







前言
从DDR3到DDR4再到DDR5, speed从1600Mbps提升到了DDR4的3200Mbps再到DDR5的8800Mbps,速度得到了成倍的提升,而电压却越来越低,一方面是process的持续演进,一方面是技术上的持续更新。
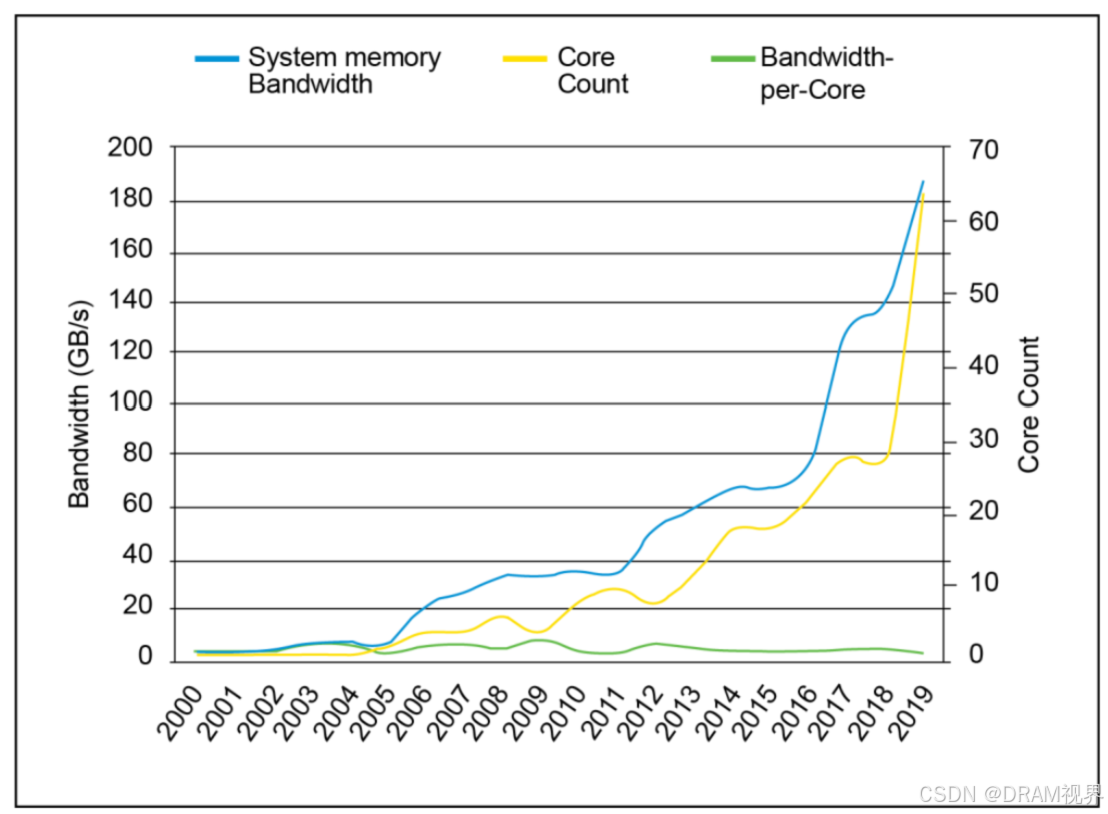
随着CPU的core数的堆叠,bandwidth越来越高,内存墙(memory wall)现象越来越严重,内存限制了CPU的性能发挥。DRAM的speed提升也是迫在眉睫。
Performance
Speed
Prefetch
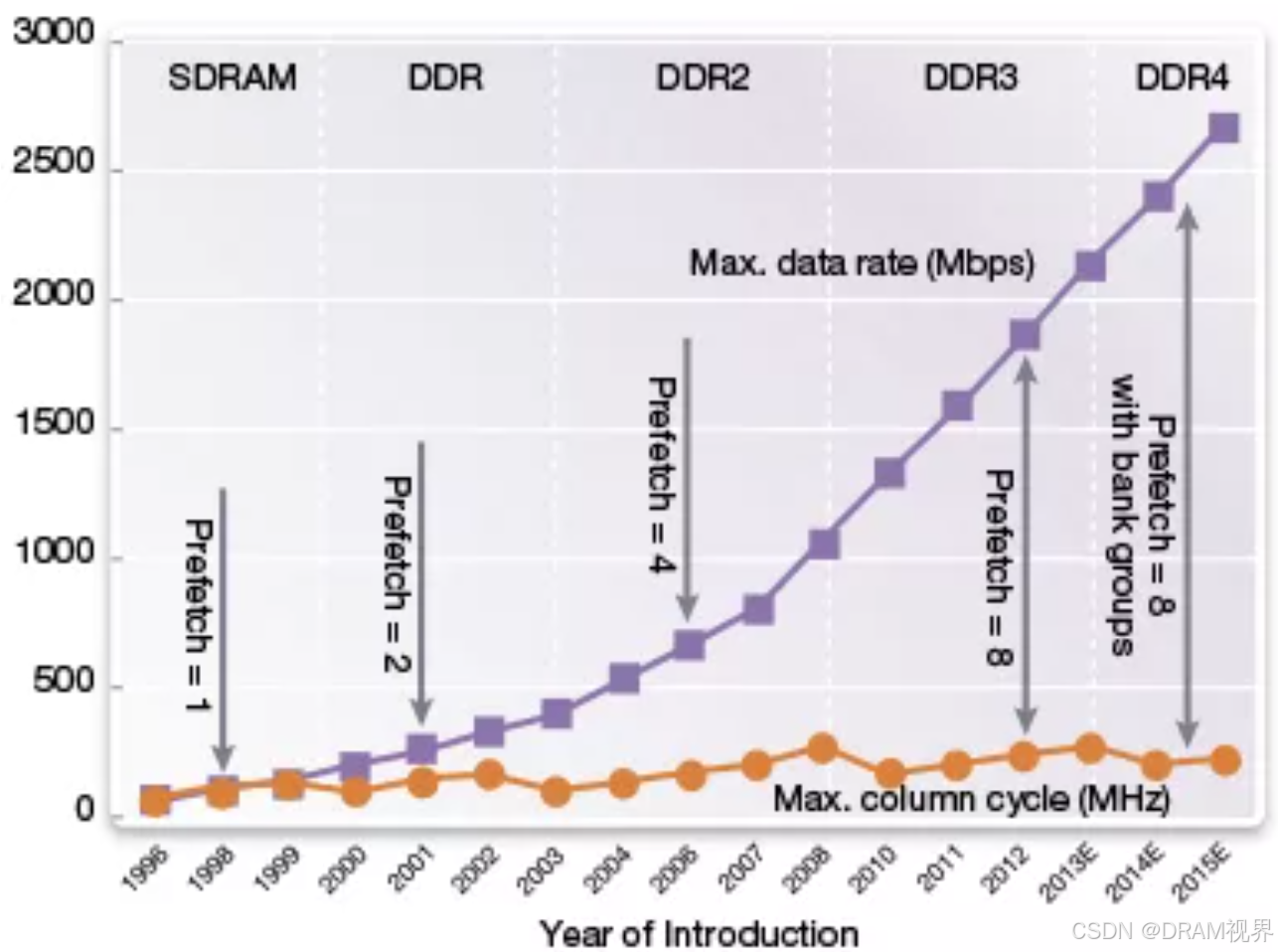
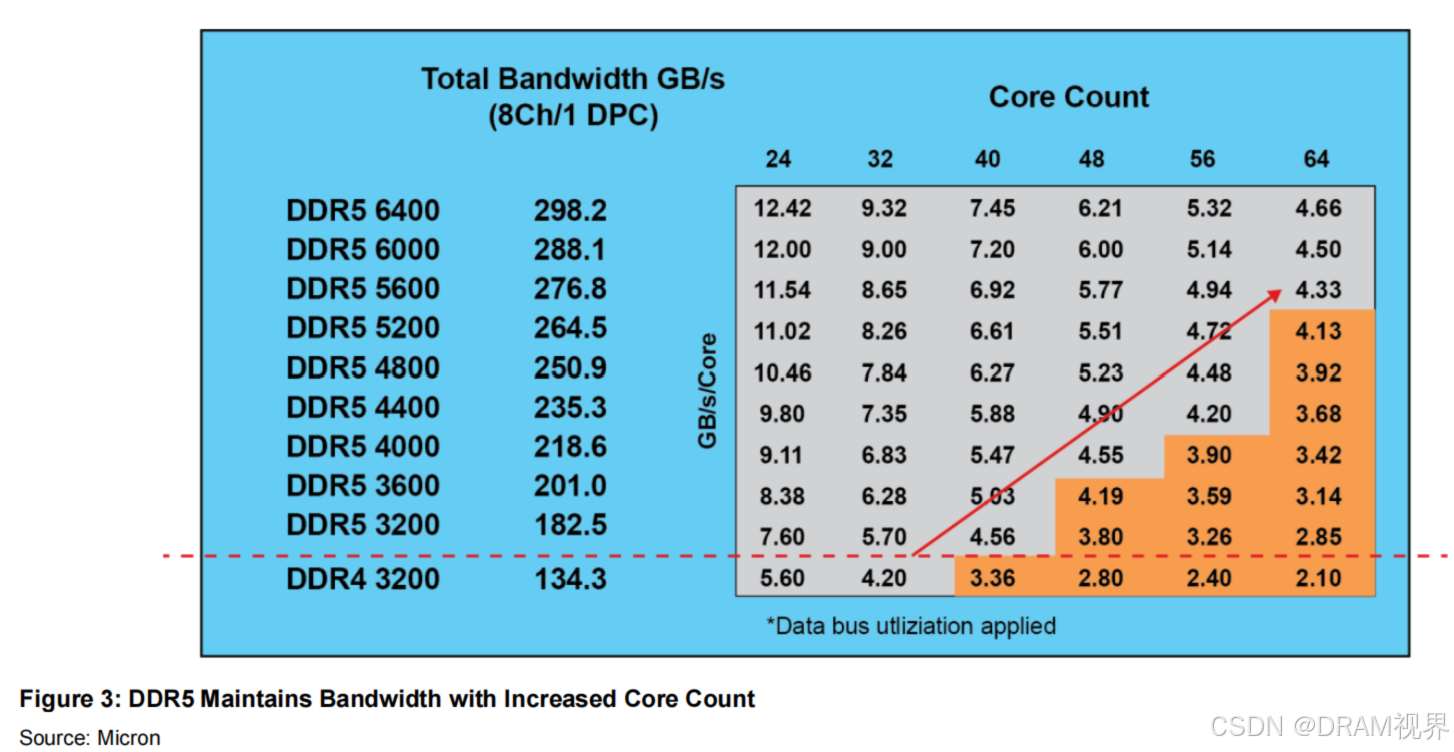
紫色的线是外部interface的datarates, 黄色的线是内部core array的访问的速度。可以看见外部interface的速度一直在提升,但是内部core array部分的速度其实基本维持不变。为什么呢?主要是prefetch随着DDR generation的演进在逐步增加。从SDRAM的pre-fetch=1到DDR3的pre-fetch=8. pre-fetch的深度就意味着可以从array里面一次访问能预取多少data。这就类似与并转串的概念,时分复用。通过增加一次读取array的数据的数量,从而interface上的speed只能提升才能把array里面的data及时处理完,从而datarates可以得到提升。而到了DDR5, pre-fetch进一步提升到了16(BL=16),那DDR5怎么解决64B的问题呢,DDR5主要是通过减小DQ数量到32个DQ来实现keep 64B的cache line的要求不变,同时keep DIMM上 follow DDR4相同数量的颗粒的前提下,增加了sub-channel的概念,相当于channel数量在DDR4的基础上提升了一倍,从而提升了bandwidth。
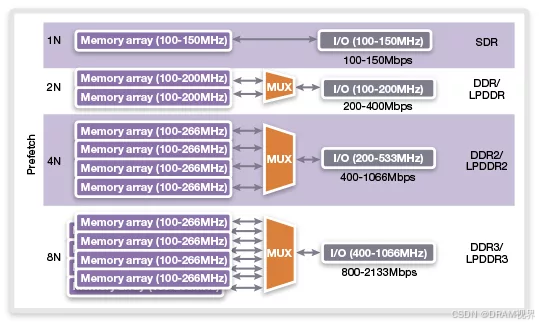
但是从DDR3到DDR4, prefetch并没有从8增加到16.其中一个原因是如果pre-fetch继续增加,对DDR4的一次访问数量将不再是64B(64B是cache line的大小), 一般的DDR系统的位宽是64个DQ,每个DQ上的突发长度是8(BL=8),就刚好一次读取DDR内存的数据量是64B,如果DDR4的prefetch增加到16,一次读取的数据量将变为128B,这个对于x86的cache line的访问上不友好,会造成效率上的损失。
Bankgroup
DDR4通过引入bank-group的概念来提升DDR4的性能。bank-group顾名思义,就是把几组bank单独分成一个group,再每个group里面采用pre-fetch=8, 但是bank-group之间采用类似ping-pong的interleave操作,从而近似于pre-fetch提升到了16,从而达到可以提升IO上的速度的目的。
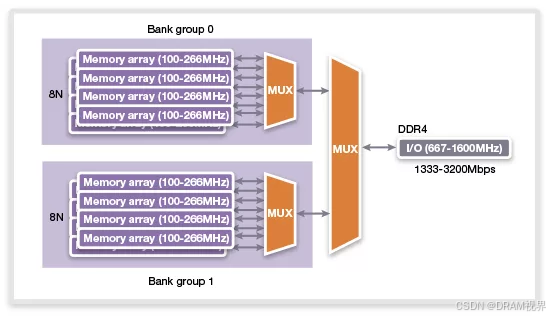
但是这种架构也带来了side effect.跨BG来访问的时候,write to write or read to read的CCD的timing可以做到无缝连接,但是同一个BG里面的bank之间的访问,却因为同Bankgroup内的data bus是common的,从而必须确保bus的data必须传送到bank内部之后,才能有下一比data过来,否则会导致内部的时间timing上如果卡的太紧的话,会有data conflict.
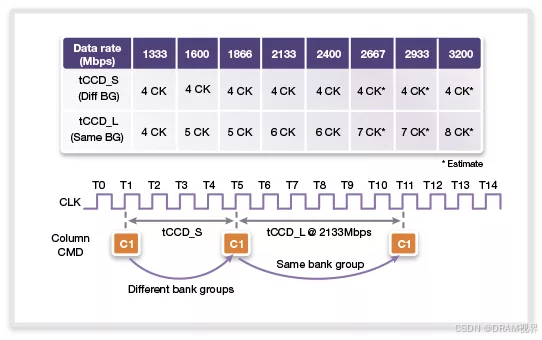
那么DDR4相对于DDR3,性能上的提升就没有那么明显了。CCD_L的存在导致了DDR4在bandwidth上有一定的损失存在。DDR5继续沿用了bankgroup的概念,而且在DDR4 16bank的数量基础上继续通过增加bank-group的数量把bank数量扩充到了32个。扩充bank数量是有效的,因为bank数量越多,对于控制器而言,就能有越多的机会开启更多的page数量来做到bank interleaving操作来实现seamless+gapless的访问memory,从而可以有效的提高page-hit ratio。
Refresh
DDR3到DDR4, refresh的操作基本没有变化,只是在DDR4上新增了一个FGR/TCR mode,目的其实主要是降功耗,但是对performance影响不大。这个地方很奇怪,LPDDR系列有refresh per-bank,但是到了DDR4的更新,也没有apply refresh per-bank的功能。但是到了DDR5,新增了REFSB的功能。REFSB(refresh same bank:不同BG里面的同一个bank可以同时刷新)可以有效减小tRFC(减小latency),减小peak power, 减小refresh带来的overhead,从而提高bandwidth.
Power
- 电压从DDR3的1.5V降到DDR4的1.2V再降到DDR5的1.1V。
- Apply refresh same bank and precharge same bank also can reduce peak current consumption
- DDR5的command pin做了更多的复用功能,能有效的减少CA pin数量,从而也能减少CA input buffer带来的电流损耗
Interface
- Vref pin,从DDR3的CA/DQ都有外部Vref pin,到DDR4的时候,拿掉了VrefDQ pin,到DDR5的时候,拿掉了VrefCA/VrefDQ pin的演进。这么做的好处是内部动态调节vref的值,能training到一个更加的值,确保有更多的maring,从而更有利于high speed的performance,另外,还能减少外部cost,节省了pin number,也节省了外部的vref generator.
- DDR5采用了更多pin的复用,参见前面的介绍
- DDR5 apply了MIR/CAI feature,从而可以更方便的对dual rank的PCB进行layout.因为dual rank的颗粒本身是处于背靠背的位置,通过MIR function基本可以减少layout走线的麻烦,直接一对一mapping就好了
- DDR5新增了loopback mode,这个就跟DDR5的测试有关。在未来更高速的IO上,测试开始要采用BERT来进行。BER在测试receiver的能力的时候,一方面,IO作为input的时候,设备无法灵活的切换到output mode,从而增加了loopback作为output pin来进行监测。一方面,为了更好的看receiver的能力,排除output的high speed因素带来的干扰,loopback pin采用了四分频的方式进行output。
- DDR5的CA/CK/CS开始有了ODT配置。这个也是为了更高速的信号的信号完整性来进行的。
- Command上在DDR5上新增了更多的multi-cycle的command,主要目的就是确保前期training的时候,command能有效的被DRAM detect到从而确保前期margin不是很好的时候可以有效的工作。LPDDR是通过先降频做training来实现。
Training
- 由于DDR3有外部的vrefCA/VrefDQ pin,所以内部无需做CA/DQ上voltage方向的training. 到了DDR4, remove了VrefDQ,从而内部增加了VrefDQ的voltage方向的training,到了DDR5, remove了VrefDQ/CS/CA,从而DDR5的training变得更为复杂,增加了CSTM/CATM training mode, DDR5新增了4-tap DFE,从而也需要增加DFE tap code的training.
- DDR5新增了LFSR,从而对read方向的training的pattern的选择可以更加灵活多变
- DDR4新增了CA Parity mode,从而DDR4也可以通过CA Parity来对CA信号进行training.这个功能比较鸡肋,DDR5 remove了
- DDR3 vs DDR4 vs DDR5都有write-leveling training.这是DIMM level fly-by架构带来的天性。DDR3 vs DDR4大同小异,但是到了DDR5的write-leveling,有了较大的变化,之前DDR4的write-leveling training在DDR5里面基本等同于external write leveling training, DDR5新增了internal write leveling training,基本目的是让DRAM内部path减短,从而可以减少PVT/power等带来的variation,也能降低功耗,for high speed是有好处的。
- DDR3 vs DDR4,基本可以不做perDQ training, perDQ之间的skew的影响不至于导致margin suffer太多,DDR5的时候,speed更高,需要apply perDQ training来获得更多的margin(不管是for read,还是for write)。针对这一点,DDR5 spec甚至定义了perDQ vrefDQ offset,从而可以让系统能apply perDQ给不一样的VrefDQ的值,来或许更多的RMT margin.
- DDR5开始有了tDQS2DQ training, DQSOSC tracing跟DCA training.这些training的应用都是为了更高的速度带来的挑战。其中tDQS2DQ training是因为到了DDR5, DQS跟DQ之间的internal phase开始有了gap,原因是因为DDR5 apply了DFE, DFE要求DQ的内部timing要做的尽可能的短,才能满足DFE的运算要求,而DQS从PAD进来到DQ里面去,必然会经过delay。那这部分delay就造成了DQS2DQ的timing gap.从而follow LPDDR开始有了tDQS2DQ跟DQSOSC的feature.
DRAM这部分的training算法/flow的演进基本都是为了更高速信号的更好的quality跟margin
RAS
ECC/ECS
DDR4在DDR3的基础上,增加了CA的CRC跟CA的奇偶校验来提升RAS性能,但是并没有在DQ上做什么(DQ上的improve策略是VrefDQ pin拿掉,采用internal training的方式提高margin), DDR5开始从spec remove了CA parity, remove了VrefCA/VrefCS,通过内部vref training来获取更多的margin,另外,DDR5增加了DQ的CRC校验来提升DQ上的监控。同时DDR5开始定义了on-die ECC的需求,并提出了ECS的概念(这个是Lowpower系列没有的). ECS要求24hrs内要偷偷的在refresh command里面检验一遍full array,如果data有错,ECS要纠错并对data进行纠错改写。
CRC
DDR4对CA做了CRC check, DDR5增加了对DQ的CRC check.或许再更高速的DDR5产品中会apply这个feature,但是在6400的DDR5产品上,目前没看到有此应用。原因大概率还是因为CRC不能纠错,另外,CRC产生的码流会增加DQ上的traffic,导致bandwidth受到影响,除非是更高速的DDR5,可以弥补这部分CRC code带来的性能损失。
RFM
RFM=Refresh managememt. 这个是DDR5才出现的feature. LPDDR5也有这个feature. DDR5 vs LPDDR5基本大同小异。目的是为了做row hammer的保护。DRAM对hammer的次数提供一个阈值,当controller发现hammer次数大于这个阈值后,会触发RFM command, RFM command做了什么呢?其实就是刷新。
PPR
DDR3没有PPR的功能。DDR4开始有了hPPR跟sPPR,到了DDR5,多出来了mPPR跟mBIST.
以上feature的演进,都是为了DRAM的RAS性能提出来的improve的方案。
Core Timing
随着DDR generation的演进,其实core-timing基本没什么变化。
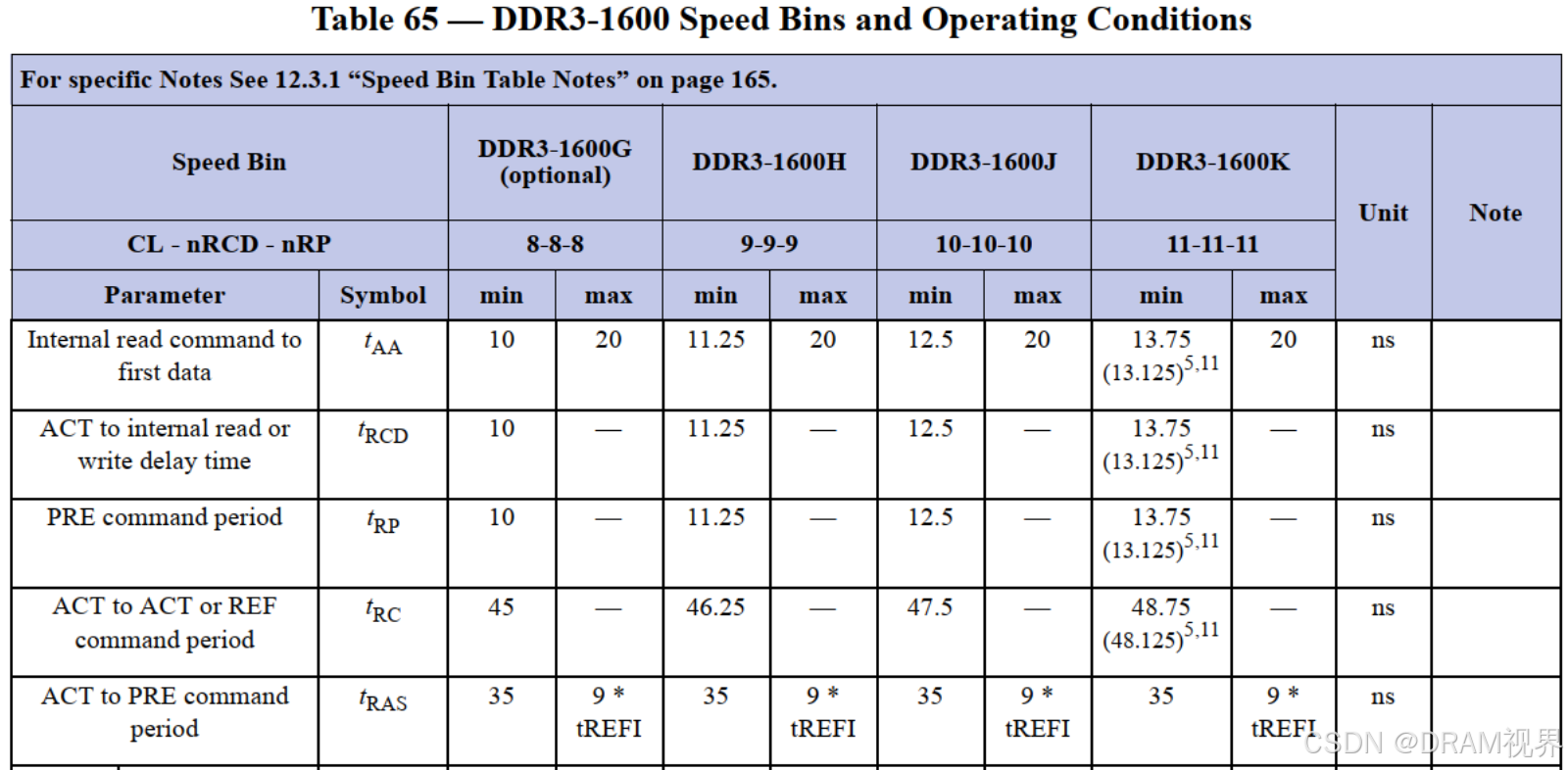
DDR3:(1600G/H/J/K属于不同的speed bin,代表不同的performance)
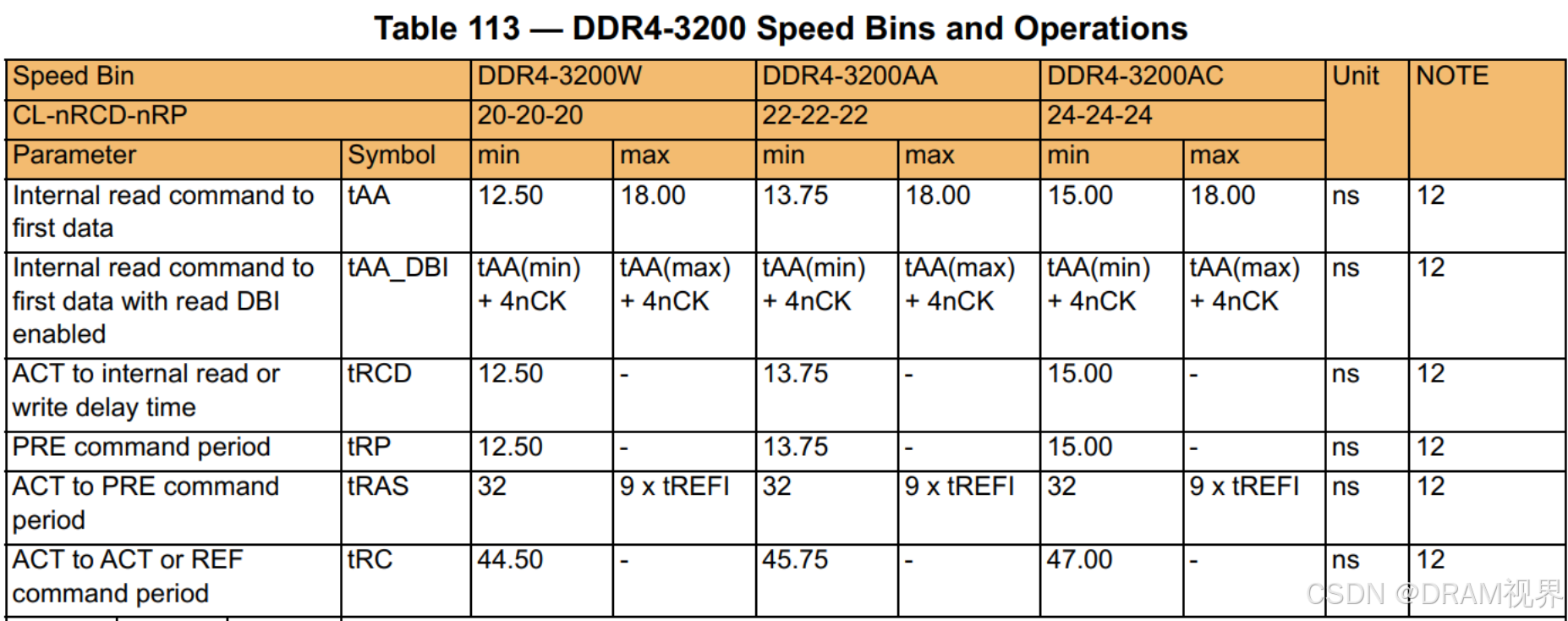
DDR4:(3200W/AA/AC代表不同的speed bin,代表不同的performance)
DDR5:(6400AN/B/BN/C代表不同的speed bin,不同的performance)
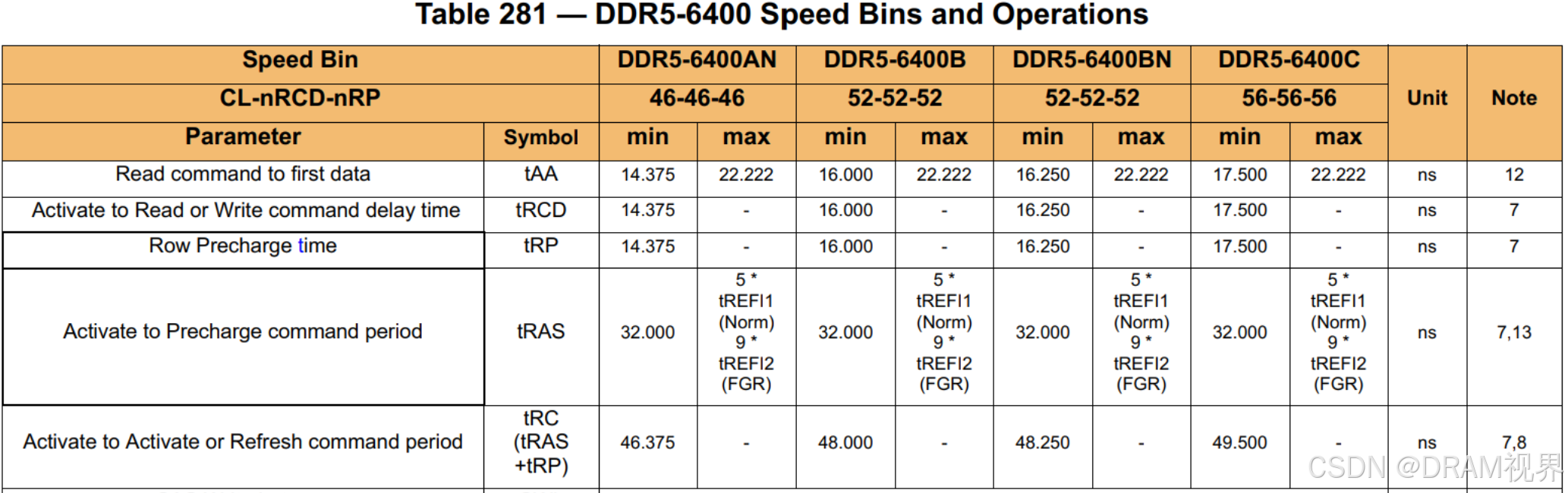
从上图的几代DDR的core-timing对比,其实基本没怎么变化。因为这些都不是cycle base的,是个绝对值。那么随着speed的更高更快,拿tAA举例子,变化的不是tAA,而是RL的cycle base的配置。
从DDR4到DDR5的演进,burst length由8到了16,在DDR4 3200Mbps的年代,DDR PHY的speed要做到1600MHz,controller的speeed要做到400MHz, 内外频率之比是1:4,那么到了DDR5, 内外频率之比是1:8, 从而对于controller而言,400MHz的controller speed,依然可以做到DDR5的6400Mbps.我们都拿tAA=16ns来计算。DDR4 3200的时候,RL要配置成26tCK, 对于DDR5 6400而言,RL要配置成52tCK.计算到controller的cycle base,latency并没有增加。有人说DDR5的RL变得那么大,latency变长了,性能反而会比DDR4还要差。这个是没有根据的。cycle数量是增加了,但是DDR5的speed也翻倍了,算上绝对时间,DDR5跟DDR4是一样的。DDR4 vs DDR5,即使同样的speed,性能上,也是DDR5更好。



















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











