







关于YOLOv5_deepsort数据集训练自己的数据集——自学使用1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
一窍不通,我先看看这个标准数据集的介绍:
*Market 1501数据集
Market-1501 是目前常用的行人重识别数据集,,在清华大学校园中采集,夏天拍摄,在 2015 年构建并公开。它包括由6个摄像头(其中5个高清摄像头和1个低清摄像头)拍摄到的 1501 个行人、32668 个检测到的行人矩形框。每个行人至少由2个摄像头捕获到,并且在一个摄像头中可能具有多张图像。训练集有 751 人,包含 12,936 张图像,平均每个人有 17.2 张训练数据;测试集有 750 人(来自另外750个不同的人),包含 19,732 张图像,平均每个人有 26.3 张测试数据。3368 张查询图像的行人检测矩形框是人工绘制的,而 gallery 中的行人检测矩形框则是使用DPM检测器检测得到的。该数据集提供的固定数量的训练集和测试集均可以在single-shot或multi-shot测试设置下使用。
数据集目录结构
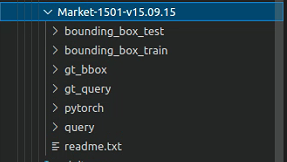
共包含四个文件夹
bounding_box_test: 用于测试
bounding_box_train: 用于训练
query: 有750个身份。我们为每个摄像机随机选择一个查询图像
gt_query: 包含实际标注。对于每个查询,相关图像被标记为“好”或“垃圾”。“垃圾”对搜索准确性没有任何影响。“垃圾”图像还包括与query相同的相机中的图像
gt_bbox: 手绘边框,主要用于判断DPM边界框是否良好
图片命名规则
以0001_c1s1_000151_01.jpg为例
0001表示每个人的标签编号,从0001到1501,共有1501个人
c1表示第一个摄像头(c是camera),共有6个摄像头
s1 表示第一个录像片段(s是sequence),每个摄像机都有多个录像片段
000151表示c1s1的第000151帧图片,视频帧率fps为25
01表示c1s1_001051这一帧上的第1个检测框,由于采用DPM自动检测器,每一帧上的行人可能会有多个,相应的标注框也会有多个。00则表示手工标注框
正文开始:
先克隆大神的原地址文件,我在这里用的是v3.0版本
https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch/tree/v3.0
git clone https://github.com/mikel-brostrom/Yolov5_DeepSort_Pytorch.git
**
注意注意:
requirements.txt依赖项的Python 3.8 或更高版本,包括torch>=1.7
不然会有这样的错误:
can’t convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first
一.目标追踪整体代码
代码的目录:

二.代码注释
2.1 Configs文件夹目录下
deep_sort.yaml:这个yaml文件主要是保存一些参数。
REID_CKPT: "deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7"#里面有特征提取权重的目录路径;
MAX_DIST: 0.2 #最大余弦距离,用于级联匹配,如果大于该阈值,则忽略。
MIN_CONFIDENCE: 0.3 #检测结果置信度阈值
NMS_MAX_OVERLAP: 0.5 #非极大抑制阈值,设置为1代表不进行抑制
MAX_IOU_DISTANCE: 0.7 #最大IOU阈值
MAX_AGE: 70 #最大寿命,也就是经过MAX_AGE帧没有追踪到该物体,就将该轨迹变为删除态。
N_INIT: 3 #最高击中次数,如果击中该次数,就由不确定态转为确定态。
NN_BUDGET: 100 #最大保存特征帧数,如果超过该帧数,将进行滚动保存
2.2 deep_sort/deep_sort/deep目录下
ckpt.t7:这是一个特征提取网络的权重文件,特征提取网络训练好了以后会生成这个权重文件,方便在目标追踪的时候提取目标框中的特征,在目标追踪的时候避免ID switch。
evaluate.py:计算特征提取模型精确度。
feature_extractor.py:特征提取器,提取对应bounding box中的特征, 得到一个固定维度的特征,作为该bounding box的代表,供计算相似度时使用。
model.py和original_model.py:特征提取网络模型,该模型用来提取训练特征提取网络权重。
train.py:训练特征提取网络的python文件
test.py:测试训练好的特征提取网络的性能
2.3 deep_sort/deep_sort/sort目录下:
detection.py:保存通过目标检测的一个检测框框,以及该框的置信度和获取的特征;同时还提供了框框的各种格式的转化方法。
iou_matching.py:计算两个框框之间的IOU。
kalman_filter.py:卡尔曼滤波器的相关代码,主要是利用卡尔曼滤波来预测检测框的轨迹信息。
linear_assignment.py:利用匈牙利算法匹配预测的轨迹框和检测框最佳匹配效果。
nn_matching.py:通过计算欧氏距离、余弦距离等距离来计算最近领距离。
preprocessing.py:非极大抑制代码,利用非极大抑制算法将最优的检测框输出。
track.py:主要储存的是轨迹信息,其中包括轨迹框的位置和速度信息,轨迹框的ID和状态,其中状态包括三种,一种是确定态、不确定态、删除态三种状态。
tracker.py:保存了所有的轨迹信息,负责初始化第一帧,卡尔曼滤波的预测和更新,负责级联匹配,IOU匹配。
deep_sort/deep_sort/deep_sort.py:deepsort的整体封装,实现一个deepsort追踪的一个整体效果。
deep_sort/utils:这里最主要有一些各种各样的工具python代码,例如画框工具,日志保存工具等等。
三.训练自己的数据集
由于我们需要把yolov5_deepsort结合在一起,所以在目录YOLOv5下,将https://github.com/ultralytics/yolov5/tree/v3.0 放入yolov5目录下。其实我不确定和版本关系大不大,但是为了可以一次成功我就都用了第3版本。
这时候当然要获取我们目标检测权重,已经在YOLOv5训练自己的数据集(VOC格式的数据集和txt格式的数据集)写了目标检测的流程,train.py以后就可以在runsexp/weights文件目录下看到自己的权重了,这里就跳过咯。
四.准备分类数据
我在训练的时候主要操作如下:
–扣数据
可以将标注gt中的数据,抠出来,然后拿来训练模型,kou.py可创建在自己数据文件下,具体路径习性修改,代码如下:
import cv2
import xml.etree.ElementTree as ET
import numpy as np
import xml.dom.minidom
import os
import argparse
def main():
# JPG文件的地址
img_path = '/home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/data/voc/images/'
# XML文件的地址
anno_path = '/home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/data/voc/Annotations/'
# 存结果的文件夹
cut_path = '/home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/data/voc/crops/'
if not os.path.exists(cut_path):
os.makedirs(cut_path)
# 获取文件夹中的文件
imagelist = os.listdir(img_path)
# print(imagelist
for image in imagelist:
image_pre, ext = os.path.splitext(image)
img_file = img_path + image
img = cv2.imread(img_file)
xml_file = anno_path + image_pre + '.xml'
# DOMTree = xml.dom.minidom.parse(xml_file)
# collection = DOMTree.documentElement
# objects = collection.getElementsByTagName("object")
tree = ET.parse(xml_file)
root = tree.getroot()
# if root.find('object') == None:
# return
obj_i = 0
for obj in root.iter('object'):
obj_i += 1
cls = obj.find('name').text
xmlbox = obj.find('bndbox')
b = [int(float(xmlbox.find('xmin').text)), int(float(xmlbox.find('ymin').text)), int(float(xmlbox.find('xmax').text)),
int(float(xmlbox.find('ymax').text))]
img_cut = img[b[1]:b[3], b[0]:b[2], :]
path = os.path.join(cut_path, cls)
# 目录是否存在,不存在则创建
mkdirlambda = lambda x: os.makedirs(x) if not os.path.exists(x) else True
mkdirlambda(path)
cv2.imwrite(os.path.join(cut_path, cls, '{}_{:0>2d}.jpg'.format(image_pre, obj_i)), img_cut)
print("&&&&")
if __name__ == '__main__':
main()
上述代码在自己的数据集上生成了crops文件夹,我这里训练里裂纹的数据集,所以经过该代码生成该crops --crack0(我自己的类就叫crack0)目录:
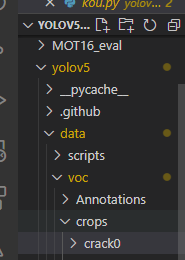
然后我们需要把crack0这个文件夹的图片划分测试集和训练集,在我们自己的数据集目录下创建prepara.py:
import os
from PIL import Image
from shutil import copyfile, copytree, rmtree, move
PATH_DATASET = '/home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/data/voc/crops/crack0' # 需要处理的文件夹
PATH_NEW_DATASET = '/home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/data/voc/crops/crack1' # 处理后的文件夹
PATH_ALL_IMAGES = PATH_NEW_DATASET + '/all_images'
PATH_TRAIN = PATH_NEW_DATASET + '/train'
PATH_TEST = PATH_NEW_DATASET + '/test'
# 定义创建目录函数
def mymkdir(path):
path = path.strip() # 去除首位空格
path = path.rstrip("\\") # 去除尾部 \ 符号
isExists = os.path.exists(path) # 判断路径是否存在
if not isExists:
os.makedirs(path) # 如果不存在则创建目录
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
class BatchRename():
'''
批量重命名文件夹中的图片文件
'''
def __init__(self):
self.path = PATH_DATASET # 表示需要命名处理的文件夹
# 修改图像尺寸
def resize(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 修改图片尺寸到128宽*256高
im = Image.open(src)
out = im.resize((128, 256), Image.ANTIALIAS) # resize image with high-quality
out.save(src) # 原路径保存
def rename(self):
for aroot, dirs, files in os.walk(self.path):
# aroot是self.path目录下的所有子目录(含self.path),dir是self.path下所有的文件夹的列表.
filelist = files # 注意此处仅是该路径下的其中一个列表
# print('list', list)
# filelist = os.listdir(self.path) #获取文件路径
total_num = len(filelist) # 获取文件长度(个数)
i = 1 # 表示文件的命名是从1开始的
for item in filelist:
if item.endswith('.jpg'): # 初始的图片的格式为jpg格式的(或者源文件是png格式及其他格式,后面的转换格式就可以调整为自己需要的格式即可)
src = os.path.join(os.path.abspath(aroot), item)
# 根据图片名创建图片目录
dirname = str(item.split('_')[0])
# 为相同车辆创建目录
#new_dir = os.path.join(self.path, '..', 'bbox_all', dirname)
new_dir = os.path.join(PATH_ALL_IMAGES, dirname)
if not os.path.isdir(new_dir):
mymkdir(new_dir)
# 获得new_dir中的图片数
num_pic = len(os.listdir(new_dir))
dst = os.path.join(os.path.abspath(new_dir),
dirname + 'C1T0001F' + str(num_pic + 1) + '.jpg')
# 处理后的格式也为jpg格式的,当然这里可以改成png格式 C1T0001F见mars.py filenames 相机ID,跟踪指数
# dst = os.path.join(os.path.abspath(self.path), '0000' + format(str(i), '0>3s') + '.jpg') 这种情况下的命名格式为0000000.jpg形式,可以自主定义想要的格式
try:
copyfile(src, dst) #os.rename(src, dst)
print ('converting %s to %s ...' % (src, dst))
i = i + 1
except:
continue
print ('total %d to rename & converted %d jpgs' % (total_num, i))
def split(self):
#---------------------------------------
#train_test
images_path = PATH_ALL_IMAGES
train_save_path = PATH_TRAIN
test_save_path = PATH_TEST
if not os.path.isdir(train_save_path):
os.mkdir(train_save_path)
os.mkdir(test_save_path)
for _, dirs, _ in os.walk(images_path, topdown=True):
for i, dir in enumerate(dirs):
for root, _, files in os.walk(images_path + '/' + dir, topdown=True):
for j, file in enumerate(files):
if(j==0): # test dataset;每个车辆的第一幅图片
print("序号:%s 文件夹: %s 图片:%s 归为测试集" % (i + 1, root, file))
src_path = root + '/' + file
dst_dir = test_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
else:
src_path = root + '/' + file
dst_dir = train_save_path + '/' + dir
if not os.path.isdir(dst_dir):
os.mkdir(dst_dir)
dst_path = dst_dir + '/' + file
move(src_path, dst_path)
rmtree(PATH_ALL_IMAGES)
if __name__ == '__main__':
demo = BatchRename()
demo.resize()
demo.rename()
demo.split()
生成的目录如下:

然后,我们把crack1文件夹,即刚才生成的测试集和训练集整体放入该目录下:
\Yolov5_DeepSort_Pytorch-3.0\deep_sort_pytorch\deep_sort\deep\crack1
长这样:

–修改train.py中train dataset的预处理如下:`
transform_train = torchvision.transforms.Compose([
torchvision.transforms.Resize((128, 64)),
torchvision.transforms.RandomCrop((128, 64), padding=4),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
五.训练跟踪类型
修改:Yolov5_DeepSort_Pytorch-3.0\deep_sort_pytorch\deep_sort\deep\model.py中的num_class=52,我这里改52是因为报错提示张量是52.我没仔细看源码,就是为了先训练出来。

修改track.py的路径,参数以及自己的视频路径
 在终端运行:
在终端运行:
python track.py --yolo_weights /home/lad/Yolov5_DeepSort_Pytorch-3.0/yolov5/runs/exp4/weights/best.pt --source /home/lad/Yolov5_DeepSort_Pytorch-3.0/crack.mp4 --deep_sort_weights /home/lad/Yolov5_DeepSort_Pytorch-3.0/deep_sort_pytorch/deep_sort/deep/checkpoint/ckpt.t7 --device 0 --classes 0 --save-vid
保存结果至:
F:\写完cscn就删\Yolov5_DeepSort_Pytorch-3.0\inference\output\crack.mp4
检测效果:就这样咯
















 3752
3752











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











