







我自己的原文哦~ https://blog.51cto.com/whaosoft/13759942
#斯坦福吴佳俊扩散自蒸馏来了
突破文生图身份保留挑战
艺术家们该高兴了。
近年来,文本到图像扩散模型为图像合成树立了新标准,现在模型可根据文本提示生成高质量、多样化的图像。然而,尽管这些模型从文本生成图像的效果令人印象深刻,但它们往往无法提供精确的控制、可编辑性和一致性 —— 而这些特性对于实际应用至关重要。
单靠文本输入可能不足以传达图像细节,中间出现的变化很多情况下与用户的意图不完全一致。
然而,保持主体身份的一致性面临很大的挑战。如下图所示,在「结构 - 保留编辑」中,目标和源图像共享总体布局,但可能在风格、纹理或其他局部特征上有所不同;在「身份 - 保留编辑」中,图像结构可能发生大规模变化,但资产在目标和源图像之间可识别为相同。

对于结构 - 保留编辑,添加层(如 ControlNet )可引入空间条件控制,但仅限于结构指导,无法解决跨不同上下文的一致身份适应问题。对于身份保留编辑,DreamBooth 和 LoRA 等微调方法可以使用一些参考样本来提高一致性,但耗时且计算密集,需要对每个参考进行训练。零样本替代(如 IP-Adapter 和 InstantID )提供了更快的解决方案,无需重新训练,但无法提供所需的一致性和定制水平;IP-Adapter 缺乏完全的定制功能,而 InstantID 仅限于面部身份。
在新鲜出炉的一项研究中,斯坦福大学的吴佳俊等研究者提出了一种名为扩散自蒸馏(Diffusion Self-Distillation,DSD)的新方法,该方法使用预训练的文本到图像模型来生成它自己的数据集,并用于文本条件的图像到图像任务。

- 论文标题:Diffusion Self-Distillation for Zero-Shot Customized Image Generation
- 论文链接:https://arxiv.org/pdf/2411.18616
- 项目主页:https://primecai.github.io/dsd/
首先利用文本到图像扩散模型的上下文生成能力来创建图像网格,并在视觉语言模型的帮助下策划一个大型配对数据集。然后,使用精选的配对数据集将文本到图像模型微调为文本 + 图像到图像模型。该研究证明了扩散自蒸馏法优于现有的零样本方法,并且在广泛的身份保留生成任务上与每个实例的微调技术具有竞争力,而无需测试时间优化。
论文作者之一、斯坦福大学计算机科学博士生蔡盛曲表示:DSD 重新定义了使用 FLUX 进行零样本自定义图像生成,DSD 类似于 DreamBooth,是零样本、无需训练的。它适用于任何输入主题和所需的上下文角色一致性,项目、资产适应,场景重照明等等。它甚至可以创建漫画,而无需任何微调或训练个性化模型!

以下是一些示例展示:
角色保留:

实物保留:

创建漫画:

扩散自蒸馏
最近的文本到图像生成模型具有令人惊讶的能力,可以生成上下文一致的图像网格(见图 2 左)。受此启发,研究者开发了一种零样本适应网络,它能快速、多样、高质量地生成图像,并能保留身份,即以参考图像为条件生成一致的图像。

为此,研究者首先使用预训练的文本到图像扩散模型、大语言模型 (LLM) 和视觉语言模型 (VLM) 生成并整理出具有所需一致性的图像集(3.1 节)。
然后,研究者利用这些一致的图像集对相同的预训练扩散模型进行微调,并采用新提出的并行处理架构(3.2 节)来创建条件模型。
通过这种方法,扩散自蒸馏以监督的方式将预训练好的文本到图像扩散模型微调为零样本定制图像生成器。
生成成对数据集
为了创建用于监督扩散自蒸馏训练的成对数据集,研究者利用预训练文本到图像扩散模型的新兴多图像生成功能,生成由 LLM 生成的提示(第 3.1.2 节)所创建的潜在一致的普通图像(第 3.1.1 节)。然后,研究者使用 VLM 对这些普通图像样本进行整理,获得具有所需身份一致性的干净图像集(第 3.1.3 节)。数据生成和整理流程如图 2 左所示。
并行处理架构
研究者希望有一个适用于通用图像到图像任务的条件架构,包括保留结构的转换以及保留概念 / 特征但不保留图像结构的转换。这是一个具有挑战性的问题,因为它可能需要在不保证空间一致性的情况下传输精细细节。
虽然 ControlNet 架构在结构保留编辑(如深度 - 图像或分割图 - 图像)方面表现出色,但在更复杂的身份保留编辑(源图像和目标图像不是像素对齐的)中,它却难以保留细节。
另一方面,IP-Adapter 可以从输入图像中提取某些概念,比如风格。但它仍然严重依赖于特定任务的图像编码器,往往无法保留更复杂的概念和特征。
研究者从多视角和视频扩散模型的成功经验中汲取灵感,提出了一种简单而有效的方法,将普通扩散 transformer 模型扩展为图像条件扩散模型。
具体来说,他们将输入图像视为视频的第一帧,并生成双帧视频作为输出。最终损失是通过双帧视频计算得出的,为第一帧建立了一个身份映射,为第二帧建立了一个条件编辑目标。
如图 2 右所示,本文的架构设计可实现两帧之间的有效信息交换,使模型能够捕捉复杂的语义并执行复杂的编辑,因此可用于通用的图像到图像转换任务。
实验
在实验中,研究者使用了 FLUX1.0 DEV 作为教师模型和学生模型,实现了自蒸馏。生成提示使用的是 GPT-4o,数据集整理和字幕制作使用 Gemini-1.5。他们在 8 个英伟达 H100 80GB GPU 上训练所有模型,有效批大小为 160,迭代次数为 100k,使用 AdamW 优化器,学习率为 10^-4。这里的并行处理架构在基础模型上使用了秩为 512 的 LoRA。
定性评估
下图 4 展示了定性对比结果,表明本文的模型在主体适应性和概念一致性方面明显优于所有基线模型,同时在输出结果中表现出出色的提示对齐性和多样性。文本反转法作为一种早期的概念提取方法,只能从输入图像中捕捉到模糊的语义,因此不适合需要精确主体适应的零样本定制任务。

值得注意的是,IP-Adapter+ 使用了更强的输入图像编码器,加剧了这一问题,导致输出的多样性和适应性降低。相比之下,本文的方法既能有效地保留主体的核心身份,又能进行多样化的、与上下文相适应的转换。如图 5 所示, 「扩散自蒸馏」技术具有显著的多功能性,能熟练处理不同目标(人物、物体等)和风格(逼真、动画等)的各种定制目标。此外,还能很好地概括各种提示,包括类似于 InstructPix2Pix 的指令,凸显了其在各种定制任务中的鲁棒性和适应性。

定量评估
表 1 展示了与基线的定量对比。本文的方法在概念保留和提示跟随方面都取得了最佳的整体性能,而在前者方面仅逊于 IP-Adapter+ (主要是因为「复制粘贴」效应),在后者方面则逊于按实例调整的 DreamBooth-LoRA。我们注意到,DreamBench++ 的概念保留评估仍然偏向于「复制粘贴」效应,尤其是在更具挑战性和多样性的提示上。例如,IP-Adapter 系列之所以在概念保留方面表现出色,主要是因为它们具有很强的「复制粘贴」效果,即在复制输入图像时不考虑提示中的相关基本变化。
这在一定程度上也可以从它们表现不佳的提示跟随得分中看出来,它们偏向于参考输入,而不考虑输入提示。因此,研究者也提出了「去偏见」版 GPT 分数,它就像告诉 GPT 如果生成的图像类似于参考图像的直接拷贝就进行惩罚一样简单。可以注意到,IP-Adaper+ 的优势已不复存在。总体来说,扩散自蒸馏是其中表现最好的模型。

消融实验
左图是基础模型的上下文采样能力与 LoRA 过拟合模型进行了比较。研究者观察到,虽然将 LoRA 应用于基础模型可以增加输出为一致网格的可能性,但它可能会对输出多样性产生不利影响。右图将本文提出的架构设计与原始条件模型(通过添加一些输入通道)、ControlNet 和 IP-Adapter 进行了比较,表明本文架构可以更好地学习输入概念和身份。实验还证明了本文架构可以有效地扩展到类似于 ControlNet 的深度条件图像生成。

更多研究细节,可参考原论文。
#BlueLM-V-3B
算法系统协同优化,vivo与港中文推出BlueLM-V-3B,手机秒变多模态AI专家
BlueLM-V-3B 是一款由 vivo AI 研究院与香港中文大学联合研发的端侧多模态模型。该模型现已完成对天玑 9300 和 9400 芯片的初步适配,未来将逐步推出手机端应用,为用户带来更智能、更便捷的体验。
近年来,多模态大语言模型(MLLM)的迅猛发展,为我们的日常生活带来了无限可能。手机作为我们形影不离的「智能伴侣」,无疑是 MLLM 最理想的落地平台。它能够将强大的 AI 能力,无缝融入我们的日常任务,让科技真正服务于生活。
然而,要将 MLLM 部署到手机上,并非易事。内存大小和计算能力的限制,就像两座大山,横亘在 MLLM 与手机之间。未经优化的模型,难以在手机上实现流畅、实时的处理,更遑论为用户带来良好的体验。
- 论文地址:https://arxiv.org/abs/2411.10640
为了攻克这一难题,vivo AI 全球研究院和香港中文大学多媒体实验室共同推出了 BlueLM-V-3B。这是一款专为移动平台量身打造的 MLLM,采用了算法与系统协同设计的创新理念,重新设计了主流 MLLM 的动态分辨率方案,并针对手机硬件特性进行了深度系统优化,从而实现了在手机上高效、流畅地运行 MLLM。
BlueLM-V-3B 具有以下几个显著特点:
算法与系统协同优化
研究团队分析了经典 MLLM 使用的动态分辨率方案,发现了图像过度放大的问题,并提出了针对性的解决方案。
此外,他们还针对硬件感知部署进行了一系列系统设计和优化,使 MLLM 在移动设备上能够更高效地进行推理,充分发挥硬件潜力。
卓越的模型性能
BlueLM-V-3B 在性能上表现出色,在参数规模相似的模型中达到了 SOTA 水平(例如,在 OpenCompass 基准测试中取得了 66.1 的高分)。
更令人惊喜的是,BlueLM-V-3B 甚至超越了一系列参数规模更大的 MLLM(例如,MiniCPM-V-2.6、InternVL2-8B),展现了其强大的实力。
高效的移动端部署
BlueLM-V-3B 在移动端部署方面同样表现优异。以联发科天玑 9300 处理器为例,其内存需求仅为 2.2GB,能够在约 2.1 秒内完成对 768×1536 分辨率图像的编码,并实现 24.4token/s 的 token 输出速度。
这意味着,用户可以在手机上享受到流畅、高效的 MLLM 体验,而无需担心算力瓶颈。

BlueLM-V-3B 设计思路
模型主体结构
BlueLM-V-3B 延续了传统的 LLaVA 架构,包括视觉编码器 SigLIP-400M,MLP 线性映射层,以及大语言模型 BlueLM-3B。
为了更好地处理高分辨率图片,和主流 MLLM 一样,BlueLM-V-3B 采用了动态分辨率方案,并针对 InternVL 1.5 和 LLaVA-NeXT 中存在的图像过度放大问题进行了改进。
此外,为了应对手机 NPU 在处理长输入 token 时的性能限制,BlueLM-V-3B 还引入了 token 降采样的方案,以确保模型在移动设备上的顺利部署。

动态分辨率
- 算法改进:
为了提升多模态模型应对高分辨率图片的能力,主流的 MLLM 往往采用动态分辨率的方案进行图片的放缩和裁切。该团队发现主流动态分辨率方案,如 LLaVA-NeXT 和 InternVL 1.5 往往伴随图片过度放大。

传统的动态分辨率方案往往会选择一个分辨率(如 384x384)作为基准尺寸,并选择合适的长宽比对图像进行缩放。
对于 LLaVA-NeXT,给定一个分辨率为 394×390 的图像,它会选择 2:2 的图片比例,然后将原始图像调整并填充至 768×768(放大 4 倍)。
对于 InternVL1.5,给定一个分辨率为 380×76 的图像,它会选择 5:1 的比例,直接将原始图像调整至 1920×384(放大 25 倍)。
这种放大并不一定丰富了图像信息,但会导致更多的图像切块,从而增加图像 token 的数量,增加移动设备上的部署难度。
鉴于此,BlueLM-V-3B 基于 LLaVA-NeXT 设计了一种宽松的长宽比选择算法,综合考虑了放缩后图片的有效信息分辨率以及浪费的空间,有效提高了图片信息的利用率,减少了部署时的图片 token 长度,降低图片的处理延时。

- 硬件感知的系统设计
图像并行编码:经过动态分辨率处理后,图像被分为多个局部切块以及一张全局缩略图切块。为了加速部署推理,BlueLM-V-3B 采用并行策略来利用 NPU 的计算能力。
与高级语言(例如 Python)不同,硬件加速设计需要对计算资源进行底层控制,例如内存布局和基于寄存器大小的计算优化。
由于 NPU 的计算能力有限,所有图片切块无法同时有效处理;相反,BlueLM-V-3B 一次处理固定数量的切块,以获得并行处理和硬件性能的平衡。

流水线并行处理:在模型推理过程中,BlueLM-V-3B 实现了流水线并行方案,以优化图像切块的编码效率。
具体而言,对于从单个图像中提取的不同切块,BlueLM-V-3B 为 SigLIP 视觉嵌入模块的 Conv2D 层和 ViT 层设计了流水线并行方案。这种方法有效地隐藏了 Conv2D 操作的执行延迟,提升了整体处理速度。

Token 降采样
- 基础算法:
虽然 BlueLM-V-3B 设计了一种宽松的长宽比选择算法来降低部署过程中图片 token 的数量,但动态分辨率带来的图片 token 数量依然很多。
为此,BlueLM-V-3B 采用了 VILA 提出的 token 数量下采样方案,将每 2×2 个图像 token 合并为一个 token,并采用一个线性层做信息融合,降低了部署难度。
- 系统设计:
分块计算输入 token:在 LLM 推理过程中,传统 GPU 通过并行计算技术同时处理所有输入 token 以加速计算。然而,由于图像 token 长度较长、上下文信息复杂以及 NPU 计算能力有限,导致并行处理效率低下。逐个 token 的顺序处理也不是最佳选择。
因此,BlueLM-V-3B 在移动设备上采用了分块策略,每次迭代并行处理 128 个输入 token(t128),然后合并结果,以在并行处理与 NPU 计算资源之间实现平衡。
模型量化和总体推理框架
- 模型量化:
混合参数精度:BlueLM-V-3B 通过混合精度量化降低内存使用并提升推理速度。权重方面,SigLIP 和 MLP 线性映射层采用 INT8 精度,LLM 则使用 INT4 精度,平衡了计算效率与模型精度。
由于激活值对量化更敏感,LLM 的激活使用 INT16 精度,SigLIP 及映射层的激活则使用 FP16,以确保模型性能。推理过程中,KV 缓存采用 INT8 精度存储。
- 解耦图像编码与指令处理:
为了提高部署效率,BlueLM-V-3B 将图像处理与用户输入解耦。在模型初始化时,ViT 和 LLM 模型同时加载到内存中。用户上传图像时,由于 MLLM 在本地部署,上传几乎没有延迟。图像上传后,ViT 立即开始处理,用户可以同时输入指令;对于音频指令,BlueLM-V-3B 会先将其转换为文本。
图像处理完成后,用户的命令提交给 LLM 生成响应,ViT 可以从内存中释放。这种并行处理减少了第一个 token 生成的等待时间,提高了响应速度,并将 BlueLM-V-3B 的峰值内存使用限制在 2.2GB。

BlueLM-V-3B 的训练过程
训练流程
BlueLM-V-3B 从 BlueLM-3B 语言模型开始分两个阶段进行训练。在第一阶段,预训练线性映射层,同时保持 ViT 和 LLM 冻结。在第二阶段,使用大量的图像 - 文本对对模型进行全面微调。
训练数据
- 第一阶段:
第一阶段旨在赋予模型基本的多模态能力。在这一阶段,该团队利用开源数据集,创建了一个由 250 万条图像 - 文本对组成的综合预训练数据集,这些数据集来自 LLaVA、ShareGPT4V 和 ALLaVA。
- 第二阶段:
在这一阶段,研究团队精心构建了一个包含 6亿+ 条图像 - 文本对的数据集,其中包括开源数据集和内部数据集。该数据集涵盖了各种下游任务和多样化的数据类型,如图像描述、视觉问答、文本图片识别和纯文本数据。
除了开源数据集,他们还加入了大量内部数据以增强模型的能力。比如,从各种网站上爬取了大量的纯文本数据和图像 - 文本对。对于不同的数据类别,如 PDF、公式、图表、解题数据、多语种数据,团队还手动渲染并创建了大量的图像-文本对,以丰富训练数据的多样性。
除了进行图像渲染外,研究团队还使用 GPT-4o 和 Gemini Pro 构造和修改图片描述及视觉问答对。开源与专有数据的结合显著提升了模型的能力,使其能从多样化的示例中学习,并在多种任务和模态上提升性能。
实验结果
宽松的长宽比选择算法
- 部署效率:
该团队在 LLaVA 665k 训练集上验证了改进方案是否能降低部署成本。为公平对比,他们将 LLaVA-NeXT、InternVL 1.5 和改进方案的最大分块数均设置为 9。
与 LLaVA-NeXT 相比,提出的方法在 2.9 万个样例中选择了更小的长宽比;而在与 InternVL 1.5 的比较中,在 52.3 万个样例中采用了更小的长宽比,在 2.5 万个样例中选择了更大的长宽比。这显著提升了 NPU 上的推理效率。
- 测评集性能:
研究团队在 MiniCPM-2B 和 BlueLM-3B(均为 2.7B 参数量)两个模型上进行实验,利用 LLaVA 558k 进行第一阶段训练,用 LLaVA 665k 进行第二阶段训练。比较 LLaVA-NeXT、InternVL 1.5 和改进方案在测评集上的性能表现。
由于 3B 模型的学习速度较慢,每个阶段训两轮。该团队统计了在多个常用测评集上的结果。

可以看到新设计的动态分辨率方案不仅降低了部署成本,还提升了测评集上的准确率。
不同测评集上的准确率比较
- OpenCompass 测评集:
下图展示了全量微调完的 BlueLM-V-3B 模型在 OpenCompass 测评集上的精度表现,并和总参数量小于等于 10B 的模型进行比较。

可以看到,BlueLM-V-3B 模型在 4 个测试项目中取得最高分,并在均分上排名第二。这展示了 BlueLM-V-3B 模型的强劲性能。
- 文本数据集 / OCR 能力:
下图是 BlueLM-V-3B 与参数量相近的多模态模型在 TextVQA,DocVQA 以及多语种多模态数据集 MTVQA 上的评测结果。

可以看到,在 OCR 相关任务上,BlueLM-V-3B 取得了非常有竞争力的成绩,并在多语言测评中远超主流的多模态模型。
BlueLM-V-3B 部署效率
团队汇报了在搭载天玑 9300 处理器的 vivo X100 手机上的部署结果。
- 图像并行编码:
实验中,采用了 2:4 的分块方案(对手机屏幕的处理采用 2:4 方案),共有 2x4=8 个局部分块和一个全局分块。该团队测试了同时处理 1 块、2 块、4 块、6 块图像切块的 NPU 处理延时。

可以看到,同时处理 4 个切块的总延时最低,仅为 1.9 秒。
- 流水线并行处理:
该团队设计了对 SigLIP 模型的 Conv2D 和 ViT 部分在 CPU 和 NPU 上的流水线并行,并测试了 2:4 分块方案下的部署效率。如上文流水线管线所示,可以掩盖 200 毫秒的 Conv2D 的处理延时。
- 分块计算输入 token:
该团队在 NPU 上采用了一种分块处理策略,每次迭代并行处理 128 个输入 token(t128),以平衡并行处理与 NPU 性能。在此展示并行处理不同数量输入 token 时的 LLM 首词延时:t32、t128、t512 和 t2048。
论文中还列出了输出 token 的生成速度,其中仅显示了 t1 的情况,因为 LLM 在输出时一次处理一个 token。输入 token 长度被固定为 2048,KV 缓存长度被设置为 2048。

可以看到,t128/t1 实现了最低的延迟和最快的生成速度。
- 和 MiniCPM-V 对比:
该团队对 BlueLM-V-3B 与 MiniCPM-V 论文中提供的统计数据进行了直接比较。MiniCPM-V 论文仅报告了 8B 参数量的 MiniCPM-V 2.5 模型在天玑 9300 芯片的 CPU 上使用 llama.cpp 部署的情况。BlueLM-V-3B 团队使用分辨率为 768×1536 的图像,固定输入 token 长度为 2048,并将 KV 缓存长度设为 2048。

MiniCPM-V 将模型加载时间也计入了延迟。对于 BlueLM-V-3B,在系统初始化阶段,同时加载 ViT 和 LLM 的时间仅为 0.47 秒。结果显示,BlueLM-V-3B 因其较小的参数量和优秀的系统设计,在延迟和 token 吞吐量上更具优势。
总结
在 BlueLM-V-3B 的开发过程中,vivo 和港中文团队在确保良好用户体验的同时,注重算法 - 系统协同设计和硬件感知优化。据实验与统计分析显示,BlueLM-V-3B 在移动设备上表现出色,性能强劲且部署高效。
未来,该团队将继续致力于提升端侧模型的可扩展性,并探索先进算法,持续优化性能与可用性,以适应更多的手机设备。




#OASIS
上百万智能体在OASIS模拟平台上玩推特,AI玩社交媒体和真人有多像?
OASIS 的共同第一作者为(按随机顺序):阿卜杜拉国王科技大学(KAUST)访问学生,上海 AI Lab 实习生,CAMEL AI 社区实习生杨子熠,以及大连理工大学博士生、上海 AI Lab 实习生张再斌(导师为卢湖川教授)。
通讯作者包括:上海 AI Lab 星启研究员尹榛菲,Egent.AI CEO、CAMEL AI 社区发起人李国豪,以及上海 AI Lab 青年科学家邵婧。
由超过一百万个大模型智能体组成的虚拟社会会是什么样的?
最近,上海 AI Lab、CAMEL-AI.org、大连理工大学、牛津大学、马普所等国内外多家机构联合发布了一个名为 OASIS 的百万级智能体交互开源项目。
该项目构建了一个以大模型为基座的通用社会模拟平台,支持多达百万个 AI 智能体进行交互。研究人员可以利用 OASIS 轻松模拟超大规模 AI 智能体在复杂社会环境中的互动。
例如,在社交媒体场景(例如 Twitter 和 Reddit 等平台)上对消息传播、群体极化和羊群效应等经典社会现象进行研究。
这些示范性研究验证了 OASIS 作为社会模拟平台的有效性和实用性,同时 OASIS 也对智能体社会在大模型和智能体迈向 AGI 的技术路径中产生的影响进行了讨论。
- 论文地址:https://arxiv.org/abs/2411.11581
- 代码地址:https://github.com/camel-ai/oasis
- 项目主页:https://oasis.camel-ai.org
- 论文标题:OASIS: Open Agent Social Interaction Simulations with One Million Agents
研究背景
随着大语言模型通用能力的不断提升,基于大语言模型的 AI 智能体已成为当前 AI 领域的主要研究趋势。从单个智能体的研究到多个智能体的交互,诞生了诸多引人注目的成果,例如 CAMEL [1]、Generative Agents [2]、ChatDEV [3]、MetaGPT [4] 等。
然而,现有方法普遍面临以下几个挑战:
1. 规模扩展不足:目前很少有研究将智能体的交互数量扩展到上万量级,而实现这一目标需要克服复杂的工程挑战。
2. 交互形式有限:即便有一些工作实现了上万量级的智能体交互,这些交互的形式仍然较为初步,通常只能支持简单场景的模拟。
OASIS 平台思考的核心问题之一是:「如何设计一个平台,能够支持上万甚至上百万智能体的交互模拟?」
一个很直观的想法是采用类似「群聊」的模式,但让一百万个智能体同时参与群聊显然不现实。
现实生活中,有一种成熟的平台每天支持数亿用户的高频交互,那就是社交媒体。

琳琅满目的社交媒体 APP [5]
社交媒体已经深刻改变了我们的生活、工作和学习方式,同时也彻底革新了人们的沟通与协作模式。它不仅能够支持超大规模用户的高效交互,还可以灵活扩展到各种应用场景。
因此,社交媒体为构建一个支持大规模智能体交互的通用平台提供了理想的基础。
正是基于这一认识,OASIS 团队从社交媒体的视角出发,设计并搭建了这一平台,旨在充分利用社交媒体的优势,探索和实现智能体的大规模交互与协作。
OASIS 框架

OASIS 框架的主要特点有:
可扩展性
OASIS 基于社交媒体的基本组件进行设计,因此可以适配不同形式的社交媒体平台,例如 X(原 Twitter)、Reddit 等,用户能够轻松搭建符合自身需求的社交媒体环境。进一步来说,OASIS 模块性的设计使得研究人员可以轻松的将其拓展到其他场景中,例如城市模拟、AI Scientist Society 等等,这种灵活性使其适用于多种研究和应用场景。
支持大规模交互
OASIS 在计算资源上的优化表现尤为突出。例如,利用 24 块 A100 GPU,可以在一周内完成百万级智能体的模拟;而对于上万规模的智能体交互,仅需 1 块 A100 GPU 即可完成。这种高效性能大幅降低了大规模智能体研究的门槛。
复杂性和真实性
OASIS 支持 21 种不同的交互动作,包括发帖、转发、点赞、关注、搜索等,全面模拟社交媒体用户的行为。此外,OASIS 还集成了推荐系统、动态环境等高级功能,为研究复杂的社会行为提供了一个高度仿真的环境,满足用户多样化的研究需求。
OASIS 整体结构

OASIS 由以下五大核心组成部分:
1. Environment Server(环境服务)
环境模块是整个社交媒体环境的核心数据库,负责存储用户、帖子、关注关系等动态信息。这些数据支持实时更新,模拟真实社交媒体交互的动态性和复杂性。
2. Information Channel(信息通道)
Information Channel(信息通道)将根据当前环境的定义来选择如何传递智能体之间的交互信息。如在社交媒体中,信息通道会根据社交网络和推荐系统从 Environment Server 获取用户信息、帖子内容和关注关系等数据,并参考 Twitter 的开源技术方案搭建了类似 X 平台 的算法。该系统可以根据用户的关注和兴趣进行精准的信息推送。
同时,信息通道是模块化的,即插即用,支持轻松切换到其他平台(如 Reddit)的推荐机制,以及其他领域的信息交换机制(如 AI 审稿和 Arxiv 机制)。
3. Action Module
推荐系统会将精选的帖子推送给智能体。智能体根据帖子信息采取不同的动作(action)。OASIS 支持多种开源或闭源的大语言模型(LLM),并赋予智能体丰富的交互能力,从而与环境进行高度仿真的互动。
4. Time Engine
为了模拟社交媒体中的时间概念,OASIS 设计了时序概率激活模块,通过采集用户发布内容的频率,模拟用户在不同时间点的行为,提升系统的仿真性。
5. Scalable Inferencer
为支持大规模智能体的高效模拟,OASIS 采用多线程调度、负载均衡等技术,在模拟过程中同时运行上百个线程以处理推理任务。该设计显著提升了推理效率,满足上万甚至百万级智能体交互的需求。
OASIS 的工作流
1. 用户生成
该团队通过数据采集与生成的方式获取大规模用户信息,并将这些信息注册到 Environment Server(环境服务器)中,构建社交媒体环境的基本框架。
2. 信息通道
Environment Server(环境服务器)将用户、帖子和关系数据传递给 Information Channel(信息通道)。
信息通道会根据当前场景中特定的环境规则,决定信息如何推送给其他智能体。例如,在社交媒体中,信息通道会根据社交网络和推荐算法将个性化内容推送给不同的智能体。
3. 智能体交互
智能体基于推荐内容与环境进行交互,其行为(action)会动态更新到 Environment Server(环境服务器)中,从而形成闭环模拟真实社交媒体的动态演化过程。
社会模拟实验
研究团队利用 OASIS 框架在 X 平台和 Reddit 平台上开展了多个经典的社会现象实验,包括消息传播、群体极化、流言传播以及羊群效应。
1. 消息传播实验
消息传播实验旨在通过 OASIS 尽可能模拟真实世界的场景,观察其是否能够较好地复现消息传播的趋势。
研究团队选用了开源的 Twitter15 和 Twitter16 数据集,并通过 Twitter API 收集了数据集中用户的相关信息(如个人简介、历史推文等)。
在实验中,他们重现了 200 条源推文的传播路径,并将模拟结果与真实数据进行了对比分析,以评估模型的复现能力。

研究团队从三个维度分析了模拟结果与真实结果之间的差距:传播规模(Scale,指影响到的用户数量)、传播深度(Depth,指信息传播的层级渗透程度)以及传播最大广度(Max Breadth,指传播路径的最大分支数)。
结果显示,在传播规模和广度方面,模拟结果与真实结果较为接近。然而,在传播深度上,模拟结果与真实情况存在一定差距。
这种差距是可以理解的,因为 Twitter 在用户建模方面更为精细,能够更准确地捕捉用户的兴趣偏好和行为特征,从而更有效地反映传播深度的实际情况。
2. 群体极化实验
研究团队还利用 OASIS 模拟了一个经典的社会心理学实验 —— 群体观点极化实验(Group Polarization),并将实验场景迁移至 Twitter 平台进行。群体极化现象指用户的观点在交互过程中逐渐变得更加极端化。
在实验中,该团队向 196 名用户发布了一条争议性的帖子。帖子的内容是:「一个已经取得一定成功的作家,是否应该冒着收入中断的风险撰写一部宏伟巨著以增加成名概率,还是维持现状,享受稳定的收入。」
通过这种情景模拟,研究团队在多轮交互中对用户的观点进行问卷调查,以记录其态度的变化趋势。结果如图所示。

从实验结果可以看出,随着交互的不断进行,用户的观点逐渐趋于极端,并给出愈发偏激的回答。
该团队进一步测试了未设安全护栏的 Uncensored 模型与经过对齐处理的 Aligned 模型,结果显示,Uncensored 模型的极端化趋势显著更加明显。这表明,去除安全约束后,模型在交互中的观点极端化程度会进一步加剧。
3. 羊群效应实验
该团队利用 OASIS 的 Agent Society 模块复现了一项发表于 Science 的研究 [6],探讨了羊群效应(Herding Effect)的现象。
羊群效应是指个体倾向于追随群体的行为或观点,例如用户更倾向于点赞那些已有大量点赞的帖子。
实验在模拟的 Reddit 平台中进行,该平台仅显示帖子的最终得分(点赞数减去点踩数)。帖子被分为三组进行对比实验:
- 点赞组:帖子初始设置为有一个「赞」。
- 对照组:帖子初始得分为零(无「赞」或「踩」)。
- 点踩组:帖子初始设置为有一个「踩」。
通过观察智能体在交互后各组帖子的最终得分变化,可以评估初始得分对用户行为的影响。实验结果(如下图所示)表明,初始「赞」显著提高了帖子最终得分,而初始 「踩」则对得分造成了抑制效果。这表明,用户在决策时受到群体行为的显著影响,进一步验证了羊群效应的存在。

实验结果显示,agent 表现出比人类更强的羊群效应。当一条初始评论收到「反对」 时,agent 更倾向于继续跟随他人行为,进一步点「踩」 或减少点「赞」。
4. 流言传播实验
研究团队构建了一个包含 100 万用户的 Twitter 社交环境,其中包括 196 个核心用户(拥有大量粉丝的大 V),其余用户为普通用户。
在实验中,论文作者们让分析能力最强的核心用户发布了 8 条消息,这些消息包括 4 对真假消息对,分别涉及科技、娱乐、教育和健康等领域。
实验模拟了 96 分钟的交互过程,每 3 分钟为一个时间步。在此期间,该团队统计了真假消息相关帖子的数量变化,以分析真假消息的传播和影响力差异。

实验结果显示,流言(假消息)的影响力显著强于真消息。这一现象表明,在 OASIS 构建的代理社会中,假消息的传播规律与人类社会中类似 [7],表现出对假消息的强倾向性。
团队对新增的关注关系进行了可视化,其中绿色的点表示用户,红色的线表示新增的关注关系。从可视化结果可以观察到,用户之间的新增关注关系呈现出明显的聚集效应。
这种现象与谢林隔离模型(Schelling Segregation Model)[8] 中的群体聚集模式有一定相似之处。

具体来说,用户更倾向于关注与自己已有社交网络更接近的用户,导致新增的关系逐步形成小型的网络团体。
5. 不同量级的实验
研究团队还模拟了不同群体规模对实验结果的影响,并从中得出了一些发现。例如,随着群体规模的扩大,Agent 的观点更有建设性,群体行为的趋势也更加显著。具体内容请参见论文。

用户规模越大,用户的观点更加有建设性。

用户的规模越大,群体行为的趋势就更明显。
社区反馈
OASIS 发布后,引发了许多人对 Agent 社会的畅想,一些大 V 也纷纷分享了自己的观点。

例如,假如 AI Agent 社会与人类社会融为一体,我们该如何区分 Agent 和人类?这是一个非常值得深入研究的问题。

一些网友想要把 OASIS 框架融入到 APP 世界中,让 agent 操纵自己的账户以及各种各样的日常 APP。

也有的网友对于能进行 100 万量级智能体交互感到非常有趣和惊讶。
总结
OASIS 是我们迈向「智能体社会」过程中的一个节点。研究团队希望 OASIS 成为人工智能、社会科学等多个学科领域的有力工具。他们将在这个起点上继续推出更多工作,欢迎感兴趣的朋友们 Star,或直接建联,共同探索 AI 未来的无限可能!
#美芯片新禁令下周出台
100+公司或列入实体清单
拜登政府下台之前,还要公布一项限制芯片出口的新举措。据称,新规重点放在了对特定中国实体,以及100多家芯片制造设备研发公司的出口限制。另外,还会新增一些高带宽内存(HBM)条款。
针对芯片限制,美国又将出台新规?
彭博最新报道,即将卸任的拜登政府正准备进一步限制向中国出售半导体设备,以及AI存储芯片。
据称,这些新举措不会像最初预期的那样严厉,预计最早在下周公布。
芯片限制,提案再更改
在正式公布之前,一切都不是最终决定。
美国官员之前的多次提案,包括最终出台政策时间,已经发生了多轮变化。在此期间,他们经过数月审议,和日本、荷兰等盟友进行谈判。
对此,美国芯片设备制造商反对声不断,警告称愈加严厉的措施,只会给自己的业务带来灾难性的损害。
据知情人士透露,最新提案与先前草案又有着关键的区别。
首要问题是,把哪些中国企业列入实体清单。
新规将重点限制对特定中国实体的出口,而不是广泛类别的芯片制造商。
其中,主要被针对的是两家晶圆厂,而供应商则从最初的12家缩减到了个位数。
此外,新限制措施将包括一些关于高带宽内存(HBM)的条款。这些芯片用于处理数据存储,是人工智能的关键组件。
据知情人士透露,三星电子、SK海力士,以及美国存储芯片制造商美光科技预计将受到新措施的影响。
但中国DRAM制造商之一,一家具备生产HBM2的企业,将不会受到直接影响。
名单中,还将包括100多家从事新兴半导体制造设备研发的中国公司。
这也是新措施的主要目的,最终遏制中国本体芯片制造设备上商的技术发展,限制推动中国AI领域发展芯片制造工具的供应。
受此影响,亚洲和欧洲的芯片股大幅上涨。
ASML的股价最高上涨5.5%,领涨包括BESI和爱思强在内的芯片设备公司。
在日本,东京电子的股价直接飙升7%,SCREEN控股上涨6%,而国际电气更是大涨近13%。
或遭日本荷兰反对
最新计划对美国芯片设备制造商来说是某种程度上的胜利——包括泛林集团、应用材料、科磊公司。
数月来,这些制造商一直反对美国单方面对中国的出口限制,包括中国公司的六家供应商的制裁。
他们担心的是,来自东京电子、阿斯麦等竞争对手可能会填补了市场的空白,让自身在全球市场处于不利地位。
2022年,日本和荷兰曾推出了一些与美国措施相匹配的举措,但两国最近都抵制了美国进一步加强管控的要求。
今年夏天,美国官员尝试了一种强硬的谈判策略,警告盟友美国可能直接限制外国公司对中国的出口,却被日本和荷兰视为极端的越界行为。
为此,美国采取强硬手段,希望通过所谓的外国直接产品规则(FDPR),施压盟友采取限制措施。
尤其是考虑到川普未来重返白宫,日本和荷兰对即将下台的政府的新措更是表现冷淡。
据知情人士透露,美国的新规虽然也限制了一些额外的工具类别,但仍将盟友(包括日本和荷兰)排除在FDPR条款之外。
目前尚不清楚日本或荷兰是否最终会对美国现在计划制裁的中国公司实施额外限制。
全球强国陷入计算机芯片之争
芯片是数字经济的核心动力,其不断提升的计算能力正在推动生成式AI等技术的发展。
在这种背景下,这些半导体器件理所当然地成为了世界经济超级大国之间激烈竞争的焦点。
目前,美国政府已经出台了一系列限制措施来抑制中国半导体的发展,从而确保该国在这一关键领域保持领先地位。
为什么芯片如此重要?
芯片是处理和理解数据的必需品,而这些数据已经与石油一样成为经济的命脉。
内存芯片(Memory chips)用于存储数据,结构相对简单,在市场上像大宗商品一样交易。
逻辑芯片(Logic chips)负责程序的运行。作为设备的「大脑」,它的结构更加复杂,价格也更高。
像英伟达H100这样的AI加速器,已经与国家安全和科技巨头的发展紧密相连。比如,谷歌和微软就在竞相建设大型数据中心,争夺在未来计算领域的领先地位。
谁主导着芯片供应链?
芯片制造已经发展成为一个门槛越来越高且高度集中的行业。
新建晶圆厂投资额超过200亿美元,建设周期长达数年,而且必须24小时不间断满负荷运转才能实现盈利。
这种规模要求导致掌握尖端制造技术的公司仅剩三家——台积电、三星和英特尔。
其中,台积电和三星作为晶圆代工企业,为全球客户提供芯片制造服务;英特尔过去主要为自己生产芯片,但现在也开始在代工业务领域展开竞争。
在下游,还存在着一个规模庞大的模拟芯片产业。
德州仪器和意法半导体等公司是这类芯片的主要制造商,这些芯片主要用于智能手机的电源管理、温度控制以及声音信号转换等功能。
芯片竞争的态势如何?
2023年,美国对最尖端的芯片和芯片制造设备出台了严厉的管制措施,限制中国发展诸如超算、AI这类的技术。
此外,美国还向合作伙伴施压,要求限制中国获取浸没式深紫外光刻(DUV)等相对成熟的芯片制造技术,同时限制自身不要从中国进口半导体产品。
但美国政府认为,仅对中国的发展进行遏制是远远不够的。
于是,又在2022年通过了《芯片与科学法案》(CHIPS and Science Act),专门划拨390亿美元用于直接补贴,并提供750亿美元的贷款及贷款担保,以重振美国本土芯片制造业。
各国的战略布局如何?
欧盟制定了总额463亿美元的计划,用于扩大本地芯片制造能力。
欧盟委员会估计,该行业的公共和私人投资总额将超过1080亿美元。目标是到2030年将欧盟的芯片产量翻一番,占全球市场的20%。
日本经济产业省已经为2021年启动的半导体振兴计划筹集了约253亿美元资金。
具体项目包括台积电在熊本县的两座晶圆厂,以及在北海道的另一座晶圆厂。在北海道工厂,Rapidus株式会社计划于2027年实现2nm先进逻辑芯片的量产。
印度则在2月批准了总值152亿美元的半导体制造厂投资计划,其中包括由塔塔集团负责的印度首座大型芯片制造工厂的提案。
沙特阿拉伯的公共投资基金,也正考虑进行一笔「大规模投资」(具体金额未披露)来启动该国的半导体产业发展计划。
参考资料:
#Predicting Emergent Capabilities by Finetuning
GPT-5涌现能力可预测?UC伯克利仅使用当前模型检查点预测未来模型
LLM 规模扩展的一个根本性挑战是缺乏对涌现能力的理解。特别是,语言模型预训练损失是高度可预测的。然而,下游能力的可预测性要差得多,有时甚至会出现涌现跳跃(emergent jump),这使得预测未来模型的能力变得具有挑战性。
最近,来自加州大学伯克利分校(UC 伯克利)的研究团队提出涌现预测的任务:是否可以仅通过使用 GPT-N 模型的检查点(即当前模型的状态)来预测 GPT-N+1(未来模型)是否会出现涌现能力? 并在论文《Predicting Emergent Capabilities by Finetuning》中给出了答案。
论文标题:Predicting Emergent Capabilities by Finetuning
论文地址:https://arxiv.org/pdf/2411.16035
值得注意的是,这篇论文的作者包括强化学习大牛 Sergey Levine。
该研究拟合了一个参数函数 —— 涌现定律,模拟了涌现点如何随数据量的变化而变化。
为了进行验证,该研究使用四个标准 NLP 基准 ——MMLU、GSM8K、CommonsenseQA 和 CoLA。通过仅使用小规模 LLM 来拟合涌现定律,该研究能够准确预测涌现点。
最后,该研究提出了两个实际的涌现案例研究,表明该研究提出的涌现定律可用于预测更复杂的能力。
思维链提出者 Jason Wei 称赞:「这是一篇非常聪明的论文,可以预测预训练模型的下游性能,非常有价值。因为可以使用它来预测和证明对下一个大模型训练运行的资本投资的合理性。」

论文介绍
作者首先提出了涌现预测,并将涌现预测定义为仅使用涌现前的模型检查点,来识别发生涌现的扩展点的问题。
简单理解就是,对于给定的 LLM,其在特定任务上具有随机少样本准确率,我们能否预测这个 LLM 在哪个扩展点(例如,预训练损失)上性能将超越随机表现?
带着这一疑问,作者发现了这样一个见解:在给定的任务上微调 LLM, 可以将涌现发生的临界点向着能力较低的模型移动 ,这意味着,通过微调,模型在涌现能力出现的时间点可以提前,这对于理解模型扩展和能力跃升的过程非常重要。微调所使用的数据量,会调节这种临界点移动的幅度。
图 3(左)绘制了每个模型在 GSM8K 和 MMLU 上的少样本和微调性能与预训练损失的关系。可以看到,微调后的模型遵循与少样本设置类似的 ReLU 形状。此外,在相同的预训练损失下,所有模型大小的转变都是一致的,这表明预训练损失可以作为少样本和微调设置中有效的独立变量。
作者还发现出现涌现偏移受微调数据量的影响。图 3(右)绘制了 3B 模型检查点在完整数据子集上进行微调后的性能。在 MMLU 和 GSM8K 上,随着微调数据量的增加,涌现点进一步向能力较弱的 LLM 偏移。因此,微调数据量可以调节涌现偏移。

为了将这一洞察付诸实践,作者针对不同数量的数据对 LLM 进行了微调,并拟合了一个参数函数(即涌现定律),该函数模拟了涌现点如何随数据量的变化而变化。


然后,根据这一发现可以推断出在少样本设置中关于涌现的预测。

作者利用四个标准 NLP 基准来验证涌现定律,结果发现涌现定律可以提前准确预测涌现点,最多可提前 4 倍 FLOP。

接下来作者进行了这样一个实验,就预训练 FLOPS 而言,可以提前多久成功做出预测。结果发现,可以提前预测涌现的程度在某种程度上取决于任务。
在 MMLU 和 GSM8K 上,可以分别提前最多 4.3 倍和 3.9 倍的 FLOPS 涌现出现。然而,在 CommonsenseQA 和 CoLA 上,分别只能提前预测 1.9 倍和 2.3 倍。

最后,作者还进行了真实世界的案例研究:1)低成本评估预训练数据质量(左)。2)使用困难 APPS 编码基准预测更复杂的能力,更接近未来前沿模型的能力(右)。

感兴趣的读者可以阅读论文原文,了解更多研究内容。
#三名高中生,为近百年的分形定理带来了新证明
本周,量子杂志又介绍了另一个早早就在数学领域展露头角的三人高中生团队:Niko Voth(右上)、Joshua Broden(右下)和 Noah Nazareth(最左)。
在他们的导师、多伦多大学数学家 Malors Espinosa(以下简称 Malors) 的帮助下,他们证明了一条关于扭结和分形(knots and fractals)的新定理。

2021 年秋天,Malors 开始设计一个特殊的数学问题。与任何好的研究问题一样,这个数学问题必须发人深省,解决方案也要非同寻常。当时还是多伦多大学数学研究生的他希望高中生能够证明这个数学问题。
多年来,Malors 一直在为当地的高中生举办暑期讲习班,教他们数学研究的基本思想,并向他们展示如何写证明。不过,他的一些学生似乎准备做更多,他们想要找出在没有答案的情况下做数学意味着什么。因此,这些学生需要正确的问题来指导。
后来,Malors 在阅读一本关于混沌的教科书时终于找到了这样的问题。在书中,他发现了一个熟悉的物体:分形或自相似形状,学名为门格海绵(Menger sponge),它的结构简单但优雅。
首先将立方体分成类似魔方的形状,接下来移除正中央的立方体以及六个面的中心立方体,最后对剩下的 20 个立方体重复此过程。你很快就会明白为什么得到的分形被称为海绵:随着每次迭代,其孔隙会成倍增加。

选择门格海绵作为高中生数学「试炼场」
自从数学家 Karl Menger(卡尔・门格尔)在近一个世纪前提出分形海绵以来,它就一直吸引着专业和业余数学家发挥想象力,原因之一是它看起来很酷。
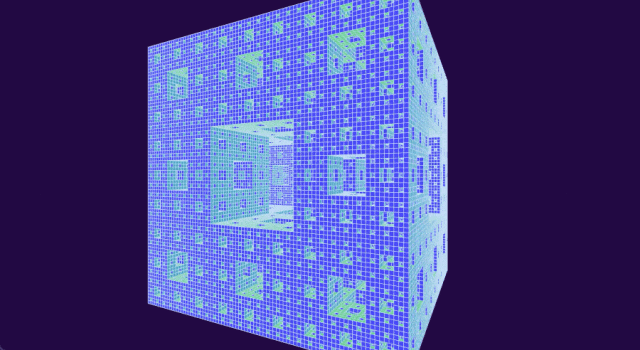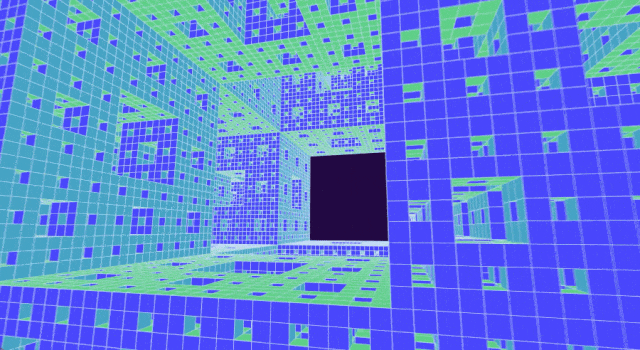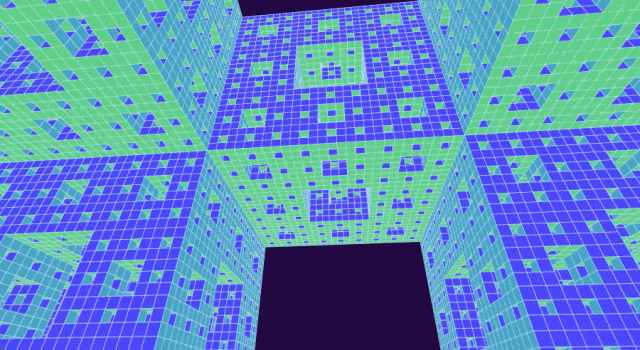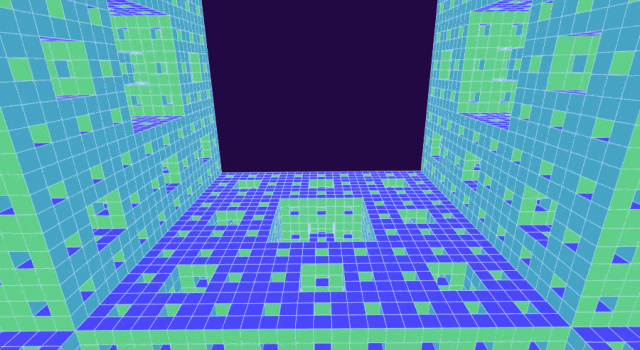
通过从起始立方体中移除越来越小的立方体,可以构造出门格海绵。
2014 年,数百名数学爱好者参加了一项名为「MegaMenger」的全球性活动,用名片制作了重达 200 磅的海绵。由于其多孔的泡沫状结构,海绵还被用来模拟减震器和奇特的时空体形式。
最重要的是,分形具有各种违反直觉的数学特性。例如继续拔出更小的碎片,最初的立方体就会变成完全不同的东西。经过无数次迭代后,体积会缩小到零,而其表面积会无限大。这就是分形的奇特之处:徘徊在维度之间,占据空间但又没有真正填满它。
1926 年,Menger 首次定义了海绵,还证明了任何可想象的曲线(包括简单的线条和圆圈、看起来像树或雪花的结构、分形粉尘)都可以变形,然后嵌入海绵的某个地方。它们可以沿着海绵缠绕的轮廓蜿蜒前行,而不会离开海绵表面,不会撞到洞,也不会相互交叉。Menger 写道,「这种海绵是一条通用曲线。」
但 Malors 后来意识到,这又引出了一个新问题。Menger 虽然已经证明,你可以在海绵中找到一个圆。但在某种意义上,与圆等价的物体又如何呢?
考虑数学上的一个扭结:一根绳子被扭成一团,然后两端闭合形成一个环。从外面看,它可能看起来像一团乱麻。但一只蚂蚁沿着它爬,最终会回到起点,就像在圆上一样。这样一来,每个扭结都等价于圆,或「同胚于」圆。

每个扭结都「同胚于」圆,这意味着可以将点从一个点映射到另一个点,同时满足一组简单的条件。
不过,Menger 的证明没有区分同胚曲线,他的证明仅保证可以在海绵中找到圆,而不是所有同胚扭结中都可以找到。因此,Malors 想证明可以在海绵中找到每个扭结。
这个问题似乎激发了年轻学生们的兴趣,他们最近在 Malors 的研讨会上学习了扭结,玩得很开心。谁不喜欢分形呢?问题在于是否可以完成自己的证明。「我真的希望有一个答案,」Malors 表示。
最终,在与 Malors 每周进行 Zoom 会议几个月后,他的三名高中学生,即 Niko Voth、Joshua Broden 和 Noah Nazareth,证明了所有扭结确实都可以在门格海绵中找到。另外,他们还发现,另一种相关的分形也可能存在同样的情况。

- 论文标题:Knots inside Fractals
- 论文地址:https://arxiv.org/pdf/2409.03639
对此,北卡罗来纳州立大学拓扑学家 Radmila Sazdanovic 表示,这是一种巧妙的把事物组合在一起的方法。在重新审视 Menger 百年历史的定理时,Malors 显然提出了一个以前没人想过要问的问题,这是一个非常新颖的想法。而且,他的三名学生完成了证明。
从另一个角度思考扭结
多年来,Broden、Nazareth 和 Voth 参加了 Malors 的几次夏季研讨会。在早期的研讨会上,当 Malors 第一次教他们扭结时,14 岁的 Voth 被深深震撼了。
然而,他们遇到了一些极其复杂的 Menger 问题,这与他们以前的作业不同,没有现成的答案可以参考。
Nazareth 表示这个问题让他感到紧张,因为这是他第一次做没人知道答案的事情,连 Malors 也不知道。「也许根本就没有答案。」
他们的目标就像是要将一根显微针穿过一团尘土,这团尘土是海绵在多次移除材料后的残余物。这项任务极度复杂,他们需要把针插到正确的地方,打结的过程必须极为精准,不能出错,也不能偏离原本的结构。任何一个扭结如果线漂浮在海绵的空洞里,就意味着失败。
这不是一件容易的事。但有一种方法可以简化它。扭结可以在一张平整的纸上以称为弧表示(arc presentation)的特殊图表来描绘。要创建一个扭结,首先要了解扭结的线如何在彼此前面或后面穿过。然后应用一组规则将这些信息转换为网格上的一系列点。网格的每一行和每一列都将包含两个点。

用水平线和垂直线连接这些点。当两条线段相交时,将垂直线段画在水平线段前面。

每个结都可以用这种网格状的方式表示。当学生们考虑交叉线段的图形时,他们想到了门格海绵的表面。将弧表示的水平线放置在海绵的一面,将垂直线放置在相反的一面,这就足够简单了。
难点在于如何连接这个扭结 —— 如何将其拉伸回三维空间。
数学家们转向了所谓的康托尔集,构造这个集的步骤是:从一个线段开始,将其分成三等份,去掉中间的三分之一,然后对剩下的两个部分重复相同的操作,依此类推,直到无限进行下去。最终,你将只剩下一些散落的点。

康托尔集和门格海绵的结构有相似之处,都是通过去除中间部分或某些区域逐渐构建出来的。他们意识到,当海绵的面上的点的坐标都在康托尔集中的时候,这些点的位置上不应该有空洞。更重要的是,由于海绵具有重复的设计结构,这些点背后的位置也不应该有空洞。因此,扭结可以在海绵的结构中自由地穿过,而不会不小心脱离海绵的物质。
那么,剩下的就是让学生证明他们总是可以压缩或拉伸给定扭结的弧表示,以便其所有角都与康托尔集合中的坐标对齐。
为了完成最后一步,Broden、Nazareth 和 Voth 采取了一个捷径。他们证明了可以变形任何弧线表示法,使得其垂直和水平线段交叉的点都位于康托尔集中。他们可以始终将一个给定的扭结嵌入门格海绵的某一迭代中。

现在他们已经解答了 Malors 原本的问题,他们还想更进一步。他们已经开始研究是否所有扭结都可以嵌入到四面体版本的门格海绵中:

Broden 说:「这让人非常恼火。」如果没有将这些面直接对齐,他们将扭结穿过该分形的方法就不再有效。
扭结度量
Malors 表示,正是在这个阶段,学生们了解到了数学研究的痛苦 —— 数学的很大一部分工作内容都是寻找有希望的前进之路,然后遭遇失败。「我们面对的是数学,而数学并不怜悯任何人。」他说 ,「不过对于高中生来说,通常还不会受到这种伤害。」
Malors 之前以为不可能在四面体中找到所谓的三叶结。在一次视频通话中,这三名学生反驳了这一观点。他们回忆说,离开会议时感到沮丧和失望。但他们决定坚持自己的直觉。
几周后,令 Malors 惊讶的是,他们带着一个结果回来了:他们找到了一种新方法,可将三叶结的弧表示映射到四面体上。之后他们证明,所有「扭结面包(pretzel)」形式的扭结都能做到这一点(三叶结也属于此类别),但对于其他类型的扭结而言,这个问题仍未得到解决。

各种扭结面包,图源:维基百科
Malors 推测,这些学生的方法也许能提供更广泛适用的测量分形复杂性的方法。并非所有分形都允许各种扭结。也许可以根据它们可以容纳和不能容纳的扭结类型来更好地理解它们的结构。
至少,这项研究能启发新的艺术成果,类似于 2014 年的 MegaMenger 竞赛。弗吉尼亚联邦大学的扭结 结理论科学家 Allison Moore 说:「看到它被用物理材料建造出来真是太好了。」
与此同时,Joshua Broden、Noah Nazareth 和 Niko Voth 全都已经高中毕业。仅有 Joshua Broden 决定继续研究四面体问题(当他不忙于大学课程时),但他们三个人都在考虑从事数学研究工作。
Nazareth 说:「如果能为比自己更伟大的事情、为真理做出贡献,会感觉很有意义。」而这一切的起点是问出那个正确的问题。
原文链接:https://www.quantamagazine.org/teen-mathematicians-tie-knots-through-a-mind-blowing-fractal-20241126/
#通义千问QwQ奥数真厉害
QwQ 具有神奇的推理能力。
一个刚发布两天的开源模型,正在 AI 数学奥林匹克竞赛 AIMO 上创造新纪录。
本周五,知名数学家、加州大学洛杉矶分校教授、菲尔茨奖得主陶哲轩(Terence Tao)介绍了第二届 AIMO 竞赛的最新进展。比赛在数据竞赛平台 Kaggle 上已经持续了一个月,现在有队伍快要触发「Early Sharing Prize」的门槛了。

Early Sharing Prize 是为了鼓励 AIMO 参赛者在比赛早期分享高分模型经验设立的奖项,需要选手在竞赛中第一个获得 20/50 分,且公开自己的 notebook,奖金为额外的两万美元。
据陶哲轩介绍,就在不到一天前有参赛团队使用 QwQ-32B 的特定实例已经拿到了 18/20 的成绩,该模型似乎比之前的开源模型在解决数学竞赛问题方面表现得更好。
今年 7 月,陶哲轩在国际数学奥赛 IMO 上给第一届 AIMO 的获奖团队进行了颁奖,分享了自己对 AI 在数学研究中应用范式的思考,也打响了 AIMO 竞赛的名声。
AI 数学奥林匹克竞赛 AIMO 的初衷是让参与者使用 AI 模型解决国际数学难题,这将有助于推动人工智能模型的数学推理能力,并促进前沿知识的发展。
由于大模型技术的快速进步,人们对 AI 解决数学问题的能力寄予厚望,第一届 AIMO 的获奖队伍分获了 104.8 万美元的奖金,而现在第二届,奖池已经上升到了 211.7 万美元。
AIMO 竞赛要求参赛团队公开发布其代码、方法、数据和模型参数。刚刚结束的第一届比赛里大家使用的模型各不相同,包括 Mixtral 8x7b、Gemma、Llama 3 等等,有的来自大厂,有的来自 AI 创业公司,呈现百花齐放的态势。
而到了这一届,现在似乎已经变成了 Qwen 系列在刷屏,其他模型偶尔出现:

刚刚发布的 QwQ,还在把开源大模型推向新的高度。
QwQ 的能力也并不仅限于奥数这一个方面,最近社交网络上也有不少人在夸它的推理能力。

HuggingFace 的产品设计人员也表示:测试了一下 QwQ,结果令人惊叹:

有人说,QwQ 就是一个在冉冉升起的新神,虽然有时仍会出错,但令人着迷的就是它的推理路径,就像给 o1 再来一个巨大的加号。
更有趣的是,有人发现这个模型用于思考的原生语言似乎是中文:

难不成这就是 QwQ 逻辑能力强大的原因之一?无论如何,开源大模型领域的风向,似乎已经变了。
11 月 28 日,阿里云通义团队发布了全新 AI 推理模型 QwQ-32B-Preview,并同步开源。评测数据显示,预览版本的 QwQ 已展现出研究生水平的科学推理能力,在数学和编程方面表现尤为出色,整体推理水平比肩 OpenAI 的 o1。
- HuggingFace 开源地址:https://huggingface.co/Qwen/QwQ-32B-Preview
- HuggingFace Space 体验:https://huggingface.co/spaces/Qwen/QwQ-32B-preview
据介绍,QwQ(Qwen with Questions)是通义千问 Qwen 大模型最新推出的实验性研究模型,也是阿里云首个开源的 AI 推理模型。阿里云通义千问团队研究发现,当模型有足够的时间思考、质疑和反思时,其对数学和编程的理解就会深化。基于此,QwQ 取得了解决复杂问题的突破性进展。

在考察科学问题解决能力的 GPQA 评测集上,QwQ 获得了 65.2% 的准确率,具备研究生水平的科学推理能力;在涵盖综合数学主题的 AIME 评测中,QwQ 以 50% 的胜率证明其拥有解决数学问题的丰富技能;在全面考察数学解题能力的 MATH-500 评测中,QwQ 斩获 90.6% 的高分,一举超越了 o1-preview 和 o1-mini;在评估高难度代码生成的 LiveCodeBench 评测中,QwQ 答对一半的题,在编程竞赛题场景中也有出色表现。
另外当面对复杂问题时,QwQ 展现了深度自省的能力,会质疑自身假设,进行深思熟虑的自我对话,并仔细审视其推理过程的每一步。
比如,在经典智力题「猜牌问题」中,QwQ 会通过梳理各方对话并推演现实情况,它像个擅长思考的人一样,能揣摩「这句话有点 tricky」,反思「等一下,也许我需要更仔细地思考」,最终分析得出正确答案,这似乎是以前没有 AI 能做到的事情。
面对目前高涨的热度,通义团队表示,尽管 QwQ 展现了强大的分析能力,但该模型仍是个供研究的实验型模型,存在不同语言的混合使用、偶有不恰当偏见、对专业领域问题不了解等局限。随着研究深入模型迭代,这些问题将逐步得到解决。
参考内容:
https://mathstodon.xyz/@tao/113568284621180843
https://www.kaggle.com/competitions/ai-mathematical-olympiad-progress-prize-2/leaderboard
#大模型基础面试知识
- 注意力的计算公式
MHA GQA MQA MLA
- 几种位置编码,几种norm,几种ffn
正弦位置编码,可学习位置编码,ROPE(旋转位置编码),都用在过qkv的linear之后,qk矩阵计算之前。
LayerNorm(PreNorm/PostNorm)、GroupNorm、RMSNorm(提升运行效率)
RMSNorm计算公式:

class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps) ###RMS Norm公式"rsqrt" 是 "reciprocal square root" 的缩写,意为 "倒数平方根"。
def forward(self, x):
if rms_norm is not None and x.is_cuda:
return rms_norm(x, self.weight, self.eps)
else:
output = self._norm(x.float()).type_as(x)
return output * self.weight- 为什么自回归是最主流的预训练方法,除此之外还有什么其他的预训练方法
和下游任务最接近,zero shot能力好,记忆能力强,低秩。最主要就是Openai跑通了,它没成功之前,就是Bert的天下,哈哈哈哈,OPT175B复现不出来GPT3,否则GPT范式会更早。
GLM(输入部分bert mask,输出部分gpt mask)、T5(encoder-decoder)
Bert填空,GLM、T5半填空半自回归
- 常见的微调方法,以及常见的下游任务
SFT:CFT(GPT4和GPT3对比学习)、CUT、ORPO(SFT加DPO loss)
RLHF:DPO(离线强化学习算法)、PPO(在线强化学习算法)、RLAIF
- Attention结构的几种变体
MHA GQA MQA (超长文本RingAttention Ulysses)flash attention
GQA:【全网首发】聊聊并写写GQA(Group Query Attention)
RingAttention :朱小霖:ring attention + flash attention:超长上下文之路
- flash attention的大致原理
(利用GPU SRAM比DRAM(GDDR/HBM)快,融合多个算子,省去softmax前用于反向梯度求导的激活值)
- 提升长文本性能的几种可行做法
ROPE、ROPE ntk外推、KV量化、(序列并行:超长文本RingAttention Ulysses)、增大预训练预料长度
- 如何在预训练阶段提升模型的性能
清洗高质量数据,丰富多样,去重复,无害化,低噪音,代码结构和数学结构更加合理。
用bert或小模型洗,尤其是互联网数据。
其余数据:github、百科、专利、arvix
数据格式:markdown->json
- 知识蒸馏
- 量化 AWQ(激活感知权重量化)[1] GPTQ(GPT量化方法)[2] GGUF(llama.cpp)[3]
4bit、8bit、16bit量化,一般都说W4A16,即参数为4bbit,激活值为16bit。推荐W8A8。临时常用bitsandbytes库,动态量化。
量化可以用open triton或者FasterTransformer重写算子作为支撑。
[1]https://qwen.readthedocs.io/en/latest/quantization/awq.html
[2]https://qwen.readthedocs.io/en/latest/quantization/gptq.html#
[3]https://qwen.readthedocs.io/en/latest/quantization/gguf.html
- 混合精度训练
fp16、bf16
amp(nvidia),torch amp(autocast),deepspeed(强制全部参数fp16)
混合精度训练节省的显存仅来源于激活值,而非参数值、梯度、优化器。
计算方法:fp32:4(参数)+4(梯度)+8(优化器)=16
fp16:2(参数)+2(梯度)+4(参数的fp32备份)+8(优化器)=16
- 分布式训练dp,mp,ddp,pp;zero的三个stage
dp、ddp:数据并行,dp几乎没人用了,DDP是分布式训练入门,可以用accelerate封装。多卡all_gather、all_reduce要会(这玩意好像叫通信原语,底层是nccl(GPU)或者Gloo(win))。
mp:模型并行,就是把模型劈成几份,要么按layer切分到不同卡上,要么叫tensor并行,就是把权重切分(Megatron威震天)。第一种慢的要死,不如pp。第二种必须有nvlink,要么PCIE满得要死,而且切分权重要改代码,得学,但大厂都这么搞。
pp:流水线并行,模型拆到几张卡,然后用小的batch弥合卡的计算中的“气泡”.参考刘聪NLP中的Qwen的deepspeed实现,或者参考良慕路程序员的torch实现,需要重新封装模型。
sp:序列并行,长文本,长视频专用。1M的token,1个多小时视频一张卡不够了,就切分到不同卡上,ringattention。Opensora就是这个东西。
zero1:切分优化器,优化器显存占用/并行卡数
zero2:优化器基础上切分梯度,梯度显存占用/卡数
zero3:zero2基础上把参数也切分了。
经典理解下,chatglm1为什么是6B?应该是有8卡a100 80g几台,做zero1或者zero2切分,正好加上激活值差不多就是80G。用点bert时代祖传数据集,再sft调下,就是chatglm1。试错成本低,迭代效率高。
- 多模态clip、blip2、minigpt4、llava、CogVLM
clip是图文对比预训练
blip2用clip做视觉backbone,中间加bert做对齐训练(Qformer)。再用一个MLP/linear接到LLM上,只更新MLP/linear浅层对齐。
minigpt4:换更好LLM
llava,clip输出的embedding过linear直接拼接到LLM的输入embedding中,两阶段训练,图文预训练和图文指令训练,均只训练浅对齐linear。可以只用指令数据集,不用预训练,前提指令数据集要够。
CogVLM:换更大的clip和LLM,LLM增加视觉专家部分(LLM部分copy然后微调)
- 多模态的实现方式(双流、单流、浅对齐)
看李沐视频去,CoCa、flamingo什么的,现在更多都是VLLM了,BLIP2那种浅对齐,CLIP和LLM分别快速发展,哪天要用了,浅对齐下。LLM模型越大越不好对齐,需要更多数据。更多参考Deepseek和Qwen的技术报告。
- Lora理解、QLora
每层都增加点可训练参数量,在主参数旁边增加个参数量很小,低秩的参数,(W+BA)x,A随机初始化,B输出0初始化。可以一定程度避免遗忘现象,但不能节省计算量。省显存主要省在优化器上,这对于LLM参数量大有明显影响,对视觉模型影响很小。一般LLM微调或者AIGC(diffusion)生成用。
原理:限制在一个较小的偏移空间中,请尽情发挥!
QLora:把参数量化了,这样进一步节省显存。
- Ptuning和全量微调的对比
Prompt Tuning:增加几个可学习的prompt token并调它们。省显存,不容易遗忘,不容易过拟和,效果没有全量微调好。
- 写出RLHF的目标公式

这个 loss 意思是希望 LLM 输出的回答的评分能尽可能高,同时不要偏离太多,保证它还能正常做回答,不要训成一个评分很高但是回答乱码的东西。
LLM语境中的RLHF:LLM生成token的过程是递归进行的。每次递归中,给定的上下文则是当前的状态,需要预测出的token则是行动,该token是从一个字典中选择的(编码的过程被称为tokenize),且该字典是有限的。这时,该问题被归类到离散动作空间的强化学习。
PPO(Proximal Policy Optimization)是强化学习中策略梯度法中的一个算法,可用于离散或连续动作空间(最初提出时被应用于连续动作空间)的强化学习问题。当策略函数是个神经网络,也就是可以用策略梯度法改进时,这样便可以应用 PPO 。此时,LLM本身便是 策略网络(在强化学习语境中,也被称为 actor,因为其产生行动 act)。李宇:从技术报告揭秘 InternLM2 尚未开源的部分——RLHF(二)奖励函数篇
- 目标公式中衰减因子的作用,取大取小有什么影响?
是我们在训练的 LLM,是训练的初始值。希望 LLM 输出的回答的评分能尽可能高,同时不要偏离太多,保证它还能正常做回答,不要训成一个评分很高但是回答乱码的东西。
取大了RLHF效果不明显,取小了容易偏离太多,遗忘知识。
- RLHF的目标公式中可以加入什么其他的项?

- RLHF中的PPO比率相对什么来算?
- 其中对数概率的作用?
缩放损失函数,对数相除等于对数相减
- Reward model的训练loss是什么?


- 文本数据处理到进入模型的整个过程?
经过byte2unicode转换,过tokenizer转换为数字,再查找embedding层转换为token,然后进入transfomer模型,模型输出的经过MLP head后softmax做分类,分类结果tokenizer转换为文字,文字再输入到下一个位置。
- 分词和向量化的过程
分词:分词是将文本拆分成单独的单词或符号(称为"tokens")的过程。这是NLP中的一个基本步骤,因为我们通常希望在单词级别上处理文本,而不是在字符级别上处理。分词的方法有很多种,包括空格分词、基于规则的分词、基于统计的分词等。例如,对于句子 "I love machine learning.",分词后的结果可能是 ["I", "love", "machine", "learning", "."]。
向量化:在分词后,我们需要将这些单词转化为机器可以理解和处理的形式。这就是向量化的过程。向量化的目标是将每个单词转化为一个向量,这个向量可以捕捉到该单词的语义信息。最简单的向量化方法是one-hot编码,但这种方法无法捕捉到单词之间的语义关系。因此,更常用的方法是使用词嵌入(word embeddings),如Word2Vec
大部分GPT都是BPE算法,部分T5、bert不用这个,用wordpiece。
一般10w左右词汇,10万分类问题。压缩率、速度和效果的权衡问题。
BPE库:sentencepiece
- 模型微调过程中的调参?
- Recall,Precision的计算?
准确率(accuracy)=(TP+TN)/(TP+FN+FP+TN)
通俗解释:在所有样本中,预测正确的概率
精确率(precision)=TP/(TP+FP)
通俗解释:你认为的正样本中,有多少是真的正确的概率
召回率(recall)=TP/(TP+FN)
通俗解释:正样本中有多少是被找了出来
- 训练的数量级?
RLHF reward model:240w条数据
预训练:2T token
- 如何把控数据质量?
参考InternLM2的洗数据的论文
- 对大模型整个发展趋势如何理解?
RAG(RAG还是bert抽取特征,计算余弦相似度,然后送给LLM整理输出)、长文本、Agent、群体对话、拒答,web搜索技术、文本整理、报表分析
- 你认为LLM的数据质量的关键在于什么?
多样、去重、无风险、涉及面广、正确、结构化
- DPO公式?

- sft指令格式?
{"instrct":{},"input":{}, "bot":{}}
- bert的下游任务?
文本分类(Text Classification):这可能是最常见的NLP任务之一,包括情感分析、主题分类等。BERT可以用于理解文本的上下文,从而进行准确的分类。
命名实体识别(Named Entity Recognition, NER):这是从文本中识别并分类命名实体(如人名、地名、公司名等)的任务。BERT可以帮助模型更好地理解实体在文本中的上下文。
问答系统(Question Answering):这是从给定的文本段落中回答问题的任务。BERT可以用于理解问题和文本的上下文,从而找到正确的答案。
语义相似性(Semantic Similarity):这是评估两段文本在语义上的相似性的任务。BERT可以用于理解文本的深层含义,从而准确地评估相似性。
摘要生成(Summarization):这是从长文本中生成短的摘要的任务。尽管BERT主要用于理解任务,但它也可以通过与其他模型(如Transformer)的结合来进行摘要生成。
文本生成(Text Generation):虽然BERT不是直接设计用于文本生成的,但通过某些技术,如Masked Language Model,BERT也可以用于生成文本。
关系抽取(Relation Extraction):这是从文本中识别和分类实体之间的关系的任务。BERT可以用于理解实体的上下文,从而准确地识别关系。
情感分析(Sentiment Analysis):这是识别和分类文本的情感倾向(如积极、消极或中立)的任务。BERT可以用于理解文本的上下文,从而准确地识别情感。
- bert的网络结构和训练方式?
mask形式
- DPO在什么情况下是等价于PPO的?
PPO有显式解转为DPO,等价情况:swtheking:百面LLM-14
- 介绍DIT
- 介绍Controlnet
两路分支模型。冻结原模型,复制一份unet下采样部分到右侧,右侧分支上采样部分为zero卷积。基于输入条件训练调整模型输出。
改进:https://vislearn.github.io/ControlNet-XS/只需基础模型 1% 的参数的新架构即可实现最先进的结果,并且在 FID 分数方面的性能明显优于 ControlNet。
原因,controlnet的右侧下采样直接复制,需要重新学习知识,改进增加了右侧下采样和左侧下采样信息的交互,参数量更小,解决了“延迟反馈”的问题。
- 介绍SAM
过vit的特征和点/框位置的编码embedding进行交互,输出层级的segment框。
- Adam优化器和SGD有什么区别
更新规则:SGD(随机梯度下降)是最简单的优化算法,每次迭代时,它仅仅使用当前批次的梯度信息来更新模型的权重 AdamW是一种自适应学习率的优化器,它不仅考虑了当前批次的梯度信息,还考虑了过去的梯度的平方的移动平均值。这使得AdamW在不同的参数维度上有不同的学习率,这对于稀疏数据和非凸优化问题非常有用。AdamW还包含了权重衰减(相当于L2正则化),这可以帮助防止模型过拟合。
收敛速度:通常,AdamW的收敛速度要比SGD快。这是因为AdamW使用了动量(考虑了过去的梯度)和自适应学习率,这可以帮助优化器更快地找到最优解。然而,有些研究表明,在某些任务中,尤其是深度学习任务,SGD在训练的后期阶段可能会达到更好的泛化性能。计算复杂性:由于AdamW使用了更复杂的更新规则,所以其计算复杂性要比SGD高。但是,由于其更快的收敛速度,实际的训练时间可能不会比SGD长很多。
- sqrt(d)是qkv谁的维度,作用是什么
不知道,d是嵌入维度。
为了防止点积的大小随着维度d的增大而变得过大,这可能会导致softmax函数在计算注意力权重时产生过小的梯度(也称为梯度消失问题)。
- classifier guidence和classifier-free guidence区别是什么,都怎么实现?
基于贝叶斯公式,classifier guidence是guided ddpm的工作,训练个分类器,用分类器引导普通无引导训练的ddpm。正常往score方向不断走就是干净图片,这里在score基础上加上个分类器引导的梯度,让score往这个类别的数据梯度上走。上是score sde,下面是DDIM。注意输入分类器和Unet的都是
classifer-free是把分类器融合进diffusion的Unet中,可以用clip没有类别限制,生成质量好。
训练方法是随机drop掉一些输入的文本,这样就对应为无监督生成。
classifier guidence - 搜索结果 - 知乎
guidence大小?7.5~10
- sft和(增量)预训练有什么区别
sft只计算回答部分的loss,而预训练计算问答loss。
- sft数据需要很多吗
不需要,1000条高质量就够,less is more for alignment。
- ROPE的了解?为什么ROPE能做长文本?ROPE ntk是什么?
- 手写diffusion公式,DDPM和VPSDE、EDM是什么关系?
- Consistency models的原理?
diffusion蒸馏,还有逐步蒸馏技术。训练loss是mse_loss(x+sigma(t_n)*eps,x+sigma(t_{n+1})*eps),其中加噪较小的为伪标签,不梯度反传
- 什么是GAN?GAN loss什么样?
对于判别器D,损失函数通常定义为:

这个损失函数的第一项鼓励判别器将来自真实数据分布的样本分类为真(即,尽可能让D(x)接近1),第二项鼓励判别器将来自生成器的样本分类为假(即,尽可能让D(G(z))接近0)。
对于生成器G,损失函数通常定义为:

这个损失函数鼓励生成器生成判别器更难以区分的样本,即尽可能让D(G(z))接近1。
- 介绍Sora,Sora的任意分辨率是怎么实现的?
Patch n’ Pack: NaViT, a Vision Transformer for any Aspect Ratio and...
- 为什么大语言模型经过DPO之后输出长度会变长?
因为被选的项目中,一般“虽然”,“但是”这些比较多。
A density estimation perspective on learning from pairwise human preferences中第四章
- 3D卷积,Video感知
- IP-Adapter
dual cross_attention,一个保留原能力,一个输入图片信息,图片信息学习LLAVA那种浅对齐。为什么用clip而不用SAM的backbone?因为更想提取语义风格信息,而非精细化的OCR信息。
- Sora是什么?有什么重要技术?
不懂哈,还没看
- moe是什么?
原石人类:MoE 入门介绍 核心工作回顾 模型篇
- BatchNorm三连:归一化了哪些维度,训练测试区别,部署时如何加速。
- megatron原理?
参考:Dylan:[实践] Tensor Parallel(精简版)
感觉面壁智能的OpenBMB train也不错,简洁干净
https://github.com/OpenBMB/BMTrain
如果知道百度这种大厂怎么实现的,欢迎赐教
- sd常用的t5模型都有什么版本?
Flan-T5
nghuyong:Flan-T5: One Model for ALL Tasks
手撕算法:最长回文子串。
#IC-Light
ICLR 惊现[10,10,10,10]满分论文,ControlNet 作者新作,Github 5.8k 颗星
四个 10 分!罕见的一幕出现了。
您正在收看的,不是中国梦之队的跳水比赛,而是 ICLR 2025 的评审现场。
虽说满分论文不是前无古人,后无来者,但放在平均分才 4.76 的 ICLR,怎么不算是相当炸裂的存在呢。

https://papercopilot.com/statistics/iclr-statistics/iclr-2025-statistics/
这篇征服了列位审稿人的论文,正是 ControlNet 作者张吕敏的新作 IC-Light。我们很少看到一篇论文,能够让四位审稿人给出高度一致的「Rating: 10: strong accept, should be highlighted at the conference」。
早在向 ICLR 投稿之前,IC-Light 就已经在 Github 上开源半年了,收获了 5.8k 的星标,足见其效果之优秀。

最初版本是基于 SD 1.5 和 SDXL 实现的,而就在前几天,团队又推出了 V2 版本,适配了 Flux,效果也更上一层楼。
感兴趣的朋友们,可以直接试玩。
- Github 项目:https://github.com/lllyasviel/IC-Light?tab=readme-ov-file
- V2 版本:https://github.com/lllyasviel/IC-Light/discussions/98
- 试玩链接:https://huggingface.co/spaces/lllyasviel/IC-Light
IC-Light 是一个基于扩散模型的照明编辑模型,可以通过文本精准控制图像的光照效果。

也就是说,要放在 PS 里打开蒙版、打开 alpha 通道,调试明暗分离才能搞定的光影效果,用上 IC-Light,就变成了「动动嘴皮子的事」。
输入 prompt,要让光从窗户里打进来,于是就能看到阳光透过雨后的窗户,在人物侧脸打出柔和的轮廓光。

IC-Light 不仅精准地还原了光线的方向,还精准地呈现了光透过玻璃的漫射效果。
对霓虹灯这样的人工光源,IC-Light 的效果同样出色。
根据提示词,原本在教室里的场景立马爆改赛博朋克风格:霓虹灯的红蓝双色打在人物身上,营造出深夜都市特有的科技感和未来感。

模型不仅准确还原了霓虹灯的色彩渗透效果,还保持了人物的一致性。
IC-Light 还支持上传背景图片,来改变原图的光照。

而说到 ControlNet,大家应该都不陌生,它可是解决了 AI 绘画界一个老大难问题。

Github 项目:https://github.com/lllyasviel/ControlNet
之前,Stable Diffusion 最让人头疼的就是无法精确控制图像细节。不管是构图、动作、面部特征还是空间关系,即便提示词已经做了很详细的规定,但 SD 生成的结果,依然要坚持 AI 独特的想法。
但 ControlNet 的出现就好像是给 SD 装上了「方向盘」,许多商业化的工作流也因此催生。
学术应用两开花,ControlNet 在 ICCV 2023 摘下了马尔奖(最佳论文奖)的桂冠。

虽然很多业内人士表示在卷得飞起的图片生成领域,真正的突破越来越难。但张吕敏似乎总能另辟蹊径,每次出手都能精准命中用户需求。这一次也不例外。
在现实世界中,光照和物体表面的材质是紧密关联的。比如你看到一个物体时,很难分清楚是光线还是材质,让物体呈现出是我们眼中样子。因此,在让 AI 编辑光线时,也很难做到不改变物体本身的材质。
以前的研究想通过构建特定的数据集来解决这个问题,但收效甚微。而 IC-Light 的作者发现用 AI 合成生成的数据加上一些人工处理,能达到不错的效果。这个发现对整个研究领域都有启发意义。
ICLR 2025 刚放榜之时,IC-Light 就凭借「10-10-8-8」稳坐最高分论文的宝座。
审稿人们在审稿意见里也不乏赞美之词:
「这是一篇精彩论文的典范!」
「我认为所提出的方法和由此产生的工具将立即对许多用户有用!」


在 rebuttal 结束,补了一些参考文献和实验之后。那两位给 8 分的审稿人也欣然改成了满分。

下面,就让我们一起来看看满分论文具体都写了什么。
研究细节

- 论文标题:Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport
- 论文链接:https://openreview.net/pdf?id=u1cQYxRI1H
在这篇论文中,研究者根据光传输独立性的物理原理,提出了在训练过程中强加一致光(IC-Light)传输的方法,其物理原理是:不同光照条件下物体外观的线性混合与混合光照下的外观一致。
如图 2 所示,研究者利用多种可用数据源对照明效果的分布进行建模:任意图像、3D 数据和灯光舞台图像。这些分布可以捕捉现实世界中各种复杂的照明场景,背光、边缘光、辉光等。为简单起见,此处将所有数据处理为通用格式。

但学习大规模、复杂和嘈杂的数据是一项挑战。如果没有合适的正则化和约束条件,模型很容易退化为与预期光照编辑不符的随机行为。研究者给出的解决方案是在训练过程中植入一致光(IC-Light)传输。

通过施加这种一致性,研究者引入了一个强大的、以物理为基础的约束条件,确保模型只修改图像的光照方面,同时保留反照率和精细图像细节等其他固有属性。这种方法可以在 1000 多万个不同样本上进行稳定、可扩展的训练,样本包括来自光照舞台的真实照片、渲染图像以及带有合成光照增强的野外图像。本文提出的方法能够提高光照编辑的精度,降低不确定性,减少伪影,同时不改变基本的外观细节。
总体来说,这篇论文的贡献主要包括:
(1) 提出了 IC-Light,一种通过施加一致光传输来扩展基于扩散的光照编辑模型训练的方法,确保在保留内在图像细节的同时进行精确的光照修改;
(2) 提供了预训练的光照编辑模型,以促进不同领域内容创建和处理中的光照编辑应用;
(3) 通过大量实验验证了这种方法的可扩展性和性能,显示了它在处理各种光照条件时与其他方法的不同之处;
(4) 介绍了其他应用,如法线贴图生成和艺术照明处理,进一步展示了该方法在真实世界、实际场景中的多功能性和鲁棒性。
实验结果
在实验中,研究者验证了扩大训练规模和数据源多样化可以增强模型的鲁棒性,并能提高各种与光照相关的下游任务的性能。
消融实验证明,在训练过程中应用 IC-Light 方法可以提高光照编辑的准确性,从而保留反照率和图像细节等内在属性。
此外,与在更小或更结构化的数据集上训练的其他模型相比,本文方法适用于更广泛的光照分布,如边缘照明、背光照明、魔法发光、日落光晕等。
研究者还展示了该方法处理更多野外照明场景的能力,包括艺术照明和合成照明效果。此外还探讨了生成法线贴图等更多应用,并讨论了这种方法与典型主流几何估计模型之间的差异。
消融实验
研究者首先恢复了训练中的模型,但删除了野外图像增强数据。如图 4 所示,移除野外数据严重影响了模型的泛化能力,尤其是对于肖像等复杂图像。例如,训练数据中不存在的肖像中的帽子经常会以不正确的颜色呈现(如从黄色变为黑色)。

研究者还尝试了移除光传输一致性。没有了这一限制,模型生成一致光照和保留反照率(反射颜色)等固有属性的能力明显下降。例如,一些图像中的红色和蓝色差异消失了,输出结果中也出现了明显的色彩饱和度问题。
而完整的方法结合了多种数据源,并加强了光传输的一致性,产生了一个能够在各种情况下通用的均衡模型。它还保留了细粒度图像细节和反照率等固有属性,同时减少了输出图像的误差。
其他应用
如图 5 所示,研究者还展示了其他应用,例如利用背景条件进行光照协调。通过对背景条件的额外通道进行训练,本文的模型可以完全根据背景图像生成照明,而无需依赖环境映射。此外,模型还支持不同的基础模型,比如 SD1.5、SDXL 和 Flux,这些模型的功能在生成的结果中都有所体现。

定量评估
在定量评估中,研究者使用了峰值信噪比(PSNR)、结构相似性指数(SSIM)和学习感知图像补丁相似性(LPIPS)等指标。并从数据集中提取了 50000 个未见过的 3D 渲染数据样本子集进行评估,确保模型在训练过程中没有遇到过这些样本。
测试的方法有 SwitchLight、DiLightNet,以及本文方法不包含某些组件(例如,不包含光传输一致性、不包含增强数据、不包含三维数据和不包含灯光舞台数据)的变体。
如表 1 所示,就 LPIPS 而言,本文方法优于其他方法,表明其具有卓越的感知质量。仅在三维数据上训练的模型获得了最高的 PSNR,这可能是由于对渲染数据的评估偏差所致(因为本次测试仅使用了三维渲染数据)。结合多种数据源的完整方法在感知质量和性能之间取得了平衡。

视觉对比
研究者还与之前的方法进行了直观比较。如图 6 所示,与 Relightful Harmonization 相比,由于训练数据集更大更多样化,本文模型对阴影的鲁棒性更高。SwitchLight 和本文模型产生了具有竞争力的重新照明结果。这种方法的法线贴图质量更细致一些,这要归功于从多个表象中合并和推导阴影的方法。此外,与 GeoWizard 和 DSINE 相比,该模型生成的人类法线贴图质量更高。

#神奇大模型不存在的,只是对人类标注的拙劣模仿
Andrej Karpathy~
也许是时候寻找新的方法了?
大模型回答人类的对话内容,究竟有多少「智能」成分在里面?
本周五,知名 AI 领域学者,OpenAI 创始成员、特斯拉前 AI 高级总监 Andrej Karpathy 发表观点:「人们对『向人工智能询问某件事』的解释过于夸张」,引发网友热议。

Karpathy 称:人工智能基本上是通过模仿人工标注数据来进行训练的语言模型。所以不要将对话视为「询问人工智能」的神秘主义,而应将其更多地视为「询问互联网上的平均数据标注者」。
例如,当你问「阿姆斯特丹十大景点」之类的问题时,一些受雇的数据标签员可能在某个时候看到了类似的问题,使用谷歌等软件研究了 20 分钟,列出了 10 个景点的列表,然后字面意思就变成了正确答案,训练人工智能给出该问题的答案。如果有问题的确切位置不在微调训练集中,神经网络会根据从预训练阶段(互联网文档的语言建模)获得的知识来进行估计。
当有网友评论称:「RLHF 可以创造超越人类的结果」,Karpathy 表示:「RLHF 仍然是来自人类反馈的 RL,所以我不会这么说」。

Karpathy 认为:RLHF 将模型性能从 SFT 的「人工生成」级别提升到「人工判别」级别。但这与其说是「原则上」,不如说是「实践上」,因为「判别」对于普通人来说比「生成」更容易(例如,判断这 5 首关于 X 的诗中哪一首最好,而不是写一首关于 X 的诗)。
另外,还可以从群体智慧效应中获得单独的提升,即 LLM 的性能不是达到人类水平,而是达到人类整体水平。因此,原则上,对于 RLHF,所能期望的最好结果就是达到专家水平。
所以从某种意义上来说,这算是「超人」,但 Karpathy 认为:要按照人们默认的方式成为真正的「超人」,要去 RL 而不是 RLHF。
其实,这已不是 Andrej Karpathy 第一次批判 RLHF 了。作为前 OpenAI 重要成员,他在今年 8 月就和 Yann LeCun 等人一起质疑过由 GPT 系列模型发扬光大的 RLHF 强化学习的意义。

「RLHF 只是勉强算强化学习。」
他当时使用 DeepMind 的 AlphaGo 作为例子。如果我们当时用 RLHF 的方法训练 AlphaGo 会是什么样子?可能会既无法构成有效的奖励,又会形成偏离正常轨道的优化,那就势必无法创造出「打败人类世界冠军」的历史了。
出于同样的原因,Karpathy 对 RLHF 竟然适用于 LLM 感到「有点惊讶」。因为我们为 LLM 训练的 RM(Reward Model)只是以完全相同的方式进行直觉检查。它会对人类标注者可能喜欢的判断给出高分,它不是正确解决问题的「实际」目标,而是人类认为好的替代目标。
其次,你甚至不能运行 RLHF 太长时间,因为你的模型很快就会学会适应游戏奖励模型,再推理出一些不正常的 Token。这在人类看来很荒谬,但出于某种原因 RM 会认为看起来很棒。
无独有偶,今年 9 月,一篇来自 VRAIN、剑桥大学研究人员的 Nature 论文对 o1-preview 等模型进行了评测,发现很多对于人类来说简单的任务,大模型却根本无法解决。而在一些复杂的任务上,LLM 也根本不知道「回避」,而是会装模作样的思考一通之后,给出一个错误的答案。
虽然随着时间的推移,大模型的参数体量越来越大,训练的数据也越来越多,性能也不断提升,但从基础机制的角度来说,它们似乎并不靠谱。
如果 RLHF 不管用,还能有什么样的奖励机制能帮助大模型「准确遵循指令」呢?
今年 7 月,OpenAI 就公布了一种教导 AI 模型遵守安全政策的新方法,称为基于规则的奖励(Rule-Based Rewards,RBR)。RBR 不仅限于安全训练,它们可以适应各种任务,其中明确的规则可以定义所需的行为,例如为特定应用程序定制模型响应的个性或格式。这或许为大模型下一步性能突破提供了新的思路。
参考内容:
https://x.com/karpathy/status/1821277264996352246
#用 MCP 让大模型自动批量下载文献
MCP 最近这么火,你还不知道它是啥吗?别慌,动手实战一番就包你明白了。
而且,咱这个是真的实战,绝对干货啊,全网少见的干货。
我们之前讲了很多建立知识库之类的,新鲜的知识才有意思嘛。问题是新鲜货哪里来呢,徒手去搜索加下载?2025 年了,咱不能这么干了。
你有没有想过让大模型自动给我们搜索、下载、解读文献,一条龙服务?即便像 Deep Research 之类的服务也主要是帮你搜索和整合资源,但不给你下载资源对不。
实际上,是可以手撸一个智能体帮我们干这项大工程的。只是现在不是流行 MCP 嘛,咱们也想通过这种方式来建一个。
马上给你安排上。
本篇将以 arxiv 为例,目标是让你发个话,智能体就帮你搜索、下载文献,甚至解读一条龙到家。
为了照顾不同需求,咱这里贴心地实现了两套方案,
- Trae CN + Cline,功能强大
- Cherry Studio,容易上手
当然,如果你喜欢的话,也不拦着你直接用 Python 开干。1、MCP
这个概念最近很热,相信大家都见过。这里简要地作个解释,毕竟本篇的主旨是在于动手实践。
你别看网文一篇一篇,不如跟着本篇撸一撸,你就真刀真枪见识过了。
当然,概念了解下还是有必要的。先看一个图,心急的话也可以跳过此图看下面的大白话。

MCP 作为「模型上下文协议」,可以看成专门为 AI 模型设计生态系统服务,它通过一个标准化的协议来管理和交换 AI 模型所需的各种信息,从而实现与各种外部服务和数据源的无缝集成。
用大白话来说,MCP 就像是 AI 模型(比如 DeepSeek、Gemini 等)的「超级翻译官」和「万能助手」。
我们不妨想象一下,AI 模型是个很厉害的专家,但是它自己只会说一种「AI 语言」。它需要跟各种网站、数据库、工具等外部世界打交道才能完成任务。
- 翻译官: 这些「外部世界」说的都是不同的「外语」,即各种不同的数据格式和通信方式。MCP 就负责把 AI 模型说的话翻译成这些外语,也把这些外语翻译成 AI 模型能听懂的话。这样,AI 模型就不用学那么多外语了,只需要跟 MCP 说就行。
- 万能助手: AI 模型有时候需要很多信息才能做好一件事,就像做菜需要菜谱、食材、调料一样。MCP 就负责把 AI 模型需要的所有信息(比如要查的资料、要用的工具、之前的聊天记录等等)都准备好,打包成一个大礼包(上下文),交给 AI 模型。这样,AI 模型就能直接开始工作。
举个例子:
你问 DeepSeek:杭州今天天气怎么样?
DeepSeek 自己没这项功能啊,咋办?它通过 MCP 获知提供这项功能的服务,然后使唤它查询外部天气预报网站,得知今天杭州的天气情况,再将数据整理好,最后给你答案:杭州今天晴,最高 27 度。
所以,MCP 的好处是:
- 简单: AI 模型不用学那么多外语,不用操心那么多杂事,只需要跟 MCP 打交道。
- 方便: 要加新的功能,比如查天气、订机票、下载文献等,只需要让 MCP 学会跟新的外部世界打交道就行,不用改 AI 模型本身。
- 整洁: MCP 把所有乱七八糟的信息都整理好,AI 模型用起来更顺手。
总之,MCP 就是一个让 AI 模型更方便、更强大、更容易跟各种服务和数据打交道的「中间人」。
这时候可以品一下这个图,

2、安装服务
回到主题,我们的目标是自动给咱从 arxiv 上下载文献,那就先搜一下提供这个功能的 MCP 服务器。
找到两个,一个如下图所示,但感觉它主要是搜索,貌似不提供下载业务。

另一个见下图,看起来它是能够下载文献的。这下省事了,必须给一个大赞。

本人用的是 mac,下面的安装流程也是针对它而言。因为手头没有 Windows 电脑,稍微有点差异吧,但问题应该不大,稍微捣鼓一下肯定没问题。
- 安装第一个比较方便,用命令
pip install mcp-simple-arxiv 即可; - 用
brew install uv 先安装 uv,然后用命令 uv tool install arxiv-mcp-server 安装第二个。
顺利的话,很快就搞定啦。主要一点,你安装过 Python,就方便了。

然后就是在 Cline 里配置,可以用 VS Code 或者 Cursor、Windsurf 之类的。
此处我们用国货 Trae 的国内版,安装插件 Cline 咱就略过了,直接打开 Cline,点击 MCP 服务器。

然后,点击左侧底部的 Configure MCP Servers,像右侧那样填写,然后看到灯绿就算配置好了。

这样子就算配置好两个 MCP 服务了,然后就等着给大模型发号施令:搜索、解读、下载等任务。搜索和下载不是大模型自己的本事,需要外挂。
在 Cline 中提供了两种与大模型的交互模式,计划模式(Plan)和执行模式(Act),分别负责智能规划任务和高效执行任务。
3、设置大模型
别忘了在 Cline 里选择大模型!注意,这里需要大模型的 API Key。你可以让 plan 和 act 使用同一个模型,或者让它们分别使用不同模型。比如一个用 deepseek-chat,另一个使用 deepseek-reasoner,像下面这样。

虽然在 DeepSeek API 那里咱也充了钱,但为了省钱,继续撸谷歌的羊毛,此处均使用 Gemini 2.0 Pro or Flash。
4、论文智能体
好了,现在就是整装待发的状态了。

Cline 默认在左侧,如果你习惯右侧开车的话,像下面这样点击一下即可发射到右侧。

左侧关掉,就可以右侧开车了。
给大模型下达命令:帮我搜一下扩散模型和大语言模型相结合的最新论文。

Gemini 调用 simple-arxiv 搜了 10 篇论文,

继续下命令:把这些论文的摘要和方法概要用中文解读一下,然后存放到一个 Markdown 文件中。
稍等一会儿,左侧就自动出现一个 Markdown 文件,里面就是摘要和对方法的简要解读。

下载论文
接下来,我们让它下载论文。你会发现,这时它会自动调用第二个服务,就是 arxiv-mcp-server。因为第一服务并没有提供下载业务嘛。

它会询问你是否下载到配置好的那个目录里,选 yes。

不一会儿,任务完成。不过你也可以让它给你把文件名改一改。

上面这样子其实是比较泛泛地搜索,如果想让它精细一些,比如让它搜题目中包含 Self-Supervised Learning 的论文。

会发现返回的结果不符要求,只有一篇的题目符合要求。
那就给它明确指示:在 arxiv 上使用 ti: "Self-Supervised Learning" 搜。

这样看着就对路了嘛。

接着,让它给出详细信息,

5、Cherry Studio
如果你没怎么编过程,也许不喜欢 Trae + Cline 这种方式,那咱们也可以使用可爱的小樱桃是不。代价是用不了 Trae 强大的文件编辑能力。
因为我们前面已经安装好相应的工具了,这里只需要配置一下 MCP 服务器即可。
先如下步骤打开配置文件,

然后,可以直接参考我的配置。
{
"mcpServers": {
"arxiv-mcp-server": {
"command": "uv",
"args": [
"tool",
"run",
"arxiv-mcp-server",
"--storage-path",
"~/Documents/arxiv"
]
},
"simple-arxiv": {
"command": "/opt/anaconda3/bin/python",
"args": [
"-m",
"mcp_simple_arxiv"
]
}
}
}回到上面那个图,启用那里的绿灯点亮的话,就说明 OK 啦。
接着,到聊天界面打开 MCP 服务器。

最后,选择大模型,给它上活。


最后三篇如下,

不错,题目都符合要求。然后,让它下载一篇看看。

好了,今天就到这里了。
怎么样,有没有心动?论文自动下载、自动解读,是不是有很多事情可以搞了?请你发挥想象吧。MCP + 论文,赶紧捣鼓起来吧,别忘了回来交流经验。
#CFG-Zero*
南洋理工&普渡大学提出:在Flow Matching模型中实现更稳健的无分类器引导方法
本篇论文是由南洋理工大学 S-Lab 与普渡大学提出的无分类引导新范式,支持所有 Flow Matching 的生成模型。目前已被集成至 Diffusers 与 ComfyUI。
- 论文标题:CFG-Zero*: Improved Classifier-Free Guidance for Flow Matching Models
- 论文地址:https://arxiv.org/abs/2503.18886
- 项目主页:https://weichenfan.github.io/webpage-cfg-zero-star/
- 代码仓库:https://github.com/WeichenFan/CFG-Zero-star
随着生成式 AI 的快速发展,文本生成图像与视频的扩散模型(Diffusion Models)已成为计算机视觉领域的研究与应用热点。
近年来,Flow Matching 作为一种更具可解释性、收敛速度更快的生成范式,正在逐步取代传统的基于随机微分方程(SDE)的扩散方法,成为主流模型(如 Lumina-Next、Stable Diffusion 3/3.5、Wan2.1 等)中的核心方案。
然而,在这一技术迭代过程中,一个关键问题依然存在:如何在推理阶段更好地引导生成过程,使模型输出更加符合用户提供的文本描述。
Classifier-Free Guidance(CFG)是当前广泛采用的引导策略,但其引导路径在模型尚未充分训练或估计误差较大时,容易导致样本偏离真实分布,甚至引入不必要的伪影或结构崩塌。
对此,南洋理工大学 S-Lab 与普渡大学的研究者联合提出了创新方法——CFG-Zero*,针对传统 CFG 在 Flow Matching 框架下的结构性误差进行了理论分析,并设计了两项轻量级但效果显著的改进机制,使生成图像/视频在细节保真度、文本对齐性与稳定性上全面提升。

研究动机:CFG 为何失效?
传统的 CFG 策略通过对有条件与无条件预测结果进行插值来实现引导。然而在 Flow Matching 模型中,推理过程是通过解常微分方程(ODE)进行的,其每一步依赖于前一步的速度估计。
当模型训练不足时,初始阶段的速度往往较为不准确,而 CFG 此时的引导反而会将样本推向错误轨迹。研究者在高斯混合分布的可控实验中发现,CFG 在初始步的引导效果甚至不如「静止不动」,即设速度为 0。
方法介绍
研究者提出了 CFG-Zero*,并引入以下两项关键创新:

1.优化缩放因子(Optimized Scale):在每个时间步中动态计算有条件速度与无条件速度的内积比值,从而调整 CFG 中无条件项的强度,避免「过度引导」导致的误差。
2.零初始化(Zero-init):将 ODE 求解器的前 K 步速度置为零(默认 K=1),跳过模型最不可靠的预测阶段,有效降低初始误差传播。
这两项策略可无缝集成至现有的 CFG 推理流程中,几乎不引入额外计算开销。下面我们具体介绍该方法的细节:
优化缩放因子
首先,CFG 的目标是能够估计出一个修正的速度,能够尽可能接近真实速度:

为了提升引导的精度,研究者引入了一个修正因子 s:

基于此可以建立优化的目标:

代入化简可以得到:

求解最优值为:

因此新的 CFG 形式为:
![]()
零初始化
研究者在 2D 多元高斯分布上进行进一步定量分析,可以求解得到扩散过程中每一步的最优速度的 closed-form:

基于此,他们在训练了一个模型,并分析训练不同轮数下模型的误差,如下图所示。

研究者发现在训练早期阶段,无分类引导得到的速度误差较大,甚至不如将速度设置为 0:

他们进一步在高维情况下验证了这一观察,如下图所示。

研究者对比原始 CFG 与仅使用零初始化的 CFG,发现随着模型的收敛,零初始化的收益逐渐变小,在 160 轮训练后出现拐点,与多元高斯实验结果吻合。
实验结果
研究者在多个任务与主流模型上验证了 CFG-Zero* 的有效性,涵盖了文本生成图像(Text-to-Image)与文本生成视频(Text-to-Video)两大方向。
在图像生成任务中,研究团队选用了 Lumina-Next、SD3、SD3.5、Flux 等当前 SOTA 模型进行对比实验,结果显示 CFG-Zero* 在 Aesthetic Score 与 CLIP Score 两项核心指标上均优于原始 CFG。
例如在 Stable Diffusion 3.5 上,美学分有明显提高,不仅图像美感更强,而且语义一致性更好。在 T2I-CompBench 评测中,CFG-Zero* 在色彩、纹理、形状等多个维度均取得更优表现,特别适用于需要精准表达复杂语义的生成任务。
在视频生成任务中,研究者将 CFG-Zero* 集成到 Wan2.1 模型中,评估标准采用 VBench 基准套件。结果表明,改进后的模型在 Aesthetic Quality、Imaging Quality、Motion Smoothness 等方面均有所提升,呈现出更连贯、结构更稳定的视频内容。CFG-Zero* 有效减少了图像跳变与不自然的位移问题。

实际测试
CFG-Zero* 在开源社区中实现了快速落地。目前,该方法已正式集成至 ComfyUI 与 Diffusers 官方库,并被纳入视频生成模型 Wan2.1GP 的推理流程。借助这些集成,普通开发者与创作者也能轻松体验该方法带来的画质与文本对齐提升。

该方法可以用于图生视频。我们使用官方的 repo 用这张测试图:
输入 prompt:「Summer beach vacation style. A white cat wearing sunglasses lounges confidently on a surfboard, gently bobbing with the ocean waves under the bright sun. The cat exudes a cool, laid-back attitude. After a moment, it casually reaches into a small bag, pulls out a cigarette, and lights it. A thin stream of smoke drifts into the salty breeze as the cat takes a slow drag, maintaining its nonchalant pose beneath the clear blue sky.」
得到的视频如下:(第一个为原始 CFG 生成的,第二个为 CFG-Zero* 生成的),效果还是比较明显,值得尝试。
该方法对 Wan2.1 文生视频同样适用:(图 1 为原始 CFG,图 2 为 CFG-Zero*)
使用的 Prompt:「A cat walks on the grass, realistic.」
该方法同时兼容 LoRA:
使用的 LoRA 为:https://civitai.com/models/46080?modelVersinotallow=1473682
Prompt:「Death Stranding Style. A solitary figure in a futuristic suit with a large, intricate backpack stands on a grassy cliff, gazing at a vast, mist-covered landscape composed of rugged mountains and low valleys beneath a rainy, overcast sky. Raindrops streak softly through the air, and puddles glisten on the uneven ground. Above the horizon, an ethereal, upside-down rainbow arcs downward through the gray clouds — its surreal, inverted shape adding an otherworldly touch to the haunting scene. A soft glow from distant structures illuminates the depth of the valley, enhancing the mysterious atmosphere. The contrast between the rain-soaked greenery and jagged rocky terrain adds texture and detail, amplifying the sense of solitude, exploration, and the anticipation of unknown adventures beyond the horizon.」

该方法对最强文生图模型 Flux 同样支持:

使用的 Prompt:「a tiny astronaut hatching from an egg on the moon.」
该方法实现也比较简单,作者在附录中直接附上了代码,如下图:

#VideoScene
打通视频到3D的最后一公里,清华团队推出一键式视频扩散模型VideoScene
论文有两位共同一作。汪晗阳,清华大学计算机系本科四年级,研究方向为三维视觉、生成模型,已在CVPR、ECCV、NeurIPS等会议发表论文。刘芳甫,清华大学电子工程系直博二年级,研究方向为生成模型 (3D AIGC和Video Generation等),已在CVPR、ECCV、NeurIPS、ICLR、KDD等计算机视觉与人工智能顶会发表过多篇论文。

从视频到 3D 的桥梁:VideoScene 一步到位
随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。但传统方法往往需要大量图片、繁琐的多步迭代,既费时又难以保证高质量的 3D 结构重建。
来自清华大学的研究团队首次提出 VideoScene:一款 “一步式” 视频扩散模型,专注于 3D 场景视频生成。它利用了 3D-aware leap flow distillation 策略,通过跳跃式跨越冗余降噪步骤,极大地加速了推理过程,同时结合动态降噪策略,实现了对 3D 先验信息的充分利用,从而在保证高质量的同时大幅提升生成效率。
- 论文标题:VideoScene:Distilling Video Diffusion Model to Generate 3D Scenes in One Step
- 论文地址: https://arxiv.org/abs/2504.01956
- 项目主页: https://hanyang-21.github.io/VideoScene
- Github 仓库: https://github.com/hanyang-21/VideoScene
稀疏视角重建方法挑战
在稀疏视角重建领域,从少量图像中精准恢复 3D 场景是个极具挑战性的难题。传统方法依赖多视角图像间的匹配与几何计算 ,但当视角稀疏时,匹配点不足、几何约束缺失,使得重建的 3D 模型充满瑕疵,像物体结构扭曲、空洞出现等。
为突破这一困境,一些前沿方法另辟蹊径,像 ReconX 就创新性地借助视频生成模型强大的生成能力,把重建问题与生成问题有机结合。它将稀疏视角图像构建成全局点云,编码为 3D 结构条件,引导视频扩散模型生成具有 3D 一致性的视频帧,再基于这些帧重建 3D 场景,在一定程度上缓解了稀疏视角重建的不适定问题。
不过,当前大多数 video to 3D 工具仍存在效率低下的问题。一方面,生成的 3D 视频质量欠佳,难以生成三维结构稳定、细节丰富、时空连贯的视频。在处理复杂场景时,模型容易出现物体漂移、结构坍塌等问题,导致生成的 3D 视频实用性大打折扣。另一方面,基于扩散模型的视频生成通常需要多步降噪过程,每一步都涉及大量计算,不仅耗时久,还带来高昂的计算开销,限制了其在实际场景中的应用。
继承与超越:ReconX 理念的进化
此前研究团队提出 video-to-3D 的稀释视角重建方法 ReconX,核心在于将 3D 结构指导融入视频扩散模型的条件空间,以此生成 3D 一致的帧,进而重建 3D 场景。它通过构建全局点云并编码为 3D 结构条件,引导视频扩散模型工作 ,在一定程度上解决了稀疏视角重建中 3D 一致性的问题。
VideoScene 继承了 ReconX 将 3D 结构与视频扩散相结合的理念,并在此基础上实现了重大改进,堪称 ReconX 的 “turbo 版本”。
在 3D 结构指导方面,VideoScene 通过独特的 3D 跃迁流蒸馏策略,巧妙地跳过了传统扩散模型中耗时且冗余的步骤,直接从含有丰富 3D 信息的粗略场景渲染视频开始,加速了整个扩散过程。同时也使得 3D 结构信息能更准确地融入视频扩散过程。在生成视频帧时,VideoScene 引入了更强大的动态降噪策略,不仅仅依赖于固定的降噪模式,而是根据视频内容的动态变化实时调整降噪参数,从而既保证了生成视频的高质量,又极大地提高了效率。

研究团队提出的 VideoScene 方法流程图
实验结果
通过在多个真实世界数据集上的大量实验,VideoScene 展示出了卓越的性能。它不仅在生成速度上远超现有的视频扩散模型,而且在生成质量上也毫不逊色,甚至在某些情况下还能达到更好的效果。这意味着 VideoScene 有望成为未来视频到 3D 应用中的一个重要工具。在实时游戏、自动驾驶等需要高效 3D 重建的领域,有潜力能发挥巨大的作用。

VideoScene 单步生成结果优于 baseline 模型 50 步生成结果

视频扩散模型在不同去噪步数下的表现
,时长00:54
如果你对 VideoScene 感兴趣,想要深入了解它的技术细节和实验结果,可访问论文原文、项目主页和 GitHub 仓库。
#Deep Research for arXiv
论文党狂喜!alphaXiv推出Deep Research一秒搜遍arXiv,研究效率直接爆表
刚刚,alphaXiv 推出了新功能「Deep Research for arXiv」,该功能可协助研究人员更高效地在 arXiv 平台上进行学术论文的检索与阅读,显著提升文献检索及研究效率。

体验链接:https://www.alphaxiv.org/assistant
在官方演示视频中,当用户输入「Can you help me do a lit review for self-supervised learning. with relevant applications?」时,系统迅速生成了一篇内容完整、结构清晰的文献综述,并提供了 arXiv 链接。
随后,用户询问「What are the latest breakthroughs in RL fine-tuning for LLMs?」,系统立即生成了包含当前热门论文的详细回答,将原本可能需要数小时的文献搜索过程缩短至几秒钟。
,时长00:50
该功能在 X 上引发了热烈讨论,有用户迅速试用并送出大大的点赞。

上手实测一下,输入「图文大模型的最新研究进展」,可以看到,系统给出了最新的 arXiv 论文链接。

此前,alphaXiv 还推出过自动为 arXiv 论文生成博客风格概述的功能,该功能结合了 Mistral OCR 和 Claude 3.7 的处理能力。

alphaXiv
alphaXiv 是一个开放式学术讨论平台,直接基于 arXiv 构建,旨在使学术研究更加开放、易于访问和互联。该平台由斯坦福大学的两位学生 Rehaan Ahmad 和 Raj Palleti 于 2023 年 5 月创立,最初是一个本科项目,目的是为学生和研究人员提供在线平台,用于讨论 arXiv 上未经同行评审的预印本论文。

alphaXiv 专注于 arXiv 论文,有效避免了类似 X 或 Reddit 等平台上信息过载的问题,同时保持了学术讨论的专业性。
论文逐行讨论
用户可通过将 arXiv 论文 URL 中的「arxiv.org」替换为「alphaxiv.org」,直接访问该论文的 alphaXiv 页面,并进行逐行评论与讨论。页面左侧显示原始论文,右侧展示相关评论及回复,便于用户针对特定段落提出问题或分享见解。
社区互动
平台支持研究人员、学生和爱好者之间的互动交流,部分作者会亲自回复评论。用户可通过「Trending」页面查看当前讨论最活跃的论文,或使用「Talk to Authors」功能筛选出作者参与讨论的论文。
增强用户体验的工具
- 浏览器扩展:alphaXiv 提供 Chrome 扩展,当用户阅读 arXiv 论文时提示是否有相关讨论。
- ORCID 集成:用户可连接 ORCID 账户,提升在论坛中的可信度。
- 私密笔记:支持用户记录仅自己可见的私人笔记,便于个人研究。
#video-dit
AI封神了!无剪辑一次直出60秒《猫和老鼠》片段,全网百万人围观
AI 圈永远不缺「新活」。
这两天,加州大学伯克利分校、斯坦福大学、英伟达等机构联合制作的《猫和老鼠》AI短片火了。

论文共同一作 Karan Dalal 的帖子收获百万观看。
我们先来欣赏下面两段视频,重温儿时的快乐。
,时长01:03
故事梗概:In an underwater adventure, Jerry locates a treasure map and searches for the treasure while evading Tom in a chase through coral reefs and kelp forests. Jerry triumphantly discovers treasure inside a shipwreck, blissfully celebrating while Tom's pursuit leads him into trouble with a hungry shark. (在一次水下探险中,Jerry 找到了藏宝图,并在躲避 Tom 追捕的同时寻找宝藏,途中穿过珊瑚礁和海藻森林。Jerry 在一艘沉船中发现了宝藏,欣喜若狂地庆祝着,而 Tom 的追捕却让他陷入了饥饿鲨鱼的困境。)
,时长01:03
故事梗概:Tom is happily eating an apple pie at the kitchen table. Jerry looks longingly wishing he had some. Jerry goes outside the front door of the house and rings the doorbell. While Tom comes to open the door, Jerry runs around the back to the kitchen. Jerry steals Tom's apple pie. Jerry runs to his mousehole carrying the pie, while Tom is chasing him. Just as Tom is about to catch Jerry, he makes it through the mouse hole and Tom slams into the wall.(Tom 在厨房餐桌上开心地吃着苹果派。Jerry 看起来渴望地想要吃一些。Jerry 走到屋前门外按门铃。Tom 来开门时,Jerry 绕到后面的厨房。Jerry 偷走了 Tom 的苹果派。Jerry 拿着苹果派跑到他的老鼠洞里,而 Tom 正在追赶他。就在 Tom 即将抓住 Jerry 时,他从老鼠洞里逃了出来,Tom 撞到了墙上。)
类似的《猫和老鼠》短片共五集,每集都是全新的故事。大家可以在项目主页查看对应的故事梗概和完整的提示词。

项目主页:https://test-time-training.github.io/video-dit/
效果怎么样?如果不提前告知,你能分辨出它们是 AI 生成的吗?
据论文另一位共同一作 Gashon Hussein 介绍,为了实现逼真的动画效果,他们利用 TTT(Test-time Training,测试时训练)层来增强预训练 Transformer,并进行了微调,从而生成了时间和空间上连贯性很强的《猫和老鼠》一分钟短片。
尤其值得注意的是,所有视频都是由模型一次性直接生成,没有进行任何二次编辑、拼接或后期处理。

Gashon Hussein 进一步解释了背后的技术原理。
TTT 层是专门的 RNN 层,其中每个隐藏状态代表了一个机器学习模型。此外,这些层内的更新使用梯度下降来完成。本文将 TTT 层集成到一个预训练的 Diffusion Transformer 中,随后使用文本标注对长时间视频进行微调。并且,为了管理计算复杂度,自注意力被限制在局部片段,而 TTT 层以线性复杂度来高效地处理全局上下文。
此外,为了高效地实现 TTT-MLP 内核,本文开发了一种「片上张量并行」(On-chip Tensor Parallel)算法,具体包括以下两个步骤:
- 在 GPU 流多处理器(Sreaming Multiprocessor,SM)之间划分隐藏状态模型的权重;
- 利用 Hopper GPU 的 DSMEM 功能在 SM 之间执行高效的 AllReduce 操作,显著降低全局内存(HBM)和共享内存(SMEM)之间的数据传输,确保大量隐藏状态在 SMEM 内可以有效访问。
下图 3 为方法概览,其中(左)为本文修改后的架构在每个注意力层后添加一个带有可学习门的 TTT 层,(右)为整体 pipeline 创建了由 3 秒片段组成的输入序列,这种结构允许在片段上局部应用自注意力层,在整个序列上全局应用 TTT 层。

具体实现过程是这样的:
本文研究者从一个预训练好的 DiT(CogVideo-X 5B)开始,它只能以 16 帧 / 秒的速度生成 3 秒钟的短片(或以 8 帧 / 秒的速度生成 6 秒钟的短片)。然后添加了从零开始初始化的 TTT 层,并对该模型进行微调,以便从文本故事板生成一分钟的视频。研究者将自注意力层限制在 3 秒钟的片段内,使其成本保持在可控范围内。仅通过初步的系统优化,训练运行就相当于在 256 台 H100 上花费了 50 个小时。
这项研究博得了评论区一众网友的惊呼与赞许。

研究细节
在论文《One-Minute Video Generation with Test-Time Training》中,英伟达、斯坦福等机构的研究者介绍了《猫和老鼠》短片背后的更多生成技术细节。

- 论文标题:One-Minute Video Generation with Test-Time Training
- 论文地址:https://arxiv.org/pdf/2504.05298
此前视频生成技术限制背后的根本挑战是长上下文,因为 Transformers 中自注意力层的成本随着上下文长度的增加而呈二次曲线增加。这一挑战在生成动态视频时尤为突出,因为动态视频的上下文不容易被 tokenizer 压缩。使用标准 tokenizer,每段一分钟的视频都需要 30 多万个上下文 token。基于自注意力,生成一分钟视频所需的时间要比生成 20 段每段 3 秒钟的视频增加 11 倍,而训练所需的时间也要增加 12 倍。
为了应对这一挑战,最近有关视频生成的研究将 RNN 层作为自注意力的有效替代方法,因为 RNN 层的成本随上下文长度呈线性增长。现代 RNN 层,尤其是线性注意力的变体(如 Mamba 和 DeltaNet),在自然语言任务中取得了令人印象深刻的成果。然而,我们还没有看到由 RNN 生成的具有复杂故事或动态动作的长视频。
本文研究者认为,这些 RNN 层生成的视频复杂度较低,因为它们的隐藏状态表现力较差。RNN 层只能将过去的 token 存储到固定大小的隐藏状态中,而对于 Mamba 和 DeltaNet 等线性注意力变体来说,隐藏状态只能是一个矩阵。要将成百上千个向量压缩到一个只有数千级的矩阵中,这本身就是一项挑战。因此,这些 RNN 层很难记住远处 token 之间的深层关系。
因此研究者尝试使用另一种 RNN 层,其隐藏状态本身也可以是神经网络。具体来说,研究者使用两层 MLP,其隐藏单元比线性注意力变体中的线性(矩阵)隐藏状态多 2 倍,非线性也更丰富。即使在测试序列上,神经网络的隐藏状态也会通过训练进行更新,这些新层被称为测试时间训练层(TTT)。

局部注意力机制在汤姆的颜色、杰瑞的鼠洞之间保持了一致性,并且扭曲了汤姆的身体。

TTT-MLP 在整个视频时长中表现出强大的特性和时间一致性。
研究者策划了一个文本到视频的数据集,该数据集基于大约 7 小时的《猫和老鼠》动画片,并附有人类注释的故事板。他们有意将范围限制在这一特定领域,以便快速进行研究迭代。作为概念验证,该数据集强调复杂、多场景和具有动态运动的长篇故事,此前的模型在这些方面仍需取得进展;而对视觉和物理逼真度的强调较少,因为此前的模型在这些方面已经取得了显著进展。研究者认为,尽管本文是面向这一特定领域的长上下文能力改进,但也会转移到通用视频生成上。
生成质量评估
在测评中,与 Mamba 2、Gated DeltaNet 和滑动窗口注意力层等强大的基线相比,TTT 层生成的视频更连贯,能讲述复杂的动态故事。

在 LMSys Chatbot Arena 中,GPT-4o 比 GPT-4 Turbo 高出 29 个 Elo 分数。

具体对比参考下列 demo:
,时长01:03
当汤姆咆哮并追逐杰瑞时,Mamba 2 扭曲了汤姆的外貌。
,时长01:03
Gated DeltaNet 在汤姆的不同角度上缺乏时间一致性。
,时长01:03
滑动窗口注意力改变了厨房环境并重复了杰瑞偷馅饼的场景。
不过,在生成内容中,我们也能发现 TTT-MLP 一些明显的瑕疵。
1、时间一致性:盒子在同一场景的 3 秒片段之间变形。
2、运动自然性:奶酪悬停在半空中,而不是自然地落到地上。
3、美学:当汤姆转身时,厨房里的灯光变得更加明亮。
#DeepSeek-V3 + SGLang
推理优化 (v0.4.3.post2+sgl-kernel:0.0.3.post6)
本文详细介绍了DeepSeek V3与SGLang集成的推理优化策略,涵盖CUDA Graph执行、Torch编译、FP8精度改进、NextN推测解码、MLA数据并行注意力、重叠调度器、FlashInfer优化、FP8 GEMM调优、CUTLASS实现以及MoE融合优化等多个方面,旨在通过这些优化提升DeepSeek V3模型系列的推理性能和效率。
DeepSeek V3 SGLang 优化
继续我们的DeepSeek V3与SGLang集成的技术系列,我们旨在全面概述可用于提高性能和效率的各种优化策略。最终目标是在为DeepSeek V3模型系列(包括R1)提供基于原生优化的竞争性推理性能的同时,培养LLM前沿改进的专业知识。作为推理服务引擎,SGLang与ML基础设施堆栈的多个组件交互,为不同级别的优化提供了机会。大多数优化都以launch_server CLI的标志形式出现。这些标志为了解SGLang生态系统中随时间实现的各种性能增强提供了一个便捷的入口点。
优化总结表

kernel执行优化相关标志:
--disable_cuda_graph: # 禁用CUDA Graph。
--cuda_graph_bs: # 由`CudaGraphRunner`捕获的批量大小。
--cuda_graph_max_bs: # 使用CUDA Graph时调整最大批量大小。
--enable-torch-compile: # 启用捕获的CUDA Graph的torch.compile编译。背景:
CUDA Graph(https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/)和torch.compile(https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)标志都致力于提高 kernel操作的效率。CUDA Graph通过记录和重放CUDA操作序列作为单个单元,显著减少了 kernel启动开销,消除了推理期间每个 kernel的启动成本。同时,torch.compile采用 kernel融合、算子消除和专门的 kernel选择来优化计算图。然而,SGLang的torch.compile可以使用PyTorch生成的图或CUDA Graph来连接这两种优化。
提交:
支持triton后端的CUDA Graph(https://github.com/sgl-project/sglang/pull/1401),支持DP注意力的CUDA Graph #2061(https://github.com/sgl-project/sglang/pull/2061)
基准测试:
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--torch-compile-max-bs 1 --disable-cuda-graph
--profile
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--torch-compile-max-bs 1 --cuda-graph-max-bs 1
--profile
$ python3 -m sglang.bench_one_batch --batch-size 1 --input 256
--output 32 --model deepseek-ai/DeepSeek-V3 --trust-remote-code --tp 8
--enable-torch-compile --torch-compile-max-bs 1 --cuda-graph-max-bs 1结果:

compile-bench
正如预期的那样,当堆叠优化(torch.compiler / CUDA Graph + torch.compiler / torch.compiler(CUDA Graph) + torch.compiler)时,我们减少了总延迟(7.322 / 1.256 / 1.011 s)并提高了总吞吐量(39.34 / 229.27 / 284.86 token/s)。注意: 我们看到预填充阶段延迟的下降,这是由于torch.compiler编译和CUDA Graph未捕获预填充阶段操作导致的初始计算增加(0.21180 / 0.25809 / 0.26079 s)和吞吐量(1208.67 / 991.92 / 981.64 token/s)。
bf16批量矩阵乘法 (bmm)
背景:
批量矩阵乘法是LLM中执行的主要工作负载。由于DeepSeek-V3使用不同的量化fp8数据类型(float8_e5m2和float8_e4m3fn)进行训练(从而减少内存分配),我们测试了具有不同fp8和基础bf16数据类型组合的随机bmm集合的精度和延迟。此优化不依赖于标志。
提交:
(修复MLA的fp8并支持DeepSeek V2的bmm fp8(https://github.com/sgl-project/sglang/pull/1285),在AMD GPU上启用DeepseekV3(https://github.com/sgl-project/sglang/pull/2601),将bmm_fp8 kernel集成到sgl-kernel中(https://github.com/sgl-project/sglang/pull/3056))
基准测试:
$ pytest -s test_bmm_fp8.py- 使用修改版的
test_bmm_fp8.py获得的结果
结果:

bmm-bench
结果之间的相似度接近相同(余弦相似度=1相同),这表示没有精度损失,而fp8的延迟比bf16差,这是由于类型转换计算导致的。
支持nextn推测解码
相关标志:
--speculative-num-steps: # 从草稿模型中采样的步骤数。
--speculative-eagle-topk: # 在EAGLE-2的每个步骤中从草稿模型中采样的token数。
--speculative-num-draft-tokens: # 在推测解码中从草稿模型中采样的token数。
--speculative-draft: # 要使用的草稿模型。它需要与验证器模型相同的分词器(默认:SGLang/DeepSeek-V3-NextN)。背景:
推测解码通过引入草稿模型(一个更小、更快的模型)来加速推理,该模型一次生成多个token。然后验证步骤检查这些草稿token是否与更大、更准确的LLM的预测匹配。其主要缺陷是,由于Naive的推测解码生成单个线性草稿token序列,如果序列中的单个token被拒绝,所有后续token都会被丢弃,降低了接受率。SGLang的NextN实现基于EAGLE-2和SpecInfer:

speculative_decoding.png
使用基于树的推测解码(SpecInfer和EAGLE-2),预测被组织为树,其中每个节点代表一个可能的下一个token。通过这种方法,我们生成多个可以并行验证器LLM验证的推测分支,提高了接受率。EAGLE-2的关键改进是基于上下文的动态草稿树和基于草稿模型置信度分数的节点剪枝。
提交:
([Track] DeepSeek V3/R1 nextn进度 #3472,(https://github.com/sgl-project/sglang/issues/3472),支持DeepSeek-V3/R1的NextN (MTP)推测解码 #3582(https://github.com/sgl-project/sglang/pull/3582),支持Triton后端的Eagle2 #3466(https://github.com/sgl-project/sglang/pull/3466),Eagle推测解码第4部分:添加EAGLE2工作器 #2150(https://github.com/sgl-project/sglang/pull/2150))
基准测试:
无标志。
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 1 --host 127.0.0.1 --port 30000--speculative-algo NEXTN --speculative-draft SGLang/DeepSeek-V3-NextN --speculative-num-steps 2 --speculative-eagle-topk 4 --speculative-num-draft-tokens 4python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --speculative-algo NEXTN --speculative-draft SGLang/DeepSeek-V3-NextN --speculative-num-steps 2 --speculative-eagle-topk 4 --speculative-num-draft-tokens 4 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 1 --host 127.0.0.1 --port 30000结果:

spec-bench
我们实现了总体吞吐量(请求、输入和输出)的改进,并显著(x6)减少了端到端延迟。
GiantPandaLLM注:这里的测试结果存疑,应该没这么大加速,不过先了解这是一个有用的优化就可以。
MLA
TP+DP注意力
相关标志:
--enable-dp-attention: # 启用兼容的MLA数据并行。背景:
张量并行(TP)通过将KV Cache按TP设备(通常是8)分割来与MHA一起工作,因此每个设备处理KV Cache的1/TP。 [1]如果我们将其应用于多头潜在注意力(MLA)和TP,每个GPU沿head_num维度分割kv cache。然而,MLA的kvcache的head_num为1,使其无法分割。因此,每个GPU必须维护一个完整的kvcache → kvcache在每个设备上被复制。当对MLA使用DP(数据并行)时,它按请求分割,不同请求的潜在状态缓存存储在不同的GPU中。例如,由于我们无法分割唯一的KV Cache,我们将数据分成批次并将它们并行化到执行不同任务(预填充、解码)的不同工作器中。在MLA之后,执行all-gather操作,允许每个GPU获取所有序列的hidden_state。然后,在MOE(专家混合)之后,每个GPU使用slice操作提取其对应的序列。

dp_attn.png
提交:
(支持DP注意力的CUDA Graph(https://github.com/sgl-project/sglang/pull/2061),支持多节点DP注意力(https://github.com/sgl-project/sglang/pull/2925),多节点张量并行(https://github.com/sgl-project/sglang/pull/550),支持DP MLA(https://github.com/sgl-project/sglang/pull/1970))
基准测试:
无标志
# 使用分析器环境启动服务器
export SGLANG_TORCH_PROFILER_DIR=/sgl-workspace/profiler_env_folders/ # 可选用于分析
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
# 预填充
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 512 --random-output 1 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
# 解码
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 1 --random-output 512 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000—enable-dp-attention
# 使用分析器环境启动服务器
export SGLANG_TORCH_PROFILER_DIR=/sgl-workspace/profiler_env_folders/
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code --enable-dp-attention
# 预填充
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 512 --random-output 1 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000
# 解码
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 1 --random-output 512 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000结果:

dp-bench
由于它是一个调度器范式,在使用大批量大小时表现更好。否则,添加的开销大于实际的数据并行化。对于较大的批量大小(在这种情况下为10,000),我们看到从端到端延迟到总体吞吐量和并发性的预填充和解码阶段都有整体改进。
支持与DP注意力重叠调度器
相关标志:
--disable-overlap-schedule: # 禁用开销调度器背景:
我们可以将CPU调度与GPU计算重叠。调度器提前运行一个批次并准备下一个批次所需的所有元数据。通过这样做,我们可以让GPU在整个持续时间内保持忙碌,并隐藏昂贵的开销,如radix cache操作。

overlap_scheduler.png
提交:
(更快的重叠调度器(https://github.com/sgl-project/sglang/pull/1738),默认启用重叠(https://github.com/sgl-project/sglang/pull/2067),为triton注意力后端默认启用重叠调度器(https://github.com/sgl-project/sglang/pull/2105))
基准测试:
--disable-overlap-schedule
python3 -m sglang.bench_serving --backend sglang --dataset-name random --random-input 256 --random-output 32 --random-range-ratio 1 --num-prompts 10000 --host 127.0.0.1 --port 30000无标志 → 启用重叠调度器:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 -m sglang.bench_serving --backend sglang --dataset-name random --num-prompts 2500 --random-input-len 1024 --random-output-len 1024 --random-range-ratio 1结果:

fig_overlap
我们看到延迟的普遍减少:端到端(标准:1080152.26s|重叠:1066166.84s),每个输出token的时间(标准:348.10s|重叠:196.79s)和token间延迟(标准:350.62s|重叠:197.96s),尽管第一个token的时间呈现了调度开销的下降结果(标准:724050.93s|重叠:864850.926s)。对于更大的输入和输出请求大小,重叠调度器的效果将更加明显。
FlashInfer预填充和MLA解码
相关标志:
--enable-flashinfer-mla: # 启用FlashInfer MLA优化背景:
使用FlashInfer后端代替triton。
提交:
(为flashinfer mla添加快速解码plan,(https://github.com/sgl-project/sglang/pull/3987) 无权重吸收的MLA预填充(https://github.com/sgl-project/sglang/pull/2349))
基准测试:
无标志:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319Accuracy: 0.951
Latency: 77.397 s
Output throughput: 1809.790 token/s使用--enable-flashinfer-mla
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-V3 --tp 8 --trust-remote-code --enable-flashinfer-mla
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319Accuracy: 0.948
Latency: 71.480 s
Output throughput: 1920.021 token/s结果:

flashinfer_mla png
由于FlashInfer融合操作,我们在相似精度下获得了更低的延迟和更高的输出吞吐量。
FP8
提高FP8的精度
背景:
当值超过给定数值格式(如FP8)的可表示范围时,会发生数值溢出,导致不正确或无限值。在Tensor Core上FP8量化的上下文中,溢出发生是因为FP8具有非常有限的动态范围。为了防止数值溢出,在量化之前使用矩阵的最大元素将值缩小,尽管这使其对异常值敏感。为了避免这种情况,DeepSeek团队提出了分块和分片缩放,其中权重矩阵的每个128×128子矩阵和激活向量的每个1×128子向量分别进行缩放和量化。
NVIDIA H800 Tensor Core上的FP8 GEMM累加限制在约14位精度,这显著低于FP32累加精度。这就是为什么DeepSeek使用CUDA Core的单独FP32累加器寄存器,从而减轻精度损失。反量化缩放因子也应用于这个FP32累加器。

fp8_deepseek.png
提交:
(支持分块fp8矩阵乘法 kernel #3267(https://github.com/sgl-project/sglang/pull/3267),添加分块fp8的单元测试#3156(https://github.com/sgl-project/sglang/pull/3156),集成分块fp8 kernel#3529(https://github.com/sgl-project/sglang/pull/3529),[Track] DeepSeek V3/R1精度(https://github.com/sgl-project/sglang/issues/3486))
基准测试:
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1 --tp 8 --trust-remote-code
python3 benchmark/gsm8k/bench_sglang.py --num-shots 8 --num-questions 1319 --parallel 1319结果:

对于相同的精度(gsm8k上为0.955 vs 0.957),我们观察到更高的输出吞吐量和更低的延迟。
FP8 GEMM调优
背景:
SGLang采用FP8分块量化调优来优化不同GPU的性能。该实现特别针对AMD和CUDA架构对FP8 GEMM(通用矩阵乘法) kernel进行基准测试,测试不同的块形状以基于延迟确定最有效的配置。这种方法确保分块量化与GEMM操作的最佳块大小对齐,在最大化计算效率的同时最小化精度损失。计算在FP8中执行,但累加在BF16中进行以在最终输出存储之前保持数值稳定性。关键函数:
# fn: benchmark_config(A_fp8, B_fp8, As, Bs, block_size, config, out_dtype=torch.float16, num_iters=10)
A: torch.Tensor, # 输入矩阵 (FP8) - 通常是激活
B: torch.Tensor, # 输入矩阵 (FP8) - 通常是权重
As: torch.Tensor, # `A`的每个token组的缩放因子
Bs: torch.Tensor, # `B`的每个块的缩放因子
block_size: List[int], # 量化的块大小 (例如, [128, 128])
config: Dict[str, Any], # kernel配置参数
output_dtype: torch.dtype = torch.float16, # 输出精度
``
`# fn: tune(M, N, K, block_size, out_dtype, search_space):
M,N,K: int # 矩阵乘法的形状 (M × K @ K × N → M × N)
block_size: int # 定义分块量化大小的元组 ([block_n, block_k])
out_dtype: str # 输出精度 (例如, float16, bfloat16)
search_space: List[dict{str,int}] # 要测试的配置列表 (例如, 块大小, warp数量)。
# search_space示例:
{
"BLOCK_SIZE_M": block_m,
"BLOCK_SIZE_N": block_n,
"BLOCK_SIZE_K": block_k,
"GROUP_SIZE_M": group_size,
"num_warps": num_warps,
"num_stages": num_stages,
}提交:
(添加分块fp8调优#3242]https://github.com/sgl-project/sglang/pull/3242))
基准测试:
$python3 benchmark/kernels/quantizationtuning_block_wise_fp8.py结果:
kernel的最佳配置示例:N=512,K=7168,device_name=NVIDIA_H200,dtype=fp8_w8a8,block_shape=[128, 128]
[...]
{
"2048": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 64,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 1,
"num_warps": 4,
"num_stages": 4
},
"3072": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 64,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 1,
"num_warps": 4,
"num_stages": 3
},
"4096": {
"BLOCK_SIZE_M": 64,
"BLOCK_SIZE_N": 128,
"BLOCK_SIZE_K": 128,
"GROUP_SIZE_M": 64,
"num_warps": 4,
"num_stages": 3
}
}对于所有要调优的批量大小和给定的FP8数据类型,给定脚本测试并比较不同的模型权重维度(N和K)以基于最低延迟优化FP8 GEMM分块量化。这为每个批量大小获得块平铺维度(BLOCK_SIZE_M/N/K)、组大小(GROUP_SIZE_M)(用于一起分组的块数量,改善L2缓存使用)、每个线程块(即每个块)的warp数量(num_warps)以及用于将块加载到共享内存作为预取的阶段数量(num_stages)的最优配置。反过来,这实现了不同配置的计算参数的自动调优。
FP8 GEMM CUTLASS实现
背景:
量化操作可以融合到FP8矩阵乘法操作中以提高效率。在sgl-kernel/src/sgl-kernel/csrc/int8_gemm_kernel.cu中,有一个CUDA加速的8位整数(int8)缩放矩阵乘法实现,与W8A8量化融合。
提交:
(支持CUTLASS的w8a8 fp8 kernel #3047(https://github.com/sgl-project/sglang/pull/3047),支持cutlass Int8 gemm #2752(https://github.com/sgl-project/sglang/pull/2752),支持sm90 Int8 gemm#3035(https://github.com/sgl-project/sglang/pull/3035),来自NVIDIA/cutlass的FP8分块缩放 #1932(https://github.com/NVIDIA/cutlass/pull/1932))
基准测试:
root@cluster-h200-02-f2:/sgl-workspace/sglang/sgl-kernel/benchmark# python3 bench_int8_gemm.py结果:

基准测试测量每个批量大小的GB/s(吞吐量的另一种度量)。比较vLLM kernel(int8 gemm)与SGLang kernel,我们为不同配置(N和K)的不同批量大小获得更高的吞吐量。
注意: 我们使用DeepSeek-Coder-V2-Lite-Instruct测试了这个基准,因为DeepSeek-V3的代码尚未在SGLang中实现。
MoE
H200的FusedMoE调优
以下是使用token和专家矩阵的专家混合(MOE)融合计算的实现,使用乘法A @ B(token×专家矩阵乘法)进行top-k路由,并支持:
-
fp16、bfloat16、fp8、int8格式 - 通过
A_scale、B_scale进行权重/激活缩放 - 分块量化
- 通过
expert_ids进行专家路由
背景:
SGLang的自定义融合MoE kernel,使用vLLM作为参考和基准,由以下组成:
tuning_fused_moe_triton.py:用于调优fused_moe_triton kernel的工具。改编自vllm的benchmark_moe.py(https://github.com/vllm-project/vllm/blob/main/benchmarks/kernels/benchmark_moe.py),增加了对各种模型架构的支持。
benchmark_vllm_vs_sglang_fused_moe_triton.py:用于比较vLLM和SGLang实现之间融合MoE kernel性能的工具。支持各种模型架构和数据类型。
benchmark_torch_compile_fused_moe.py:用于对融合MoE kernel与torch.compile和原始融合MoE kernel进行基准测试的工具。
提交:
(为fused_moe添加单元测试(https://github.com/sgl-project/sglang/pull/2416),MoE专家并行实现(https://github.com/sgl-project/sglang/pull/2203),benchmark/kernels/fused_moe_triton/README.md(https://github.com/sgl-project/sglang/tree/main/benchmark/kernels/fused_moe_triton))
基准测试:
$ python3 benchmark/kernels/fused_moe_triton/tuning_fused_moe_triton.py --model deepseek-ai/DeepSeek-V3 --tp-size 8 --dtype fp8_w8a8 --tune
Writing best config to E=256,N=256,device_name=NVIDIA_H200,dtype=fp8_w8a8,block_shape=[128, 128].json...
Tuning took 5267.05 secondsFusedMoE基准测试sgl-kernel vs vllm:
python3 benchmark/kernels/fused_moe_triton/benchmark_vllm_vs_sglang_fused_moe_triton.py
[...]
benchmark sglang_fused_moe_triton with batch_size=505
benchmark vllm_fused_moe_triton with batch_size=506
benchmark sglang_fused_moe_triton with batch_size=506
benchmark vllm_fused_moe_triton with batch_size=507
benchmark sglang_fused_moe_triton with batch_size=507
benchmark vllm_fused_moe_triton with batch_size=508
benchmark sglang_fused_moe_triton with batch_size=508
benchmark vllm_fused_moe_triton with batch_size=509
benchmark sglang_fused_moe_triton with batch_size=509
benchmark vllm_fused_moe_triton with batch_size=510
benchmark sglang_fused_moe_triton with batch_size=510
benchmark vllm_fused_moe_triton with batch_size=511
benchmark sglang_fused_moe_triton with batch_size=511
benchmark vllm_fused_moe_triton with batch_size=512
benchmark sglang_fused_moe_triton with batch_size=512
fused-moe-performance:
[...]
batch_size vllm_fused_moe_triton sglang_fused_moe_triton
505 506.0 1.014688 0.507488
506 507.0 1.011744 0.509344
507 508.0 1.007200 0.504288
508 509.0 1.007232 0.505696
509 510.0 1.007792 0.507712
510 511.0 1.011072 0.507248
511 512.0 1.012992 0.507840结果:
我们对DeepSeek-V3的融合MoE kernel进行了FP8量化调优,获得了每个批量大小的最优配置,类似于调优FP8 GEMM时:
对于块平铺维度(
BLOCK_SIZE_M/N/K),组大小(GROUP_SIZE_M)用于一起分组的块数量,改善L2缓存使用,每个线程块(即每个块)的warp数量(num_warps),以及用于将块加载到共享内存作为预取的阶段数量(num_stages)。

然后我们比较SGLang的融合MoE kernel实现与vLLM的基准实现,获得了一个更精细的版本,在增加批量大小时几乎保持恒定延迟。

fused_moe_latency_comparison.png
作为结束语,本技术博客使用的版本是sglang: v0.4.3.post2, sgl-kernel: 0.0.3.post6, torch: 2.5.1和CUDA: 12.5。我们强烈支持sglang的协作,它作为DeepSeek模型系列的事实上的开源推理引擎。未来的工作计划通过分析关键组件(如FlashMLA kernel、FlashAttention和sglang Triton kernel)的性能和增量改进来进一步探索这些优化。我们还建议探索sglang团队实现的新优化,如预填充和解码阶段的分割以及DeepGemm与FusedMoE的集成。感谢sglang团队的帮助、对本博客的审查以及他们在项目上的联合协作。
参考文献
- sglang kernel测试: https://github.com/sgl-project/sglang/tree/main/sgl-kernel/tests
- sglang kernel基准测试: https://github.com/sgl-project/sglang/tree/main/sgl-kernel/benchmark
- [功能] DeepSeek V3优化 #2591: https://github.com/sgl-project/sglang/issues/2591
- 博客 deepseek v3 10倍效率背后的关键技术: https://dataturbo.medium.com/key-techniques-behind-deepseek-models-10x-efficiency-1-moe-9bd2534987c8
- AI编译器Sglang优化工作: https://carpedm30.notion.site/02-19-2024-2nd-meeting
- lmsys sglang 0.4数据并行: https://lmsys.org/blog/2024-12-04-sglang-v0-4/#data-parallelism-attention-for-deepseek-models
- lmsys sglang 0.4零开销批处理调度器: https://lmsys.org/blog/2024-12-04-sglang-v0-4/#zero-overhead-batch-scheduler
- spaces.ac.cn: MQA, GQA, MLA博客: https://spaces.ac.cn/archives/10091
- 基于树的推测解码论文: https://arxiv.org/pdf/2305.09781
- EAGLE2推测解码论文: https://arxiv.org/pdf/2406.16858
- DeepSeek v3论文: https://arxiv.org/pdf/2412.19437
- 知乎博客: EAGLE: 推测采样需要重新思考特征不确定性: https://zhuanlan.zhihu.com/p/687404563
- 知乎博客: MLA tp和dp: https://zhuanlan.zhihu.com/p/25573883266
- 知乎博客: MLA tp和dp第2部分: https://zhuanlan.zhihu.com/p/15280741714
- Colfax deepseekv3 fp8混合精度训练: https://research.colfax-intl.com/deepseek-r1-and-fp8-mixed-precision-training/
#EAGLE-3
大模型推理无损加速6.5倍!EAGLE-3碾压一切、延续Scaling Law能力
自回归解码已然成为大语言模型的推理标准。大语言模型每次前向计算需要访问它全部的参数,但只能得到一个 token,导致其生成昂贵且缓慢。
近日,EAGLE 团队的新作《EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test》通过一系列优化解锁了投机采样的 Scaling Law 能力,可以将大语言模型的推理速度提高 6.5 倍,同时不改变大语言模型的输出分布,确保无损。同时,随着训练数据的增加,加速比还能进一步提高。
论文标题:EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
arXiv 地址:https://arxiv.org/abs/2503.01840
项目地址:https://github.com/SafeAILab/EAGLE
SGLang 版本:https://github.com/sgl-project/sglang/pull/4247
EAGLE-3 的加速效果(DeepSeek-R1-Distill-LLaMA 8B 在数学推理数据集 GSM8K 上测试,其他模型在多轮对话数据集 MT-bench 上测试):

不同方法的生成速度对比:
,时长00:12
背景
投机采样使用一个小的模型快速生成草稿,一次生成多个 token。目标大语言模型通过一次前向计算并行验证草稿的正确性,输出正确的草稿,并确保无损。EAGLE 系列是投机采样的最快实现。
EAGLE-1 在更有规律的特征层面而不是 token 层面进行自回归,同时输入采样结果(超前一个时间步的 token)消除了不确定性,明显提升了草稿模型的准确率。EAGLE-2 利用草稿模型的置信度近似接受率,据此动态地调整草稿树的结构,进一步提升了投机采样的效率。
之前已经报道了 EAGLE-1 和 EAGLE-2 的工作:
- EAGLE-1:大模型推理效率无损提升3倍,滑铁卢大学、北京大学等机构发布EAGLE
- EAGLE-2:无损加速最高5x,EAGLE-2让RTX 3060的生成速度超过A100
最新的大模型通过使用越来越多的训练数据以取得更好的性能。比如说,对于 LLaMA 系列 7B(8B)大小的模型,LLaMA 1、LLaMA 2 和 LLaMA 3 分别使用了 1T、2T、15T token 训练数据,模型结构和推理成本基本不变的前提下各项指标取得了明显提升。
EAGLE-3 的作者们希望通过增加草稿模型的训练数据量以提高接受率和加速比(蓝色曲线)。遗憾的是, EAGLE-1 从训练数据增加中得到的提升非常有限(红色曲线)。
EAGLE-1 和 EAGLE-3 的加速比随着训练数据的增加而变化的趋势:

动机
EAGLE 在特征层进行自回归,再使用目标模型的分类头得到草稿 token。这种方式利用了目标模型的中间结果和信息,相比 token 层自回归有更好的性能。因为草稿模型的最终任务是预测草稿 token,EAGLE 的损失函数包括两部分,一部分是特征预测损失,另一部分是 token 预测损失。特征预测损失也可以被认为是一种约束,限制了模型的表达能力。
EAGLE-3 的作者们进行了实验验证,观察第一个草稿 token 的接受率 0-α,在数据集较小时,特征预测损失在训练数据较少时可以提高性能,但严重损害了草稿模型的 scaling up 能力。

不过,不使用特征预测损失会导致生成后续草稿 token 时的输入偏离训练分布,导致第二个草稿 token 的接受率 1-α 严重下降。为了解决这一问题,EAGLE-3 使用 “训练时测试” 模拟多步生成,从而兼顾了模型的 scaling up 能力和生成多个草稿 token 的能力。

EAGLE、Medusa 等投机采样方法都重用目标模型的最后一层特征作为草稿模型的提示,但 EAGLE-3 的作者们发现这存在缺陷。大语言模型的最后一层特征经过线性变换就能得到下一个 token 的分布。对于满秩的分类头,最后一层特征和下一个 token 的分布一一对应。最后一层特征只有下一个 token 的信息,失去了目标模型的全局性质。
因此,EAGLE-3 不再使用目标模型的最后一层特征作为辅助信息,而是混合目标模型的低层、中层、高层信息来作为草稿模型的输入。
方法
与其他投机采样方法一致,EAGLE-3 交替执行草稿阶段和验证阶段。
草稿阶段以下图为例。在预填充或者上一个验证阶段,EAGLE-3 记录模型的低、中、高层特征序列,分别记为 l、m 和 h,拼接 k 维向量 l、m 和 h 得到 3k 维向量,然后通过一个全连接层将其降维到 k 维,就得到融合了不同层级信息的特征 g,其中 k 为目标模型的隐藏层维度。目标是生成以 “How can I” 为前缀的草稿 token 序列,只输入 g_how 和 g_can,草稿模型无法感知随机的采样过程。
因此 EAGLE-3 引入采样结果 I 的词向量嵌入 e_I。将 g 与对应的超前一个时间步的嵌入 e 拼接,即 g_how 与 e_can 拼接,g_can 和 e_I 拼接。将拼接后的向量通过全连接层降到 k 维,并将其输入进一个单层的 transformer 得到 a。然后,将 a 输入分类头,采样得到第一个草稿 token “do”。
在 step 1,以 “How can” 为前缀时,EAGLE-3 重用了来自目标模型的 g_how 和 g_can。
在 step 2,前缀是 “How can I”。理想的方式是重用来自目标模型的 g_how、g_can 和 g_I。但这是不可能的,因为 token “I” 还没有被目标模型检查,无法获取 g_I。EAGLE-3 用上一个 step 草稿模型的输出 a_I 替代 g_I,拼接 a_I 与采样结果 “do” 的词向量嵌入作为草稿模型 step2 的输入。
在 step 3,同样无法获得 g_do,所以使用 a_do 代替,拼接 a_do 与 e_it 作为草稿模型的输入。之后的 step 同理。

实验
EAGLE-3 在多轮对话、代码、数学推理、指令遵循、总结五项任务上分别使用 MT-bench、Humaneval、GSM8K、Alpaca、CNN/DM 数据集进行了实验,并与 7 种先进的投机采样方法(SpS、PLD、Medusa、Lookahead、Hydra、EAGLE、EAGLE-2)进行了比较。
该实验分别在 Vicuna (V), LLaMA-Instruct 3.1 (L31), LLaMA-Instruct 3.3 (L33), DeepSeek-R1-Distill-LLaMA (DSL) 上进行。

表格中的 Speedup 为加速比,τ 为平均接受长度,也就是目标模型每次前向计算能生成的 token 数。EAGLE-3 每次前向计算能生成大约 4-7 个 token,而自回归解码每次生成 1 个 token,因此 EAGLE-3 明显加速了大语言模型的生成,加速比为 3.1x-6.5x。
在所有任务和模型上,EAGLE-3 的加速比和平均接受长度都是最高的,明显优于其他方法。
应用
EAGLE-3 发布第一天就被集成到 SGLang 中。在生产级框架中,EAGLE-3 也有数倍加速效果。以下实验由 SGLang 团队提供并以 LLaMA 3.1 8B(batch size=1, 1x H100)为例。

投机采样往往被认为在大 batch size 下会降低吞吐量。但是在 SGLang 这一生产级框架下,EAGLE-3 在 batch size 为 64 时仍可以提高 38% 的吞吐量,而 EAGLE 在 batch size 为 24 时就导致吞吐量下降。这里 1.00x 以 SGLang (w/o speculative) 的吞吐量作为基准。以下实验由 SGLang 团队提供并以 LLaMA 3.1 8B(1x H100)为例。

作者介绍
李堉晖:北京大学智能学院硕士,滑铁卢大学访问学者,受张弘扬老师和张超老师指导,研究方向为大模型加速和对齐。
魏芳芸:微软亚研院研究员,研究方向为具身智能、图像生成和 AI agents。
张超:北京大学智能学院研究员,研究方向为计算机视觉和大模型加速。
张弘扬:滑铁卢大学计算机学院、向量研究院助理教授,研究方向为大模型推理加速、AI 安全和世界模型。
#因研发FPGA工具,丛京生院士获得ACM计算突破奖
今天凌晨,国际计算机学会(ACM)宣布了今年的 ACM 计算突破奖获奖者。丛京生(Jason Cong)「因其在现场可编程系统和可定制计算的设计和自动化方面做出的奠基性贡献而获奖」。
ACM 计算突破奖,全名为 ACM Charles P. “Chuck” Thacker Breakthrough in Computing Award(ACM 查尔斯・帕特里克・萨克尔计算机突破奖),旨在表彰那些对计算理念或技术做出惊人、颠覆性或跨越式贡献的个人或团体。该奖项还附带由微软资助的 10 万美元奖金。
微软首席科学官 Eric Horvitz 表示:「丛京生在可定制计算和架构设计工具方面的开创性方法,体现了该奖项旨在表彰的『跨越式进步』。他的工作至今仍至关重要,为高度灵活且节能的 FPGA 架构奠定了基础,而这对于人工智能、云计算和其他快速发展领域的前沿应用而言都非常重要。」
丛京生对 FPGA 发展贡献巨大
丛京生,1963 年 2 月 20 日出生于北京市。于 1985 年从北京大学计算机科学与技术系毕业,之后赴美国留学;并于 1987 年和 1990 年分别获得美国伊利诺大学香宾校区计算机科学系硕士和博士学位,之后进入加州大学洛杉矶分校工作。
丛京生现在是加州大学洛杉矶分校 Samueli 工程学院 Volgenau 卓越工程主席。他的研究领域包括 VLSI 电路和系统的设计自动化、可定制计算、量子计算和高度可扩展的算法。他发表了 500 多篇研究论文,领导了 100 多个研究项目,并获得了多项专利。
在获得 ACM 计算突破奖之前,他已经获得了多项荣誉,包括菲尔・考夫曼奖、IEEE 罗伯特・N・诺伊斯奖章、 ACM/IEEE A・理查德・牛顿电子设计自动化技术影响力奖等。他也是 ACM 和 IEEE 会士,同时也是美国艺术与科学学院和美国国家工程院院士以及中国工程院外籍院士。
丛京生在其学术界和工业界的职业生涯中开发了一系列用于自动化集成电路设计的卓越工具,尤其是用于现场可编程门阵列(FPGA)的工具。
FPGA 是一种特殊的集成电路,可以在制造后进行编程,进而更改其功能,这使得它们成为许多应用的标准硬件的一部分,被用于数据中心、电信、航空航天、国防和汽车工程等许多领域。
虽然 FPGA 是可编程的,但为其创建配置文件却很复杂,用户难以完成。丛京生在其职业生涯的大部分时间里都在开发用于解决这个问题的工具。例如,他的工作让人们现在可以使用 C 或 C++ 等软件编程语言对 FPGA 进行编程,从而显著提高了 FPGA 的可访问性和可用性。除了设计基本算法外,丛京生和他的学生还创造了嵌入这些算法的商业工具,进而支持了当今使用的 FPGA 设计工具。
在 1990 年代末,丛京生研究了如何将逻辑映射到查找表(FPGA 的基石)。这个问题非常难 —— 起初都是采用启发式方法解决的。
丛京生及其学生们取得了重大的理论突破。他们证明这个问题可以在多项式时间内精确求解。这一发现催生了商业化这项技术的 Aplus Design Automation—— 如今它已被应用于所有 FPGA 综合工具。
虽然丛京生的早期工作使设计人员能够使用 Verilog 等硬件描述语言来设计 FPGA,但软件应用工程师仍然难以编写这些电路。
21 世纪初,丛京生的团队开始研究高级综合技术,使人们能够使用 C/C++ 编程 FPGA。这一成功尝试催生了 AutoESL—— 这是他在加州大学洛杉矶分校领导的实验室的衍生产品,已于 2011 年被赛灵思公司(现为超微半导体公司的一部分)收购。 之后,他们基于 AutoESL 技术开发了一款商业产品 AutoPilot,这正是 AMD/Xilinx 目前高级综合工具的基础。
在开发这些工具后,丛京生将其应用于可定制的特定于具体领域的计算领域。他和他的团队利用 FPGA 设计了一系列特定于具体领域的硬件加速器,涵盖深度学习、医学图像处理、基因组测序、数据压缩、可满足性求解以及许多其他计算密集型任务。这些定制计算解决方案有一个重要优势:与传统的基于 CPU 的计算方法相比,它们有显著的能效优势。
参考链接

















 1002
1002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









