






DeepSurv,一个Cox比例风险深度神经网络和先进的生存分析方法,用于模拟患者的预后变量(协变量)与治疗效果之间的相互作用。
一、Cox比例风险模型
当下,医学研究者使用生存模型来评估预后变量在如死亡或癌症复发等结果中的重要性。
一个常用且标准的生存模型是Cox比例风险模型 (CPH)。CPH 是一个半参数模型,用于计算观察到的协变量对事件发生(例如“死亡”)的风险的影响。CPH 一般被认为是线性的,是因为它假设给定的协变量和风险之间的关系是对数线性的。具体来说,模型的基本形式是:
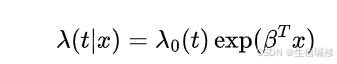
其中:

当我们考虑对数风险(也就是风险的对数),这种关系就变成了线性的:
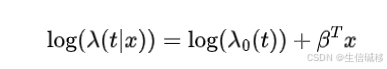
然而,在许多应用中,假设对数风险函数是线性的可能过于简化。因此,需要一个更灵活的生存模型来拟合具有非线性对数风险函数的生存数据。
二、DeepSurv神经网络模型
神经网络是一类热门的计算模型,其灵活的结构与强大的激活函数为拟合非线性生存数据提供了更完善的方案。DeepSurv 是一个深度前馈神经网络,它预测患者的协变量对其危险率的影响。
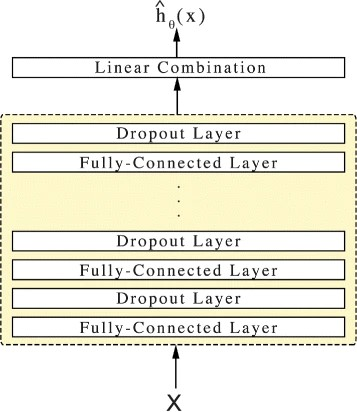
上图展示了 DeepSurv 的基本结构。网络的输入是患者的基线数据 x ,其隐藏层由一层完全连接的节点(神经元)组成,后面跟着一个 dropout 层。网络的输出 ![]() 是一个具有线性激活的单一节点,它用于估计Cox模型中的对数风险函数。最后,该模型使用如下损失函数来训练网络:
是一个具有线性激活的单一节点,它用于估计Cox模型中的对数风险函数。最后,该模型使用如下损失函数来训练网络:
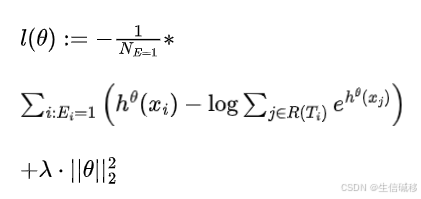
其中:
![]()
简单来说:上方损失函数的第一项用于最小化模型预测的风险![]() 与实际观察到的风险
与实际观察到的风险![]() 之间的差异;而第二项是将模型的权重限制在一个较小的范围内,防止模型的变得过于复杂。
之间的差异;而第二项是将模型的权重限制在一个较小的范围内,防止模型的变得过于复杂。
DeepSurv 于2018年发表在 BMC Medical Research Methodology,截至目前共计 1152 被引。作者在原文中对DeepSurv进行了一系列的分析,包括在模拟和真实的生存数据上进行训练。他们证明了 DeepSurv 的性能与其他最先进的生存模型相当或更好,并表示 DeepSurv 能够模拟协变量与其风险之间越来越复杂的关系。
三、简单的实例
gihub 项目地址如下:
https://github.com/jaredleekatzman/DeepSurv/tree/master
① 下载DeepSurv并从目录中安装:
git clone https://github.com/jaredleekatzman/DeepSurv.git
cd DeepSurv
pip install .
② 其它需要安装的依赖项:
-Theano
-Lasagne
-lifelinesmatplotlib
-tensorboard_logger
③ 从目录导入DeepSurv与各种依赖项:
import sys
sys.path.append('../deepsurv')
import deep_surv
from deepsurv_logger import DeepSurvLogger, TensorboardLogger
import utils
import viz
import numpy as np
import pandas as pd
import lasagne
import matplotlib
import matplotlib.pyplot as plt
%matplotlib inline
④ 读入数据集:
# 读入example_data.csv
train_dataset_fp = './example_data.csv'
train_df = pd.read_csv(train_dataset_fp)
#展示表头
train_df.head()
example_data.csv 表头如下:
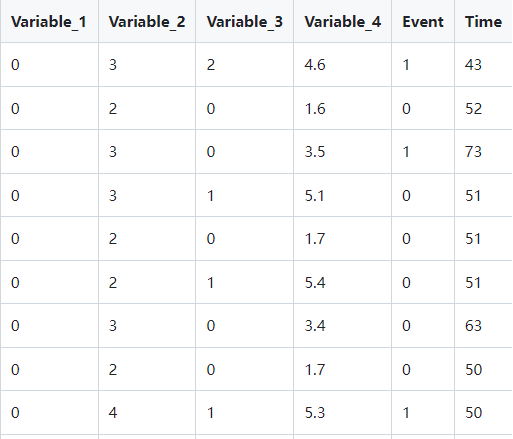
▲ 输入数据表头
⑤ 将数据集匹配为 DeepSurv 格式,x、t、e 分别为预后变量、生存时间、生存状态(注意下面注释):
# DeepSurv格式如下:
# {
# 'x': (n,d) observations (dtype = float32), # n*d维,共n个样本、d个变量
# 't': (n) event times (dtype = float32), # 生存时间,n维
# 'e': (n) event indicators (dtype = int32) # 生存状态,n维
# }
##### 将pandas数据框转换为上面的DeepSurv格式
###
##
# 自定义函数进行转换,event_col表示生存状态、time_col变量表示生存时间
def dataframe_to_deepsurv_ds(df, event_col = 'Event', time_col = 'Time'):
e = df[event_col].values.astype(np.int32)
t = df[time_col].values.astype(np.float32)
x_df = df.drop([event_col, time_col], axis = 1)
x = x_df.values.astype(np.float32)
return {
'x' : x,
'e' : e,
't' : t
}
# event_col、time_col分别定义为自己数据的表头(在这里分别是Event和Time)
# 使用该函数对训练数据集进行转换,同样可以用于测试数据集、验证数据集
train_data = dataframe_to_deepsurv_ds(train_df, event_col = 'Event', time_col= 'Time')
⑥ 定义一些超参数,都是很常见的参数了(看注释),不懂就先使用默认设置:
hyperparams = {
'L2_reg': 10.0, # L2正则化项权重,防止过拟合
'batch_norm': True, # 进行Batch Normalization,不是常规所理解的批次矫正哈,这里是用于提高模型的训练速度和稳定性
'dropout': 0.4, # 神经元丢失的概率,越大表明丢失的可能越高,对模型的过拟合越严格
'hidden_layers_sizes': [25, 25], # 隐藏层的配置
'learning_rate': 1e-05, # 学习率,为了确保模型的收敛和减少训练震荡,通常会逐渐减小学习率
'lr_decay': 0.001, # 学习率衰减,0.001 是每次迭代或每个epoch后学习率减少的量
'momentum': 0.9, # 动量更新
'n_in': train_data['x'].shape[1],
'standardize': True
}
⑦ 训练你的DeepSurv模型:
#创建一个实例
model = deep_surv.DeepSurv(**hyperparams)
#(可选) 利用 TensorBoard 来监控训练和验证
# 这个步骤是可选
# 如果你不想使用tensorboard logger,请取消下面一行的注释"#",并注释掉其他三行
# logger = None
experiment_name = 'test_experiment_sebastian'
logdir = './logs/tensorboard/'
logger = TensorboardLogger(experiment_name, logdir=logdir)
# 开始训练我们的模型
update_fn=lasagne.updates.nesterov_momentum # 你目前使用的optimizer,可以检查以下网址获得更多optimizer:http://lasagne.readthedocs.io/en/latest/modules/updates.html
# 定义epoch迭代数量,适量即可
n_epochs = 2000
# 如果有验证数据valid_data,可以将其作为第二个参数添加到下方函数中:
# model.train(train_data, valid_data, n_epochs=500)
metrics = model.train(train_data, n_epochs=n_epochs, logger=logger, update_fn=update_fn)
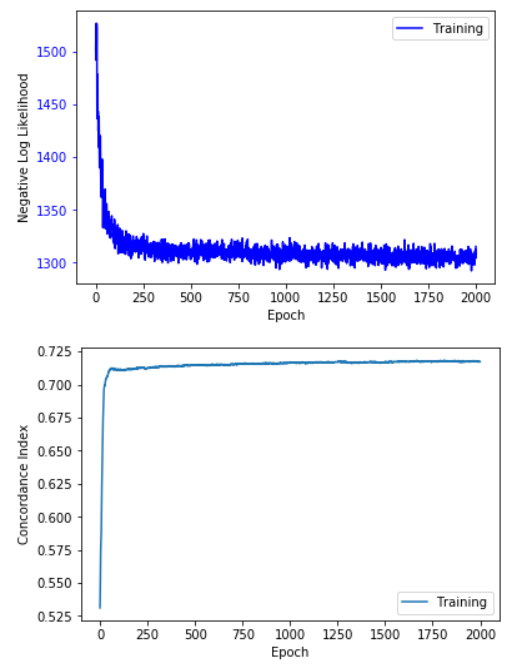
⑧ 可视化结果:
# Print the final metrics
print('Train C-Index:', metrics['c-index'][-1])
deepsurv.plot_log(metrics)
引用
-
Katzman, J.L., Shaham, U., Cloninger, A. et al. DeepSurv: personalized treatment recommender system using a Cox proportional hazards deep neural network. BMC Med Res Methodol 18, 24 (2018). https://doi.org/10.1186/s12874-018-0482-1
-
https://www.jianshu.com/p/cdc745f91deb

















 6768
6768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









