







 本文详细介绍了TensorFlow中Adam优化器的函数用法,包括其参数学习率、beta_1、beta_2和epsilon的作用。默认设置为beta_1=0.9, beta_2=0.999, epsilon=1e-07。通过(optimizer=tf.keras.optimizers.Adam(0.001))创建实例,并使用(optimizer.apply_gradients(zip(gradients, elmo.trainable_variables)))进行参数更新。理解优化器对于深度学习模型的训练至关重要。
本文详细介绍了TensorFlow中Adam优化器的函数用法,包括其参数学习率、beta_1、beta_2和epsilon的作用。默认设置为beta_1=0.9, beta_2=0.999, epsilon=1e-07。通过(optimizer=tf.keras.optimizers.Adam(0.001))创建实例,并使用(optimizer.apply_gradients(zip(gradients, elmo.trainable_variables)))进行参数更新。理解优化器对于深度学习模型的训练至关重要。
函数原型
tf.keras.optimizers.Adam(
learning_rate=0.001,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-07,
amsgrad=False,
name='Adam',
**kwargs
)
函数说明
Adam函数定义了参数更新的方式,模型参数
θ
\theta
θ的具体更新过程如下所示:
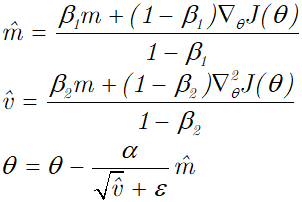
参数leanrning_rate对应于学习率或者步长
α
\alpha
α;参数beta_1,beta_2对应于
β
1
\beta_1
β1,
β
2
\beta_2
β2,表示梯度的带权平均和带权方差,初始为0向量;参数epsilon对应于
ϵ
\epsilon
ϵ。
建议参数 β 1 \beta_1 β1=0.9, β 2 \beta_2 β2=0.99, ϵ \epsilon ϵ=10^-8。针对特定问题,需要结合数值选择合适的算法。
函数使用
# 优化器adam
optimizer = tf.keras.optimizers.Adam(0.001)
# 应用梯度,这里会可以更新的参数应用梯度,进行参数更新
optimizer.apply_gradients(zip(gradients, elmo.trainable_variables))


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











