



 VisionTransformer(ViT)提出了将Transformer应用于视觉领域的创新方法,通过将图像切分为小块,然后输入Transformer进行处理,克服了自注意力机制在高分辨率图像上的计算复杂性。模型结构包括全连接层、多头注意力和MLP。尽管Transformer缺乏CNN的空间性和平移不变性,但它能学习到图像的概念信息。在微调时,对于不同尺寸的图片,位置编码可能需要重新学习或插值处理。
VisionTransformer(ViT)提出了将Transformer应用于视觉领域的创新方法,通过将图像切分为小块,然后输入Transformer进行处理,克服了自注意力机制在高分辨率图像上的计算复杂性。模型结构包括全连接层、多头注意力和MLP。尽管Transformer缺乏CNN的空间性和平移不变性,但它能学习到图像的概念信息。在微调时,对于不同尺寸的图片,位置编码可能需要重新学习或插值处理。
Vision Transformer
提出背景:
当时Transformer在自然语言领域取得巨大成功,但在视觉领域还没有广泛应用。在视觉中的attention要么是直接替换卷积操作,要么是先卷积后attention,但整体上的模型结构并没有变,例如还是几个残差block。但在视觉领域中,对卷积网络的依赖是不必要的,只利用Transformer直接对图片进行操作,效果就可以达到很好。

但在自然语言中的自注意力机制需要两两进行运算,运算复杂度是n2,目前硬件支持的最大长度也就是几百上千,若将整个256*256分辨率的图片直接拉成像素进attention,复杂度为256X256远远大于几百,故不可行。所以在此文章之前大多数的方法都是用CNN抽取的图片特征图拉直进attention或在图片中取几个小框或者跨轴进行操作(先在高度上进行self-attention再在宽度上进行self-attention)。
本文方法
将(224,224,3)的图片分成小块,每一块的大小为(16,16,3);每一个图像块就像一个单词一样。则输入进attention的维度为16*16*3=768,正好和文本维度一样,可直接输入进Transformer。
模型结构如下图:

其中将整个图片打成9个patch,每个patch维度为1616*3=768。输入进768768的全连接层,在借鉴BERT加上一个[cls]位用于分类,并加入position embedding。

输入197768,经过多头,若使用12个头则每个头的KQV为19764,再concat回到768,经过MLP先升维再降维。
Transoformer对比CNN的缺点:
缺点:CNN有两个归纳偏置:空间性和平移不变性
空间性:相邻的像素块会有相近的含义;
平移不变性:先平移后卷积和先卷积后平移的结果是一样的。
所以相当于CNN有了两个先验知识,故在小一点的数据集上就可以学到很多知识。
视觉和自然语言方法的不同:
- 在nlp中用[cls]进行分类,在视觉中用glob pooling,通过对比实验发现两种方法效果一样。
- 在nlp中position embedding用1d的,对图片采用2d的位置编码或采用相对位置编码,通过实验对比发现效果一样。
缺陷:
在微调时,理论上可以处理任意尺寸的图片。但若不是论文中的224*224,则预训练所训得的位置编码就没有用了,就得重新学。若想临时的解决,则可以做插值操作。
位置编码可视化:
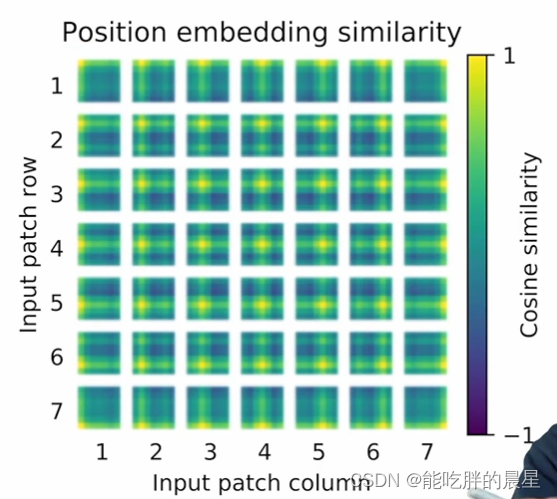
可以发现位置编码是可以学到2d图像间距离的概念。
注意力可视化:

图中可以发现attention是可以学习到图片中的概念信息的。
本博客借鉴b站沐神精读论文系列中朱毅大神对ViT的讲解

















 3706
3706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









