







我自己的原文哦~ https://blog.51cto.com/whaosoft/13076849
#Deepfake Detection
ACM Computing Surveys | 港大等基于可靠性视角的深度伪造检测综述,覆盖主流基准库、模型
本文作者包括香港大学的王天一、Kam Pui Chow,湖南大学的廖鑫 (共同通讯),圭尔夫大学的林晓东和齐鲁工业大学 (山东省科学院) 的王英龙 (第一通讯)。
基于深度神经网络对人脸图像进行编辑和篡改,深度伪造的发展为人们的生活带来了便利,但对其错误的应用也同时危害着人们的隐私和信息安全。
近年来,针对深度伪造对人们隐私安全造成的危害,虽然领域内的研究者们提出了基于不同角度和不同算法的检测手段,但是在实际的深度伪造相关案例中,鲜有检测模型被成功应用于司法判决,并真正做到保障人们的隐私安全。
近日,一篇基于可靠性视角的深度伪造检测综述收录在 ACM Computing Surveys (IF=23.8)。文章作者分析,在当前深度伪造领域内的研究中,尚缺乏一条完整的桥梁,可以将成熟的深度伪造检测模型与其在实际案例中的潜在应用联系起来。
- 论文标题:Deepfake Detection: A Comprehensive Survey from the Reliability Perspective
- arXiv 地址: https://arxiv.org/abs/2211.10881
本综述由香港大学、齐鲁工业大学、湖南大学、圭尔夫大学联合发布,从可靠性的角度全面回顾了当前领域内的常用深度伪造基准数据库 (表 1) 和代表性检测模型,并基于现有检测模型的类型和优缺点,提出了三个值得领域内研究者们持续探索的话题和挑战 (图 1):迁移性、可解释性和鲁棒性。

表 1: 依据质量、多样性、难度等特点而划分的三代深度伪造基准数据库信息。
三大话题和挑战
迁移性话题关注已完成训练的深度伪造检测模型是否能够在未曾见过的数据和篡改算法上依然维持令人满意的检测准确率。
详细来说,当一个深度伪造检测器在被广泛使用的 FaceForensics++ 数据集上完成训练后,除了在 FaceForensics++ 的测试集上展现出色的检测准确率,仍需要能够在 cross-dataset 和 cross-manipulation 设定下,维持较为稳定的效果。此目标旨在避免针对持续迭代出现的新的伪造数据和伪造算法时无休止地增加模型训练成本。
可解释性话题侧重于检测模型在判断真伪的同时能否额外提供令人信服的证据和通俗易懂的解释。
详细来说,当一个深度伪造检测器判断一张图片的真伪时,通常只能提供对其真或假的判断结论,以及在各个实验数据集上测试时的检测准确率。然而,对于需要依赖于检测模型来保护个人隐私信息的非专业人士,能够提供除准确率指标之外通俗易懂的额外证据 (例如,被标记的伪造区域定位或被可视化的伪造痕迹和噪声) 是极其重要的。
鲁棒性话题则基于已有的客观模型检测效果,着眼于实际生活场景,关注深度伪造素材在传播中遭受主观和客观画质损失后,是否依然可以被检测器正确判断。
详细来说,深度伪造素材的危害随着其在网络中的持续性传播而不断增加,而在上传、下载、转载等传播过程中,受不同平台对素材属性的限制和协议要求,该素材将不可避免地遭受质量上的折损和降低。另一方面,当攻击者 (即深度伪造素材的制造者) 已知领域内已有针对各类深度伪造算法的检测手段时,其会刻意向伪造的素材内有针对性地添加能够一定程度上扰乱深度伪造检测器的噪声。以上两类情况,都需要依赖于深度伪造检测模型的鲁棒性,从而可以持续地在实际生活案例中发挥作用。

图 1 : 关于三种话题和挑战的阐述
评估与实验
除了深入探讨三个话题和挑战的意义以及综述性地总结领域内的相关工作之外,本文还着重提出了一个针对模型可靠性的评估方法 (图 2)。
该方法受到司法鉴定中对 DNA 比对过程的启发,通过模拟和构建真实世界中的深度伪造数据的总 population,引入统计学中随机采样的方法,科学且严谨地评估深度伪造检测模型的可靠性,从而提供关于模型性能的统计学指标,以作为法庭审判的潜在证据和辅助证据。基于该指标,可得出在不同置信度条件下的模型检测准确率结论。该可靠性评估方法的初步探索,旨在提供一条路线可以使众多深度伪造检测模型能够在实际生活案例中真正发挥价值。
同时,该综述通过进行大量实验,在不同的样本集大小、置信度、采样次数等环境设定下,对为解决三种话题和挑战的七个深度伪造检测模型进行模型复现和可靠性分析。

图 2: 深度伪造检测模型可靠性分析算法。
此外,该综述将实验中的深度伪造检测模型应用在受害者分别为明星、政客、普通人的实际深度伪造案例中的假视频进行鉴伪和分析,并针对检测结果提供基于特定置信度条件下的模型检测准确率结论 (图 3)。
实验结果表明,当前领域内的现存深度伪造检测模型分别在迁移性、可解释性、鲁棒性话题方面各有建树,但当令其兼顾两个或三个话题和挑战时,在模型效果上则展现出了显著的权衡和取舍。
然而,通常来说,人们希望,一个可靠的深度伪造检测模型应同时具备良好的迁移性、通俗易懂的可解释性、稳定的鲁棒性,以便能够在实际生活中的深度伪造案例中保护和保障受害者的隐私安全。
因此,本综述论文所总结的理念、发现、结论也为深度伪造检测领域的研究者们提供了新的研究挑战与研究方向。

图 3: 深度伪造检测模型在四个实际案例中的视频上的检测结果以及其对应的 95% 置信度可靠性结论。
第一作者信息
王天一,本科毕业于美国华盛顿大学西雅图分校,修习计算机科学和应用数学双专业;博士毕业于香港大学,研究方向为多媒体取证;现为南洋理工大学在职博士后研究员。
引用信息
Tianyi Wang, Xin Liao, Kam Pui Chow, Xiaodong Lin, and Yinglong Wang. 2024. Deepfake Detection: A Comprehensive Survey from the Reliability Perspective. ACM Comput. Surv. 57, 3, Article 58 (March 2025), 35 pages. https://doi.org/10.1145/3699710
#OpenAI 不装了
左手赚钱,右手就一定有「神奇药水」吗?
近期,OpenAI CEO Sam Altman 一反此前的「故弄玄虚」「卖关子」,在其博客文章中明确表示,「已经知道如何构建通用人工智能(AGI)」。
为何 Sam Altman 这次如此笃定地表示已经明确知道如何做 AGI?要知道,在此前 OpenAI 官方发布的 AGI 路线图中,OpenAI 表示目前尚在 AGI 的 L2(推理者)阶段,在朝着 L3 阶段前进。
目录
01. 从「神奇药水」到「通用软件」:OpenAI 不装了?
OpenAI 要如何构建 AGI?OpenAI 对于 AGI 定义的转变是为了其商业化战略调整铺路?
02. 通用人工智能系统才是 OpenAI 的「金苹果」?撑大「盘子」只是第一步
为什么说「通用」二字直接代表着「钱」?为什么通用人工智能系统才是「金苹果」?
03. Agent 才是最佳落地方式?Agent 方向最大的机会在哪?
Agent 的重要机会方向在哪?能否突破技术局限?
01 从「神奇药水」到「通用软件」:OpenAI 不装了?
Sam Altman 的自信,来自 OpenAI 对于定义 AGI 的转变。
1、据 OpenAI 与微软在 2024 年达成的一项未公开协议中提到,只有当 OpenAI 开发的 AI 系统,有「能力」为早期投资者(包括微软)创造出应得的最大总利润时,才视为实现了 AGI。最大总利润数字为 1000 亿美元。
① 简单来说,OpenAI 和微软将 AGI 定义为了能开发出盈利超 1000 亿美元的 AI 系统。
2、由此,在 OpenAI 看来,对于 AGI 的定义从在广泛的认知任务上能够与人类智能相媲美的人工智能转变成了盈利超 1000 亿美元的 AI 系统。
3、但为了实现 1000 亿的目标,对于 OpenAI 来说并不容易。OpenAI 目前仍处于亏损状态,预计在 2029 年才能实现首次盈利。
4、同样,Sam Altman 在其近期的推特中表示,由于用户使用 ChatGPT 的次数远远超出预期,OpenAI 在会员 PRO 付费订阅业务上仍是亏损状态。
5、2024 年 12 月,OpenAI 宣布了其组织架构调整,分为营利性和非营利性两部分。将现有的有限利润营利性公司 OpenAI Global 转化为特拉华州公共利益公司(Delaware Public Benefit Corporation,PBC。在完成转变后,公司非营利性组织对有限利润营利性公司 OpenAI Global 的股权将转化为 PBC 股份。PBC 将负责运营和控制盈利业务,而非营利组织将单独雇佣一支领导团队和员工,致力于在医疗、教育和科学等领域推进慈善事业。
6、OpenAI 将公司「一分为二」的调整,或许在一定意义上意味着要追求不同的「目标」。从「非盈利组织」到「有限利润公司」的转变,将更为方便地让 OpenAI 实现盈利和对外融资。一半是「赚钱」,另一半是「摘星 ASI」,而后者更像是提高盈利和股价的「砝码」。
7、从 OpenAI 对于定义 AGI 的转变,不难看出,关于「AGI 到底什么」、「是否已经真的找到了构建 AGI 的有效途径」等争议或许对于 OpenAI 来说并不重要,OpenAI 更大的关注点落在了如何做成通用人工智能系统,更进一步确切地讲,OpenAI 更想成为那个未来 10 亿或更多消费者使用的通用人工智能系统的「基石」。
8、OpenAI 技术团队成员 John Hallman 的话很有意思,「当 Sam 以及我们研究人员说 AGI 即将到来时,我们并不是为了卖你神奇的药水、2000 美元的订阅服务,或者诱使你在我们下一轮融资中投资。而是 AGI 时代真的要来了。」
02 OpenAI 更想做通用人工智能系统的基石,撑大「盘子」是第一步
回顾 OpenAI 从 24 年到 25 年伊始的种种动作,都指向了一个共同的关键词「通用」。
1、OpenAI 的目标是期望在未来一年内将用户规模扩大至 10 亿。让消费者在不同端侧、不同平台更好、更多地使用 OpenAI 的产品及服务,进一步扩大其市场「盘子」。
2、在 2024 年 5 月的「春季新品发布会」上,OpenAI 推出了生成模型 GPT-4o,该模型可以接收文本、音频和图像的任意组合作为输入,并实时生成文本、音频和图像的任意组合输出。ChatGPT 基于 GPT-4o 的更新,集成了文本、语音、图像三种模态,相比于以往的 Siri 等语音助手,反应更快,且带感情、更通人性,能让用户感受更为自然的进行交互。GPT-4o 的推出,被认为是 OpenAI 抢夺移动端入口的「信号」。
3、同样,OpenAI 还 ......
03 通用人工智能系统是「金苹果」,而 Agent 是其重要载体
1、AI 为何重要?近来有一些说法将「AI」比作和电力一样重要且广泛可用的资源。电力曾经彻底变革了工业生产和生活方式,重塑了各个领域。
2、「通用」和「广泛可用」是目前业内追求实现 AI 的两个关键点。
3、吴恩达曾指出,AI 技术作为一项通用目的技术,如电力一般正在重塑各个领域。AI 应用是未来产生价值和收入的关键,随着半导体、云基础设施和基础模型的快速发展,AI 技术正成为推动社会进步的新引擎。
4、另一关键点是 AI 作为一种资源应广泛可用。谷歌前 CEO Eric Schmidt 曾提到,希望最大化人工智能技术的优势,AI 与电力、供暖、空调等东西一样重要,甚至可能更为重要,是人类可以利用、甚至滥用的智能,且是每个人都可以获得的智能,所以它极其强大。
5、OpenAI 也曾提到,公司的目标是让高级智能成为一种广泛可用的资源。
6、那么,通用人工智能中的「通用」具体指的是什么?如何构建通用人工智能系统?现在有能达到「通用人工智能」的系统吗?......
#Video Ocean V2.0
视频质量全面升级,依旧完全免费,薅羊毛的快乐等你来!
今日,潞晨 Video Ocean V2.0 正式来袭,本次升级不仅在模型、速度、功能玩法上 “大步进化”,还依旧完全免费,等着你来薅羊毛。创新的技术架构和用户导向的视频生成体验为你呈现全新的数字互动世界。
,赞1049
全面升级:不止于 “想得到”,更要 “拍得到”
在本次版本迭代中,我们对视频质量进行了全面升级:无论是人物、动物、环境,还是特写、近景、远景,画面精细度和真实感,都达到了全新的高度,带给你超级真实的样例。而且,不论是小幅动作还是大运动幅度的动态场景,都能做到流畅自然,让创作更加轻松、便捷。
现在,每个用户都可以轻松掌控镜头,导演属于自己的视觉大片!
三大亮点,让创作不再有束缚
1. 超级真实的画质
- 人物、场景、动作细节尽显逼真,视频中的每一帧都栩栩如生;角色面部、光影变化与环境交互细节,层次感倍增。
2. 运动幅度显著提升
- 无论是飞奔、跳跃还是极限运动场景,动态表现自然流畅,带来酣畅淋漓的视觉冲击;再 “疯狂” 的动作,Video Ocean 也能完美还原。
3. 风格更加多样
- 支持从 3D 写实到 2D 动画、从电影质感到赛博朋克等多重画风切换,让你的每个作品都拥有独特个性、无限惊喜。
现在就来体验 Video Ocean V2.0,让创意不再有束缚,轻松制作属于你的视觉大作!
X 网友都集体上头,热度直冲云霄!
- 不仅真人表现力更强,3D 角色的效果也同样出色。

- 国内用户创作入口:video.luchentech.com/zh-CN
视觉盛宴:多种 Demo,体验 V2.0 的 “大片” 魅力
下面展示几种风格各异的 Demo,看看 Video Ocean V2.0 如何将你的脑洞 “动” 起来:
未来视觉

极限驰骋
,时长00:04
动物世界

,时长00:05
真实瞬间
,时长00:05

萌宠拟人
,时长00:04
,时长00:04
源自开源模型 Open Sora:让 AI 视频创作为人人所及
Video Ocean 视频大模型源自潞晨科技超火热的开源项目 Open Sora。自诞生以来热度持续飙升,一度登上 Github Trending 榜首。目前在 GitHub 上已经疯狂收割 23k+ stars,开发者们爱得不要不要的。Video Ocean 延续了该项目 “让 AI 视频创作为人人所及” 的初衷,这次的诚意也是拉满了,对所有人完全免费开放!

来,聊聊你能玩啥:文生、图生、角色生,一次爽个够!
文生视频:懒得拍摄、剪辑?只需写几行文字交给 AI,它帮你自动生成短片!风格随心选 —— 科幻、暗黑、古风、治愈系,灵感飞扬,创意无极限。
,时长00:04
一只熊猫骑着自行车穿梭在城市街头,车辆飞驰而过,4K 高清画质,电影级质感。
图生视频:给宠物照片 “注入灵魂”,让它在短视频里活蹦乱跳?上传图片,AI 就能将它变成动感十足的短片主角。让你的创意瞬间 “活” 起来!
,时长00:04
一只背上长着翅膀,带着彩虹项圈的小羊从草地上站起来,背景有彩虹和蝴蝶在飞,动画效果。
角色生视频:想拍连续剧或者同一角色出镜,烦恼每次都得重新设计形象?这个功能让你在不同场景下保证角色 “保持一致”,打造专属 IP,轻松实现多期内容联动,简直完美!
,时长00:04
,时长00:04
泰勒・斯威夫特和道恩・强森为你送上新年祝福!
“视频续写 & 重试”:够长够爽,不满意就再来一发
有人喜欢短平快?有人偏爱长叙事?没问题!Video Ocean 支持最长续写到 20 秒,剧情更丰满,转折更多样。故事讲到一半还不过瘾?再加几秒!
而且,如果 AI 给你的初始版本没有击中内心深处的小宇宙,别急,直接点 “重试”—— 它再重新跑一遍,直到把你心里的小期待变成现实。这才叫自由创作,对吧?
全新 UI:像打开新年红包那样简单爽快
既然是 “全面升级”,怎么能少了 UI 改版?Video Ocean 的界面现在主打一个简洁好用:
- 简洁页面:不会埋伏太多功能 “陷阱”,新手拿到手也能秒懂怎么操作。
- 灵活输入框:文字输入、图片上传随意切换。5 秒搞定输入,光速开始生成。
从此,大佬小白都能在这个平台上嗨到飞起!
重点来了:本次升级依旧完全免费!见证真正的 “薅羊毛” 快乐!
别人家的平台,要么限时要么收费,但 Video Ocean 豪气冲天,完全免费啊!不用都感觉亏啊!
- 自媒体人士:换个思路打造爆款,“文案 + AI 短片” 轻松拿流量。
- 制片人导演:想搞大片、拍电影?玩转高难度动作和震撼特效?动作太危险、场景太贵?别担心!借助 AI 生视频,既能省钱又能降风险,大片照样拍得精彩!
- 个人爱好者:想捣鼓个贺岁小视频、二次元翻跳、宝可梦冒险?随时随地,有灵感就能动手,不怕犯错。
- 学生党:做课题、搞展示,一条 AI 视频燃爆全场,老师当场拍桌喊 666!
简直就是一场不花钱的 “创意大纵火”,喜欢就上手,不喜欢就删掉重来,也没损失。
这波操作,为什么大家都在 Pick Video Ocean?
- 技术过硬:自研 Open Sora,23k+ stars 可不是吹的!
- 算力逆天:潞晨科技为你保驾护航,少量机器也能跑出大片效果。
- 质量顶尖:视频质量全面升级,清晰度、流畅度、角色一致性都不逊色大厂。
- 操作门槛低:界面简单明了,生怕你不会用,手把手教你上天。
- 薅羊毛先行:完全免费!无需担心 “没钱尝试”。
- 多场景适用:短片、连续剧、IP 打造,皆可一站式满足。
- 模式灵活:文、图、角色,想怎么折腾就怎么折腾,还能继续写剧情。
最重要的一步:赶紧来体验啊!
点击链接前往 Video Ocean(http://video.luchentech.com/zh-CN),马上注册、登录,上手试一波,让 AI 把你的各种天马行空变成高清 “大片”。错过了,也别说我没提醒 —— 能免费创作视频的好机会可不常见!
别让免费的薅羊毛机会浪费!来,pick 一下!我们在 Video Ocean 等你哦!一起用 AI 把世界玩出花儿来~

#o1不是聊天模型?
24小时热度暴涨,奥特曼、Brockman在线围观
不要再将 o1 当做聊天模型了。
如何定位 o1 模型?你是否常常将其当做一个聊天模型来使用。
在刚刚过去的一天,一篇名为《o1 isn’t a chat model(and that’s the point)》的文章引发了包括 OpenAI CEO Sam Altman、总裁 Greg Brockman 的关注。
这篇文章表示 o1 不是一个聊天模型,我们可以将它想象成一个报告生成器。
原文链接:https://www.latent.space/p/o1-skill-issue
2024 年,OpenAI 接连放出了 o1、o1 pro、o3 模型,随着模型推理能力的提升,随着而来的是高昂的订阅费。但很多人在订阅使用后发现 o1 的表现并不如宣传的那样好,当然也包括本文的作者——曾任SpaceX软件工程师、苹果VisionOS人机交互设计师的Ben Hylak。
Hylak 表示每次他问 o1 一个问题时,都要等上 5 分钟的时间,结果看到的只是一大堆自相矛盾的胡言乱语,还有未经请求的架构图 + 优缺点列表。这让 Hylak 很是恼火,因此直言 o1 就是垃圾。

o1 回答问题,多次自相矛盾。
为了表达心中的愤怒,Hylak 还在社交媒体上分享了这种观点,「我今天一整天都在使用 o1 pro—— 我再怎么强调也不为过 —— 它真的很糟糕。」

「输出内容几乎接近胡言乱语,在同一个答案中多次自相矛盾。例如:我向它征求关于重构的建议。它建议合并文件,但输出的代码块中文件并未合并,然后又出现了完全不相关的结论。」

图源:https://x.com/benhylak/status/1864835651725910023
对于 Hylak 的观点,有人表示赞同,但也有人强烈反对,他们认为 o1 表现非常好。
随着 Hylak 与那些持反对意见的人交流越来越多,他逐渐意识到自己完全错了:他把 o1 当作聊天模型来使用,但实际上 o1 并不是聊天模型。
对于作者态度的转变,奥特曼很是欣慰,表示道:「随着人们学会如何使用 o1(包括 pro 版),观察人们对它态度的转变真是很有趣。」

奥特曼关于这条博客的推文浏览量达到 1.5M 。
Greg Brockman 表示:「o1 是一个不同类型的模型。要获得出色的性能,需要以一种与标准聊天模型不同的新方式来使用它。」

如果 o1 不是聊天模型,那它是什么?
我们可以把它想象成一个报告生成器(report generator)。如果你给定足够的上下文,然后告诉它你想要的输出,o1 通常会一下子确定解决方案。
接下来的问题是,如何使用 o1。
不要写提示,要写 Brief
给它大量的上下文,上下文的数量作者用 ton 来形容,我们可以把它想象成提示的 10 倍。

这张图解释了如何构建一个针对 o1 模型的提示(prompt),并将其分为几个部分。
通常情况下,当你使用像 Claude 3.5 Sonnet 或 4o 这样的聊天模型时,会先提出一个简单的问题并附带一些上下文。如果模型需要更多的上下文,它通常会向你询问。
你会与模型来回迭代,纠正它并扩展需求,直到达到期望的输出。聊天模型本质上是通过这种来回交互的方式从你这里获取上下文。在与模型交互过程中,我们可能会变得越来越懒,只要还能得到好的输出,输入的提示越来越敷衍。
但是,o1 会直接接受那些敷衍的问题,并不会试图从我们这里获取上下文。相反,你需要尽可能多地向 o1 提供上下文。
即使你只是询问一个简单的工程问题,你也需要:
- 详细说明所有你尝试过但没有奏效的方法;
- 添加所有数据库架构的完整 dump;
- 解释你公司的业务、规模(并定义公司特有的术语)。
简而言之,我们要把 o1 当作一个新入职的员工来对待。

把更多的时间用在开头提示上。图源:https://x.com/swyx/status/1839213190816870425
专注于目标:准确地描述你想要什么
一旦你向模型提供了尽可能多的上下文,就需要专注于解释你希望输出是什么。
在大多数模型中,我们会告诉模型我们希望它如何回答我们。例如:你是一位专家级软件工程师。你需要模型进行慢思考且思考的很仔细。
这与使用 o1 取得成功的方法完全相反。不要告诉它如何做 —— 只告诉它做什么。然后让 o1 接管,自行规划和解决问题的步骤。这就是自主推理的作用所在,实际上这比你作为人工环节手动审查和聊天要快得多。

知道 o1 擅长什么、不擅长什么
o1 擅长什么:
- 完美地一次性处理整个 / 多个文件:到目前为止,这是 o1 最令人印象深刻的能力。例如,复制 / 粘贴大量代码,大量关于正在构建内容的上下文,o1 会完全一次性地完成整个文件(或多个文件),通常没有错误,遵循现有模式代码库。
- 减少幻觉:例如,o1 确实擅长定制查询语言(如 ClickHouse 和 New Relic),而 Claude 经常混淆 Postgres 的语法。
- 医疗诊断:Hylak 的女朋友是一名皮肤科医生,当朋友或家人有皮肤问题时,他们通常会给 Hylak 的女朋友发一张照片。当 Hylak 拿照片询问 o1 时,o1 的回答通常与正确答案惊人地接近(约 60%)。对于医疗专业人员来说更有用 ——o1 几乎总能提供极其准确的鉴别诊断。
- 解释概念:Hylak 发现 o1 非常擅长通过示例解释非常困难的工程概念。
- 在制定困难的架构决策时,Hylak 经常会让 o1 生成多个计划,甚至比较这些计划,每个计划都有优缺点。
- 评估:Hylak 一直对使用 LLM 作为评估的判别器持非常怀疑的态度,但 o1 表现出巨大的希望 —— 它通常能够在很少的上下文下确定生成结果是否正确。
o1 做得还不够好的地方:
- 用特定的声音 / 风格写作:Hylak 发现 o1 不擅长写任何东西,尤其是在特定的声音或风格中。它遵循一种非常学术 / 企业的报告风格。

Hylak 尝试让 o1 写这篇博客的一个例子 — — 经过多次反复,它只会写一份平淡的报告。
- 构建整个应用程序:o1 非常擅长一次性构建整个文件,但 o1 不会构建整个 SaaS,至少不会进行大量迭代。不过,它几乎可以一次性完成整个功能,特别是前端功能或简单的后端功能。
延迟从根本上改变了我们对产品的体验。考虑一下电子邮件和短信之间的区别 —— 主要是延迟,语音消息与电话通话 —— 延迟,等等。
Hylak 将 o1 称为「报告生成器」,因为 o1 显然不是聊天模型 —— 它感觉更像电子邮件。
Hylak 认为 o1 将首次使某些产品成为可能 —— 例如,可以从高延迟、长时间运行的后台智能中受益的产品。
用户愿意等待 5 分钟来完成什么样的任务?一个小时?一天?3-5 个工作日?如果设计正确的话,有很多。
需要注意的是,o1-preview 和 o1-mini 支持流式传输,但不支持结构化生成或系统提示。o1 支持结构化生成和系统提示,但尚不支持流式传输。
当开发人员在 2025 年设计产品时,实际使用该模型做什么将会非常重要。
#从今以后,所有淘宝天猫商家都能一键图生视频了
这两年,大模型作为前沿技术,正逐步深入电商行业的各个环节。
2025,这一变革仍在加速:近日,【淘宝星辰 · 图生视频】工具已重磅上线,并对淘宝天猫商家正式开放!
体验地址:https://agi.taobao.com/
(目前仅对淘宝天猫商家开放,普通用户请耐心等待~)
以下视频来源于
阿里妈妈技术
,时长01:32
一、淘宝星辰:懂你,更懂电商!
【淘宝星辰】是由阿里妈妈基于自研的淘宝星辰视频生成大模型推出的视频AIGC工具。依靠先进的自研大模型、海量的电商数据、丰富的设计语言和业内领先的营销经验,【淘宝星辰 · 图生视频】工具在电商视频生成中展现出以下核心优势:
更懂商品的展示手法:基于丰富的电商数据和设计经验,自动识别并应用最适合不同类别商品的展示手法。从产品细节的精准呈现到整体风格的统一协调,确保每一件商品都能以最佳方式展示。
更强的多语种语义遵循能力:深度理解参考图片和多语种指令(中/英),精准捕捉文本指令中的关键动作信息,确保生成视频与用户意图高度契合。
合理的物理和动作规律:严格遵循物理规律和动作规范,确保画面流畅自然,避免出现不符合现实的画面效果,提升视频的真实感和专业度。
稳定的人物、商品和装饰保持:无论是人脸、商品、还是文字、贴纸等装饰元素,始终保持清晰、完整、无抖动或变形,提升视觉一致性。
二、淘宝星辰视频生成大模型
在主流AIGC背景下,视频生成早已不是单纯的生成算法优化和应用,而是一个更加复杂的、系统性的算法工程,其中人、数据、模型、算力是最核心的四个因素。
在2024年3月,我们基于Unet Diffusion Model路线研发并上线了阿瞳木动效视频,实现了视频AIGC在电商场景的首次应用落地,在业内产生了一定的传播度和影响力。但是,由于技术路线、数据等多个因素的限制,阿瞳木动效视频在画面稳定性、内容可控性、目标与动作丰富性等关键要素上,仍然存在较大的进步空间。
从去年3月至今,我们在视频AIGC方向上坚定地持续投入。通过算法、数据、工程等众多团队的密切协作,我们完成了面向生成任务的数据飞轮、自研3D VAE、自研淘宝星辰视频生成大模型(包括Tbstar-T2V、Tbstar-I2V、Tbstar-V2V等)等多个关键模块和模型从0到1的建设。目前,Tbstar-I2V大模型已经应用于【淘宝星辰 · 图生视频】工具中,为用户提供更懂电商的图生视频功能。

淘宝星辰视频生成大模型
三、更懂电商的图生视频3.1 操作便捷
仅需输入一张静态图片,淘宝星辰可根据对图片的理解直接生成视频,也可遵循用户输入的文本描述生成视频,一键生成高质量的5秒视频。

【淘宝星辰 · 图生视频】工具
3.2 更懂商品的展示手法
以更懂电商的方式展示服饰和非服饰商品,尤其是对模特动作的流畅性和专业性提升显著。
prompt:一个模特脸上带着酷酷的表情展示衣服
prompt:模特拿着咖啡,走向镜头,展示衣服
prompt:悬浮的气泡和水滴飘动
prompt:商品不动,植物随风摇动,云雾移动
3.3 更强的多语种语义遵循能力
深度理解参考图片,支持中英输入,精准捕捉文本指令中的关键动作信息,确保生成视频与用户意图高度契合。
prompt:模特拿手机挡着脸,对镜自拍展示衣服
,时长00:05
prompt:男生把手搭在女生肩膀上,两人靠在一起
3.4 专业的光影效果
根据参考图片和用户,推理光线变化,生成电影质感的光影效果。
,时长00:05
prompt:一个女人的脸部特写,创造出柔和的阴影和高光
,时长00:05
prompt:光线缓慢移动,创造出动态的阴影,背景保持不变,突出了人物面部和装饰的微妙变化
3.5 稳定的人物、商品和装饰保持
尤其针对电商图片中常见的文字、贴纸等装饰元素,始终保持清晰、完整、无抖动或变形,提升视觉一致性。
prompt:一个女模特对着镜头展示衣服
prompt:镜头后退,女模特走向镜头,展示衣服
四、高品质低成本的原生化应用
结合解说视频、模版视频等后期剪辑类工具,实现高品质、原生化电商视频的低成本智造,应用至主流电商场景,以及泛娱乐场景。
应用1:商品主图视频供给
单张商品主图一键生成主图视频。
单张主图 vs 主图视频
应用2:卖点吸睛视频
根据多张模特图分别生成视频片段,采用模版视频方式制作商品短视频,添加转场、特效和文字,快速生成吸睛的产品展示视频。

,时长00:11
应用3:服饰一体化解决方案
“模特图”或“平铺图”+虚拟模特,都能轻松生成多样化服饰视频。
根据用户虚拟试穿图片一键生成虚拟试穿视频,模拟服饰的真实上身效果。

用户虚拟试穿图
,时长00:05
用户虚拟试穿视频
应用5:UGC场景视频化
UGC图片一键转为视频,提升视频供给,例如评价、买家秀、逛逛等。
应用6:泛娱乐场景
AIGC时代可以不活但不能没活儿~

prompt:超级英雄和恐龙在沙滩上慢慢散步,背景是城市的天际线
,时长00:09
#FedCFA
破解联邦学习中的辛普森悖论,浙大提出反事实学习新框架
江中华,浙江大学软件学院硕士生二年级,导师为张圣宇老师。研究方向为大小模型端云协同计算。张圣宇,浙江大学平台「百人计划」研究员。研究方向包括大小模型端云协同计算,多媒体分析与数据挖掘。
随着机器学习技术的发展,隐私保护和分布式优化的需求日益增长。联邦学习作为一种分布式机器学习技术,允许多个客户端在不共享数据的情况下协同训练模型,从而有效地保护了用户隐私。然而,每个客户端的数据可能各不相同,有的数据量大,有的数据量小;有的数据特征丰富,有的数据特征单一。这种数据的异质性和不平衡性(Non-IID)会导致一个问题:本地训练的客户模型忽视了全局数据中明显的更广泛的模式,聚合的全局模型可能无法准确反映所有客户端的数据分布,甚至可能出现「辛普森悖论」—— 多端各自数据分布趋势相近,但与多端全局数据分布趋势相悖。
为了解决这一问题,来自浙江大学人工智能研究所的研究团队提出了 FedCFA,一个基于反事实学习的新型联邦学习框架。
FedCFA 引入了端侧反事实学习机制,通过在客户端本地生成与全局平均数据对齐的反事实样本,缓解端侧数据中存在的偏见,从而有效避免模型学习到错误的特征 - 标签关联。该研究已被 AAAI 2025 接收。
论文标题:FedCFA: Alleviating Simpson’s Paradox in Model Aggregation with Counterfactual Federated Learning
论文链接:https://arxiv.org/abs/2412.18904
项目地址:https://github.com/hua-zi/FedCFA
辛普森悖论
辛普森悖论(Simpson's Paradox)是一种统计现象。简单来说,当你把数据分成几个子组时,某些趋势或关系在每个子组中表现出一致的方向,但在整个数据集中却出现了相反的趋势。

图 1:辛普森悖论。在全局数据集上观察到的趋势在子集上消失 / 逆转,聚合的全局模型无法准确反映全局数据分布
在联邦学习中,辛普森悖论可能会导致全局模型无法准确捕捉到数据的真实分布。例如,某些客户端的数据中存在特定的特征 - 标签关联(如颜色与动物种类的关系),而这些关联可能在全局数据中并不存在。因此,直接将本地模型汇聚成全局模型可能会引入错误的学习结果,影响模型的准确性。
如图 2 所示。考虑一个用于对猫和狗图像进行分类的联邦学习系统,涉及具有不同数据集的两个客户端。客户端 i 的数据集主要包括白猫和黑狗的图像,客户端 j 的数据集包括浅灰色猫和棕色狗的图像。对于每个客户端而言,数据集揭示了类似的趋势:浅色动物被归类为「猫」,而深色动物被归类为「狗」。这导致聚合的全局模型倾向于将颜色与类别标签相关联并为颜色特征分配更高的权重。然而,全局数据分布引入了许多不同颜色的猫和狗的图像(例如黑猫和白狗),与聚合的全局模型相矛盾。在全局数据上训练的模型可以很容易地发现动物颜色与特定分类无关,从而减少颜色特征的权重。

图 2:FedCFA 可以生成客户端本地不存在的反事实样本,防止模型学习到不正确的特征 - 标签关联。
反事实学习
反事实(Counterfactual)就像是「如果事情发生了另一种情况,结果会如何?」 的假设性推理。在机器学习中,反事实学习通过生成与现实数据不同的虚拟样本,来探索不同条件下的模型行为。这些虚拟样本可以帮助模型更好地理解数据中的因果关系,避免学习到虚假的关联。
反事实学习的核心思想是通过对现有数据进行干预,生成新的样本,这些样本反映了某种假设条件下的情况。例如,在图像分类任务中,我们可以改变图像中的某些特征(如颜色、形状等),生成与原图不同的反事实样本。通过让模型学习这些反事实样本,可以提高模型对真实数据分布的理解,避免过拟合局部数据的特点。
反事实学习广泛应用于推荐系统、医疗诊断、金融风险评估等领域。在联邦学习中,反事实学习可以帮助缓解辛普森悖论带来的问题,使全局模型更准确地反映整体数据的真实分布。
FedCFA 框架简介
为了解决联邦学习中的辛普森悖论问题,FedCFA 框架通过在客户端生成与全局平均数据对齐的反事实样本,使得本地数据分布更接近全局分布,从而有效避免了错误的特征 - 标签关联。
如图 2 所示,通过反事实变换生成的反事实样本使局部模型能够准确掌握特征 - 标签关联,避免局部数据分布与全局数据分布相矛盾,从而缓解模型聚合中的辛普森悖论。从技术上讲,FedCFA 的反事实模块,选择性地替换关键特征,将全局平均数据集成到本地数据中,并构建用于模型学习的反事实正 / 负样本。具体来说,给定本地数据,FedCFA 识别可有可无 / 不可或缺的特征因子,通过相应地替换这些特征来执行反事实转换以获得正 / 负样本。通过对更接近全局数据分布的反事实样本进行对比学习,客户端本地模型可以有效地学习全局数据分布。然而,反事实转换面临着从数据中提取独立可控特征的挑战。一个特征可以包含多种类型的信息,例如动物图像的一个像素可以携带颜色和形状信息。为了提高反事实样本的质量,需要确保提取的特征因子只包含单一信息。因此,FedCFA 引入因子去相关损失,直接惩罚因子之间的相关系数,以实现特征之间的解耦。

全局平均数据集的构建
为了构建全局平均数据集,FedCFA 利用了中心极限定理(Central Limit Theorem, CLT)。根据中心极限定理,若从原数据集中随机抽取的大小为 n 的子集平均值记为

,则当 n 足够大时,

的分布趋于正态分布,其均值为 μ,方差

,即:

,其中 µ 和

是原始数据集的期望和方差。
当 n 较小时,

能更精细地捕捉数据集的局部特征与变化,特别是在保留数据分布尾部和异常值附近的细节方面表现突出。相反,随着 n 的增大,

的稳定性显著提升,其方差明显减小,从而使其作为总体均值 𝜇 的估计更为稳健可靠,对异常值的敏感度大幅降低。此外,在联邦学习等分布式计算场景中,为了实现通信成本的有效控制,选择较大的 n 作为样本量被视为一种优化策略。
基于上述分析,FedCFA 按照以下步骤构建一个大小为 B 的全局平均数据集,以此近似全局数据分布:
1.本地平均数据集计算:每个客户端将其本地数据集随机划分为 B 个大小为

的子集

,其中

为客户端数据集大小。对于每个子集,计算其平均值

。由此,客户端能够生成本地平均数据集

以近似客户端原始数据的分布。
2.全局平均数据集计算:服务器端则负责聚合来自多个客户端的本地平均数据,并采用相同的方法计算出一个大小为 B 的全局平均数据集

,该数据集近似了全局数据的分布。对于标签 Y,FedCFA 采取相同的计算策略,生成其对应的全局平均数据标签

。最终得到完整的全局平均数据集

反事实变换模块

图 3:FedCFA 中的本地模型训练流程
FedCFA 中的本地模型训练流程如图 3 所示。反事实变换模块的主要任务是在端侧生成与全局数据分布对齐的反事实样本:
1. 特征提取:使用编码器(Encoder)从原始数据中提取特征因子

。
2. 选择关键特征:计算每个特征在解码器(Decoder)输出层的梯度,选择梯度小 / 大的 topk 个特征因子作为可替换的因子,使用

将选定的小 / 大梯度因子设置为零,以保留需要的因子
3. 生成反事实样本:用 Encoder 提取的全局平均数据特征替换可替换的特征因子,得到反事实正 / 负样本,对于正样本,标签不会改变。对于负样本,使用加权平均值来生成反事实标签:

因子去相关损失
同一像素可能包含多个数据特征。例如,在动物图像中,一个像素可以同时携带颜色和外观信息。为了提高反事实样本的质量,FedCFA 引入了因子去相关(Factor Decorrelation, FDC)损失,用于减少提取出的特征因子之间的相关性,确保每个特征因子只携带单一信息。具体来说,FDC 损失通过计算每对特征之间的皮尔逊相关系数(Pearson Correlation Coefficient)来衡量特征的相关性,并将其作为正则化项加入到总损失函数中。
给定一批数据,用

来表示第 i 个样本的所有因子。

表示第 i 个样本的第 j 个因子。将同一批次中每个样本的相同指标 j 的因子视为一组变量

。最后,使用每对变量的 Pearson 相关系数绝对值的平均值作为 FDC 损失:

其中 Cov (・) 是协方差计算函数,Var (・) 是方差计算函数。最终的总损失为:

实验结果
实验采用两个指标:500 轮后的全局模型精度 和 达到目标精度所需的通信轮数,来评估 FedCFA 的性能。



实验基于 MNIST 构建了一个具有辛普森悖论的数据集。具体来说,给 1 和 7 两类图像进行上色,并按颜色深浅划分给 5 个客户端。每个客户端的数据中,数字 1 的颜色都比数字 7 的颜色深。随后预训练一个准确率 96% 的 MLP 模型,作为联邦学习模型初始模型。让 FedCFA 与 FedAvg,FedMix 两个 baseline 作为对比,在该数据集上进行训练。如图 5 所示,训练过程中,FedAvg 和 FedMix 均受辛普森悖论的影响,全局模型准确率下降。而 FedCFA 通过反事实转换,可以破坏数据中的虚假的特征 - 标签关联,生成反事实样本使得本地数据分布靠近全局数据分布,模型准确率提升。

图 4: 具有辛普森悖论的数据集

图 5: 在辛普森悖论数据集上的全局模型 top-1 准确率
消融实验


图 6:因子去相关 (FDC) 损失的消融实验
#国产推理大模型决战2025考研数学
看看谁第一个上岸?
随着上个月 2025 研究生考试的结束,最新的考研数学真题成为大语言模型尤其是推理模型的「试炼场」,将考验它们的深度思考能力。
业内曾有着这样一种共识:大语言模型在文字水平上的表现令人印象深刻,但说到数学就不甚令人满意了。去年一度火出圈的「9.9 与 9.11」比大小的问题,包括 GPT-4o 在内的很多大模型都翻车了,直到深度推理模型出现后才从根本上改善了这一状况。
OpenAI 发布的 o1 模型在涉及复杂和专业的数理问题方面表现让人印象深刻,大模型在经过一定时间仔细思忖后,回答问题的能力和准确度大幅提升,这种被称为推理侧 Scaling Law 的现象已经成为继续推动大模型能力提升的关键力量。在黄仁勋最新 CES 2025 的演讲中,他也把测试时(即推理)Scaling 形容为大模型发展的三条曲线之一。

可以看到,继 o1 之后,国内大模型厂商也陆续推出了自己的深度推理模型,并在某些任务上有亮眼的表现。数了一下时间轴大概是这样的:
- 2024 年 11 月 21 日,深度求索团队发布 DeepSeek-r1 模型;
- 2024 年 11 月 28 日,阿里通义团队发布 QwQ 模型;
- 2024 年 12 月 16 日,月之暗面团队发布 Kimi-k1 模型;
- 2024 年 12 月 31 日,智谱 GLM 团队发布 GLM-Zero 模型;
- 2025 年 1 月 6 日,昆仑万维发布 Skywork-o1 模型。
大家也许会好奇,这些深度推理模型的能力(尤其是数学推理能力)到底有多强,又是谁能拔得头筹呢?这时就需要一场公平的标准化考试了。
清华 SuperBench 大模型测评团队(以下简称测评团队)为了全面评估这些模型在数学推理方面的能力,结合 2025 年考研数学(一、二、三)的试题,专门对以上各家深度推理模型进行了严格的评测。同时,为了确保评测的全面性,参与评测的还包括各家的旗舰基础模型。
此次选择的 13 个模型具体如下:

从结果来看,所有模型中以平均分计,第一名是 OpenAI 的 GPT-o1模型,这也是没什么意外的。第二名则是来自智谱的 GLM-Zero-Preview,它以三门数学平均 138.70 的成绩仅次于 o1,成为国产大模型第一,且距第一名不到 3 分。第三名则是来自通义的 QwQ。

测试方法
在本次评测过程中,测评团队发现并非所有模型均提供 API 支持,且部分提供 API 服务的模型在输出内容长度超出一定限制时,会出现内容截断的情况。为确保评测工作的公正性与准确性,测评团队决定统一采用各模型厂商的网页端进行测试操作。
在测试过程中,每道题目均在独立的对话窗口中进行,以此消除上下文信息对测试结果可能产生的干扰。
鉴于部分模型输出存在一定不稳定性,为降低由此引发的分数波动,测评团队设定当同一模型在三次测试中有两次及以上回答正确时,方将其记录为正确答案。
结果分析
接下来从测试总分、单张试卷分数、深度思考模型 vs 基础模型三个方面来详细分析此次测评的结果。
总分
对于总分数,测评团队对三张试卷的分数进行求和并计算平均值,按照分数高低进行排序。结果如下图所示:
从图中可以看到,GPT-o1 仍然处于领先的地位,是唯一一个达到 140 分以上的模型,相较于排名末位的 GPT-4,分数优势高达 70 分。
位于第二梯队(130 分以上)的模型有 GLM-zero-preview 和 QwQ,分别斩获 138.7 分和 137.0 分。
DeepSeek-r1-lite、Kimi-k1、Tiangong-o1-preview、DeepSeek-v3 则处于第三梯队(120 分以上)。

可以看出,深度思考模型普遍能够达到 120 + 的水平。这也彰显了深度思考模型在解决数学问题方面的强大能力。
值得注意的是,曾于 2023 年位居榜首的基础模型 GPT-4,在本次测试中仅获 70.7 分,位列末席。这一结果表明,在过去一年(2024 年)中,语言模型在数学推理领域的进步显著。
而另一方面,在缺乏深度思考能力辅助的情况下,仅凭逻辑推理能力,DeepSeek-v3 作为基础模型,已经能够跻身第三梯队,这说明基础模型和深度思考模型之间的能力并非界限分明。
单张试卷分析
为了更清晰地展现大模型在各张试卷答题能力方面的表现,测评团队对每张试卷的错题分布情况进行了深入分析。
在数学一的评测过程中,GPT-o1、GLM-zero-preview、QwQ、DeepSeek-r1-lite 四款模型的得分相同。通过进一步剖析错题情况,测评团队发现所有模型均在第 20 题(12 分,涉及曲面积分求解)以及第 21 题第二问(6 分,涉及特征向量求解)上出现了错误。


在数学二的评测中,各模型的分数分布较为分散。经统计分析发现,第 3 题、第 5 题、第 7 题成为所有模型犯错的集中区域。具体错题分布情况如下图所示:


针对数学三的评测结果显示,模型出错的重灾区主要集中在第 14 题、第 15 题、第 16 题、第 19 题。相关错题分布情况如下图所示:


综合上述各试卷错题的具体分析,我们可以清晰地看到,GPT-o1(阴影列所示)在总计 66 道题目中,仅答错 3.5 道题;并且 GPT-o1 答错的题目,其他模型亦普遍存在错误,这显示了 GPT-o1 目前依然是深度推理模型的天花板。
基础模型 vs 深度思考模型
最后,为了全面深入地探究各模型厂商在深度思考能力优化方面所取得的成果,测评团队对相应基础模型与深度思考模型进行了细致对比分析。
需要说明的是,此处对比并非意味着各深度思考模型是基于对应基础模型所做优化,其主要目的在于直观呈现各厂商在模型综合能力提升方面的进展与成效。
相关对比结果如下图所示:

注:OpenAI 的基础模型采用的是 GPT-4o。

通过对比分析,OpenAI 的深度思考模型 GPT-o1 相较于基础模型 GPT-4o,提升幅度最为显著,达到 57.3 分。紧随其后的是阿里的 Qwen 模型和智谱的 GLM 模型,提升幅度分别为 47.0 分和 34.3 分。
另外,深度求索和月之暗面的提升幅度相对较小,这主要是由于其基础模型本身分数较高。以深度求索为例,其基础模型 DeepSeek-v3 初始分数高达 120.3 分,在参评基础模型中位居榜首。
在本次测试中,测评团队选取表现最为优异的基础模型 DeepSeek-v3 作为参照基准,进而对各厂商深度思考模型的性能提升情况进行评估,相关数据呈现如下图所示:

可以看出,OpenAI、智谱、阿里在深度思考模型上的性能提升做了很大的优化,而 DeepSeek-v3 等其他模型在本项测试中的结果基本接近。
这些测试结果一一看下来,我们可以发现:虽然 OpenAI 的 o1 在深度推理方面仍然是最强的,但国产推理大模型正在逐渐缩小与它的差距,此次智谱 GLM-zero-preview 和阿里 QwQ 的成绩说明了这一点。
#余弦相似度可能没用?
对于某些线性模型,相似度甚至不唯一
好不容易找了把尺子,结果尺子会随机伸缩。
在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。
然而,Netflix 和康奈尔大学的一项研究挑战了我们对这种流行方法的理解:余弦相似度可能导致任意且毫无意义的结果。
论文地址:https://arxiv.org/pdf/2403.05440v1
余弦相似度通过测量两个向量的夹角的余弦值来度量它们之间的相似性,机器学习研究常常通过将余弦相似性应用于学得的低维特征嵌入来量化高维对象之间的语义相似性。但在实践中,这可能比嵌入向量之间的非标准化点积效果更好,但有时也更糟糕。

图源:https://www.shaped.ai/blog/cosine-similarity-not-the-silver-bullet-we-thought-it-was
为了深入了解这一经验观察,Netflix 和康奈尔大学的研究团队研究了从正则化线性模型派生的嵌入,通过分析得出结论:对于某些线性模型来说,相似度甚至不是唯一的,而对于其他模型来说,它们是由正则化隐式控制的。
该研究讨论了线性模型之外的情况:学习深度模型时采用不同正则化的组合,当对结果嵌入进行余弦相似度计算时,会产生隐式和意想不到的效果,使结果变得不透明并且可能是任意的。基于这些见解,研究团队得出结论:不要盲目使用余弦相似度,并概述了替代方案。
最近,这篇论文在机器学习社区再度引起热议,一篇题为《Cosine Similarity: Not the Silver Bullet We Thought It Was(余弦相似度:不是我们想象的灵丹妙药)》的博客概述了研究内容。

博客地址:https://www.shaped.ai/blog/cosine-similarity-not-the-silver-bullet-we-thought-it-was
有网友表示:「问题没那么严重,相似度指标需要根据嵌入空间进行量身定制,需要测试不同的指标来建立定性评估。」

网友认为余弦相似度应该是一个足够好的方法。毕竟,「根据 OpenAI 关于嵌入的文档,他们还在代码片段中使用了余弦相似度。」

这个结论是怎么得出来的呢?让我们一起看看这篇论文的主要内容,一探究竟。
研究简介
研究团队发现了一个重要问题:在特定场景下,余弦相似度会随意产生结果,这使得该度量方法变得不可靠。
研究着重分析了线性矩阵模型。这类模型能够得到封闭形式的解与理论分析,在推荐系统等应用中被广泛用于学习离散实体的低维嵌入表示。
研究分析了 MF 模型的两个常用训练目标:

其中 X 是输入数据矩阵,A 和 B 是学习到的嵌入矩阵,λ 是正则化参数。
问题根源:正则化与自由度
研究人员发现,第一个优化目标(等同于使用去噪或 dropout 的学习方式)在学习到的嵌入中引入了一个关键的自由度。这种自由度允许对嵌入维度进行任意缩放,却不会影响模型的预测结果。
从数学角度来看,如果 Â 和 B̂ 是第一个目标的解,那么对于任意对角矩阵 D,ÂD 和 B̂D^(-1) 也是解。这种缩放会影响学习到的嵌入的归一化,从而影响它们之间的余弦相似度。

来自论文:《Is Cosine-Similarity of Embeddings Really About Similarity? 》
举两个随意产生结果的例子:
1. 在全秩 MF 模型中,通过适当选择 D,item-item 余弦相似度可以等于单位矩阵。这个奇怪的结果表明每个 item 只与自己相似,而与所有其他 item 完全不相似。
2. 通过选择不同的 D,user-user 余弦相似度可以简化为 ΩA・X・X^T・ΩA,其中 X 是原始数据矩阵。这意味着相似度仅基于原始数据,完全没有利用到学习的嵌入。
线性模型之外
除了线性模型,类似的问题在更复杂的场景中也存在:
1. 深度学习模型通常会同时使用多种不同的正则化技术,这可能会对最终嵌入的余弦相似度产生意想不到的影响。
2. 在通过点积优化来学习嵌入时,如果直接使用余弦相似度,可能会得到难以解释且没有实际意义的结果。
研究人员提出了几种解决这些问题的方法:
- 直接针对余弦相似度训练模型,可能需要借助层归一化等技术。
- 完全避免在嵌入空间中工作。相反,在应用余弦相似度之前,先将嵌入投影回原始空间。
- 在学习过程中或之前应用归一化或减少流行度偏差,而不是像余弦相似度那样仅在学习后进行归一化。
语义分析中余弦相似度的替代方案
在论文的基础上,博客作者 Amarpreet Kaur 归纳了一些可以替换余弦相似度的备选项:
- 欧几里得距离:虽然由于对向量大小敏感而在文本数据中不太流行,但在嵌入经过适当归一化时可以发挥作用。
- 点积:在某些应用中,嵌入向量之间的非归一化点积被发现优于余弦相似度,特别是在密集段落检索和问答任务中。
- 软余弦相似度:这种方法除了考虑向量表示外,还考虑了单个词之间的相似度,可能提供更细致的比较。

图源:https://www.machinelearningplus.com/nlp/cosine-similarity/
- 语义文本相似度(STS)预测:专门为语义相似度任务训练的微调模型 (如 STSScore) 有望提供更稳健和和更可解释的相似度度量。
- 归一化嵌入与余弦相似度:在使用余弦相似度之前,应用层归一化等归一化技术能有效提升相似度计算的准确性。
在选择替代方案时,必须考虑任务的具体要求、数据的性质以及所使用的模型架构。通常需要在特定领域的数据集上进行实证评估,以确定最适合特定应用的相似度。
我们经常用「余弦相似度」来计算用户或物品之间的相似程度。这就像是测量两个向量之间的夹角,夹角越小,相似度越高。论文中的实验结果也表明,余弦相似度给出的答案经常与实际情况不符。
在比较简单的线性模型上都已经如此随机,在更复杂的深度学习模型中,这个问题可能会更严重。因为深度学习模型通常使用更多复杂的数学技巧来优化结果,这些技巧会影响模型内部的数值大小,从而影响余弦相似度的计算。
这就像是把一个本来就不太准的测量工具放在一个更复杂的环境中使用,结果可能会更不可靠。因此,需要寻找更好的方法,比如使用其他相似度计算方式,或者研究正则化技术对语义的影响。这提醒大家:在开发 AI 系统时,要多思考、多测试,确保工具真的好用。
对于这项研究的结论,你怎么看?
#Forest-of-Thought
思维链?思维树?华为诺亚:现在到了思维森林时刻!
OpenAI 接连发布 o1 和 o3 模型,大模型的高阶推理能力正在迎来爆发式增强。在预训练 Scaling law “撞墙” 的背景下,探寻新的 Scaling law 成为业界关注的热点。高阶推理能力有望开启新的 Scaling law,为大模型的发展注入新的活力。
近日,华为诺亚方舟实验室的研究人员提出了一个名为思维森林 “Forest-of-Thought”(FoT)的全新大模型高阶推理框架,它通过在推理时扩展计算规模,显著提升了 LLM 的高阶推理能力。
- 论文链接:https://arxiv.org/abs/2412.09078
- 项目链接:https://github.com/iamhankai/Forest-of-Thought
LLM 的推理困境
尽管 LLM 在多种语言任务上表现出色,但在解决复杂推理问题时,它们常常陷入困境。以数学问题为例,LLM 可能会在分解问题的过程中忽略关键细节或在中间步骤中出错,导致最终答案错误;通常完成一条推理路径后,大模型通常不会重新审视其他可能的方法,这种缺乏重新评估的能力使得解决方案无法全面应对复杂的问题。相比之下,人类在处理复杂问题时,会从不同角度反复思考和验证,以确保答案的准确性。
思维森林 FoT 方法介绍
图 1 中的 FoT 框架通过整合多个推理树,利用集体决策的优势来解决复杂的逻辑推理任务。它采用稀疏激活策略,选择最相关的推理路径,从而提高模型的效率和准确性。此外,FoT 还引入了动态自校正策略,使模型能够在推理过程中实时识别和纠正错误,并从过去的错误中学习。共识引导决策策略也被纳入其中,以优化正确性和计算资源的使用。

图 1 思维森林 FoT
稀疏激活策略
在 FoT 的推理过程中,并不是所有的推理树或树中的每个节点都会被计算,而是只选择最相关的推理树或节点进行计算。这种方法不仅提高了效率,还通过选择最相关的推理路径来提高模型的准确性。通过稀疏激活,FoT 能够过滤掉每个推理树的激活,确保只有某些推理树的路径被 “激活” 用于推理。
动态自校正策略
为了提高每个推理树给出正确答案的概率,FoT 引入了动态自校正策略。对于推理树的初始结果,自校正策略会评估其正确性和有效性,并在每个推理步骤完成后分配相应的分数。一旦某个步骤的分数低于预设阈值,策略会自动触发校正机制。该机制首先回顾和分析过去的失败案例,识别低分和常见错误模式的原因,然后尝试纠正错误并优化推理方向。通过这种从历史中学习和实时校正的机制,模型不仅避免了在相同问题上重复犯错,还能更迅速、更准确地找到解决新问题的有效方法。

图 2 动态自校正策略
共识引导决策策略
为了解决复杂的数学问题,FoT 设计了共识引导专家决策(CGED)策略,以确保最终答案的高准确性和可靠性。CGED 方法结合了集体智慧和专家判断,引导推理过程从基于共识的决策转向专家评估。在 FoT 方法中,每个独立树通过其独特的推理路径生成一个或多个可能的答案。子树会对候选答案进行投票,选出获得最多支持的答案。如果无法达成共识,数学专家将评估推理过程并选择最终答案,以确保其准确性和有效性。
实验结果
研究人员在多个 LLM 推理基准测试中评估了 FoT 方法,包括 24 点游戏、GSM8K 和 MATH 数据集,使用了多个开源 LLM 模型,包括 Llama3-8B,Mistral-7B 和 GLM-4-9B。
24 点游戏
24 点游戏的目标是使用给定的四个数字各一次,通过加、减、乘、除和括号构造一个算术表达式,使其结果为 24。表 1 中的实验结果表明,当推理树的数量从 2 增加到 4 时,FoT 的准确率提高了 14%,显示出显著的推理性能提升。相比之下,仅增加单个树的叶子节点数量的 ToT 方法遇到了性能瓶颈,进一步增加叶子节点数量并未带来显著的性能提升。这表明 FoT 通过多棵树提供的推理路径多样性比单纯增加单个树的复杂性更有效,凸显了 FoT 框架在实现可扩展和高效推理改进方面的优势。

表 1 24 点游戏,Llama3-8B 基模型,b 是叶子节点数量,n 是树数量
GSM8K 基准测试
研究人员在 GSM8K 数据集上评估了 FoT 在不同基模型上的性能。图 3 中的实验结果表明,基于不同的大语言模型 Llama3-8B,Mistral-7B 和 GLM-4-9B,都存在类似的 scaling law:FoT 中的树数量越多,带来的准确率提升越显著。

图 3 FoT 在不同基模型的性能
MATH 基准测试
在 MATH 数据集上,FoT 算法在不同复杂度级别的问题上均展现出一致的性能提升。如表 2 所示,从最简单的 level1 到最具挑战性的 level5,FoT(n=4)的准确率比 MCTSr 提高了约 10%。这种一致的提升凸显了 FoT 方法在处理从简单到复杂问题的有效性。

表 2 FoT 在 MATH 数据集上的性能
FoT 的广泛应用前景
FoT 框架不仅在理论上具有创新性,而且在实际应用中也具有广泛的前景。它可以帮助 LLM 在数学、逻辑、金融、医疗和法律等需要复杂推理的领域中更好地发挥作用。例如,在金融领域,FoT 可以用于风险评估和投资决策分析;在医疗领域,它可以辅助医生进行疾病诊断和治疗方案制定;在法律领域,FoT 可以用于案例分析和法律推理。此外,FoT 还可以与现有的 LLM 相结合,提升其在法律、教育、科研等领域的应用效果,为用户提供更加智能、准确的服务。
结语
思维森林 Forest-of-Thought 框架的提出,为 LLM 的推理能力提升提供了一条新的路径。它通过多路径探索和动态激活推理路径的结构化框架,有效解决了现有 LLM 推理范式中的关键局限。FoT 不仅提高了模型在复杂任务中的问题解决能力,还生成了多样化的推理结果,无需依赖反向传播或微调。随着大模型在日常工作和生活的不断渗透,FoT 有望在更多的应用场景中发挥重要作用,推动大模型向更智能、更高效的方向发展。
#AC3D
同时提升摄像机控制效率、视频质量,可控视频生成架构AC3D来了
可控的视频生成需要实现对摄像机的精确控制。然而,控制视频生成模型的摄像机运动(camera control)总是不可避免地伴随着视频质量的下降。近期,来自多伦多大学、Vector Institute、Snap Research 和西蒙・弗雷泽大学(SFU)的研究团队推出了 AC3D (Advanced 3D Camera Control)。AC3D 从基本原理出发,分析了摄像机运动在视频生成中的特点,并通过以下三方面改进了视频生成的效果和效率:
1. 低频运动建模:研究发现视频中的摄像机运动具有低频特性。研究者优化了训练和测试的条件调度,加速了训练收敛,同时提升了视觉和运动质量。
2. 摄像机信息表示:通过研究无条件视频扩散变换器的表示,研究者观察到其内部隐含地进行了摄像机姿态估计。将摄像机条件注入限制在特定子层,既减少干扰,又显著降低了参数数量并提升训练速度和视觉质量。
3. 数据集改进:通过加入包含 20,000 段动态视频的高质量静态摄像机数据集,增强模型区分摄像机运动与场景运动的能力。这些发现促成了 AC3D 架构的设计,从而同时提升了摄像机控制的效率以及视频的质量,使得 AC3D 在具有摄像机控制的生成视频建模中达到了新的技术水平。
,时长00:14
- 论文标题:AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
- 论文地址:arxiv.org/abs/2411.18673
- 项目地址:snap-research.github.io/ac3d/
方法介绍
研究者首先搭建了文生视频扩散模型作为基础模型,对该模型进行分析,从而得到摄像机控制的第一性原理。然后研究者基于这些原理设计了 AC3D。
基础模型:视频扩散模型
AC3D 基于 VDiT(Video Diffusion Transformer)采用了标准的 Transformer 结构进行构建。VDiT 通过在变分自动编码器(VAE)潜空间中执行扩散建模,从文本描述生成视频。模型架构包括:
- 使用 T5 编码器生成文本嵌入;
- 通过交叉注意力机制将文本嵌入输入 VDiT;
- 在潜空间中采用流扩散参数化技术(Rectified Flow Diffusion)进行生成。
具体而言,研究者采用了一种标准设计,预训练了一个具有 11.5B 参数的 Video DiT 模型。该模型包含 32 层,隐藏维度为 4,096,并在 CogVideoX 的潜空间中操作,并使用了 流扩散参数化技术(Rectified Flow Diffusion)。基础模型在一个大规模图像和视频数据集上训练,该数据集包含了文本注释,分辨率范围从 17×144×256 到 121×576×1024。
摄像机运动的第一性原理分析
(1)分析 1:运动光谱体积(MSVs)分析
通过运动光谱体积(Motion Spectral Volumes, MSVs)分析,研究者发现摄像机引起的运动主要位于低频段。与场景运动相比,摄像机运动更平滑且更少剧烈变化。并且,84% 的低频运动信息在扩散过程的前 10% 阶段已经确定,后续不会再改变。基于这一观察,研究者调整了训练和测试的噪声条件调度,将摄像机运动注入限制在早期噪声阶段进行训练和推理。这一方法大幅减少了后期干扰,同时提升了视频的视觉质量和运动保真度。
,时长00:05
(2)分析 2:线性探测的 VDiT 表征
研究者通过线性探测实验,在文生视频网络的每一层训练一个线性层以预测摄像机参数。实验结果显示:
1. 无条件文生视频模型在中间层对摄像机姿态信息预测最为准确;
2. 网络中间层对摄像机参数具有最佳表征,说明模型在早期阶段隐式地注入了摄像机位置信息,并利用后续层指导其他视觉元素生成。
基于此发现,AC3D 将摄像机条件注入限制在前 8 层,从而减少了对其他视觉特征表征的干扰,显著提升了训练速度和生成质量。

(3)分析 3:数据集偏见的分析
传统的具有相机参数的视频数据集(如 RealEstate10k)几乎只有静态场景。这种静态场景视频导致模型难以区分摄像机运动与场景运动,也使得网络过拟合到静态分布上,从而降低了生成视频中文运动场景的质量。然而,在动态视频中预测摄像机运动依然没有很好的开源解决方案。研究者另辟蹊径,构建了一个包含 20,000 个动态场景但使用静态摄像机拍摄的数据集。
这种混合动态场景静态摄像机与静态场景动态摄像机的数据集,显著改善了模型的学习效果。训练后,模型更能分离摄像机运动和场景运动,从而生成更加真实且动态的视频。
摄像机控制方法
为实现摄像机控制,研究者将 ControlNet 模块与 VDiT 结合,形成了 VDiT-CC(VDiT with Camera Control)。具体方法:
1. 用 Plücker 相机表征,通过全卷积编码器对摄像机轨迹进行编码;
2. 使用轻量化的 128 维 DiT-XS 模块处理摄像机编码,并类似 ControlNet 直接将摄像机特征加入到视频特征中进行融合;
3. 只在 256x256 的分辨率中训练摄像机运动注入,因为研究者发现摄像机运动属于一种低频信息。在低分辨率中训练也可以推理在推理高分辨率时实现精准相机控制。
4. 调整训练和推理时的摄像机条件调度,仅覆盖逆扩散轨迹的前 40%。这种噪声调节平均将 FID 和 FVD 指标提升了 14%,并使摄像机跟踪能力在 MSR-VTT 数据集上提高了 30%(该数据集用于评估模型对多样化、超出微调分布场景的泛化能力)。此外,这种方法还增强了整体场景的运动性,我们在实验中对其进行了定性验证。
5. 仅在前 8 个 DiT 块中注入摄像机信息,而将后续的 24 个 DiT 块保持无条件状态。这种设计能够避免摄像机信息与后续层的其他特征表征产生干扰,同时显著减少训练复杂度,提高模型的生成效率和质量。
其他改进:为了进一步提升模型的性能和摄像机控制能力,研究者引入了以下创新:
1. 一维时间编码器:通过因果卷积,将高分辨率摄像机轨迹数据转换为低分辨率表示。
2. 分离文本与摄像机引导:为文本和摄像机信号独立设计引导机制,分别调整每种输入类型的权重。
3.ControlNet 反馈机制:通过交叉注意力,从视频向摄像机提供反馈,优化摄像机表示。
4. 移除摄像机分支的上下文信息:消除上下文干扰,提高对摄像机轨迹的追踪能力。
通过这些方法,AC3D 在摄像机控制效率和生成质量上取得了显著突破,为高质量的文本生成视频提供了新的技术基准。

模型结果
研究者展示了一系列提示词,不同摄像机轨迹下的可控视频生成(总时长 40 秒),通过这些视频可以直观地观察 AC3D 在摄像机控制上的表现。
,时长00:40
Prompts:
1. 在一个艺术工作室中,一只戴着贝雷帽的猫正在小画布上作画。
2. 在一个未来厨房中,宇航员熟练地用平底锅烹饪。
3. 在一个舒适的厨房里,一只泰迪熊认真地洗碗。
4. 在一个热带海滩上,一只金毛猎犬坐在沙滩上,兴奋地吃着冰淇淋。
5. 在公园的长椅上,一只松鼠用小爪子抓着一个多汁的汉堡,悠闲地吃着。
6. 在一个温馨的咖啡馆里,一只水獭熟练地操作着浓缩咖啡机。
7. 在一个别致的城市厨房里,一只戴着小厨师帽的猫正在揉面团。
8. 在厨房里,一名宇航员正在用平底锅烹饪。
9. 在一个未来感十足的东京天台上,一只戴着耳机的机械考拉在混音。
10. 穿着正式服装的猫坐在棋盘旁,专注于下一步棋局策略。
11. 在一个废墟中,一名孤独的机器人正在寻找可利用的材料。
12. 穿着文艺复兴服饰的小老鼠正优雅地吃着一块奶酪。
总结
AC3D 对视频扩散模型中的摄像机运动进行系统性分析, 从而显著提升控制的精度和效率。通过改进条件调度、针对特定层的摄像机控制以及更精确校准的训练数据,模型在三维摄像机控制视频合成方面达到了最先进的性能,同时保持了高视觉质量和自然的场景动态。这项工作为文本生成视频中更精准和高效的摄像机控制奠定了基础。未来的研究将专注于进一步克服数据局限性,并开发适用于训练分布范围外摄像机轨迹的控制机制。
#快手可灵凭什么频繁刷屏
“可灵(KLING)”,近半年来频繁亮相于国内外各大科技媒体,已然成为科技感与创意的代名词,它代表了快手 AI 团队在视频生成领域的前沿探索。
作为全球首个可公开体验的真实影像级视频生成大模型,可灵于 2024 年 6 月 6 日正式发布并上线。在短短半年多的时间里,可灵已完成了数十次功能与效果的升级迭代,始终稳居全球视频生成领域的第一梯队,持续引领着行业效果的提升。同时,它还陆续推出多项丰富且实用的控制与编辑功能,为全球创意制作人士提供了广阔的创作空间,充分激发并展现了他们的灵感。
与 "可灵 AI 平台" 在视频生成领域的广泛行业影响力不同,可灵团队及其研究工作始终保持着低调与神秘。然而,其背后的技术突破和创新思维却吸引了众多关注者的兴趣。
近日,可灵团队公开了多项研究成果,揭示了他们在视频生成领域的洞察与前沿探索。这不仅是对学术界和开源社区的回馈,也旨在激发行业与社区的创造力,共同推动该领域的技术进步。
此次公开的研究工作涵盖了视频生成模型成功的几个关键因素:数据基建的精炼之 “术” 与大模型训练的规模之 “道”:可灵团队分享了其数据基建核心流程,并推出了视频生成领域最高质量的大规模开源数据集 Koala-36M,为学界和社区模型训练提供坚实基础;同时将语言模型中 Scaling Law 引入视频生成领域,系统性地揭示了模型规模、超参数选择与训练性能之间的关系,为高效训练和性能优化提供了科学指导。
此外,他们还积极与学界合作,联合探索未来技术的演进方向,此次分享了和清华大学近期的合作成果:提出名为 Owl-1 的全新视频生成范式。该方法使用通用世界模型(Omni World model)建模视频生成过程,通过状态 - 观测 - 动作的闭环推理演化实现时序一致的长视频生成,展现了视频生成技术更远大的前景。
一、数据基建的精炼之 “术”
可灵背后的数据链路
在当今的大模型时代,数据的重要性不言而喻。高质量的大规模数据集是训练高性能模型的基础。然而,当前视频生成领域缺乏高质量的大规模预训练数据,这成为了制约模型发展的瓶颈。
为了解决这个问题,可灵团队开源了 Koala-36M,是目前开源的质量最高的大规模视频生成数据集,其背后的数据处理流程也是可灵大模型的重要支撑。与 SOTA 数据集 Panda-70M [1] 相比,Koala-36M 分别在视频切片、文本标注、数据筛选和质量感知上做出改进,大幅提高了文本视频的一致性。
如下所示,在相同的生成模型和训练步数下,相较于 Panda70M,在 Koala-36M 上预训练的模型具备更高的生成质量和更强的收敛性,充分证明数据集和处理流程的有效性。
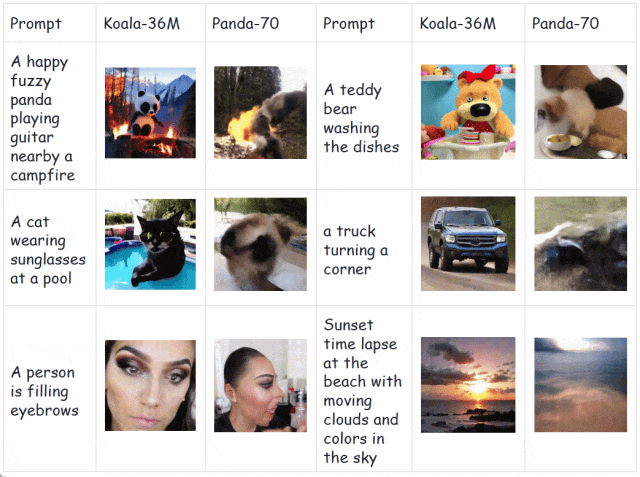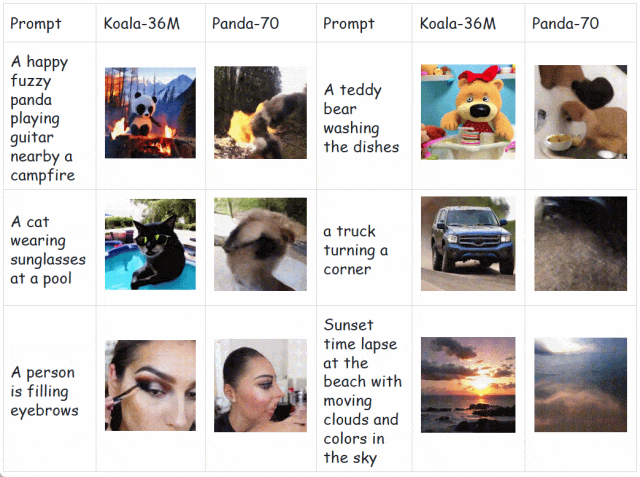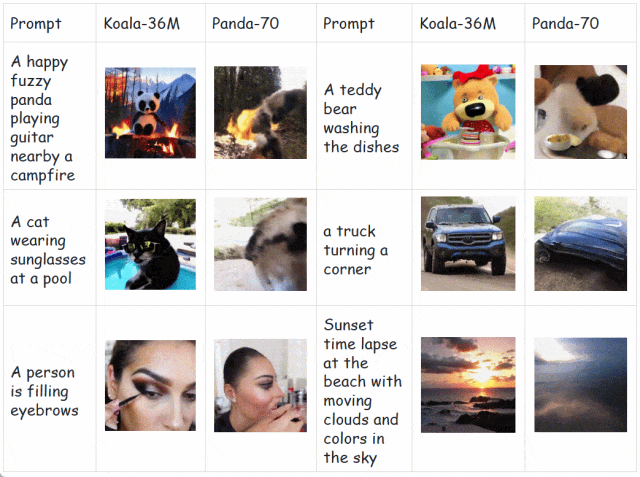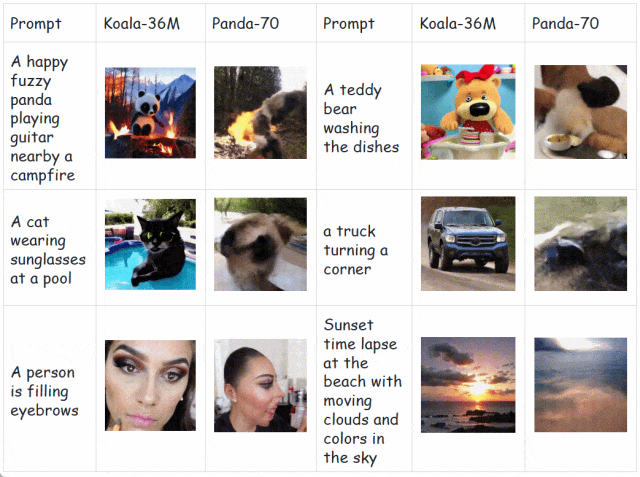
快手开源的 Koala-36M 对应的论文题目为:A Large-scale Video Dataset Improving Consistency between Fine-grained Conditions and Video Content.
- 代码地址:https://github.com/KwaiVGI/Koala-36M
- 论文链接:https://arxiv.org/abs/2410.08260
- 项目主页:https://koala36m.github.io/
- 数据集链接:https://huggingface.co/datasets/Koala-36M/Koala-36M-v1
Koala-36M 包含 3600 万个视频片段,平均时长为 13.75 秒,分辨率为 720p,片段的文字 caption 平均长度为 202 个词,相较已有数据集,在质量上有大幅提升。

1、方法介绍
通过以下效果图的展示,可以发现 Panda-70M 存在视频切片不充分、文本描述简短、部分低质量视频保留的问题,Koala-36M 对上述方面进行更细致精准的改进。

Koala-36M 出发点是为视频生成模型提供精确且细致的条件控制,通过更加精准的视频切片、更加细致的文本描述、更加丰富的条件引入,使得模型感知与视频内容更加一致。
目前视频生成数据集处理方式有一些关键的问题有待解决:
- 文本与视频语义对齐:因为视频视觉信号更加细致,所以相应的文本描述需要丰富详细。此外,由于原始视频数据常包含复杂的转场,增加了文本语义对齐的难度。
- 低质量数据的筛选:低质量(如画质差或过多特效)的视频会妨碍模型训练,但对数据的质量评估和筛选过滤依然不够出色。目前主流方法多依赖于其他人工选择的质量指标和启发式阈值筛选,并非针对视频生成任务而设计,因此存在低质量数据漏检、高质量数据误删的情况。
- 数据质量的异质性:即使经过数据筛选,不同视频在不同维度仍然有质量上的偏差。然而模型无法对这些偏差进行感知,仅仅简单地将这些异质数据喂给模型可能导致模型学习的不确定性。
更精准快速的视频切割
视频切片是构建视频文本数据集的关键一步,无转场的视频能够更加契合文本描述,利于模型学习,从而使得生成结果更加时序一致。目前视频的切分算法一般使用 PySceneDetect [2],对于渐变转场识别表现不佳。
Koala-36M 提出新的切片算法 Color-Struct SVM (CSS),通过计算帧之间的结构距离和色彩距离,输入给 SVM 学习识别转场能力。对于渐变转场,Koala-36M 假设视频在时间变化上相对稳定,估计过去帧变化的高斯分布,根据当前帧的变化是否超出 3σ 置信区间判断显著变换。这种方法在不增加计算负担的情况下,增强了对渐变和快速运动场景的区分能力。Koala-36M 进一步在 10000 个标注转场的视频片段进行检测,证明算法在精度和运行效率上的有效性。


更细粒度的 caption 算法
更加详细的视频描述会带来更好的视频文本一致性。为了获得更加详细的文本描述,Koala-36M 使用了一个结构化的文本标注体系,一段文本描述会被拆解为以下 6 个部分:
- 主体描述
- 主体运动
- 主体所处环境
- 视觉语言:构图、风格、光线等
- 镜头语言:运镜、视角、焦距等
- 整体描述
和现有的工作相似,Koala-36M 首先通过 GPT-4V [3] 生成初步文本标注,微调基于 LLaVA [4] 的文本标注网络,为其余的数据打标。训练过程中采用了图像视频混合训练的方式,以缓解视频数据多样性不足的问题。最终得到 Koala-36M 的文本描述长度分布如下。

全新的数据筛选流程
视频原始数据的质量参差不齐,需要筛掉低质量的数据,保留高质量的数据。如下图蓝框所示,传统的数据筛选方式通过多个子度量指标来衡量视频的质量,并手动设置阈值对视频进行筛选。由于视频质量是所有子度量指标的联合分布,而子度量指标之间并非完全正交,所以设定的阈值之间应该存在隐含约束。然而,现有方法忽略了子度量指标的联合分布,导致阈值设置不准确。同时,由于需要设置多个阈值,不准确阈值的累积效应使得筛选过程中出现较大偏差,最终导致低质量数据的漏检和高质量数据的误删。

为解决这一问题,Koala-36M 提出 Training Suitability Assessment Network(TSA),用于建模多个子度量指标的联合分布。该网络将视频和子度量指标作为输入,并输出单一值 “Video Training Suitability Score(VTSS)”,作为筛选数据的唯一指标,直接反映视频是否适合用于训练目的。具体来看,Koala-36M 构建了新的视频质量评价体系,考虑动态质量、静态质量和视频自然度等三个维度,邀请用户评测给出唯一分数并归一化,反映视频是否适合作为视频生成模型的训练数据。

多模态输入视频评价网络 (TSA) 用于拟合用户打分。如上图所示,网络分为三个分支,动态分支以 3D Swin Transformer 为骨干,静态分支以 ConvNext 网络为骨干,传统数据筛选策略中的各种数据标签也被保留,作为额外信息通过新的分支传递给网络模型,不同分支的特征通过权重交叉门块(WCGB)融合。如下图所示,Koala-36M 的筛选流程能够大幅减少低质量数据漏检、高质量数据误删的情况。


加强模型对异质数据感知
在现有的数据流程中,数据的标签只是简单地用于数据筛选。然而,筛选后的数据质量有所差异,导致模型难以区分高质量和低质量的数据。为了解决这个问题,Koala-36M 提出一种更精细的模型感知方法,在训练过程中将不同视频的质量标签注入生成模型,从而提高条件和视频内容之间的一致性。

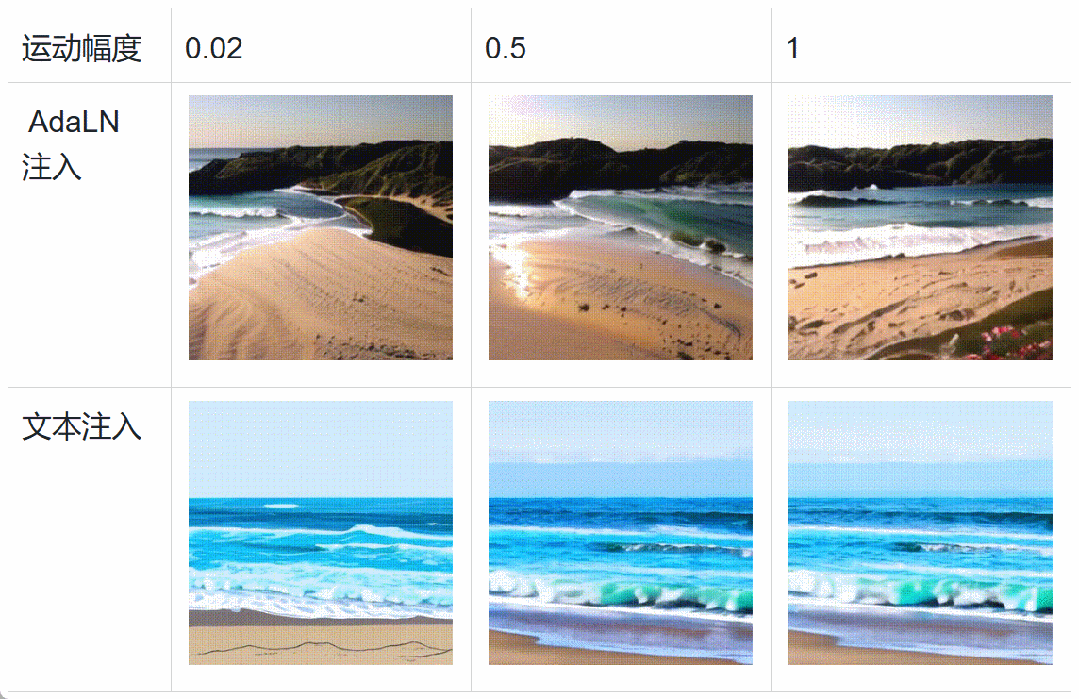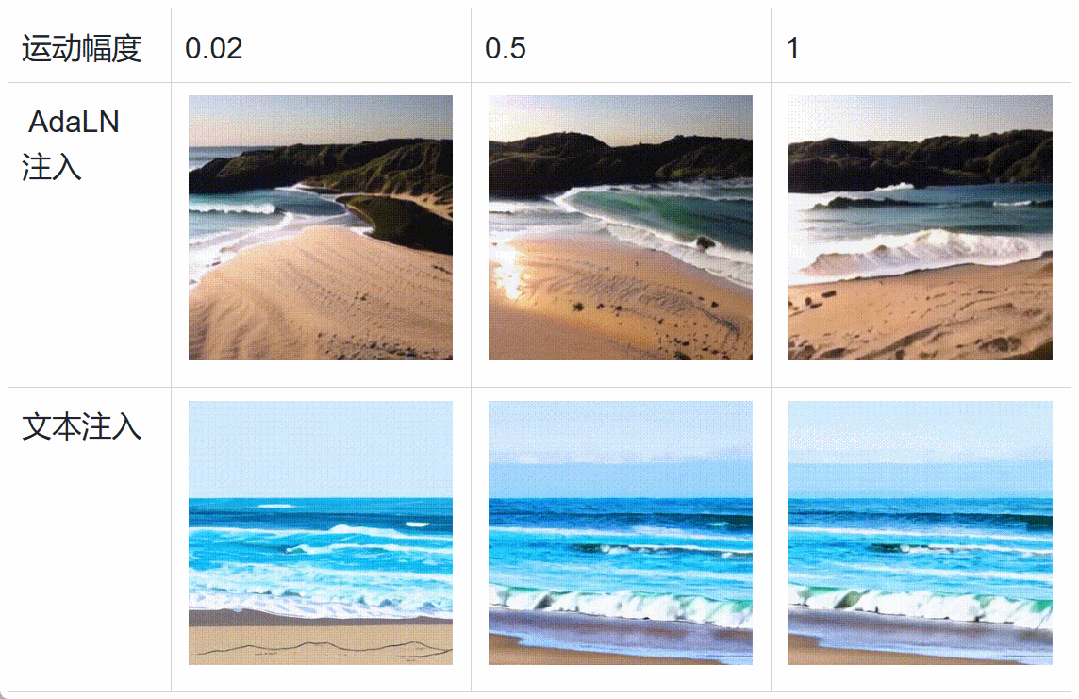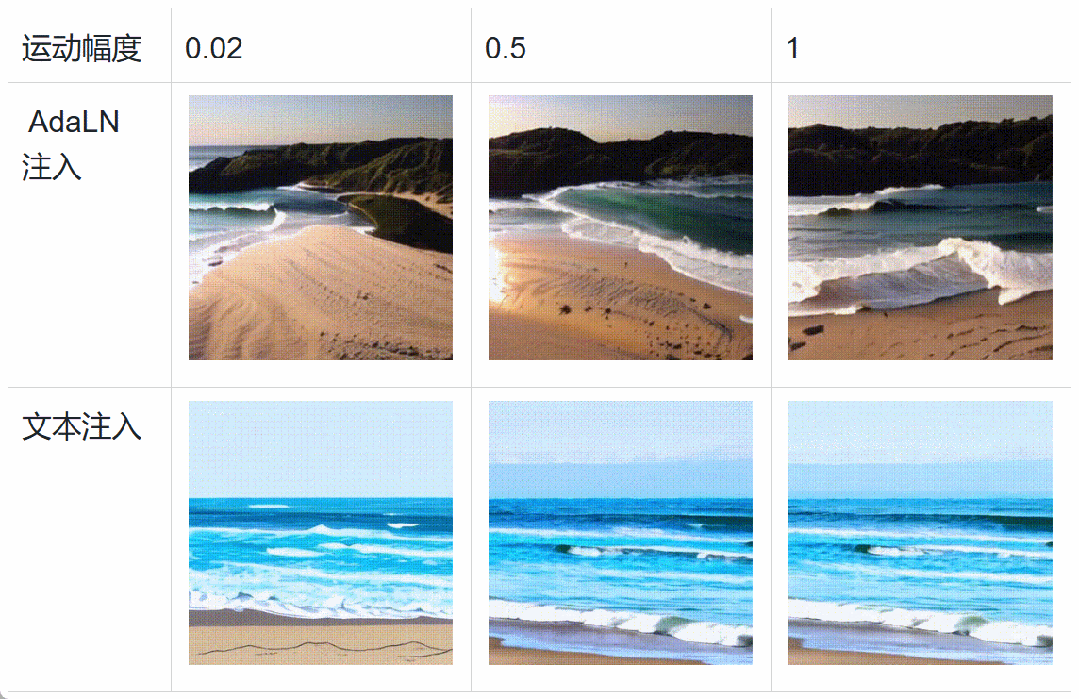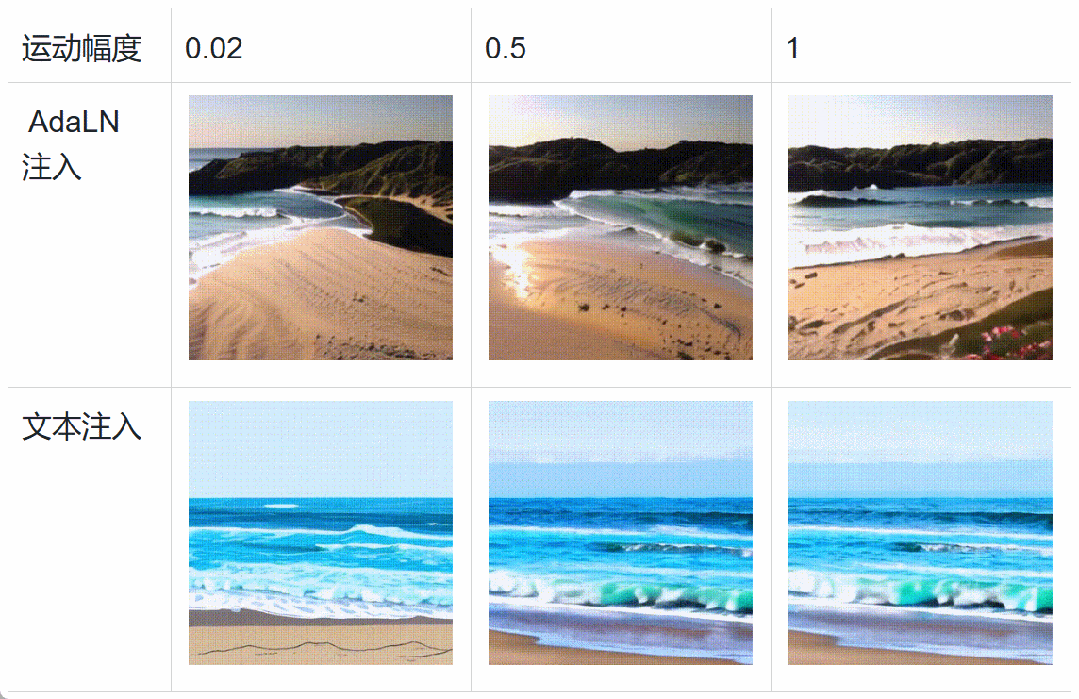
具体而言,在扩散模型训练过程中,将运动分数、美学分数和清晰度分数等数据通过自适应层归一化(AdaLN)加入 Transformer 中。这种条件加入方式不会增加扩散模型的计算负荷,反而会增强模型对异质数据的感知,加速模型的收敛。在推理阶段,可以设置不同的特征分数,细粒度地控制视频生成。此外,下图中表明基于 AdaLN 的注入方法相较于文本编码器的注入方法 [5] 具备更精细的运动幅度控制,和更强的风格解耦能力。
2、实验对比
Koala-36M 在不同数据集上预训练相同的视频生成模型,控制训练步数相同,衡量视频生成的质量,进一步对数据处理流程和训练策略的有效性进行验证。实验分为以下六组:
- Panda-70M:baseline
- Koala-w/o TSA:视频分割和文本标注后的未经数据筛选的所有 48M 数据
- Koala-37M-manual:从 48M 使用多个阈值数据手动筛选的数据
- Koala-36M:从 48M 数据使用 VTSS 筛选的数据集
- Koala-w/o TSA (condition):带有 metrics condition 注入的未经筛选的 48M 数据
- Koala-36M (condition):带有 metrics condition 注入的 Koala-36M 数据

分别比较 Koala-w/o TSA 和 Koala-36M、Koala-w/o TSA (condition) 和 Koala-36M-condition 的训练结果,后者的结果均优于前者,表明筛选低质量数据能够防止模型从低质量数据中学习到有偏差的分布。此外,Koala-37M-manual 和 Koala-36M 的训练结果,表明基于单个 VTSS 的筛选方法相较于手动设置阈值能获得更好的筛选效果。对比 Koala-36M 和 Koala-36M (condition) 的训练结果,当注入 metrics condition 时,生成模型的视频质量有显著提高,表明使用指标指导模型训练,有助于模型隐式感知不同数据的重要程度。
3、Koala-36M 总结
Koala-36M 是一个大规模高质量视频文本数据集,具有精确的视频切片、详细的文本描述和更高质量的视频内容。该数据集是目前唯一一个同时拥有大量视频(超过 1000 万)和高质量细粒度文字说明(caption 平均长度超过 200 字)的视频数据集,大大提高了大规模视频数据集的质量。此外,为了进一步提高细粒度条件与视频内容的一致性,Koala-36M 提出了一套完善的数据处理流程,包括更好的视频切片方法、结构化的文本标注系统、有效的数据筛选方法和异质数据感知。
二、大模型训练的规模之 “道”
视频生成领域的 Scaling Law
视频生成技术正迅速成为人工智能领域的核心热点,从娱乐内容创作到广告制作、虚拟现实和在线教育等场景,展现出巨大的应用潜力。然而,与静态图像生成不同,视频生成任务需要同时建模视觉结构与时间维度上的动态变化,还需处理复杂的高维解空间,以准确模拟现实世界的动态场景。这种复杂性不仅显著增加了数据和算力的需求,还使试验试错成本高昂。因此,如何在给定的数据和计算预算内实现最优性能,成为视频生成领域亟待解决的关键挑战。
当前代表性的视频生成模型 Movie Gen 的参数规模已达到 300 亿,远超早期的 Video DiT(约 7 亿参数)。在此背景下,Scaling Law 的重要性日益凸显。尽管在语言模型中已经使用 Scaling Law 来预测性能,但在视觉生成模型中的存在性和准确推导仍然未得到充分探索。
针对这一问题,在论文《Towards Precise Scaling Laws for Video Diffusion Transformers》中,快手研究团队提出了一种面向视觉生成模型(Video DiT)的更精确的 Scaling Law 建模方式。
该文首次将批次大小和学习率进行精确建模,为任意模型大小和计算预算下的最优超参数选择提供指导,并对最优超参配置下的验证损失进行了精准预测。此外,该文进一步建立了最优模型大小和计算预算之间的精确关系。实验表明,与传统 Scaling Law 方法相比,在 1e10 TFlops 的计算预算下,该工作提出的推导方法可减少 40.1% 的推理成本,同时保持了相当的性能。这一成果为视频生成领域的高效优化提供了新的方向,并为行业开发大规模视频生成模型带来了重要启示。
1、背景
近年来,大语言模型(LLM)的研究揭示了模型性能、模型规模与计算预算之间的幂律关系,这一规律被称为 Scaling Law。通过对小规模模型的实验,研究者能够有效预测大规模模型的性能表现,从而在资源受限的条件下实现高效的模型优化。尽管 Scaling Law 已在语言模型领域取得显著成效,Image DiT 的 Scaling Law 也有初步研究,但视频生成的独特复杂性使得其在这一领域的研究仍是空白,成为限制更大规模视频生成模型开发的重要阻碍。
技术难点:Video DiT 模型对超参数高度敏感
随着 Video Diffusion Transformers(Video DiT) 的发展,其在生成视频质量和多样性方面取得了显著进展。本文尝试将语言模型领域的 Scaling Law 方法扩展应用于 Video DiT。然而,研究发现,Video DiT 模型的性能对批量大小、训练步长等超参数高度敏感,经验性的参数选择往往引入较大的不确定性,从而显著影响模型验证损失(如图 1 所示)。因此,构建适用于 Video DiT 的精确 Scaling Law 并优化超参数配置显得尤为重要。

经典 Scaling Law 研究中的局限性
在语言模型的 Scaling Law 研究中,最优超参数的选择往往被忽略或存在一定争议。早期研究通常依赖启发式方法,缺乏系统性的理论依据来指导超参数选择。现有的 Scaling Law 研究在模型规模与超参数关系的细粒度探索方面仍有不足,而这对优化计算资源和提高拟合精度至关重要。现有的 Scaling Law 的问题包括:
- OpenAI 的 Scaling Law。OpenAI 的研究认为,较小的批量大小计算效率更高,但需要更多更新步数才能收敛。然而, 本文实验结果表明,在相同计算预算下,采用较小的批量大小并增加更新步数,无法达到最低的验证损失。这说明在视频生成任务中,较小的批量大小未必是提高计算效率的最佳选择。
- Chinchilla 的 Scaling Law。Chinchilla 的研究将验证损失与模型参数量 N 及训练数据量 D 建立了联系,但验证损失的拟合结果与 IsoFLOPs 曲线在最优参数量预测上存在一定偏差。文章认为偏差可能源于固定的次优超参数配置,导致模型规模预测结果的不够精确。
- DeepSeek 的 Scaling Law。DeepSeek 的研究表明,在特定计算预算下,可以找到最小化验证损失的最佳批量大小与学习率组合。然而,该方法仅针对最优模型参数量选择对应的最优超参数,未能全面考虑超参数与模型规模及训练数据量的交互关系,这限制了方法在更广泛的场景中的适用性。

通过对这些经典研究的分析与反思,作者们发现优化超参数配置对于构建适用于 Video DiT 的 Scaling Law 至关重要。因此,本文将深入探讨超参数在模型性能优化中的作用,并在给定模型规模和训练数据量时预测超参数,从而为大规模模型的训练提供更加精确的理论依据与实践指导。
最优超参数预测
研究者通过理论推导与实验验证,构建了最优学习率与批次大小的预测公式,并通过外推方法实现对大规模模型的精确预测。
- 学习率选择的权衡。学习率的选择需要在每步收益与有效更新步数(验证损失下降的步数)之间取得平衡,以实现整体优化收益的最大化。基于理论推导,本文提出了最优学习率公式,其中参数取值如表所示:
-


实验结果表明,学习率与模型规模和训练数据量之间存在明确的非线性关系,基于公式的拟合曲线能够准确预测不同规模模型的最优学习率。
- 训练批次大小的权衡。训练批次大小的选择需权衡每步梯度噪声与总更新步数之间的平衡。为此,本文从理论角度提出了最优批次大小公式,其参数值如表所示:
-


实验结果显示,批次大小与模型规模和训练数据量同样存在显著的依赖关系。拟合曲线的准确性在不同模型规模上表现一致。


- 外推验证。为了验证公式的适用性,该工作将模型参数量扩展至 1B,并在 4B 和 10B 的训练数据集上分别进行最优超参数预测。实验结果显示,基于公式预测的超参数能够有效降低验证损失,其精度接近真实值(如图 4 所示)。

2、更精确的 Scaling Law:探索 video DiT 模型的性能边界
研究者基于上述最优超参数的预测提出了一种针对 Video DiT 的更精确的 Scaling Law,从模型规模、训练数据量与计算预算的平衡角度出发,不仅可以预测给定计算预算下的最佳模型大小,还可以为不同大小的模型提供更精确的性能预测。
更高效的经验最优模型参数预测。在 [3e17, 6e17, 1e18, 3e18, 6e18] 等不同计算预算下,研究分别比较了使用最优和次优超参数配置时,经验最优模型参数(IsoFLOPs 曲线)的预测偏差(图 6)。研究发现:
在相同计算预算下(10^10 TFLOPs),使用最优超参数时的经验最优模型参数量相比非最优超参数可减少约 39.9% 的参数量(图 6c),推理成本减少了 40.1%。这在实际应用部署中所带来的收益是巨大的。
基于此,本文给出了经验最优模型参数量的经验预测公式:


更高精度的验证损失拟合公式。研究进一步分析了模型验证损失随着训练 token 数 T 与模型规模 N 的变化, 论文根据假设:
- 当
-

- ,实现的最小损失取决于训练数据熵和噪声。同样,当
-

- 时,它取决于模型大小。
- 在计算预算趋于无穷时,损失趋近于训练数据熵
-

- 。
基于上述假设,提出如下验证损失公式:


拟合结果
- 研究者在最优超参数的前提下得到拟合结果如表所示。在 1.07B 模型 + 10B 训练 tokens 与 0.72B 模型 + 140B 训练 tokens 的场景中进行外推验证,验证损失误差分别为 0.03% 和 0.15%(图 5),证明了该公式的高拟合精度。
- 此外,研究者对 L (N,T) 施加算力约束,得到预测最优模型参数量(Predicted Optimal Model Size)与经验最优模型参数量(Empirical Optimal Model Size):(图 7)
- 在最优超参数的设定下,二者的拟合结果高度一致(指数项偏差为 3.57%),进一步证明了 L (N,T) 拟合的高精确性。
- 使用固定的非最优超参数配置,二者的拟合结果存在明显偏差(指数项偏差了 30.26%),这与 Chinchilla 的 Scaling Law 方法 3 所观察到的结果一致。本文认为造成这一显著偏差的原因在于拟合存在图 1 中非最优超参配置的灰色实验点降低了 L (N,T) 的拟合度。


3、总结
本文深入探讨了 Video DiT 的 Scaling Law,提出了一种新的框架来优化超参数选择、模型规模和训练性能,为高效训练提供指导,具体来说:
- Scaling Law for Hyperparameters. 本文通过理论分析与实验验证,提出了一种新的缩放规律,用于确定 Video DiT 的最优超参数。最优超参数主要依赖于模型规模 N 和训练数据量 D,并给出了准确的拟合公式。
- Scaling Law for Optimal Model Size. 基于最优超参数,该方法能够更准确地预测经验最优模型规模。与 Movie Gen 使用相同计算资源时,此方法的方法使模型规模减少了 39.9%,同时保持相似的性能。
- Scaling Law for Performance. 在最优超参数配置下,本文推导出一个通用公式,能够精确预测不同模型规模与计算预算下的验证损失。研究表明,在固定计算预算下,当模型规模接近最优时,验证损失趋于稳定,从而在性能相当(可预测)时可显著降低推理成本。此外,本文研究结果提供了模型规模与计算预算之间关系的准确外推,相比之下,使用固定次优超参数会导致预测误差显著增加。
三、视频生成未来之势
通用世界模型
目前,视觉生成模型已经在图像生成、视频生成等领域取得了显著进展。然而,这些模型仍然面临一些挑战,尤其是在生成长视频时,如何保持时序一致性和逻辑合理性是一个难题。传统的生成模型往往依赖于大量的数据和复杂的网络结构,但仍然难以完全解决这些问题。为了解决上述挑战,清华大学与快手科技联合提出了通用世界模型(Omni World Model)。这种模型通过状态 - 观测 - 动作的闭环推理演化,实现了时序一致的长视频生成。下面来详细了解一下 Owl-1 的核心技术和优势。
- 状态 - 观测 - 动作的闭环系统 🔄
- 状态变量:捕捉世界的当前状态和历史信息,可以被视频生成模型解码成对应的视频。
- 观测变量:对当前世界状态的直接观测,即看到的视频帧。
- 动作变量:描述了世界状态随时间的变化规律,以文本形式呈现,驱动着世界的演变。
这三个组成部分共同构成了一个闭环的演化系统,相互作用、相互影响,共同推动着世界的不断演变和视频的生成。
- 提升时序一致性和逻辑合理性 🕒
通用世界模型能够直接捕捉并模拟三维世界的时空演变规律,从而提升生成视频的时序一致性和逻辑合理性。这意味着生成的视频不仅看起来自然,而且内容更加连贯,避免了单一或重复的内容。
- 丰富的内容多样性 🎨
通过预测和利用演化动作变量,Owl-1 能够丰富生成视频的内容多样性。这使得生成的视频更加生动有趣,能够更好地反映真实世界的变化规律。
论文标题:Owl-1: Omni World Model for Consistent Long Video Generation
项目主页:https://github.com/huang-yh/Owl
论文链接:https://arxiv.org/abs/2412.09600

1、方法介绍
Owl-1 的目标是构建一个时序一致的长视频生成模型,其核心在于采用通用世界模型建模视频生成任务。为什么要使用通用世界模型呢?因为视频数据本质上是对周围世界演化过程的一种观测,是四维时空向三维观测的一种投影。而通用世界模型能够直接捕捉并模拟三维世界的时空演变规律,因此从世界模型的角度建模视频生成任务是一种更加有效和本质的方法。一方面,四维时空的一致性能够提高生成视频的时序一致性;此外,对于世界演化过程的显式建模也能提高生成视频内容的多样性和逻辑性,避免单一或者重复的内容。

通用世界模型建模
通用世界模型有三个核心组成部分,包括隐空间状态变量、显式观测变量和演化动作变量。这三个部分各自扮演着不同的角色:隐空间状态变量负责捕捉世界的当前状态和历史信息,它可以被视频生成模型解码成对应的视频。显式观测变量则是对当前世界状态的直接观测,即看到的视频帧。而演化动作变量则描述了世界状态随时间的变化规律,它驱动着世界的演变,并以文本的形式呈现。
隐空间状态变量是 Owl-1 的核心,它不仅仅关注视频本身的像素信息,而是深入到视频背后的世界,通过捕捉和表示这个世界的动态变化,来更准确地模拟世界的演变,从而生成更加连贯和一致的长视频。
演化动作变量是驱动世界演变的关键因素。它以文本的形式存在,描述了世界在不同时刻之间的动态变化过程。通过预测和利用这些演化动作变量,Owl-1 能够丰富生成视频的内容多样性,并确保视频的一致性和连贯性。
Owl-1 的这三个组成部分共同构成了一个闭环的演化系统。这三个部分相互作用、相互影响,共同推动着世界的不断演变和视频的生成。

模型结构
Owl-1 充分利用了预训练的多模态大模型(LMM)和视频扩散模型(VDM)。LMM 是通用世界模型的核心组成部分,它直接建模了状态 - 观测 - 动作三元组的演化过程。而视频扩散模型则负责将隐空间状态变量解码成短视频片段,即显式观测变量,然后输入 LMM 进行后续推理。通过这两个模型的协同工作,Owl-1 实现了闭环通用世界模型的建模。
定制化多阶段训练流程
Owl-1 采用了多阶段的训练过程。首先是对齐预训练阶段,通过大规模的短视频数据来训练多模态大模型输出的隐空间状态变量与视频扩散模型对齐,这一阶段仅训练多模态大模型,能够为后续的训练过程提供一个良好的初始化。接着是生成式预训练阶段,这一阶段主要强化视频扩散模型根据隐空间状态变量生成显式视频观测的能力,因此本文联合训练多模态大模型和视频扩散模型。最后是世界模型训练阶段,因为尚没有能体现世界模型概念的视频数据集,本文采用了 Vript 和 ActivityNet 两个密集视频字幕数据集,将隐空间状态变量、显式观测变量和演化动作变量整合在一起,形成一个完整的通用世界模型。
2、效果展示
此处展示了 Owl-1 生成不同时长视频的效果,包括 2 秒,8 秒和 24 秒的视频长度,其中 2 秒的生成视频使用了 VBench 的图文提示词,8 秒和 24 秒的视频使用了 WebVid 或者 Vript 数据集的图文提示词。
,时长00:10
基于给定的初始帧和文字描述,Owl-1 能生成具有较大的姿态和场景变化的视频,同时生成的视频能够反映真实世界中物体和场景的变化规律。这说明 Owl-1 能够很好地由隐空间状态变量解码得到显式的视频观测。
,时长00:24
对于同场景多段短视频生成(~8 秒),Owl-1 能够实现视频之间的无缝衔接,且生成的视频具有较高的一致性。这验证了隐空间状态变量保持视频内容的一致性的能力。
,时长00:24
对于跨场景多段长视频生成(~24 秒),Owl-1 在场景转换、运动捕捉和细节呈现方面表现出优越的性能,其生成的视频不仅连贯流畅,而且细节丰富,在视频内容发展方面展现出一定的逻辑性。这验证了演化动作变量对于视频内容发展的重要推动作用,初步体现出基于世界模型的视频生成范式的优势。
3、定量结果
本文在 VBench-I2V 和 VBench-Long 两个基准上分别测试了 Owl-1 生成短视频和长视频的能力。

上表展示了 Owl-1 在 VBench-I2V 上的实验结果,该结果表明 Owl-1 在大部分指标上与其他模型的能力相当,但在动态程度和美学分数上仍旧有所欠缺,这可能和用于训练的视频数据的动态程度和美学分数相关。

上表展示了 Owl-1 在 VBench-Long 上的实验结果。Owl-1 与开源的视频生成方法取得了相当的性能,其中在一致性相关的指标上取得了最佳的性能。这说明了 Owl-1 在保持长视频的时序一致性方面超过了现有的方法。
四、总结
快手 “可灵大模型” 团队始终专注于视频生成技术的前沿探索与持续创新。通过对模型架构的优化、数据质量的提升以及算法范式的突破,团队致力于推动视频生成技术的持续进步。展望未来,随着这些技术的不断完善与成熟,视频生成将变得更加高效与高质量,为用户带来更丰富、更多样化的创意表达与使用体验。
#用LLM做文本分类,微调选base还是chat
本文探讨了使用大型语言模型(LLM)进行文本分类时,选择基础模型(base)还是聊天模型(chat)进行微调的问题。文章通过实验结果和结论,分析了短文本和长文本场景下不同模型的表现,并提供了分类场景的提升方案和注意点。
作者:LeonYi 链接:https://www.zhihu.com/question/632473480/answer/75664255663
使用Qwen2ForSequenceClassification实现文本分类任务。
一、实验结果和结论
这几个月,在大模型分类场景做了很多实验,攒了一点小小经验。
1、短文本
1)query情感分类,一般不如BERT
ps:结论和,https://segmentfault.com/a/1190000044485544#item-13,基本一致
2、长文本
1)通话ASR转译长文本,BERT截断512不如LLM
- LLM没有截断(如果都阶段512,可能效果差不多)
- 没有对比,BERT进行文本滑动窗口的版本
2)Base v.s. Instruct
- 数据量小时,Base微调不如Instruct(Instruct模型有对齐税,但是微调数据量小时,效果还是比Base没见过指令微调样本的好)
3)SFT v.s. LoRA
- 数据量小时(总样本10K以下,每个标签需要视情况而定),SFT微调不如LoRA(SFT调参成本也更大)
3、分类场景的提升方案
1)生成式微调独有
混合同领域相似数据类型不同业务数据,可以提升若干点
- 数据分布不能差异太大,特别是文本长度,否则混入这种数据反而会让效果下滑(一个平均长度1.2K,一个平均长度5k)
- 混入比例(接近2:1,不同场景需自行尝试)
- 混入顺序(我使用的是随机采样,没验证是否分开先后训练顺序是否有影响)
优化提示词(提示词中,增加各类别标签的精要描述;短文本可尝试few-shot)
2)分类头微调 + 生成式微调
- 数据量大时(10K以上,平均每个标签样本充足),尝试微调Base,而不是微调Instruct
- 数据增强:尝试无标注数据上跑的伪标签样本(提示词抽的标签 + 微调后的模型抽的标签)
- 数据量大时,尝试SFT
- LoRA微调时,加入LLM的embedding层(未验证过)
- 尝试蒸馏更大模型到小模型(痛点:大模型难调参,训练成本更高,部署上线还是得小模型)
- 尝试LoRA的变体
- 尝试调参(试过optuna自动搜索,效果也不太好;一般就调lr, epoch, rank)
3)重量级
Base模型,领域数据增量预训练后,再进行指令微调
- 方案待验证 (若验证成功,其好处是训出来的基座在各个领域任务上的微调都能提点)
- 这边尝试了在Qwen2-7B-Instruct的领域数据指令微调后的模型,微调效果反而比直接微调Qwen2-7B-Instruct效果差些。由于不清楚该模型训练步骤细节,所以原因尚不明确)
第一优先级,还是搞数据。其次,才是尝试各种方案的加加减减。
4、注意点
- 学习率:训练的参数量越大,学习率适当要调小
- 标签噪声:样本标注错误,需要在错误分析时进行剔除和校正
- 分类业务规则:复杂场景,需要提前确定好完备的标注规则,避免返工(那些模型可以做,那么模型不能做)
待改进点:
- 文本动态Padding
- 分类头多标签版本效果未验证成功
二、文本分类-从BERT到LLM
Qwen2ForSequenceClassification和LlamaForSequenceClassification,以及BERTForSequenceClassification,都可以用来完成文本分类任务。
都可以通过HuggingFace transformers的AutoModelForSequenceClassification库,自动加载相应的模型类,进行序列分类任务。
Qwen2ForSequenceClassification和BERTForSequenceClassification,逻辑上是一致的。都是在模型的输出层,加上一个Linear层,用来完成分类任务。
之前在,BERT上做的所有改动,都可以迁移到LLM上。譬如,BERT-CRF、BERT-SUM。
2.1 BERTForSequenceClassification
BertForSequenceClassification是一个已经实现好的用来进行文本分类的类,继承自BertPreTrainedModel,一般用来进行文本分类任务。
通过num_labels传递分类的类别数,从构造函数可以看出这个类大致由3部分组成,1个是BertModel,1个是Dropout,1个是用于分类的线性分类器Linear。
class BertForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super(BertForSequenceClassification, self).__init__(config)
self.num_labels = config.num_labels
python
self.bert = BertModel(config)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, self.config.num_labels)
self.init_weights()Bert用于提取文本特征进行Embedding,Dropout防止过拟合,Linear是一个弱分类器,进行分类,如果需要用更复杂的网络结构进行分类可以参考它进行改写。
forward()函数里面已经定义了损失函数,训练时可以不用自己额外实现,返回值包括4个内容
def forward(...):
...
if labels is not None:
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
outputs = (loss,) + outputs
return outputs # (loss), logits, (hidden_states), (attentions)2.2 Qwen2ForSequenceClassification
接下来。看看Qwen2ForSequenceClassification。
Qwen2ForSequenceClassification(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 1024, padding_idx=151643)
(layers): ModuleList(
(0-23): 24 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(o_proj): Linear(in_features=1024, out_features=1024, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=1024, out_features=2816, bias=False)
(up_proj): Linear(in_features=1024, out_features=2816, bias=False)
(down_proj): Linear(in_features=2816, out_features=1024, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm()
(post_attention_layernorm): Qwen2RMSNorm()
)
)
(norm): Qwen2RMSNorm()
)
(score): Linear(in_features=1024, out_features=3, bias=False)
)Qwen2官方代码实现,内置三种模式:
single_label_classification 单标签分类
- 损失为CrossEntropyLoss
- 取单标签对应logit,算负对数似然
multi_label_classification 多标签分类
- 损失为BCEWithLogitsLoss
- 标签为muilti-hot, 预测logits计算sigmoid,实际取对应维度标签Logit,损失求和
regression 回归
- 损失为MSELoss
- 默认为单维度回归(回归可以作为奖励模型,预测打分)
这3种模式的输入标签不同。
class Qwen2ForSequenceClassification(Qwen2PreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.model = Qwen2Model(config)
self.score = nn.Linear(config.hidden_size, self.num_labels, bias=False)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.model.embed_tokens
def set_input_embeddings(self, value):
self.model.embed_tokens = value
@add_start_docstrings_to_model_forward(QWEN2_INPUTS_DOCSTRING)
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, SequenceClassifierOutputWithPast]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
transformer_outputs = self.model(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = transformer_outputs[0]
logits = self.score(hidden_states)
if input_ids is not None:
batch_size = input_ids.shape[0]
else:
batch_size = inputs_embeds.shape[0]
if self.config.pad_token_id is None and batch_size != 1:
raise ValueError("Cannot handle batch sizes > 1 if no padding token is defined.")
if self.config.pad_token_id is None:
sequence_lengths = -1
else:
if input_ids is not None:
# if no pad token found, use modulo instead of reverse indexing for ONNX compatibility
sequence_lengths = torch.eq(input_ids, self.config.pad_token_id).int().argmax(-1) - 1
sequence_lengths = sequence_lengths % input_ids.shape[-1]
sequence_lengths = sequence_lengths.to(logits.device)
else:
sequence_lengths = -1
pooled_logits = logits[torch.arange(batch_size, device=logits.device), sequence_lengths]
loss = None
if labels is not None:
labels = labels.to(logits.device)
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(pooled_logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(pooled_logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(pooled_logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(pooled_logits, labels)
if not return_dict:
output = (pooled_logits,) + transformer_outputs[1:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutputWithPast(
loss=loss,
logits=pooled_logits,
past_key_values=transformer_outputs.past_key_values,
hidden_states=transformer_outputs.hidden_states,
attentions=transformer_outputs.attentions,
)三、LoRA微调 Qwen2ForSequenceClassification
在LoRA微调后,将合并LoRA权重,并存储模型。因为,目前PEFT代码没有,把分类头Linear层的参数存储下来。只靠LoRA权重无法,复现训练的Qwen2ForSequenceClassification模型。
有需要可以小改下代码
这边在modelscope提供的环境,完成了代码的测试。

from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name_or_path = "qwen/Qwen2.5-3B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name_or_path,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
prompt = "不想学习怎么办?有兴趣,但是拖延症犯了"
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs, max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```shell
Downloading [config.json]: 100%|██████████| 661/661 [00:00<00:00, 998B/s]
Downloading [configuration.json]: 100%|██████████| 2.00/2.00 [00:00<00:00, 2.30B/s]
Downloading [generation_config.json]: 100%|██████████| 242/242 [00:00<00:00, 557B/s]
Downloading [LICENSE]: 100%|██████████| 7.21k/7.21k [00:00<00:00, 11.7kB/s]
Downloading [merges.txt]: 100%|██████████| 1.59M/1.59M [00:00<00:00, 3.01MB/s]
Downloading [model-00001-of-00002.safetensors]: 100%|██████████| 3.70G/3.70G [00:10<00:00, 373MB/s]
Downloading [model-00002-of-00002.safetensors]: 100%|██████████| 2.05G/2.05G [00:06<00:00, 332MB/s]
Downloading [model.safetensors.index.json]: 100%|██████████| 34.7k/34.7k [00:00<00:00, 56.8kB/s]
Downloading [README.md]: 100%|██████████| 4.79k/4.79k [00:00<00:00, 10.3kB/s]
Downloading [tokenizer.json]: 100%|██████████| 6.71M/6.71M [00:00<00:00, 8.58MB/s]
Downloading [tokenizer_config.json]: 100%|██████████| 7.13k/7.13k [00:00<00:00, 13.8kB/s]
Downloading [vocab.json]: 100%|██████████| 2.65M/2.65M [00:00<00:00, 5.09MB/s]
/usr/local/lib/python3.10/site-packages/accelerate/utils/modeling.py:1405: UserWarning: Current model requires 234882816 bytes of buffer for offloaded layers, which seems does not fit any GPU's remaining memory. If you are experiencing a OOM later, please consider using offload_buffers=True.
warnings.warn(面对兴趣与拖延之间的矛盾,确实会让人感到困扰。这里有一些建议或许能帮助你克服拖延,更好地坚持学习:
- 设定小目标:将大目标分解为一系列小目标。完成每一个小目标都是一次小小的胜利,这可以增加你的动力和成就感。
- 制定计划:为自己规划一个详细的学习计划,并尽量按照计划执行。记得为休息时间留出空间,保持良好的工作与休息平衡。
- 保持积极心态:对自己保持耐心和理解,不要因为一时的困难而放弃。记住,进步的过程就是成长的过程。
由于modelscope不支持LORA, 这边查看了本地路径
print(model.model_dir)
/mnt/workspace/.cache/modelscope/hub/qwen/Qwen2___5-3B-Instruct查看文件
config.json
merges.txt
README.md
configuration.json
model-00001-of-00002.safetensors
tokenizer_config.json
generation_config.json
model-00002-of-00002.safetensors
tokenizer.json
LICENSE
model.safetensors.index.json
vocab.json
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...微调代码
### 初始化设定和随机种子
import os
os.environ["CUDAVISIBLE_DEVICES"] = "0"
import torch
import numpy as np
import pandas as pd
import random
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False基于prompt用大模型构造了20个样本。
import json
x = '''这基金表现也太差了吧,买了半年了还亏着呢。
管理费收得比别的基金都高,感觉就是在给基金公司打工。
想查查具体投了啥,结果发现透明度低得要命,啥也看不清楚。
基金经理换来换去的,都不知道到底谁在管我的钱。
客服电话打过去半天才有人接,问个问题还得等上好几天才有回复。
市场稍微有点风吹草动,这基金就跌得比谁都快。
投资组合里全是同一行业的股票,风险大得让人睡不着觉。
长期持有也没见赚多少钱,还不如存银行定期。
分红政策一会儿一个样,根本没法做财务规划。
当初宣传时说得好听,实际操作起来完全不是那么回事。'''
x_samples = x.split("n")
y = '''这基金真的稳啊,买了之后收益一直挺不错的,感觉很靠谱!
管理团队超级专业,每次市场波动都能及时调整策略,让人放心。
透明度很高,随时都能查到投资组合的情况,心里有数。
基金经理经验老道,看准了几个大机会,赚了不少。
客服态度特别好,有问题总能很快得到解答,服务真是没得说。
即使在市场不好的时候,这基金的表现也比大多数同类产品强。
分散投资做得很好,风险控制得很到位,睡个安稳觉没问题。
长期持有的话,回报率真的非常可观,值得信赖。
分红政策明确而且稳定,每年都能按时收到分红,计划财务很方便。
宣传时承诺的那些好处都实现了,真心觉得选对了这只基金。'''
y_samples = y.split("n")
# 创建一个Python字典
x_data = [{"content": i, "label": 0, "标注类别": "正向"} for i in x_samples]
y_data = [{"content": i, "label": 1, "标注类别": "负向"} for i in y_samples]
def save_json(path, data):
# 将Python字典转换为JSON字符串
with open(path, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
save_json('data/classify_train.json', x_data[:6]+y_data[:6])
save_json('data/classify_valid.json', x_data[6:8]+y_data[6:8])
save_json('data/classify_test.json', x_data[8:]+y_data[8:])数据加载
import json
from tqdm import tqdm
from loguru import logger
from datasets import Dataset, load_dataset
def get_dataset_from_json(json_path, cols):
with open(json_path, "r") as file:
data = json.load(file)
df = pd.DataFrame(data)
dataset = Dataset.from_pandas(df[cols], split='train')
return dataset
# load_dataset加载json的dataset太慢了
cols = ['content', 'label', '标注类别']
train_ds = get_dataset_from_json('data/classify_train.json', cols)
logger.info(f"TrainData num: {len(train_ds)}")
valid_ds = get_dataset_from_json('data/classify_valid.json', cols)
logger.info(f"ValidData num: {len(valid_ds)}")
test_ds = get_dataset_from_json('data/classify_test.json', cols)
logger.info(f"TestData num: {len(test_ds)}")print(train_ds[0])
{'content': '这基金表现也太差了吧,买了半年了还亏着呢。', 'label': 0, '标注类别': '正向'}准备dataset(简单实现截断和padding, 无动态padding)

id2label = {0: "正向", 1: "负向"}
label2id = {v:k for k,v in id2label.items()}
from transformers import AutoTokenizer, DataCollatorWithPadding
# from modelscope import AutoTokenizer, DataCollatorwithPadding
model_name_or_path = "/mnt/workspace/.cache/modelscope/hub/qwen/Qwen2___5-3B-Instruct"
model_name = model_name_or_path.split("/")[-1]
print(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, padding_side='left')
tokenizer.add_special_tokens({'pad_token': '<|endoftext|>'})
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
MAX_LEN = 24
txt_colname = 'content'
def preprocess_function(examples):
# padding后处理效率不高,需要动态batch padding
return tokenizer(examples[txt_colname], max_length=MAX_LEN, padding=True, truncatinotallow=True)
tokenized_train = train_ds.map(preprocess_function, num_proc=64, batched=True)
tokenized_valid = valid_ds.map(preprocess_function, num_proc=64, batched=True)sklearn评测代码
from sklearn.metrics import (
classification_report,
confusion_matrix,
accuracy_score,
f1_score,
precision_score,
recall_score
)
def evals(test_ds, model):
k_list = [x[txt_colname] for x in test_ds]
model.eval()
k_result = []
for idx, txt in tqdm(enumerate(k_list)):
model_inputs = tokenizer([txt], max_length=MAX_LEN, truncatinotallow=True, return_tensors="pt").to(model.device)
logits = model(**model_inputs).logits
res = int(torch.argmax(logits, axis=1).cpu())
k_result.append(id2label.get(res))
y_true = np.array(test_ds['label'])
y_pred = np.array([label2id.get(x) for x in k_result])
return y_true, y_pred
def compute_metrics(eval_pred):
predictions, label = eval_pred
predictions = np.argmax(predictions, axis=1)
return {"f1": f1_score(y_true=label, y_pred=predictions, average='weighted')}
def compute_valid_metrics(eval_pred):
predictions, label = eval_pred
y_true, y_pred = label, predictions
accuracy = accuracy_score(y_true, y_pred)
print(f'Accuracy: {accuracy}')
metric_types = ['micro', 'macro', 'weighted']
for metric_type in metric_types:
precision = precision_score(y_true, y_pred, average=metric_type)
recall = recall_score(y_true, y_pred, average=metric_type)
f1 = f1_score(y_true, y_pred, average=metric_type)
print(f'{metric_type} Precision: {precision}')
print(f'{metric_type} Recall: {recall}')
print(f'{metric_type} F1 Score: {f1}')模型加载,使用Trainer进行训练
import torch
from transformers import AutoModelForSequenceClassification
from transformers import Trainer, TrainingArguments
from peft import get_peft_config, PeftModel, PeftConfig, get_peft_model, LoraConfig, TaskType
rank = 64
alpha = rank*2
training_args = TrainingArguments(
output_dir=f"./output/{model_name}/seqence_classify/",
learning_rate=5e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=4,
num_train_epochs=3,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
inference_mode=False,
r=rank,
lora_alpha=alpha,
lora_dropout=0.1
)
model = AutoModelForSequenceClassification.from_pretrained(
model_name_or_path,
num_labels=len(id2label),
id2label=id2label,
label2id=label2id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
attn_implementatinotallow="flash attention2"
)
model.config.pad_token_id = tokenizer.pad_token_id
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_valid,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics
)
logger.info(f"start Trainingrank: {rank}")
trainer.train()
logger.info(f"Valid Set, rank: {rank}")
y_true, y_pred = evals(valid_ds, model)
metrics = compute_valid_metrics((y_pred, y_true))
logger.info(metrics)
logger.info(f"Test Set, rank: {rank}")
y_true, y_pred = evals(test_ds, model)
metrics = compute_valid_metrics((y_pred, y_true))
logger.info(metrics)
saved_model = model.merge_and_unload()
saved_model.save_pretrained('/model/qwen2-3b/seqcls')将LoraConfig和get_peft_model去掉,就是SFT的代码。
model的结构
PeftModelForSequenceClassification(
(base_model): LoraModel(
(model): Qwen2ForSequenceClassification(
(model): Qwen2Model(
(embed_tokens): Embedding(151936, 2048)
(layers): ModuleList(
(0-35): 36 x Qwen2DecoderLayer(
(self_attn): Qwen2SdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=True)
(k_proj): Linear(in_features=2048, out_features=256, bias=True)
(v_proj): Linear(in_features=2048, out_features=256, bias=True)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): Qwen2RotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=2048, out_features=11008, bias=False)
(up_proj): Linear(in_features=2048, out_features=11008, bias=False)
(down_proj): Linear(in_features=11008, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((2048,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((2048,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((2048,), eps=1e-06)
)
(score): Linear(in_features=2048, out_features=2, bias=False)
)
)
)预测
txt = "退钱,什么辣鸡基金"
model_inputs = tokenizer([txt], max_length=MAX_LEN, truncatinotallow=True, return_tensors="pt").to(saved_model.device)
logits = saved_model(**model_inputs).logits
res = int(torch.argmax(logits, axis=1).cpu())
print(id2label[res])
负向output输出类型
SequenceClassifierOutputWithPast(loss=None, logits=tensor([[-0.1387, 2.3438]], device='cuda:0', grad_fn=<IndexBackward0>), past_key_values=((tensor([[[[ -3.3750, 0.3164, 2.3125, ..., 56.5000, 26.0000, 87.0000],
[ -4.6875, 3.0312, 0.6875, ..., 57.7500, 24.3750, 86.0000],
[ -0.7109, 1.1094, -0.7383, ..., 56.7500, 24.8750, 86.5000],
...,
...,
[-0.2188, 0.2148, 0.4375, ..., -0.1016, 0.9336, -1.1016],
[ 1.3281, 0.3359, 1.3125, ..., -0.3906, 0.0312, -0.0391],
[ 0.8789, 0.5312, 1.4297, ..., 0.1797, -0.9609, -0.6445]]]],
device='cuda:0'))), hidden_states=None, attentinotallow=None)跑测结果
Some weights of Qwen2ForSequenceClassification were not initialized from the model checkpoint at /mnt/workspace/.cache/modelscope/hub/qwen/Qwen2___5-3B-Instruct and are newly initialized: ['score.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Detected kernel version 4.19.91, which is below the recommended minimum of 5.5.0; this can cause the process to hang. It is recommended to upgrade the kernel to the minimum version or higher.
2024-10-09 23:54:07.615 | INFO | __main__:<module>:53 - start Trainingrank: 64
trainable params: 119,738,368 || all params: 3,205,681,152 || trainable%: 3.7352
[6/6 00:08, Epoch 3/3]
Epoch Training Loss Validation Loss F1
1 No log 0.988281 0.333333
2 No log 0.527344 0.733333
3 No log 0.453125 1.000000
2024-10-09 23:54:17.371 | INFO | __main__:<module>:56 - Valid Set, rank: 64
4it [00:00, 8.03it/s]
2024-10-09 23:54:17.896 | INFO | __main__:<module>:59 - None
2024-10-09 23:54:17.897 | INFO | __main__:<module>:61 - Test Set, rank: 64
Accuracy: 1.0
micro Precision: 1.0
micro Recall: 1.0
micro F1 Score: 1.0
macro Precision: 1.0
macro Recall: 1.0
macro F1 Score: 1.0
weighted Precision: 1.0
weighted Recall: 1.0
weighted F1 Score: 1.0
4it [00:00, 13.58it/s]
2024-10-09 23:54:18.218 | INFO | __main__:<module>:64 - None
Accuracy: 0.75
micro Precision: 0.75
micro Recall: 0.75
micro F1 Score: 0.75
macro Precision: 0.8333333333333333
macro Recall: 0.75
macro F1 Score: 0.7333333333333334
weighted Precision: 0.8333333333333333
weighted Recall: 0.75
weighted F1 Score: 0.7333333333333334四、自测结果4.1 短文本
常用的对话中,客户的单轮query, 情感极性分类。3分类,长度最大128字,训练样本量6K左右
query ,比不过基础的BERT
Accuracy:0.9334389857369255
microPrecision:0.9334389857369255
microRecall:0.9334389857369255
micro F1Score:0.9334389857369255
macro Precision:0.9292774942877138
macro Reca1l:0.9550788300142491
macro F1Score:0.9388312342456646
weightedPrecision:0.9418775412386249
weighted Recall:0.9334389857369255
weighted F1Score:0.93383533375322
precision recall fi-score support
0 1.00 0.88 0.93 334
1 0.94 0.99 0.97 101
2 0.85 0.99 0.92 196
accuracy 0.93
macro avg 0.93
weightedavg 0.94使用Chinese-RoBerta-large-wwm,及其各种变体进行比较。7B、3B、1.5B和0.5B,均无优势。比不过Large、Base。一些裁减参数量就几十M的都能到85左右,所以看不出LLM的优势。
结论:
短文本场景,LLM的优势在于少样本、样本不均匀,以及基于prompt+fewshot用72B规模生成伪标签。
除非样本量上万,且价值比较大的场景,可以尝试14B以上模型,调参确认提点后,再进行蒸馏。
绝大部分短文本场景没有必要用到大模型,除非是生成场景,比如query扩写、query多轮改写。
4.2 长文本
这里用到的是ASR转译文本
训练集4918样本,平均长度740字,最大4631字,75% 918字
LoRA微调结果,一般2个epoch效果好些,rank要适当调参。
epoch=1, rank=96, alpha=2*rank
Accuracy:0.8415637860082305
micro Precision:0.8415637860082305
micro Recall:0.8415637860082305
micro F1 Score:0.8415637860082305
macro Precision:0.8075007129137883
macro Recall: 0.770659344467927
macroF1 Score:0.7726373117446225
weightedPrecision:0.8509932419375813
weighted Recall:0.8415637860082305
weighted F1Score:0.8420807262647815
precision recall f1-score support
0 0.95 0.83 0.89 163
1 0.76 0.77 0.77 66
2 0.78 0.89 0.83 63
3 0.81 0.81 0.81 42
4 0.80 0.93 0.86 30
5 0.48 0.56 0.51 18
6 1.00 0.43 0.60 7
7 0.88 0.95 0.92 97epoch=3,rank=96, alpha=2*rank
Accuracy:0.8847736625514403
micro Precision:0.8847736625514403
micro Recall:0.8847736625514403
micro F1 Score:0.8847736625514403
macro Precision:0.8765027065399982
macroRecall:0.8400805218716799
macro F1 Score:.8527883278910355
weighted Precision:0.8903846924862034
weighted Recall:0.8847736625514403
weighted F1 Score:0.8852820009557909
precision recall fl-score support
0 0.94 0.89 0.91 163
1 0.77 0.85 0.81 66
2 0.81 0.88 0.83 42
3 0.79 0.90 0.86 63
4 1.00 0.93 0.97 30
5 0.92 0.61 0.73 18
6 0.83 0.71 0.77 7
7 0.96 0.94 0.95 97五、相关资料
- 比较详细的LLM分类头微调经验 ,十分推荐看看
邱震宇:大模型在传统NLP任务的使用姿势探讨 https://zhuanlan.zhihu.com/p/704983302
在灾难推文分析场景上比较用 LoRA 微调 Roberta、Llama 2 和 Mistral 的过程及表现 https://segmentfault.com/a/1190000044485544
SFT分类头微调代码(其实就是去掉LoRA那几行代码) https://github.com/muyaostudio/qwen2_seq_cls
知乎上的一个代码
郝可爱:使用LlamaForSequenceClassification构建文本分类模型 https://zhuanlan.zhihu.com/p/691459595
相关代码可以在github上找找,kaggle也推荐去,主要就是这2个地方。
#美国首个全球AI禁令颁布
英伟达AMD禁运,各国分三级上限5万块
美国史上首个全球AI出口管制,正式出台!刚刚,拜登在下台之际,全面发布芯片禁令,全球三级管控区域AI芯片全面禁运,二级管控区域最高可得5万块GPU。
果然,美国芯片限制新规,正式上线了!
上周曾有消息曝出,拜登政府欲在交接之际放出最后一搏。
而就在1月13日,拜登政府发布全面规则,芯片禁令正式出台。
也就是说,人类史上首个全球AI出口管制规则来了。
为了将AI这项变革性技术置于美国及其盟友的控制之下,同时遏制中国等国家和地区的发展,拜登政府认为,芯片禁令势在必行。
通过新的禁令,美国将能够建立一个全球性框架,管理AI芯片和模型如何与国外共享,并指导未来几年AI在世界各地的传播。
不仅如此,在未来几年,美国预计还会发布更多与芯片和AI相关的规定,包括一项鼓励数据中心国内能源生产的行政命令,以及旨在阻止最尖端芯片流入中国的新规。
全球三个层级的芯片限制
全世界国家和地区的地区分为三级(Tier 1,Tier 2,Tier 3),分别接受不同级别的管控。
- Tier 1的美国少数盟友,可以不受限制地获取美国芯片
- Tier 2的国家和地区,将面临以国为单位的总算力限制
- Tier 3的国家和地区,数据中心将被全面禁止进口芯片
![]()
一级管控
Tier 1由美国和18个同盟组成,包括澳大利亚、比利时、英国、加拿大、丹麦、芬兰、法国、德国、爱尔兰、意大利、日本、荷兰、新西兰、挪威、韩国、西班牙、瑞典和中国台湾。
企业可以在这些地区自由部署算力,总部设在这些地区的公司还可以申请美国政府的综合许可,向世界其他大部分地区的数据中心供应芯片。
但需要满足以下条件:在Tier 1国家和地区以外的算力总和不得超过25%,且在任何一个Tier 2国家和地区的算力不得超过7%。同时,企业必须严格遵守美国政府的安全要求。
其中,总部位于美国的企业还需要确保至少50%的算力留在美国境内。
二级管控
全球大多数国家和地区,包括东欧、中东、墨西哥和拉丁美洲等,都属于Tier 2这一级别。
他们将面临美国设定的总处理性能(Total Processing Performance,TPP)限制——在2025-2027年之间,每个国家和地区能获得的上限是7.9亿,也就是等效约5万块H100 GPU。
不过,新规也表示,这些中间国家可以去申请NVEU资格,由此便可获得累计最高5,064,000,000 TPP的算力(约等于32万块GPU)。
美国认为,这些配额可确保这些国家和地区在训练模型时所用的计算集群,落后美国约12个月或一代。
三级管控
Tier 3将面临最严格的限制级别,适用于中国、俄罗斯等总计约24个所有美国武器禁运的国家和地区。
向这些地区的数据中心出口芯片,将被全面禁止。
模型权重管控
对于AI模型的参数权重,新规也首次进行了管控。
具体来说,企业不能在属于Tier 3的国家和地区部署高性能的闭源模型;而在Tier 2的国家和地区进行部署时,则必须严格遵守安全标准。
相比之下,开源模型(或称开放权重模型)并不受这些规则的限制;性能低于现有开源模型的闭源模型,也不在管控范围内。
在这种情况下,如果有AI公司需要对通用开源模型进行微调,且过程需要消耗大量算力,那就必须要向美国政府申请许可,才能在属于Tier 2的国家和地区开展相关操作。
数据中心可申请特殊认证
此外,这份168页的规则还建立了一个系统,允许微软和谷歌等运营数据中心的公司申请特殊的政府认证。
作为交换条件,这些遵守特定安全标准的公司可以在全球范围内更自由地进行AI处理器贸易。
这些公司仍需同意将其75%的AI计算能力保持在美国或盟国境内,且在任何其他单一国家和地区部署的计算能力不得超过百分之七。
在国外设立数据中心的公司,将被要求采用安全标准来保护这些知识产权,防止对手获取。
总之,受限制的国家和地区政府可以通过与美国政府签署协议,来提高他们可以自由进口的AI处理器数量,在协议中他们需要同意与美国在保护AI方面的目标保持一致。
在美国政府的指导下,微软去年已与阿联酋公司G42达成协议,作为交换条件,G42将清除其系统中的中国设备并采取其他措施。
许可证是否有其他例外?
如果买家订购少量GPU——相当于最多约1,700个H100——将不计入上限,只需向政府通报,无需许可证。
美国表示,大多数处理器订单都低于这一限制,特别是大学、医疗机构和研究组织的订单。
这一例外旨在加快美国处理器在全球范围内的低风险出货。另外,游戏GPU也在例外范围内。
掌控全球所有的算力中心
此次新规背后,还有一个更大的目标:让盟国成为企业建设全球最大算力数据中心的首选地,将最先进的AI模型控制在美国及其伙伴的境内。
此前,全球各国政府,特别是中东地区,一直在投入资金吸引和建设大型算力数据中心,试图成为下一个AI发展中心。
美国国家安全顾问利文表示,该规定将确保训练最先进AI的基础设施位于美国或亲密盟友的管辖范围内。
不过,新规是否保留,如何执行,这些问题还将由特朗普政府决定。
对此,拜登政府官员表示问题不大:这些规定已得到两党支持,他们已经就此与即将上任的政府进行了协商。
部门盟国不满
根据此次新规,世界上大多数国家和地区都将受到限制AI芯片进口数量的上限约束,即使是与美国有密切贸易关系或军事同盟的国家和地区也是如此。
不过,各国和企业可以通过与美国政府达成特别协议,来提高这一数量。
对此,欧盟委员会在周一的声明中表示:「我们对美国今天采取的限制部分欧盟成员国及其公司获取先进AI芯片出口的措施感到担忧。欧洲国家和地区对美国而言是经济机遇,而非安全风险。」
企业表示抗议
目前,全球半导体市场仍由英伟达为代表的美国公司主导。如果美国政府限制美国公司出口,就能控制全球AI技术的流向。
美国企业对此纷纷表示抗议,称限制可能会阻碍无害甚至有益的计算应用,激怒美国盟友,并最终推动全球买家转向购买包括中国在内的非美国产品。
英伟达负责政府事务的副总裁表示,该规定「前所未有且方向错误」,并表示这「威胁到全球创新和经济增长」。
新规不但无法减轻任何威胁,反而只会削弱美国的全球竞争力,破坏使美国保持领先地位的创新能力。
表示强烈反对的还有代表科技公司的信息技术产业委员会主席Jason Oxman。
在致国会领导层的一封信中,他提出这样的要求:如果特朗普政府不采取行动,国会应该介入并使用其权力推翻这一决定。
半导体行业协会主席John Neuffer表示,他的组织「对如此重大影响的政策变化在总统过渡期前几天仓促推出,且没有任何来自行业的有意义的意见感到深度失望。这关系重大,时机也很敏感。」
拜登政府在政权交接之际,匆忙推出这一系列监管措施,意在堵住漏洞,巩固其在抑制中国技术发展上的政策成功。
就在此前,中国等国家已被实施了芯片制造设备出口新禁令,许多中国公司被列入了军事管制清单。
但这次的芯片禁令,无疑是所有行动中最全面、影响最深远的。
禁令创造了一个框架,在保护美国安全利益的同时,仍允许企业在国外竞争。
在供应链被转移到出价最高的补贴方之前,美国和盟友主导的供应链将受到保护。
英伟达回应
针对拜登政府「AI扩散」新政,英伟达官方做出了正式的回应:
「AI扩散」规则将扼杀创新,削弱美国在全球技术领域的领导地位。限制对主流计算技术的使用可能会阻碍国内外各行业的AI进步。
美国的优势在于创新和竞争。这项规则只会损害美国经济,让美国落后。
其实在此之前,甲骨文也曾发文,对拜登政府即将要出台的新政做出回应。
他们称,「这将成为美国科技行业有史以来最具破坏性的事件之一」。
在最新长文中,英伟达回顾了过去几十年,计算机和软件生态系统领导地位,一直是美国实力和全球影响力的基石。
在此起期间,美国联邦政府采取了明智的不干扰政策,才得以让主流计算机和软件设计、营销和销售自由发展,这激发了创新并推动了经济增长。
他们还强调了,特朗普政府任期内为美国在AI领域的优势地位奠定了基础。
如今,AI已深度融入各类应用中,推动经济增长,确保了美国在前沿科技领域的领导地位。
然而,拜登政府新政可能会影响全球创新和经济增长,这些规则将在全球范围内进行技术管控,甚至包括已广泛应用于主流游戏PC和消费级硬件的技术。
在英伟达看来,这项政策存在以下问题:
- 缺乏充分的立法审查,政策制定过程不透明
- 官僚化控制扼杀美国半导体、计算机、系统,甚至软件在全球设计和营销方式的市场竞争
- 有可能削弱美国全球市场竞争力
尽管「AI扩散」规则要在120天后才正式生效,但其负面影响已经开始显现。
英伟达最后表示,正如特朗普政府时期所证明的,美国的成功在于创新、竞争,以及与世界分享技术,而不是躲在政府过度干预设置的高墙之后。
路透称,截至美国当地时间上午交易时段,英伟达股价下跌约5%,AMD股价下跌约1%。
三大云计算提供商微软、亚马逊、谷歌股价均下跌约1%。
参考资料:

















 899
899

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









