







 本文详细介绍了如何使用Pytorch实现注意力机制,包括SelfAttention模块的构建和计算流程,以及MultiHeadAttention的扩展,通过实例演示了如何处理查询、键和值,计算注意力分数并生成加权输出。
本文详细介绍了如何使用Pytorch实现注意力机制,包括SelfAttention模块的构建和计算流程,以及MultiHeadAttention的扩展,通过实例演示了如何处理查询、键和值,计算注意力分数并生成加权输出。
Pytorch手撸Attention
注释写的很详细了,对照着公式比较下更好理解,可以参考一下知乎的文章
注意力机制
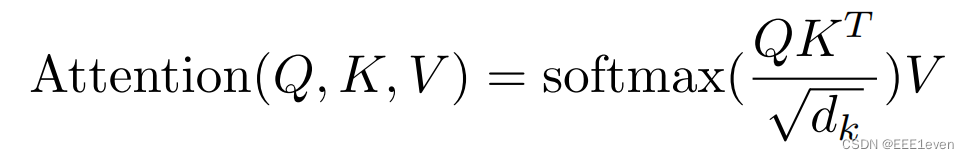
import torch
import torch.nn as nn
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_size):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
# 定义三个全连接层,用于生成查询(Q)、键(K)和值(V)
# 用Linear线性层让q、k、y能更好的拟合实际需求
self.value = nn.Linear(embed_size, embed_size)
self.key = nn.Linear(embed_size, embed_size)
self.query = nn.Linear(embed_size, embed_size)
def forward(self, x):
# x 的形状应为 (batch_size批次数量, seq_len序列长度, embed_size嵌入维度)
batch_size, seq_len, embed_size = x.shape
Q = self.query(x)
K = self.key(x)
V = self.value(x)
# 计算注意力分数矩阵
# 使用 Q 矩阵乘以 K 矩阵的转置来得到原始注意力分数
# 注意力分数的形状为 [batch_size, seq_len, seq_len]
# K.transpose(1,2)转置后[batch_size, embed_size, seq_len]
# 为什么不直接使用 .T 直接转置?直接转置就成了[embed_size, seq_len,batch_size],不方便后续进行矩阵乘法
attention_scores = torch.matmul(Q, K.transpose(1, 2)) / torch.sqrt(
torch.tensor(self.embed_size, dtype=torch.float32))
# 应用 softmax 获取归一化的注意力权重,dim=-1表示基于最后一个维度做softmax
attention_weight = F.softmax 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3199
3199

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











