







本文首先提出了PGD攻击的两个扩展,以克服由于次优步长和目标函数问题而导致的失败。然后,我们将我们的新攻击与两个互补的现有攻击结合起来,形成一个无参数、计算负担得起且独立于用户的攻击集合,以测试对手的鲁棒性
Auto-PGD
PGD攻击标准公式中的三个弱点,以及如何在对抗性鲁棒性环境中使用它。
首先,固定步长是次优的,因为即使对于凸问题,这也不能保证收敛性,算法的性能在很大程度上受其值选择的影响。
第二,总体方案对攻击的预算基本不可知:正如我们所展示的,在几次迭代后,损失趋于平稳,除了非常小的步长,但这并不能转化为更好的结果。因此,通过迭代次数来判断攻击强度具有误导性。
最后,算法不知道趋势,即不考虑优化是否成功进化,也不能对此做出反应。
APGD的主要思想:将可用的迭代划分为初始探索阶段和开发阶段,前者在可行集中搜索良好的初始点,后者在开发阶段中尝试最大化迄今为止积累的知识。这两个阶段之间的过渡是通过逐步减小步长来管理的。事实上,较大的步长允许在S中快速移动,而较小的步长则更渴望局部最大化目标函数。
算法

梯度更新步骤:
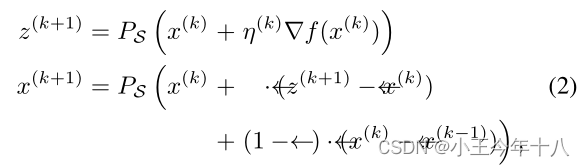
步长选择
fmax是在前k次迭代中发现的最高目标值。如果其中一个条件为真时:
将迭代k=𝜔𝑗的步长减半,并对每个k=…
进行
条件1:统计自最后一个检查点以来,更新步骤成功增加f的情况。如果至少在总更新步骤的一小部分ρ中出现这种情况,则在优化正常进行时保持步长(我们使用ρ=0.75)。
条件2:如果步长在最后一个检查点没有减小,并且自最后一个检查点以来最佳目标值没有改善,则为真。这可以防止陷入潜在的循环。
从最佳点重新开始:
如果在一个检查点wj,步长减半,那么我们设置,也就是说,我们在达到迄今为止最高目标fmax的点重新开始。这是有道理的,因为减少
会导致更本地化的搜索,这应该在当前最佳候选解决方案的附近进行。
探索与开发
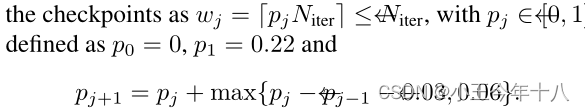
请注意,周期长度在每一步中减少0.03,但它们的最小长度至少为0.06.
APGD 与PGD的比较
在所有情况下,APGD的损失都最高(越高越好,因为这是最大化问题),这对于任何迭代预算都成立。同样,APGD始终具有最低(更好)的鲁棒性,因此对这些模型的对抗性较强(有关所有模型和不同损失的比较,请参见表9、10和11)。可以观察到APGD的自适应行为:当迭代的预算较大时,目标的值(CE损失)的增长速度较慢,但最终达到较高的值。这是由于较长的探索阶段,它牺牲了较小的改进来最终获得更好的结果。相反,不管步长的选择如何,带有动量的PGD运行趋于稳定在次优值。附录A.1节中可以找到无动量的APGD与PGD的类似比较。
损失:
如果x正确分类为y,则交叉熵损失为:
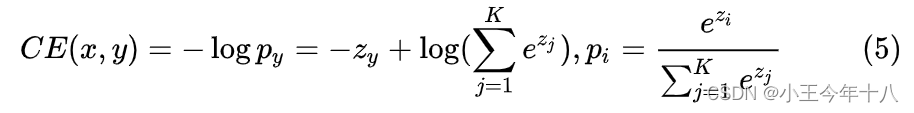
CW损失:
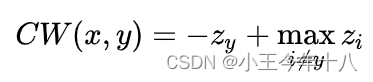
如果存在对抗样本,则CW损失的全局最大值为正
Difference of Logits Ratio (DLR)损失是移位和重缩放不变的,因此具有与分类器决策相同的自由度


AutoAttack
将PGD的两个无参数版本与FAB攻击和Square攻击结合起来,形成了自动攻击,不需要任何自由参数。

















 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









