








数智化浪潮下,越来越多的企业开始将现代信息网络作为数据资源的主要载体,并通过网络通信技术进行数据传输;网络作为主要的信息交流和分享的方式,海量不同源的网络信息,使得企业与个人消化信息的成本越来越高。音视频数据作为其中重要的信息来源之一,也随着远程视频会议、在线课堂、直播教学、电话销售等领域有了爆炸性的增长。
为了帮助用户提升信息获取及信息加工的效率,阿里巴巴达摩院语音实验室的口语语言处理团队实践了一系列针对音视频转写结果的长文本语义理解能力。
本期推出口语语义理解技术系列第二篇,围绕对长文本进行关键词抽取方法进行介绍。
▎研究背景
关键词抽取作为最经典的信息处理任务之一,目标是从输入的文档集合中抽取出最具代表性且囊括全文核心语义的短语列表。
关键词的通用性使其成为一个非常重要的文档处理任务,尤其对于新闻及学术出版业而言,关键词推荐可以辅助作者撰写文章关键词,也能帮助用户快速获取、掌握文章概要,同时系统可以据此向用户推荐更多内容。从是否需要有标签训练数据角度来看,可以分为有监督和无监督的方法;考虑到泛领域音视频场景下可能涉及的领域过多且标注数据获取困难,我们采用了无监督的技术方案。
▎研究方法
一个标准的关键词抽取系统通常包括三个流程:1) 在全文中通过启发式方法选取候选关键词列表;2) 使用算法对候选关键词进行排序;3) 对排序后的关键词列表进行归一化、去重,并集合一些其它策略进行过滤 [1][2]。
其中第一步和第三步均与具体应用场景强相关,本文后半部分再做介绍;研究者们主要针对无监督的候选关键词排序算法做出了大量研究,从整体发展阶段来划分可以分为传统的统计学方法以及近期的基于神经语言模型的向量表征方法,本章节选取了几种代表性的方法进行介绍。
No.1 传统统计学方法
TFIDF:利用候选词本身最基本的统计特性-词频以及在大规模文档中统计的逆文档频率得分进行排序,是经典的 baseline 方法。
TextRank[4]:受到 PageRank 在信息检索领域应用的启发,研究人员提出一种基于图的排序算法 TextRank 进行关键词抽取;该方法的核心思想是将整个文档看作一个词语之间的网络,网络内的边则表示词语之间的语义关系,基于这个网络可以运用 PageRank 的迭代方法来得到各个候选词的重要性得分。
Yake[5]:结合过往经验,研究人员提出了一种结合多种文本特征融合的关键词抽取方案,对于文章中的每个 token 计算是否大小写,词语位置,词频,词关联度,词覆盖度5项特征,并通过一个加权公式对上述 feature 进行融合得到 token 得分,并进一步设计了基于 token 的候选关键词权重计算,最终排序得到关键词列表。
No.2 神经语言模型的向量表征方法
基于(候选关键词 ,文档)相似度匹配的衡量方式
包括 EmbedRank[6]、SIFRank[7] 等一系列方法,它们之间的差异主要体现在文档表征及短语表征的获取方式上:从经典的 Average word2vec、Sent2Vec、Doc2Vec 到 ELMo,再到结合预训练语言模型的 BERT,RoBERTa;整体匹配逻辑如图 1 所示。
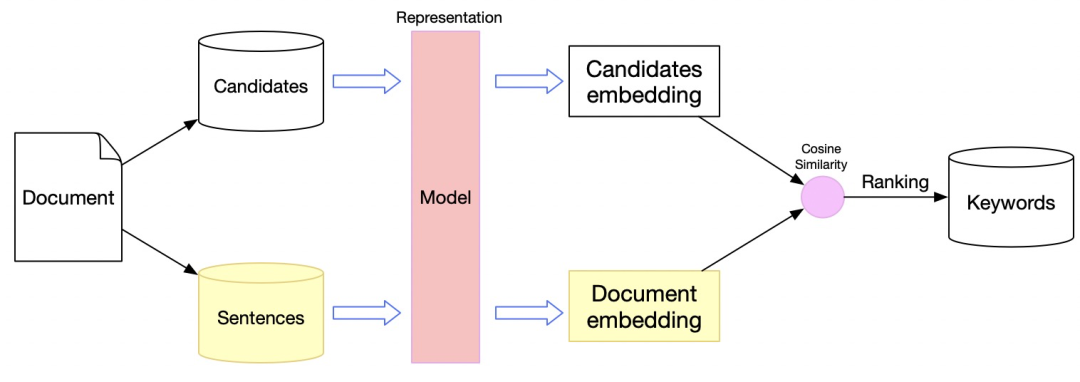
图1 基于 (候选关键词 ,文档)相似度的匹配逻辑
基于(文档-候选关键词,文档)相似度匹配的衡量方式
由于过去基于表征的方法存在候选词和文档语义粒度不匹配的问题(一个是短语词粒度,一个是篇章粒度),我们团队提出了一种基于掩码的关键词抽取技术-MDERank[8] 来改善该问题。
此方法的核心思想为:对于越为重要的短语,掩盖该短语后得到的文档表征与原始文档表征应该有越大的差异,通过对不同候选短语计算的距离得分进行排序即可得到关键词列表。
No.3 横向对比
总体来说,受益于大规模数据及预训练语言模型学到的更深层次语义信息,基于向量表征的方法在一些公开数据集上的结果普遍优于传统统计学方法;但从算法时间效率来看,基于向量表征的方法相比之下也产生了更大的计算开销。
一个较为全面的效果对比如图 2 所示。Dataset 栏目下为一系列书面语关键词抽取任务的公开数据集,其中 Inspec, SemEval2017 和 SemEval2010 为较短文档数据集;DUC2001, Krapivin 和 NUS为较长文档数据集。
AVG 为 Datasets 下六个数据集上F1@K (K=5) 的平均值,AvgRank(STD) 是对于某个方法,其在每个数据集上的性能在表格中所有11种方法的性能中的位置(Rank)的均值和方差。
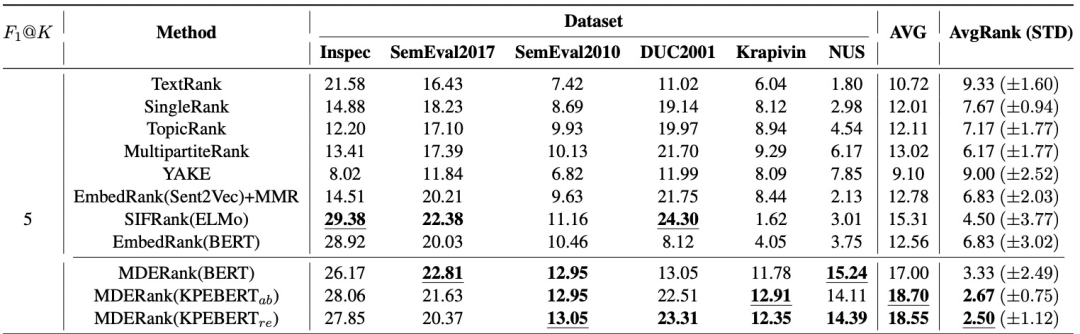
图2 不同算法在关键词抽取公开数据集上的性能对比[8]
▎技术方案
整体框架
我们面临的音视频转写场景有以下几个显著特点:
1) 类型多且涉及的领域丰富;
2) 音频转写的文本具有极强的口语以及交互特征;
3) 一小时的演讲平均字数为16000字左右,需要具备高效的长篇章处理能力。
考虑到不同方法的运行效率及效果有较大差异,综合以上场景特点,我们提出了一种注入口语特征的长篇章关键词抽取框架。其中从词粒度 -> 关键短语粒度的得分计算沿用了 Yake[5] 的计算流程,同时引入了多个额外模块、特征以及外部知识来应用到长篇章口语场景。
选用 Yake 算法作为 Term ranking 模块的主体算法,是考虑到 Yake 的高计算效率以及在不同领域和不同长度数据集上较为稳定的性能,尤其是在长文本数据集上较好的性能(图 2)。整体系统结构如图 3 所示:输入为长篇章口语的ASR结果,输出为 Top-K 关键词列表 (具体K值根据文章统计特征动态计算)。
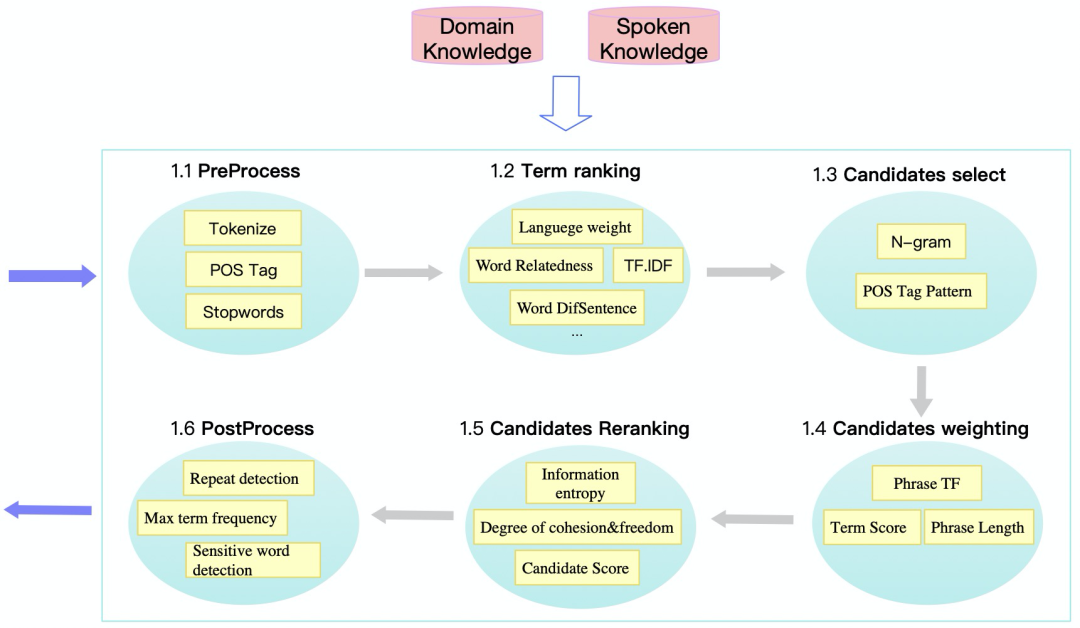
图3 长篇章口语关键词抽取框架
关键词抽取框架共包含六大模块,包括:
-
PreProcess 部分为标准的前处理模块,负责进行分词、词性标注、停用词标记、语言标记
-
Term Ranking 模块抽取分词粒度的各项特征并得到 TermScore
-
Candidates Select 模块使用 N-gram 和词性组合提取出尽可能多的关键词短语候选[9]
-
Candidates weighting 模块利用候选短语的词频,短语内子词的得分以及短语长度/词数综合计算得到候选短语得分
-
Candidates reranking 模块利用短语内子词间凝聚度以及短语的自由度来进行候选短语重排序[10]
-
PostProcess 模块对有序候选列表进行最大重复子词数、敏感词等过滤控制,最终产出结果
技术挑战及解法
1、单一的统计特征代表性弱,效果受领域影响较大
根据对经典无监督算法的调研及对比实验来看,各个方法在不同领域数据下表现差异很大;横向来看,各个数据集下不同算法的排序变化也很大。因此我们考虑在前处理、词语得分、短语得分计算中引入更多文档特征及场景特征进行融合,使得得分更契合长篇章口语场景,主要包括:
1) 词频、词语上下文关联度、词语句子覆盖度、短语词数等基础统计特征
2) 口语逆文档频率、实体词标签、领域词标签等领域特征
3) 引擎多语言适配,根据篇章的主语言自动赋予不同的语言权重
通过多项统计特征以及领域特征的引入使得系统在多个口语测试集都取得了优于经典方法的结果,同时可以兼容音视频会议中常见的多语言混杂场景。
2、口语交互场景下短语边界识别困难
标准分词的效果在口语场景上大打折扣导致算法难以精确抽取出关键短语,我们引入两个模块来缓解该问题
1). 领域知识发现
互联网百科发掘各行业实体词典,领域内语料进行新词发现扩充词典;前处理模块(PreProcess)分词过程中加入两类词典后实体词划分更准确,同时对应标签也可用于后续模块的加权得分计算。
2). 信息熵
候选选择模块 (Candidates Select) 召回了尽可能多的短语候选,解决了通用分词对一些领域实体、新词错误切分的情况,但同时也带来了很多不成词的短语,这种情况在强口语场景下尤其严重。注:比如在某些人的口语习惯里“去做”被作为常见口头禅,那么“去 做 研究”这个动词短语可能被作为关键词抽取。
针对这一问题我们参考信息熵的概念,在当前篇章中统计短语内部的凝聚度以及短语间的自由度进行加权判断成词概率,综合短语得分进行重排序。信息熵的引入使得引擎可以捕获用户维度无意义的表达组合,从而提升边界判断准确率。
通过领域知识以及信息熵两个模块的引入,引擎精确匹配F1绝对提升超过3.0。
3、口语场景常抽取出无意义词语
当前主流的词性标注工具及停用词列表主要通过书面语语料训练或统计得到,而强口语交互场景下的语言习惯与书面表达存在较大差异,使得经典算法容易抽出口语特有的无意义词语。
我们通过大规模口语交互语料统计口语语言特征,发掘出口语停用词表以及停用短语 Pattern 使得抽取结果可读性大大增强,同时也带来F1绝对提升1.1。
▎实验结果
客观指标
Exact F1@K:召回K个关键词的精准匹配F1
Partial F1@K:召回K个关键词的模糊匹配F1;最长公共子串>=2认为匹配成功
Diversity@K:用于体现召回K个关键词列表的多样性;通过两两计算Unigram的重合度并取平均得到该分值,越大越好
字/秒:算法每秒处理字数(演讲场景音频,平均每小时16000字)
效果评测
内部演讲数据集评测结果如下
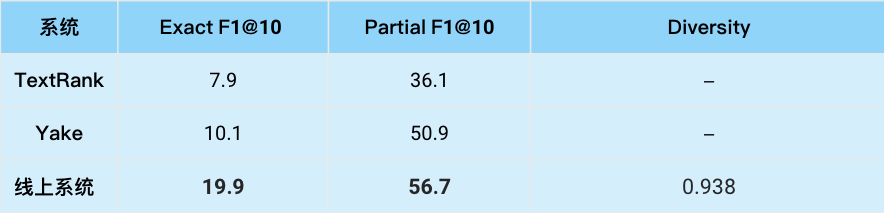
由表格内容可以看到出,相比 TextRank 和 Yake,我们的方法在精确匹配和模糊匹配的性能都有较大提升;同时内部主观评测也显示其可读性显著优于之前的方法。
针对我们的关键词引擎进行效率评测(16Core,32GB,CPU机器),单并发 = 38753 字/秒,5并发 = 32000x5 字/秒;总的来说可以做到2小时以下音频转写结果秒级响应,且提升到5并发没有明显的性能损失,满足了在各个场景下的效率要求。
▎Future work
本文介绍了阿里巴巴达摩院语音实验室口语语言处理团队在长篇章口语场景下的关键词抽取实践,包括任务背景,相关方法以及结合场景优化的技术方案,并在文末给出了评测结果。
后续的工作我们考虑如何更好利用基于预训练模型的语言表征,并将其高效引入到关键词抽取链路。相关能力已经落地到语音实验室创新产品-听悟。
Reference:
[1] Hasan K S, Ng V. Automatic keyphrase extraction: A survey of the state of the art[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2014: 1262-1273.
[2] 刘知远. 基于文档主题结构的关键词抽取方法研究. 2011.
[3] Papagiannopoulou E, Tsoumakas G. A review of keyphrase extraction[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2020, 10(2): e1339.
[4] Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
[5] Campos R, Mangaravite V, Pasquali A, et al. A text feature based automatic keyword extraction method for single documents[C]//European conference on information retrieval. Springer, Cham, 2018: 684-691.
[6] Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J]. arXiv preprint arXiv:1801.04470, 2018.
[7] Sun Y, Qiu H, Zheng Y, et al. SIFRank: a new baseline for unsupervised keyphrase extraction based on pre-trained language model[J]. IEEE Access, 2020, 8: 10896-10906.
[8] Zhang L, Chen Q, Wang W, et al. MDERank: A Masked Document Embedding Rank Approach for Unsupervised Keyphrase Extraction[J]. arXiv preprint arXiv:2110.06651, 2021.
[9] Hulth A. Improved automatic keyword extraction given more linguistic knowledge[C]//Proceedings of the 2003 conference on Empirical methods in natural language processing. 2003: 216-223.
[10] Matrix67, 互联网时代的社会语言学:基于SNS的文本数据挖掘. 2012.

















 1775
1775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









