







我自己的原文哦~ https://blog.51cto.com/whaosoft/12830632
#MIT教授NeurIPS演讲
公开歧视中国学生,大会官方认错、本人道歉
正在加拿大温哥华举办的人工智能顶会 NeurIPS,竟然有学者在演讲中公开发表对中国学者的歧视言论。
「我这样做是为了让我的论文结果看上去更好,我的学校里没有人教我们道德或价值观。—— 现在已被顶尖大学开除的中国留学生的借口。注:我认识的大多数中国人都是诚实正直的。」这是一张 Keynote 演讲 PPT 上的原话。

事情是这样的:
MIT 教授 Rosalind W. Picard 受邀登台进行演讲,主题是《如何优化最重要的事情》:

但在演讲的最后部分,她提到了一些关于诚信的建议:
如果你看到了什么,就说出什么。如果你看到什么不好的行为,就把那个人拉到一边说:「嘿,看,这就是怎么做才是正确的?」
最近,我了解到一个案例,一个非常出众的学生因为一些行为被开除了,而这个学生试图用「我的学校没有人教我们道德或价值观」来为自己辩解。这个学生来自一所非常知名的中国学校,我很震惊他们认为这是正当的行为。我希望这是一个例外,如果他们说这是那里的普遍现象,我就不会这样引述了,但我想说清楚,如果你们之中有人来自这样的学校,你们没有听说过这种情况,我想这可能是社会的新一代认为这种行为是不诚实的,无论你们的学校是否教过你们。
很显然,我们使用这些生成的东西来制作各种很酷的东西,甚至改进训练集,但我们必须划清界限,在社区里我们能容忍的是什么,我们必须教育人们更好地了解这一点。我们都想在职业生涯中优化自己的简历,但要是有限制的优化、正确的优化。不要让你的诚信度降低,你的诚信比你简历上任何令人印象深刻的东西都重要,所以当你优化你的生活、简历或其他东西时,要确保它是有限制的优化。
然后,一位中国女生在问答环节勇敢指出:「在整个演讲过程中,我注意到只有一张幻灯片你明确提到了研究人员的国籍,那就是关于中国学生的,但你也写道,你遇到的大多数中国学生都是诚实守信的。你注意到,有一两个坏人的国籍特别引起你的注意,因为你还提到了其他一些不好的做法,但他们没有提到国籍。」
教授回复道:「让我澄清一下,那不是基于我的判断,而是基于学生的引述,说学校没有教这个,这意味着它适用于很多来自那里的人,我没有亲自看到那个,我写下了我所看到的,即我合作过的所有中国人实际上都非常棒,我提到的那个是例外。也许有一个,也许它们很常见,谁知道呢。我希望这只是一个异常值。」
中国女生继续表示:「是的,感谢你的澄清,我认为这也可能表明这些学生是正直和诚实的,所以他们给了你这个反馈,但我个人作为一个中国人,觉得这有点冒犯,因为这是唯一一处你明确提到国籍的地方,尽管你提到了很多不好的做法,我认为我们在社区外保持良好声誉很重要,但在社区内我们也提高了对无意识偏见和可能的种族主义问题的认识,我希望将来如果你再次展示这个,可以删除那个国籍标注,因为这对这个特定群体来说似乎不公平。」
教授表示:「非常感谢你提出这个问题,我会采纳你的建议把它删掉。」
完整对话内容在此:
,时长04:39
NeurIPS 官方回应的速度是很快的,虽然没有给出任何结论:

随后,Rosalind W. Picard 本人在 MIT Media Lab 的官网发表了道歉声明:
在 NeurIPS 的主题演讲中,我分享了一个故事,其中提到了国籍 —— 我很后悔提到了这个细节。我认为这是不必要的,与我的观点无关,并且造成了意想不到的负面联想。我为此道歉,并对此事造成的困扰感到非常抱歉。我从这次经历中吸取了教训,我欢迎大家提出如何弥补社区过错的想法。
我坚信,生成式人工智能提出的实际和伦理问题影响着我们所有人。我希望我们能够跨越国家和文化界限,共同解决这些问题。

图源:https://media.mit.edu/posts/neurips-apology-moving-forward/
网友热议
消息从会议上传出后,引起了很多领域内研究者和网友的讨论。我们尝试梳理了几个有代表性的观点。
一些来自中国的研究者明确指出了此番言论的不当之处:





有人表示:为何在举例时加入国籍信息,然后又要注明国籍不代表什么?如果真的无关紧要,为什么要单独提出来?还是说演讲者认为是有相关性的,那么她本人就需要解释一下原因了。

更好的说法应该是:「一位学生」。

当然,我们也可以看到另外一些维度的观点:


那么,这位 NeurIPS 请来的 Keynote 嘉宾,Rosalind Picard 到底是何许人也呢?打开她的主页,附有一份长达 77 页的简历。
在个人主页上,她将自己定位为科学家、发明家、工程师、麻省理工学院教授。Rosalind Picard 是麻省理工学院媒体实验室的教授。她在 1990 年代提出了「情感计算」这个概念,认为计算机应该能够理解和回应人类的情感。

她的研究团队开发了多种可穿戴设备,能够监测人体的生理数据。这些设备现在被广泛应用在医疗领域,比如可以帮助检测癫痫发作、监测自闭症患者的情绪变化,辅助研究抑郁症、创伤后应激障碍等疾病。她在这些领域获得了 100 多项专利。基于这些研究成果,她创办了两家公司:Empatica 与 Affectiva,分别专注于开发检测癫痫的智能可穿戴设备与读懂人类情绪的人工智能技术。
各位读者如何看待呢?欢迎在评论区讨论。
参考链接:https://www.reddit.com/r/MachineLearning/comments/1hdxbru/d_what_happened_at_neurips/
#OXY2DEV
高中生手机写出2.5万行代码的热门项目,GitHub 1900星,网友:给孩子捐个电脑
「强者」小孩哥:其实我是要学医的。
最近,有一个 GitHub 开源项目引发了众人的关注。
这是一个名叫 markview.nvim 的插件,作为高度定制化的 Neovim markdown 预览器,Star 量已有 1900 个。
乍看起来似乎有点平平无奇,炸裂的是它的研发背景:全部 2.5 万行代码竟然都是作者用手机敲出来的。

手机敲代码?兄弟你太猛了,能出来让大家认识认识吗?
图中对话出现在一个 issue 里面(已解决了),项目作者 OXY2DEV 说自己没法在手机上正确的测试,Reddit 帖子的楼主说那我来吧。楼主转念一想,问道:不是哥们,这是临时不方便,还是你在告诉我,你已经在一部手机上完整开发了这个插件,我怎么感觉是后者?
如果是这样,我也必须加把劲了,这是一种什么层次的奉献精神啊!
OXY2DEV 答道:不好意思,全部 24461 行(如果只算代码的话大约 18K 行)都是手机打字完成的。他还谦虚了一下,说其中约 6000 行仅用于存储数学符号、数学字体、HTML 实体等。

做项目这么大的决心,不禁让人感叹。
现在,OXY2DEV 开发的「markview.nvim」项目星标量已经达到 1.9K:

- 项目地址:https://github.com/OXY2DEV/markview.nvim
这是一个基于热门编辑器 neovim 的插件,包含 Markdown 渲染器、HTML 渲染器、LaTeX 渲染器。
回到那个 Reddit 帖子,消息一出,网友们纷纷表示震惊,直呼想要给他送个电脑。

网友:绷不住了,谁来送他个笔记本电脑吧?要不我们发动一场募捐?
发帖人在 Reddit 上 cue 了 OXY2DEV:「希望你不会对这个提议感到不快,这是你感兴趣的事情吗?」
对方(在 Reddit 上的网名是 Exciting_Majesty2005)回复道:那可太谢谢了,然而在没有银行卡的情况下,我没法把你们捐的美元转换成本国货币。我还没有身份证,所以我不能开设自己的账户。数字支付这里也是没有的。
除了这些问题之外,我所在的地方硬件价格过高(毕竟第三世界国家)。所以,你们最终会为普通硬件花费过高价格。
此外,如果我设法进入了一所好大学,那么我显然会买一台笔记本电脑。只是现在还没有而已。
所以,真的没有必要为此筹集资金。
网友们惊掉了下巴:什么你说你还没上大学?
有人问:那你什么时候申请大学?如果你已经在开发流行的插件,我想北美、欧洲的大多数计算机科学系都会很高兴给 offer。也许,用户社区可以写一封推荐信?

OXY2DE 回复道,大学申请应该是在明年 3 月。我将首先参加医学院考试,如果我没有通过,那么我就会上大学。在这里,尝试获得计算机科学专业的 offer 是一种赌博,分数太高或是太低都没戏。总之事情很复杂。
看起来想要帮助这位新星开发者,网友们还面临着一些挑战,不过在后续的讨论中渐渐有了眉目。
另外对于用手机编程这一做法,有很多人感到好奇。不过,OXY2DE 并不是唯一一个选择这样做的。有网友分享了自己在手机上的编程经验,这位网友表示自己曾经在 Termux ( 一款基于 Android 平台的开源 Linux 终端模拟器)上使用 ACode 或 NeoVim 来编写程序,并且使用 Termux 和 NeoVim 可以获得 PyDroid 提供的所有功能,而无需每月订阅。

还有网友好奇在手机上敲代码会不会经常出现拼写错误。OXY2DE 表示「他的准确率大约为 60-70%,但由于使用了具有补全能力的 nvim-cmp,所以也可以使用它来修复拼写错误。此外,编程语言的所有关键字都是非常通用的词,因此随着时间的推移,拼写错误会越来越少。」

还有网友建议将蓝牙键盘连接到 Android 设备上进行编程,这样效果也不错,该网友还推荐了一款名为 iClever BK-05 的蓝牙键盘,不用时可以折叠起来,非常方便。
对此,OXY2DE 表示有些文件非常庞大,很容易让 Neovim 变得缓慢。因此他不得不禁用 LSP、自动补全、Tree-sitter 和语法高亮,只是为了让它不卡顿。在某种程度上,无法绕过硬件的限制。

还有人感慨道:如今 99.99% 的人都依赖先进的工具来完成工作,而这位学生却在用手机做着这些事情。难以置信,简直太疯狂了。

「不知那些需要机械键盘才能敲代码的人感想如何?」

markview.nvim 项目作者 OXY2DEV 的真名是 Mouinul Hossain,是一名来自孟加拉国的高中生,自称喜欢编程和电子设备。他在空闲时间制作 Neovim 插件,有时还会制作一些基本的网站。
OXY2DEV 小小年纪就有了使用 Lua、C、Javascript 和 Sass 语言的经验。此外,他还有一些使用 Bash 的经验。不过可能是因为生活条件有限,或是其他什么原因:他表示自己现在只有智能手机、没有电脑,所以是在 neovim 跟 Termux 中完成这所有工作的。
看起来,OXY2DEV 在努力为开源社区做出贡献的同时,开源社区也在回报他。在 Reddit 帖子里甚至有人推荐他来申请新加坡国立大学,这让一直以来想要学医的他有了更多的思考。
几天前,OXY2DEV 终于决定开启一个募捐项目。「根据其他人的建议,我决定捐款买一台笔记本电脑。」

据说他在 10 个小时内就筹集到了 2300 美元。
这就是开源社区的力量。
参考内容:
https://www.reddit.com/r/neovim/comments/1h7vhmg/bro_been_developing_his_2k_star_plugin_on_a/
https://www.reddit.com/r/neovim/comments/1hb5szp/please_help_me_raise_funds_for_a_laptop/
https://github.com/OXY2DEV/markview.nvim
#Towards Explainable and Interpretable Multimodal Large Language Models
决策过程是魔法还是科学?首个多模态大模型的可解释性综述全面深度剖析
本文由香港科技大学(广州)、上海人工智能实验室、中国人民大学及南洋理工大学联合完成。主要作者包括香港科技大学(广州)研究助理党运楷、黄楷宸、霍家灏(共同一作)、博士生严一博、访学博士生黄思睿、上海AI Lab青年研究员刘东瑞等,通讯作者胡旭明为香港科技大学/香港科技大学(广州)助理教授,研究方向为可信大模型、多模态大模型等。
本文介绍了首个多模态大模型(MLLM)可解释性综述,由香港科技大学(广州)、上海人工智能实验室、以及中国人民大学联合发布。文章系统梳理了多模态大模型可解释性的研究进展,从数据层面(输入输出、数据集、更多模态)、模型层面(词元、特征、神经元、网络各层及结构)、以及训练与推理过程三个维度进行了全面阐述。同时,深入分析了当前研究所面临的核心挑战,并展望了未来的发展方向。本文旨在揭示多模态大模型决策逻辑的透明性与可信度,助力读者把握这一领域的最新前沿动态。
- 论文名称:Towards Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
- 论文链接:https://arxiv.org/pdf/2412.02104
多模态大模型可解释性
近年来,人工智能(AI)的迅猛发展深刻地改变了各个领域。其中,最具影响力的进步之一是大型语言模型(LLM)的出现,这些模型在文本生成、翻译和对话等自然语言任务中展现出了卓越的理解和生成能力。与此同时,计算机视觉(CV)的进步使得系统能够高效地处理和解析复杂的视觉数据,推动了目标检测、动作识别和语义分割等任务的高精度实现。这些技术的融合激发了人们对多模态 AI 的兴趣。多模态 AI 旨在整合文本、视觉、音频和视频等多种模态,提供更丰富、更全面的理解能力。通过整合多种数据源,多模态大模型在图文生成、视觉问答、跨模态检索和视频理解等多模态任务中展现了先进的理解、推理和生成能力。同时,多模态大模型已在自然语言处理、计算机视觉、视频分析、自动驾驶、医疗影像和机器人等领域得到了广泛应用。
然而,随着多模态大模型的不断发展,一个关键挑战浮现:如何解读多模态大模型的决策过程?
多模态大模型(MLLMs)的飞速发展引发了研究者和产业界对其透明性与可信度的强烈关注。理解和解释这些模型的内部机制,不仅关系到学术研究的深入推进,也直接影响其实际应用的可靠性与安全性。本综述聚焦于多模态大模型的可解释性,从以下三个关键维度展开深入分析:
1. 数据的解释性:数据作为模型的输入,是模型决策的基础。本部分探讨不同模态的输入数据如何预处理、对齐和表示,并研究通过扩展数据集与模态来增强模型的可解释性,增强对模型决策的理解。
2. 模型的解释性:本部分分析模型的关键组成部分,包括词元、特征、神经元、网络层次以及整体网络结构,试图揭示这些组件在模型决策中的具体作用,从而为模型的透明性提供新的视角。
3. 训练与推理的解释性:本部分探讨模型的训练和推理过程可能影响可解释性的因素,旨在理解模型的训练和推理过程背后的逻辑。

多模态大模型可解释性文章汇总

我们将现有的方法分类为三个视角:数据(Data)、模型(Model)和训练及推理(Traning & Inference)。具体如下:
1、数据视角的可解释性:从输入(Input)和输出(Output)角度出发,研究不同数据集(Benchmark)和更多模态的应用(Application),探讨如何影响模型的行为与决策透明性。
2、模型视角的可解释性:我们深入分析了模型内部的关键组成部分,重点关注以下五个维度:
- Token:研究视觉词元(Visual Token)或视觉文本词元(Visual-textual Token)对模型决策的影响,揭示其在多模态交互中的作用。
- Embedding:评估多模态嵌入 (Visual Embedding, Textual Embedding, Cross-modal Embedding) 如何在模型中进行信息融合,并影响决策透明度。
- Neuron:分析个体神经元(Indvidual Units)和神经元组 (Specialization Group) 对模型输出的贡献。
- Layer:探讨单个网络层(Individual Components)和不同网络层(Decision-Making Workflow)在模型决策过程中的作用。
- Architecture:通过对网络结构分析(Architecture Analysis)和网络结构设计(Architecture Design),促进模型架构的透明度和可理解性。
3、训练与推理的可解释性:我们从训练和推理两个阶段研究多模态大模型的可解释性:
- 训练阶段:总结多模态大模型预训练机制或训练策略,重点讨论如何增强多模态对齐、减少幻觉现象,对提高模型可解释性。
- 推理阶段:研究无需重新训练的情况下,缓解幻觉等问题的方法,如过度信任惩罚机制和链式思维推理技术,以提升模型在推理阶段的透明性和鲁棒性。
解码多模态大模型
从词元到网络结构的可解释性全面剖析
词元与嵌入(Token and Embedding) 的可解释性:词元(Token)和嵌入(Embedding)作为模型处理和表示数据的关键单元,对于模型的可解释性具有重要意义。
- 词元研究:我们通过分析视觉词元 (Visual Token),揭示了模型如何将图像分解为基本视觉组件,从而理解单个词元对预测的影响。同时,通过探索视觉 - 文本词元 (Visual-Textual Token) 的对齐机制,揭示其在复杂任务(如视觉问答、活动识别)中的影响。
- 嵌入研究:在特征嵌入 (Embedding) 方面,研究聚焦于多模态特征的表示方式,旨在提升模型的透明度和可解释性。例如,通过生成稀疏、可解释的向量,捕捉多模态的语义信息,进一步揭示特征嵌入在多模态对齐中的作用。


神经元 (Neuron) 的可解释性:神经元是多模态大模型的核心组件,其功能和语义角色的研究对揭示模型内部机制至关重要。
- 单个神经元的研究:对于单个神经元,一些研究通过将单个神经元与特定的概念或功能关联起来,发现能够同时响应视觉和文本概念的神经元,为理解多模态信息整合提供新的视角。
- 神经元群体的研究:对于神经元群体,研究表明某些神经元组可以集体负责特定任务,例如检测图像中的曲线、识别高低频特征,或在语言模型中调节预测的不确定性。此外,在多模态任务中,神经元群体被用来连接文本和图像特征,提出了新的方法来检测跨模态神经元,为多模态信息处理的透明化提供了重要依据。

层级结构 (Layer) 的可解释性:深度神经网络由多个层级组成,层级结构的研究揭示了各层在模型决策过程中的作用。
- 单个层的研究:研究者探索了注意力头(Attention Heads)、多层感知器(MLP)等层内组件对于模型决策的影响。
- 跨层研究:对跨层的整体决策过程进行分析,增强跨模态信息的整合能力。

网络结构(Architecture)的可解释性:除了在神经元和层级层面探讨多模态大模型的可解释性外,一些研究还从更粗粒度的网络结构层面进行探索。与之前聚焦于 MLLMs 具体组件的方法不同,这里从整体网络结构视角出发,研究分为网络结构分析与设计两大类:
1、网络结构分析:这种方法独立于任何特定的模型结构或内部机制,包括:
- 特征归因:通过为特征分配重要性分数,提供基础性解释方法,。
- 单模态解释:提供单一模态(主要是图像模态)的解释。
- 多模态解释:提供多模态(如图像和文本结合)的解释。
- 交互式解释:根据人类的指令或偏好提供解释的方法。
- 其他:包括通过模型比较提供探究的网络结构级模型分析方法等。
2、网络结构设计:这类方法通过在模型网络结构中引入高度可解释的模块来增强模型的可解释性。专注于特定的模型类型,利用独特的结构或参数来探索内部机制。这一类包括:
- 替代模型:使用更简单的模型,如线性模型或决策树,来近似复杂模型的性能。
- 基于概念的方法:使模型能够学习人类可理解的概念,然后使用这些概念进行预测。
- 基于因果的方法:在网络结构设计中融入因果学习的概念,如因果推理或因果框架。
- 其他:包括网络结构中无法归类到上述类别的其他模块相关的方法。




训练和推理(Training & Inference)的可解释性:在多模态大模型(MLLMs)的训练与推理中,通过优化策略提升模型的透明性:
- 训练阶段:通过合理的预训练策略优化多模态对齐,揭示跨模态关系,同时减少生成过程中的偏差与幻觉现象,为模型鲁棒性提供支持。
- 推理阶段:链式思维推理和上下文学习技术为实现结构化、可解释的输出提供了新的可能性。这些方法有效缓解了模型在生成内容中的幻觉问题,有效提升了模型输出的可信度。
挑战与机遇并存
多模态大模型的可解释性未来展望?
随着多模态大模型(MLLMs)在学术与工业界的广泛应用,可解释性领域迎来了机遇与挑战并存的未来发展方向。以下是我们列出一些未来的展望:
- 数据集与更多模态的融合:改进多模态数据的表示和基准测试,开发标准化的预处理和标注流程,确保文本、图像、视频和音频的一致性表达。同时,建立多领域、多语言、多模态的评估标准,全面测试模型的能力。
- 多模态嵌入与特征表示:加强对模型预测结果的归因,探索动态词元重要性机制,确保结果与人类表达方式一致。通过优化视觉与文本特征的对齐,构建统一框架,揭示模型处理多模态信息的内在机制。
- 模型结构的可解释性:聚焦神经元间的对齐机制和低成本的模型编辑方法,解析多模态信息处理中的关键内部机制。同时,探索视觉、音频等模态向文本嵌入空间对齐的过程,为跨模态理解提供支持。
- 模型架构的透明化:改进架构设计,深入分析不同模块在跨模态信息处理中的作用,揭示从模态输入到集成表示的全流程信息流动。这将提升模型的鲁棒性与信任度,并为实际应用提供更可靠的支持。
- 训练与推理的统一解释框架:在训练阶段优先考虑可解释性和与人类理解的对齐,推理阶段提供实时、任务适配的可解释结果。通过建立覆盖训练与推理的统一评估基准,开发出透明、可靠且高性能的多模态系统。
未来的研究不仅需要从技术层面推动多模态大模型的可解释性,还需注重其在人类交互和实际应用中的落地,为模型的透明性、可信性、鲁棒性和公平性提供坚实保障。
#Ilya宣判:预训练即将终结
Pre-training as we know it will end.
继李飞飞、Bengio、何恺明之后,在刚刚的NeurIPS 2024中,Ilya Sutskever最新演讲也来了。虽然时长仅有15分钟左右,但内容依旧看头十足。例如这一句:
Pre-training as we know it will end.
我们所熟知的预训练即将终结。
而之于未来,Ilya还预测道:
what comes next is superintelligence: agentic, reasons, understands and is self aware.
接下来将是超级智能:代理、推理、理解和自我意识。
那么为何会有如此?我们一起来看看完整演讲。
回顾十年技术发展
Ilya先是用一张十年前的PPT截图开启了这次演讲,那时候深度学习还处于探索阶段。
在2014年的蒙特利尔,他和团队(还有Oriol Vinyals和Quoc Le)首次提出了如今成为AI领域基石的深度学习理念。
Ilya展示了当时的一张PPT,揭示了他和团队的核心工作:自回归模型、大型神经网络和大数据集的结合。
在十年前,这些元素并不被广泛看作成功的保证,而今天,它们已经成为人工智能领域最重要的基础。
例如在谈到深度学习假设时,Ilya强调了一个重要观点:
如果有一个10层的大型神经网络,它就能在一秒钟内完成人类能做的任何事情。
他解释说,深度学习的核心假设是人工神经元与生物神经元的相似性。
基于这一假设,如果人类能够在0.1秒钟内完成某项任务,那么同样的任务,一个训练良好的10层神经网络也能完成。
这一假设推动了深度学习的研究,并最终实现了当时看似大胆的目标。
Ilya还介绍了自回归模型的核心思想:通过训练模型预测序列中的下一个token,当模型预测得足够准确时,它就能捕捉到整个序列的正确分布。
这一思想为后来的语言模型奠定了基础,特别是在自然语言处理领域的应用。
当然除了“押对宝”的技术之外,也有“押错”的。
LSTM(长短期记忆网络)就是其中之一。
Ilya提到LSTM是深度学习研究者在Transformer之前的主要技术之一。
尽管LSTM在当时为神经网络提供了强大的能力,但它的复杂性和局限性也显而易见。
另一个便是并行化(parallelization)。
尽管现在我们知道pipeline并不是一个好主意,但当时他们通过在每个GPU上运行一层网络,实现了3.5倍的速度提升。
Ilya认为,规模假设(scaling hypothesis)是深度学习成功的关键。
这一假设表明,如果你有一个非常大的数据集,并训练一个足够大的神经网络,那么成功几乎是可以预见的。
这个观点已经成为今天深度学习领域的核心法则。
Ilya进一步阐述了连接主义的思想,认为人工神经元与生物神经元之间的相似性给了我们信心,认为即使不完全模仿人脑的结构,巨大的神经网络也能完成与人类相似的任务。
预训练时代即将结束
基于上述技术的发展,也让我们迎来了预训练的时代。
预训练是推动所有进步的动力,包括大型神经网络和大规模数据集。
但Ilya接下来预测说:
虽然计算能力在不断增长,硬件和算法的进步使得神经网络的训练效率得到了提升,但数据的增长却已接近瓶颈。
他认为,数据是AI的化石燃料,随着全球数据的限制,未来人工智能将面临数据瓶颈。
虽然当前我们仍然可以使用现有数据进行有效训练,但Ilya认为这一增长趋势终将放缓,预训练的时代也会逐步结束。
超级智能将是未来
在谈到未来的发展方向时,Ilya提到了“Agent”和“合成数据”的概念。
许多专家都在讨论这些话题,认为Agent系统和合成数据将是突破预训练瓶颈的关键。
Agent系统指的是能够自主推理和决策的人工智能,而合成数据则可以通过模拟环境创造新的数据,弥补现实世界数据的不足。
Ilya还引用了一个生物学上的例子,展示了哺乳动物身体与大脑大小的关系,暗示不同生物可能通过不同的“规模法则”进化出不同的智能表现。
这一思想为深度学习领域的进一步扩展提供了启示,表明人工智能也许可以通过不同的方式突破目前的规模限制。
Ilya最后谈到了超级智能的前景。他指出,虽然当前的语言模型和AI系统
在某些任务上表现出超人类的能力,但它们在推理时仍显得不稳定和不可预测。
推理越多,系统变得越不可预测,这一点在一些复杂任务中表现得尤为突出。
他还提到:
目前的AI系统还不能真正理解和推理,虽然它们能模拟人类的直觉,但未来的AI将会在推理和决策方面展现出更加不可预测的能力。
Ilya进一步推测,未来的AI将不仅仅是执行任务的工具,而会发展成“Agent”,能够自主进行推理和决策,甚至
可能具备某种形式的自我意识。这将是一个质的飞跃,AI将不再是人类的延伸,而是一个具有独立智能的存在。
参考链接:https://x.com/vincentweisser/status/1867719020444889118
#「中美科技合作协定」终于续签
但AI半导体等关键技术却遭排除
《中美科技合作协定》在几经波折之后终于续签,但更新后的协定将只包含基础研究,不涉及关键和新兴技术的开发。
12月13日,中美双方正式签署了《关于修订和延长两国政府科学技术合作协定的议定书》,将《中美科技合作协定》自2024年8月27日起延期5年。
与先前的协定相比,这项新协定的范围更为有限,仅涵盖两国政府部门和机构之间的基础科学项目合作,同时排除了可能涉及国家安全的「关键性新兴技术」领域,如AI和半导体等。
此外,新协定中也未包含任何关于中美两国高校和私营企业之间开展合作的相关内容。
新协定规定了中美双方将如何在科学技术研究领域开展合作,并规定了需要共享数据并保持开放透明。
同时,还设立了争议解决机制,以便两国能够解决在项目实施过程中遇到的各种困难。
如果任何一方未能履行承诺,双方可以通过终止机制来结束协定。
协定续签,一拖再拖
公开资料显示,《中美科技合作协定》由邓小平副总理与时任美国总统卡特于1979年1月31日签署。这是中美建交后两国签署的首批政府间协定之一。
基于此,两国将在包括能源、环境、农业、基础科学、科技信息和政策、地学、自然资源、交通、水文和水资源、医药卫生、计量和标准、统计、自然保护、林业、高能物理、聚变、材料科学和工程计量科学、生物医学、地震、海洋、大气、测绘等领域展开合作。
之后,协定通常每五年续签一次,40余年从未间断。
但就在2023年8月27日到期前两个月,美国政府突然发难拒绝续签。
随后经双方协商,协定首次延期,时长6个月。2024年3月7日,协定再次延期,时长6个月。
对此,相关研究人员和专家表示,若缺少这项具有象征意义且不涉及资金支持的协定,两国政府之间的研究合作和各项计划都可能会陷入停滞。
但即便协定已经续签,未来也依然存在着极大的不确定性。
首先,除了明确将关键性和新兴技术排除在合作范围之外,新协定并未对其他可合作的科学领域作出进一步限制。
据美政府官员透露,可能获准的项目包括气象学、海洋学和地质学研究,以及流感监测和空气质量数据收集等。
第二个悬而未决的因素是,在一个月后上任的特朗普政府,是否会遵守协定的内容。
对此,有研究人员表示,考虑到协定本身已经是双方相互妥协的结果,因此特朗普政府不太可能以协定效力不足为由予以废止。
参考资料:
https://www.gov.cn/lianbo/bumen/202412/content_6992558.htm
https://www.nature.com/articles/d41586-024-04175-7
#大模型轻量化系列解读
AWQ:适合端侧的 4-bit 大语言模型权重量化
并非 LLM 中的所有权重都同等重要。仅保护 1% 的 salient 权重可以大大减少量化误差。
大语言模型 4-bit 权重后训练量化方案,以及专为 4-bit On-Device LLM/VLMs 定制的推理框架 TinyChat。
大语言模型 (LLM) 已经改变了许多 AI 应用。On-device LLM 也变得越来越重要:在边缘设备上本地运行 LLM 可以降低云计算成本,保护用户的隐私。然而,巨大的模型尺寸以及有限的硬件资源为部署带来了重大的挑战。本文提出了激活感知权重量化方法 (Activation-aware Weight Quantization, AWQ),一种硬件友好的 LLM 低 bit 权重量化方法。
AWQ 发现,并非 LLM 中的所有权重都同等重要。仅保护 1% 的 salient 权重可以大大减少量化误差。为了识别 salient 的 weight channel,应该参考 activation 而不是 weight 的分布。为了避免硬件效率低下的混合精度量化,作者在数学上推导出扩大 salient channel 可以减少量化误差。AWQ 采用等效变换来缩放 salient 的 weight channel 以保护它们。AWQ 不依赖于任何反向传播或重建,因此它可以推广到不同的领域和模式,而不会过度拟合校准集。
AWQ 在各种语言建模和特定领域基准 (代码和数学) 上的表现优于现有工作。由于更好的泛化,它为指令调整的 LM 实现了出色的量化性能,并且首次实现了多模态 LM。除了 AWQ,作者还实现了 TinyChat,这是一个高效且灵活的推理框架,专为 4 位设备上的 LLM/VLM 量身定制。通过 Kernel Fusion 和平台感知的权重打包,TinyChat 在桌面和移动 GPU 上都比 Huggingface FP16 实现提供了 3 倍以上的加速。它还使 70B Llama-2 模型在移动 GPU 上的部署民主化。

图1:AWQ 为一种用于 LLM 的通用权重量化方法。为了实现 AWQ,作者开发了TinyChat,将 4-bit 量化 LLM 部署到各种边缘平台中,与 FP16 相比,性能提高了 3-4 倍。值得注意的是,作者还制作了一个由 TinyChat 驱动的计算机,该计算机包含一个NVIDIA Jetson Orin Nano,只有 8GB 的内存和 15W 功率
下面是对本文的详细介绍。
专栏目录
https://zhuanlan.zhihu.com/p/687092760
本文目录
1 AWQ:适合端侧的 4-bit 大语言模型权重量化
(来自 MIT 韩松团队,NVIDIA)
1 AWQ 论文解读
1.1 AWQ 研究背景
1.2 只保留 1% 的 Salient Weight
1.3 通过激活感知缩放保护 Salinet Weight
1.4 TinyChat:将 AWQ 映射到边缘设备
1.5 与经典工作 SmoothQuant 的关系
1.6 实验设置
1.7 实验结果
1.8 实际加速效果
1 AWQ:适合端侧的 4-bit 大语言模型权重量化
论文名称:AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (MLSys 2024 Best Paper)
论文地址:http://arxiv.org/pdf/2306.00978
代码链接:http://github.com/mit-han-lab/llm-awq
Demo:http://www.youtube.com/watch%3Fv%3Dz91a8DrfgEw
1.1 AWQ 研究背景
直接在边缘设备上部署大语言模型 (LLM) 至关重要。On-device 地使用 LLM 的好处有:
- 隐私和安全性: 通过保持敏感信息本地来增强数据安全性,从而减少数据泄露的机会。
- 实时性: 消除将数据发送到云服务器引起的延时,并使 LLM 离线操作,有利于虚拟助手、聊天机器人和自动驾驶汽车等实时应用。
- 降低运营成本: 减少与维护和缩放集中式云基础设施相关的运营成本。
LLM 基于基于 Transformer 架构,因其在不同基准测试中令人印象深刻的性能而引起了极大的关注。但是,较大的模型尺寸会导致较高的服务成本。例如,GPT-3 有 175B 参数,FP16 为 350GB,而最新的 B200 GPU 只有 192GB 内存,更不用说边缘设备了。
低比特权重量化可以显著降低 On-device LLM 推理的内存占用。由于训练成本高,量化感知训练 (Quantization-aware training, QAT) 效率不高,而后训练量化 (Post-Training Quantization, PTQ) 在低比特设置下存在较大的精度下降。
LLM 在当时,其量化一般有2种设置:
- W8A8量化,其中激活和权重都被量化为 INT8,比如 SmoothQuant[1]。
- 低比特 Weight-only 量化 (例如 W4A16),其中只有 weight 被量化为低位整数,比如 GPTQ[2]。
本文属于是第2种,因为这样不仅减少了硬件障碍 (需要更低的显存),而且还可以加速 token 的生成 (补救了 显存受限负载)。
与本文最接近的工作是 GPTQ,它使用二阶信息来执行误差补偿。然而,它可能会在重建过程中过度拟合校准集,扭曲分布外域上学习到的特征,这是有问题的,因为 LLM 是通才模型。
本文提出了激活感知权重量化 (Activation-aware Weight Quantization, AWQ),这是一种硬件友好的 LLM 低比特权重量化方法。本文的方法基于这样一个观察:Weight 对 LLM 的性能并不同等的重要。Salient weight 只有一小部分 (0.1%-1%),不量化这些 salient weight 将显着降低量化损失 (图2)。

图2:保持 FP16 中的一小部分权重 (0.1%-1%) 显著提高了量化模型在 Round-To-Nearest (RTN) 上的性能。只有当通过查看 activation 分布而不是 weight 分布来选择 FP16 中的重要权重时才有效
为了找到这些 salient weight channel,本文给出的见解是:应该参考 activation 分布而不是 weight 分布,尽管是在进行 weight-only 的量化:对应更大激活幅值的 weight channel 更加 salient,因为它们处理更重要的特征。为了避免硬件效率低下的混合精度实现,作者从权重量化中分析误差,并推导出 scaling salient channel 可以减少其相对量化误差。根据直觉,作者设计了一种 per-channel scaling 方法自动搜索最优缩放,在量化全部权重的情况下最小化量化误差。AWQ 不依赖任何反向传播或者重建,因此它可以很好地保留 LLM 在各种域和模态的泛化能力,而不会过度拟合校准集。
为了实现 AWQ,作者设计了 TinyChat,一个高效推理框架,可以将 4-bit LLM 的理论显存节省转换为可以测量的实际加速。本框架通过动态去量化显着加快了线性层。作者还利用高效的 4-bit 权重打包和 Kernel Fusion 来最小化推理开销 (比如中间 DRAM 访问和 Kernel 启动的开销),以便更好地实现从量化权重到 4-bit 的速度,尽管计算机是字节对齐的。
在桌面、笔记本电脑和移动 GPU 上,可以始终观察到:与各种 LLM 的 Huggingface 的 FP16 实现相比,平均加速比为 3.2-3.3 倍。此外,它可以在单个 NVIDIA Jetson Orin 上轻松部署内存为 64GB 的 Llama-2-70B。它还以 30 tokens/second 的交互式速度在只有 8GB 内存的笔记本电脑 RTX 4070 GPU 上运行了 1.3B 参数的 LLM。
AWQ 已被行业和开源社区广泛采用:HuggingFace Transformers、NVIDIA TensorRT-LLM、Microsfot DirectML、Google Vertex AI、Intel Neural Compressor、Amazon Sagemaker、AMD、FastChat、vLLM、LMDeploy,并使 Falcon180B 可部署在单个 H200 GPU 上。
1.2 只保留 1% 的 Salient Weight
量化将浮点数映射到低比特整数,是一种降低 LLM 大小和推理成本的有效方法。在本节中,作者首先提出了一种 Weight-only 的量化方法,通过保护更多的 "重要" 权重来提高准确性,而无需训练/回归。然后开发了一种数据驱动的方法来搜索减少量化误差的最佳缩放。
观察到 LLM 的权重并非同等重要:与其他模型相比,一小部分 salient weight 对于 LLM 的性能更重要。不量化这些 salient 的量化因为量化损失而可以帮助弥补性能下降,同时无需任何训练或者回归,如图3所示。为了验证这个想法,作者在图2中对量化 LLM 的性能进行了基准测试,这里就跳过了一些 weight channel 的量化。作者测量了 INT3 量化模型的性能,同时将一定比例的权重通道保持为 FP16。确定权重重要性的一种广泛使用的方法是查看其大小或 L_2 -Norm[3]。但是作者发现跳过具有 Large Norm 的 weight channel (based on \text{W} ) 并不能显着提高量化性能,与随机选择结果是类似的。但是有趣的是,基于激活幅度选择权重可以显著提高性能,尽管只保留了 0.1%-1% 的通道为 FP16。作者假设具有较大幅度的输入特征通常更重要。保持 FP16 中相应的权重可以保留这些特征,从而获得更好的模型性能。

图3:本文观察到,可以根据 (中间) 激活分布在 LLM 中找到 1% 的 salient weight,保持 FP16 的 salient weight 可以显著提高量化性能 (PPL 从 43.2 提高到 13.0),但是混合精度格式并非硬件高效
局限性: 尽管保留 0.1% 的权重为 FP16 可以提高量化性能,而不会显著增加模型大小 (使用 total bits 测量),但是这种混合精度数据类型会使得系统实现变得困难。需要提出一种保护重要权重的方法,而不实际将其保留为 FP16。

图4:本文遵循激活感知原则并提出 AWQ。AWQ 执行 per-channel scaling 以保护 salient weight 并减少量化误差
1.3 通过激活感知缩放保护 Salinet Weight
本文提出了一种替代方法,通过逐通道缩放 (Scaling) 来减少 Salinet Weight 的量化误差,不会受到硬件效率低下问题的影响。
分析量化误差
作者首先分析了 Weight-only 的误差。考虑一个权重 的组块;线性运算可以写成 ,量化对应为 。具体来说, 量化函数定义为:

其中 是量化比特数, 是由绝对最大值确定的量化 scaler。现在考虑一个权重 ,如果将 与 和 inverse scaler 相乘, 则将有: 。上式即可以写成:

其中 是应用 后的新量化 scaler。
我们实验性地发现:
- Round (表示为 RoundErr ) 的 Expected Error 不会改变:由于 round 函数将浮点数映射到整数, 误差大致均匀分布在 中, 平均误差为 0.25 。即 。
- 扩展单个权重 通常不会改变组 的最大值。因此有 。
- 由于 和 使用 FP16 表示, 因此它们没有量化误差。
因此,式 1 和 2 的量化误差可以表示为:

因此,新误差与原始误差之比为 。给定 ,因此 Salient Weight 的相对误差较小。
为了验证这个想法,作者将 OPT-6.7B 模型 1% 的 Salient Channel 与 相乘,并测量每组 的变化,如图5所示。作者发现 Scaling Salient channels 非常有效:对于 ,困惑度相比 (简单 RTN) 时从 23.54 提高到 11.92。随着 的增大, 变化 的百分比变大, 但对于 时百分比变化仍然非常小(低于5%);随着 的增加,显著通道的相对误差继续变小。尽管如此,最好的 PPL 实际上出现在 。这是因为如果我们使用非常大的 ,当 增加时,它将增加 Non-salient channels 的相对误差(Non-salient channels 的误差将被放大 ,并且 下 21.2 的 channels 的比率大于 1, 这可能会损害模型的整体精度。因此, 在保护 Salient Channels 时,还需要考虑 Non-salient channels 的错误。

图5:将 1% 的 salient channels 乘以 >1 时的统计数据。扩大 salient channels 显著提高了困惑度 (23.54 到 11.92)。随着 s 变大,变化 Δ 的百分比增加,salient channels 的错误率也增加。然而,最好的困惑度是在 s = 2 时实现的,因为进一步增加 s 将增加 non-salient channels 的量化误差
搜索 Scaling
为了同时考虑 Salient Weight 和 Non-salient Weight,作者选择自动搜索最优 (每个输入通道) 的 scaling,使某一层量化后的输出差异最小化。形式上,希望优化以下目标:

这里 表示权重量化函数(比如,组大小为 128 的 INT3/INT4 量化), 是 FP16 中的原始权重, 是从一个小的校准集缓存的输入特征 (从预训练数据集中获取一个小的校准集, 以便不过拟合特定任务)。s 是 input channel 的缩放因子。对于 , 它通常可以融合到前一个算子中 。因量化函数是不可微的, 故无法用反向传播直接优化问题。一些技术依赖于近似梯度 , 作者发现它仍然存在收敛不稳定的问题。
为了使整个过程更加稳定,作者通过分析影响比例因子选择的因素来定义最优 Scaling 的搜索空间。如上一节所示,权重通道的显著性实际上是由 activation 的尺度决定的 (因此称之为 activation-awareness)。因此,作者简单地使用非常简单的搜索空间:

其中, 是 activation 的平均幅值 (每个 channel), 作者使用超参数 来平衡 Salient channels和 Non-salient channels 的保护。可以通过在 区间上的快速 grid search 找到最佳 (0 表示不缩放;1 对应于搜索空间中最激进的缩放)。进一步应用权重裁剪来最小化量化的 MSE 误差。作者在图6中提供了 INT3-g128 量化下 OPT 模型的消融实验结果;AWQ 始终优于 Round-ToNearest Quantization (RTN),并实现了与混合精度 (1% FP16) 相当的性能,同时更硬件友好。
优势
AWQ 不依赖于许多 QAT 方法所需要的回归或者反向传播操作。它对校准集的依赖最小,因为只测量每个 channel 的平均大小,从而防止过拟合。因此,AWQ 需要更少的量化过程得数据,并且可以保留 LLM 在校准集分布之外的知识。

图6:Mistral-7B-Instructv0.2 和 Mixstral-8x7B-Instruct-v0.1 模型上的 AWQ 量化结果
1.4 TinyChat:将 AWQ 映射到边缘设备
AWQ 可以大大减少 LLM 的尺寸。然而,将 W4A16 (4-bit weight、16-bit activation) 量化的理论内存节省转换为可以实测的加速并非易事。其替代的 W8A8 量化方法,如 SmoothQuant[1],在存储和计算方面保持相同的数据精度。这允许去量化过程无缝集成到计算 Kernel 的目录中。另一方面,W4A16 量化采用不同的数据类型进行显存访问和计算。因此,必须将其去量化合并到主要计算循环中以获得最佳性能,带来了实施的挑战。为了解决这个问题,作者引入了 TinyChat:一个用于 AWQ 模型推理的系统。它拥有 PyTorch 前端和后端,利用特定于设备的指令集 (例如 CUDA/PTX、Neon、AVX)。
为什么 AWQ 有助于 On-device LLM?
为了了解量化 LLM 在边缘设备的加速机会,作者首先在 RTX 4090 GPU 上分析 LLaMA-7B 模型的延时分解。作者采用 Batch Size 为 1,满足边缘用例,并使用 NVIDIA FasterTransformer 以 FP16 精度实现模型。
上下文与生成时延
如图7所示,在总结提示时,生成 20 个 token 需要 310ms,但是总结 200 个 token 仅需 10ms。因此,生成阶段比上下文阶段慢得多,特别是对于 On-device 的交互应用程序。

图7:NVIDIA RTX 4090 上 Llama-2-7B 的瓶颈分析。On-device LLM 应用程序中,生成阶段比上下文阶段慢得多
生成阶段是 Memory-bound 的
为了加速生成,作者在图8中进行了屋顶线分析。4090 GPU 的峰值计算吞吐量为 165 TFLOPS,内存带宽为 1TB/s。因此,任何算术强度 (FLOPs 与内存访问的比率) 小于 165 的工作负载对于 4090 GPU 来讲都是 Memory-bound 的。值得注意的是,以 FP16 运行时,On-device LLM 的生成阶段的算术强度约为1。这强调了工作负载是 Memory-bound 的。由于给定模型的 FLOPs 是固定的,提高峰值性能的唯一方法是减少内存流量的总数。AWQ 将权重内存减少了 4 倍。

图8:生成阶段是 memory-bound 的,算术强度较低。W4A16 量化可以有效提高 4× 的算术强度
权重访问主导了 Memory Traffic
作者进一步分解了 weight 和 activation 的 Memory Access,如图9所示。显然,weight access 主导了 On-device LLM 的 Memory Traffic。将模型权重量化为 4-bit 整数将近似将算术强度增加到 4 个 FLOP/Byte,导致 4TFLOPS 峰值性能。由于仅权重量化导致权重位宽较低 (因此理论性能上限较高),因此 AWQ 很自然地遵循 On-device LLM 应用程序。

图9:Weight access 比 activation access 大几个数量级。因此,仅量化权重对 On-device LLM 更有效
使用 TinyChat 部署 AWQ
作者证明了 4-bit 权重量化可以带来 4 倍的理论峰值性能。作者进一步设计了 TinyChat 来实现这种加速。在 GPU 上,只关注实现基本组件,包括注意力、Layer Norm 和线性投影 Kernel。灵活的前端可以轻松定制和快速支持新模型。与 Huggingface 的 FP16 实现相比,4-bit AWQ 的 TinyChat 实现了3倍以上的加速。在 CPU 上,将整个计算图降低到 C++ 以最小化开销。
对于量化层,由于硬件不提供 INT4 和 FP16 之间的乘法指令,因此需要在执行矩阵计算之前把整数 dequantize 为 FP16。作者通过将 Dequantize Kernel 与矩阵乘法 Kernel 融合来避免将 dequantized 的权重写入 DRAM。请注意,这种融合用于 matrix-matrix (MM) 乘积和 matrix-vector (MV) 乘积的 Kernel。
Kernel Fusion
作者还应用 Kernel Fusion 来优化 On-deviece 的 LLM 推理。对于 LN,将所有运算符 (例如乘法、除法和平方根) 融合到单个 Kernel 中。对于 Attention 层,将 QKV 投影融合到单个 Kernel 中,并执行动态位置编码计算。作者还预分配 KV cache 并在 Attention Kernel 中执行缓存更新。Kernel Fusion 对于前向传播实现效率低下的模型特别有用,例如 Falcon 和 StarCoder。值得注意的是,每个 FP16 Kernel 的计算时间在 4090 GPU 上约为 0.01ms,与 GPU Kernel 启动开销相当。因此,通过 Kernel Fusion 减少 Kernel 调用的数量会导致直接加速。
1.5 与经典工作 SmoothQuant 的关系
与经典工作 SmoothQuant 的相同点:
- 都是后训练量化 (Post-Training Quantization PTQ)。
- 都有对一些 weight (及其对应的 input activation) 做 scaling,即 weight 乘以一个 scaling factor,对应的 input activation 除以这个 scaling factor。
- 都需要校准集确定 scaling factor 的值 (无需额外的训练)。
- 都来自著名的 MIT HAN LAB 团队,很经典,很厉害。
与经典工作 SmoothQuant 的区别:
- 量化精度不同: SmoothQuant 量化精度为 W8A8;AWQ 量化精度为 W4A16。
- Scaling factor 的确定方法不同: SmoothQuant 的 scaling factor 是算出来的: ; AWQ 的 scaling factor 是搜出来的 , 其中 是 activation 的平均幅值。
- Scaling factor 施加的 weight 不同: SmoothQuant 平等地对每个 weight (及其对应的 input activation) 做 scaling;AWQ 只对少量 (约 0.1%) 的 salient weight (及其对应的 input activation) 做 scaling。
- 实验不同: AWQ 还开发了推理框架 TinyChat,作为后来的工作,更加完备了。
1.6 实验设置
量化设置
AWQ 专注于 Weight-only 的 Group Quantization。如之前的工作[6][2]所示,Group Quantization 总是有助于提高性能/模型大小的权衡。作者在整个工作中都使用了 128 的 group size,除非另有说明。AWQ 专注于 INT4/INT3 量化,因为它们会保留 LLM 性能。对于 AWQ,作者使用了来自 Pile 数据集的小型校准集,以便不过拟合特定的下游域。作者使用 20 的 grid size 来搜索式 5 中的最佳 \alpha 。
模型
作者在 LLaMA 和 OPT 家族上对本文方法进行了基准测试。其他开源的 LLM 如 BLOOM 在质量上通常较差,所以本文不研究它们。作者进一步对指令微调模型 Vicuna 和视觉语言模型 OpenFlamingo-9B 和 LLaVA-13B 进行了基准测试,以证明本文方法的泛化性。
评估方案
继之前的工作[6][2][1]之后,作者主要分析了语言建模任务 (WikiText-2 上评估困惑度),因为困惑度可以稳定地反映 LLM 的性能。
Baseline
- Round-To-Nearest Quantization (RTN)
- GPTQ (GPTQ-Reorder)[2]
1.7 实验结果
LLaMA 模型实验结果
作者评测了 LLaMA 和 LLaMA2 因为它们与其他开源 LLM 相比具有更好的性能。它还是许多流行的开源模型[7][8]的基础。作者在图10中评估了量化前后的困惑度。AWQ 在不同的模型尺度 (7B-70B) 和 epoch 之间始终优于 RTN 和 GPTQ。

图10:AWQ 针对不同的模型大小和不同的位精度改进了 RTN。在 LLaMA 和 LLaMA-2 模型上,它始终比 GPTQ 获得更好的困惑度
Mistral / Mixral 模型实验结果
作者还在 Mistral 和 Mixral 模型上评估了 AWQ,这些模型分别是最流行的开源 LLM 和专家混合 (MoE) 模型[9]。结果如图11所示,AWQ 在 Mistral 和 Mixral 模型上都取得了卓越的性能。这表明 AWQ 在各种模型架构中都是有效的。

图11:Mistral-7B-Instructv0.2 和 Mixstral-8x7B-Instruct-v0.1 模型 上 AWQ 量化结果。wikitext 上的 PPL 结果表明,AWQ 可以在不同的模型架构上实现卓越的量化性能,包括 GQA 和专家混合 (MoE) 模型的 LLM
指令微调模型的量化
指令微调可以显着提高模型的性能和可用性。在模型部署之前,它已成为必不可少的过程。作者在图12中进一步对本文方法在流行的指令微调模型 Vicuna 上的性能进行了基准测试。作者使用 GPT-4 分数来评估量化模型在 80 个样本问题上与 FP16 模型的性能对比。AWQ 在两个尺度 (7B 和 13B) 下始终优于 RTN 和 GPTQ 的 INT3-g128 量化 Vicuna 模型,证明了指令微调模型的泛化性。

图12:在 GPT-4 评估下,将 INT3-g128 量化 Vicuna 模型与 FP16 模型进行比较。更多的获胜案例 (蓝色) 表明更好的性能。与 RTN 和 GPTQ 相比,AWQ 不断提高量化性能,显示出对指令调整模型的泛化性
多模态语言模型的量化
大型多模态模型 (LMM) 或视觉语言模型 (VLM) 是增加了视觉输入的 LLM。这些模型能够根据图像/视频输入执行文本生成。由于本文的方法对校准集没有过拟合问题,因此可以直接应用于 VLM 提供准确和高效的量化。作者使用 OpenFlamingo-9B 模型 在 COCO 字幕数据集上进行实验,结果如图13所示。作者测量了 5K 个样本在不同 few-shot 设置下的平均性能。作者只量化模型的语言部分,因为其主导了模型大小。AWQ 在 zero-shot 和各种 few-shot 设置下优于现有方法,展示了对不同模式和上下文学习工作负载的泛化性。在 INT4-g128 下,它将量化退化从 4.57 降低到 1.17,减少了 4× 模型尺寸,性能损失可以忽略不计。

图13:COCO 字幕数据集上视觉语言模型 OpenFlamingo-9B 的量化结果
为了进一步证明 AWQ 的泛化性,作者还在 SoTA 多图像视觉语言模型之一 VILA 上评估了 AWQ。图14中的结果表明,AWQ 在 11 个视觉语言基准测试中实现了无损量化性能。作者进一步在图15中提供了一些字幕结果,以展示 AWQ 优于 RTN 的优势。AWQ 为 LMM/VLM 量化提供了一个一键解决方案。

图14:11 个视觉语言基准上 VILA-7B 和 VILA-13B 的 INT4-g128 结果

图15:COCO 字幕数据集 (4-shot, INT4-g128 量化) 上量化 OpenFlamingo-9B 的定性结果
视觉推理结果
作者在图16中进一步提供了 LLaVA-13B 模型的一些定性视觉推理示例。与 INT4-g128 量化的 RTN 相比,AWQ 提高了响应,从而导致更合理的答案。

图16:LLaVA-13B 模型的视觉推理示例
编程和数学任务的结果
为了进一步评估 AWQ 在涉及复杂代的任务上的性能,作者还在 MBPP 和 GSM8K 上测试了 AWQ。MBPP 由大约 1,000 个 Python 编程问题组成,这些问题旨在通过入门级程序员解决,涵盖编程基础、标准库功能等。创建 GSM8K 以支持问答任务关于需要多步推理的基本数学问题。作者将 CodeLlama-7b-Instruct-hf 和 LLaMA-2 量化为 INT4-g128,并对编程和数学数据集进行了实验,结果如图17所示。AWQ 在两个数据集上都优于现有方法,证明了对复杂生成的泛化性。INT4-g128 配置下的 AWQ 在两个数据集上都表现出与原始 FP16 模型相当的性能。

图17:MBPP 数据集上的 CodeLlama-7bInstruct-hf 和 GSM8K 数据集上的 Llama-2 (7B/13B/70B) 的 INT4-g128 量化结果
超低比特量化
作者进一步将 LLM 量化为 INT2 以适应有限的 device 显存。RTN 完全失败,AWQ 在 GPTQ 之上带来了显着的困惑度改进。AWQ 与 GPTQ 正交,可以与 GPTQ 相结合进一步提高 INT2 量化性能,使其成为更实用的设置。

图18:AWQ 与 GPTQ 正交:当与 GPTQ 结合时,它进一步缩小了超低比特量化 (INT2-g64) 与 FP16 之间的性能差距
1.8 实际加速效果
图19中,作者展示了 TinyChat 的系统加速结果。作者在 RTX 4090 和 Jetson Orin 上进行了实验。作者使用 4 个 token 的固定提示长度对所有 LLM 执行 batch size= 1 的推理。作者为每个推理运行生成 200 个 token,并计算中值延迟作为最终结果。

图19:TinyChat 提供了一个一键式的解决方案,将理论内存占用减少转换为实际的加速
如图19(a)所示,与 Huggingface FP16 实现相比,TinyChat 在 4090 上为 3 个 LLM (LLaMA-2、MPT 和 Falcon) 家族带来了 2.7-3.9 倍的加速。对于 LLaMA-2-7B,作者通过 FP16 Kernel Fusion 将推理速度从 52 tokens/s 提高到 62 tokens/s。对于 Falcon-7B,官方实现在推理时没有正确支持 KV 缓存,因此它明显比其他模型慢。在这种情况下,本文的 FP16 优化带来了 1.6 倍的更大加速。在只有 8GB 内存的笔记本电脑 4070 GPU 上,AWQ 仍然能够在 33 tokens/s 上运行 LLaMA-2-13B 模型,而 FP16 实现无法拟合 7B 模型。作者还在图20中展示了视觉语言模型 加速结果。TinyChat 在 NVIDIA Jetson Orin 上为 VILA-7B 和 VILA-13B 带来了大约 3 倍的加速。值得注意的是,作者使用本地 PyTorch API 实现了所有 AWQ 模型的前向传递,并且该代码在各种 GPU 架构中重用。因此,TinyChat 提供了卓越的可扩展性。

图20:TinyChat 还能够在多个 GPU 平台上无缝部署 VILA,当时最先进的视觉语言模型
与其他系统的比较
作者在图21中将 TinyChat 与现有的端侧 LLM 推理系统 AutoGPTQ、llama.cpp 和 exllama 进行了比较。本系统在 Orin 上实现了高达 1.7 倍的加速。而且,llama.cpp 和 exllama 主要针对 LLaMA 和 LLaMA-2 模型量身定制,因此适配度有限。相比之下,TinyChat 支持广泛的应用,包括 StarCoder、StableCode (GPTNeoX)、Mistral 和 Falcon,同时始终比 AutoGPTQ 提供了显著的加速。TinyChat 甚至可以在资源极度受限的 Raspberry Pi 4B 上民主化 LLM 的部署,为 7B 模型实现 0.7 tokens/s。

图21:在 NVIDIA Jetson Orin 上运行 4-bit 量化 LLaMA 模型时,TinyChat 比现有系统提供了 1.2-3.0 倍的加速
#NeurIPS 2024 Auto-Bidding in Large-Scale Auctions
与1500多支国内外队伍同台竞技,快手在NeurIPS 2024顶级大赛中上演双杀
这几天,学术圈的小伙伴肯定都很关注正在加拿大温哥华举办的机器学习顶会——NeurIPS 2024。本届会议于今日落下帷幕,共接收 15671 篇有效论文投稿,比去年增长了 27%,最终接收率为 25.8%。
本届会议上同样值得关注的,还有一项重要的赛事,它就是「NeurIPS 2024 Auto-Bidding in Large-Scale Auctions」(大规模拍卖中的自动出价),旨在探索当前火热的强化学习、生成模型、Agent 等前沿 AI 技术在广告投放以及决策智能场景的应用。
该赛事不仅是业内首次广告出价比赛,也是 NeurIPS 2024 唯一的搜广推比赛,可以说规格和含金量都很高,也因此收获了超高的热度,吸引超过 1500 支队伍参赛,其中不乏国内外知名高校和公司、专业研究机构以及决策智能领域知名团队的身影。

赛事主页:https://tianchi.aliyun.com/specials/promotion/neurips2024_alimama#/
简单来说,在比赛中,参赛者扮演自动出价 Agent(即广告主),在大规模拍卖环境下与其他 47 个竞争对手对抗,作出有效的出价决策,并在满足投放需求的情况下帮助广告主最大化投放效果。

从①到⑤为典型广告平台的自动出价全流程。
此次比赛分为了两个赛道,分别是通用赛道和 AIGB(AI-Generated Bidding)赛道。两个赛道侧重点各有不同,对参赛队伍提出了不同的技术要求,其中:
- 通用赛道关注不确定环境中的自动出价,需要解决数据稀疏性、转化方差、多坑等不确定问题;
- AIGB 赛道使用生成模型来学习自动出价 Agent,需要采用生成模型来端到端输出决策。
算起来,自今年 6 月底注册阶段开始,经过了近半年的激烈角逐,比赛终于决出了胜负!
快手商业化算法团队(简称快手团队)从千余支队伍中脱颖而出,包揽了两个赛道的第一名,成为本次赛事最大赢家。

夺冠方案
自动出价服务是国内外各广告平台的基础组成模块,有众多的业界实践和研究工作。
此次比赛任务基于一个简化版本的 Target CPA,并将 CPA 定义为平均转化成本。参赛者需要设计和实现一个自动出价 Agent。给定广告主 j 的预算 B 和目标 CPA C,该自动出价 Agent 在一个广告投放周期内对 N 个展现机会进行竞价,目标是在保证最终实现的 CPA 不大于 C 的前提下,最大化总转化量。
具体来说,所有展现机会按顺序到达,出价 Agent 依次对每个机会进行竞价。对于每个机会 i:
出价:自动出价 Agent 出价

,同时其他竞争广告主利用他们的单独的出价 Agent 出价

,来竞争 3 个广告坑位。其中,出价会依赖转化概率值,

定义为广告主 j 的广告曝光给用户时的转化动作概率,

定位为预估的标准差。
拍卖:广告平台运行 GSP(Generalized Second Price)拍卖机制,按照出价从高到低依次分配 3 个到坑位上,获胜者按照下一位出价进行扣费。拍卖结果会返回给出价 Agent,其中

表示是否获胜,

表示赢得的广告坑位,

表示需要支付的费用。

不仅取决于

还取决于

。
展现:广告坑位

是否曝光给用户由随机变量

决定,其中

是广告坑位

的曝光概率。实际是否发生转化也是一个随机变量,定义为

,其中

,

为预估标准差。如果广告坑位未曝光,广告主无需支付费用,转化也不会发生。因此,这个任务可以形式化如下:

最终实现的 CPA 定义为:

自动出价 Agent 的目标是在满足广告主设定的 CPA 约束情况下最大化转化量。具体的评估指标定义如下:

其中,

对应优化目标最大化转化

,在超成本即实际 CPA > C 时,P (CPA; C) < 1,会对转化进行降权。
总体来说,这项比赛不仅可以促进决策技术的突破,而且还将给行业应用场景带来启发。我们来看下快手是如何在通用和 AIGB 两个赛道拔得头筹的。
通用赛道
现实世界中,复杂的广告拍卖环境往往会带来额外的挑战,特别是不确定性。因此,通用赛道要求参赛者在大规模拍卖中做出有效竞价决策,需要有效感知竞争对手策略的变化。参赛者必须考虑客户到达的随机性、转化预测的方差、数据稀疏性和其他因素。
这就需要在离线规划最优解的基础上,自适应在线竞价过程,以获得更优出价序列。快手团队创新地提出了一种基于强化学习的在线探索技术方案,巧妙地解决了该问题。
首先,考虑多坑特点,快手团队基于竞胜率以及多坑的曝光率将问题建模成约束优化问题,并基于该问题的对偶问题求解出离线最优出价系数,得到最优出价形式。
然后,快手团队建模出价系数和未来预期消耗以及预期转化的关系,并且为了解决不确定性问题,在建模时综合考虑了稠密的先验转化以及稀疏的后验转化。
最后,为了适应在线环境的不确定性,快手团队提出基于强化学习的在线搜索方案:首先搭建一个竞价模拟器环境,能够学习不同出价对应的序列长期价值;然后基于离线最优出价系数划定一个区间进行采样,最后挑选出价值最优的动作(action)作为最终的出价系数。

结合最优化理论和强化学习在线搜索。
AIGB 赛道
相比于通用赛道,AIGB 赛道面向一种全新的迭代范式。由于生成模型,包括扩散模型(Diffusion Model)、决策 Transformer(Decision Transformer)、大型语言模型(LLM),在语言、视觉等领域体现出算力和数据的 scaling law,并且在决策任务中表现出了巨大的潜力,因此 AIGB 赛道要求采用生成模型,将自动出价建模为生成式序列决策问题,探索生成模型用于出价问题的机会。
在 AIGB 赛道,一个首先要解决的问题是选择模型架构。序列决策领域有扩散模型和决策 Transformer 两大类。参赛者面临在竞争性游戏中做出长期战略决策的关键挑战,众多竞争对手的策略会快速发生变化,以 DiffBid 为代表的扩散模型方案存在两个不足:
- 优化目标对齐能力弱:一次性生成一条序列,序列之间约束较弱,甚至学不出剩余预算单调递减这一性质;
- 训练效率低:是两阶段范式,首先预测状态序列 {s_{t+1},s_{t+2},...,s_{T}},然后根据 {s_t,s_{t+1}} 预测最终出价,训练较为复杂。
而决策 Transformer 建模长期价值 return to go(RTG),直接预测出价,相比于 DiffBid 具有和目标对齐能力更强、训练更简单的优势。
然而,快手团队发现:决策 Transformer 模型的学习机制是模仿学习,难以学习到超出数据集的出价策略。因此,他们考虑在策略学习时探索更优的出价系数,增强模型学习,但简单的探索很容易导致离线强化学习的分布外(Out Of Distribution,OOD)问题。
为了解决这个问题,快手团队从决策 Transformer 的本质出发,即决策 Transformer 根据 RTG 生成对应的出价系数,下一时刻的高 RTG 出价系数(长期价值)需要有更大的生成概率。
有了这个关键认知,快手团队提出一种 RTG 引导的出价系数探索方案——Decision Transformer with RTG-driven Explorations,保证探索性的同时兼顾安全性,从而增强模型学习。

Decision Transformer with RTG-driven Explorations
简单来说,Decision Transformer with RTG-driven Explorations 方案主要包括如下步骤:
- 首先训练模型预估下一时刻的 RTG,具备评估探索的出价系数好坏的能力。
- 每个 timestep 额外预测一个基于原始出价系数
-

- 探索新的出价系数
-

- ,鼓励模型探索下一时刻 RTG 更高的出价系数。
- 模型朝着原始出价系数和探索到的出价系数中更优的出价系数更新,避免 OOD 问题。
广告收入提升 5%+
基于 RL 的自动出价在业务侧开始发力
说起来,广告投放的目的其实很简单,以企业或商家为主的广告主选择合适的广告平台,将广告传递给受众(即消费者)。但实现起来需要考虑的因素就多了,比如针对同一广告位展开竞争出价、投放预算与实际投放成本、投放收益等。这就要求广告主进行全方位权衡,其中动态调整出价是控制广告成本和提升广告收入的关键一环。
而作为广告投放平台,快手也在广告推荐、预算分配策略、效果预估以及尤为重要的自动出价调整等层面进行算法上的优化升级,更好地服务于客户的同时增加自身广告收入。
从纵向来看,快手的出价算法经历了从 PID、MPC 到强化学习(RL)的「三代」演化路径,技术上的持续迭代更新带来了广告投放效果的节节提升。
第一代出价算法 PID(被动反馈式控制)包含了三个关键的控制参数:比例(Proportional)、积分(Integral)和微分(Derivative)。该算法可以通过动态调整出价来很好地将广告平均成交价稳定在目标成交价,但不足的点在于对未来消耗和预期消耗没有预估和规划。
第二代出价算法 MPC,它的全称为 Model Predictive Control,引入了对未来的预测,在对出价与未来消耗、成本的关系进行建模的基础上可以做出更精准的出价规划。不过,该算法建模能力较弱,也无法做出多步长期决策。
到了强化学习阶段,包括出价、成本、用户行为在内各个变量的建模能力大大加强,并对序列整体长期价值进行优化。通过不断与环境互动,强化学习算法可以根据实时市场环境变化调整出价,并能够预估长期广告效果以做出更精确的出价决策。相较于 PID、MPC,强化学习算法在动态决策、处理复杂环境与竞争行为、多目标优化、应对不确定性与数据稀缺、长期收益优化等多个方面都占优。
此外,面对 OOD 问题,快手在算法选型上采用了离线强化学习算法,缓解了训练数据集不足带来的问题,可以更稳健地进行决策,降低策略失效的风险;快手又搭建离线模拟环境,优化出价策略并验证效果,确保在线策略的安全性、有效性和稳健性,降低高风险决策可能造成的损失。
目前,基于强化学习的自动出价模型已经在快手广告系统全量推全,在成本达标不降约束下取得了 5% 以上的广告收入提升。消融实验也证明了:收益来自于模型泛化以及强化学习最大化序列价值建模。
通过此次大赛,快手看到生成模型(如 Decision Transformer)在广告出价场景中的应用潜力。虽然相较于强化学习在最大化序列整体价值方面存在短板,但对序列数据的拟合能力更强,因此二者的有效结合可能是下一代更强出价模型的演化方向。同时,快手也畅想借鉴 o1 思想,通过 Monte-Carlo Tree Search(MCTS)技术搜索不同出价序列,挑选出最优路径,在多轮决策和推理过程中优化出价策略。
夺冠背后
是 AI 技术的厚积薄发
此次 NeurIPS 2024 大赛,真正诠释了快手商业化算法团队的 AI 技术积累以及在实际业务中经受考验的信心。
从确定参赛、前期准备, 到练习轮(Practice Round)、再到正式比赛(Official Round),参赛成员在几个月的时间里,攻克了不少的难关,这才有了最终的双赛道夺冠。
参赛成员来自清华大学、香港中文大学、香港城市大学、南洋理工大学等国内外名校。在谈到此次最大的收获时,他们表示对几类出价算法(包括最优化理论、强化学习和生成模型)的优劣有了定性和定量的分析,并对未来出价技术的演进做出清晰的判断。而且,此次比赛提出的创新点在快手的广告业务中也得到了初步验证。
据了解,作为快手核心算法部门,商业化算法团队负责快手国内及海外多场景的变现算法研发,着力构建领先的广告变现算法,通过算法驱动商业营销增长,优化用户和客户体验。团队依托快手实际业务问题,产出顶会论文覆盖 KDD、ICLR、NeurIPS、CVPR 等多个领域的国际会议,还先后斩获 CIKM Best Paper、SIGIR Best Paper 提名奖、钱伟长中文信息处理科学技术奖一等奖。在 AI 技术层面的硬实力,是他们此次夺冠的最大底气。
作为一家以人工智能为核心驱动和技术依托的科技公司,快手已经看到了以技术为引擎、辅以算法在推动业绩增长方面的巨大价值。
未来,快手将继续探索强化学习、生成模型等 AI 技术在广告出价以及更广泛业务场景的落地。届时又会带来哪些惊喜,我们拭目以待。
#企业大模型落地关键是什么?
这家领先的大模型技术和应用公司给出答案
12 月 12 日,由中国人工智能产业发展联盟(AIIA)指导、北京中关村科金技术有限公司主办的【2024 大模型技术与应用创新论坛】在北京成功举办。

论坛现场,中关村科金总裁喻友平正式发布大模型时代的 “三级引擎战略”,推出重磅升级的得助大模型平台 2.0,以及一系列大模型应用。其中,得助大模型平台 2.0 具备算力统一调度能力、一站式模型训推、应用快速构建三大核心能力,并基于企业级最佳实践沉淀上百个全场景套件,能够帮助各类企业快速构建和部署自己的大模型应用,显著降低企业大模型落地成本。
基于得助大模型平台 2.0,中关村科金已与各行业伙伴一起构建了 200 + 覆盖智能营销、智能客服、智能运营和知识管理四大核心场景的应用,现场重点展示了大模型外呼、大模型接警助手、大模型陪练和大模型财富助手在帮助企业实现对外增长和对内提效的实战效果。
喻友平认为,大模型行业的发展已不再是暴风骤雨的狂飙状态,而是真正进入到精细化落地的进程中,平台+应用+服务是企业大模型落地的最佳路径。
以下为演讲实录
尊敬的各位领导、朋友,欢迎大家来到今天下午这个论坛。今天非常热闹,人非常多,就像大模型技术和应用现在非常热烈的状态,非常应景。过去一年多的时间里,大模型技术一直在不断进步,无论是郑院士还是斯坦利(Kenneth Stanley)对大模型技术都提出了一些观察、预测,当然还有一些担忧。对企业界来说,特别是对中关村科金这样的 "大模型 + X" 的企业来说,我们更关心的是如何将大模型应用到企业以及各种场景中,真正找到价值。
可以看到,整个业界对行业大模型和 AI 大模型解决方案的发展还是非常乐观。从两家国际知名咨询公司的报告来看,从 2024 年到 2028 年,大模型市场复合增长率的预测基本是 40%-50% 以上的增速。在这种情况下,大模型应用将必然有一个蓬勃的爆发。

中关村科金作为一线参与者来说,还是看到很多挑战。比如成本的问题。现在把大模型应用到实际的业务中,成本不低。即使不做基础大模型研发,就是做 TTS/NLP,算力还好,最关键的是标注成本,尤其是需要很多高精度、高准确的数据,这都是时间成本和人力成本。在数据的获取方面,本身处理的难度不小。其实构建一个场景大模型,并不需要海量数据,万级别的数据就可以解决很多问题。但技术和需求的匹配也是实践过程中的问题,如何把技术和需求匹配,相信也是今天在座大部分人非常关心的问题。
虽然媒体对大模型的普及做得非常好,但我们对大模型边界的认知程度,分析业务场景中问题和提供解决办法的能力,以及跟公司业务系统和流程如何建立链接形成技术解决方案,在这些方面坦率说我们还处于非常早期的阶段,仍有许多需要探索的,所以这些方面的人才也是非常缺乏的。除了大模型技术,大模型应用人才的需求量也远大于市场供给。
对企业来说行业 Know-how 上也有很多不足。每个行业都有行业独特的问题,有些问题在一个行业里很关键,但换一个行业就会发生变化。在非常细分的场景中,需要大模型应用厂商和客户有非常深度的沟通。此外,新技术在法规和伦理风险方面都会面临新挑战,比如数据安全性,用户隐私安全,所以对于大模型应用,法律法规和制度的健全也是迫在眉睫的。

当然市场在不断进步,在过去一年多时间,我们在不断跟大模型客户交流的过程中略有心得。
第一,无论是大模型还是任何技术,其商业本质还是要帮客户解决问题。比如一个家装公司,希望通过电话外呼触达客户后从公域转私域加友,这个场景看起来就是做训练、部署、外呼,TTS 跟 ASR 结合起来就可以搭建。但想在业务中发挥作用,提高转化率,就不能这么简单。其中有很多具体的技术问题,比如大模型幻觉消除,在企业的应用中是非常普遍的需求。我们和家装行业公司的合作,经过七次迭代,把私域加友转化率从 1.5% 提升到 3.5%。
第二,端到端的解决方案。大模型可以生成 Agent,硅谷现在已经把 Agent 当成一个新的 API,但一个 API 无法构成一个业务系统,也无法让你的业务有质的飞跃。在这个过程中非常重要的是实现端到端的产品体系。举一个例子,中关村科金重点在做的是连接企业和客户全流程的智能化。这个过程中有几个关键点。首先是全媒体联络中心,这是企业跟客户连接的基础平台,这个平台看似是基础软件,但其中的业务流程、业务逻辑非常复杂。中关村科金过去花了很多年才把这一套产品建设得比较完善。纯粹做大模型技术的公司没有这样的平台能力,需要建立在别人的平台能力之上,那提供的产品解决方案就是硬凑出来的,适配就差很多。
中关村科金在一个全媒体联络中心打造了语音和文本两类机器人,同时提供面向坐席效能优化的助手、质检和陪练的三件套。这三件套在任何场景下都可以使用,帮企业做好培训,还可以监督效果。在金融行业落地智能客服,不能只做客服机器人,而是把 “1 个联络中心 + 2 个机器人 + 3 个套件” 的全套解决方案提供给客户,实现端到端的智能化。大模型时代,数字化 + 智能化的升级思路是一个非常关键的点。
第三,全链条的服务。各行各业有着丰富的应用场景,既有面向外部客户的,也有面向内部员工的,这两类体验的提升就是大模型在企业落地的两个最重要方向。在这个过程中,企业需要建立大模型的内生能力。大模型基于企业内部的数据做一个发电站,电发出来之后,具体用在什么地方需要企业内部有管理和调配的能力。我们为国内若干个头部央国企提供了平台解决方案及实施,同时在平台之上合作应用开发,帮助客户解决内部的办公、写作、客服、营销等各类场景的需求。更重要的是,我们还提供陪伴式服务,包括数据标注、问题定义、检测方案的实施等等。
所以这三个方向是我们现在认为市场上真正需要的大模型应用,既要能够解决客户的核心问题,又要能提供端到端解决方案,同时还要有全链条的服务。

中关村科金基于 10 年来积累的 ToB 服务经验,加上大模型智能升级过程中的沉淀,我们今天正式发布中关村科金大模型时代企业智能化升级的 “三级引擎战略”。
首先是平台,智能化平台 + 数字化平台才能让企业的数字化真正进入一个智能化阶段。所以平台本身是大模型落地的技术引擎。
其次是应用,在企业经营全流程的各个环节中,都可以通过大模型进行智能化的升级,包括营销、运营、服务、知识管理等,甚至像生产、供应链、财务等场景都有可能利用智能化和数字化的平台相结合,打造智能化的应用。所以应用是大模型落地的产品引擎。
第三是服务。企业 “最后一公里” 的交付还有一个关键点就是服务。服务是一个价值引擎,最终要让客户、企业把大模型用起来,包括咨询服务、平台搭建、应用调试和效果运营都是缺一不可的。
因此,平台 + 应用 + 服务是企业大模型真正实现落地的最佳路径。这既是我们的心得,也是希望跟各行业进行分享探索,如何让中国的大模型落地更快更好。

对中关村科金来说,我们定位是领先的大模型技术与应用公司。在 2018 年,我们发布了全媒体联络中心。2019 年把传统的基础 AI 能力,如 OCR、TTS、ASR 用到了平台智能化里。中关村科金一直紧随着人工智能技术,从上一代以 CV 和语音为主的智能化技术到现在的大模型技术,一直跟随着大模型技术不断演进,面向企业的服务和产品进行升级。2020 年发布了音视频平台、远程双录等,其中用到如 OCR、人脸识别技术,让双录场景效率和效果更优。2021 年发布了坐席效能优化套件,2022 年发布了营销服一体化平台,2023 年发布了行业大模型。2024 年,一年的过程中我们不断利用大模型能力重构所有的应用产品。

基于中关村科金的 “三级引擎战略”,向大家介绍我们的产品全景图。通过全媒体联络中心和音视频平台这两大数字化平台,把企业与客户连接的各种渠道、各种媒介进行很好的整合,以及企业与内容员工的连接。在此之上,得助大模型平台可以提供从算力调度,模型训推到智能体构建。再结合企业的应用场景,在智能营销、智能客服、智能运营、知识管理等领域提供非常丰富的产品解决方案。同时结合各行各业的应用场景推出了一系列场景解决方案。这是中关村科金过去一段时间里的心得和方法。

今天,中关村科金重磅发布得助大模型平台 2.0,它具备算力统一调度,一站式模型训推,应用快速构建三大能力。算力统一调度能够对 GPU 算力进行共享调度,对模型统一纳管,包含所有的开源模型和开放的 MaaS 平台等最前沿的大模型技术,同时也兼顾了国产化信创适配。在模型训推方面,支持训推一体化,量化压缩及模块化的部署。智能体构建,自主编排可视化工作流,多 Agent 协同自主任务规划。最重要的是中间全场景套件,这些都是基于各类场景应用的企业级最佳实践沉淀而来。

我们把多个行业套件都沉淀在得助大模型平台,每个套件都是极具针对性的场景解决方案,要综合运用数据流、Agent 流、工作流组合,用大模型、小模型、MoE 模型组合,还有 SFT 模型,每个场景都经过实践检验,最后沉淀在平台上。得助大模型平台 2.0 已经沉淀了上百个通用套件和行业套件。这样一个灵活的大模型平台,企业只需要 5 分钟即可构建自己专属的场景应用。
,时长00:25
通过得助大模型我们已与各行业伙伴一起构建了 200 + 大模型应用,覆盖智能营销、智能客服、智能运营和知识管理四大核心场景。接下来分享几个典型案例。

第一个案例是智能营销场景。现在机器人坐席表现愈发接近人工坐席的表现。在大模型外呼实际运行过程中,机器人说话时有很多口语化内容,这是基于一些绩优的客服人员、营销人员做的优化。有几个关键点,比如附近门店的推荐,因为这是一个本地化的服务,不可能推荐一个很远的地址。机器人可以说出离客户最近门店,这种亲切感会让客户的体验更好。结合品牌信息、营销目的,作为一个外呼人员的任务不是随便聊天,而是需要引导客户留下联系方式、做好客户预约。整个过程每个小技术点都需要专门优化。
,时长00:45
在这个场景下,大模型外呼把过去传统 AI 外呼的转化率成功的从 1.5% 提高到 3.5%,人工外呼的比例是 4.1%,所以大模型外呼跟人工外呼成功的比例只有不到 17% 的差距。而且随着技术的提升,大模型外呼超越人工外呼转化率是有可能的。这中间要突破很多技术难点,需要增强 RAG 技术,Agent 协同技术,运用对产品的理解及优化数据学习,才可以打造出高拟人、高专业的外呼机器人。很多机构都在预测,未来 5-10 年,人工外呼 BPO 或将被机器人替代。基于大模型外呼的 BPO,具有标准化、覆盖广、成本低的特点,未来会成为外呼 BPO 的主流。这是第一个方向。

再讲一个跟每个人都息息相关的生活场景,就是大模型赋能反诈接警全流程,守护百姓钱袋子。这是一个典型的民生应用场景。电信诈骗随时随地都在发生,公安部反诈中心 2023 年的数据显示,破获诈骗案件超过 47.3 万件,预警指令达到 940 万,见面劝阻人次 1389 万,拦截金额 3288 亿。这是接到报警已破获的,还有大量未报警未破案的。大模型如何在这个场景中发挥价值,起到关键性作用呢?
,时长00:57
这段对话其实是 96110 反诈接警的真实对话场景。以往是靠接警人员手动记录,包括转账给谁,转出帐号是多少,报警人身份证号是多少等核心信息。这时候最紧急的事是止付,也就是制止转移支付,有的地方要用手写记录再联络银行止付。在大模型接警助手的辅助下,接警人员一边接电话,大模型同步把对话中的关键信息全部提取出来,记录到系统里,最短时间就可以发送到银行系统进行止付操作。这样的反诈接警过程,通过大模型优化,让接警到止付的周期从 30 分钟缩短到 2 分钟。这看似不是大模型应用的常规场景,但却切切实实守护了老百姓的钱袋子。

刚才说的过程看似非常简单,大家可以想像一下对大模型的挑战是什么?最大的挑战是准确度一定要高,因为这涉及到银行账号和接警人员与银行系统的操作,所以要花大量时间对优秀样本进行提炼,报案人员的口音也要用各种方式进行精调,最后才可以达到非常高的准确度。从实验室产品到真正可落地可应用的产品,这中间的距离中关村科金有深刻的亲身体会。我们做了大量的技术工作,才使得准确率达到可使用的状态。其实在更多的民生场景包括社区服务领域,社区民警、社工要做大量的服务性工作,如果可以用大模型提升他们的工作效率,这个世界会变得更加美好。
除了在服务方面的优化,还有一个非常典型的场景叫陪练。特别是像销售人员,对很多企业来说员工培训是刚需。大模型将企业培训物料自动消化并转化为剧本,生成一个数字人跟员工对话,帮助员工模拟更好地跟客户沟通。在沟通过程中大模型可以提示他应该说什么话。下面这个视频展示的是一个汽车营销人员的培训案例,将这款汽车相关介绍资料直接上传,就可以生成各种脚本,然后就可以模拟真实场景对练了。
,时长01:38
可以看到通过这种培训方式,可以把一个新人快速培训成一个专业的汽车销售人员。这个过程中综合运用了多种跨模态技术,包括大模型技术的生成,机器人陪练,高拟人的数字人模拟。通过运用智能陪练平台,销售线索留资的获取比例明显提升,达到 20%,剧本构建周期可以缩短 80%,员工学习效率提升 70%,能力评估的准确率提升到 30%。

最后一个是大模型赋能财富顾问的场景。很多金融机构的财富顾问要掌握大量专业知识跟客户交流沟通,而一名财富顾问每天可以接待的客户数量有限。如何帮助财富顾问提供更好、更贴心的服务就非常关键了。这个过程中,大模型的作用很多,包括通过数据的综合运用实现多元数据融合,比如市场资讯、企业年报、研报观点自动提取等。以及结合客户需求洞察和产品理解等实现客户意图挖掘,更好的匹配推荐理财产品。
,时长01:22
在这样的过程中,融合市场、产品文档、研究报告,包括企业内部的系统、数据进行连接。财富顾问在展业的过程中就有了一个百宝箱,相当于他身边有一个老师傅不断指导他如何做好工作。这个过程是财富顾问不断学习跟客户交流的过程,帮助他们更好地展业。目前在多家头部证券公司都在落地这样的应用。

在智能营销、智能客服、智能运营、知识管理几个场景,大模型的应用都是非常典型的。同时服务是非常重要的价值引擎。中关村科金提供全链条交付与服务的体系,包括咨询到平台构建、应用搭建,持续运营,全链条给客户提供专业、贴心的服务。

同时我们携手行业伙伴,搭建了非常丰富的场景应用,都是结合客户需求和痛点,结合客户的业务流程、业务系统进行端到端的打造。

此外,我们推出了面向中企出海的 Instadesk 平台,帮助客户针对出海业务量身打造全球联络中心,一站式服务全球客户。对海外客户来说社交媒体的渠道更重要,开放性更强。我们可以为企业官网、电商独立站提供多国语言的国际化服务,多媒体全渠道覆盖,以及安全合规保障。截至目前,我们已经提供 30 种以上的语言,覆盖两百多个国家线路、十多种国际化渠道,已成功服务了数十家出海中企以及海外直客。

最后,中关村科金期待把大模型的技术与应用,以及过去这些年的沉淀,输出给合作伙伴。携手千行百业,共赴行业大模型落地的奇点时刻。
相信只要我们面向客户的关键需求,回归商业本质,解决客户的实际问题,并且提供端到端的解决方案,做好贴身服务,坚定的与客户一路同行。中国也好,世界也好,大模型的落地一定会迎来一个全面开花的时刻。
大模型的落地从过去的 “暴风骤雨”,到现在的 “润物细无声”,我们相信踏实笃行者,虽远行必至。
#AI安全指数报告
Bengio参与的首个《AI安全指数报告》出炉,最高分仅C、国内一家公司上榜
安全话题,在人工智能(AI)行业一向备受关注。
尤其是诸如 GPT-4 这样的大语言模型(LLM)出现后,有不少业内专家呼吁「立即暂停训练比 GPT-4 更强大的人工智能模型」,包括马斯克在内的数千人纷纷起身支持,联名签署了一封公开信。
这封公开信便来自生命未来研究所(Future of Life Institute),该机构由麻省理工学院教授、物理学家、人工智能科学家、《生命 3.0》作者 Max Tegmark 等人联合创立,是最早关注人工智能安全问题的机构之一,其使命为 “引导变革性技术造福生活,避免极端的大规模风险”。
公开信息显示,生命未来研究所的顾问委员会成员阵容强大,包括理论物理学家霍金、企业家马斯克、哈佛大学遗传学教授 George Church、麻省理工学院物理学教授 Frank Wilczek 以及演员、科学传播者 Alan Alda、Morgan Freeman 等。

日前,生命未来研究所邀请图灵奖得主 Yoshua Bengio、加州大学伯克利分校计算机科学教授 Stuart Russell 等 7 位人工智能专家和治理专家,评估了 6 家人工智能公司(Anthropic、Google DeepMind、Meta 、OpenAI、x.AI、智谱)在 6 大关键领域的安全实践,并发布了他们的第一份《人工智能安全指数报告》(FLI AI Safety Index 2024)。
报告显示,尽管 Anthropic 获得了最高的安全性评级,但分数仅为 “C”,包括 Anthropic 在内的 6 家公司在安全实践方面仍有提升空间。

报告链接:https://futureoflife.org/document/fli-ai-safety-index-2024/
关于这份报告,Tegmark 在 X 上甚至一针见血地指出:Anthropic first and Meta last,即:Anthropic 的安全性最高,而坚持开源的 Meta 在这方面却垫底。但 Tegmark 也表示,“这样做的目的不是羞辱任何人,而是激励公司改进。”
值得一提的是,生命未来研究所在报告中写道,“入选公司的依据是其在 2025 年之前打造最强大模型的预期能力。此外,智谱的加入也反映了我们希望使该指数能够代表全球领先企业的意图。随着竞争格局的演变,未来的迭代可能会关注不同的公司。”
6 大维度评估 AI 安全
据介绍,评审专家从风险评估(Risk Assessment)、当前危害(Current Harms)、安全框架(Safety Frameworks)、生存性安全策略(Existential Safety Strategy)、治理和问责制(Governance & Accountability)以及透明度和沟通(Transparency & Communication)分别对每家公司进行评估,最后汇总得出安全指数总分。
维度 1:风险评估

在风险评估维度中,OpenAI、Google DeepMind 和 Anthropic 因在识别潜在危险能力(如网络攻击滥用或生物武器制造)方面实施更严格的测试而受到肯定。然而,报告也指出,这些努力仍存在显著局限,AGI 的相关风险尚未被充分理解。
OpenAI 的欺骗性能力评估和提升研究获得了评审专家的关注;Anthropic 则因与国家人工智能安全机构的深度合作被认为表现尤为突出。Google DeepMind 和 Anthropic 是仅有的两家维持针对模型漏洞的专项漏洞奖励计划的公司。Meta 尽管在模型部署前对危险能力进行了评估,但对自治、谋划和说服相关威胁模型的覆盖不足。智谱的风险评估相对不够全面,而 x.AI 在部署前的评估几乎缺失,大幅低于行业标准。
评审专家建议,行业应扩大研究的规模与范围,同时建立明确的可接受风险阈值标准,从而进一步提高人工智能模型的安全性和可靠性。
维度 2:当前危害

在当前危害维度中,Anthropic 的人工智能系统在安全性与信任度基准测试中得到了最高分,Google DeepMind 紧随其后,该公司的 Synth ID 水印系统被认可为减少人工智能生成内容滥用的最佳实践。
其他公司得分偏低,暴露出安全缓解措施的不足。例如,Meta 因公开前沿模型权重被批评,该做法可能被恶意行为者利用来移除安全防护。
此外,对抗性攻击仍是一个主要问题,多数模型易受越狱攻击,其中 OpenAI 的模型尤为脆弱,而 Google DeepMind 在此方面防御表现最佳。评审专家还指出,只有 Anthropic 和智谱在默认设置下避免将用户交互数据用于模型训练,这一实践值得其他公司借鉴。
维度 3:安全框架

在安全框架(Safety Frameworks)方面,所有 6 家公司均签署了《前沿人工智能安全承诺》,承诺制定安全框架,包括设置不可接受风险阈值、高风险场景下的高级防护措施,以及在风险不可控时暂停开发的条件。
然而,截至本报告发布,仅有 OpenAI、Anthropic 和 Google DeepMind 公布了相关框架,评审专家仅能对这三家公司进行评估。其中,Anthropic 因框架内容最为详尽而受到认可,其也发布了更多实施指导。
专家一致强调,安全框架必须通过强有力的外部审查和监督机制支持,才能真正实现对风险的准确评估和管理。
维度 4:生存性安全策略

在生存性安全策略维度,尽管所有公司均表示有意开发 AGI 或超级人工智能(ASI),并承认此类系统可能带来的生存性风险,但仅有 Google DeepMind、OpenAI 和 Anthropic 在控制与安全性方面开展了较为严肃的研究。
评审专家指出,目前没有公司提出官方策略以确保高级人工智能系统可控并符合人类价值观,现有的技术研究在控制性、对齐性和可解释性方面仍显稚嫩且不足。
Anthropic 凭借其详尽的 “Core Views on AI Safety” 博客文章获得最高分,但专家认为其策略难以有效防范超级人工智能的重大风险。OpenAI 的 “Planning for AGI and beyond” 博客文章则仅提供了高层次原则,虽被认为合理但缺乏实际计划,且其可扩展监督研究仍不成熟。Google DeepMind 的对齐团队分享的研究更新虽有用,但不足以确保安全性,博客内容也不能完全代表公司整体战略。
Meta、x.AI 和智谱尚未提出应对 AGI 风险的技术研究或计划。评审专家认为,Meta 的开源策略及 x.AI 的 “democratized access to truth-seeking AI” 愿景,可能在一定程度上缓解权力集中和价值固化的风险。
维度 5:治理和问责制

在治理和问责制维度,评审专家注意到,Anthropic 的创始人在建立负责任的治理结构方面投入了大量精力,这使其更有可能将安全放在首位。Anthropic 的其他积极努力,如负责任的扩展政策,也得到了积极评价。
OpenAI 最初的非营利结构也同样受到了称赞,但最近的变化,包括解散安全团队和转向营利模式,引起了人们对安全重要性下降的担忧。
Google DeepMind 在治理和问责方面迈出了重要一步,承诺实施安全框架,并公开表明其使命。然而,其隶属于 Alphabet 的盈利驱动企业结构,被认为在一定程度上限制了其在优先考虑安全性方面的自主性。
Meta 虽然在 CYBERSEC EVAL 和红队测试等领域有所行动,但其治理结构未能与安全优先级对齐。此外,开放源代码发布高级模型的做法,导致了滥用风险,进一步削弱了其问责制。
x.AI 虽然正式注册为一家公益公司,但与其竞争对手相比,在人工智能治理方面的积极性明显不足。专家们注意到,该公司在关键部署决策方面缺乏内部审查委员会,也没有公开报告任何实质性的风险评估。
智谱作为一家营利实体,在符合法律法规要求的前提下开展业务,但其治理机制的透明度仍然有限。
维度 6:透明度和沟通

在透明度和沟通维度,评审专家对 OpenAI、Google DeepMind 和 Meta 针对主要安全法规(包括 SB1047 和欧盟《人工智能法案》)所做的游说努力表示严重关切。与此形成鲜明对比的是,x.AI 因支持 SB1047 而受到表扬,表明了其积极支持旨在加强人工智能安全的监管措施的立场。
除 Meta 公司外,所有公司都因公开应对与先进人工智能相关的极端风险,以及努力向政策制定者和公众宣传这些问题而受到表扬。x.AI 和 Anthropic 在风险沟通方面表现突出。专家们还注意到,Anthropic 不断支持促进该行业透明度和问责制的治理举措。
Meta 公司的评级则受到其领导层一再忽视和轻视与极端人工智能风险有关的问题的显著影响,评审专家认为这是一个重大缺陷。
专家们强调,整个行业迫切需要提高透明度。x.AI 缺乏风险评估方面的信息共享被特别指出为透明度方面的不足。
Anthropic 允许英国和美国人工智能安全研究所对其模型进行第三方部署前评估,为行业最佳实践树立了标杆,因此获得了更多认可。
专家是如何打分的?
在指数设计上,6 大评估维度均包含多个关键指标,涵盖企业治理政策、外部模型评估实践以及安全性、公平性和鲁棒性的基准测试结果。这些指标的选择基于学术界和政策界的广泛认可,确保其在衡量公司安全实践上的相关性与可比性。
这些指标的主要纳入标准为:
- 相关性:清单强调了学术界和政策界广泛认可的人工智能安全和负责任行为的各个方面。许多指标直接来自斯坦福大学基础模型研究中心等领先研究机构开展的相关项目。
- 可比较性:选择的指标能够突出安全实践中的有意义的差异,这些差异可以根据现有的证据加以确定。因此,没有确凿差异证据的安全预防措施被省略了。
选择公司的依据是公司到 2025 年制造最强大模型的预期能力。此外,智谱的加入也反映了该指数希望能够代表全球领先公司的意图。随着竞争格局的演变,未来可能会关注不同的公司。

图|评价指标概述。
此外,生命未来研究所在编制《AI 安全指数报告》时,构建了全面且透明的证据基础,确保评估结果科学可靠。研究团队根据 42 项关键指标,为每家公司制作了详细的评分表,并在附录中提供了所有原始数据的链接,供公众查阅与验证。证据来源包括:
- 公开信息:主要来自研究论文、政策文件、新闻报道和行业报告等公开材料,增强透明度的同时,便于利益相关方追溯信息来源。
- 公司问卷调查:针对被评估公司分发了问卷,补充公开数据未覆盖的安全结构、流程与策略等内部信息。
证据收集时间为 2024 年 5 月 14 日至 11 月 27 日,涵盖了最新的人工智能基准测试数据,并详细记录了数据提取时间以反映模型更新情况。生命未来研究所致力于以透明和问责为原则,将所有数据 —— 无论来自公开渠道还是公司提供 —— 完整记录并公开,供审查与研究使用。
评分流程方面,在 2024 年 11 月 27 日完成证据收集后,研究团队将汇总的评分表交由独立人工智能科学家和治理专家小组评审。评分表涵盖所有指标相关信息,并附有评分指引以确保一致性。
评审专家根据绝对标准为各公司打分,而非单纯进行横向比较。同时,专家需附上简短说明支持评分,并提供关键改进建议,以反映证据基础与其专业见解。生命未来研究所还邀请专家小组分工评估特定领域,如 “生存性安全策略” 和 “当前危害” 等,保证评分的专业性和深度。最终,每一领域的评分均由至少四位专家参与打分,并汇总为平均分后展示在评分卡中。
这一评分流程既注重结构化的标准化评估,又保留了灵活性,使专家的专业判断与实际数据充分结合。不仅展现当前安全实践的现状,还提出可行的改进方向,激励公司在未来达成更高的安全标准。
#从伯克利到PromptAI创业,发明创造下一代视觉智能
对话肖特特
通用语言模型率先起跑,但通用视觉模型似乎迟到了一步。
究其原因,语言中蕴含大量序列信息,能做更深入的推理;而视觉模型的输入内容更加多元、复杂,输出的任务要求多种多样,需要对物体在时间、空间上的连续性有完善的感知,传统的学习方法数据量大、经济属性上也不理性...... 还没有一套统一的算法来解决计算机对空间信息的理解。
2023 年,Meta AI 发布了首个 "Segment Anything Model" (SAM),该模型无需专门的类别标注,而是通过交互的方式对真实世界中动态的任意物体进行分割。其分割方法通用,可对不熟悉的物体和图像进行零样本泛化,体现了对空间信息的处理和理解能力。这项工作获得了 ICCV 2023 Best Paper Honorable Mention。
来自加州大学伯克利人工智能实验室 (BAIR) 的肖特特博士是该项工作的主要参与者之一。他评价说:“以往我们通过增加类别来提升模型效果,但 SAM 放弃了旧时代的很多枷锁,放弃了特定的类别标注的方式,提升了模型对空间的理解能力。”
这为 CV 新时代打开了一道门。
而不同于上一代视觉智能,新时代下产生的空间智能最大的场景体现在具身智能的应用上,它让机器人、自动驾驶、无人机等硬件设备拥有像人类的眼睛一样,感知世界,并产生与世界互动的行动力。
这就是 “看见不只是看见,更是理解到行动” 的智能产生链条。
肖特特于 2015 年以优异成绩(summa cum laude)获得了北京大学智能科学专业的理学学士学位,后于 2019 年在加州大学伯克利分校计算机科学系获得博士学位,并曾在 Facebook AI 研究院从事研究工作。作为年轻一代人工智能学者的代表样本,他的多篇重要工作发表在包括《Science Robotics》、CVPR、ICCV、ECCV 和 NeurIPS 等主要期刊和会议上。
他认为,未来 5-10 年 CV 要解决的是真实世界的问题,让 AI 有人类一样对物理空间的感知能力。
2023 年,特特没有继续留在 Meta,而是选择了人生新路径,成立 PromptAI,致力于打造通用视觉智能平台,为机器赋予类人的视觉感知能力。
成立一年时间,PromptAI 获得来自 UC Bekerley Pieter Abbeel 的投资与 Trevor Darrell 的技术支持。两位教授同为伯克利人工智能实验室(BAIR)联合主任,Trevor Darrell 教授在计算机视觉领域极大推动了大规模感知的创新研究,而 Pieter Abbeel 教授是深度强化学习应用于机器人领域的先驱人物。
公司其他成员都是十分年轻的 AI 研究员与工程师,在算法架构、产品运营、工程管理上拥有杰出经验。
而追问 What's next 的精神,是 PromptAI 这群年轻的 AI 科学家找到问题答案的关键。
永远在提问 What’s next?
BV:PromptAI 在解决什么问题?
特特:发明创造跟人一样有感知能力的空间智能模型,让机器和算法成为人类额外的眼睛。
BV:为什么是 “发明创造”?很少听到这个词。
特特:“发明创造” 一定是技术驱动,但技术驱动的东西不一定是 “发明创造”。举个例子,在互联网时代,我们可以用已有的互联网技术来降本增效,这中间产生很多行业机会。这受到新技术的驱动,但并不是 “发明创造”。
而目前在计算机视觉领域,新的方式还没有出现,我们希望发明创造下一代视觉技术,并定义新的人与机器交互的方式。

图片来源:公司官网
BV:是什么时候产生创业想法的?
特特:我们看到了 AI 给人类社会带来的这个机会:人类能看到的东西,计算机也能看到。计算机能把人类从繁琐无聊的工作、任务中解脱出来,拥有更多的时间和自由去做更喜欢、更擅长的事情。
我觉得 AI 在成熟,它可以变成我们额外的眼睛帮助我们更高效、更快乐地生活。这是我们创业开始时,在社会应用上的 insights,当然,除此之外还有技术变革上的 insights。
BV:那技术上推动你创业的原因是什么?
特特:在 PhD 后期,看到视觉领域从 MAE(注:《Masked Autoencoders》,这项工作来自 Meta AI,采用无监督学习的方式,提高模型的泛化能力和鲁棒性。)到 SAM(注:《Segment Anything Model》)的变化,用通用视觉模型去解决大量不同问题是可行的。谷歌的前 CEO 埃里克・施密特在《How Google Works》中,就曾强调技术洞见的重要性,这是产品开发和公司成长的源动力。
带着应用和技术上的想法,我找到我在 UC Bekerley 的导师 Trevor Darrell 教授聊,他很认可也很支持。后来又吸纳了更多团队成员,大家都共享一个理念:新一代视觉技术的应用机会以及由此产生的空间智能对人类社会的价值。
BV:是什么驱使你想到这种新范式?
特特:往回看,研究者总是在问:What’s next?这是个非常自然而发的问题。
What’s next 问的内容有很多种,一种是目前现有的技术能解决哪些任务,带来哪些能力上的提升。比如视觉分类研究中,现在能做到准确率 95%,我能不能推到 97%?推到 99%?
而另一种是,下一代技术是什么样子?我们利用下一代技术能够做什么事情?比如对数据集来说,原来只能看到 20 类物体,后来 80 类,后来 200 类,再往后,能否看到他们其他维度的特性?看到材质、结构、组成部分?因为很难定义类别,能否干脆用自然语言描述物体?这是在研究中水到渠成会思考到的问题。
这两种问题一定是交织进行、同时发生的。当前技术的深挖是很有必要的,不然很难看到他的影响力的扩散。但有时候这个技术不一定是最优解,这个时候就需要我们跳出来,去问问有没有新的解决方案。
而通用视觉模型,就是面对 CV1.0 时代中的各种问题而提出的新的解决方案。
肖特特参加 2024 智源大会,分享《A Real-World Approach to Intelligence》
BV:这种 What’s next 既可以问是否加速了过去的应用,也可以问是否创造了新的范式。
特特:是的。伟大的公司都想要知道 “what's next”,比如 Google 用了新的技术方式去管理世界上五花八门的知识;Apple 创造了新的人与计算机交互的方式,让个人电脑走进我们的生活里;英伟达实现了加速计算,用新的硬件形态去解决计算领域的问题。
在研究和创业中,一旦停下对未来技术的追问,做的事情就会变得平庸,囿于目前已经掌握到的技术,只解决眼前有限的问题,而无法找到下一代技术,解决更多问题。
这种追问的精神,就是我们的团队信仰。
CV 变革,智能产生:1.0-2.0
BV:什么是 CV1.0 ?解决了哪些任务?
特特:CV1.0 解决专一的、特定的任务,它在经济属性上并不是很理性。
2012 年出现 AlexNet,这个机器学习范式,对图片识别的能力大大超过了其它技术路线,可以用在自然语言处理、推荐系统、计算机视觉等多个方向上,瞬间激发了 AI 的应用价值。互联网产品可以利用这种范式来学习图片、视频当中的特质,来更好地提升用户体验;医疗上会利用机器学习来做诊断;工厂里可以做各种质量检测;城市管理当中还可以分析人的轨迹、流向。
但这些任务之间不能互通,比如说,A 工厂生产手机屏幕,需要一套针对划痕检测这个单一任务的视觉系统;而 B 工厂生产汽车,也需要一套检测划痕的视觉系统。但此划痕非彼划痕,这是两套完全不一样的检测系统。
总结下来,我们一直在解决同一个问题,就是感知。这个大问题在应用中会被细分为无数细分问题,比如检测材质、大小、位置、组成部分等等。在 CV1.0 时代,这些问题非常细,并且每个场景对智能的需求是有限的,我们解决了一个子问题,却没有能力解决另一个子问题。回到划痕检测问题,就算有一个模型能够识别世界上所有的划痕,但你却识别不了世界上所有的杯子。如此以往,这个模型就非常的单一、不完善,实现难度也很大,经济投入也会很多。
BV:这种方法跟人类感知物体的方式是不一样的。这是不是也回答了:为什么过去的 CV 技术没有出现很多解决通用行业问题的产品?
特特:是的。
另外,CV1.0 与人类智能相比,“数据输入” 的模式也并不相通。打个比方,对 CV1.0 来说,需要标注很多数据,让计算机知道这个杯子是不锈钢的,另一个是玻璃的。如果我再加一类塑料杯,那就又要标注成千上万的这类数据。
但是回过头想,难道我真的需要 “见到” 成千上万的玻璃杯,才能知道这个是玻璃杯吗?人类并不是这样做判断的,我们用过玻璃杯,或者是见过玻璃制品,在不需要众多 “数据输入” 的情况下就可以推断出来。
BV:正因为这样,我们需要大模型的能力。
特特:大模型的目的不是把模型做大,价值并不在于加参数。回到刚才识别三种杯子的例子,你可以做出一个上亿级参数的模型来完成这个任务,但仍存在无法解决更多任务的瓶颈。
Foundation Model 和 Pre-training 的好处是,把不同的信息源都学习进来,我们可能并不知道模型从哪里学到的关于 “玻璃” 的概念,但当它习得这个概念之后,会把这个概念抽象出来,并且能把这个知识运用到未来的预测和感知当中。这个是大模型和过去的技术不一样的地方。
BV:CV 2.0 有哪些不同?
特特:区别在于,第一是让 AI 具备和人一样感知世界的智能,解决真实世界的问题;第二是解决开放世界中通用任务问题;第三是具有人的常识能力。
BV:从 CV1.0 到 2.0 的分水岭有哪些?
特特:第一个关键节点,是 2021 年 OpenAI 的 CLIP 工作(《Learning Transferable Visual Models From Natural Language Supervision》),它讲的是如何 “以语言作为监督” 学习视觉信息。过去,如果我们用预定类别的方式来做识别,这个过程跟语言是没有关系的。而这篇工作提到,不同的概念在语义上有相关性,我们可以从人类的语言中获得这种相关性。思路就是,让模型去学习图片对应的描述,学习图片的视觉语义信息。
但这个 idea 即使在当时来看也并不新鲜,它独特性在于,用更大的数据量和计算量,用几百个 million 的数据来做训练,并且这些数据能很容易从互联网上获取。之所以有这个想法,是因为这项工作来自 OpenAI,当时已经开始做 GPT,他们看到了 scale 后模型的变化和影响,这彻底改变了我们对视觉和语言之间的认知。
再往后,2023 年 Meta AI 发布的 SAM(《Segment Anything Model》)相关工作也是这个转变过程中的 milestone。

SAM 是 CV 旧时代的最后一篇工作,新时代的第一篇工作。原因是,它要解决的是传统的视觉分割问题,这是一个旧问题。高等生命的视觉系统都有对物体分割的能力,这个能力非常重要,但实现 AGI 不会通过完美解决分割问题而实现。
尽管如此,SAM 放弃了旧时代的很多枷锁,放弃了特定的类别,解决了通用物体分割的问题。以椅子举例,椅子里有很多零部件,零部件里面可能还有细分的零部件,那么到底什么才是这个椅子呢?在 SAM 中,我们无需对椅子及其零部件进行标注,而是通过交互的方式对任意物体进行分割,找到我们希望得到的部分。
这为我们指明了一个方向:在一个模型下,一个通用的视觉模型去解决大量不同问题是可行的。这就是为什么我相信这项工作是为 CV 新时代开了一道门的原因。
比如,分割人像和分割文字,是两套系统。但在 SAM 中,是一套系统中需要解决的两个任务。那么思路打开之后,这套系统能解决的问题就很多了,有些人用它来去分割卫星的图像,有人其实用它来分割古书籍里面的一些文字,还可以去分割微生物体...... 这个模型完全没有见过古书字,但依靠良好的泛化性,可以再零样本情况下取得很好的效果。
BV:那下一个 10 年 CV 要去解决哪些问题?
特特:未来 5-10 年 CV 要解决的是真实世界的问题,让 AI 像人一样有感知世界的能力。但我们的真实世界是连续的视觉信息,不是单帧的,为了感知更多真实世界的内容,我们需要更强的视频理解能力。这里也有很多难题,比如说如何去表征一个视频?如何让模型去理解时间的概念?理解动作在时间上的连续性?理解物体在空间中的具体位置、远近大小?
假如有一个人经过一个障碍物,在单帧系统中,计算机就会感知不到被挡住的人;但如果是视频系统,就会捕捉到人经过障碍物前后的信息,“看” 到人在障碍物后面。
计算机视觉的金标准是人的感知能力。这个不光是学术领域的下一代问题,也是工业界下一代 AI 的经济价值所在的地方。
BV:感知和 “世界模型” 的联系是什么?“世界模型” 的本质是什么?
特特:当有了对真实世界更多的理解之后,对感知到的信息做未来的预测,这一套系统就是 “世界模型”。“世界模型” 是推理的一种形式,这种推理不仅包括逻辑推理,还包括一些 low-level (比如在像素上)的推理。例如,如果我推了球一下,这个球下一秒在视频里会显示成什么样子?对球的运动的推理,就是 “世界模型” 的体现。
这样的 “世界模型” 固然理想,但它很难构建,甚至人也不会用这样的推理方式来完成任务。
其实世界模型不是一个全新的概念,麦卡锡、明斯基和香农等科学家在 1956 年达特茅斯会议上谈论人工智能开端的时候,就提到了 Abstraction(注:抽象指的是 AI 系统对现实世界的简化和概念化表示,这种表示使得 AI 能够进行状态估计、预测、模拟、推理和决策,从而更好地与外部环境互动)。Abstraction 是比世界模型更广泛的定义,世界模型是实现 Abstraction 的一种构想,但不会是唯一的一种方案。我认为它甚至大概率不是未来成功实现智能的方式 —— 智能体对常识的推理能力应该是涌现的。

达特茅斯会议主要参与者及议题
BV:当 AI 能更好地理解视频、建立 “世界模型”,是否就拥有了空间上的智能能力?
特特:这个问题的关键在于,理解是智能的原因还是智能的现象?
如果理解是智能的现象的话,我们看到一个智能体,它就应该具有理解世界的能力;但如果理解是智能产生的原因,那么只有它学会了对世界的预测、掌握了世界模型之后,它才能成为智能体。
生物进化是一个很复杂的过程,智能的出现在进化的角度是一个相辅相成的过程。理解能力越强,智能体就越强大,智能体越强大,它在进化上就更占优势,就会有更好地理解能力。
下一代 AI 一定是对世界有理解、推理和搭建 “世界模型” 的能力的,但下一代的 AI 未必会因为学习 “世界模型” 而产生。
BV:如果学习推理未必产生智能,那么智能如何产生?
特特:把 AI 部署到真实世界中去,在与世界的互动中获得空间智能。
如果一套系统只存活在数字世界,没有办法在真实世界中一览天下,那它不一定会成为真正的智能体。
就像具身智能机器人,从多模态环境里学到各种各样的常识,获得预测能力。比如踩到了石头会摔倒,从手中掉了的杯子可能会摔碎。我们很难只通过训练世界模型的方式产生下一代智能,所以我们要像滚雪球一样,让智能体学到越来越多的常识,做更多的任务。说不定有一天智能体可以把自己送到月球上去,自己干活工作,然后回来告诉你它干了什么事情。
BV:智能是在智能体跟环境的交互过程中产生、涌现。这样来看,空间智能的产生路径就很清楚了。
特特:是的,第一步是通过传感器观察、理解物理世界,如果没有办法观察物理世界,就没有办法理解物理世界。
第二步,跟物理世界做交互,知道如何做抓取、走路、避障、操作物体。
因此,我们需要通用视觉模型来更好地理解感知世界,理解时间上、空间上的运动性等特征;另一个就是 Embodied AI,让机器跟环境交互,在多模态的真实世界里产生智能。
比如,在与 Ilija Radosavovic 合作的《Real-World Robot Learning with Masked Visual Pre-training》中,我们通过在大规模真实世界图像和视频数据上进行自监督视觉预训练,预训练后需要在实际的任务中做小规模 finetune,使机器人在现实世界任务中学习到丰富的视觉表示,帮助机器人更好地理解和感知现实世界中的三维空间信息,并在复杂环境中做出合理的决策和行动。
做 AI 的人怎么看艺术生成?
BV:生成呢?在智能产生的过程中,生成到底以什么形式出现?
特特:这个是目前大家没有定论的事情。这与人的想象是不同的,人的想象是抽象地去想象可能会发生的事情;而现在的生成式 AI,更多是以在细节上、以像素级别的水准,把内容给生成出来。
大多数人都不是画家,我的画画的艺术能力极为落后,但我还是有艺术上欣赏的能力。
回到达特茅斯会议上大家对人工智能的憧憬。大家认为生成其实是 creativity and randomness,计算机不是完全按照既定的程序去执行每一个指令。就像人类一样,无论是我们的思维还是动作,都不一定是在执行一个特定的指令,因为我们有创造力和想象力。所以我觉得生成是智能的一个重点,但是具体能不能像画家一样把它的艺术性画出来,就是另一回事。
BV:“热爱艺术人” 和 “搞技术的人” 这两个标签的叠加下,让你对 “AI 是否能创造艺术” 这个话题有什么不同的感受?
特特:音乐、美术、电影,这些在我的生命中是不可或缺的。
第一,艺术是关于未来的,不是关于过去的,无法用过去已有的信息来训练 “生成” 艺术。艺术需要经历和感受,是人对外在世界和内在世界的抽象理解。
目前,AI 的价值更多的体现在生产工具的属性上,我们可以通过 AI 来让生活更便捷、安全、理想,解放我们的时间和生产力。但 AI 没有感情经历,没有生活经历,跟人类的悲喜并不相通,所以 AI 很难去感受艺术,也就很难生成艺术。

法国印象派代表人物克劳德・莫奈《日出印象》
回过头来看,艺术之所以是艺术,很多时候是跟观察者有关系的,一千个人里有一千个不同的哈姆雷特。当人们欣赏画作、音乐的时候,会从中得到共鸣,感受到新的东西。
第二,艺术和内容制作很难区分开来。艺术是一个复杂的过程,其中包括创造 idea 部分,也包括制作内容部分。
比如说,画家画画,雕塑家雕刻作品,剧作家创作剧本,我们很难把创造 idea 和制作内容区分开来。这些艺术行为不仅是一个灵感想法的产生,更重要的是要把灵感想法串起来、表现出来、制作出来,这中间需要很多 “体力活”。比如罗丹的每一个雕塑作品,都经历了艺术家大量绘画,试验,和完善。当我们用写 prompt 的方式去生成一个内容,我们只是利用 AI 制作了内容,不一定是创造了艺术。
第三,我们也要把艺术和娱乐也要区分开来。当我们听到一段旋律或是看到一段影像,觉得很好看、很过瘾,但不代表它激发我产生了认知上的改变、情绪上的共鸣、对世界新的理解。
目前 AI 更多是在生成娱乐,而不是艺术。
故事另一面
BV:科研路上,哪些人给你带来技术上的启发?
特特:2018 年,我在孙剑老师的指导下参加 COCO 竞赛(注:Common Objects in Context),题目就是如何做出更强大的物体检测器。我们用了 256 张 GPU 去训练这个模型,这个数量级的 GPU 让模型的收敛速度非常快,但却很 “非主流”。因为当时的主流观点是模型并非越大越好,而我们的方案甚至早于第一代 GPT。孙剑老师问我们:这个东西的边界、上限在哪里?模型效果好的背后原因到底是什么?
这个启发非常重要:你要不停的问为什么是这样,而不是那样?传统的方式就一定是对的吗?有没有下一代解决方案?授人以鱼不如授人以渔,总有问题是老师解决不了的,总有问题是需要年轻的头脑去思考的。而这些思考对刚入门的年轻科研者来说是非常重要的一课,能让我们的工作做的更扎实。
图中左三为肖特特,右二为孙剑老师
BV:伯克利人工智能实验室(BAIR)给你留下什么印象?
特特:BAIR 不是一个 lab,而是一个很多方向的 super lab 联合体。整个科研楼还挺挤挺小的,很多教授就挤在角落里没有窗户的办公室里搞科研。
BAIR 有很多方向,在计算机视觉领域有传统感知,有 3D 重建,也有图片和视频生成,还有视觉和语言中间的 understanding。其他还有 NLP、robotics、AI 伦理、AI for Science 等领域方向。BAIR 成立的背景,就是希望学生们从不同的方向上做交流,在学科内交叉领域相互碰撞。理解、感知、思考、推理、操作、运动这些都是 AI 的一部分,更广一点来看,我们跟心理学、神经科学、行为科学也都有关系。
我的教授 Trevor Darrell 是 BAIR 的 co-founder 和 Founding Director。Trevor Darrell 教授最大的特点就是包容,在一个有很大变化的研究领域,研究者需要自由的空间去探索感兴趣的问题。很多时候我们的发现发明不一定是大家都认可的技术路线,但我们要有空间去追逐这样不被认可的技术想法。
在 BAIR Lab,从 2021 年开始,我与 Ilija Radosavovic 合作了多篇工作,从《Masked Visual Pre-training for Motor Control》到《Real-World Robot Learning with Masked Visual Pre-training》,以及《Real-world Humanoid Locomotion with Reinforcement Learning》。
我们原来都是学习计算机视觉的,但都认为如果没有机器在真实世界的部署,AI 的发展就会陷入瓶颈。之后我们放弃了原有的研究舒适圈,进入到没接触过的 robotics 领域,希望探索下一代通用人工智能。
图片来源:Berkeley Artificial Intelligence Research 官网,首排左四为肖特特
BV:创业之后一定有很多团队建设上的思考。组建团队是否是在找 CEO 的 “复制粘贴”?
特特:我们团队非常多元。有刚从学校出来的 PhD,也有工业界工作 20 多年的成员,还有大学辍学自学设计来做产品的成员。我们在组建团队的时候,并不是看这个人跟我的经历背景、技术观点、对未来的想法 “有多像”,而是看他是否能独立地带来不同的观点,提出不同的声音。因为我们要做一个新的东西,既然是新的,那它就没有对错之分。
Debate 是我们的团队文化之一。Debate 的价值不是输赢,不见得每一个技术想法我们都需要达成一致。而越是不一致,我们就可以去讨论更多的 corner cases。
我也很鼓励大家在职业早期到创业公司经历一番,锻炼自己定义问题的能力,以及在小团队工作承担更多责任的能力。
BV:如今,AI 领域涌现出新一代年轻有为的创始人。空间智能是下一代 AI 创业者的机会吗?
特特:我相信所有的新的技术都会带来新的改变,不只是空间智能。而新一代创业者只是对新一代技术的理解会更深刻一些。
但是更重要的是,新一代创业者有没有去创造新事物的激情,有没有对旧世界、旧方法体系的不甘,有没有问出 what's next 的勇气。
BV:看到你朋友圈有分享过一句歌词:What shall be our legacy?What will our children see?你更希望留给世界、留给下一代技术人些什么呢?
特特:我觉得每一代的人都有每一代人的责任。
个体的总和就是世界。我觉得各行各业的人应该对工作有热情,因为我们的工作就是对理想世界的塑造,都会最终对世界产生影响。
同时,我们技术人就像是新世界的守门人,也要保护技术不被滥用。开发和保护,是相辅相成的。这不是两拨人的责任,是同一拨人的责任。
BV:那最后一个问题:为什么叫 PromptAI?
特特:Maybe leave it for the future. 大家现在都不知道苹果公司的苹果为什么少了一块,对吧。永远不满足于目前的定义,永远在提出下一个问题的路上。
#「小模型时代」让奥特曼预言成真
Ilya错了,预训练没结束!LeCun等反击
Ilya「预训练结束了」言论一出,圈内哗然。谷歌大佬Logan Klipatrick和LeCun站出来反对说:预训练还没结束!Scaling Law真的崩了吗?Epoch AI发布报告称,我们已经进入「小模型」周期,但下一代依然会更大。
最近,Ilya在NeurIPS 2024中宣布:预训练结束了!瞬间一石激起千层浪。
在他看来,数据如同化石燃料般难以再生,因此训练模型需要的海量数据即将枯竭。
作为前OpenAI首席科学家,Ilya的这番话,有可能影响之后数十年的AI发展方向。
不过,预训练真的结束了吗?
最近,几位圈内大佬,就公开站出来质疑和反对Ilya了。
谷歌大佬Logan Kilpatrick是这样内涵Ilya的:认为预训练结束,恐怕是因为你缺乏想象力。
前Meta具身智能团队的高级总监Dhruv Batra也站出来共同表示:Ilya错了!
在他看来,人类的数据还没有用完。
我们只是用完了人类书写的文本而已,但我们拥有的视频数量,依然远超我们的处理能力,目前只是尚未解决视觉领域的预训练问题罢了。
的确,要知道,网络上的文本公共数据,毕竟只是冰山一角而已。
我们除了文本,还能对音频、视频、图像进行预训练,甚至可以把视觉、嗅觉、触觉、平衡和传感器这些人类进化出来的功能赋予机器。
而如果模型真的可以学习的话,那数据或许确实是无所不在。
左右滑动查看
有人则充分放分想象:如果预训练能和生物相连,那它的确永远不会结束。
Scaling Law和预训练到底有没有撞墙?
种种事件表明,我们已经站在了一个发展路线的分水岭。
Ilya、LeCun甚至奥特曼,都已经感觉到:目前的发展路线不能再延续下去了,我们亟需探索新的出路。
早期,Ilya曾是暴力Scaling的早期倡导者之一,认为通过增加数据和算力来「scale up」,能显著改善模型性能。
但现在,Ilya已经承认自己曾经的想法错了,并透露SSI正在研究一种全新的替代方法,来扩展预训练。
相较之下,外媒SemiAnalysis则在一篇关于o1的深度报道中指出——scale的维度远不止预训练,Scaling Law仍将继续下去。
最近,Epoch AI研究员的一篇长文,更是直观地展示了这个「矛盾」的现象。
从2017年Transformer架构诞生到GPT-4发布,SOTA模型的规模一直在变大,但增幅在变小。
- 从GPT-1到GPT-3,用了2年时间,模型参数量从1.17亿增加到1750亿,增加了1000倍
- 从GPT-3到GPT-4,用了2年9个月,模型参数量从1750亿增加到1.8万亿,增加了10倍
而到了2023年,这一趋势直接发生了逆转。
据估计,当前SOTA模型的参数可能要比GPT-4的1.8万亿小一个数量级!
- GPT-4o大约为2000亿参数
- Claude 3.5 Sonnet约为4000亿参数
但有趣的是,下一代模型的规模,可能又会重新超过GPT-4。
当今SOTA模型最大只有约4000亿参数
尽管许多实验室没有公开模型架构,Epoch AI的研究员依然从蛛丝马迹中发现了线索。
首先是开源模型的证据。根据Artificial Analysis的模型质量指数,当前最佳的开源模型是Mistral Large 2和Llama 3.3,分别拥有1230亿和700亿参数。
这些稠密模型,架构与GPT-3相似,但参数更少。它们总体的基准表现超过了GPT-4和Claude 3 Opus,且由于参数更少,它们的推理成本和速度也更优。
对于闭源模型,尽管我们通常无法得知参数详情,但可以根据推理速度和收费推测它们的大小。
仅考虑短上下文请求,OpenAI提供的2024年11月版本GPT-4o,每个用户每秒100-150个输出token,收费每百万输出token 10美元;而GPT-4 Turbo每秒最多大约55个输出token,费用是每百万输出token 30美元。
显然,GPT-4o比GPT-4 Turbo更便宜且更快,因此它的参数可能比GPT-4小得多。
另外,我们还可以使用推理经济学的理论模型,来预测GPT-4在H200上进行推理的成本。
假设使用H200进行推理的机会成本为每小时3美元,下面的图显示了不同价格点下,GPT-4及其假设缩小版的生成速度。
总体来说,为了让模型每秒生成100个以上的token并且能够流畅服务,模型需要比GPT-4小得多。
根据上图,假设OpenAI的价格加成大约是GPU成本的八分之一,GPT-4o的参数量可能在2000亿左右,虽然这个估计可能有2倍的误差。
有证据表明,Anthropic的Claude 3.5 Sonnet可能比GPT-4o更大。Sonnet每秒生成约60个token,每百万输出token收费15美元。这速度在优化设置下接近原版GPT-4的收支平衡点。
不过,考虑到Anthropic API可能加价不少,Sonnet参数规模仍显著小于GPT-4,估计在4000亿左右。
总体来看,当前前沿模型的参数大多在4000亿左右,像Llama 3.1 405B和Claude 3.5 Sonnet可能是最大的。
虽然对于闭源模型的参数估计有很大的不确定性,但我们仍然可以推测,从GPT-4和Claude 3 Opus到如今最强的模型,规模缩小的幅度可能接近一个数量级。
为什么会这样?
针对这一现象,Epoch AI认为有四个主要原因:
1. AI需求爆发,模型不得不瘦身
自ChatGPT和GPT-4发布以来,AI产品需求激增,服务商面临的推理请求大大超出预期。
此前,从2020年到2023年3月,模型训练的目标是最小化训练计算量,即在固定的能力水平下,花费尽可能少的计算资源完成训练。Kaplan和Chinchilla的Scaling Law建议,随着训练计算量的增加,模型规模也应扩大。
随着推理成本占据支出的大头,传统法则的适用性受到了挑战。相比scaling模型规模,在更多训练数据(token)上训练较小的模型反而更划算,因为较小的模型在推理阶段的计算需求较低,能够以更低的成本服务用户。
比如,从Llama 2 70B到Llama 3 70B,虽然模型参数规模没有显著增加,但模型的性能却显著提升。
这是因为通过过度训练(在更多数据上训练较小的模型),可以让模型在保持小规模的同时,表现得更强大。
2. 蒸馏,让小模型更能打
实验室还采用了「蒸馏」方法,从而让更小的模型表现得更强大。
蒸馏指的是让小模型模仿已经训练好的大模型的性能。
蒸馏方法有很多种,其中一种简单的方法是使用大模型生成高质量的合成数据集来训练小模型,而更复杂的方法则需要访问大模型的内部信息(如隐藏状态和logprobs)。
Epoch AI认为,GPT-4o和Claude 3.5 Sonnet很可能是从更大的模型蒸馏得到的。
3. Scaling Law的转变
Kaplan Scaling Law(2020)建议,模型的参数量与训练用的token数量(即数据量)应保持较高的比例。简单来说,当你增加训练数据时,应该相应增加模型的规模(参数量)
而Chinchilla Scaling Law(2022)则偏向于更多训练数据和更少的参数。模型不必越来越大,关键在于训练数据的规模和多样性。
这个转变导致了训练方式的改变:模型变得更小,但训练数据更多。
从Kaplan到Chinchilla的转变,并非因为推理需求的增加,而是我们对如何有效scaling预训练的理解发生了变化。
4. 推理更快,模型更小
随着推理方法的改进,模型生成token的效率和低延迟变得更加重要。
过去,判断一个模型「足够快」的标准是看它的生成速度是否接近人类的阅读速度。
然而,当模型在生成每个输出token时需要先推理出多个token时(比如每个输出token对应10个推理token),提升生成效率就变得更关键。
这推动了实验室,像OpenAI,专注于优化推理过程,使得模型在处理复杂推理任务时能够更高效运行,也因此促使它们缩小模型的规模。
5. 用AI喂AI,成本更低
越来越多的实验室开始采用合成数据作为训练数据来源,这也是促使模型变小的原因之一。
合成数据为训练计算scaling提供了一种新的途径,超越了传统的增加模型参数量和训练数据集大小的方法(即,超越预训练计算scaling)。
我们可以生成将来用于训练的token,而不是从互联网上抓取它们,就像AlphaGo通过自我对弈生成训练数据一样。
这样,我们可以保持Chinchilla Scaling Law下计算最优的token与参数比例,但通过生成数据时为每个token投入更多计算,从而增加训练计算量而不增加模型大小。
奥特曼:参数规模竞赛即将终结?
2023年4月,OpenAI发布了当时最强的,同时也是第一款未公开参量的模型GPT-4。
之后不久,CEO奥特曼曾预言了模型参数竞赛的终结:围绕模型参数量的竞赛,就像历史上对更高处理器主频的追求,是一个死胡同。
那么,前沿模型的规模会不会越变越小呢?
简短的答案是——可能不会。但也很难说是否应该期待它们在短期内变得比GPT-4更大。
从Kaplan到Chinchilla的转变是一次性的,因此我们没有理由期待它继续让模型变小。
GPT-4发布后的推理需求增长也可能快于未来推理支出的增长速度。且合成数据和scaling计算并非每个实验室都在采纳——即使有高质量的训练数据,对于非常小的模型而言,能够取得的成就可能非常有限。
此外,硬件的进步可能会促使更大的模型变得更优,因为在相同预算下,大模型通常表现更好。
较小的模型在推理时可能表现更差,尤其在长上下文和复杂任务上。
未来的模型(如GPT-5或Claude 4)可能会恢复或稍微超过GPT-4的规模,之后是否继续缩小规模难以预料。
理论上,当前硬件足以支持比GPT-4大50倍、约100万亿参数的模型,可能以每百万输出token 3000美元、每秒10-20个token的速度提供服务。
但正如Karpathy所说,相比于如今这种只能根据prompt去解决博士级别问题的AI,一个能够真正作为「实习生」入职的AI更为实用。
参考资料:
https://epoch.ai/gradient-updates/frontier-language-models-have-become-much-smaller
https://x.com/OfficialLoganK/status/1868002617311596552
https://x.com/DhruvBatraDB/status/1868009853324865762
https://x.com/karpathy/status/1868061331355840704
#大模型轻量化系列解读
降低 LLM 中因 Activation Spikes 导致的量化误差
本文研究了基于GLU变体的大型语言模型在后训练量化时面临的激活量化挑战,发现GLU激活中的“激活尖峰”会导致显著的量化误差。为此,作者提出了两种方法:量化自由模块和量化自由前缀,通过在量化过程中隔离这些激活尖峰,有效提升了量化模型的性能,尤其是在粗粒度量化方案下,显著改善了模型的推理效率和性能。
借助前缀削弱激活异常值,改善 LLM 后训练量化。
量化方案:
Weight: Per-channel,Activation:Per-tensor Dynamic
现代大型语言模型 (LLM) 通过架构改进建立了最先进的性能,但仍然需要大量的计算成本进行推理。
后训练量化 (Post-Training Quantization) 是大模型轻量化的一种流行方法,把 weight 和 activation 表示为低比特,比如 INT8。本文中,作者揭示了基于 GLU[1]的 LLM (常见于现代 LLM 模型的 FFN 层,如 LLaMA) 中 activation 量化的挑战。作者将这些 activation 称之为 activation spike。
作者列举了activation spike 的一些特点:
- activation spike 发生在特定层的 FFN 中,尤其是在早期的层和后期的层中。
- activation spike 专门存在于一些特定的 tokens 中,而不是在整个序列中都有。
为了隔离量化过程中的 activation spike,本文实证性地提出了 2 种方法:Quantization-free Module (QFeM) 和 Quantization-free Prefix (QFeP)。作者在很多具有 GLU 变体的最新 LLM 中验证了所提出的激活量化方法的有效性,包括 LLAMA-2/3、Mistral、Mixstral、SOLAR 和 Gemma。
1 降低 LLM 中因 Activation Spikes 导致的量化误差
论文名称:Mitigating Quantization Errors Due to Activation Spikes in GLU-Based LLMs
论文地址:http://arxiv.org/pdf/2405.14428
代码链接:http://github.com/onnoo/activation-spikes
1.1 Activation Spikes 研究背景
大语言模型 (LLM) 通常会采用 GLU[1]、RoPE[2]、GQA[3]和 MoE[4]等架构改进,拓宽了自然语言任务的基本能力和各种应用的潜力。尤其是,考虑到训练效率的缘故,大多数现代 LLM 架构 (如 LLaMA 家族) 都采用了门控线性单元 (Gated Linear Unit, GLU) 变体 (如 SwiGLU、GeGLU)。但是,大模型中的数十亿个参数对用户施加了相当大的计算成本。为了减少 GPU 显存需求并加快推理速度,后训练量化 (PTQ) 通过将权重和激活量化为低精度 (例如 INT8) 来降低使用成本。然而,最近的研究表明,LLM activation 中的某些位置存在很大幅值的数值,通常称为异常值,对 activation 的量化提出了关键的挑战。有一些工作试图解释异常值在注意力机制中的作用[5]。然而,目前对不断发展的 LLM 架构对异常值影响的研究仍然不足。
本文作者发现 FFN 中的 GLU 架构会产生过大的 activation 值,这些 activation 值造成局部量化误差显著。具体来说,作者观察到这些有问题的激活值出现在特定的线性层中,并且专门用于几个 token。为了区分 GLU 中过大的 activation 与异常值 (Outlier),作者将前者称为激活值尖峰 (Activation Spike)。鉴于本文的观察,作者提出了两种方法来减轻 Activation Spike 对量化的影响:免量化模块 (Quantization-free Module, QFeM) 和免量化前缀 (Quantization-free Prefix, QFeP)。
免量化模块 QFeM: 目的是排除一部分发生较大量化误差的线性层 (或模块) 的量化,而不是量化 LLM 中的所有线性模块。QFeM 会排除掉那些 scale 差异程度大的线性模块。
免量化前缀 QFeP: 目的是识别触发激活值尖峰的前缀 (Prefix),并将其上下文存储在 key-value (KV) cache 里面,从而防止后续 token 中激活值尖峰的递归。值得注意的是,QFeM 和 QFeP 都依赖于校准结果来提前捕获激活峰值,无需对要做量化的 LLM 进行任何修改。这表明本文方法可以集成到任何现有的量化方法中。
1.2 Activation Spikes:GLU 激活函数带来超大激活值
最近的工作[5]研究了现代 LLM 的隐藏状态中存在的一种新的异常值。尽管这些异常值在 Transformer 中的 Attention 中起了至关重要的作用,但是其与输入 activation 之间的关系还没得到充分的探索。作者关注每个线性层之前的 input activation。具体而言,作者检查了 4 个线性层:Query,Out 的投影,以及 FFN 中 Up 和 Down 投影。
为了分析 input activation,作者采用了一种校准方法,用于估计 scale 和 zero point 等量化因子。校准数据使用从 C4[6]训练数据集中随机收集的 512 个样本。之后,将每个样本输入到 LLM 中,并监控每个隐藏状态和 input activation。为了估计比例因子,使用绝对值的最大值。
观察1:GLU-implemented LLM 在特定层会出现 Activation Spikes。
在图 1 中,作者展示了实现 GLU-implemented 的 LLM (例如,SwiGLU、GeGLU) 的校准比例因子。从结果中可以观察到一些共性。在前期和末期的层中,FFN 中的 Down Projection 模块会出现显著的 input activation。这些输入激活来自 GLU 中的 Hadamard 积。因此,GLU 变体在特定层会生成 Activation Spikes。有趣的是,作者注意到大规模激活尖峰的出现和中间隐藏状态之间存在高度相关性。这表明 FFN 通过残差连接中的加法操作有助于放大隐藏状态。一旦隐藏状态的幅值爆炸,就会在不同的层中持续存在,直到在后期层遇到 Activation Spikes。
![]()

图1:GLU-implemented 的 LLM 的校准结果,展示了每个线性模块,每层隐藏状态的 input activation 的最大幅值
观察2:Non GLU-implemented LLM 显示适度的分布。
图 2 说明了在Transformer 中具有原始 FFN 实现的 LLM 的结果。可以观察到 LLM 的 hidden state 也会同样有较高的幅值,与[5]中的观察结果相呼应。但是,图 2 也说明 hidden state 比较大的幅值并没有转移到线性层的 input activation 上面。恰恰相反的是,GLU-implemented 的 LLM 形成了 Activation Spikes。这些结果也展示了 GLU-implemented 的 LLM 在量化方面的挑战,尤其是在前期的层和后期的层中。

图2:Non GLU-implemented 的 LLM 的校准结果,展示了每个线性模块,每层隐藏状态的 input activation 的最大幅值
在上一节中,观察到了因为 GLU 激活函数导致 input activation 出现过大的异常值的情况。在量化 input activation 的时候,每个 token 的 input activation 的方差会影响量化性能。在图 3 中可以观察到,给定一个 token 序列,在几个 token 中观察到大量 input activation,例如 BOS token, newline (\n), 和 apostrophe (')。这些特定的 token 与[5]中的观察结果一致,表明此类 token 会在 hidden state 中表现出异常值。因此,Activation Spikes 与 Transformer 层为这些 token 分配特殊作用的过程相联系。但是,这些特定 token 的很大的值影响了其他 token 的量化,尤其是在 per-tensor 的量化中。

图3:具有 Activation Spike 的特定层中的不同 token 的幅值。当对 input activation 使用 per-tensor 量化时,Activation Spike 的幅值会主导其他 token
1.3 Activation Spikes 对量化的影响
作者还探讨了 Activation Spikes 对量化的影响。为了识别发生 Activation Spikes 的层,作者计算了 input activation 幅值的最大值和中位数之间的比例。线性层 中的 max-median ratio 可以表示为:

其中, 表示模块 的 token-wise 的 input activation 的幅值。这个比例反映了了最大幅值支配其他 token 幅值的程度。为了比较,作者根据这个比例按照降序选择前 4、中 4 和后 4 个模块,再使用校准数据集评估困惑度和均方误差 (MSE)。这里的 MSE 是针对原始 (FP16) 和部分量化 LLM 之间的最后一个隐藏状态计算的。结果如图 4 所示,前 4 模块上的量化会显著降低 LLM 性能,其他情况的性能下降可以忽略不计。作者认为这些对量化敏感 input activation 是量化瓶颈,在本文中,它指的是异常值引起的量化误差。

图4:LLM 量化一部分激活值之后的困惑度和 MSE
为了解决量化的瓶颈,本文的方法基于 Activation Spikes 常见的模式。首先,Activation Spikes 出现在特定的层中。这意味着对 LLM 直接量化会受到这些瓶颈的影响。其次,作者发现 Activation Spikes 源于一些特定的 token 第一次出现的时候。因此,如果我们可以让这些特定的 token 按照我们的想法 "有计划" 地出现,那么就可以阻止 Activation Spikes 在未来 token 中的出现。下面就是针对这两个现象的针对性方案:
1.4 缓解量化质量退化:免量化模块
在 LLM 的量化中,LLM 中的所有线性层都被量化。在这些线性层中,作者提出略去一些线性层的 input activation 的量化,那么这些线性层里面 Activation Spikes 引起了显著的量化误差。值得注意的是,增加不量化模块的数量会在推理时延与模型性能之间取得平衡。因此,确定应该量化哪些模块对于保留量化的功效至关重要。
因此,作者定义了一个阈值 ,如果 max-median ratio 大于这个阈值,这个模块的 input activation 就不进行量化。例如,如果 ,则所有线性层都被量化。为了控制 activation 量化的影响,作者将未被量化的线性层中的 weight 保留为 INT8,并将其在进行矩阵乘法时 dequant为 FP16。不量化 activation 的模块其实就相当于仅权重量化。
优化阈值
阈值 与其对性能 (通过校准集进行评测) 的影响之间的关系如图 5 所示,展示了量化如何降低性能。作者不做完全量化,而是通过找到两个性能曲线的交集来识别最佳阈值。在图 5 中,这个阈值约为 16。

图5:LLaMA-2-13B 模型的阈值,困惑度 (代表性能) 和 |Munq| (代表时延) 之间的权衡
1.5 缓解量化质量退化:免量化前缀
免量化前缀通过预先计算好对应于 Activation Spikes 的 Prefix 来减轻量化误差。受这种 Activation Spikes 发生模式的启发,本文的目标是构建一个 Prefix,该 Prefix 会稳定之后标记的量化参数。换句话说,一旦 Prefix 在开始时是固定的,Activation Spikes 始终出现在 Prefix 中。之后,作者采用 KV cache 机制提前处理 Activation Spikes。在实践中,KV cache 用于通过存储先前 token 预计算的 Key, Value 来优化因果语言模型的解码速度。Prefix 的 KV cache 通过 LLM 的离线推理预计算一次,不进行量化。然后,KV cache 被用于量化阶段,如校准或动态量化。
前缀搜索
为了形成 Activation Spikes 的前缀,作者首先识别具有最大 max-median ratio 的 Activation Spikes 的候选 token。例如,候选 token 可以是 LLaMA-2-70B 模型的 apostrophe (') token,如图 6 中的红色所示。一旦确定了候选 token,就会搜索 BOS token 和前缀中的候选 token 之间的中间上下文 token。最后,准备搜索得到的 Prefix 的 KV cache。

图6:QFeM 和 QFeP。左:QFeM 不量化 max-median ratio 超过阈值 α 的模块。右:QFeP 提前计算 Activation Spikes 的前缀,并在量化阶段仅使用它们的 KV cache,有效地防止后续序列中的进一步出现 Activation Spikes
实现细节
在前缀搜索阶段,作者使用校准数据集。对于候选 token,作者考虑 input activation 幅值最大的前 3 个标记。然后在校准数据集中前 200 个最频繁的 token 中搜索中间上下文 token,它是词汇表 V 的子集。最后,通过搜索结果,以 FP16 精度为目标模型准备 KV cache。图 7 显示了搜索的前缀。

图7:实验中使用的 QFeM 和 QFeP 的规范。|M| 表示 LLM 中线性层的总数,|Munq| 表示 QFeM 未量化层数
1.6 实验设置
模型
本文的方法 QFeM 和 QFeP 旨在减轻由 Activation Spikes 引起的量化瓶颈,尤其是在基于 GLU 的 LLM 变体中。为了验证所提出的方法的效率,作者根据他们的论文和源代码测试了使用 GLU 实现的 LLM。最近的 LLM,包括LLAMA2-{7B, 13B, 70B}、LLaMA-3-{7B, 70B}, Mistral-7B、Mixstral-8x7B、SOLAR-10.7B 和 Gemma-7B,都用了 GLU 架构。
量化设置
在实验中,作者量化了 INT8 矩阵乘法操作的 input activation 和线性层的权重。在这些线性层中,使用 dynamic per-tensor quantization 作为 input activation 的量化方案,使用 per-channel quantization 作为 weight 的量化方案。对于 input activation 和 weight,作者使用 absolute maximum value 估计 scale,作对称量化。为了比较,使用 FP16 和 per-token activation 量化[7]作为比较的 Baseline。
评估
作者使用两个指标评估量化的 LLM:Zero-Shot 的评估精度和困惑度。对于 Zero-Shot 评估,使用 4 个数据集:PIQA、LAMBADA、HellaSwag 和 WinoGrande。作者利用 lm-evaluation-harness 库来评估 Zero-Shot 任务。为了衡量困惑度,使用 WikiText-2 数据集。所有情况下默认使用 [BOS] token 作为每个输入序列的起始 token。
1.7 主要结果
LLaMA-2 模型
作者在图 8 中报告了 LLaMA-2 模型量化的评估结果。与 FP16 精度相比,量化 weight 和 activation (W8A8) 会降低整体性能。结果表明,本文提出的方法解决了 Activation Spikes,使得 W8A8 的性能恢复到了接近 FP16。例如,LLaMA-2 7B 模型在 FP16 的性能下降不到 1%。值得注意的是,本文提出的 QFeM 和 QFeP 提升了性能。这表明 Activation Spikes 直接导致量化性能显着下降。由于所提出的方法是正交的,因此与单独应用 QFeM 和 QFeP 相比,结合 QFeM 和 QFeP 的性能略有提高。

图8:LLaMA-2 模型量化的困惑度和 Zero-Shot 评估。FP16 表示原始模型精度,W8A8 表示权重和激活量化为 INT8 结果
其他 GLU-implemented LLM
对于其他 GLU-implemented LLM,作者研究了本文方法在减轻量化瓶颈方面的有效性。如图 9 所示,本文方法始终可以纠正 Activation Spikes 引起的性能下降。值得注意的是,Mixral 模型展示了对性能下降的鲁棒性。这表明专家架构的混合,将 MLP 专家按令牌划分,有助于减轻激活峰值的影响。同时,与其他模型相比,解决 Activation Spikes 对于 Gemma 模型似乎并不能构成有效的补充。作者将此归因于 GLU 变体中激活函数的选择:Gemma 使用 GeGLU,而其他模型使用 SwiGLU。

图9:Zero-Shot 评估对其他 GLU-implemented 的 LLM 的平均精度。与 W8A8 相比,大多数模型性能显著恢复,性能接近 FP16
1.8 消融实验结果
对于 QFeP,作者为 KV cache 设计了一个长度为 3 的 Prefix,包括 BOS token、上下文 token 和 Activation Spikes 的额外 token。作者对 KV cache 的不同 Prefix 进行了消融实验。作者对比了不同的 Prefix 的 KV cache,包括:随机,BOS,没有 context token 的 QFeP,有 context token 的 QFeP,并在图 10 中说明了消融实验结果。在所有情况下,随机 Prefix 的性能都是最低的。而且,使用 BOS token 的 KV cache 性能不一致,本文的 QFeP 始终显示出显著的改进。

图10:Prefix 消融实验结果。Y 轴表示 4 个 Zero-Shot 任务的平均精度
1.9 计算复杂度分析
本文提出的方法需要额外的资源来驱逐激活峰值。因此,作者分析了方法的计算成本,并将它们在各种方案中进行比较。作者评估了不同的激活量化方案:dynamic per-token, dynamic per-tensor, 和 static per-tensor 的量化,分别用 AQ1、AQ2 和 AQ3 表示。为了校准静态量化 scale,作者使用校准数据集估计绝对最大值。
推理时延
对于每个设置,作者展示了固定标记序列的 Zero-Shot 任务的精度和推理时延,如图 11 所示。虽然细粒度方案 AQ1 的精度下降可以忽略不计,但 AQ2, AQ3 的精度会下降会降低。
通过应用本文方法,粗粒度方案实现了具有竞争力的性能增益。例如,AQ2 和 QFeM 的组合展示了接近 AQ1 的性能,且时延更快。结果表明,解决量化的瓶颈对于粗粒度量化的推理加速,降低时延很重要。具体而言,最快的方案,即直接静态量化 (AQ3) 表现出显著性能下降。作者希望未来的工作可以解决静态量化的挑战。

图11:不同 activation 量化方案的精度-延迟比较:dynamic per-token (AQ1), dynamic per-tensor (AQ2), 和 static per-tensor (AQ3)
Memory Footprint
在图 12 中,作者记录了本文方法的最大显存占用。对于 QFeP,保留的 KV cache 会需要额外的显存。然而,这种显存开销远小于细粒度量化 AQ1 中使用的显存开销,因为 QFeM 仅将 3 个令牌用于缓存。与 QFeP 不同,QFeM 的内存利用率表现得不一致。例如,具有 QFeM 的 7B 模型的内存使用量类似于 AQ2,具有 QFeM 的 70B 模型在 1K 的序列长度上会产生额外的消耗。这是因为在 QFeM 中会对免量化的模块使用 W8A16 精度。为了定制化显存使用或者推理速度,QFeM 可以采用另一种策略,比如对于免量化模块使用细粒度的 activation 量化,而不是使用 W8A16。

图12:Memory footprint
参考
- ^abGlu variants improve transformer
- ^RoFormer: Enhanced Transformer with Rotary Position Embedding
- ^GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
- ^Mixtral of experts
- ^abcdMassive Activations in Large Language Models
- ^Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- ^ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
#Electronic Design Automation,EDA
南大钱超团队攻克百亿晶体管难题,斩获EDA顶会2025最佳论文!AI学院本硕博生联手
南大AI学院钱超教授团队,荣获EDA顶会2025最佳论文奖!其中,论文一作、四作、五作都是南大人工智能学院的本硕博生。芯片设计领域的传统难题——如何为多达百亿量级晶体管设计最优布局,从此有了一种巧妙的全新方法。
据南京大学人工智能学院网站报道,南大LAMDA组钱超教授团队在DATE 2025发表的芯片设计优化论文「Timing-Driven Global Placement by Efficient Critical Path Extraction」获会议最佳论文奖。
电子设计自动化(Electronic Design Automation,EDA)是芯片设计的基石产业,被誉为「芯片之母」。
欧洲设计自动化与测试会议(Design, Automation and Test in Europe Conference,DATE)是EDA领域的顶级国际学术会议。
本次DATE 2025最佳论文第一作者侍昀琦、第四作者林熙、第五作者薛轲分别是南京大学人工智能学院的硕士生、本科生和博士生,钱超教授为通讯作者,论文与华为诺亚方舟实验室合作完成。
论文:https://www.lamda.nju.edu.cn/qianc/DATE_25_TDP_final.pdf
开源:https://github.com/lamda-bbo/Efficient-TDP
在芯片设计领域,为多达百亿量级晶体管设计最优布局,一直是一个难解的技术难题。传统的布局方法要么选择快速但不够精准的网线加权方案,要么采用精确但运算量巨大的路径优化方法。
就像在一个拥挤的城市规划新的交通路线,既要考虑道路长度,又要确保交通畅通,面临精度与效率、局部与整体的冲突。这个两难困境一直困扰着芯片设计行业。
该论文提出了一种全新的时序驱动布局方法,巧妙地将效率和精度统一起来:
- 经典开源时序分析工具OpenTimer 使用O(n^2)复杂度的算法提取top-n条时序违例路径,且不支持基于违例端点的路径分析。该论文针对每个违例端点提取其top-n条违例路径,不仅能覆盖所有时序违例端点,还将提取n条违例路径的复杂度降至O(n),在时序分析中能够实现6倍加速。这个创新方法的核心在于「智能关键路径提取」技术,它能够快速定位需要优化的关键路径,将分析速度提升了6倍。
- 传统的基于线网的加权方案对于高扇出线网经常带来不必要的权重,从而过度优化许多不涉及时序违例的路径。论文提出了基于引脚间吸引力的精确指标,通过精确捕捉时序违例路径上的引脚对来建模时序信息,在显著提升时序指标的同时,几乎不造成整体线长的损失。
- 常用的时序模型RC Delay Model中,线网延时与其长度的平方成正比。论文首次提出将引脚间欧式距离的平方作为损失函数,并在GPU上实现了前向、反向传播的加速。较以往常用损失函数,在关键时序指标TNS和WNS上分别提升50%和30%。
图1:基于引脚间吸引力的时序目标建模
论文在ICCAD-2015竞赛数据集上进行了广泛的对比,相较于最先进的开源布局算法DREAMPlace 4.0做到了全部8个芯片的显著领先,特别是在TNS指标上达到60%的平均提升。
相较于SOTA方法Differentiable-TDP和Distribution-TDP算法分别达到50%和40.5%的TNS平均提升。

图2:时序和线长指标的实验结果
审稿人高度评价该工作,称「结果令人印象非常深刻,超过了所有先进工作」(「The results are very impressive, outperforming all state-of-the-art works」),取得显著提升(「significant improvements」)。
DATE自1994年创办以来已举办31届,今年将于3月31日至4月2日在法国里昂召开。DATE今年收到逾1200篇投稿,录用率约25%,共评选出4篇最佳论文奖(获奖率仅0.3%)。
近期,AI技术在芯片设计中的应用受到了国际上高度关注。Google在Nature提出AlphaChip,应用于TPU设计,而多家EDA头部厂商也推出了AI赋能的EDA产品。芯片设计流程冗长复杂,存在大量复杂优化问题。
作为人工智能的重要研究分支,演化算法受达尔文进化论启发,通过模拟「交叉变异」和「自然选择」行为,可用于求解机器学习中复杂优化问题,但这类算法几乎纯粹是「启发式」:在不少情况下有效, 但为何奏效、在何种条件下奏效却并不清楚。
LAMDA组周志华教授带领俞扬教授和钱超教授长期努力,希望能够建立起相应理论基础,并对算法设计给出指导;2019年他们在Springer出版专著《Evolutionary Learning: Advances in Theories and Algorithms》,总结了他们在该方向上过去二十年的主要工作,并于2021年出版中文版《演化学习:理论与算法进展》。
基于这些长期理论研究,LAMDA组近期针对芯片设计中的复杂优化问题设计出了多个原创领先算法,如:
- 针对芯片宏元件布局问题,该团队在NeurIPS’23发表的工作「Macro Placement by Wire-Mask-Guided Black-Box Optimization」较Google在Nature’21提出方法的布线长度缩短80%以上,并获得ACM SIGEVO Human-Competitive Results奖;
- 针对芯片全局布局问题,该团队在DAC’24发表的Poster工作「Escaping Local Optima in Global Placement」通过变异算子缓解了当前解析式布局器易于陷入局部最优的问题,进一步提升芯片布线长度指标15%;
- 针对芯片宏元件布局问题,该团队在NeurIPS’24发表的工作「Reinforcement Learning Policy as Macro Regulator Rather than Macro Placer」提出了新的基于强化学习的问题建模,通过训练策略对已有布局进行高效微调而不是从头摆放,保证了宏元件布局的贴边和规整,在时序和拥塞等指标上均取得了一致的显著提升;
- 针对芯片宏元件布局问题,该团队在DAC’25发表的工作「ReMaP: Macro Placement by Recursively Prototyping and Periphery-Guided Relocating」将大量专家知识引入算法,优化了宏元件和标准元件的数据流,更加符合工业界的实际需求,较当前最先进的开源EDA工具OpenROAD的方法,提升芯片最终时序指标超65%;
- 若干技术在华为海思落地验证,包括攻克华为「揭榜挂帅」难题「EDA专题难题:超高维空间多目标黑盒优化技术」,将芯片寄存器寻优效率平均提升22.14倍等。
LAMDA组目前与华为正在进一步合作攻关,希望通过先进芯片设计缓解当前先进制造工艺局限。
参考资料:
https://ai.nju.edu.cn/5d/02/c17806a744706/page.htm
#1000 Layer Networks for Self-Supervised RL
强化学习也涌现?自监督RL扩展到1000层网络,机器人任务提升50倍
虽然大多数强化学习(RL)方法都在使用浅层多层感知器(MLP),但普林斯顿大学和华沙理工的新研究表明,将对比 RL(CRL)扩展到 1000 层可以显著提高性能,在各种机器人任务中,性能可以提高最多 50 倍。
- 论文标题:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
- 论文链接:https://arxiv.org/abs/2503.14858
- GitHub 链接:https://github.com/wang-kevin3290/scaling-crl
研究背景
最近在人工智能领域里,强化学习的重要性因为 DeepSeek R1 等研究再次凸显出来,该方法通过试错让智能体学会在复杂环境中完成任务。尽管自监督学习近年在语言和视觉领域取得了显著突破,但 RL 领域的进展相对滞后。
与其他 AI 领域广泛采用的深层网络结构(如 Llama 3 和 Stable Diffusion 3 拥有数百层结构)相比,基于状态的强化学习任务通常仅使用 2-5 层的浅层网络。相比之下,在视觉和语言等领域,模型往往只有在规模超过某个临界值时才能获得解决特定任务的能力,因此研究人员一直在寻找 RL 中类似的能力涌现现象。
创新方法
普林斯顿大学和华沙理工的最新研究提出,通过将神经网络深度从常见的 2-5 层扩展到 1024 层,可以显著提升自监督 RL 的性能,特别是在无监督目标条件任务中的目标达成能力。
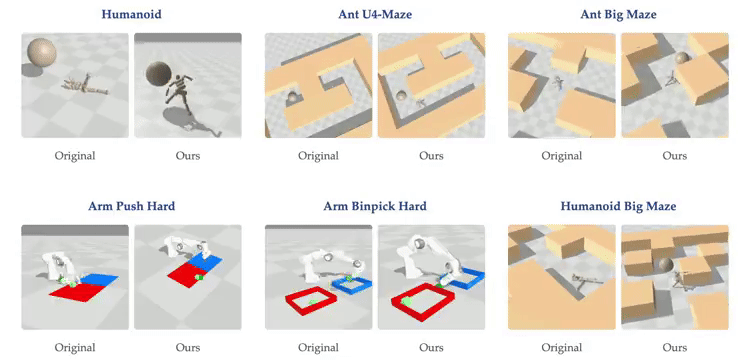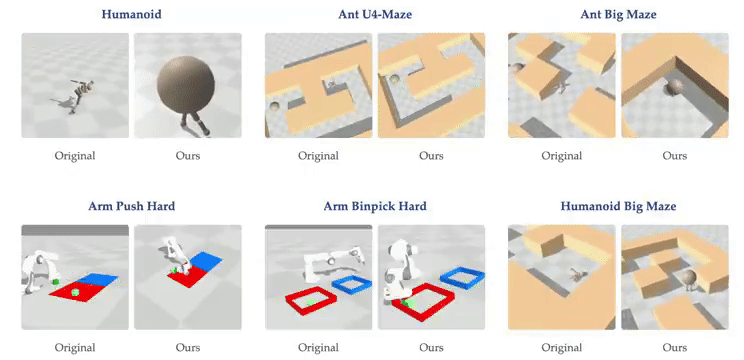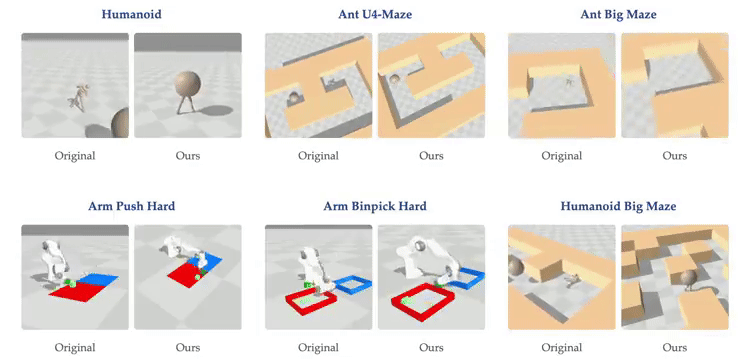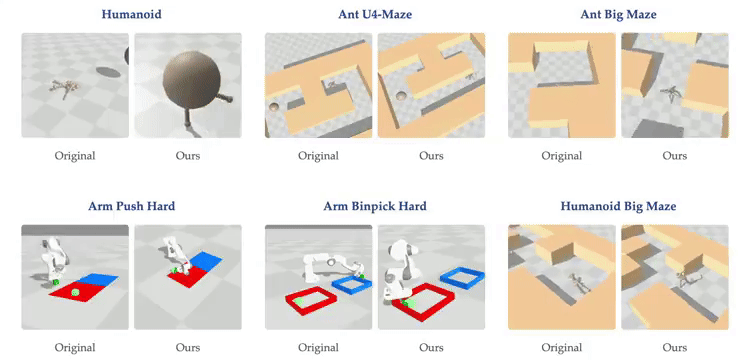
这一发现挑战了传统观点。过去认为训练大型 RL 网络困难是因为 RL 问题提供的反馈极为稀少(如长序列观测后的稀疏奖励),导致反馈与参数比率很小。传统观点认为大型 AI 系统应主要以自监督方式训练,而强化学习仅用于微调。
研究团队从三个关键方面进行创新:
- 范式融合:重新定义「强化学习」和「自监督学习」的关系,将它们结合形成自监督强化学习系统,采用对比强化学习(Contrastive RL, CRL)算法;
- 增加数据量:通过近期的 GPU 加速强化学习框架增加可用数据量;
- 网络深度突破:将网络深度增加到比先前工作深 100 倍,并融合多种架构技术稳定训练过程,包括:残差连接(Residual Connections)、层归一化(Layer Normalization)、Swish 激活函数。
此外,研究还探究了批大小(batch size)和网络宽度(network width)的相对重要性。
关键发现
随着网络深度的扩大,我们能发现虚拟环境中的强化学习智能体出现了新行为:在深度 4 时,人形机器人会直接向目标坠落,而在深度 16 时,它学会了直立行走。在人形机器人 U-Maze 环境中,在深度 256 时,出现了一种独特的学习策略:智能体学会了越过迷宫高墙。

进一步研究,人们发现在具有高维输入的复杂任务中,深度扩展的优势更大。在扩展效果最为突出的 Humanoid U-Maze 环境中,研究人员测试了扩展的极限,并观察到高达 1024 层的性能持续提升。

另外,更深的网络可以学习到更好的对比表征。仅在导航任务中,Depth-4 网络使用到目标的欧几里得距离简单地近似 Q 值,而 Depth-64 能够捕捉迷宫拓扑,并使用高 Q 值勾勒出可行路径。

扩展网络深度也能提高 AI 的泛化能力。在训练期间未见过的起始-目标对上进行测试时,与较浅的网络相比,较深的网络在更高比例的任务上取得了成功。
技术细节
该研究采用了来自 ResNet 架构的残差连接,每个残差块由四个重复单元组成,每个单元包含一个 Dense 层、一个层归一化(Layer Normalization)层和 Swish 激活函数。残差连接在残差块的最终激活函数之后立即应用。
在本论文中,网络深度被定义为架构中所有残差块的 Dense 层总数。在所有实验中,深度指的是 actor 网络和两个 critic encoder 网络的配置,这些网络被共同扩展。

研究贡献
本研究的主要贡献在于展示了一种将多种构建模块整合到单一强化学习方法中的方式,该方法展现出卓越的可扩展性:
- 实证可扩展性:研究观察到性能显著提升,在半数测试环境中提升超过 20 倍,这对应着随模型规模增长而涌现的质变策略;
- 网络架构深度的扩展:虽然许多先前的强化学习研究主要关注增加网络宽度,但在扩展深度时通常只能报告有限甚至负面的收益。相比之下,本方法成功解锁了沿深度轴扩展的能力,产生的性能改进超过了仅靠扩展宽度所能达到的;
- 实证分析:研究表明更深的网络表现出增强的拼接能力,能够学习更准确的价值函数,并有效利用更大批量大小带来的优势。
不过,拓展网络深度是以消耗计算量为代价的,使用分布式训练来提升算力,以及剪枝蒸馏是未来的扩展方向。
预计未来研究将在此基础上,通过探索额外的构建模块来进一步发展这一方法。
#BodyGen
让机器人实现「自主进化」,蚂蚁数科、清华提出具身协同框架
第一作者卢昊飞、第二作者吴哲,分别为清华大学计算机系在读硕士与博士研究生。通讯作者兴军亮教授长期致力于感知与博弈决策的理论与应用研究,在多智能体系统、强化学习及智能决策等领域取得了一系列重要成果。
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由蚂蚁数科与清华大学联合团队提出的全新具身协同框架 BodyGen 成功入选 Spotlight(聚光灯/特别关注)论文。
论文题目:BodyGen: Advancing Towards Efficient Embodiment Co-Design
论文地址:https://arxiv.org/abs/2503.00533
项目代码:https://github.com/GenesisOrigin/BodyGen
本文研究探索了一个有趣但引人深思的问题:机器人能否像生物一样自主进化?团队通过实验给出了肯定答案:结合强化学习与深度神经网络技术,BodyGen 能在极短时间内自动演化出适应当前环境的最优机器人形态及控制策略,为具身智能的加速进化提供了全新的思路。
相关代码已开源至 GitHub 仓库,欢迎尝试。
据了解,本届大会共收到 11672 篇论文,被选中做 Spotlight(聚光灯/特别关注)或者 Oral Presentation(口头报告)的比例约为 5.1%。
以下是论文作者团队对该论文的解读:
为什么机器人需要「自主进化」?
自然界生物通过数百万年的进化,获得了适应环境的完美身体结构与环境交互能力。然而,机器人的设计不但需要极其庞大的人类专家知识,且针对特定环境需要进行大量的实验、设计和迭代。
受自然界生物学启发,科学家提出形态控制协同设计(Co-Design)技术:让机器人模仿生物进化过程,在优化控制策略(大脑)的同时演化自身形态(形体结构、关节参数)从而适应复杂环境。
然而,这一领域长期面临两大难题:一是形体搜索空间巨大,在有限时间内难以穷举所有可能的机器人形态;二是机器人形态与控制策略深度耦合,评估每一个候选形态设计需要大量计算资源。
BodyGen 的核心思路

来自清华大学与蚂蚁数科的研究团队提出 BodyGen 框架,利用强化学习实现了端到端的高效形态-控制协同设计。
在这项工作中,将形体设计过程划分为两个连续阶段:形态设计阶段、环境交互阶段。
在演化阶段:研究引入 Transformer(GPT-Style)自回归地构建机器人的形体结构并优化参数;在环境交互阶段,同样使用 Transformer(Bert-Style)对机器人的每一个关节信息进行集中处理并发送到对应关节马达,与环境交互并获得反馈。在几轮的迭代后,BodyGen 可以快速生成当前环境的最佳机器人形态和相应的控制策略。
BodyGen 的三大技术点解读
BodyGen 是一个生物启发式的训练框架,它使用深度强化学习进行端到端的形态-控制协同设计。BodyGen 包含三项核心技术点:
(1)轻量级的形体结构位置编码器 TopoPE
TopoPE 就像机器人的「身体感知」系统,通过给机器人每个部位贴上「智能标签」。无论机器人的形状如何变化,这些标签都能帮助 AI 理解「这是腿」、「这是手臂」等。这样,即使机器人的形态发生变化,AI 也能快速适应并控制新的身体结构。
(2)基于 Transformer 的集中式的神经中枢处理网络 MoSAT
MoSAT 就像机器人的「大脑中枢」,它的工作方式很像人脑:
- 信息收集:首先收集机器人各个部位的信息(位置、速度等)
- 中央处理:所有信息在「大脑」(Transformer 网络)中进行交流和处理
- 指令发送:处理后的信息转化为具体动作指令,告诉机器人如何移动
(3)时序信用分配机制下的协同设计
- BodyGen 让 AI 同时负责两件事:设计机器人的身体和控制机器人的动作。
- 设计动作:AI 可以给机器人「长出」新的肢体,「剪掉」不需要的部分,或保持现有结构
- 控制动作:AI 学习如何控制机器人的每个关节来完成任务(如行走、跳跃)
设计一个好的机器人形态可能要等很久才知道效果好不好(比如设计了长腿,要等机器人学会走路才知道这设计是否合理)。BodyGen 通过特殊的「奖励分配机制」,让 AI 能够合理评估自己的设计决策,不会因为短期效果不明显就放弃可能很好的设计。
第一:TopoPE 形体结构位置编码器

在人脑中,来自身体不同区域的信号会被传输到特定的神经区域进行处理,这隐含了消息来源的位置信息。对于机器人,我们同样需要高效的形体信息表征。

在 BodyGen 中,拓扑感知位置编码(TopoPE)通过哈希映射,将机器人肢体到根肢体的路径映射为唯一的嵌入(Embedding),有效解决了形体演化过程中的索引偏移问题,从而促进了协同设计过程中相似形态机器人的知识对齐和共享。
第二:MoSAT 集中式的神经中枢网络

为了通用表征形体空间中的各种各样的机器人,作者使用标准序列模型 Transformer 处理拓扑结构可变的机器人形体。机器人的每一个关节信息都会经过「编码」-「集中处理」-「解码」三个阶段,最终生成动作信号:
信息编码:来自不同肢体的信息首先会携带其拓扑位置信息首先通过编码层进行信号编码

集中处理:这些编码后的信息借助 Transformer 网络进行点对点的信息通讯,实现集中式的信息交互和处理

信息解码:最终,这些信息经过解码网络解码,从而获得机器人的动作信号

第三:时序信用分配机制下的协同设计
在 BodyGen 的定义中,智能体具有两类基本动作:形态设计动作和形体控制动作。形态设计动作包含三类基本元动作:
- 肢体生长:机器人的形体向下生长出一个额外的肢体
- 肢体退化:机器人的形体删除一个指定的肢体
- 肢体维持:机器人的形体维持某一个肢体不变
同时形体控制动作包含机器人与环境交互每一个关节马达的输出力矩。

本研究使用近端策略优化算法(PPO)进行端到端的协同设计训练优化。相较于形体控制动作,形态设计动作无法获得及时的环境反馈。作者提出改进的广义优势估计(GAE),层次化地对环境奖励进行动态分配,从而使智能体在形态设计和控制阶段获得平衡的优势估计,从而提升训练性能。
BodyGen 测评效果:参数低至 1.43M,实现 60% 性能提升
研究者选取了 3 种基础的机器人拓扑结构(线性、双腿、四腿),在不同的仿真环境中,环境奖励信号仅为运动敏捷性(指定方向的运动速度)。给定初始结构设计,借助 BodyGen 进行形态-控制协同优化。
,时长00:07
作者在 10 个不同类型的环境进行了综合测评,实验表明,BodyGen 相对于最先进的基线实现了 60.03% 的平均性能提升,在 10 个不同任务种类的环境下(如爬行、地形穿越、游泳等),BodyGen 生成的机器人形态相比于现有最优方法(如 Transform2Act、NGE 等)在环境适应性评分获得了 60.03% 的涨幅。

研究对序列模型、时序信用分配算法进行了充分的对比消融,对文章提出的 MoSAT 架构和时序信用分配算法的进行了详细和充分的实验验证。

作者同样对形体结构位置编码进行了消融实验,证实 TopoPE 在形态表征上的有效性。

BodyGen 的平均参数量为 1.43M,相较于其他基线算法更加轻量级。BodyGen 的紧凑设计使其在保持生成能力的同时,显著降低了计算成本和存储需求,提升了训练的稳定性与效率。这种高效的模型架构不仅减少了训练时的资源消耗,还提升了推理阶段的响应速度,使其更适用于资源受限的环境,甚至可在一台笔记本上借助 CPU 进行高效推理。

场景应用
BodyGen 作为一个通用形体-控制协同设计算法,展现出了一定的应用潜力,包括但不限于:
- 环境适应性机器人设计:针对特定环境需求,快速生成最优形态与控制策略,显著缩短机器人设计周期,提升开发效率;
- 仿生机器人研究:通过模拟生物运动机理,设计仿生足、鳍、翼等结构,为探索生物运动原理提供可计算平台;
- 虚拟人物动作生成:基于物理引擎的高效动作优化,为游戏、动画制作及虚拟角色行为生成提供技术支持。
未来展望
团队计划通过物理模拟迁移技术推动 BodyGen 在实际场景中的应用。随着计算能力的提升,这一框架有望成为实现通用具身智能的重要路径,使机器人能够通过感知-行动闭环持续优化形态与行为策略,逐步实现自我设计与自动进化。
#IDOL
高分论文 | 单图秒变3D真人!技术开启数字分身新时代
在虚拟现实、游戏以及 3D 内容创作领域,从单张图像重建高保真且可动画的全身 3D 人体一直是一个极具挑战性的问题:人体多样性、姿势复杂性、数据稀缺性等等。
终于,近期由来自南京大学、中科院、清华大学、腾讯等机构的联合研究团队,提出一个名为 IDOL 的全新解决方案,高分拿下 2025 CVPR。项目主页目前访问次数已超 2500+ 次,且是可商用的 MIT 开源协议,备受业界瞩目。

图 1 IDOL 速览
为什么 IDOL 这么受欢迎?因为它为单图 3D 人体重建问题提供了一种全新的高效解决方案。该模型不仅能够在单 GPU 上以秒级速度生成高分辨率的逼真 3D 人体,还具备实时渲染、直接动画化与编辑的能力,为 VR/AR、虚拟数字人以及相关领域的应用提供了全新思路。
- 论文标题:IDOL: Instant Photorealistic 3D Human Creation from a Single Image
- 论文地址:https://arxiv.org/pdf/2412.14963
- 项目主页:https://yiyuzhuang.github.io/IDOL
- 该工作已开源:https://github.com/yiyuzhuang/IDOL(开源协议为 MIT,可商用)
,时长01:11
IDOL demo video
单图重建人体,为什么这么难?
从单幅图像重建高质量且可驱动的人体模型是一项极具挑战性的任务。这一挑战主要源于人体姿态和衣物拓扑外观的多样性,以及缺乏大规模高质量的训练数据。
当前解决这一问题的方案通常面临以下困难:
- 优化时间长:基于扩散模型的优化过程耗时较长,通常需要数分钟甚至数小时。
- 依赖准确的 SMPL 参数估计:采用参数化人体模型作为拓扑先验,依赖精确的 SMPL-X 参数估计,且迭代优化时间较长。
- 泛化性不足:处理大姿态、大侧面视角以及宽松衣物等挑战性样本时,泛化能力不足。
- 缺乏真实感:重建结果常常出现卡通化或过饱和的现象,且对不可见区域的补充往往不够自然。
- 动画化困难:许多重建方法未充分考虑后续的驱动需求,需额外的骨骼绑定(rigging)处理。且表达方式的限制使其难以泛化到新姿态。
- 编辑能力受限:生成的 3D 模型往往难以直接进行外观修改,需要额外的 UV 展开等处理。
IDOL 为什么有效?
作者提出了一种高效且可扩展的重建框架,通过训练一个简单的前馈模型(IDOL),实现了即时且可泛化的真实感 3D 人体重建。
大规模数据集 HuGe100K
作者通过微调构建了一个能够生成高视点一致性的多视点图像生成网络(MVChamp),并创建了 HuGe100K 数据集——一个以人为中心的大规模生成数据集。
该数据集包含超过 240 万张高分辨率(896×640)的人体多视图图像,共计 100K 个(10 万组)样本。每组图像通过一个可控姿势的图像到多视角生成模型生成,共包含 24 个视角帧。
数据集涵盖了多样化的个体特征(包括不同年龄、性别、体型、服饰和场景)为模型训练提供了充足的样本,从而显著提升了模型在各种复杂条件下的重建能力。

图 2 构建 HuGe100K 数据集的路线图
前馈式 Transformer 重建模型 IDOL
基于此数据集,我们训练了一个预训练的编码器和一个基于 Transformer 的骨干网络,能够在 1 秒内实现快速重建。
该模型能够直接从单张输入图像中预测出人体在统一空间下的 3D 高斯表示。通过将人体姿势、体型、服装几何结构与纹理进行解耦,模型不仅能生成高保真 3D 人体,还能实现无需后处理的直接动画化,为后续的形状与纹理编辑提供了便利。

图 3 IDOL 的技术路线图
方法流程与技术细节,如图 3:
1. 数据集构建流程
- 文本提示与图像生成:利用先进的文本到图像生成模型(如 Flux),设计描述性提示语,确保在「区域、服饰、体型、年龄、性别」等维度上实现均衡采样,从而生成 10 万张高质量全身人体图像(经过人工筛选,保留 90K 张合成图像,并融合 10K 张真实图像)。
- 多视角图像生成:基于生成的全身图像,通过训练多视角视频生成模型(MVChamp),再结合 SMPL-X 人体模板进行姿态拟合,获得 24 个均匀分布的视角图像,确保数据在 3D 一致性上的准确性。
2. 模型架构
- 高分辨率编码器:采用预训练的人体基础模型 Sapiens,对 1024×1024 高分辨率图像进行特征提取,保留图像中的细粒度信息。
- UV 对齐 Transformer:通过学习的 UV Token 与图像特征进行融合,将不规则的输入图像映射到规则的 2D UV 空间中,此空间由 SMPL-X 模型定义,能够提供丰富的几何和语义先验。
- UV 解码器:将融合后的特征重构成 3D 高斯属性图(包括位置偏移、旋转、尺度、颜色及不透明度),从而得到用于重建人体的高斯表示。
- 动画与渲染:利用线性混合蒙皮(LBS)技术,根据预定义的关节运动,对高斯表示进行前向变换,实现人体在不同姿态下的动画化。
3. 训练目标与损失函数
- 模型采用多视角图像监督,利用均方误差(MSE)和基于 VGG 网络的感知损失共同优化。这样的组合既保证了重建图像在像素级别的准确性,又能提高整体的感知质量,使生成的人体纹理更为自然、细腻。
本方法的优势:高效与实时性
IDOL 模型经过优化后,在单个 GPU 上仅需不到 1 秒即可重建 1K 分辨率的逼真 3D 人体,极大地提升了实用性和应用场景的广泛性。该方法具有以下优势:
- 1 秒内完成高质量 3D 角色重建;
- 统一的 UV 表达与大规模数据集支撑,泛化性强;
- 可驱动性,无需额外绑骨;
- 支持形变与纹理编辑;
- 基于 3DGS 的表达,支持实时渲染。
定量看 IDOL 怎么样?
IDOL 与其他方法的对比
IDOL 相较传统 3D 建模方法实现多重突破:自研 10 万级多视角数据集 HuGe100K(传统方法仅依赖少量扫描数据),显著提升模型泛化能力;
创新性融合 SMPL-X 人体拓扑与 UV 展开的高斯溅射属性(替代传统体素/隐式场),实现解剖学精准建模;
1 秒级实时重建(传统需数小时)且支持线性蒙皮自动驱动动画(无需手动 RIGGING),更具备形变、换装等灵活编辑特性。

表 1 IDOL 与传统方法对比一览
HuGe100K 与其他数据集的对比
通过对模型中各关键组件(如 Sapiens 编码器、HuGe100K 数据集)的逐一剔除测试,验证了各模块对整体性能的重要贡献,证明了数据集规模与高分辨率特征提取对高质量重建不可或缺。
与现有数据集相比,HUGE100K 以 100K 个体数量(远超同类最高 4500 个 ID)和超 2.4M 帧数的规模,成为目前全球最大、多样性最丰富的 3D 人体数据集。
- 多样性突破:覆盖 10 万级体型与姿态,解决模型泛化瓶颈;
- 动态建模:百万级多视角帧包含多样化姿态;
- 准确动作标注:集成准确的 SMPL-X 参数,无缝适配主流 3D 工具链。为单图重建、数字人驱动提供工业化级数据引擎,填补了高多样性、大规模动态人体数据的空白。

表 2 HuGe 100K 数据集与其他数据集对比
重建质量对比
IDOL 在与现有方法(如基于迭代优化的 GTA、SIFU 等)对比中,IDOL 在 MSE、PSNR 和 LPIPS 等指标上均取得显著优势,证明了其在重建精度和细节保留上的优越性。

表 3 对比实验及消融实验指标
实验验证了 IDOL 在不同场景和姿态下均能生成细节丰富、纹理一致的 3D 人体。
无论是复杂服饰、特殊角度拍摄,还是不同体型的人体重建,IDOL 均表现出极好的泛化能力和鲁棒性。

图 4 IDOL 与其他方法效果对比
IDOL 未来能做什么?
IDOL 方法不仅在技术上取得了显著突破,其应用前景也十分广阔。其开源协议 MIT 自由可商用,欢迎大家随意搭建到自己的应用中。
利用 IDOL 生成的 3D 人体,用户可以直接进行形状和纹理编辑,例如调整服装图案或改变体型参数。同时,结合动画技术,该模型还可以实现视频中的身份替换等应用,展现出极高的实用价值。
虚拟现实与增强现实:
即时生成真实感 3D 人体模型为 VR/AR 应用提供了新的交互方式,可以实现实时虚拟形象替换、数字孪生等创新应用场景。
数字娱乐与游戏开发:
通过单图重建,游戏开发者可以快速生成高质量角色模型,大幅降低建模成本,加速内容创作流程,从而推动数字娱乐产业的发展。
虚拟试衣与时尚产业:
在电商和虚拟试衣领域,利用 IDOL 技术可以实现用户上传单张照片后即刻生成 3D 人体模型,为消费者提供个性化试衣、定制服务,提升用户体验。
这篇论文通过创新性的单图重建思路,实现了从单张 2D 图像瞬时生成高质量 3D 人体模型的目标。其核心在于将视频模型先验、人体先验、隐式表示与可微渲染技术紧密结合,构建了一个端到端可微分的优化框架。重构了传统单目人体重建的管线(图片→3D→绑骨→驱动),极大的提高了泛化性与实用性。
实验结果证明,IDOL 在重建精度、纹理细节和实时性方面均表现出色,展现了广泛的应用前景。
未来,随着技术的不断演进和数据规模的进一步扩大,该方法有望在 VR/AR、游戏、时尚等领域引领一场 3D 数字内容创作的革新,为实际应用提供更加高效、真实的解决方案。

















 1285
1285

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









