






神经网络中有着大量的乘法运算,一般采用脉动阵列来进行流水线加速运算。
如图所示是一个大体的设计结构图,方块是最小MAC计算单元,左边和上边分别为乘法运算的两个数据。
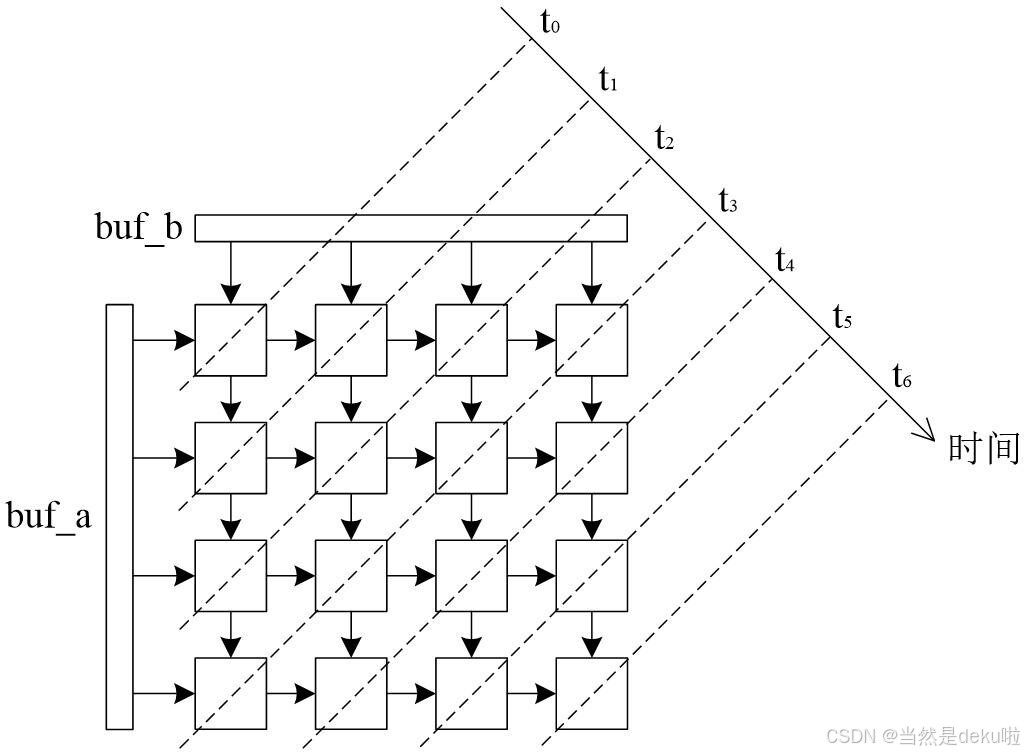
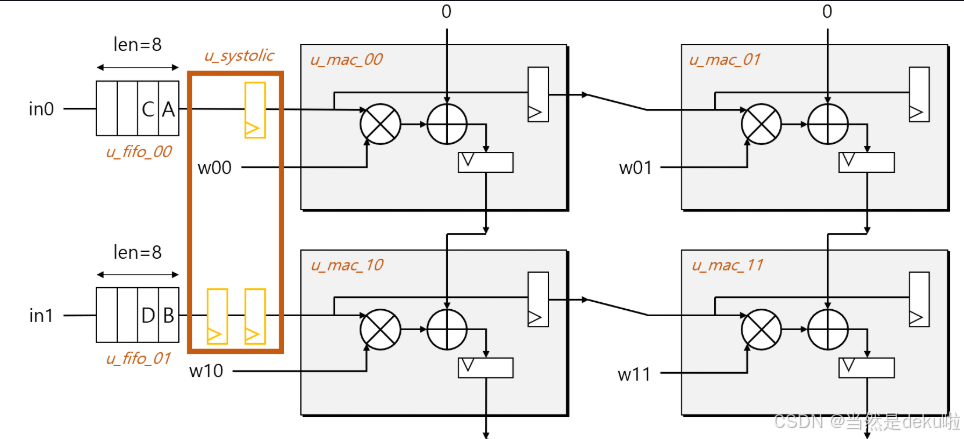
由于神经网络中权重一般是固定的,所以我就将结构设计成为了另一张图,也就是这样,左边是源源不断的数据流,权重使用寄存器配置,从上到下就是是每一列寄存器某一时刻的累加值。
手画一个简单的例子。
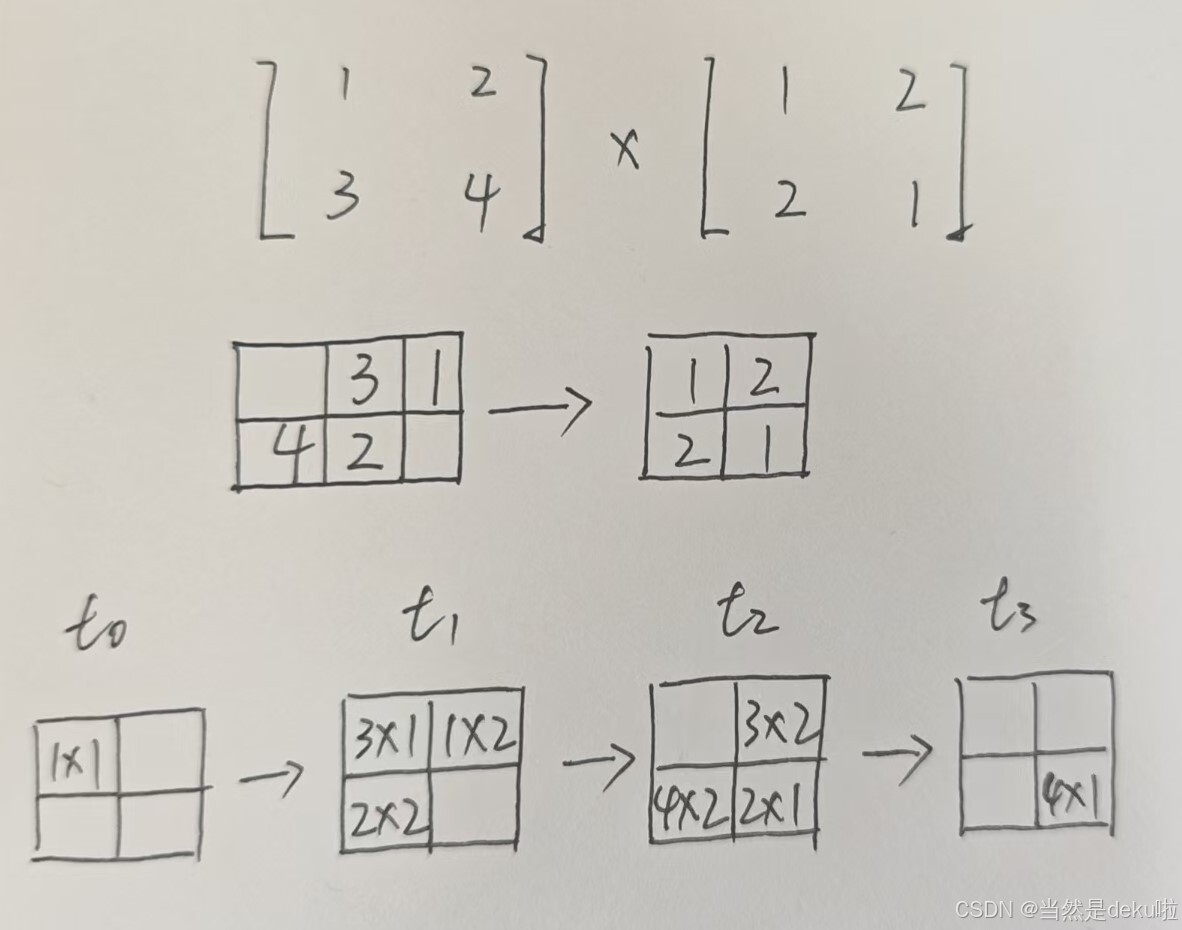
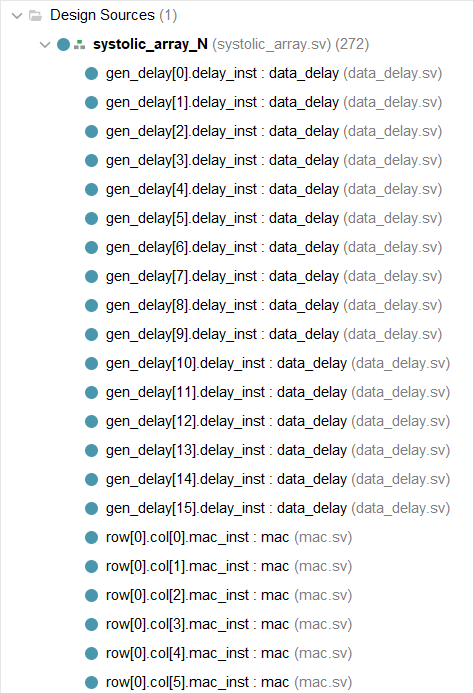
针对16*16的矩阵结构图展示:
流水线展示:
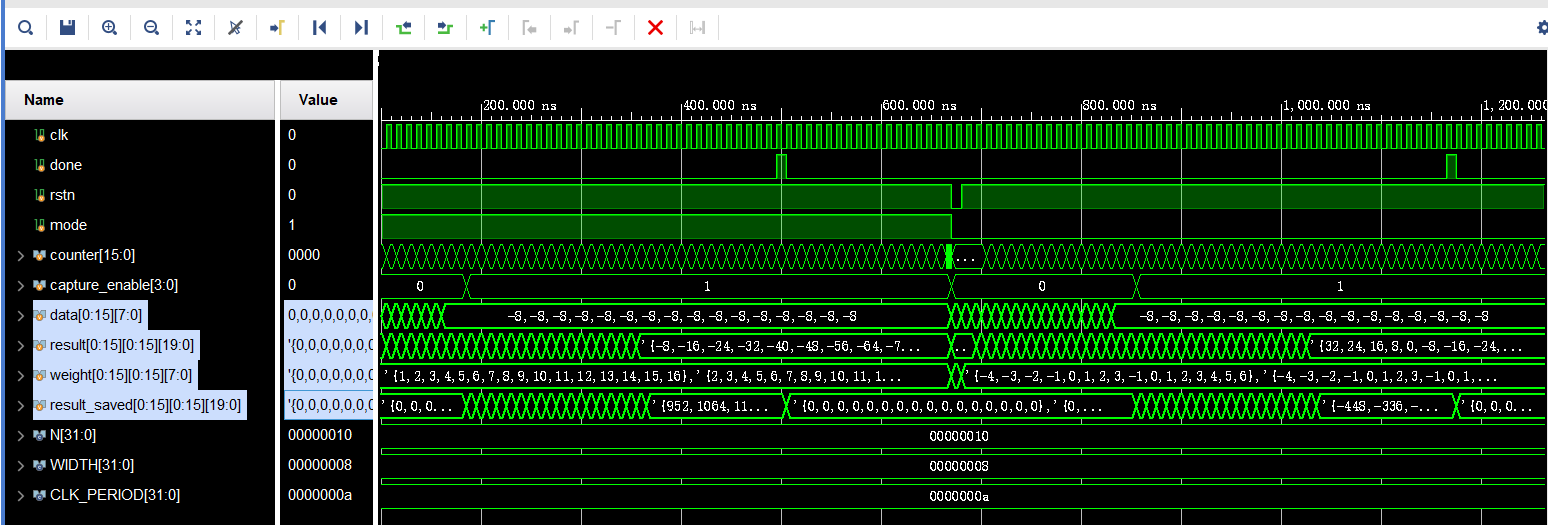
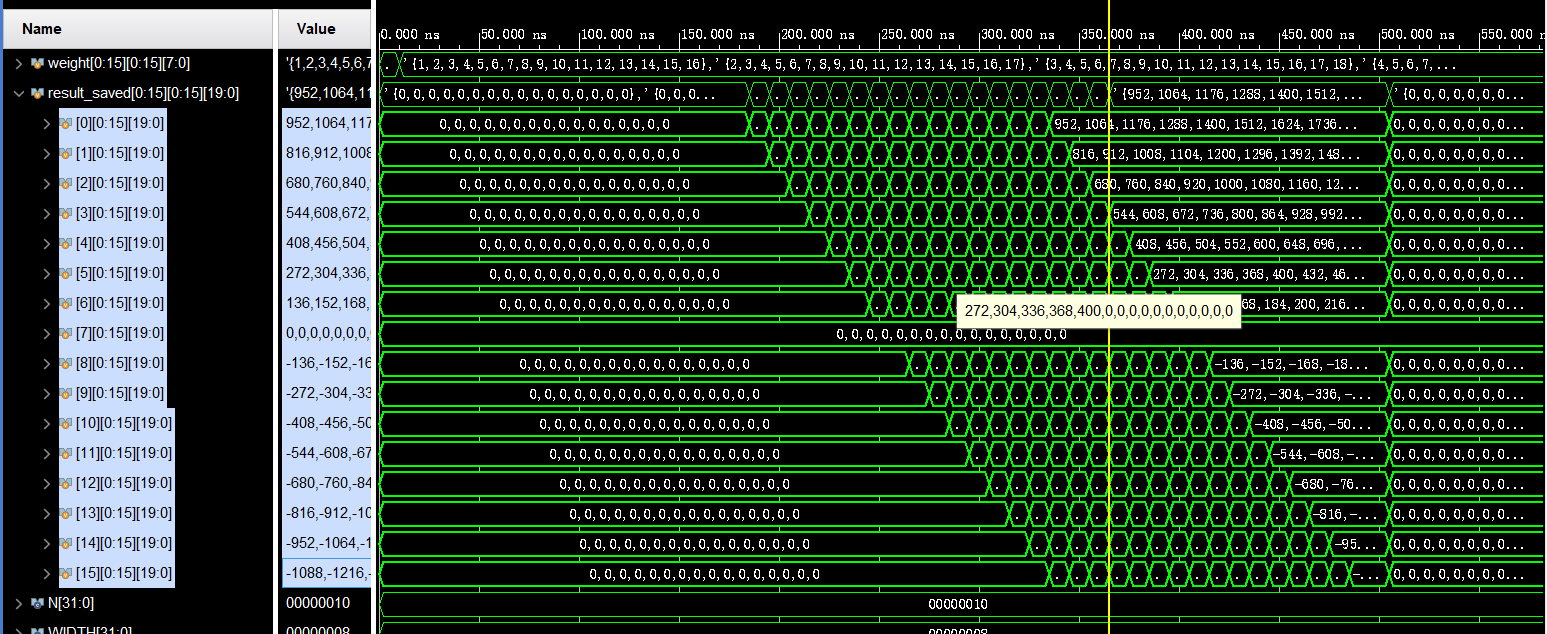
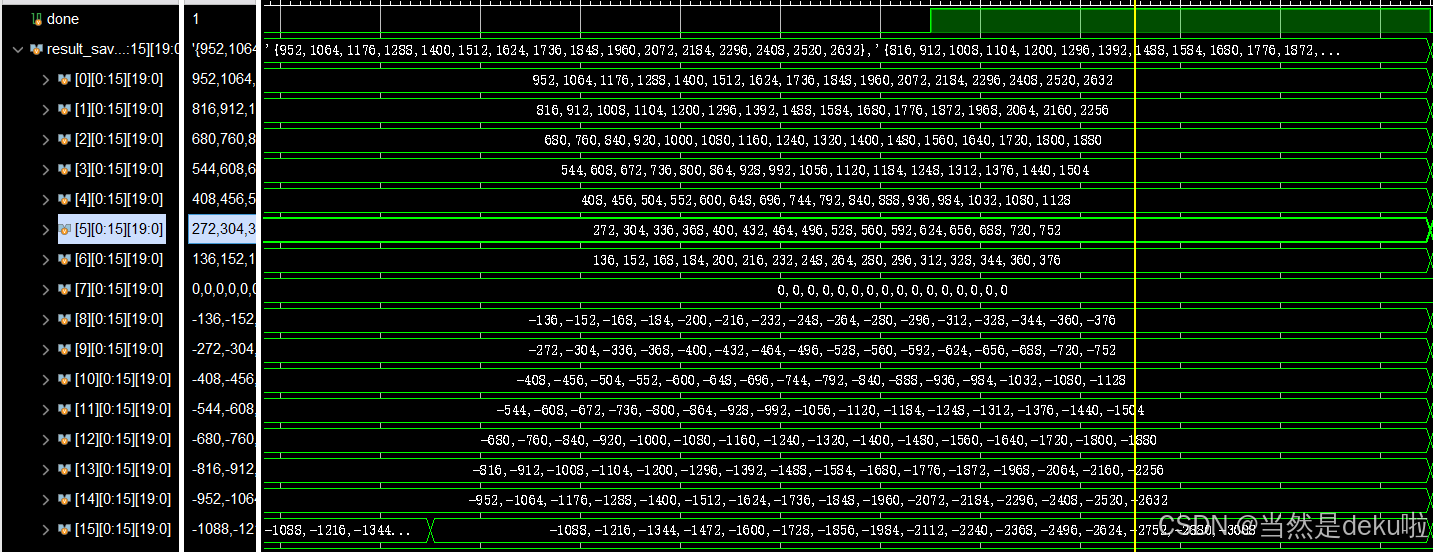
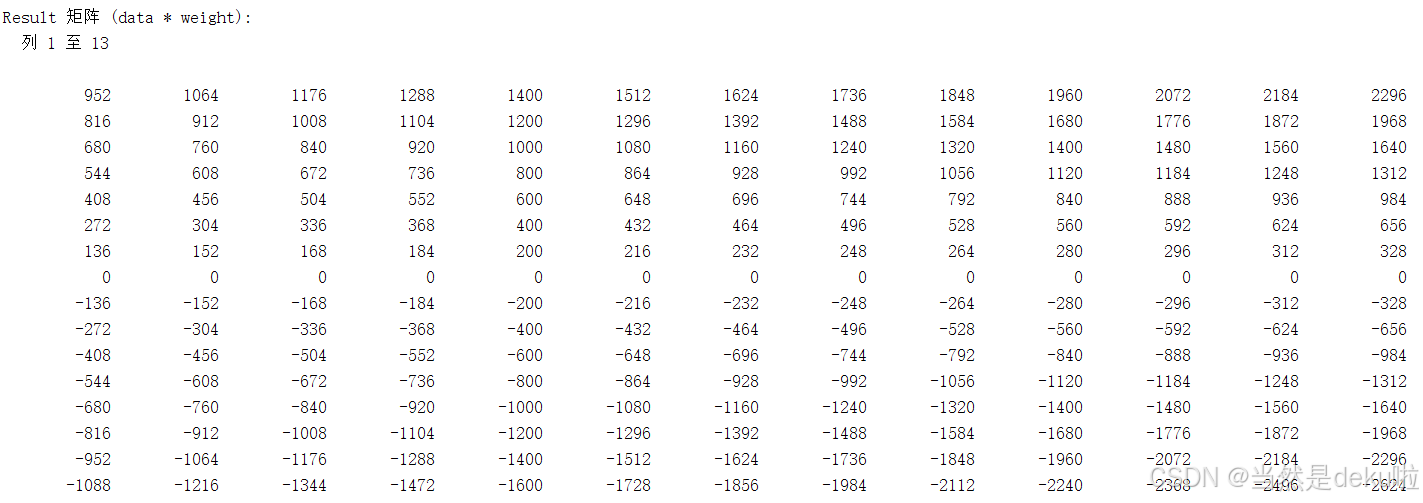
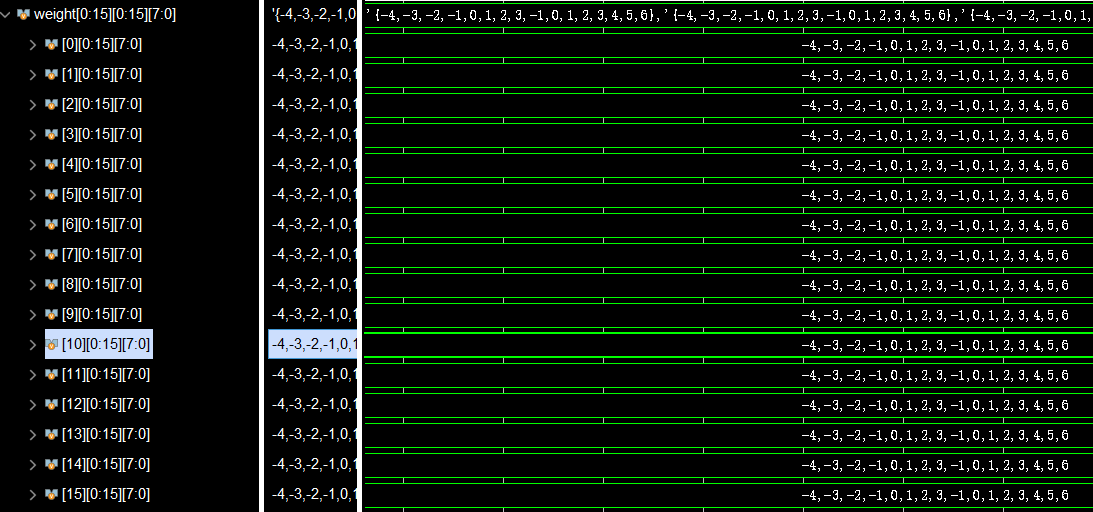
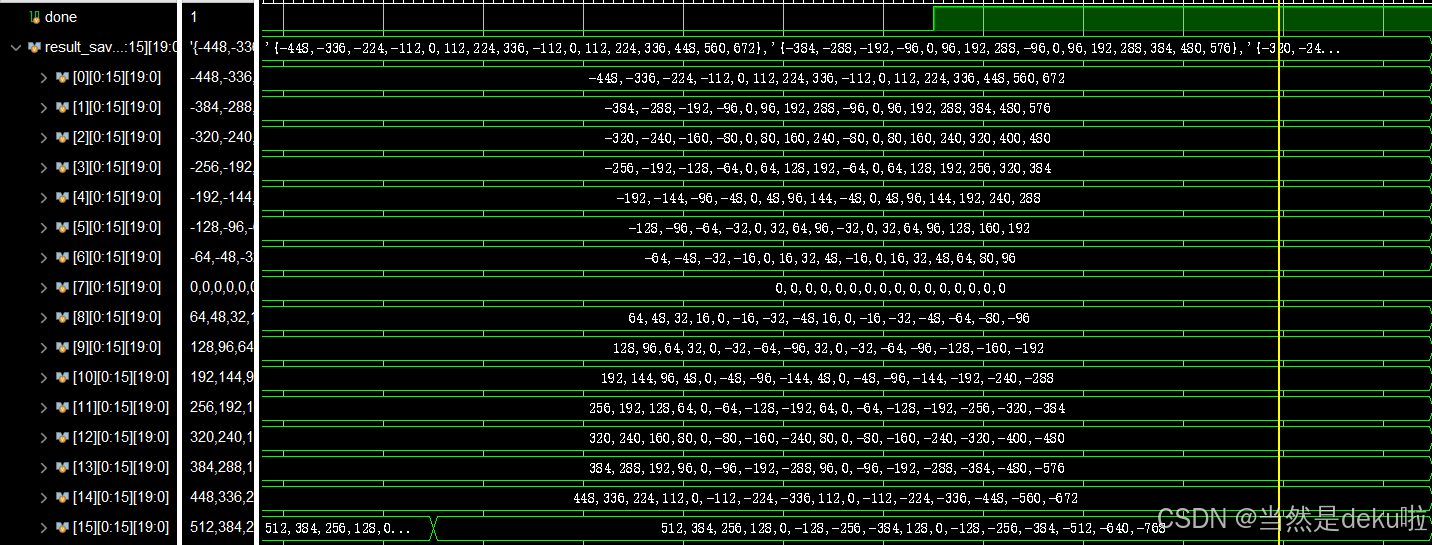
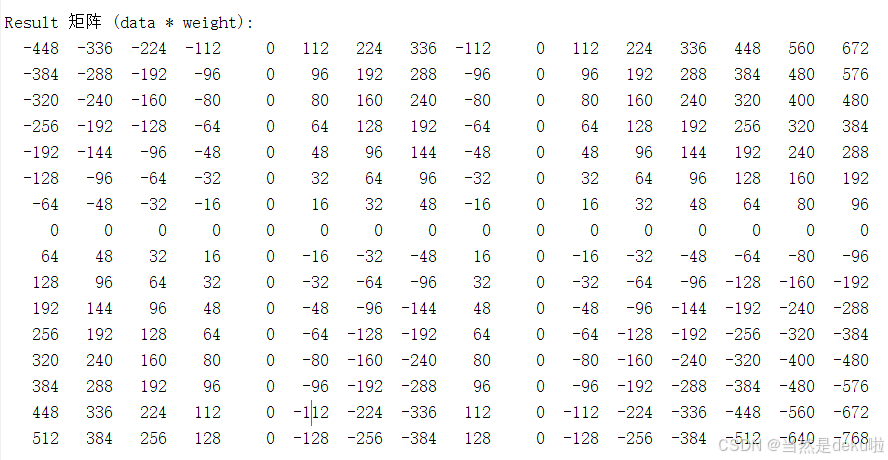
最后就是结果图,实现了任意阶数N*N矩阵乘法的脉动阵列,并支持有符号int4和int8模式选择,这里取N=16,分别在int4和int8做了测试。
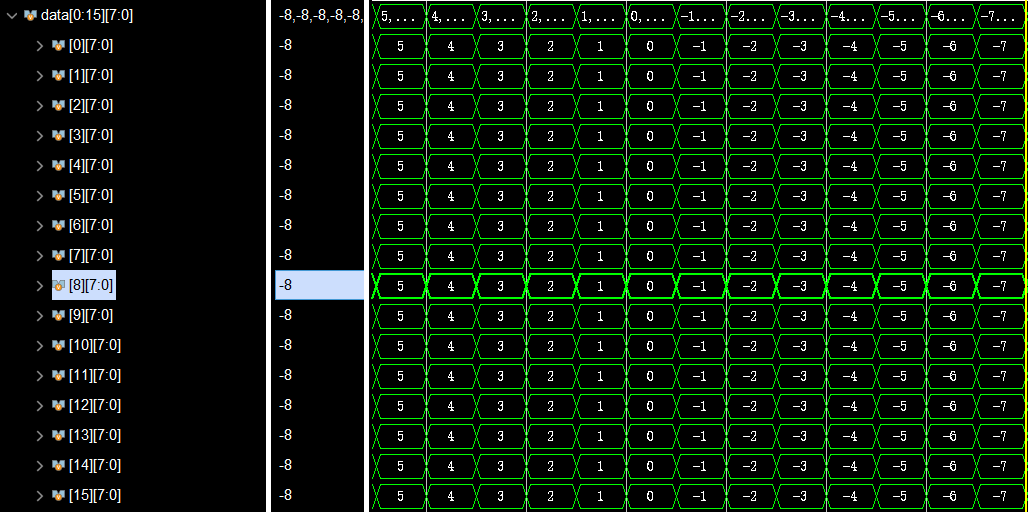
首先是int8:
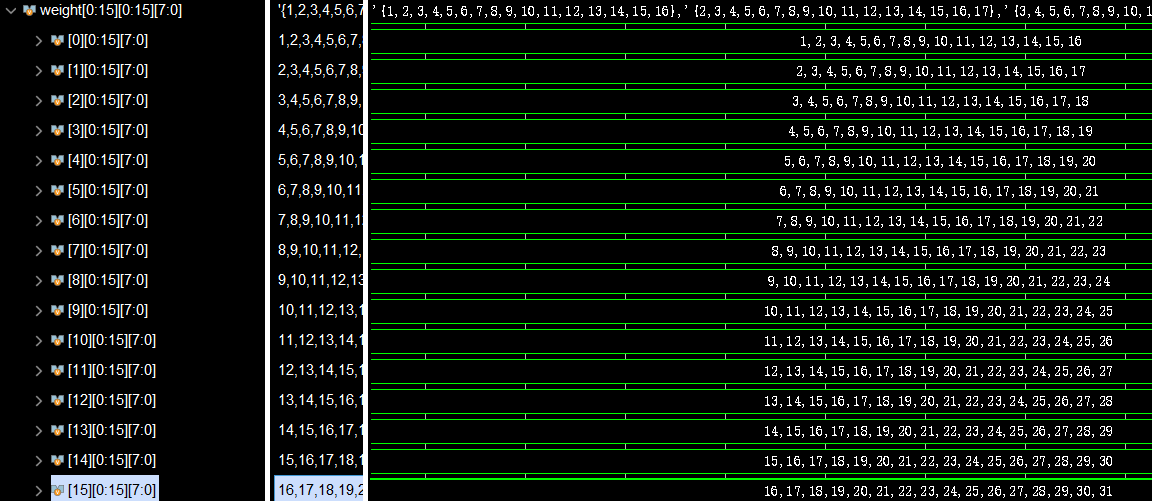
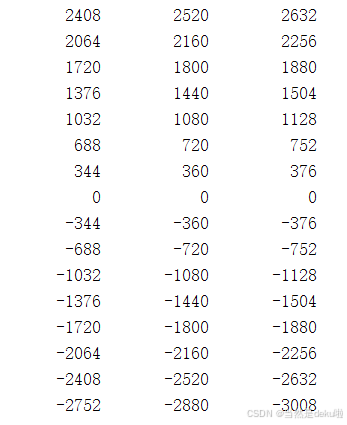
然后是int4:
有需要的联系咸鱼:cllllll28


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









