







目录
命名空间this_thread中的sleep_for()&&sleep_until()
recursive_mutex 类&recursive_timed_mutex类
condition_variable类&condition_variable_any类
前情提要
如果你接触过单片机的RTOS,或者是Linux的话,再看这一部分内容可能也就一天时间就明白里面讲的是什么,因为这一些内容很多都是一通百通的。自C++11开始加入了线程库之后,就有封装好的模块调用,这样就很方便实现多线程的功能。


学习工具
因为草鸟工具的C++好像没有thread库,所以没办法,我换了另外一个轻量级IDE。

后面都是基于这个IDE讲的。
什么是线程?
可能你很久很久以前写C的时候,几乎都是写好几个子函数,然后扔到main里面调用执行,并且跑一趟。如果需要做一个轮询系统,那就需要把这一些子函数扔到main的循环体里面(做嵌入式裸机开发的时候可能会这样做)。如果你有点经验,你可能会把前面说的轮询系统写成前后台系统。或者,你会写成一个状态机。
后来,你可能接触了RTOS或者Linux,你开始应用这一些系统,于是你就接触到线程这样的东西。因为做嵌入式的主控大多都是单核的,所以如何榨干CPU的性能,几乎成了每个工程师都要考虑的问题(尽可能在有限资源里面发挥最好性能)。
打个比如,在RTOS里面,有一个任务调度器(UOS\FreeRTOS\RT-Thread\鸿蒙等等都有),用户将一个个任务设计好时间片长度,然后放入调度器,这样就可以实现“看上去多线程并行”的样子。在这里,任务就是写出来的线程,本质就是安排好每个线程占用CPU的时间,然后开启调度。相当于告诉CPU在什么时候做什么事情,减少CPU的空闲时间,提高CPU使用率。
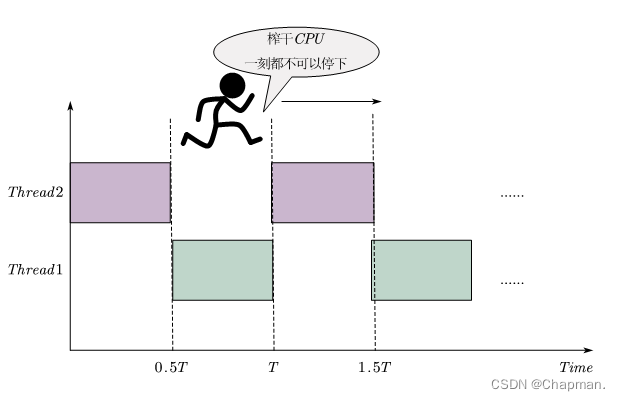
而在多核CPU里面就不是在这么一个说法了。
真假并发
其实对于单核的CPU来讲(拿个单片机来说),你所看到“同时多线程进行”,其实只是系统安排好时间片,然后到点了就执行不同任务而已。换句话说,就是一个CPU在多个任务之间“反复横跳”而已,这个就是假并发(某种程度上也叫轮询)。对于多核CPU来讲,首先假如这是一个4核CPU。那么,我现在有四个任务,我把每个任务分配给不同的CPU去完成,这个就是真并发了(一个核跑一个任务)。如果我一个核可以跑4个线程,那么,四个核就可以跑16个线程。
无论是C++,还是java(我没学过,但是稍微了解一下,毕竟我不是搞软件的,学太多也难搞。)等等乱七八糟的,你要搞高并发,首先你的硬件必须允许你这么搞(打个比如你用的是一个单核处理器,你的高并发真的很有限)。其次,这一些计算机软件语言,这些方法,这些架构只是用来榨干硬件的性能(这就是你学习这些东西的根本原因)。用最少的资源,实现最大化的性能。但这是有极限大的,硬件的封顶性能就是你榨干CPU的极限(超频可不是好办法,如果散热做的好的话就另说。毕竟对于半导体来说,损耗是跟着频率上去的。还有一个就是结温,长时间超过这一个限度,会导致半导体损坏烧毁。其次是半导体的物理特性,工作频率超过一定值,信号开始出现失真状况,毕竟是有死区的,有可能导致整个系统跑飞)。所以讨论真假并发这个我觉得意义不大,而是应该更多讨论:如何把尽可能多的任务往这个系统里面塞,而且确保这些任务可以安全的,稳定的运行。只要你塞的任务越多,你的任务运行越稳定,越安全,那么你的办法就是好办法(记得还要便于维护和拓展)。
关于你可能学过的RTOS的线程创建
以RT-Thread为例子,建立一个动态线程(就是可以随时创建,使用完销毁,其运行内存动态分配),它的代码如下:
#include "board.h"
#include "rtthread.h"
/*
*************************************************************************
* 变量
*************************************************************************
*/
/* 定义线程控制块指针 */
static rt_thread_t led1_thread = RT_NULL;
/*
*************************************************************************
* 函数声明
*************************************************************************
*/
static void led1_thread_entry(void* parameter);
/*
*************************************************************************
* main 函数
*************************************************************************
*/
int main(void)
{
/* 线程控制块指针 */
led1_thread = rt_thread_create( "led1", /* 线程名字 */
led1_thread_entry, /* 线程入口函数 */
RT_NULL, /* 线程入口函数参数 */
512, /* 线程栈大小 */
3, /* 线程的优先级 */
20); /* 线程时间片 */
/* 启动线程,开启调度 */
if (led1_thread != RT_NULL)
rt_thread_startup(led1_thread);
else
return -1;
}
/*
*************************************************************************
* 线程定义
*************************************************************************
*/
static void led1_thread_entry(void* parameter)
{
while (1)
{
LED1_ON;
rt_thread_delay(500); /* 延时 500 个 tick */
LED1_OFF;
rt_thread_delay(500); /* 延时 500 个 tick */
}
}
/*******************************END OF FILE****************************/在建立线程的过程如下:先定义线程的控制模块的指针(暂且先指向NULL),再定义线程函数:led1_thread_entry(),最后再主函数main里面启动这一个线程的调度器即可(把前面创建的led1_thread线程控制模块指针指向线程构造函数rt_thread_creat,并且对里面传参。其中包括了:1、线程名称,用于使用msh功能的时候可以参看进程功能;2、线程函数入口;3、线程分配空间大小;4、线程的优先级;5、线程占用CPU的时间长)。
C++线程创建
和RTOS一样,C++实现多个线程同时进行,就需要用到一些库函数创建线程。在C++11这一个版本之后(2011发布),就多了<thread>(注意:如果你是在Linux上面敲C++代码,那么你可能用到的是<pthread>,作用都差不多)这一个模块,用户可以使用这一个模块里面的功能实现多线程的建立。
下面有这个例子(用printf的原因是,一开始打印信息就乱序):
#include <iostream>
#include <thread>
#include <ctime>
#include <stdio.h>
using namespace std;
void Delay(int time)//time*1000为秒数
{
clock_t now = clock();
while(clock() - now < time);
}
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
Delay(500);
}
}
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
Delay(400);
}
}
int main()
{
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t1.detach();
printf("主线程任务开始执行!\r\n");
for(int main_i=0; main_i<= 50; main_i++)
{
printf("num_main = %d \r\n",main_i);
Delay(50);
}
printf("主线程任务结束!\r\n");
/*让线程t2都执行完了才跑完主线程main*/
t2.join();
cout << "END"<<endl;
return 0;
}结果是:
开始运行...
t2创建成功!
num2 = 0
t1创建成功!
主线程任务开始执行!
num_main = 0
num1 = 0
num_main = 1
num_main = 2
num_main = 3
num_main = 4
num2 = 1
num_main = 5
num_main = 6
num_main = 7
num1 = 1
num_main = 8
num_main = 9
num_main = 10
num_main = 11
num2 = 2
num_main = 12
num_main = 13
num_main = 14
num_main = 15
num_main = 16
num1 = 2
num_main = 17
num_main = 18
num2 = 3
num_main = 19
num_main = 20
num_main = 21
num_main = 22
num_main = 23
num_main = 24
num1 = 3
num_main = 25
num2 = 4
num_main = 26
num_main = 27
num_main = 28
num_main = 29
num_main = 30
num_main = 31
num2 = 5
num1 = 4
num_main = 32
num_main = 33
num_main = 34
num2 = 6
num_main = 35
num_main = 36
num1 = 5
num_main = 37
num_main = 38
num_main = 39
num_main = 40
num_main = 41
num2 = 7
num_main = 42
num_main = 43
num_main = 44
num1 = 6
num_main = 45
num_main = 46
num_main = 47
num2 = 8
num_main = 48
num_main = 49
num_main = 50
主线程任务结束!
num1 = 7
num2 = 9
num2 = 10
num1 = 8
END
运行结束。可以看到,线程t1、t2、主函数main(主线程)都一起跑起来了。
thread
从上面的例子可以看出,thread就相当于一个类。在创建线程的时候,相当于使用thread这一个构造函数(对象就是线程函数,关于构造函数,可以看一下:这一篇C++里面类的构造函数),把线程构造出来,并且向里面传参(传入线程函数的入口、线程函数的参数表)。当构造好这一个线程之后,线程就可以自己跑起来(就是thread构造好之后线程就立刻跑起来)。
join
关于join的作用,可以看作是让子线程都加入到main里面,main要等待子线程都跑完之后才可以关闭。不然,主线程就不会管子线程跑完没跑完,只要主线程跑完就关闭,结果是造成子线程没跑完就一起被关闭了,所以加入jion的地方一般在主线程任务的后面。
detach
一般地,如果要使用detach,就需要跟在线程构造完成之后。它的作用是,让指定线程在主线程main跑完之后,剥离出去归系统管理,这个也叫守护进程。所以在上面的例子输出结果里面可以看到,t1、t2、主线程三个线程一起跑的时候,主线程是等待t2线程跑完才关闭。但是在t2线程跑完之后,t1线程才跑到第八次,还有两次才跑完。这时候,主线程已经关闭了,结果是t1线程被剥离出这一个主线程,归系统管了,所以后面输出两次的内容就没显示出来。
线程资源回收
一般地,当线程执行完成之后,就会被系统回收其运行空间。因为C++已经把线程回收的步骤封装好,只要使用了join和detah,子线程跑完就会自己回收。下面有一个例子:
#include <iostream>
#include <thread>
#include <ctime>
#include <stdio.h>
using namespace std;
void Delay(int time)//time*1000为秒数
{
clock_t now = clock();
while( clock() - now < time );
}
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
Delay(500);
}
}
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
Delay(400);
}
}
int main()
{
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t1.detach();
printf("主线程任务开始执行!\r\n");
for(int main_i=0; main_i <= 15; main_i++)
{
printf("num_main = %d \r\n",main_i);
Delay(200);
}
printf("主线程任务结束!\r\n");
return 0;
/*让线程t2都执行完了才跑完主线程main*/
t2.join();
}
执行结果是:
Could not disable address space layout randomization (ASLR).
t2创建成功!
num2 = 0
num1 = 0
t1创建成功!
主线程任务开始执行!
num_main = 0
num_main = 1
num2 = 1
num_main = 2
num1 = 1
num_main = 3
num2 = 2
num_main = 4
num1 = 2
num_main = 5
num2 = 3
num_main = 6
num_main = 7
num2 = 4
num1 = 3
num_main = 8
num_main = 9
num2 = 5
num1 = 4
num_main = 10
num_main = 11
num2 = 6
num1 = 5
num_main = 12
num_main = 13
num2 = 7
num_main = 14
num1 = 6
num_main = 15
num2 = 8
主线程任务结束!
terminate called without an active exception
Stop reason: signal SIGABRT可以看到把return 0放到了t2.join()前面,当主线程跑完之后,很明显可以看到线程t2还没跑完就被终止了。t1是因为在建立线程之后就被设置成守护线程,因此被挪到主线程以外由系统接管。而t2因为还没运行完,被return 0结束了主线程从而被回收资源,也就没有执行join,所以就不能往下执行。
线程回收方法
为了保证线程安全,稳定运行,每次建立一个线程的时候,就需要对应使用一次join()或者detach()。使用join()时候,主线程就需要等待该子线程运行完毕之后再返回,然后主线程关闭统一回收资源。使用detach()时候,子线程剥离出去主线程,即使主线程运行完毕,该子线程还会在后台运行并且交由系统管理。调用detach()的线程,在运行完毕之后,系统自动回收其资源。
注意,当使用了detach()之后,就不能再使用join(),因为此时该线程已经从主线线程分离出去。所以,主线程不能再操作该子线程。
关于joinable()的使用
该成员函数可以用于判断线程的分离状态,返回的是布尔类型。例子如下:
#include <iostream>
#include <thread>
#include <ctime>
#include <stdio.h>
using namespace std;
void Delay(int time)//time*1000为秒数
{
clock_t now = clock();
while( clock() - now < time );
}
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
Delay(500);
}
}
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
Delay(400);
}
}
int main()
{
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t1.detach();
printf("主线程任务开始执行!\r\n");
for(int main_i=0; main_i <= 15; main_i++)
{
printf("num_main = %d \r\n",main_i);
Delay(200);
}
printf("主线程任务结束!\r\n");
/*让线程t2都执行完了才跑完主线程main*/
printf("t2线程返回状态 %d\r\n",t2.joinable());
if(t2.joinable())
{
t2.join();
}
cout << "END"<<endl;
return 0;
}
结果是:
开始运行...
t2创建成功!
num2 = 0
t1创建成功!
主线程任务开始执行!
num_main = 0
num1 = 0
num_main = 1
num2 = 1
num_main = 2
num1 = 1
num_main = 3
num2 = 2
num_main = 4
num1 = 2
num_main = 5
num2 = 3
num_main = 6
num_main = 7
num2 = 4
num1 = 3
num_main = 8
num_main = 9
num2 = 5
num1 = 4
num_main = 10
num_main = 11
num2 = 6
num_main = 12
num1 = 5
num_main = 13
num2 = 7
num_main = 14
num1 = 6
num_main = 15
num2 = 8
主线程任务结束!
t2线程返回状态 1
num1 = 7
num2 = 9
num2 = 10
num1 = 8
END
运行结束。
当使用joinable()之后,如果joinable()返回1,则说明对应线程未分离出去,这时候可以进行join或者detach。
命名空间this_thread
C++11里面提供了一个命名空间this_thread。在这一个命名空间里面,一共有以下四个函数,分别是:get_id()、sleep_for()、sleep_until()以及yield()。另外,在这一部分再讲一下以下几个函数的功能,它们分别是:swap()、move()。下面是例子:
#include <iostream>
#include <thread>
#include <stdio.h>
using namespace std;
void task_1(int start, int end)
{
cout << "t1程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
//休眠两秒
this_thread::sleep_for(chrono::seconds(2));
}
}
void task_2(int start, int end)
{
cout << "t2程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
//立即让出线程占用CPU资源
//this_thread::yield();
//休眠一秒
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
cout << "主程返回id: "<<this_thread::get_id()<<endl;
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
cout << "主程返回t1id: "<<t1.get_id()<<endl;
cout << "主程返回t2id: "<<t2.get_id()<<endl;
t1.swap(t2);
cout << "交换后t1id: "<<t1.get_id()<<endl;
cout << "交换后t2id: "<<t2.get_id()<<endl;
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t2.detach();
/*t1转移线程资源到t3*/
thread t3 = move(t1);
cout << "t1转移资源后t3id: "<<t3.get_id()<<endl;
printf("t3线程返回状态 %d\r\n",t3.joinable());
if(t3.joinable())
{
t3.join();
}输出结果是:
开始运行...
主程返回id: 140167245567808
t2创建成功!
t2程返回id: 140167245563648
num2 = 0
t1程返回id: 140167237170944
num1 = 0
t1创建成功!
主程返回t1id: 140167237170944
主程返回t2id: 140167245563648
交换后t1id: 140167245563648
交换后t2id: 140167237170944
t1转移资源后t3id: 140167245563648
t3线程返回状态 1
num2 = 1
num1 = 1
num2 = 2
num2 = 3
num1 = 2
num2 = 4
num2 = 5
num1 = 3
num2 = 6
num2 = 7
num1 = 4
num2 = 8
num2 = 9
num1 = 5
num2 = 10
END
运行结束。命名空间this_thread中的get_id()
在上面的代码里面,有这样的语句:“this_thread::get_id()”、“t1.get_id()”或者是“t2.get_id()”。这一些语句都是用来获取当前程序线程的所用到的函数。假如使用的是:“this_thread::get_id()”,那么,它输出的结果是,它所在线程的id号。例如:“this_thread::get_id()”在t1线程函数里面,则输出t1线程的id。例如:“this_thread::get_id()”在主线程里面,则输出主线程的id。假如使用的是:“t1.get_id()”,则输出为被指定的t1线程id。每一运行时候,每个线程的id号都会不一样。
命名空间this_thread中的sleep_for()&&sleep_until()
在上面的代码里面,有这样的语句:"this_thread::sleep_for(chrono::seconds(2))",这个的作用是,要把当前运行的线程休眠,并且让出CPU资源。里面的参数是一个时间,里面使用到的是命名空间chrono的seconds()函数,这一个函数用于计时用。所以在“this_thread::sleep_for()”,这样的语句经常被用于线程精确延时,精确计时休眠的。
关于sleep_until(),这个和sleep_for()的作用相类似。只不过sleep_until()的作用是,让线程延时到指定的时间,例如精确延时到2044年太空电梯危机当天的早上2点30分再启动这条线程。但是务必请在这个线程休眠期间请保证代码是一直跑着的,并且没有被detach出去。但是这个东西实际上很少人用。
命名空间this_thread中的yield()
上面的代码把:“this_thread::yield()”注释掉,是因为我不把它注释掉的话,当前线程会跑的很快,并且很快跑完,结果都不明显。下图是没注释下跑出来的结果:
开始运行...
主程返回id: 139841764710208
t2创建成功!
t2程返回id: 139841764706048
num2 = 0
num2 = 1
num2 = 2
num2 = 3
num2 = 4
num2 = 5
num2 = 6
num2 = 7
num2 = 8
num2 = 9
num2 = 10
t1创建成功!
主程返回t1id: 139841756313344
主程返回t2id: 139841764706048
t1程返回id: 交换后t1id: 139841764706048
交换后t2id: 139841756313344
139841756313344t1转移资源后t3id: 139841764706048
t3线程返回状态 1
END
num1 = 0
运行结束。因为使用了yield(),t2线程瞬间跑完了。这个函数的作用是:立即让出当前线程所占用CPU的资源。这个函数主要用于紧急处理一些特殊情况之后,确保整个系统的实时性,对其他线程的影响减少到最低。在RTOS里面,也有类似的功能函数,其实可以参考一下它们,功能几乎相同。
swap()&move()
这一个函数是在thread类里面的,是用于把两个线程所占有的资源交换。在上面的例子可以看到,在使用“ t1.swap(t2)”之后,t1线程和t2线程的资源发生了交换。所以,后续t1的线程id和t2线程的id也互换了。
在thread类里面线程是不能拷贝的,但是可以转移资源。因此,move()的作用就是用于转移线程资源的。例如使用" thread t3 = move(t1); "之后,其意思是:创建一个thread类的对象t3,并且把t1的资源转移到t3上面。转移之后,t3就是原来的t1线程。
call_once()
就跟名字一样,这个函数名字:呼叫一次。这一个函数作用是,让传参进来的函数只允许被调用一次。这一个函数是属于<mutex>里面的,所以使用这个函数的时候,请务必把<mutex>包含进来。例子如下:
#include <iostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//once_flat全局变量,是一个bool的锁
once_flag once;
//用于被调用一次函数
void func_once(int start)
{
printf("once num = %d \r\n",start);
}
void task_1(int start, int end)
{
call_once(once, func_once, 1);
cout << "t1程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
//休眠两秒
this_thread::sleep_for(chrono::seconds(2));
}
}
void task_2(int start, int end)
{
call_once(once, func_once, 2);
cout << "t2程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
//立即让出线程占用CPU资源
//this_thread::yield();
//休眠一秒
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
cout << "主程返回id: "<<this_thread::get_id()<<endl;
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
cout << "主程返回t1id: "<<t1.get_id()<<endl;
cout << "主程返回t2id: "<<t2.get_id()<<endl;
t1.swap(t2);
cout << "交换后t1id: "<<t1.get_id()<<endl;
cout << "交换后t2id: "<<t2.get_id()<<endl;
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t2.detach();
/*t1转移线程资源到t3*/
thread t3 = move(t1);
cout << "t1转移资源后t3id: "<<t3.get_id()<<endl;
printf("t3线程返回状态 %d\r\n",t3.joinable());
if(t3.joinable())
{
t3.join();
}
cout << "END"<<endl;
return 0;
}
运行结果是:
开始运行...
主程返回id: 139738439292736
t2创建成功!
once num = 2
t1创建成功!
t1程返回id: 主程返回t1id: 139738430895872139738430895872
主程返回t2id: 139738439288576
交换后t1id: 139738439288576
交换后t2id: 139738430895872
t1转移资源后t3id: 139738439288576
t3线程返回状态 1
t2程返回id: 139738439288576
num1 = 0
num2 = 0
num2 = 1
num1 = 1
num2 = 2
num2 = 3
num1 = 2
num2 = 4
num2 = 5
num1 = 3
num2 = 6
num2 = 7
num1 = 4
num2 = 8
num2 = 9
num1 = 5
num2 = 10
END
运行结束。可以看到once函数只有被调用了一次。要使用call_once()函数,就需要把<mutex>包含进来。然后定义一个once_flat全局变量,这是一个bool的锁。在使用call_once()往里面传参,其中第一个参数为:once_flat变量,第二个参数为被调用函数名(也就是被调用函数入口),后面的参数就是被调用函数的参数,如果没有就不用填。
关于有人用call_once()函数调用所在的线程函数,这个我没试过,也不打算试。我觉得可以但没必要,我知道肯定会出问题。其实这个和做这么一个实验是一样的:把一个线程用线程锁上锁之后再把这个线程挂起一样。这一些问题都没什么可讨论的,肯定会出问题。
线程控制语句柄获取native_handle()
在thread类里面,使用native_handle(),实现对指定线程的控制语句柄获取。如果需要对一个线程进行操作,但是这一些操作是C++11里面并没有的。那么,可以通过调用native_handle()获取线程的控制语句柄,再把控制语句柄传参到操作函数里面,实现对线程的控制。下面是例子:
#include <iostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//once_flat全局变量,是一个bool的锁
once_flag once;
//用于被调用一次函数
void func_once(int start)
{
printf("once num = %d \r\n",start);
}
void task_1(int start, int end)
{
call_once(once, func_once, 1);
cout << "t1程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num1 = %d \r\n",i);
//休眠两秒
this_thread::sleep_for(chrono::seconds(2));
}
}
void task_2(int start, int end)
{
call_once(once, func_once, 2);
cout << "t2程返回id: "<<this_thread::get_id()<<endl;
for(int i=start; i<= end; i++)
{
printf("num2 = %d \r\n",i);
//立即让出线程占用CPU资源
//this_thread::yield();
//休眠一秒
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
cout << "主程返回id: "<<this_thread::get_id()<<endl;
thread t2(task_2,0,10);
printf("t2创建成功!\r\n");
printf("打印t2语句柄: %d\r\n",t2.native_handle());
thread t1(task_1,0,10);
printf("t1创建成功!\r\n");
cout << "主程返回t1id: "<<t1.get_id()<<endl;
cout << "主程返回t2id: "<<t2.get_id()<<endl;
t1.swap(t2);
cout << "交换后t1id: "<<t1.get_id()<<endl;
cout << "交换后t2id: "<<t2.get_id()<<endl;
/*让线程t1在跑完主线程main之后剥离出去,归系统管理,独立出来一条主线程*/
t2.detach();
/*t1转移线程资源到t3*/
thread t3 = move(t1);
cout << "t1转移资源后t3id: "<<t3.get_id()<<endl;
printf("t3线程返回状态 %d\r\n",t3.joinable());
if(t3.joinable())
{
t3.join();
}
cout << "END"<<endl;
return 0;
}
输出结果里面有一行显示了:
打印t2语句柄: -1404086528这一句话是通过thread类的native_handle()传递出来的参数。例如在Linux里面,使用下面一个类型变量:<pthread>里面的pthread_t,然后往里面赋上线程控制语句柄的值。再把pthread_t类型的控制语句柄传递到函数pthread_cancel()里面,就可以实现把当前线程中断。
线程的安全性
在一个进程中的所有子线程中,如果多个线程同时访问或者操作同一个资源,就有可能发生数据出错的情况。这个例如前面的例子中,发生了打印输出数据乱序的情况,这个就是线程之间没有良好的安全措施保证所导致的。
特别是在使用cout打印数据的时候,机会都会出现打印内容乱序的情况。有一个原因是因为,cout本身是个容器,它不小心把好几个线程成的打印数据存放到里面去,而且顺序出现了错误。其次,是因为线程之间没有做好CPU资源的保护导致的。
如果要实现线程之间安全运行,就需要遵循下面的原则:
1、可见性:一个线程对一个资源操作的时候,其他线程都要知道。
2、原子性:把一套操作完整进行,不能分隔开。要么全部执行,要么全部不执行。
3、顺序性:代码执行应该按照代码编写顺序执行,一定要注意编译器可能把你的代码进行了优化。
保证线程安全的方法
要确保线程安全运行,有以下几个方法:使用volatile(用于保证代码按顺序执行,不被编译器优化;以及保证变量的可见性)、使用原子操作(确保线程操作的完整性)、使用锁(保证线程在执行过程中不被打断,以确保线程的安全运行)。
互斥锁的类型
互斥锁是一种线程操作访问共享资源的安全防护机制。它可以确保在每一段时间之内,只有一个线程对共享资源进行操作。在访问操作之前给资源上锁,并且占有CPU资源,在完成访问操作之后给资源解锁,并且让出CPU资源。C++11 里面,提供了四种互斥锁:互斥锁(mutex)、带超时机制的互斥锁(timed_mutex) 、递归互斥锁(recursive_mutex)、带超时机制的递归互斥锁(recursive_timed_mutex)。
mutex类
这个类里面的互斥锁,是不带任何特殊功能的互斥锁。这个类里面的从成员一共有三个:lock()、unlock()以及try_lock()。其中:
lock()的作用是让调用它的线程上锁,该线程上锁之后,其他线程无法访问操作共享资源(包括CPU占有权)。只要有一条线程上锁了,其他线程都处于阻塞状态。
unlock()的作用是让调用它的线程解锁,调用这个函数的前提是,这个线程之前是已经上锁的。只要这一条线程解锁了,其他线程就可以占有共享资源并且上锁。
try_lock()的作用是,让一条调用它的线程在不确定有没有其他线程上锁的情况下,申请是否能给自己上锁。如果能上锁,则该线程自动给自己上锁。并且,这一个函数有一个bool类型的返回值,如果上锁成功,则返回1,失败则返回0,并且不再等待(阻塞)。注意:失败是返回0不再等待。
下面是例子:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//这个互斥锁用于保护cout资源
mutex mtx;
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
mtx.lock();
cout<<"num1 = "<<i<<endl;
mtx.unlock();
//休眠2秒
this_thread::sleep_for(chrono::seconds(1));
}
}
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
//尝试上锁
printf("上锁是否成功?%d \r\n",mtx.try_lock());
cout<<"num2 = "<<i<<endl;
mtx.unlock();
//休眠2秒
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
thread t1(task_1,0,3);
printf("t1创建成功!\r\n");
thread t2(task_2,0,3);
printf("t2创建成功!\r\n");
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout << "END"<<endl;
return 0;
}运行结果是:
开始运行...
t1创建成功!
num1 = 0
t2创建成功!
上锁是否成功?1
num2 = 0
上锁是否成功?1
num2 = 1
num1 = 1
上锁是否成功?1
num2 = 2
num1 = 2
上锁是否成功?1
num2 = 3
num1 = 3
END
运行结束。可以看到,经过上锁处理之后,使用cout再也没有出现打印乱序的情况发生。说明上锁之后有效保护了线程使用公共资源的安全性。其实,这一个功能可以满足绝大部分应用场景。
timed_mutex类
在这一个类里面,比mutex类增加了两个成员:try_lock_for()和try_lock_until()。这两个函数都是定时等待的。其中try_lock_for()的作用是,给定函数一个精确的定时时间,如果在这个时间里面尝试成功上锁,则返回bool类型1,否则返回bool类型0,并且不在等待。参数是赋予前面讲过的命名空间chrono的函数,例如:try_lock_for(chrono::seconds(1))。而另外一个函数try_lock_until()的作用是,传入一个准确的时间,然后在这个时间到达之前一直尝试上锁。超过这个时间之后,线程不再等待。例子如下:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//这个互斥锁用于保护cout资源
timed_mutex mtx;
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
mtx.lock();
cout<<"num1 = "<<i<<endl;
mtx.unlock();
//休眠2秒
this_thread::sleep_for(chrono::seconds(1));
}
}
void task_2(int start, int end)
{
int ret = 0;
for(int i=start; i<= end; i++)
{
//尝试在1秒内上锁
ret = mtx.try_lock_for(chrono::seconds(1));
printf("上锁是否成功?%d \r\n",ret);
cout<<"num2 = "<<i<<endl;
mtx.unlock();
//休眠2秒
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
thread t1(task_1,0,3);
printf("t1创建成功!\r\n");
thread t2(task_2,0,3);
printf("t2创建成功!\r\n");
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout << "END"<<endl;
return 0;
}
结果是:
开始运行...
t1创建成功!
num1 = 0
t2创建成功!
上锁是否成功?1
num2 = 0
num1 = 1
上锁是否成功?1
num2 = 1
num1 = 2
上锁是否成功?1
num2 = 2
num1 = 3
上锁是否成功?1
num2 = 3
END
运行结束。可以看到,线程尝试1秒内成功上锁。
recursive_mutex 类&recursive_timed_mutex类
先看下面的例子:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//这个互斥锁用于保护cout资源
recursive_mutex mtx;
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
mtx.lock();
cout<<"num2 = "<<i<<endl;
mtx.unlock();
}
}
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
mtx.lock();
cout<<"num1 = "<<i<<endl;
task_2(0, 3);
mtx.unlock();
this_thread::sleep_for(chrono::seconds(1));
}
}
int main()
{
thread t1(task_1,0,3);
printf("t1创建成功!\r\n");
thread t2(task_2,0,3);
printf("t2创建成功!\r\n");
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout << "END"<<endl;
return 0;
}输出出结果是:
开始运行...
t1创建成功!
num1 = 0
t2创建成功!
num2 = 0
num2 = 1
num2 = 2
num2 = 3
num2 = 0
num2 = 1
num2 = 2
num2 = 3
num1 = 1
num2 = 0
num2 = 1
num2 = 2
num2 = 3
num1 = 2
num2 = 0
num2 = 1
num2 = 2
num2 = 3
num1 = 3
num2 = 0
num2 = 1
num2 = 2
num2 = 3
END
运行结束。这是典型的“锁中锁”问题,因为这段代码使用的递归锁(recursive_mutex类的互斥锁),所以可以实现“锁中锁”的问题。因为原本的t1和t2是两个不同的线程,而t1线程又的调用了t2线程的执行函数。导致给t1上锁之后调用了t2又给t2上锁,形成一个“死锁”。那么,递归锁就相当于把这个互斥锁分成了两把,先上锁的后解锁,这样就完美解决这一个问题。原理如下图:
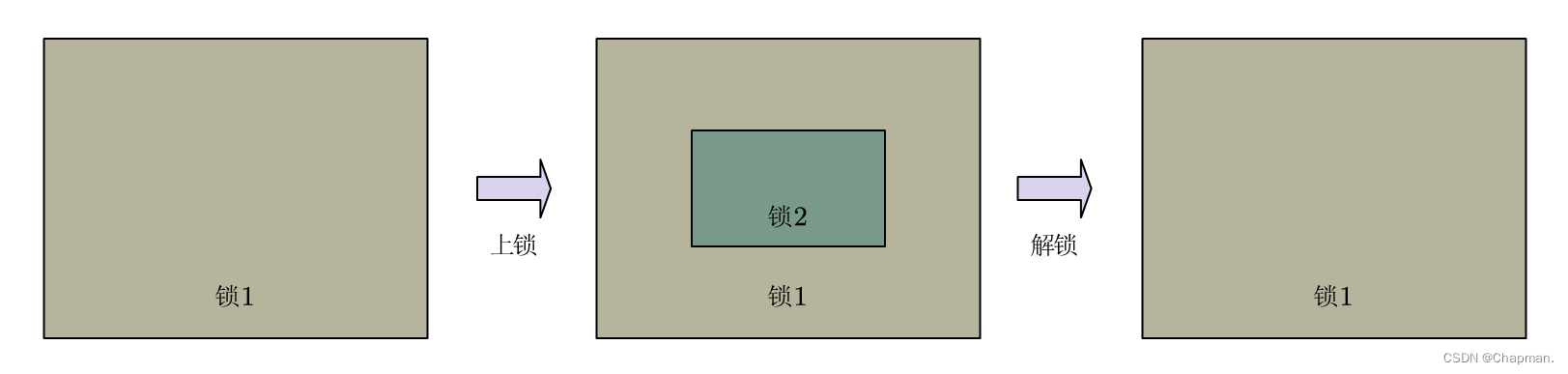
这样就不会产生锁中锁的问题了。关于recursive_timed_mutex类,这里就略过。因为功能和recursive_mutex是一样的,只是加上了计时超时的功能而已。
lock_guard类
这里需要补充一个lock_guard类,这一个类型的互斥锁是一个模板类的互斥锁。它可以简化互斥锁的使用,功能和mutex类是一样的,不过它是在类的构造时候上锁,析构的时候自动解锁,所以也比较安全。例子如下:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
//这个互斥锁用于保护cout资源
mutex mtx;
void task_2(int start, int end)
{
for(int i=start; i<= end; i++)
{
lock_guard<mutex> mlock(mtx);
cout <<"num2 = "<<i<<endl;
}
}
void task_1(int start, int end)
{
for(int i=start; i<= end; i++)
{
lock_guard<mutex> mlock(mtx);
cout <<"num1 = "<<i<<endl;
}
}
int main()
{
thread t1(task_1,0,3);
printf("t1创建成功!\r\n");
thread t2(task_2,0,3);
printf("t2创建成功!\r\n");
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout << "END"<<endl;
return 0;
}输出结果如下:
开始运行...
t1创建成功!
num1 = 0
num1 = 1
num1 = 2
t2创建成功!
num1 = 3
num2 = 0
num2 = 1
num2 = 2
num2 = 3
END
运行结束。unique_lock 类
它的作用和lock_guard类的使用方法一样,都是互斥锁的模板类。将一个互斥锁转换变成unique_lock类,然后在类构造的时候自动上锁,在类析构的时候自动解锁。但是他和lock_guard类的区别是,它还支持手动解锁和手动上锁。
原子类型atomic
在C++11里面,提供了一个叫原子类型(或者原子操作)的类型。所谓原子,就是用那些最小不可分的粒子,比喻一个操作或者一段代码是完整一个整体的整体,不可分割的整体。使用这样的类型能确保访问操作共享资源的安全性。它的模板是这样的:atomic<>,里面支持类型可以是:bool、char、 int、long、long long、指针类型,但是不支持浮点或者自定义的类型。
原子操作是直接由CPU指令提供的,传递效率远高于互斥锁。而且,用户也不需要关注有没有上锁问题。有下面例子:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
using namespace std;
int a = 0;
void task_1(int start, int end)
{
for(int i=start; i< end; i++)
{
a++;
}
}
int main()
{
thread t1(task_1,0,20000);
thread t2(task_1,0,20000);
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout<<"num = "<< a <<endl;
cout << "END"<<endl;
return 0;
}输出结果a应该为40000的,可是实际上:
开始运行...
num = 28019
END
运行结束。因为两个线程在使用共享资源的时候发生了冲突,导致数据计算出错。但是如果使用原子类型或者使用互斥锁,那么执行以下代码:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
#include <atomic> // 原子类型的头文件。
using namespace std;
atomic<int> a(0);
void task_1(int start, int end)
{
for(int i=start; i< end; i++)
{
a.fetch_add(1);
}
}
int main()
{
thread t1(task_1,0,20000);
thread t2(task_1,0,20000);
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout<<"num = "<< a.load() <<endl;
cout << "END"<<endl;
return 0;
}或者执行:
#include <iostream>
#include <ostream>
#include <thread>
#include <stdio.h>
#include <mutex>
using namespace std;
int a = 0;
mutex mtx;
void task_1(int start, int end)
{
for(int i=start; i< end; i++)
{
mtx.lock();
a++;
mtx.unlock();
}
}
int main()
{
thread t1(task_1,0,20000);
thread t2(task_1,0,20000);
if(t1.joinable())
{
t1.join();
}
if(t2.joinable())
{
t2.join();
}
cout<<"num = "<< a <<endl;
cout << "END"<<endl;
return 0;
}结果都是:
开始运行...
num = 40000
END
运行结束。那么说明,某种程度上原子操作有类似互斥锁操作的作用。
原子构造
这里讲一下,原子类型的构造方法,就好像上面的例子一样。有使用:“atomic<T> T(val)”声明定义一个原子类型。例如“atomic<int> a(0)”这一个用法,指的是将一个int类型a转换成int的原子类型a,并且给a赋值0。
常用原子操作
假如有一个“int a”的原子类型被转换好(使用了“atomic<int> a(2)”)。那么使用函数“a.load()”,可以返回出int原子类型a的数值。如果使用函数“a.fetch_add(1)”,可以将a加上1,并且返回出加上1之前a的数值。如果使用“a.fetch_sub(1)”,可以将a减去1,并且返回出减去1之前a的数值。如果使用函数“a.exchange(1)”,可以将1赋值到a里面,并且返回未赋值之前a的数值。如果使用函数“a.compare_exchange_strong(c,d)”,如果c和d相等,则把d的数值赋值到a里面,并且返回一个bool类型1;如果c和d不相等,则把a的数值赋值给c,并且返回一个bool类型0。
生产者——消费者模型
生产者——消费者模型是一个很常见的模型,它被广泛应用在服务器里面。当前台收到来至客户端的数据时候,先把数据做简单处理,然后放到数据缓存区。当数据缓存区有数据时,就会唤醒后台处理数据。它的简单模型示意图如下:

条件变量
条件变量是一种线程同步机制。如果条件不满足,当前线程就会被一直阻塞,直到条件满足的时候线程再次被唤醒。一般地,条件变量和互斥锁相互协同工作。条件变量是常被用于实现:消费者——生产者模型(高速缓存队列)。
代码实例
下面是根据上面的生产者——消费者模型编写出来的实验代码:
#include <iostream>
#include <string>
#include <thread> // 线程类头文件。
#include <mutex> // 互斥锁类的头文件。
#include <deque> // deque 容器的头文件。
#include <queue> // queue 容器的头文件。
#include <condition_variable> // 条件变量的头文件。
using namespace std;
class AA
{
mutex m_mutex; // 互斥锁。
condition_variable m_cond; // 条件变量。
queue<string, deque<string>> m_q; // 缓存队列,底层容器用 deque。
public:
void incache(int num) // 生产数据,num 指定数据的个数。
{
lock_guard<mutex> lock(m_mutex); // 申请加锁。
for (int ii=0 ; ii<num ; ii++)
{
static int bh = 1; // 客户请求编号。
string message = to_string(bh++) + "号客户请求"; // 拼接出一个数据。
m_q.push(message); // 把生产出来的数据入队。
}
//m_cond.notify_one(); // 唤醒一个被当前条件变量阻塞的线程。
m_cond.notify_all(); // 唤醒多个被当前条件变量阻塞的线程。
}
void outcache() // 消费者线程任务函数。
{
while (true)
{
string message;
{
// 把互斥锁转换成 unique_lock<mutex>,并申请加锁。
unique_lock<mutex> lock(m_mutex);
while (m_q.empty()) // 如果队列空,进入循环,否则直接处理数据。必须用循环,不能用 if
m_cond.wait(lock); // 等待生产者的唤醒信号。
// 数据元素出队。
message = m_q.front();
m_q.pop();
cout << "服务线程id号:" << this_thread::get_id() << ",处理: " << message << endl;
}
// 处理出队的数据(把数据消费掉)。
this_thread::sleep_for(chrono::milliseconds(1)); // 假设处理数据需要 1 毫秒。
}
}
};
int main()
{
AA aa;
thread t1(&AA::outcache, &aa); // 创建消费者线程 t1。
thread t2(&AA::outcache, &aa); // 创建消费者线程 t2。
thread t3(&AA::outcache, &aa); // 创建消费者线程 t3。
this_thread::sleep_for(chrono::seconds(2)); // 休眠 2 秒。
aa.incache(10); // 生产 20 个数据。
this_thread::sleep_for(chrono::seconds(3)); // 休眠 3 秒。
aa.incache(10); // 生产 20 个数据。
t1.join(); // 子线程加入到主线程
t2.join();
t3.join();
return 0;
}输出结果:
开始运行...
服务线程id号:139630585300736,处理: 1号客户请求
服务线程id号:139630593693440,处理: 2号客户请求
服务线程id号:139630576908032,处理: 3号客户请求
服务线程id号:139630585300736,处理: 4号客户请求
服务线程id号:139630593693440,处理: 5号客户请求
服务线程id号:139630576908032,处理: 6号客户请求
服务线程id号:139630585300736,处理: 7号客户请求
服务线程id号:139630593693440,处理: 8号客户请求
服务线程id号:139630576908032,处理: 9号客户请求
服务线程id号:139630585300736,处理: 10号客户请求
服务线程id号:139630593693440,处理: 11号客户请求
服务线程id号:139630576908032,处理: 12号客户请求
服务线程id号:139630585300736,处理: 13号客户请求
服务线程id号:139630593693440,处理: 14号客户请求
服务线程id号:139630576908032,处理: 15号客户请求
服务线程id号:139630585300736,处理: 16号客户请求
服务线程id号:139630593693440,处理: 17号客户请求
服务线程id号:139630576908032,处理: 18号客户请求
服务线程id号:139630585300736,处理: 19号客户请求
服务线程id号:139630593693440,处理: 20号客户请求
运行结束。condition_variable类&condition_variable_any类
在C++11里面提供了这两个类:condition_variable类、condition_variable_any类。这两个类位于<condition_variable>里面,使用时候需要包含这一个头文件。这两个类都属于条件变量类,需要搭配互斥锁类使用。其中,condition_variable只能搭配mutex,而condition_variable_any则可以搭配其他互斥锁。
condition_variable类
condition_variable()是condition_variable类的构造函数。notify_one()是condition_variable类用于唤醒一个线程,而notify_all()则是用于唤醒全部线程的。wait()这一个函数是用于阻塞调用它的线程,直到条件满足的时候再将该线程唤醒(这一个函数有两种判断方式,一个是通知送达,一个是条件满足)。下面是wait函数的详解:
| 函数 | 使用实例 |
| m_cond.wait(unique_lock lock) | while (m_q.empty()) m_cond.wait(lock); |
| m_cond.wait(unique_lock lock,Pred pred) | m_cond.wait(lock,[this] {return !m_q.empty();}) |
上述这两个函数的使用方法不同,但是实现的效果都是一样的。换句话来说:m_cond.wait(unique_lock lock,Pred pred)是自带循环等待的,而m_cond.wait(unique_lock lock)只有判断条件。
对于像wait_for(lock,时间长度)这样的函数,其实和前面timed_mutex类很相似,里面的参数传入chrono的函数,可以做到精确的等待唤醒效果。还有wait_for(lock,时间长度,Pred pred)也是类似的,只不过这个比wait_for(lock,时间长度)多了循环等待的效果。当然还有wait_for(lock,时间长度)、wait_until(unique_lock lock,时间点,Pred pred) 类似的,这里也不再赘述。
condition_variable_any类
这一个condition_variable_any类用的机会比较少,其实可以完全参考condition_variable类,因为它支持mutex以外的互斥锁。
deque和queue
再前面的代码里面,使用到了deque和queue这两个库。其中queue容器是一种是队列,物理结构可以是数组或链表,主要用于多线程之间的数据共享。它只支持操作头部和尾部,在这里的作用就类似于一个软件fifo。而deque则是类似于链表的结构,可以不安一定顺序,只有有指定位置就可以添加和删除节点,这样方便管理不等长的数据。对于这两个类型,这里不展开讨论。关于链表可以参考这里。















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









