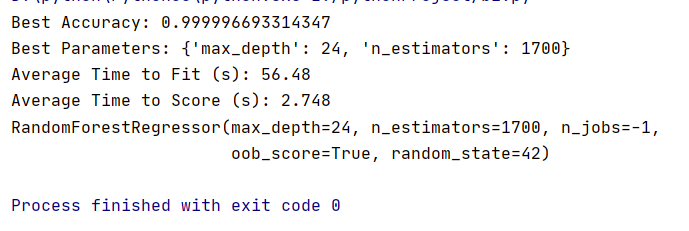
图3-29 随机森林模型预测准确率运行结果
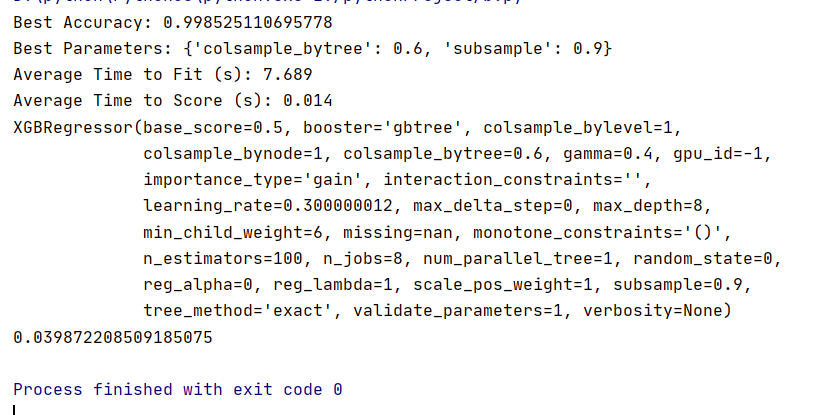
图3-30 xgboost预测准确率运行结果
图3-31 随机森林的平均薪资预测结果
利用数据对模型的训练过程,我利用plot_learning_curve()对模型的学习曲线进行了呈现,可以看出,模型在训练的过程中,准确率是在不断增加的。
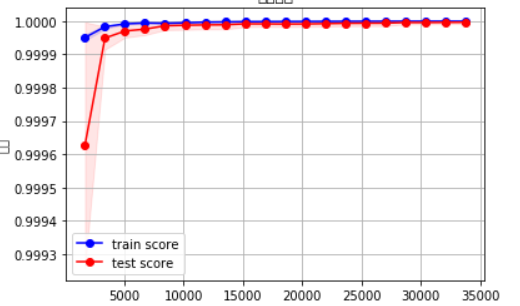
图3-32 模型学习曲线折线图展示
每文一语
纸上得来终觉浅,绝知此事要躬行


















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











