






Nhanes美国营养调查数据库的培训课程来了!
“Nhanes数据挖掘”课程即将开始! 欢迎报名, 发表文章即退款
近年来,全球肾结石的发病情况有所上升,给医疗支出和社会负担带来很大压力,也逐渐引起国内外学者更多关注。先前的推文中提到一个指标:全身免疫炎症指数(SII),它最初被认为是多种疾病的预后指标。本期推文我们一起来学习一篇研究 SII 对肾结石的影响的文章。
2023年2月,一篇题为:Association between the systemic immune-inflammation index and kidney stone: A cross-sectional study of NHANES 2007-2018的研究论文发表于《Front Immunol》,本文为中国学者写作,文章属于中科院分区医学二区,2023年IF=7.3。
这项研究利用美国营养健康(NHANES)的数据,通过多种方法,研究了SII与肾结石之间的关系。结果表明, SII 与50岁以下的美国成年人肾结石的高风险呈正相关。结果补充了以前的研究,仍然需要更大规模的前瞻性队列验证。

摘要与主要结果
一、摘要
背景:近几十年来,全球肾结石的发病率呈上升趋势,给医疗支出和社会负担带来很大压力。全身免疫炎症指数(SII)最初被认为是多种疾病的预后指标。我们对 SII 对肾结石的影响进行了最新的分析。
方法:这一横断面研究招收了2007-2018年全国健康和营养调查的参与者。我们进行了单变量和多变量 Logit模型分析,以研究 SII 与肾结石之间的关系。
结果:在22220名参与者中,平均(SD)年龄为49.45 ± 17.36岁,肾结石发生率为9.87% 。一个完全调整的模型显示,在20-50岁的成年人中,超过330x109/L 的 SII 与肾结石平行相关(优势比[ OR ] = 1.282,95% 置信区间[ CI ] = 1.023至1.608,P = 0.034)。然而,在老年亚组中没有发现差异。多重插补分析证实了我们的结果的稳健性。
结论:在50岁以下的美国成年人中,SII 与肾结石的高风险呈正相关。结果补偿了以前的研究,仍然需要更大规模的前瞻性队列验证。
二、研究结果
1. 研究人群的基线资料
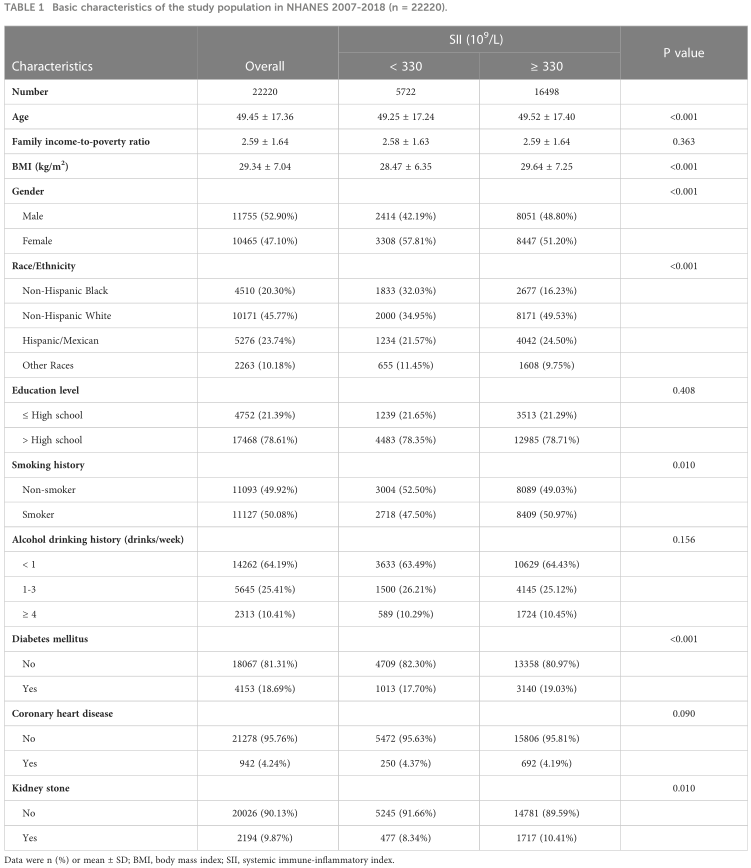
这项研究包括 2007 年至 2018 年期间的 59842 名参与者。25163 名参与者因缺失肾结石数据而被排除,3054 名参与者因缺失 SII 数据而被排除。在删除了 9405 名缺少 SII 协变量和极端数据的参与者后,最终招募了 2220 名参与者。在 22220 名参与者中,男性 11755 名,女性 10465 名(表 1)。肾结石患病率为9.87%。与 SII 低于 330 x 109/L 的参与者相比,SII 高于 330 x 109/L 的参与者中非西班牙裔白人、吸烟者、糖尿病和肾结石的比例更高(P < 0.05)。
2.分层并建立多种logistics回归模型
随后,逻辑回归分析发现,在调整整个人群的协变量后,SII 亚组和肾结石之间没有显着差异(表 2)。
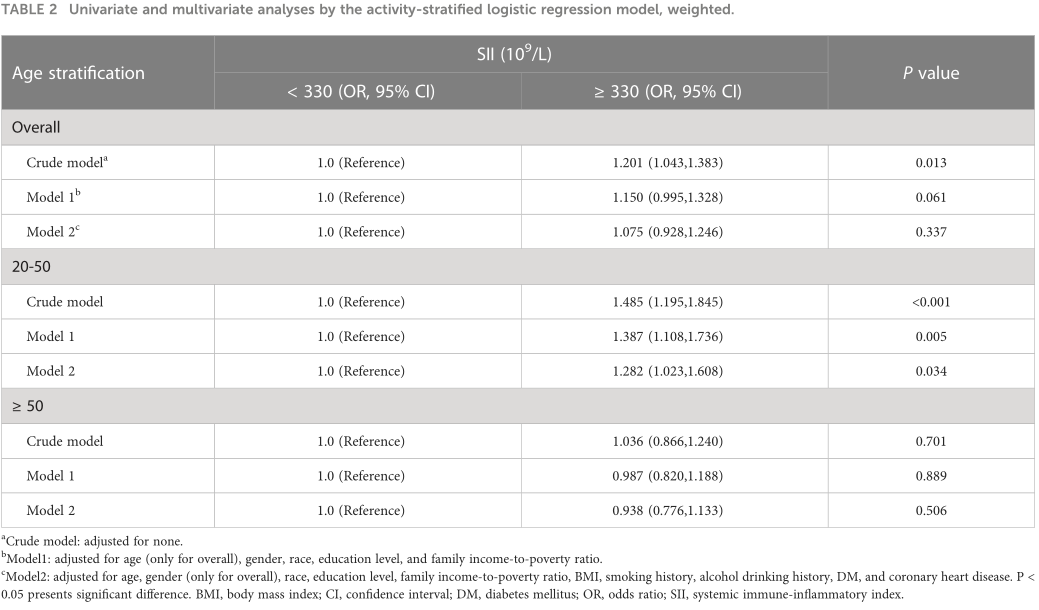
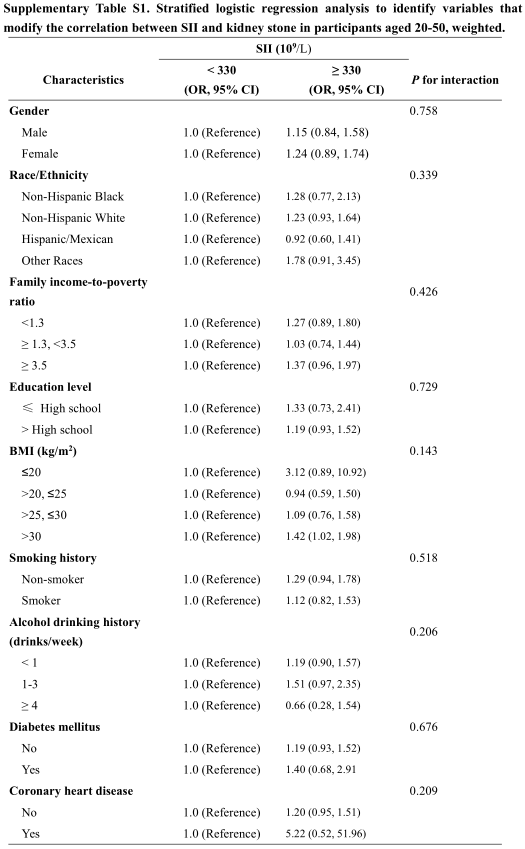
按 50 岁对年龄进行分层后,单变量和多变量分析表明,在粗略模型中,超过 330 x 109/L 的高 SII 与较高的肾结石风险相关(优势比 [OR] = 1.485,95% 置信区间) [CI] = 1.195 至 1.845,P < 0.001)和模型 1(OR = 1.387,95% CI = 1.108 至 1.736,P = 0.005)。调整所有混杂因素后,在 20-50 岁人群中,高 SII 仍然与肾结石呈正相关。(OR = 1.282,95% CI = 1.023 至 1.608,P = 0.034)50 岁及以上的参与者没有发现差异。20-50 岁人群的分层逻辑回归分析表明,20-50 岁人群中 SII 和肾结石之间的关系没有潜在的修正因素(补充表 S1)。
3.敏感性分析
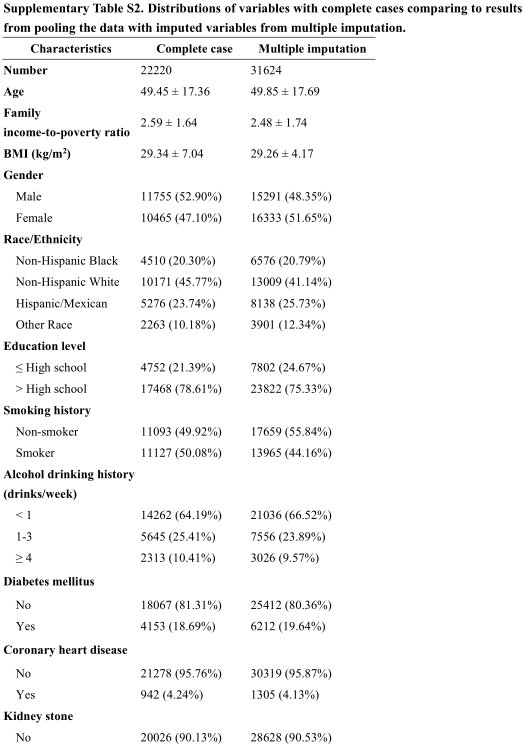
为了进一步验证结果,进行了多重插补。补充表 S2 中描述了基线特征分布。
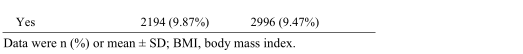
敏感性分析显示完全调整模型中的结果相似(OR = 1.251,95% CI = 1.015 至 1.541,P = 0.036)(表 3)。

设计与统计学方法
一、研究设计
P:2007-2018 年国家健康和营养检查调查的参与者。
I:暴露因素为SII水平。
O:结局:肾结石发病。
S:横断面研究。
二、统计方法
1.基线资料描述以及差异性分析,SII亚组的比较是使用连续变量的调查加权逻辑回归(平均值±标准差[SD])和分类变量的调查加权卡方检验(计数,[n])进行的。

2.建立多变量逻辑回归模型,采用多变量逻辑回归分析来研究 SII 与肾结石之间的关系。粗模型没有调整协变量。模型1是针对年龄、性别、种族/民族、家庭收入与贫困率和教育水平进行调整的最小调整模型。模型 3 针对 BMI、吸烟史、饮酒史、糖尿病和冠心病进行了调整。(未见模型2,表示困惑)

3.年龄分层亚组分析,进行年龄分层亚组分析以阐明 SII 的影响。我们进行了进一步的分层逻辑回归分析,以确定改变 20-50 岁参与者之间关联的变量。

4.敏感性分析,使用多重插补(MI)方法进行敏感性分析。MI 是一种基于 RMI 程序中的五次重复和链式方程方法来补偿缺失数据的方法,以解释教育水平、家庭收入与贫困率、BMI、吸烟史、饮酒史、DM 和冠心病。

5.补充说明,所有分析均使用 R 软件版本 4.1(http://www.R-project.org;The R Foundation)和 EmpowerStats(http://www.empowerstats.com,X&Y Solutions, Inc.)进行。P<0。0 5(两侧)设置为显着差异。

小感悟
本期介绍的是一篇二区文章,7.3分,高分文章。
文章的研究方法并不复杂,先对基线资料进行分析再差异性分析,随后建立回归模型,回归模型也采用了传统三件套:未校正,部分校正以及完全校正三种模型。回归模型建立完成后发现出事了,随着校正程度的提升发现p值越来越大,咋办,进行年龄分层!终于,在20到50岁的群体中找到了完全校正模型P值也小于0.05。最后再进行一个敏感性分析用于验证。
写文章,重点在于出结果,不仅指标和对象要选好,在分析过程中还要灵活变通。统计方法并不难,在得不到阳性结果以后怎么办,先别急着放弃,年龄分层做一做,性别分开看一看,没准就出结果了,这些灵感往往来自于日积月累的尝试。总之多看多学多试,就是发文秘诀。
最后,欢迎报名郑老师团队的统计学9.2-9.3的Nhanes数据挖掘课程
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









