







前面我们已经知道了tRFC/tREFI/tREF之间的关系了。那么refresh操作的带来的问题主要有以下2个:
tRFC期间DRAM无法被访问。因为DRAM内部再做刷新动作,这个时候禁止对DRAM进行访问。这个tRFC就增加了SoC访问DRAM的延迟,导致当访问DRAM的时候恰巧碰到tRFC的时候,latency会变得很长。
REF整个command队系统造成了很大的功耗,如下图是Micron的DDR3产品官方release的IDD value,可以看到IDD5B(refresh带来的功耗)甚至都要比IDD4R/IDD4W要大了,只比IDD7小了一点。
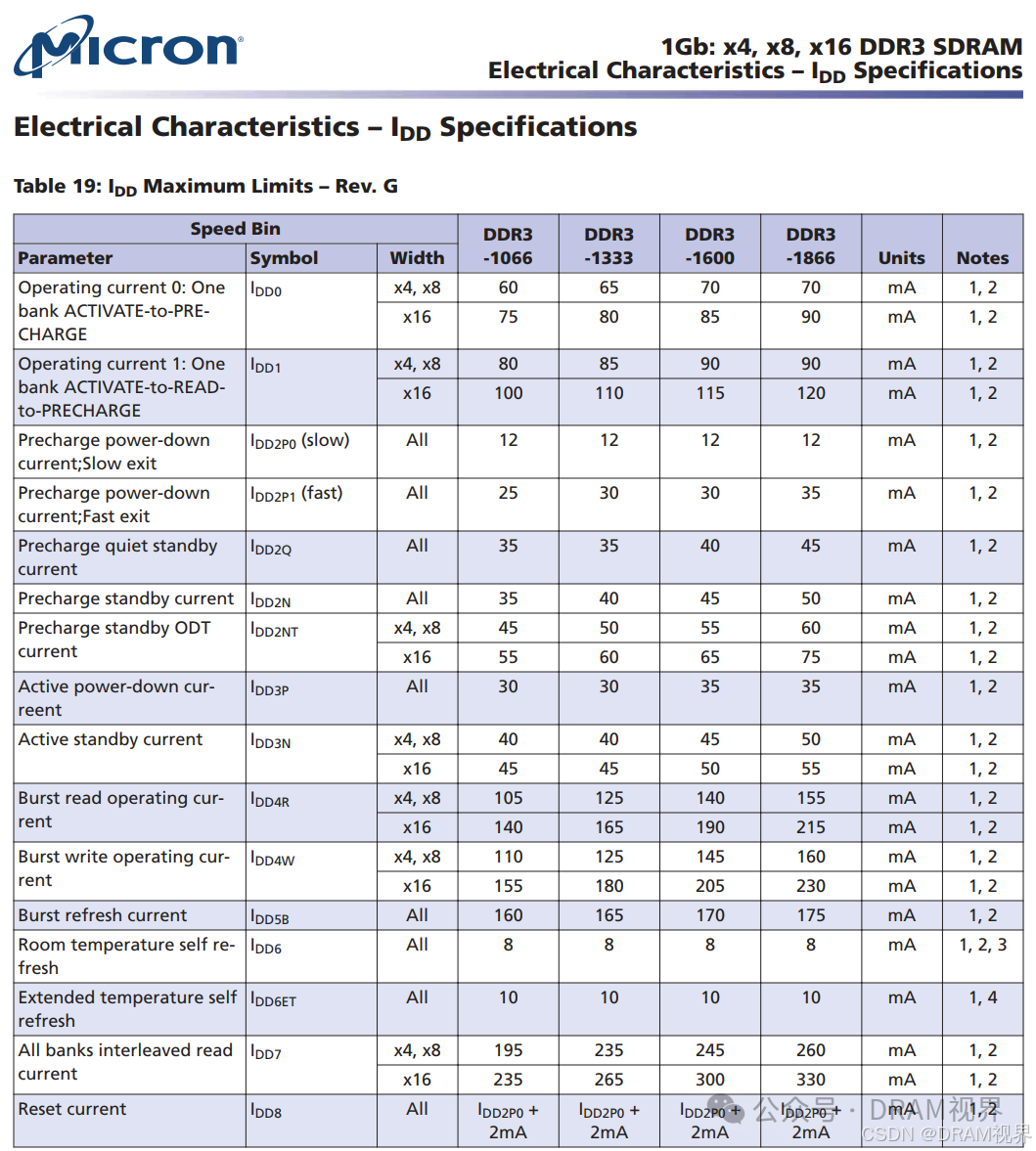
这部分IDD5B的功耗很讨厌,因为随着温度的升高,这个refresh rate甚至要求更快,导致不仅是温度升高单纯带来的leakage功耗的增加,还因为温度升高带来的refresh rate的加快带来的功耗增加。
针对第一点,简单rough的评估一下tRFC对DRAM性能到底有多大影响: 以tRFC=350ns为例,tREFI=7.8us(DDR4), 8K refresh times. 那么在64ms内(tREF), 至少需要8KtRFC的时间是不能访问DRAM的. **所以不能访问DRAM的ratio是8KtRFC(ns)/64ms100%=4.48%.**
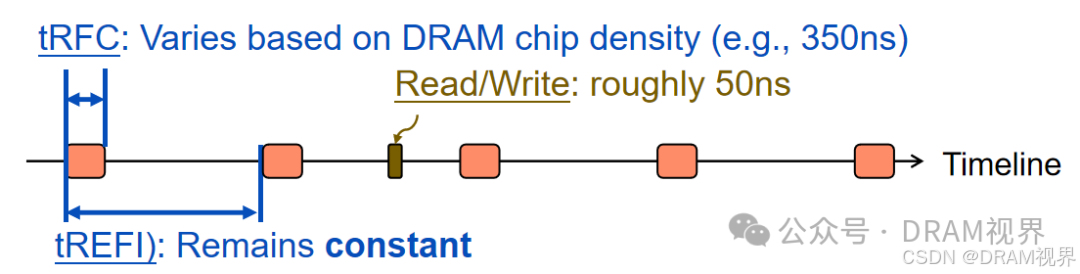
!接近5%左右的DRAM时间是完全利用不到的!谁能接受?DRAM controlelr能做到的访问DRAM的效率也顶多目前能做到70%上下。结果因为tRFC就要吃掉5%。高温tREFI减半,这个甚至会suffer 10%的效率loss. DDR5在这个地方做了基本两个优化,一个是tRFC缩短了(其实refresh次数是增加了的,所以这地方并没有优化),另一个是加了REFSB的feature.那么之前的文章也有介绍到,随着DRAM density增加,tRFC也会跟着增加,DRAM的性能反而会有一定的suffer.

我们先base DDR5 8Gb的tRFC跟DDR4实际计算一下做个对比: DDR5 8Gb with tRFC=195ns. 195ns16K/64ms*100%=4.99%.所以实际上DDR5单纯考虑REFAB的tRFC的话,因为tRFC带来的影响,DDR5甚至比DDR4还要差一点。
然后我们用DDR5的32Gb vs 16Gb做个对比的话,32Gb的tRFC增大了115ns. 16K115ns/64ms100%=2.9%. 也即意味着,32Gb跟16Gb相比,32Gb的DDR5至少性能上会因为tRFC多suffer接近3%的loss.
针对以上两点,缩短tRFC的话,方法不多。
1). 增加同开wordline的条数来缩短tRFC,好处是latency变短,坏处是power增加
2). 增大tREFI, 也就是要有更好的retention performance(能有更长的tREF timing). 这个主要要有process的支持。随着工艺的演进,这个会越来越难达到。
3). spec没有强制规定REF跟REF之间的间隔一定要meet tREFI.允许controller可以提前或者推后发burst refresh command。严格意义上而言,DRAM只要求64ms内刷完所有row就好了,实际上要怎么发REF command,只要满足tRFC,其实对tREFI没有特别一定的要求。
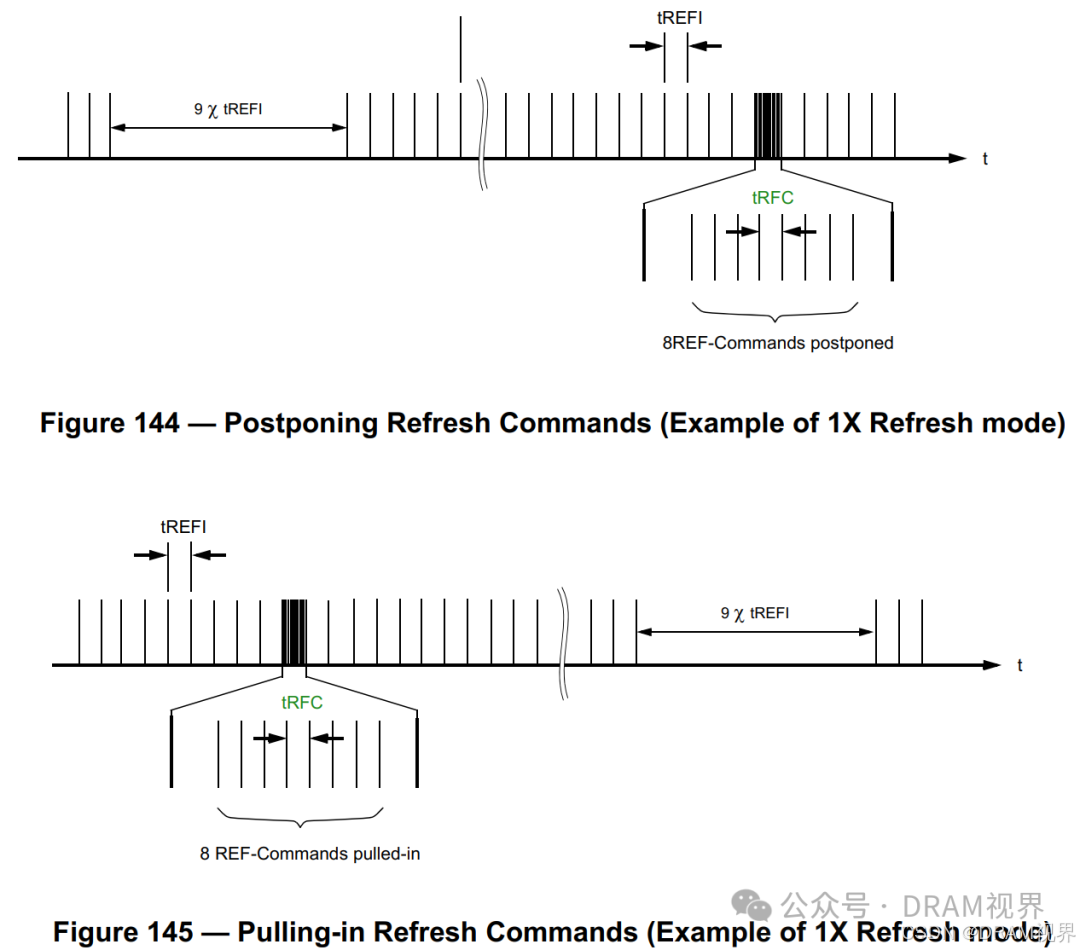
spec之所以对上面的sequence有要求,强制只允许连续以tRFC的时间间隔发8比REF command(not tREFI),即所谓burst refresh, 大概率是因为power的考虑。那么对于controller而言,就没必要严格遵守tREFI时间到了就得发送REF command了,在系统访问DRAM的traffic比较busy的时候,完全就可以推迟一点时间发REF command从而错开高峰期。当然唯一的硬性指标是64ms内必须刷满8K.(DDR5是16K).
4). 让REF command不要刷新所有bank。LP系列除了REF all bank(REFAB) command之外, 还有refresh perbank(REFPB),目的就是为了refresh操作可以对bank进行分开操作。好处是配合controller的优化算法,可以在controller需要访问bank0的时候,发non-bank0的refresh command.这个时候未被刷新的bank还是可以被正常访问的,不至于整个tRFC期间DRAM完全不能access. 但是这种方式在DDR上一直到DDR5才有了一点采用的苗头(DDR5 apply了REFSB的概念).
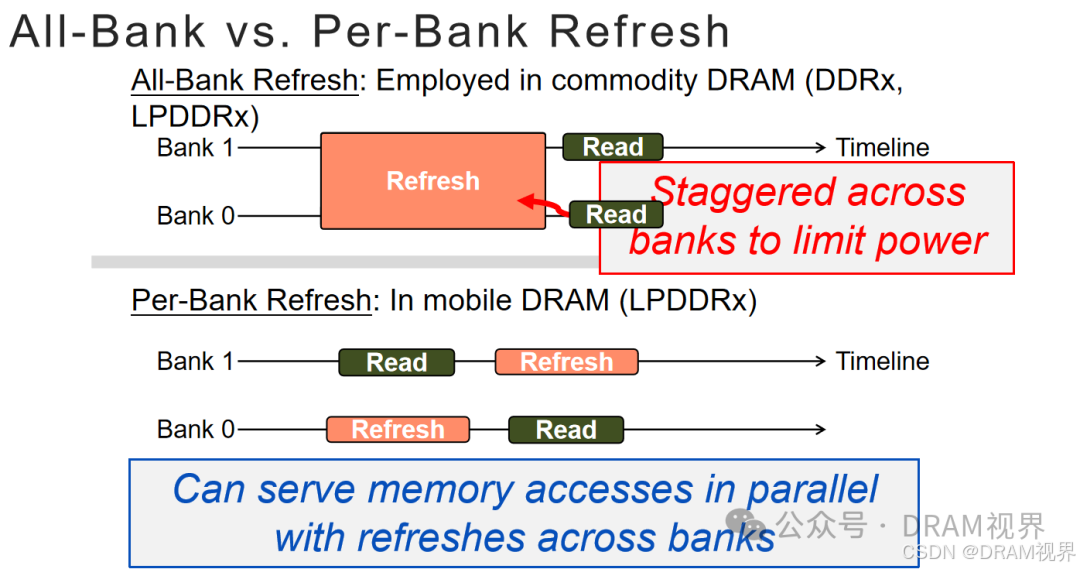
但是不管是REFPB还是REFSB,其实都是还有一定的限制,为了让所有bank的refresh counter是同一个状态而不至于错乱(如果每个bank的refresh counter都不一样,控制逻辑会相当复杂, dynamic ordering当然也是可以实现的),REFPB/REFSB的逻辑基本是RR(round robin)的刷新调度策略.也即bank0->1->2->3->…->15,类似这种扫完所有bank后再开始下一轮扫法。
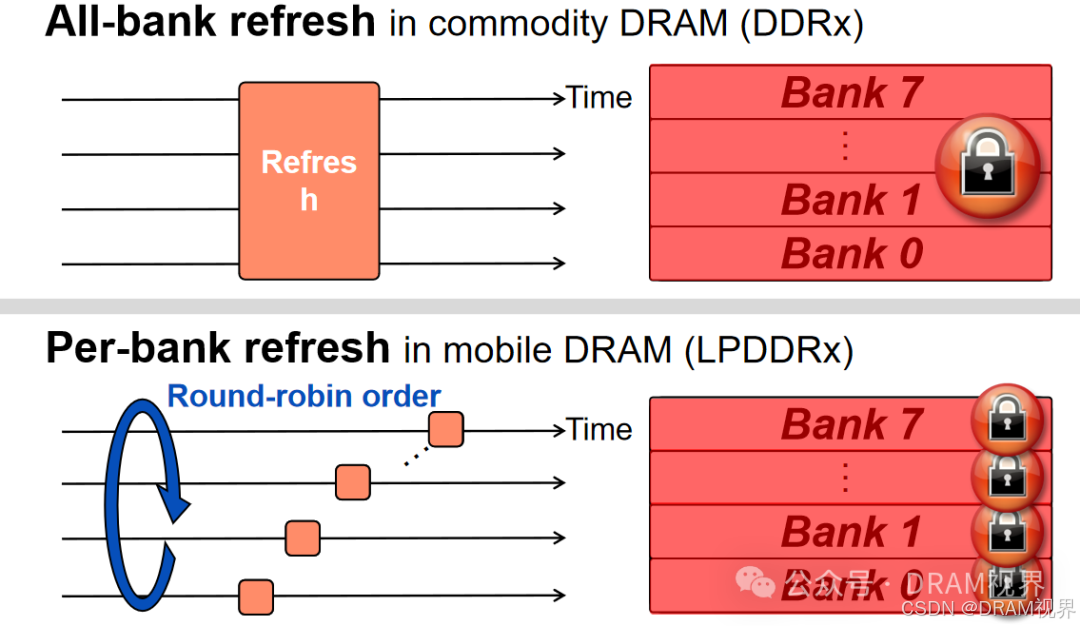
round robin的方法最简单,但是仍然会碰到write/read bank0的时候正在做bank0的refresh. 目前的controller为了进一步优化refresh的性能,基本采用了OOO(Out Of Order)的方法来优化:当碰到要write/read的bank时候,先做write/read,等该bank有空闲的时候,再做该bank的refresh。
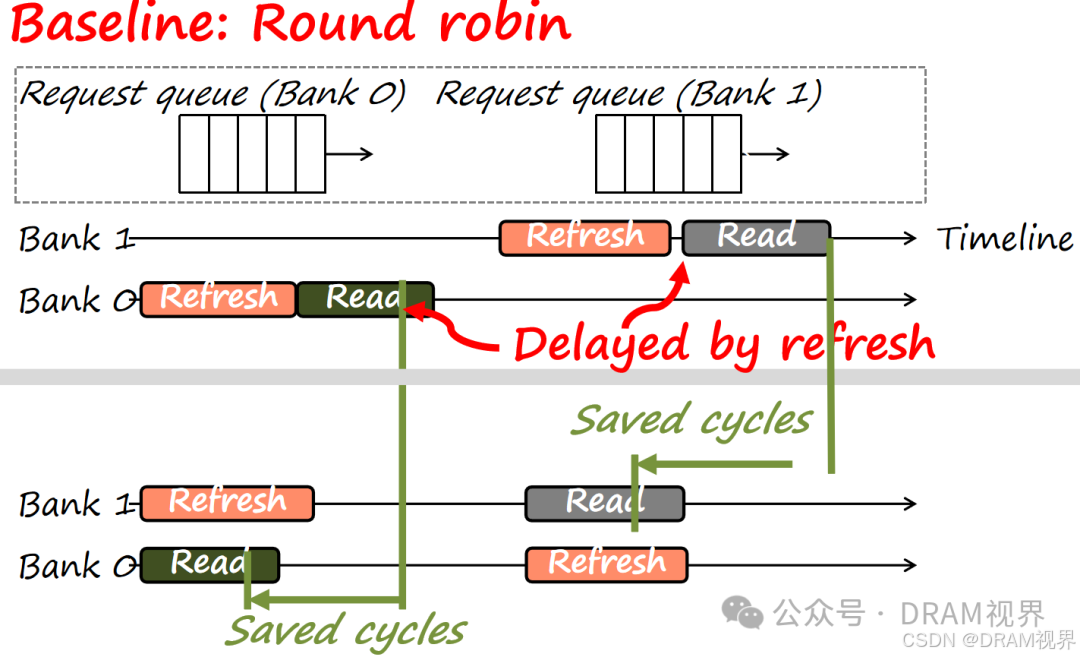
采用REFPB或者REFAB的策略还有一个好处是减少的power consumption.对系统是有好处的。多多采用REFSB/REFPB,就可以把IDD5降下来。
5). 充分利用温度的影响。DDR4采用了FGR mode, LP呢,则一直通过MR4来判断DRAM温度来提供给controller对refresh rate的动态选择。比如低温下,refresh rate降低,高温的时候refresh rate提高来动态优化系统的功耗跟性能。(refresh rate越低当然性能越好,因为碰到tRFC的次数少了).
当然排除以上的策略,我们当然还需要一些金点子。毕竟那接近5%的性能loss一直存在在那里。



















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











