






NHANES(National Health and Nutrition Examination Survey)是美国一项具有代表性的跨越全国的健康和营养调查项目,由美国疾控中心(CDC)领导的国家健康统计中心(NCHS)于1999年执行。NHANES的调查每两年进行一次,它的目的是通过综合性的健康和营养评估来监控美国民众的健康趋势和生活方式的变化,每个调查周期发布的数据可以分为的人口统计、饮食、检查和实验室数据几种类型。
一、背景知识
①NHANES项目的目标与范围:
NHANES通过美国全国范围内的问卷调查、身体检查和实验室测试来收集各种健康和营养数据。其涉及范围广泛,涵盖以下几个领域:
-
人口统计学信息:如年龄、性别、种族、教育程度等,通常被归类为“Demographic Variables & Sample Weights”。
-
营养摄入:包括饮食行为和每日食品摄入情况,如“Dietary Interview - Individual Foods”数据集。
-
实验室测试:对血液、尿液等生物样本进行的化验,包括各种生理和代谢指标。
-
体格检查:身高、体重、血压等常规检查。
-
生活方式和社会经济调查:例如吸烟、饮酒、体力活动、经济状况等。
②NHANES的数据周期 (Cycle):
NHANES采用跨年度的连续周期,每2年为一个周期。例如:
-
2005-2006 和 2019-2020 分别表示这些数据是收集自这些两年周期,数据周期的划分是为了连续监控不同时间段的健康趋势,这样可以进行时序分析。

▲ 图1:进入数据发布网址页https://wwwn.cdc.gov/nchs/nhanes/Default.aspx,可以看到NHANES数据库的每个周期发布的数据,以及相应的介绍(页面经过翻译)。
③数据类型(记住下面几个英文):
-
Demographics Variables & Sample Weights: 这些数据集通常包含人口统计数据以及样本权重,用于分析过程中确保数据的全国代表性。需要注意的是,样本权重在NHANES中非常重要,因为它们允许分析人员根据所调查的人群来推断美国整体人口的趋势。
-
Dietary Interview - Individual Foods: 这些数据主要是关于受试者在特定日子中所食用的食物详细信息,通过24小时回忆法进行收集。
-
实验室数据:这些数据包括受试者的血液、尿液等生物标本的实验室测试结果,比如血糖、胆固醇等指标,适合用来研究某些健康状况的生物标志物。
④数据文件(XPT格式):
-
如果在官网检索,可以看到该数据库提供的文件类型都是
XPT,即SAS Transport Format (XPORT)。这种文件格式可以进行跨平台的数据分析,是SAS软件常用的导出格式之一。便捷性在于即使你不使用SAS,也可以通过Python的pandas库或者R的foreign包加载这些文件。 -
需要注意的是,不同的数据文件大小是不一样的。内存较大的文件通常包含大量个体化数据,可能涉及受访者在一天中的饮食信息,包含大量记录。较小的文件通常是人口统计信息或者权重变量,数据相对较少。
-
在调查文件中,通常使用缩写的变量名称(Variable Name)来代表不同的表型。比如,
DMDBORN表示的是 "In what country were you born?"(你出生在哪个国家?)。如果不知道相应缩写的变量名称是什么意思,可以在提供的数据表Variable Description列中 (变量描述)找到每个变量名称详细的描述。

▲ 指定年份原始数据的简要查询。
⑤权重的重要性
在使用NHANES数据进行统计分析时,权重非常重要,因为NHANES的样本并不是简单的随机抽样,而是通过一个分层、多阶段的概率设计。样本权重帮助修正由抽样设计带来的偏差,使得结果可以推及全国人口。如果忽略了权重,分析结果可能不会反映真实的人口水平。例如,在分析人口统计数据时,需要将样本权重 WTINT2YR 应用于模型或计算中。
二、使用RNHANES包整合来自NHANES的数据

RNHANES是一个用于访问和分析NHANES数据的R包,该包由Silent Spring Institute开发,有下面几个特点:
-
下载并搜索NHANES数据文件
-
计算调查加权的检测频率、分位数和几何平均数
-
绘制加权直方图
①小编推荐下载最新的RNHANES包:
devtools::install_github("silentspringinstitute/RNHANES")
②可以使用下面两个函数分别获得最新的files以及variables列表:
files <- nhanes_data_files()
variables <- nhanes_variables()
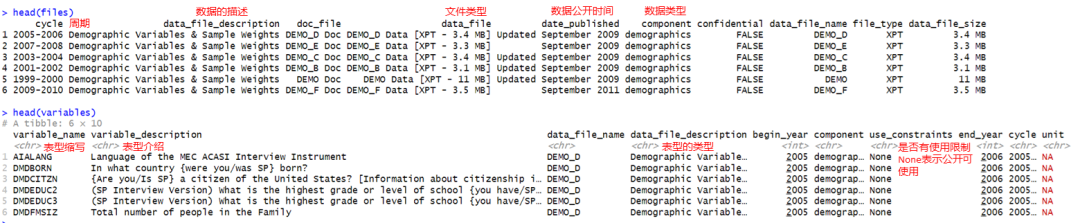
▲ files与variables对应的内容分别如上。
③随后可以使用nhanes_search在files和variables列表中搜索感兴趣的数据,第二个参数默认搜索data_file_description列下包含相应字符的数据行(看下面的注释):
# 在files列表中搜寻
nhanes_search(files, "environmental phenols") # data_file_description列限定包含environmental phenols
nhanes_search(files, "pesticides", component == "laboratory", cycle == "2003-2004") # data_file_description列限定包含pesticides,同时component列为laboratory,cycle列为2003-2004
nhanes_search(files, "", cycle == "2003-2004") # data_file_description列不做限制,cycle列为2003-2004
# 在variables列表中搜寻
nhanes_search(variables, "triclosan") # data_file_description列限定包含triclosan
nhanes_search(variables, "DDT", data_file_name == "LAB28POC") # data_file_description列限定包含DDT,限定data_file_name列为LAB28POC
④使用nhanes_load_data函数加载文件,第一种使用方法是直接加载相应年份的数据,EPH_E对应files列表中data_file_name列,2007-2008对应相应的研究周期:
nhanes_load_data("EPH_E", "2007-2008")
第二种使用方法是一次性加载多个周期、多个文件:
nhanes_load_data(c("PHTHTE", "PFC"), c("2007-2008", "2007-2008"))
第三种使用方法是基于第③步nhanes_search函数的返回结果加载文件:
results <- nhanes_search(variables, "triclosan")
triclosan <- nhanes_load_data(results$data_file_name, results$cycle, demographics = TRUE)
额外给大家介绍nhanes_load_data函数的两个参数,demographics与recode:
phenols <- nhanes_load_data("EPH", "2007-2008", demographics = TRUE, recode = TRUE)
前者可以让我们获得调查权重信息,后者可以将原先的表格的分类数值,转换成相应的表型描述。各位老铁实操一下即可。
三、示例文献
再给各位老铁们分享最近发表的纯NHANES建模文献,于2024年09月02号发表在 Journal of Affective Disorders [4.9] 的相关文章:"Development and external validation of a risk prediction model for depression in patients with coronary heart disease",冠心病患者抑郁症风险预测模型的开发与外部验证。

▲ DOI: 10.1016/j.jad.2024.08.218
该研究收集了NHANES数据库中2005年至2012年间四个调查周期的数据作为训练集,2013-2014、2015-2016 和 2017-2018调查周期的数据被用作外部验证集。在训练集中,分别采用已发表的文献方案、逻辑回归、LASSO回归、最优子集算法和随机森林算法筛选预测变量。根据C指数、净重分类改善(NRI)和综合区分改善(IDI)选择了最佳预测模型,同时构建了最佳预测模型的列线图。简单来讲,这个模型就是在患有冠心病的人身上构建了一个抑郁症预测模型,基于NHANES数据库中的各种表型
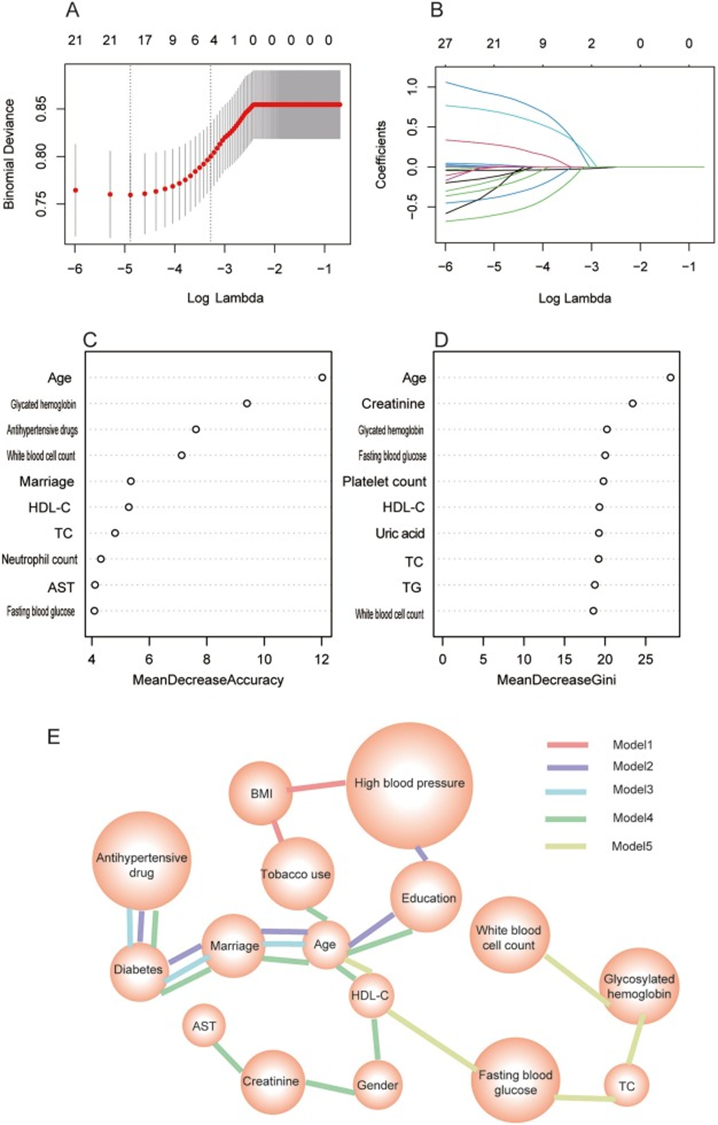
▲ 论文中图片:几种算法筛选最优的预测变量。
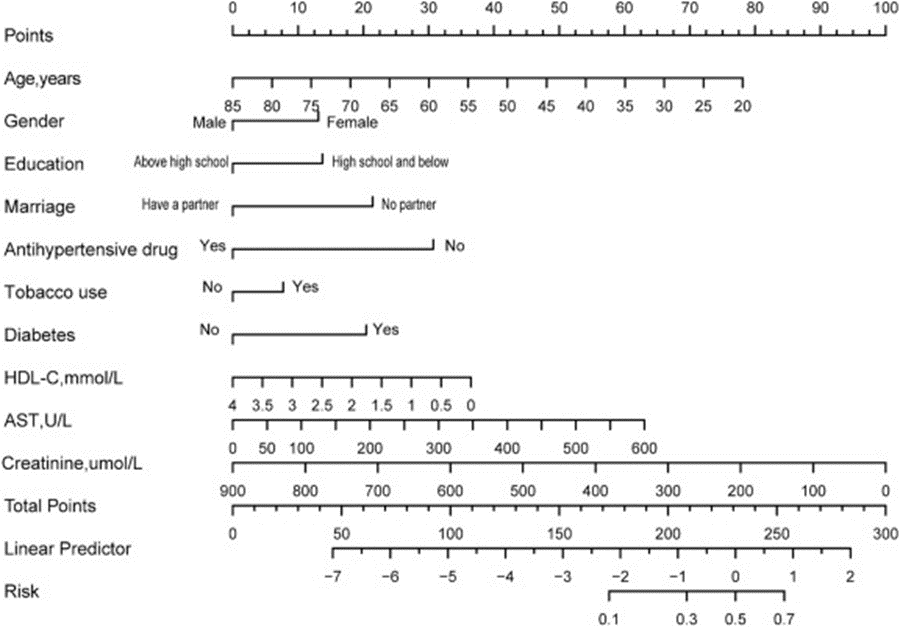
▲ 论文中图片:最终构建的列线图模型。
今天就分享到这里
各位老铁节日快乐


















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









