







我自己的原文哦~ https://blog.51cto.com/whaosoft/13349569
#AgentSociety
清华团队构建大型社会模拟器AgentSociety,推动智能社会治理与研究范式变革
“凡我无法创造的,我就无法真正理解。” -- 费曼
智能时代呼啸而来,正深刻改变着人们生产、生活和学习的方式。过去几十年里,社会科学家和相关领域的研究者,一直致力于通过实证数据与模型揭示人类行为和智能社会运行的基本规律,试图找出隐藏在各种社会现象和治理痛点背后的因果机制,从而回答 “是什么?为什么?如何治” 等一系列问题。然而,在社会科学研究从 “解释世界” 向 “改造世界” 演进的范式转型中,研究者们始终面临着一个根本性挑战 —— 如何突破传统实证主义方法的局限,实现对人类行为模式与社会运行规律的可计算、可干预、可预测的深度理解。正如物理学家费曼所说的那句经典名言:“凡我无法创造的,我就无法真正理解。” 真正的理解,不仅是观察和解释,更在于能否通过 “生成式” 的方式,自底而上地模拟复现人类行为的复杂模式与社会系统的运行规律,从而模拟、预测和研判智能社会治理演化路径和潜在社会风险,推动基于前瞻性实验主义智能社会治理最佳路径。
正如复杂性科学先驱霍兰德所指出的:“社会系统的本质在于其构成元素间的非线性涌现。” 这一论断揭示了传统还原论方法在应对社会复杂性时的固有局限,也催生了 “生成式社会科学”(Generative Social Science)这一研究范式的迅速崛起,该范式将社会视为复杂自适应系统,从微观层面出发,通过模拟个体的行为和互动来探索复杂社会系统的内在机制,强调通过自底向上的计算实现对社会数字孪生的构建。其中,智能体建模(Agent-Based Modeling)是目前广泛应用的一种方法,它通过构建 Agent 以及多 Agents 之间的交互关系,动态再现社会的运行状态。这种方法已被广泛应用于社会科学、政治学、经济学等领域,帮助研究者更深入地理解人类行为及社会的复杂性。
尽管这一领域取得了重要进展,仍面临一个亟待解决的核心问题:这样的模拟究竟能在多大程度上真实还原现实社会的复杂性?因此,如何在保证模拟规模足够庞大以支持复杂性研究的同时,提升模拟的真实性,使其更贴近现实社会的运行逻辑,仍是亟待突破的重要方向。
近日,清华大学电子系城市科学与计算中心研究团队,联合清华大学智能社会治理研究院、公共管理学院、社会科学学院等跨学科团队深度协作,充分发挥大模型智能体、真实社会环境仿真与大规模模拟加速框架的技术优势,结合智能社会治理的前沿理论与实践探索,成功构建了基于大模型的 “大型社会模拟器 AgentSociety” 1.0 版本,可精确模拟社会舆论传播、认知观点极化、公众政策响应等。AgentSociety 从社会学第一性原理出发,以助力推动社会科学研究范式变革,推动了社会学领域从行为模拟到心智建模、从静态推演到动态共生、从实验室工具到社会基础设施的发展。具体而言,该模拟器包括:
- 大模型驱动的社会人智能体:基于社会学理论,构建具有 “类人心智” 的社会人智能体,赋予其情感、需求、动机与认知能力,并在这些心智驱动下进行复杂社会行为,如移动、就业、消费、社交互动等。
- 真实城市社会环境:精准模拟社会人赖以生存的城市空间,重现交通、基础设施和公共资源,使智能体能在真实环境约束下交互,形成逼真的社会生态。
- 大规模社会模拟引擎:采用异步模拟架构与 Ray 分布式计算框架,结合智能体分组和 MQTT 高并发通信,实现高效、可扩展的智能体交互与社会行为模拟。
- 智能社会科学研究与治理工具箱:全面支持实验、访谈、问卷调查等一系列社会学研究方法,提供多种自动化数据分析工具,从定性研究到定量分析全面助力社会科学研究的深入开展。
- 文章地址:https://arxiv.org/abs/2502.08691
- 官方文档:https://agentsociety.readthedocs.io/en/latest/
- GitHub 链接:https://github.com/tsinghua-fib-lab/agentsociety/


图 1 AgentSociety 总览(交互案例见:https://agentsociety.fiblab.net/exp/1a4c4fa5-04c1-4973-9433-b8b696f2fda0)
大型社会模拟器通过数字化和虚拟化的方式,使研究者能够在无需进行实际实验的情况下,模拟并观察社会现象的变化过程,显著降低了研究的风险与成本。同时,模拟器能够在不同情境下进行多维度的数据采集和实验设计,克服传统研究因受限于时间、空间和资源等因素所带来的局限。团队提供可视化交互工具和智能社会治理研究工具箱,支持实时监测、主动干预和数据收集,助力社会研究和治理实验。
社会模拟器的应用不仅限于具体的社会实验,它还可以作为社会科学研究的核心方法工具,辅助开展前期研究和假设验证,辅助政策决策者和公共事务参与主体进行智能决策。研究团队可以利用其进行初步的理论构建、实验设计和政策效果评估,为后续的实证研究提供依据。这种工具的灵活性和可扩展性使得研究者能够在不同的社会情境和变量条件下,快速测试理论假设并验证其可行性,为学术研究的精准性和实用性提供有力支持。
为了展示大规模社会模拟器在社会科学研究中的价值,团队开展了一系列典型社会实验,涵盖干预实验、访谈和调查问卷等方法。实验聚焦观点极化、煽动性消息传播与治理、全民基本收入(Universal Basic Income, UBI)政策和飓风冲击下的社会动态,深入探讨个体与群体行为在不同社会机制下的演化规律。基于 AgentSociety 的实验,有效模拟了真实世界中常见的 “回音室效应”、煽动性信息具有更强的传播性和情绪引导力、UBI 政策在个体消费和改善心理健康方面的效果、以及飓风冲击下的人群流动的受限与恢复,研究结果与真实世界高度一致,证明了 AgentSociety 作为低成本实验场地验证政策的有效性。
一、大模型驱动的社会人智能体
社会人智能体是 AgentSociety 的核心。团队提出的大模型驱动的社会人智能体,旨在通过结合大模型智能体技术与心理学、经济学和行为科学理论,模拟具有复杂社会行为的智能体,并通过模拟大规模智能体间及智能体与环境的交互,探索社会现象的演变和集体行为。具体而言,团队将社会人智能体设计分为三个层面:心智、心智 - 行为耦合和行为。

图 2 社会人智能体的基本构成,分为心智、心智 - 行为耦合和行为
心智层面:构建智能体的心理认知系统
在心智层面,为每个智能体构建稳定的个体画像(如性格、年龄、性别)和动态的个人状态(如情感、经济状况和社会关系),以确保智能体在不同情境下展现个性化的行为模式。在此基础上,团队引入情感(Emotions)、需求(Needs)和认知(Cognition) 三大核心心理过程,共同决定智能体的决策推理、行为模式和社会适应能力。具体而言,情感反映智能体对外部刺激的即时反应,影响其短期决策和社交互动,例如在正面反馈下增强合作意愿,或在负面情境中表现出回避行为;需求是行为的内在驱动力,基于马斯洛需求层次理论,智能体在满足基本生存需求后,会逐步追求安全、社交、尊重乃至自我实现,从而塑造其长期行为轨迹和社交策略;认知决定了智能体如何理解外部世界,包括对社会事件、政策环境和群体行为的态度,这一过程不仅受其个性和过往经历影响,还会因长期社会互动不断演化。
心智 - 行为耦合:心智如何驱动智能体行为
智能体的行为并非随机或被动响应,而是由其情感、需求和认知共同驱动,并根据个人状态与外部环境的交互不断调整。团队基于马斯洛需求层次理论(Maslow’s Hierarchy of Needs)和计划行为理论(Theory of Planned Behavior, TPB),构建从心理状态到行为执行的完整路径,使智能体的行为更符合人类的动机模式。按照马斯洛需求层次理论,智能体会优先满足生存和安全需求,在此基础上逐步追求社交等更高级目标。与此同时,基于计划行为理论,智能体在形成目标后,会结合自身认知和环境因素主动规划行动,使其行为既具适应性,又能展现长期连贯性。
行为层面:智能体如何展现复杂类人行为
在行为层面,提出的社会人智能体不仅能够执行简单行为,还能够展现多层次的复杂社会行为,包括移动、社交和经济活动。简单行为主要涵盖睡眠、饮食、娱乐和休息等基础活动,这些行为虽然不涉及复杂的决策,但对智能体的整体状态和长期行为模式至关重要。例如,睡眠不足可能影响情绪和社交意愿,而良好的饮食和娱乐体验则可能提升幸福感,进一步塑造智能体的社交和工作行为。复杂社会行为方面,智能体能够在移动、社交和经济活动中展现高度的自主智能。移动行为不仅涉及简单的地点切换,还包括出行方式选择、路径规划以及对交通环境的动态调整,使智能体的移动模式更符合现实社会的出行习惯。社交行为不仅限于基本互动,还涉及社交关系的建立、维持和演变,智能体会根据自身需求、情感状态和外部环境调整社交策略,从而形成类似人类的社交网络。经济行为方面,智能体不仅理解资源交换的基本概念,还能根据自身经济状况、市场环境和个体偏好进行工作、消费等经济决策,展现出符合社会规则的经济行为模式。

图 3 社会人智能体设计架构
社会人智能体模拟:自主生活的一日
为了验证智能体的自主决策能力及其行为模式的合理性,团队模拟了社会人智能体的一日生活,观察其在移动、社交和经济活动 方面的决策和适应能力(如下表所示)。通过 24 小时的仿真,智能体在需求、情感和认知 的驱动下自主规划日常任务,并动态调整行为,以符合现实社会中的时间节奏和互动逻辑。

表 1 社会人智能体自主生活一日示例
二、真实社会环境
为了让智能体的行为更加贴近现实世界,团队构建了一个高度真实、可交互的城市社会环境,支持移动、社交和经济活动等核心行为的模拟。与仅依赖大模型推理不同,团队的环境结合物理约束、社会规则和资源限制,确保智能体的行为符合现实逻辑,避免大模型生成的“幻觉”影响。
这一环境具备三大核心优势:
1.精准建模现实世界机制:融合物理约束、成本反馈和社会运行规则,让智能体在时间、资源、经济等多维度受到真实限制,使其行为更具合理性和连贯性。
2.数据源自现实,确保行为逻辑一致:环境数据直接来源于真实世界,或基于现实社会原则构建,保证模拟结果具有现实参考价值,避免虚拟环境脱离社会规律。
3.智能体可交互接口,支持真实决策:智能体不仅能够感知环境,还可直接与其交互,实现路径规划、社交关系演变、经济交易等动态决策,确保行为不仅是文本推理的结果,而是真实行动的模拟。
此外,团队将环境划分为城市空间、社交空间和经济空间,共同构建完整、动态的社会系统,为智能体行为的模拟提供精准支撑,使其更符合人类社会的运行模式。

图 4 真实城市社会环境
为了验证真实城市社会环境在大规模社会模拟中的适应性和运行效率,团队进行了性能测试,评估其在不同规模的智能体数量和高并发查询场景下的表现。实验模拟了 1,000、10,000、100,000 和 1,000,000 个智能体在城市、社交和经济空间内的交互,并采用典型工作日出行模式,在 8:30 早高峰启动模拟。测试过程中,团队设定查询执行比为 1:999(即每 999 次数据查询后进行 1 次环境状态更新),贴近智能体的真实交互模式,同时控制模拟进程数为 2、4、8、16 和 32。每种实验条件下,团队重复测试五次,每次持续 10 秒,并记录查询速率(QPS) 在 10^2 至 10^5 之间的变化情况。实验结果表明,即使智能体数量和查询速率显著增加,系统仍保持稳定运行,能够高效处理大规模智能体交互,为大规模社会模拟提供实时、可靠的计算支持。

表 2 城市社会环境性能评估
三、大规模社会模拟引擎与社会学研究工具箱
为了实现真实、高效地大规模社会模拟,团队构建了一个高效、可扩展、支持大规模社会人智能体并行执行的社会模拟引擎。该引擎不仅结合了 LLM 驱动的多智能体系统和真实城市社会环境,更在系统架构上进行了深度优化,以确保模拟结果既具备现实合理性,又能大规模、高效运行。

图 5 大规模社会模拟引擎
传统多智能体框架(如 CAMEL、AgentScope)通常依赖严格的消息传递机制来组织智能体间的交互,以保证任务的执行顺序。然而,在现实社会中,个体的行为决策并非总是受外部输入直接驱动,而是源自个体记忆、认知状态和环境约束的自主整合。因此,团队的社会模拟引擎采用了更接近现实的异步模拟架构,让每个智能体作为独立的模拟单元,不依赖特定的执行顺序,而是通过消息系统进行信息交换,实现智能体之间的相互影响。
为了提升大规模并行模拟的计算效率,团队基于 Ray 分布式计算框架,结合 Python 的 asyncio 机制进行异步执行,使模拟任务能够高效利用多核计算资源,并支持分布式集群扩展。同时,为了降低智能体间通信的系统开销,团队引入了智能体分组(Agent Group)机制,使多个智能体可以在单个进程中运行,从而减少进程间通信开销,提高计算效率。此外,为了实现大规模社会智能体的高并发、可靠消息传输,团队引入了 MQTT 通信协议,该协议广泛应用于物联网场景,具备高吞吐量和低延迟的特点,非常适用于大规模社会模拟中智能体间的信息交换。
在系统架构上,团队采用模块化设计,包括共享服务层、模拟任务管理层和可选的 GUI 交互层。共享服务层包括 LLM API 接口、MQTT 消息服务器、数据库存储和指标管理系统,确保模拟过程中数据传输高效、智能体行为可记录、结果可视化。模拟任务管理层则基于 Ray 框架,提供高效的智能体管理和任务调度能力,使得不同实验能够独立执行,同时共享计算资源,提升可扩展性和复用性。
大型社会模拟器通过数字化和虚拟化的方式,使研究者能够在无需进行实际实验的情况下,模拟并观察社会现象的变化过程,显著降低了研究的风险和成本。同时模拟器能够在不同情境下进行多维度的数据采集和实验设计,解决传统研究因受限于时间、空间和资源等因素所带来的局限。团队提供可视化交互工具与社会学研究工具箱,支持实时监测、主动干预和数据收集,助力社会实验研究。
- 实时可视化监测:直观展示社交网络、经济活动、移动轨迹 等核心变量,支持实验参数调整,精准跟踪社会演化过程。
- 访谈(Interviews):研究者可实时向智能体提问,获取基于记忆、当前状态和环境的回答,不影响其正常行为。
- 调查问卷(Surveys):支持 批量分发结构化问卷,智能体按预设规则作答,确保数据一致性,便于趋势分析。
- 干预实验(Interventions):提供三种行为干预方式,测试社会情境下的个体与群体响应,包括:1)智能体配置:预设性格、目标和关系,影响初始行为倾向;2)记忆操控:修改情绪和认知,观察对决策与社交互动的影响。3)外部信息干预:发送特定信息(如灾害预警)测试应急响应与传播模式。
社会模拟器的应用不仅限于具体的社会实验,它还可以作为社会科学研究的核心方法工具,辅助开展前期研究和假设验证,辅助政策决策者和公共事务参与主体进行智能决策。研究团队可以利用其进行初步的理论构建、实验设计和政策效果评估,为后续的实证研究提供依据。这种工具的灵活性和可扩展性使得研究者能够在不同的社会情境和变量条件下,快速测试理论假设并验证其可行性,为学术研究的精准性和实用性提供有力保障。
为了评估社会模拟引擎的扩展性和计算效率,团队进行了大规模测试,模拟不同数量的智能体,并测量系统在高并发场景下的表现。在消息通信系统方面,团队测试了 MQTT、Redis Pub/Sub 和 RabbitMQ,比较了它们的并行处理能力、吞吐量(msg/s)和辅助工具支持。实验结果显示,MQTT 和 Redis Pub/Sub 满足高吞吐需求。

表 3 消息系统性能评估
在大规模智能体模拟方面,团队在 64 核服务器上运行实验,32 核分配给模拟引擎,32 核用于智能体执行,并测试了 1,000 和 10,000 智能体在不同进程数(8、16、32) 下的运行情况。实验测量了 总执行时间、LLM API 响应时间、模拟器 API 响应时间和令牌消耗,结果表明 Ray 分布式计算框架和智能体分组机制大幅提高了模拟效率,确保系统在 高并发负载下仍能稳定运行。

表 4 AgentSociety 总体性能评估表
上表展示了随着智能体数量增加,系统在分布式计算下的可扩展性及性能表现。实验表明,令牌使用模式(包括输入和输出)保持稳定,分布式并行框架能够有效支持大规模智能体的执行,充分利用多核计算能力,成功缓解了 CPU 瓶颈,确保了系统的可扩展性。同时,实验结果也表明,在完全并行的条件下,执行效率主要受限于大模型 API 调用的性能。
四、社会实验典型案例
为了展示大规模社会模拟器在社会科学研究中的价值,团队开展了一系列典型社会实验,涵盖干预实验、访谈和调查问卷等方法。实验聚焦 观点极化、煽动性消息传播与治理、UBI 政策和飓风冲击下的社会动态,深入探讨个体与群体行为在不同社会机制下的演化规律。
4.1 观点极化社会传播现象模拟
观点极化指社会群体内部的观点逐渐分化,形成难以调和的对立阵营。本实验以枪支管控政策为议题,模拟社会智能体的观点演化过程。实验设计包含对照组和两个干预组:在对照组中,智能体通过相互讨论更新观点,没有外部干预,观点的演化完全依赖于智能体之间的自主社交交互;在同质信息组中,智能体仅接收到与其立场相同的信息,从而模拟信息茧房效应;在对立信息组中,智能体仅接收与其立场相反的信息,旨在测试不同观点的影响。通过这种实验设计,研究人员仅需要书写简单实验配置文件,即可在模拟器中开展该实验:

图 6 观点极化实验配置模板

图 7 接触不同信息条件下观点极化程度的对比
如上图所示,针对枪支管控这一政治议题,三种实验设置下的观点变化呈现出明显的差异。在对照组中,智能体之间进行自由讨论,没有外部干预,结果显示 39% 的智能体在互动后变得更加极化,而 33% 的智能体则倾向于持更加温和的观点。与此相比,在同质信息组中,观点极化现象更加显著,52% 的智能体的观点变得更加极端。这表明,与志同道合的个体过度互动可能会加剧观点的极化,即真实世界中常见的 “回音室效应”。而在对立信息组中,89% 的智能体的观点变得更加温和,11% 的智能体甚至被说服接受了对立的观点。这表明,接触到不同意见的内容能够有效缓解观点极化,或可成为应对极化现象的一种有效策略。
4.2 煽动性消息的传播模拟与智能治理
煽动性消息指包含极端观点或误导性信息的内容,这类信息在社交网络中的快速传播可能加剧群体冲突,影响公共讨论环境。本实验模拟 煽动性信息在社交网络中的传播,并测试不同的内容治理策略对其扩散模式和群体情绪的影响。实验包括对照组和煽动性信息组:在对照组中,智能体仅传播普通信息,团队观察其自然扩散过程及情绪演化。在煽动性信息组,团队引入带有强烈情绪表达的煽动性内容,分析其对信息传播速度和群体情绪的影响。针对煽动性信息传播的治理,团队设计了节点干预和边干预 两种策略,其中节点干预 通过检测并封禁反复传播煽动性内容的账户、以减少信息源头,边干预则在发现煽动性内容传播时切断社交连接,以遏制其扩散。实验还通过与智能体的交互式访谈探究个体在分享煽动性消息时的心理动因。在模拟器中开展该实验的配置如下:

图 8 煽动性消息实验配置模板

图 9 煽动性消息的传播与治理策略
实验结果显示,煽动性消息在社交网络中具有更强的传播潜力和更高的情绪反应。节点干预,即暂停频繁传播煽动性内容的账户,比边干预更有效,能够更好地控制煽动性消息的扩散。情绪强度分析的结果表明,煽动性消息显著放大了网络中的情绪强度,而节点干预在调节情绪反应方面表现尤为突出。进一步,访谈结果揭示,强烈的情绪反应和社会责任感是推动煽动性信息分享的主要驱动因素,用户常因同情或担忧而分享信息,希望引起公众关注或推动社会反应。总体来看,煽动性信息具有更强的传播性和情绪引导力,与真实人类社会中的观测结果高度一致。同时,节点干预在信息控制和情绪调节方面更为有效,为优化社交网络内容管理策略提供了有力支持。
4.3 全民基本收入(Universal Basic Income,UBI)政策推演
UBI 旨在缓解贫困、促进经济稳定和提升社会福祉,尽管其高昂成本和经济影响存在争议,但作为 改善收入分配和增强社会保障的政策工具,已成为研究焦点。本实验通过模拟 UBI 政策的干预效果,探讨其对个体经济行为和宏观经济环境的影响。实验包括对照组和 UBI 干预组。对照组中,智能体在无 UBI 政策的条件下进行经济活动;干预组则模拟实施 UBI,每名智能体每月获得 $1,000 的无条件收入,以观察其消费、储蓄、就业选择等行为变化。实验基于 UBI 试点地区(如美国德克萨斯州)的人口分布数据,并通过对比两组模拟的 经济和社会指标,评估 UBI 对个体和整体经济的影响,分析其是否与现实 UBI 社会实验的结果相符。

图 10 UBI 政策效果与公众意见
实验结果显示,模拟中的经济系统随着时间推移逐渐稳定,实际 GDP 和智能体消费水平的波动逐渐缩小。团队在第 96 步引入了 UBI 政策,并比较了接下来 24 步内的经济和社会指标,具体包括智能体消费水平和抑郁水平(使用 CES-D 量表进行调查问卷评估)。结果表明,UBI 政策显著提高了消费水平并降低了抑郁水平,这与德州 UBI 政策的影响相似,验证了模拟的现实性。此外,通过对智能体的访谈,分析了它们对 UBI 政策的看法。访谈结果显示,UBI 政策的影响与利率、长期福利、储蓄和生活必需品等关键因素密切相关,反映了现实中公众对 UBI 政策的普遍认知。这些结果一方面支持了 UBI 政策在提高消费和改善心理健康方面的效果,另一方面也证明了模拟器作为低成本实验场地验证政策的有效性。
4.4 飓风冲击下的社会动态模拟推演
飓风等极端自然灾害对社会结构和个体行为产生深远影响,理解此类事件对人口流动、基础设施和社会稳定的冲击对于优化应急响应和降低灾害风险至关重要。本实验模拟飓风来袭期间的社会动态,分析个体在灾害环境下的行为模式。实验基于 2019 年飓风多里安(Hurricane Dorian) 对美国东南部的影响,选取南卡罗来纳州哥伦比亚市作为案例研究。数据来源包括 SafeGraph 移动数据(记录城市内人群流动模式)和 Census Block Group(CBG)数据(提供人口统计特征),用于构建 1,000 名社会智能体,模拟其在飓风期间的行为变化。
实验结果显示,模拟智能体在飓风事件中的移动模式与真实数据高度一致,活动水平随飓风来临大幅下降,并在灾后逐步恢复,符合实际人群出行趋势。模拟数据与真实人口流动的时间演化相似,验证了模拟器在复现极端天气下人类行为的有效性,为优化灾害应对策略提供支持。

图 11 飓风冲击实验配置模板

图 12 飓风冲击下人流移动强度变化
五、未来展望
面向未来智能社会治理探索,AgentSociety 将成为人机共生、治理创新、后稀缺经济模式的试验场,测试 AI 议员参与立法对民主决策的影响,模拟 UBI 与机器人税组合政策,甚至在数字环境推演 AI 时代的法律与伦理框架,探讨科技与社会的共存模式。团队所提出的 AgentSociety 是一个基于大语言智能体的大型社会模拟器,正在从 “预测与解释工具” 逐渐进化为 “智能社会治理实验室”。其核心价值不仅在于分析社会现象,更在于构建一个实验平台,用于政策沙盒测试、危机预警和未来社会形态探索,助力社会治理与文明演化。

图 13 AgentSociety 未来展望
六、平台使用方法
AgentSociety 同时提供在线使用和离线运行两种智能体部署方式,欢迎智能社会治理同仁和社会科学研究人员关注使用。
1. 在线体验
目前平台正处于内测阶段(详见 https://agentsociety.readthedocs.io/en/latest/,https://agentsociety.fiblab.net/exp/1a4c4fa5-04c1-4973-9433-b8b696f2fda0)。研发团队诚挚欢迎来自社会科学、大模型、智能体等各个领域的学者尝试平台并提出宝贵建议和意见。平台提供易用的在线实验环境,包括智能体、城市社会环境、社会科学研究工具箱、完善的手册文档与实验案例以及在线指导。后续内部评测后,将提供在线使用模式。
用户可以通过邮箱 agentsociety.fiblab2025@gmail.com 提交研究提案。经过团队审核和讨论后,团队将通过邮件发送内测账号,协助您顺利完成实验。期待与大家共同探索和推动社会科学研究的前沿发展!
2. 离线运行
用户可以在官方网站 https://agentsociety.readthedocs.io/en/latest/ 下载离线版本,在本地部署后进行智能体的配置和实验,平台提供适用于 Linux、MacOS Arm 等不同类型操作系统的相应版本,方便模拟环境的快速部署和测试。
#DynamicCity
让城市「动」起来!DynamicCity突破4D大场景生成技术边界
过去一年,3D 生成技术迎来爆发式增长。在大场景生成领域,涌现出一批 “静态大场景生成” 工作,如 SemCity [1]、PDD [2]、XCube [3] 等。这些研究推动了 AI 利用扩散模型的强大学习能力来解构和创造物理世界的趋势。
尽管这些方法在生成复杂且稀疏的三维环境方面表现出色,现有技术仍面临一个核心挑战:在生成大型 3D 场景时,它们将环境视为静止的 “快照”—— 道路凝固、行人悬停、车辆静止不动。这种静态生成方式缺乏真实世界瞬息万变的交通流,难以反映复杂多变的交通场景,限制了实际应用。
那么,如何让生成的 3D 场景突破静态单帧的限制,真正捕捉动态世界的时空演化规律?
对此,上海人工智能实验室、卡耐基梅隆大学、新加坡国立大学和新加坡南洋理工大学团队提出DynamicCity,给出了突破性的解答。这项创新性工作以4D 到 2D 的特征降维为核心突破点,首次实现了高质量、高效的 4D 场景建模,并在生成质量、训练速度和内存消耗三大关键维度上取得跨越式进展。

DynamicCity已被 ICLR 2025 接收为Spotlight论文,项目主页和代码均已公开。
- 论文:https://arxiv.org/abs/2410.18084
- 主页:https://dynamic-city.github.io
- 代码:https://github.com/3DTopia/DynamicCity
引言
3D 大型场景生成技术旨在利用深度学习模型,如扩散模型,构建高保真、可扩展的场景。该技术有望为智能系统的训练与验证提供近乎无限的虚拟试验场。然而,现有方法大多还在探索静态场景的单帧生成(如 XCube [1]、PDD [2]、SemCity [3] 等),难以捕捉真实驾驶环境中交通流、行人运动等动态要素的时空演化规律。这种静态与动态的割裂,严重制约了生成场景在复杂任务中的应用价值。
主流的静态场景生成方法 [1, 2, 3] 主要依赖体素超分或 TriPlane 压缩,以实现大规模静态场景的高效生成,其本质仍是对单帧 3D 场景的 “快照式” 建模。尽管近期研究尝试将生成范围扩展至动态(如 OccSora [4], DOME [5]),4D 场景的复杂性 —— 包含数十个移动物体、百米级空间跨度及时序关联 —— 仍导致生成质量与效率的严重失衡。例如 OccSora 无法在大压缩率的情况保证较好的重建效果,以及扩散模型生成的结果也较为粗糙。
针对这一难题,上海人工智能实验室等提出DynamicCity—— 面向 4D 场景的生成框架。核心思想是,通过在潜空间显式建模场景的空间布局与动态变化,并借助扩散模型,直接生成高质量的动态场景。具体而言,DynamicCity 采用以下两步方法:1) 通过变分自编码器(Variational Autoencoder, VAE)将复杂的 4D 场景压缩为紧凑的 2D HexPlane [5][6] 特征表示,避免高维潜空间过于复杂导致生成模型难以学习;2) 采用 Padded Rollout Operation (PRO) 使潜空间捕捉到更多时空结构,帮助扩散模型(Diffusion Transformer, DiT [7])更好生成场景的空间结构与动态演化。
DynamicCity 的主要贡献如下:
1. 时空特征压缩:提出基于 Transformer 的投影模块(Projection Module),将 4D 点云序列压缩为六个 2D 特征平面(HexPlane),相较于传统平均池化方法,mIoU 提升 12.56%。结合 Expansion and Squeeze Strategy (ESS),在提升 7.05% 重建精度的同时,将内存消耗降低 70.84%。
2. 特征重组:提出 Padded Rollout 操作,将 HexPlane 特征重组为适配 DiT 框架的特征图,最大程度保留 HexPlane 结构化信息,帮助生成 DiT 更好的学习潜空间。
3. 可控生成:支持轨迹引导生成、指令驱动生成、4D 场景修改、布局条件生成等功能,并可轻松扩展至更多应用,实现更可控的生成。
DynamicCity:基于 HexPlane 的动态场景扩散模型

DynamicCity 采用HexPlane 表征和DiT构建了一个高效的4D 场景生成框架 。核心思想通过特征降维的方式,将 4D 场景映射到紧凑的 2D HexPlane,并在此基础上训练 DiT 进行场景生成。如图所示,DynamicCity 主要由以下两个核心模块构成:
1. 基于 HexPlane 表征的 VAE:利用投影模块 (HexPlane Projection Module),将 4D 场景压缩到六个互相正交的2D 特征平面,并通过 Expansion & Squeeze Strategy (ESS) 进行解码,以高效恢复原始时空信息。
2. 在重组 HexPlane 上训练的扩散模型:基于Padded Rollout Operation (PRO),对 HexPlane 进行结构化展开,并在此潜空间训练DiT进行采样,以生成新的 4D 动态场景。
DynamicCity 通过这两个核心模块,解决了现有 4D 生成模型重建效果和生成结果差的问题,提供了更紧凑的表征、更高效的训练、更高质量的动态场景合成。
基于 HexPlane 表征的 VAE

DynamicCity 使用 VAE 将 4D 点云转换为紧凑的 HexPlane 表征。一个 4D 场景被表示为时空体素数据

,其中

分别表示时间、空间维度,而

代表特征通道数。VAE 将 4D 数据进行降维成 HexPlane:

其中,下标表示每个平面保留的维度。

负责建模空间维度信息,

负责建模时空关联。这一映射成功将 4D 表达压缩至 2D 空间,使得后续的生成任务更高效。
投影模块(Projection Module)
为了高效获取 HexPlane,作者设计了投影模块 (Projection Module),用于将高维特征映射至 HexPlane。在通过共享 3D 卷积特征提取器提取初步的时空 4D 特征后,作者使用多个投影网络

,将 4D 特征投影到 2D 平面,每一个投影网络会压缩一个或两个维度。
投影模块由 7 个小型的投影网络组成,其中

首先进行时间维度压缩,而后三个小型网络分别提取空间特征平面

。而时空特征平面

则是通过三个小型网络直接从 4D 特征中提取得到。
Expansion & Squeeze Strategy (ESS) 解码
在动态 NeRF 等领域中,HexPlane 常用一个多层感知机(MLP)进行逐点解码。然而在 4D 场景中,点的数量非常多,导致模型速度慢,显存占用大。DynamicCity 提出 ESS 解码策略,用卷积神经网络代 MLP,减少显存占用,加速训练,同时显著提升重建效果。
首先,对每个 2D 特征平面进行扩展和重复,使其匹配 4D 体素特征;然后,利用 Hadamard 乘积进行信息融合:

最终,通过卷积解码器

生成完整 4D 语义场景。
在重组 HexPlane 上训练的扩散模型
在 VAE 编码器学习到 4D 场景的 HexPlane 表征之后,DynamicCity 使用 DiT在学习 HexPlane 空间的分布,并生成时空一致的动态场景。

HexPlane 的六个特征平面共享部分空间维度或时间维度。作者希望能够用一种简单有效的方式,在训练扩散模型时,六个平面并非互相独立,而是共享部分时空信息。Padded Rollout Operation (PRO)将六个特征平面排列成单个统一的 2D 矩阵,并在未对齐的区域填充零值,以最大程度地保留 HexPlane 的结构化信息 。
具体而言,PRO 将六个 2D 特征平面转换为一个方形特征矩阵,通过将空间维度和时间维度尽可能的对齐,PRO 能够最小化填充区域的大小,并确保空间与时间维度之间的信息一致性。
随后,Patch Embedding将该 2D 特征矩阵划分为小块,并将其转换为 token 序列。在训练过程中,作者为所有 token 添加位置嵌入,并将填充区域对应的 token排除在扩散过程之外,从而保证生成过程中时空信息的完整性。
可控生成与应用

为了让 HexPlane 生成过程具备可控性,作者引入 Classifier-Free Guidance (CFG)[8]机制,以支持不同条件约束下的场景生成。
对于任意输入条件,作者采用AdaLN-Zero技术来调整 DiT 模型内部的归一化参数,从而引导模型生成符合特定约束的场景。此外,对于图像条件 (Image-based Condition),作者额外添加跨模态注意力模块 (Cross-Attention Block),以增强 HexPlane 与外部视觉信息的交互能力。
通过 CFG 和 HexPlane Manipulation,DynamicCity 支持以下的应用,且可以轻松拓展到其他的条件:
1. HexPlane 续生成 (Long-term Prediction):通过自回归方式扩展 HexPlane,实现 4D 场景未来预测,长序列 4D 场景生成等任务。
2. 布局控制 (Layout-conditioned Generation):根据鸟瞰 (BEV) 视角语义图,生成符合交通布局的动态场景。
3. 车辆轨迹控制 (Trajectory-conditioned Generation):通过输入目标轨迹,引导场景中车辆的运动。
4. 自车运动控制 (Ego-motion Conditioned Generation):允许用户输入特定指令,引导自车在合成场景中的运动路径。
5. 4D 场景修改 (4D Scene Inpainting):通过掩膜 HexPlane 中的局部区域,并利用 DiT 进行局部补全,实现 4D 动态场景的高质量修复。
结果
下面展示了一些 DynamicCity 的结果,包括无条件生成的结果,布局控制生成结果等。
无条件生成(左:OccSora [4]; 右:DynamicCity)


长序列生成

布局控制生成


车辆轨迹 / 自车运动生成

4D 场景编辑


总结
DynamicCity 提出了基于 HexPlane 的 4D 场景扩散生成模型,通过 HexPlane 表征、Projection Module、Expansion & Squeeze Strategy、Padded Rollout Operation (PRO),以及Diffusion Transformer 扩散采样,实现了高效、可控且高质量的 4D 场景生成。此外,DynamicCity 还支持多种可控生成方式,并可应用于轨迹预测、布局控制、自车运动控制及场景修改等多个自动驾驶任务。
作者介绍
DynamicCity是上海人工智能实验室、卡耐基梅隆大学、新加坡国立大学和新加坡南洋理工大学团队的合作项目。
本文第一作者卞恒玮,系卡耐基梅隆大学硕士研究生,工作完成于其在上海人工智能实验室实习期间,通讯作者为上海人工智能实验室青年科学家潘亮博士。
其余作者分别为新加坡国立大学计算机系博士生孔令东,新加坡南洋理工大学谢浩哲博士、刘子纬教授,以及上海人工智能实验室乔宇教授。
#MoBA
撞车DeepSeek NSA,Kimi杨植麟署名的新注意力架构MoBA发布,代码也公开
昨天下午,DeepSeek 发布了一篇新论文,提出了一种改进版的注意力机制 NSA;加上还有创始人兼 CEO 梁文锋亲自参与,一时之间吸引眼球无数,参阅报道《刚刚!DeepSeek 梁文锋亲自挂名,公开新注意力架构 NSA》。
但其实就在同一天,月之暗面也发布了一篇主题类似的论文,并且同样巧合的是,月之暗面创始人兼 CEO 杨植麟也是该论文的署名作者之一。并且不同于 DeepSeek 只发布了一篇论文,月之暗面还发布了相关代码。且这些代码已有一年的实际部署验证,有效性和稳健性都有保证。
这篇论文提出了一种名为 MoBA 的注意力机制,即 Mixture of Block Attention,可以直译为「块注意力混合」。据介绍,MoBA 是「一种将混合专家(MoE)原理应用于注意力机制的创新方法。」该方法遵循「更少结构」原则,并不会引入预定义的偏见,而是让模型自主决定关注哪些位置。
- 论文标题:MoBA: Mixture of Block Attention for Long-Context LLMs
- 论文地址:https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
- 项目地址:https://github.com/MoonshotAI/MoBA
与 DeepSeek 的 NSA 注意力机制新论文一样,月之暗面这篇 MoBA 论文也收获了诸多好评。

下面我们就来解读一下这篇论文。
最近一段时间,大语言模型(LLM)发展到了前所未有的规模,我们希望它们能够处理模拟人类认知的复杂任务。具体来说,实现 AGI 的一个关键能力是处理、理解和生成长序列的能力,这对于从历史数据分析到复杂推理和决策过程的各种应用至关重要。这种对扩展上下文处理能力的需求不仅体现在长输入提示理解的普及上,还体现在最近 Kimi k1.5、DeepSeek-R1 和 OpenAI o1/o3 中展示的,对长链思维(CoT)输出能力的探索中。
然而,由于传统注意力机制带来的计算复杂度呈二次函数增长,扩展 LLM 的序列长度并非易事。这一挑战催生了一波研究浪潮,其中一个重要方向是利用注意力分数的固有稀疏性。这种稀疏性既源于数学上的 softmax 操作,也源于生物学上的观察,即人们已在与记忆存储相关的大脑区域中观察到了稀疏连接。
现有方法通常利用预定义的结构约束(例如基于 sink 的注意力机制或滑动窗口注意力机制)来利用这种稀疏性。虽然这些方法可能有效,但它们往往高度依赖于特定任务,可能会限制模型的整体泛化能力。另一种方法是采用动态稀疏注意力机制,例如 Quest、Minference 和 RetrievalAttention,这些方法在推理时选择部分 token 进行计算。尽管这些方法可以减少长序列的计算量,但它们并未显著缓解长上下文模型的高昂训练成本。
最近,线性注意力模型作为一种有前景的替代方案出现,例如 Mamba、RWKV 和 RetNet。这些方法用线性近似替代了传统的基于 softmax 的注意力机制,从而降低了长序列处理的计算开销。然而,由于线性注意力与传统注意力机制存在显著差异,适配现有的 Transformer 模型通常需要高昂的转换成本,或者需要从头开始训练全新的模型。更重要的是,它们在复杂推理任务中的有效性证据仍然有限。
因此,一个关键的研究问题随之而来:我们如何设计一种稳健且适应性强的注意力架构,既能保留原始 Transformer 框架,又能遵循「更少结构」的原则,使模型能够在不依赖预定义偏差的情况下自主决定关注哪些部分?理想情况下,这种架构能够在完全注意力和稀疏注意力模式之间无缝切换,从而最大限度地与现有预训练模型兼容,并在不牺牲性能的前提下实现高效推理和加速训练。
为此研究人员提出了块注意力混合机制(Mixture of Block Attention, MoBA),这是一种全新架构,它基于混合专家系统(MoE)的创新原理,并将其应用于 Transformer 模型的注意力机制中。MoE 此前主要应用于 Transformer 的前馈网络(FFN)层,而 MoBA 首次将其引入长上下文注意力机制中,允许动态选择与每个查询 token 相关的历史关键块和值块。这种方法不仅提高了 LLM 的效率,还使其能够处理更长、更复杂的提示,而无需按比例增加资源消耗。
相比之下,MoBA 通过将上下文划分为块并采用门控机制选择性地将查询 token 路由到最相关的块,解决了传统注意力机制的计算效率低下的问题。这种块稀疏注意力显著降低了计算成本,为更高效地处理长序列铺平了道路。模型能够动态选择最具信息量的关键块,从而提高了性能和效率,这对于涉及大量上下文信息的任务尤为有益。
在该工作中,月之暗面详细介绍了 MoBA 的架构,首先是其块划分和路由策略,其次是与传统注意力机制相比的计算效率。他们也进行了实验,证明了 MoBA 在处理长序列任务中的卓越性能。
MoBA:将 MoE 原理应用于注意力机制
MoBA 通过动态选择历史片段(块)进行注意力计算,扩展了 Transformer 模型的能力。
MoBA 的灵感来源于混合专家(Mixture of Experts,简称 MoE)技术和稀疏注意力技术。前者主要应用于 Transformer 架构中的前馈网络(Feedforward Network,简称 FFN)层,而后者已被广泛用于扩展 Transformer 以处理长文本上下文。
本文创新点在于月之暗面将 MoE 原理应用于注意力机制本身,从而实现对长序列更高效和更有效的处理。
MoBA 主要包括如下部分:
- 可训练的块稀疏注意力:将完整上下文分割成若干块,每个查询 token 都会学习关注最相关的 KV 块,从而实现长序列的高效处理。
- 无参数门控机制:引入了一种新颖的无参数 top-k 门控机制,为每个查询 token 选择最相关的块,确保模型只关注最具信息量的内容。
- 完全注意力与稀疏注意力的无缝切换:MoBA 被设计为完全注意力机制的灵活替代方案,能够在完全注意力和稀疏注意力模式之间实现平滑过渡。

总体而言,MoBA 注意力机制使模型能够自适应且动态地关注上下文中最有信息量的块。这在处理涉及长文档或序列的任务时尤其有益,因为在这些任务中,关注整个上下文可能是不必要的,并且计算代价高昂。MoBA 选择性地关注相关块的能力,使得信息处理更加细致且高效。
月之暗面通过整合来自 FlashAttention 和 MoE 的优化技术,实现了 MoBA 的高性能版本。图 2 展示了 MoBA 的高效率。

MoBA 实现过程包含五个步骤:
- 根据门控网络和因果掩码,确定查询 token 对 KV 块的分配。
- 根据分配的 KV 块,安排查询 token 的顺序。
- 计算每个 KV 块的注意力输出和分配给它的查询 token,这一步可以通过不同长度的 FlashAttention 来优化。
- 将注意力输出重新排列回其原始顺序。
- 使用在线 Softmax 合并相应的注意力输出,因为一个查询 token 可能会关注其当前块以及多个历史 KV 块。
下图为该算法的形式化描述,并在图 1b 中进行了可视化,展示了如何基于 MoE 和 FlashAttention 实现 MoBA。

MoBA 的实验表现
为了验证 MoBA 的实际效果,月之暗面进行了一系列 Scaling Law 和消融实验。
Full Attention 与 MoBA 对比实验
该团队训练了 5 个模型来进行比较,表 1 给出详细配置。

结果见图 3a,可以看到,Full Attention 与 MoBA 的 scaling 趋势非常相似。具体来说,这两种注意力机制之间的验证损失差异在 1e − 3 的范围内保持一致。这表明,尽管 MoBA 的稀疏注意力模式稀疏度高达 75%,但它实现了与完全注意力相当的扩展性能。

此外,该团队也验证了 MoBA 的上下文可扩展性。在实验中,该团队将最大序列长度从 8k 提升到了 32k。结果见图 3b,可见尽管在所有五项实验中,MoBA 最后的块 LM 损失与 Full Attention 相比略高,但损失差距正在逐步缩小。该实验表明 MoBA 具有长上下文可扩展性。
该团队也通过消融实验对 MoBA 的细粒度块分割的有效性进行了验证,结果见图 4。

可以看到,MoBA 的性能受块粒度的显著影响。具体来说,最粗粒度设置(从 8 个块中选择 2 个块)与更细粒度的设置之间的性能差异为 1e-2。这些发现表明,细粒度分割似乎是增强 MoE 系列(包括 MoBA)模型性能的普适技术。
将 MoBA 与 Full Attention 融合到一起会如何?
MoBA 本就是作为 Full Attention 的灵活替代而设计的,可以最小的开销轻松地互相切换,并实现相当的长上下文性能。月之暗面实验表明,Full Attention 和 MoBA 之间的无缝过渡可以成为高效长上下文预训练的解决方案。然后他们还讨论了分层混合策略,其作用主要是提升监督微调(SFT)的性能。
在实验中的混合训练时,模型使用的是两阶段方案:第一阶段使用 MoBA 完成 90% 的 token 训练,第二阶段模型切换到 Full Attention 使用剩余 10% 的 token 进行训练。另外,当然也使用了纯 MoBA 和纯 Full Attention 方法作为对比。
结果见图 5a,仅使用 MoBA 时会导致 trailing token 的位置损失更高。重要的是,混合方案的损失几乎与 Full Attention 一样。这一结果凸显了混合训练方案在平衡训练效率和模型性能方面的有效性。更有趣的是,在 MoBA 和 Full Attention 之间切换时没有观察到明显的损失峰值,这再次证明了 MoBA 的灵活性和稳健性。

月之暗面也研究了分层混合的方案。这种方案当然更加复杂,研究动机是他们观察到 MoBA 有时会导致 SFT 期间的性能不佳,如图 5b 所示。
他们推测这可能归因于 SFT 中使用的损失掩蔽(loss masking)—— 提示词 token 通常被排除在 SFT 期间的损失计算之外,这可能会对 MoBA 等稀疏注意力方法造成稀疏梯度难题。因为它可能会阻碍梯度的反向传播,而这些梯度最初是根据未掩蔽的 token 计算出来的,并贯穿整个上下文。
为了解决这个问题,他们提出了另一种混合方法 —— 将最后几层 Transformer 从 MoBA 换成 Full Attention,而其余层继续采用 MoBA。如图 5b 和图 5c 所示,此策略可以显著减少 SFT 损失。
大语言模型评估
研究团队基于 Llama 3.1 8B 模型开发了 Llama-8B1M-MoBA,通过持续预训练将上下文长度从 128K 逐步扩展到 1M token。模型采用块大小 4096 和 top-K 参数 12 的设置,实现了高达 95.31% 的注意力稀疏度。为平衡性能,他们保留最后三层为 Full Attention,其余 29 层使用 MoBA。

评估结果显示,MoBA 模型与 Full Attention 模型(Llama-8B-1M-Full)性能相当。特别是在最具挑战性的 RULER 基准测试中,即使在 62.5% 的稀疏度下,MoBA 模型仍达到了 0.7818 的得分,几乎与 Full Attention 模型的 0.7849 持平。对于需要处理 100 万 token 的「大海捞针」测试集中,模型同样展现出优秀的能力。

效率和可扩展性
实验证明,MoBA 在保持性能的同时显著提升了效率:在处理 1M token 时,比 Full Attention 模型快 6.5 倍。在扩展到 1000 万 token 时,较标准 Flash Attention 实现了 16 倍加速;通过块稀疏注意力机制和优化实现,MoBA 将计算复杂度从二次方降低到了亚二次方级别。
这使得 MoBA 的优势在序列长度增加时更为明显,特别适合处理超长文本场景。
参考链接:
https://github.com/MoonshotAI/MoBA/blob/master/MoBA_Tech_Report.pdf
#从Deepseek R1和NSA算法谈谈个人的一些反思
先谈一个测验Reasoning模型的题目
最近某个群里面有一道考验大模型能力数学题, 感觉这个题比9.9和9.11谁大更考验Reasoning模型, 似乎很多大模型的答案都做的不好. DeepSeek-R1能做对,但是整个思考过程非常长, 大家可以自己试试.
给如下等式添加括号,可以加多个括号,使得等式成立:8 + 28 / 4 -2 * 3 = 6
正确的答案是(8+28)/((4-2)x3), 因为后一项的两层括号嵌套增加了模型的搜索难度. 如果更严格一点的考验是:
给如下等式添加括号,可以加多个括号,使得等式成立:8 + 28 / 4 -2 * 3 = 7
可能对于搜索算法而言存在一个停时问题, 可以产生一个对大模型产生一个超级长context输出的攻击, 例如我就专门构造这样的数据, 多层括号嵌套才能得出答案, 或者根本没有答案的不同的数值去攻击, 会导致模型大量的资源用于Decode, 我不确定是否会导致Expert负载的极端偏斜,从而引发后台调度系统的弹性扩容?
其实我们在通往AGI的路上还有很多的路走, 还有很多踏踏实实的工作要去做.
谈谈关于DeepSeek R1和NSA算法的反思
最近一段时间复现了一下R1的算法, 训练了一个渣-7B-R1, 似乎能做对一点题目了.

然后针对中文和英文的数据集做了一些测试, 数据集导致的reward方差还是挺有趣的一个话题.

在这个过程中, 伴随着昨天发布的Native Sparse Attention(NSA)有了太多的感触. 从算法的角度, 我一开始就不太相信一个的算法上会有ScalingLaw, 在2023年的时候, 就写过一篇文章《大模型时代的数学基础(1)》 探讨Transformer模型结构的优化,特别是算力约束下, 引用当时的一段文字:
现阶段国内大量的模型都还在仿制的基础上进行一些微小的创新,例如Tokenizer算法的选择上用BPE,或者位置编码上采用RoPE或者ALiBi,激活函数上SwiGlU等,归一化层上的位置,RMSNorm实现等,这些在模型的根本结构上没有太多的变化。
那么一个命题作文:在短期算力受约束,只能使用L20/H20后,如何降低每参数的训练FLOPS开销?如何能够通过模型网络结构的修改能获得在算力受限时的线性扩展能力?
当然FP8/Log8 Quantization是一条路,而另一条路是在模型结构上,MoE该如何做的问题,此时还有一个更诛心的问题出来了,国内也有把模型规模扩展到万亿级别的,但是为什么还没有达到GPT-4的能力?这个问题会从范畴论的视角来阐述的,当然还有更多的问题:
训练数据集质量对大模型的直接影响是什么?MoE的网络结构要求是什么,Sparse Transformer和一些window attention为什么没有太大的作用,Prompt和ICL为什么作用有限,RLHF为何有一个代价叫对齐税,CoT一类的东西背后的数学原理是什么,如何对大模型推理能力增强,如何通过模型的结构来约束降低幻觉,如何从理论上证明FP8并控制模型在低精度下依旧能够保证训练收敛?
最终由这些问题解决的答案推出一个模型网络结构,再有针对性的设计AI infra,这才是我们最迫切需要的东西,可惜国内各个团队除了做一点微小的模型改动,没见到有任何一个团队有系统性的思考。
里面谈到了FP8, MoE 这些DeepSeek-V2/V3的优化策略, 也谈到了sparse transformer为什么不行, 也谈到了CoT一类的Reasoning的问题, 以及国内厂家都在做一些微小的创新等等一系列问题. 而最近发布的DeepSeek NSA和Kimi MoBA进一步加重了对过去两年工作的反思, (顺便调侃一下为啥每次Kimi都和DeepSeek撞车呢? R1和Kimi K1.5也是...)
对于NSA和MoBA,其实渣B也想到了, 在《谈谈大模型架构的演进之路, The Art of memory.》也谈到过这样一段话:
诚然, 我们在做很多尝试, 通过KV Head的构造来修改Attention block降低训练和推理时的内存开销. 但是很多压缩到Latent Space本身就是有损的, 所以这也是我一开始就在怀疑DeepSeek MLA的作用(当然这些担忧现在看起来是没有意义了).
这些工作实质是在一个固定的物理内存上进行处理, 放不下的时候, 去压缩数据结构. 再加上《Space-time tradeoffs of lenses and optics via higher category theory 》这篇文章通过高阶范畴中的一些关于Optics和Lens的时空折中描述, 也是一个很值得去分析的东西.
但是从计算机体系架构的视角, 我们真的需要把所有的Context都在内存里放着, 供Attention这样的Control Unit全量去访问么? 其实一个真正的Attention应该在这个基础上引入页表的机制. 就像我们读书或者读论文, 某一段某一章节引用另一章节. 整个计算引擎只需要它程序指向的那几个页表.
基于这个思路, 我们就可以构造一个虚拟内存空间, 将真正所需要的那些页来进行Attention计算. MoE或许就是一个最早期的页表内存的实现. 而前段时间提出的MoE Group本质上就是想要把它扩展成一个多级页表.
但是现在的反思就是, 为什么就差那么几步就能点破了呢? 过去的两年多, 因为工作职责的原因, 大概只能偶尔申请几台机器在本质工作做完了的基础上做点小实验, 主要工作还是在一些和Infra相关的ScaleUP/ScaleOut总线相关的研究上. 没有算力的支持下, 把更多的精力投入到了一些高阶范畴/代数几何相关的算法研究上, 少了很多实验的机会.
但事实上这条路对不对? 某种意义上是对的, 例如对于R1的训练上, 在2023年的《大模型时代的数学基础(2)》中提到了一段, 指向了通过代数构造的ORM based RL.
例如在降低Transformer的计算量时,稀疏Transformer或者MoE是否会破坏态射结构? Transformer算子的可组合性如何设计?通过这样顶层的抽象视角会得出不少有价值的答案。当然还有很多范畴论的内容,例如limit/colimit,以及相应约束下的强化学习和基于Hom函子去构造数据,最终来提高大模型的逻辑推理能力,范畴论视角下函数式编程和大模型的融合,这些都是非常值得我们去深思的问题,或许这也部分回答了OpenAI Q* 的一些解法,我们拭目以待...
但是渣B很多时候还是欠点火候, 前段时间还被家里老阿姨PUA了一下, “人家搞量化私募的,你也搞, 人家有OIer你也是, 为啥做的不好呢?", 有一些反思是作为一个老的MLer, 还是有些特征工程的视角, 并不如新一代的DLer那么纯粹. 有些过往GNN的成功经验把自己的路走偏了, 特别是前段时间用LLM生成论文的Abstraction时就有了要用Compression Attention去做索引的想法, 但是确实是能力不够, 把问题想复杂了, 要去构造代数结构, 尝试用GNN去约束, 没有DeepSeek那么直接的一个Token Compression上的MLP训练顺便用Attention Score去做Token Selection的想法. 然后RL算法上也是想着代数结构的构造, 而少了几分DeepSeek那种端到端的纯粹.
其实你去看看DeepSeek的论文, 解决问题的方法特别优雅, 又有大量长期主义的特点, 又富有理想主义的浪漫, 他们的研究品味高出国内厂商一大截. 当看到DeepSeek-MoE的论文的时候, 就觉得这家公司路走对了, 再看到DeepSeek-V2的MLA时,就坚信这家公司能做出一番大事业来. 毕竟在国内清一色的Llama系跟随的路上, 有那么一家公司直接对Transformer结构动刀, 勇气上就胜出一大截了.
作为一个RLer, 仔细来看, DeepSeek的长期主义路线是非常明确的. MLA/MoE/NSA其实只是RL路上优化计算复杂度的手段, 包括GRPO本身也是在计算效率上的极致优化.
谈谈未来大模型的基础研究
其实有一个问题, 为什么DeepSeek的很多创新没有发生在一些大厂呢? 倒是大厂为了抢算力还有在训练模型的集群投毒的事情. 归根结底还是一个绩效机制的问题, 组和组之间的内卷导致的. 人生活在绩效的不安全感里, 势必会做一些非常规的动作,这是人性. 所以大厂可能更多的是一些微小的创新, 例如NSA这样的东西, 如果训练1~3个月失败了,后面还有没有训练资源, 再往后的绩效如何? 不安下的巨大创新是几乎不可能发生的. 另一方面是大厂的组织结构和部门墙的厚度决定了协同效率的差异. 当然还有更重要的一点, 老板的定力和眼界也决定了整个机构的研究天花板, 例如NSA的论文有梁总的直接参与, 老板是否有更加全面的知识面直接影响到研究路线. 还有一个问题来自于大厂选择的标准几乎都是看发了多少论文, 做成了多少事情,把过去的经历看的比能力本身重要太多. 而为什么梁老板更倾向于找一些年轻人? 年轻人更能够承担失败的代价, 更少的被过去的经验束缚, 再加上一个更宽松的绩效机制和更紧密的全栈融合的小团队, 以及更远大的理想和目标, 没有融资的压力,自然会比其他大厂少了很多经营上的烦恼.
抛弃这些, 很多时候打铁还需自身硬, 大模型本身还有大量的基础研究工作要去做:
FP4或者Log8下的大模型训练该如何做, 量化的方式如何, 如何通过这些在GPU微架构上的调整.
接着第一个问题, FP8在这一代生命周期偏中后期了才用起来FP8, 以及FlashAttention和TK才逐渐用起来TMA, 问题在哪? FP4的研究要尽早.
优化器是否也是一个可以去静下心来研究的?
MoE的细粒度程度估计, 算力/内存带宽/网络带宽三者之间的平衡, 特别是如何利用Infra的一些细微的改动提升访存效率, 例如2级Gating? 例如文章《谈谈DeepSeek MoE模型优化和未来演进以及字节Ultra-Sparse Memory相关的工作》所述.
softmax函数在训练时, 温度是否可以构成一个可训练的参数?
训练参数本身在非线性空间下的一些约束是否能加速训练? 例如Nvidia的Hypersphere?
ORM based RL中, 如何构造数据集更多的从代数结构上约束?
模型结构本身的深度, 例如60层 vs 128层, 是否可以用预测Next Few Token然后作为Context后影响计算来对模型深度折中?
如何进一步降低对ScaleUP网络的依赖, 甚至构建异构加速器的训练场景? 进一步把国产加速器用在训练上.
计算机体系结构的视角去理解大模型, 例如DeepSeek CodeI/O相关的工作和《谈谈大模型架构的演进之路, The Art of memory.》谈到的一些内容.
一些数学基础的研究还是必须的, 例如草稿箱里一直还有一篇未写完的文章

当然还有许许多多基础的工作都还没有列出来, 特别是一些涉及Infra相关的工作, 因为涉密无法多说.
这次个人的反思, 更重要的一点是,忘记人本身的经验, 当你一心一意想用人的经验去构建一个AGI/ASI时,必定不会成功. 做一个更纯粹的RLer, Let it learn, don't teach, keep it simple.
#Grok3 把 o3 干翻了
马斯克大力出奇迹
大模型盲测榜单 LYSYS Arena 有史以来首先打破 1400 分,在所有类别中排名#1
就在刚刚,马斯克发布了 xAI 最新的模型:Grok-3 和 Grok-3 推理版!
现在 X 官网上开会员已经可以直接体验,网页和应用的所有功能会在一周内完善、API 会在几周内推出。
什么模型才让马斯克敢说是“地球上最聪明的 AI?
简单粗暴给大家汇总一下目前的信息:
- Grok 3 表现超越 DeepSeek R1、GPT-o1、Gemini 2 Pro、GPT-4o、Claude 3.5
- 大模型盲测榜单 LYSYS Arena 有史以来首先打破 1400 分,在所有类别中排名#1
- 带推理 Reasoning
- 带 DeepSearch 深度搜索
首先,Grok3 比 Grok2 多了十倍的计算量,而且是和 o1 一样的 Reasoning 模型。
评测结果
Grok-3 早期化名'chocolate'在 LMSYS 上开启盲测,排名第一,得分 1402,并且在所有类别中排名第一。
这次发布,马斯克还一起祭出了两个推理模型:Grok-3 Reasoning Beta 和 Grok-3 mini Reasoning 。
看官方放出来的评测图,我震惊了。在 AIME'24,GPQA,LCB Oct-Feb 以及前几天最新发布的 AIME'25 基本都是碾压级的?!
包括最强选手和最热推理选手 o3 mini high 、Deepseek r1、 gemini2-flash-thinking 以及 o1。
Big Brain 选项
同时,Grok-3 还支持开启 Big Brain 选项,这会让 Grok3 花费更多的计算和推理时间来思考从而解决难题:
直播中还专门提到,Grok-3 在创意编程方面能力也很强。
比如,让他开启 Big Brain 选项后,生成一个结合《俄罗斯方块》和《宝石迷阵》的游戏,代码执行起来 是能正常运行的。
,时长00:33
DeepSearch 功能
Grok-3 同时也发布了 DeepSearch 功能。可以看到和 OpenAI 的 deep research 类似,它具备以下能力:
- 深入思考用户意图。
- 考虑应该选择哪些事实。
- 应该浏览多少个网站。
- 交叉验证不同的来源。
DeepSearch 还展示了其进行搜索本身所采取的步骤。
马斯克对此评价为:"Next generation of search agents to understand the universe"(新一代可以理解宇宙的搜索引擎)
Andrej Karpathy:Grok3 处于和 o1 Pro 相当的水平
对于模型的实际能力,Andrej Karpathy 刚刚也发推表示:
“就今天上午大约两个小时的快速测试来看,Grok 3 开启 Reasoning 思考能力感觉处于 OpenAI 最强模型(o1-pro,每月 200 美元)的最先进领域附近,并且略优于 DeepSeek-R1 和 Gemini 2.0 Flash Thinking。”
网友测评 case
收集了一些手速快的网友们的 case,看看表现咋样。
制作一个 P5.JS 素描,一堆 Groks 在一个旋转的脉动球体中弹跳。
,时长00:28
还有一个推理的 case 测试——
超长预警!
Grok3 的使用方式
X.com 上的 Permium+ 会员可以直接使用 Gork3,网页版稍后就可以使用。
同时,SuperGrok 专属 APP 也将发布,拥有以下特权:
- 保证访问 Grok 3 的权限
- 解锁 DeepSearch 和 Think 功能
- 抢先体验新功能
- 更高的图像生成限制
在 Q&A 环节,他们表示将在几个月后对 Grok-2 进行开源,因为只有发布新一代模型之后,才会开源上一代的模型。
最后,Grok-3 还放出了一个语音模式彩蛋,我们是否可以期待马斯克版的贾维斯面世呢(狗头)
,时长00:12
#DeepSeek R1、Kimi k1.5发现o1的秘密
强化学习确实可显著提高LLM性能
最近,OpenAI 发了一篇论文,宣称 o3 模型在 2024 IOI 上达到了金牌水平,并且在 CodeForces 上获得了与精英级人类相当的得分。
他们是怎么做到的呢?OpenAI 在论文开篇就用一句话进行了总结:「将强化学习应用于大型语言模型(LLM)可显著提高在复杂编程和推理任务上的性能。」
- 论文标题:Competitive Programming with Large Reasoning Models
- 论文地址:https://arxiv.org/pdf/2502.06807
这两天,这篇论文又引起了广泛热议,尤其是其中被博主 Matthew Berman 指出的关键:这种策略不仅适用于编程,它还是通往 AGI 及更远未来的最清晰路径。

也就是说,这篇论文不仅仅是展示了 AI 编程的新成绩,更是给出了一份创造世界最佳 AI 程序员乃至 AGI 的蓝图。正如 OpenAI 在论文中写到的那样:「这些结果表明,扩展通用强化学习,而不是依赖特定领域的技术,能为在推理领域(例如竞技编程)实现 SOTA AI 提供一条稳健的路径。」
此外,这篇论文还特别提到,中国的 DeepSeek-R1 和 Kimi k1.5 通过独立研究显示,利用思维链(CoT)学习方法可显著提升模型在数学解题与编程挑战中的综合表现,这也是 o1 此前没有公开过的「配方」—— 直到前些天才半遮半掩地揭示一些,参阅报道《感谢 DeepSeek,ChatGPT 开始公开 o3 思维链,但不完整》。(1 月 20 日,DeepSeek 和 Kimi 在同一天发布推理模型 R1 和 k1.5,两个模型均有超越 OpenAI o1 的表现。)

下面,我们先看看这篇论文的核心内容,然后再看看 Matthew Berman 为什么说扩展通用强化学习是「通往 AGI 及更远未来的最清晰路径」。
OpenAI 从自家的三个模型入手,这三个模型分别是 o1 、 o1-ioi 以及 o3。
OpenAI o1 :
在竞争性编程任务上的性能大幅提升
o1 是一个通过强化学习训练的大型语言模型,旨在解决复杂的推理任务。
在回答问题之前,o1 会先生成一个内部思维链,并且用强化学习完善这种思维链过程,帮助模型识别和纠正错误,将复杂任务分解为可管理的部分,并在一种方法失败时探索替代的解决方案路径。这些上下文推理能力显著提升了 o1 在广泛任务上的整体表现。
Kimi 研究员 Flood Sung 也谈到了推理模型 Kimi k1.5 的研发过程也有类似的发现,他指出:「长思维链的有效性曾在 Kimi 内部得到验证,使用很小的模型,训练模型做几十位的加减乘除运算,将细粒度的运算过程合成出来变成很长的 CoT 数据做 SFT,就可以获得非常好的效果。」他说,「依然记得当时看到那个效果的震撼。」
除此之外,o1 还可调用外部工具验证代码。
不同模型在 CodeForces 基准上的表现。
OpenAI 将 o1 与非推理型大语言模型(gpt-4o)以及早期的推理模型(o1-preview)进行了对比。
图 1 展示了 o1-preview 和 o1 都显著优于 gpt-4o,这凸显了强化学习在复杂推理任务中的有效性。
o1-preview 模型在 CodeForces 上的评分达到了 1258 分,相比 gpt-4o 的 808 分有了显著提升。进一步的训练将 o1 的评分提升至 1673,为 AI 在竞争性编程中的表现树立了新的里程碑。

OpenAI o1-ioi:
增加强化学习和测试时推理就能带来大幅提升
OpenAI 在开发和评估 OpenAI o1 的过程中,他们发现增加 RL 计算量和测试时推理计算量都能持续提升模型性能。
如图 2 所示,扩展 RL 训练和延长测试时推理可以显著提升模型性能。基于这些洞见,OpenAI 创建了 o1-ioi 系统。

他们从以下方面来实现。
第一步是扩展 OpenAI o1 的强化学习阶段,重点关注编码任务。具体如下:
- 从 OpenAI o1 检查点开始继续强化学习训练;
- 特别强调了具有挑战性的编程问题,帮助模型改进 C++ 生成和运行时检查。
- 指导模型以 IOI 提交格式生成输出。
在高层次上,OpenAI 将每个 IOI 问题分解为子任务,并为每个子任务从 o1-ioi 中采样了 10,000 个解决方案,然后采用基于聚类和重新排名的方法来决定从这些解决方案中提交哪些。
图 3 显示,o1-ioi 的 CodeForces 评分达到 1807,超过 93% 的竞争对手 —— 这证明了在编码任务上进行额外的 RL 训练可以带来明显的改进。
这些结果证实,特定领域的 RL 微调与高级选择启发式相结合可以显著提高编程结果。

图 4 为 IOI 比赛结果。在比赛期间,系统为每道问题生成了 10,000 个候选解决方案,并使用测试时选择策略从中筛选出 50 次提交。最终,模型获得了 213 分,排名位于前 49 % 。

OpenAI o3:
无需人类的强化学习效果卓越
基于从 o1 和 o1-ioi 获得的洞见,OpenAI 又探索了仅依赖强化学习(RL)结果如何,而不依赖于人为设计的测试时策略。
甚至 OpenAI 试图探索进一步的 RL 训练,模型是否能够自主开发和执行自己的测试时推理策略。
为此,OpenAI 使用了 o3 的早期检查点,以评估其在竞技编程任务上的表现。
如图 5 所示,进一步的强化学习(RL)训练显著提升了 o1 和完整 o1-ioi 系统的表现。o3 能够以更高的可靠性解决更广泛的复杂算法问题,使其能力更接近 CodeForces 上的顶级人类程序员。

图 7 为模型在 IOI 2024 上的最终得分。2024 年比赛的总分上限为 600 分,金牌的分数线约为 360 分。
以下是关键结果:
o1-ioi 在 50 次提交的限制下获得了 213 分,而在 10,000 次提交的限制下提升至 362.14 分,略高于金牌分数线。
o3 在 50 次提交的限制下获得了 395.64 分,超过了金牌分数线。
这些结果表明,o3 在不依赖针对 IOI 手工设计的测试时策略的情况下,表现优于 o1-ioi。相反,o3 在训练过程中自然涌现的复杂测试时技术(例如生成暴力解法以验证输出)足以替代 o1-ioi 所需的手工设计的聚类和选择流程。
总体而言,在 IOI 2024 上的结果证实,仅通过大规模强化学习训练即可实现最先进的编程和推理性能。通过独立学习生成、评估和优化解决方案,o3 超越了 o1-ioi,而无需依赖领域特定的启发式方法或基于聚类的方法。

另外,在 CodeForces 上,如前图 5 所示,o3 的成绩达到了 2724 分,已经进入了全球前 200 名。

该论文的作者之一 Ahmed El-Kishky 在 𝕏 上分享了一个有趣的发现。他表示,他们在检查思维链时发现该模型独立发展出了自己的测试时策略:该模型首先会编写一个简单的暴力解决方案,然后再使用它来验证一种更加复杂优化版方法。

软件工程评估
OpenAI 还对模型进行了软件工程评估。他们在两个数据集上测试了模型:HackerRank Astra 数据集和 SWE-bench verified。
图 8 表明了模型进行思维链推理的影响:与 GPT-4o 相比,o1-preview 模型在 pass@1 上提升了 9.98%,在平均得分上提高了 6.03 分。
通过强化学习进一步微调后,o1 的表现得到了提升,其 pass@1 达到了 63.92%,平均得分为 75.80%—— 相比 o1-preview,pass@1 提高了 3.03%。

图 9 所示,o1 预览版在 SWE-bench 上相比 gpt-4o 提升了 8.1%,突显了模型推理能力的显著进步。
在训练过程中应用额外的强化学习计算,o1 进一步实现了 8.6% 的性能提升。
值得注意的是,o3 使用了比 o1 显著更多的计算资源进行训练,比 o1 实现了 22.8% 的显著改进。

通用强化学习是实现 AGI 的最清晰路径?
基于此论文,Matthew Berman 通过一系列推文佐证了一个论点:通用强化学习是实现 AGI 的最清晰路径。下面我们来看看他的论据。
首先,在这篇论文中,OpenAI 的研究表明「强化学习 + 测试时计算」是构建超智能 AI 的关键。OpenAI CEO Sam Altman 也说 OpenAI 的模型已经在竞争性编程任务上从 175 名上升到了 50 名,并有望在今年底达到第 1 名。
,时长00:42
视频来自 𝕏 @tsarnick
同时,上述论文中也指出,一开始模型依赖于人类设计的推理策略,但进步最大时候并不是在这个阶段出现的,而是在将人类完全移出流程之后。

Berman 也引出了 DeepSeek-R1 的巨大成就。

他指出,DeepSeek-R1 的突破来自于「可验证奖励的强化学习」,而这其实也是 AlphaGo 使用的方法 —— 让模型在试错中学习,然后无限地扩展智能。
AlphaGo 在没有人类引导的情况下成为了世界最强围棋棋手。它的方法就是不断与自己博弈,直到其掌握这个游戏。

Kimi 研究员 Flood Sung 也谈到了这一点,他指出:「不管模型中间做错了什么,只要不是重复的,最后模型做对了就认为这是一个好的探索,值得鼓励。反之,要惩罚。随后在实际训练中,发现模型会随着训练提升表现并不断增加 token 数,证明强化训练过程中模型可以自己涌现,这与 DeepSeek 的发现非常相似,也为 k1.5 视觉思考模型的上线奠定了基础。」
而现在,类似的策略也被 OpenAI 用在了编程领域,并且未来也可能被用在更多领域。
这意味着什么呢?Berman 认为,这意味着每个具有可验证奖励的领域(包括数学、编程、科学)都可被 AI 通过自我博弈方法掌握。
Flood Sung 也表达了类似的期待:「o3 在前面,还有很多路要走。给 AI 一个可衡量的目标,然后让其自己去探索。比如让 AI 写出 10 万 + 的公众号文章,比如让 AI 发布一个复制 tiktok 的 app,让我们一起期待一下接下来的进展!」
届时,AI 将不再受到人类水平的限制。这或许也就是 AGI 诞生之时。
实际上,特斯拉已经在全自动驾驶任务上验证这一点了。过去,他们的方法是依靠一个「人类规则 + AI」的混合模型;但他们换成端到端的 AI 方法之后,性能实现了大幅提升。Berman 表示:「AI 只需要更多计算 —— 而不是更多人类干预。」
,时长04:11
正如 Sam Altman 之前说过的那样,AGI 就是个规模扩展问题。
实际上,已经有不少研究者将强化学习用在编程和数学等领域之外了。

当然,并不是所有人都认可 Berman 与 Altman 的看法,比如有人指出了竞争性编程与实际编程的区别 —— 实际编程往往涉及到更多问题,包括可扩展性、安全性、弹性和投资回报等。

也有人直言反驳:

你已经看过这篇论文了吗?对于「可验证奖励的强化学习」的未来潜力,你有什么看法?你认为这能否实现 AGI?
#LIMR
大模型强化学习新发现:删减84%数据反提升效果
在人工智能领域,"更大即更强" 的理念一直主导着大模型强化学习的发展方向。特别是在提升大语言模型的推理能力方面,业界普遍认为需要海量的强化学习训练数据才能获得突破。然而,最新研究却给出了一个令人惊喜的发现:在强化学习训练中,数据的学习影响力远比数量重要。通过分析模型的学习轨迹,研究发现精心选择的 1,389 个高影响力样本,就能超越完整的 8,523 个样本数据集的效果。这一发现不仅挑战了传统认知,更揭示了一个关键事实:提升强化学习效果的关键,在于找到与模型学习历程高度匹配的训练数据。
- 论文标题:LIMR: Less is More for RL Scaling
- 论文地址:https://arxiv.org/pdf/2502.11886
- 代码地址:https://github.com/GAIR-NLP/LIMR
- 数据集地址:https://huggingface.co/datasets/GAIR/LIMR
- 模型地址:https://huggingface.co/GAIR/LIMR
一、挑战传统:重新思考强化学习的数据策略
近期,强化学习在提升大语言模型的推理能力方面取得了显著成效。从 OpenAI 的 o1 到 Deepseek R1,再到 Kimi1.5,这些模型都展示了强化学习在培养模型的自我验证、反思和扩展思维链等复杂推理行为方面的巨大潜力。这些成功案例似乎在暗示:要获得更强的推理能力,就需要更多的强化学习训练数据。
然而,这些开创性工作留下了一个关键问题:到底需要多少训练数据才能有效提升模型的推理能力?目前的研究从 8000 到 150000 数据量不等,却没有一个明确的答案。更重要的是,这种数据规模的不透明性带来了两个根本性挑战:
- 研究团队只能依靠反复试错来确定数据量,这导致了大量计算资源的浪费
- 领域内缺乏对样本数量如何影响模型性能的系统性分析,使得难以做出合理的资源分配决策
这种情况促使研究团队提出一个更本质的问题:是否存在一种方法,能够识别出真正对模型学习有帮助的训练数据?研究从一个基础场景开始探索:直接从基座模型出发,不借助任何数据蒸馏(类似 Deepseek R1-zero 的设置)。通过深入研究模型在强化学习过程中的学习轨迹,研究发现:并非所有训练数据都对模型的进步贡献相同。有些数据能够显著推动模型的学习,而有些则几乎没有影响。
这一发现促使研究团队开发了学习影响力度量(Learning Impact Measurement, LIM)方法。通过分析模型的学习曲线,LIM 可以自动识别那些与模型学习进程高度匹配的 "黄金样本"。实验结果证明了这一方法的有效性:
- 精选的 1,389 个样本就能达到甚至超越使用 8,523 个样本的效果。

精选 1,389 个样本就能达到全量数据的效果,在小模型上强化学习优于监督微调
这些发现更新了学术界对强化学习扩展的认知:提升模型性能的关键不在于简单地增加数据量,而在于如何找到那些真正能促进模型学习的高质量样本。更重要的是,这项研究提供了一种自动化的方法来识别这些样本,使得高效的强化学习训练成为可能。
二、寻找 "黄金" 样本:数据的学习影响力测量(LIM)
要找到真正有价值的训练样本,研究团队深入分析了模型在强化学习过程中的学习动态。通过对 MATH-FULL 数据集(包含 8,523 个不同难度级别的数学问题)的分析,研究者发现了一个有趣的现象:不同的训练样本对模型学习的贡献存在显著差异。
学习轨迹的差异性
在仔细观察模型训练过程中的表现时,研究者发现了三种典型的学习模式:
- 部分样本的奖励值始终接近零,表明模型对这些问题始终难以掌握
- 某些样本能迅速达到高奖励值,显示模型很快就掌握了解决方法
- 最有趣的是那些展现出动态学习进展的样本,它们的奖励值呈现不同的提升速率
这一发现引发了一个关键思考:如果能够找到那些最匹配模型整体学习轨迹的样本,是否就能实现更高效的训练?

(a) 不同训练样本在训练过程中展现出的多样化学习模式。(b) 样本学习轨迹与平均奖励曲线(红色)的比较。
LIM:一种自动化的样本评估方法
基于上述观察,研究团队开发了学习影响力测量(Learning Impact Measurement, LIM)方法。LIM 的核心思想是:好的训练样本应该与模型的整体学习进程保持同步。具体来说:
1. 计算参考曲线
首先,计算模型在所有样本上的平均奖励曲线作为参考:

这条曲线反映了模型的整体学习轨迹。
2. 评估样本对齐度
接着,为每个样本计算一个归一化的对齐分数:

这个分数衡量了样本的学习模式与整体学习轨迹的匹配程度。分数越高,表示该样本越 "有价值"。
3. 筛选高价值样本
最后,设定一个质量阈值 θ,选取那些对齐分数超过阈值的样本。在实验中,设置 θ = 0.6 筛选出了 1,389 个高价值样本,构成了优化后的 LIMR 数据集。
对比与验证
为了验证 LIM 方法的有效性,研究团队设计了两个基线方法:
1. 随机采样(RAND):从原始数据集中随机选择 1,389 个样本
2. 线性进度分析(LINEAR):专注于那些显示稳定改进的样本
这些对照实验帮助我们理解了 LIM 的优势:它不仅能捕获稳定进步的样本,还能识别那些在早期快速提升后趋于稳定的有价值样本。
奖励设计
对于奖励机制的设计,研究团队借鉴了 Deepseek R1 的经验,采用了简单而有效的规则型奖励函数:
- 当答案完全正确时,给予 + 1 的正向奖励
- 当答案错误但格式正确时,给予 - 0.5 的负向奖励
- 当答案存在格式错误时,给予 - 1 的负向奖励
这种三级分明的奖励机制不仅能准确反映模型的解题能力,还能引导模型注意答案的规范性。
三、实验验证:少即是多的力量
实验设置与基准
研究团队采用 PPO 算法在 Qwen2.5-Math-7B 基座模型上进行了强化学习训练,并在多个具有挑战性的数学基准上进行了评估,包括 MATH500、AIME2024 和 AMC2023 等竞赛级数据集。
主要发现
实验结果令人振奋。使用 LIMR 精选的 1,389 个样本,模型不仅达到了使用全量 8,523 个样本训练的性能,在某些指标上甚至取得了更好的表现:
- 在 AIME2024 上达到了 32.5% 的准确率
- 在 MATH500 上达到了 78.0% 的准确率
- 在 AMC2023 上达到了 63.8% 的准确率
相比之下,随机选择相同数量样本的基线模型(RAND)表现显著较差,这证实了 LIM 选择策略的有效性。

三种数据选择策略的性能对比:LIMR 以更少的数据达到更好的效果

LIMR 在三个数学基准测试上的训练动态表现与全量数据相当,显著优于随机采样
训练动态分析
更有趣的是模型在训练过程中表现出的动态特征。LIMR 不仅在准确率上表现出色,其训练过程也展现出了更稳定的特征:
- 准确率曲线与使用全量数据训练的模型几乎重合
- 模型生成的序列长度变化更加合理,展现出了更好的学习模式
- 训练奖励增长更快,最终也达到了更高的水平
这些结果不仅验证了 LIM 方法的有效性,也表明通过精心选择的训练样本,确实可以实现 "少即是多" 的效果。

LIMR 的训练动态分析:从精选样本中获得更稳定的学习效果
四、数据稀缺场景下的新发现:RL 优于 SFT
在探索高效训练策略的过程中,研究者们发现了一个令人深思的现象:在数据稀缺且模型规模较小的场景下,强化学习的效果显著优于监督微调。
为了验证这一发现,研究者们设计了一个精心的对比实验:使用相同规模的数据(来自 s1 的 1000 条数据和来自 LIMO 的 817 条数据),分别通过监督微调和强化学习来训练 Qwen-2.5-Math-7B 模型。结果令人印象深刻:
- 在 AIME 测试中,LIMR 的表现较传统监督微调提升超过 100%
- 在 AMC23 和 MATH500 上,准确率提升均超过 10%
- 这些提升是在使用相近数量训练样本的情况下实现的

小模型上的策略对比:强化学习的 LIMR 优于监督微调方法
这一发现具有重要意义。虽然 LIMO 和 s1 等方法已经证明了在 32B 规模模型上通过监督微调可以实现高效的推理能力,但研究表明,对于 7B 这样的小型模型,强化学习可能是更优的选择。
这个结果揭示了一个关键洞见:在资源受限的场景下,选择合适的训练策略比盲目追求更具挑战性的数据更为重要。通过将强化学习与智能的数据选择策略相结合,研究者们找到了一条提升小型模型性能的有效途径。
参考资料:https://github.com/GAIR-NLP/LIMR
#2025全球开发者先锋大会
技术大神授课,百亿AI项目招标
2025 年,DeepSeek 的破圈掀起了一场 AI 革新浪潮,如星火燎原般席卷各行各业。企业与机构纷纷寻求与顶尖 AI 技术人才展开深度对话,渴望把握技术发展的最新脉搏,同时也期待在这波智能化变革中发掘独特的商业价值和创新机遇。
2 月 21 日至 23 日,2025 全球开发者先锋大会将在上海徐汇举办。在大会中,你可以与 AGI 安全领域专家朱小虎等技术大师零距离交流,参与 AI 安全攻防等前沿工作坊,更能直接对接总额超百亿的 AI 项目招标。
从智能制造的 4000 万风电运维项目,到 8000 万的公共安全多模态大模型应用,再到医疗、教育、文旅等垂直领域的创新机遇,这里汇聚了当下最具潜力的 AI 商业化场景。无论你是技术供应商还是创新企业,都能在这场盛会中找到属于自己的发展机遇,共同谱写 AI 技术落地的新篇章。
授课嘉宾
朱小虎(Xiaohu Zhu)
中国首位通用人工智能安全研究员,专注于通用人工智能 AGI 发展与安全,麻省理工生命未来研究所(Future of Life Institute )通用人工智能风险安全研究员,Center for Safe AGI 和 University AI 创始人,长期从事人工智能领域科研、教学和产业落地。
2 月 21-23 日,在西岸艺术中心 B 馆 B-M-4,朱小虎将亲自带队现场授课及辅导,开展 3 场关于 AI4S、安全攻防授课及黑客松的工作坊活动。
项目招标
本次大会将携总额超百亿人工智能项目招标,热忱邀请在智能制造、教育、医疗、金融、文旅、城市治理等重点行业领域的技术供应商面对面深入交流沟通,共同参与这场业务集中的招投标大会!
场景一:智能制造行业
典型项目:基于大模型的大型风电装备智能运维 (4000W)
1、项目概述
单位:** 电气风电公司
场景概要:当前风电运维高度依赖专家,但面临人才数量有限、运维决策实时性较差等诸多难题。本项目计划基于风电运行过程中产生的海量监测数据以及运维报告,借助垂域大模型实现精准理解运维需求、灵活调用工具并推理出合理运维建议,同时能够生成设备控制指令,助力打造无人值守风电场。
2、招标需求
2.1 大模型应用开发平台搭建
- 算力平台搭建:需构建满足垂域大模型训练与推理需求的算力平台,确保平台具备高效、稳定的计算能力,能够支撑大规模数据处理与复杂模型运算。
- AI 平台搭建:具体建设内容虽尚未公布,但需搭建完整的 AI 平台,以满足后续基于大模型的风电运维应用开发需求。
- 风电运维垂类模型搭建和微调:搭建风电运维垂类模型,并基于现有数据进行微调,形成适用于风电运维领域的基座大模型。同时,考虑打造开源项目,推动行业技术共享与发展。
2.2 深远海风电运维标准语料库建设
基于风电相关文档,构建深远海风电问答语料数据集,并开发便于后续语料扩展的工具。
3、验收指标
大模型应用开发平台:AI 平台需完整支持建设内容所涉及的各项功能,且在相关运维建议推理、指令生成等关键应用中的准确率不低于 90%。
深远海风电运维标准语料库:语料库需全面覆盖风电设计标准文档、现场运维记录、图像和表格信息读取等多方面内容。
场景二:文旅行业
典型项目:红色文创与传播生成式人工智能设计服务系统
1、项目概述
单位:某纪念馆
场景概要:某纪念馆数字文创项目,鉴于传统展示方式已难以契合观众需求,拟借助 AIGC 技术对平台进行升级。通过构建符号库、语料库以及建立设计大模型,达成历史元素的精准传递等目标,进而提升上海红色文化的传播深度与国际影响力。
2、招标需求
2.1 AIGC 技术应用优化
运用 AIGC 技术,打造既贴合历史背景,又富有创意与美学价值的文创产品及数字藏品。研发并优化人工智能算法,促使其能够深度领悟红色文化的历史语境与文化内涵,精确生成契合市场需求的设计方案。
2.2 数字化符号库建设与智能识别
高效搭建并管理上海红色文化数字化符号库,整合历史资料、图像、音频等多维度资源。同时,确保 AI 系统能够智能化识别并生成符号库内的相关文化元素。在此过程中,需保证数据的精确性与全面性,并实现符号库内容的实时更新与优化。
2.3 用户需求分析与个性化推荐
借助 AI 技术剖析用户行为及反馈,精准识别不同观众群体的个性化需求,进而生成定制化的文创产品设计。涵盖依据年龄、兴趣、文化背景等因素展开智能推荐,为用户提供量身打造的文化体验。
2.4 AI 协同设计与优化
利用 AI 技术革新设计协作模式,凭借智能算法为设计师提供创意辅助,自动生成设计草案,并依据实时反馈持续优化设计。
2.5 大数据支持与预测模型
搭建精准的红色文创产品需求语料库,运用大数据技术预判市场需求的变化趋势,为文创产品的开发与推广提供科学依据。
场景三:金融行业
典型项目:面向普惠金融的智能产融生态圈智能平台搭建 & 信贷智能体场景搭建(2000W)
1、项目概述
单位:** 银行金融研究院
场景概要:依托 AI 大模型技术构建普惠金融综合金融智能群集,借助信贷全流程大模型智能体之间的协作,提升尽职调查与授信的效率,形成普惠金融信贷领域的样板工程,树立示范标杆。同时,与互联网机构展开合作,共同开发大模型应用,并将成功经验分享给中小金融机构与科创公司,营造智能共创的良性生态环境。
2、招标需求
2.1 AI 智能体平台搭建
构建具备高级认知能力的金融大模型智能体平台,该平台需实现 Agent 开发等核心功能,以此加速金融智能体在实际业务中的应用建设。
2.2 信贷智能体场景建设
基于上述搭建完成的平台与模型,打造适用于信贷全流程的尽职调查与授信智能体,实现财务分析报告以及行业分析报告的智能生成。
3、验收指标
3.1 AI 智能体平台
平台必须全面支持所提及的各项功能,在实际应用中,问答准确率、召回准确率以及工具调用准确率均需超过 90%。
3.2 信贷智能体场景
指标抽取计算的准确率需超过 95%,分析要点覆盖率需超过 90%。
场景四:城市治理行业
典型项目一:面向公共安全领域的多模态大模型深度应用(8000W)
1、项目概述
单位:** 研究所
场景概要:公共安全领域内视图为主体的多模态数据在公共安全业务中发挥核心作用,但目前应用层次依然很浅,对人工依赖度高,事前防控薄弱。迫切需要通过多模态大模型,对多模态数据资源做深度解析、理解和应用,对各警种业务提供 AI 能力支撑,推进主动防御型的立体化治安防控体系建设。
2、招标需求
2.1 多模态基础模型研发
研究面向公共安全领域的多模态基础模型,使其能够满足公共安全领域不同业务场景的需求。
2.2 具身智能多模态 AI 大脑
开发面向具身智能的多模态 AI 大脑,实现对多种模态信息的智能理解与处理。
2.3 超维度特征关联追踪
开展面向城域级目标防控的超维度特征关联追踪技术研究,提升城域范围内目标追踪的准确性与效率。
2.4 模型生成研发
进行面向复杂应用和资源弹性调度的模型生成研发,以适应公共安全领域复杂多变的业务需求与资源动态调配。
3、验收指标
3.1 多模态大模型场景覆盖
多模态大模型需全面覆盖刑侦的视频追踪、交警的路面违章识别、治安的重点场所的事件识别、法制的执法规范等场景业务需求。
3.2 确保覆盖各个场景的主要业务模型,能够准确、高效地完成各场景下的核心业务任务。
3.3 具身智能多模态理解与巡检
- 多模态大模型应能对具身智能的移动感知视频进行智能理解,所涉及的模态需涵盖视频、语音、传感、文本等四种。
- 实现对无人机和机器人的多模态感知实时解析,能够针对重点区域、化工、能源等区域进行巡检,并覆盖常规的异常事件识别。
3.4 城域级目标防控示范
在城域级范围开展示范应用,监控网络规模需超过 1 万个。
系统能够对网络中的目标进行快速智能追踪,满足城域级目标防控的实际业务需求。
典型项目二:漕河泾人工智能创新平台(2600W)
1、项目概述
单位:上海市漕河泾新兴技术开发区发展总公司
场景概要:项目以实现漕河泾 5.98 平方公里本部园区的全面覆盖为核心目标。在首发示范区的基础上,进一步扩大感知设备的物理空间覆盖范围,并研究既有感知终端的组合利用,实现漕河泾园区重点关注区域的基本覆盖。同时,综合考虑各区域的属性和业务特点,实现不同颗粒度的空间人流感知,进一步加强在园区服务精细化和园区动态洞察方面的应用能力。
2、招标需求
2.1 构建汇聚多要素的时空数据平台;
2.2 基于园区知识库和多元数据,打造领域模型引擎;
2.3 开发面向园区各类人群的园区助手应用和机器人协同系统;
2.4 建设漕河泾算力实验室;
2.5 结合区域特色,试点北杨人工智能小镇的覆盖,并寻求集团内部其他园区的合作意愿。
3、验收指标
园区人工智能平台功能满足需要,接入多个基础模型,适配多种人形机器人与多种智能算力环境。
场景五:教育行业
典型项目:有温度的引导式教育大模型及其应用 (1500W)
1、项目概述
单位:** 师范大学
场景概要:构建教育领域大模型,融入苏格拉底教学法与心理学理论语料,结合相关框架,提升引导教学与情感支持能力,实现智能教育的因材施教、公平有温度,并赋能心理诊断、疏导,数学引导教学及智能黑板等项目。
2、招标需求
2.1 大模型算力支持
- 提供服务器用于教育大模型训练
- 指标:不少于 32 卡 A800
2.2 教育领域语料构建
构建教育领域特有数据集,包括预训练和指令数据。
3、验收指标
3.1 覆盖不少于 50 个场景的下游任务数据,包括教案撰写、作文批改、解答题批改等场景。
场景六:医疗行业
典型项目:基于垂类生成模型的妇产科患者全程 AI 助理研发与应用示范 (1700W)
1、项目概述
单位:** 妇产科医院
场景概要:采用以大模型为核心的检索增强生成技术,构建专业知识库,打造涵盖智能问诊等功能的诊前中后全程医疗服务平台,改善就医体验、降低成本。建设中保护患者隐私,对信息脱敏处理。建成后,系统具备自动更新与增量学习能力,保证知识信息时效。
2、招标需求
2.1 妇产科专精知识增强
2.1.1 专业语料库构建:整合医院内部电子病历(含 B 超、影像数据)、科研论文(生物样本库相关)、诊疗指南(如《中国实用妇科与产科杂志》)等资源,结合外部权威数据源,形成结构化妇产科领域知识库。
2.1.2 领域知识图谱开发:基于大模型构建多模态知识图谱,涵盖妇科肿瘤、围产医学等子领域,关联影像、超声等多类数据。
2.2 生成内容真实可靠
2.2.1 检索增强生成(RAG)优化:结合医院知识库与实时医学文献,通过 RAG 技术限制生成范围,引入多级验证机制确保内容真实。
2.2.2 动态可信度评分:为生成内容标注来源并提供置信度评分。
2.2.3 自动化知识更新系统:利用 NLP 自动识别并更新诊疗指南变动,对接医院内部信息系统同步医生执业状态。
2.2.4 增量学习与版本管理:采用轻量化微调技术(如 LoRA)更新知识,保留历史版本知识库。
2.3 长周期健康管理支持
2.3.1 全生命周期数据整合:设计患者健康档案动态更新机制,整合多源数据,对产妇进行全流程跟踪服务。
2.3.2 个性化健康计划引擎:基于风险分层生成定制化随访计划,结合生成式 AI 提供实时健康建议。
2.4 患者隐私保护与数据脱敏
2.4.1 本地搭建测试环境:适配业务进行软硬件选型,保障数据不离院。
2.4.2 数据分级管控:对健康数据分类分级识别与管控。
2.4.3 数据脱敏处理:对训练数据脱敏或添加差分隐私噪声,防止个体信息逆推。
3、验收指标
3.1 妇产科专精知识增强
知识库覆盖妇产科 95% 以上疾病类型,问答准确率≥95%,诊疗建议与权威指南一致性≥95%。
3.2 生成内容真实可靠
出具更新说明和可靠性报告,AI 生成内容真实性验证通过率≥98%,错误信息自动拦截率≥95%,指南更新覆盖率≥99%,院内信息系统更新≤24 小时。
3.3 长周期健康管理支持
全生命周期数据可即时调阅分析,能提供个性化服务,孕期并发症预警准确率≥85%。
3.4 患者隐私保护与数据脱敏
满足《网络安全法》《数据安全法》《个人隐私保护》等法律法规要求。
场景七:具身智能
典型项目:漕河泾具身智能语料基地(3000W)
1、项目概述
单位:上海市漕河泾新兴技术开发区发展总公司
场景概要:人形机器人正处于技术集中突破和应用初步试水的关键时期,有望在未来几年实现商业化落地。目前,主要产业主体大多聚焦于机器人本体的研发,从 “大脑”“小脑” 到 “肢体” 等多角度实现对人类的模仿,尤其在智慧化和拟人化方面取得了长足进展。然而,要实现像无人机那样从撒农药到搬运物品,再到集群表演生成龙图腾等多样化应用场景,人形机器人仍有很长的路要走。为此,建设漕河泾具身智能语料基地项目,将以应用示范为牵引,打造人形机器人孵化器、动作捕捉训练场、共性技术中心、虚拟训练平台、智能算力中心和安全校验场等产业生态平台,推动人形机器人产业的全面发展。
2、招标需求
以人形机器人场景应用与批量推广为目标,厘清人形机器人科学发展规律,建设漕河泾具身智能语料基地项目,打造人形机器人创新孵化器、人形机器人动作捕捉训练场、人形机器人共性训练中心、人形机器人智能算力实验室、人形机器人虚拟训练平台、人形机器人安全校验实验室,并与印象城、创新中心、会议中心建设面向商业、办公、公共服务等领域的人形机器人应用,在实现「1 公里」典型应用示范的同时,实现漕河泾园区服务成本降低和效率提升。
3、验收指标
不同品牌不同功能的人形机器人功能、性能、安全、体系测试、验证、校验平台,符合相关标准与要求。满足功能的人形机器人部署。
更多项目请扫文末二维码或注册全球开发者先锋大会公众号后了解详情。
结语
2025 全球开发者先锋大会将以超百亿 AI 项目搭建连接供需双方的桥梁!在这里,你不仅能与行业顶尖技术人才交流,获取最前沿的技术信息,更重要的是,能深度参与到项目机会中,在六大行业里精准找到企业想要的业务和项目,为自己的技术事业开启全新篇章。这是一次促进场景与技术企业对接的绝佳机会,错过这次,你可能要再等一年!还在等什么?2 月 21 日,GDC 大会,我们不见不散,一起用 AI 创造未来!
#LeCun等新研究揭示AI可如何涌现出此能力
物理直觉不再是人类专属
在当今的 AI 领域,图灵奖得主 Yann LeCun 算是一个另类。即便眼见着自回归 LLM 的能力越来越强大,能解决的任务也越来越多,他也依然坚持自己的看法:自回归 LLM 没有光明的未来。
在近期的一次演讲中,他将自己的观点总结成了「四个放弃」:放弃生成式模型、放弃概率模型、放弃对比方法、放弃强化学习。他给出的研究方向建议则是联合嵌入架构、基于能量的模型、正则化方法与模型预测式控制。他还表示:「如果你感兴趣的是人类水平的 AI,那就不要研究 LLM。」
总之,他认为有望实现 AGI 或「人类水平的人工智能」的方向是世界模型(World Model),其领导的团队也一直在推进这方面的研究工作,比如基于 DINO 的世界模型(DINO-WM)以及一项在世界模型中导航的研究。
近日,Yann LeCun 团队又发布了一项新研究。他们发现,只需在自然视频上进行自监督预训练,对物理规则的直觉理解就会涌现出来。似乎就像驴一样,通过观察世界,就能直觉地找到最轻松省力的负重登山方法。


- 论文标题:Intuitive physics understanding emerges from self-supervised pretraining on natural videos
- 论文地址:https://arxiv.org/pdf/2502.11831v1
- 项目地址:https://github.com/facebookresearch/jepa-intuitive-physics
该论文发布后,收获了不少好评:


直觉物理理解
要理解这篇论文,我们首先需要明确一下什么才算是「直觉物理理解」。这篇论文写到,对物理规则的直觉理解是人类认知的基础:我们会预期事物的行为方式是可预测的,比如不会凭空出现或消失、穿透障碍物或突然改变颜色或形状。
这种对物理世界的基本认知不仅在人类婴儿中有所记录, 在灵长类动物、海洋哺乳动物、鸦科鸟类和雏鸡中也有所发现。这被视为核心知识(或核心系统)假说的证据,根据该假说:人类拥有一套与生俱来或早期进化发展的古老计算系统,专门用于表示和推理世界的基本属性:物体、空间、数字、几何、agent 等。
在追求构建具有高级人类智能水平的机器的过程中,尽管 AI 系统在语言、编程或数学等高级认知任务上经常超越人类表现,但在常识性物理理解方面却显得力不从心,这体现了莫拉维克悖论,即对生物有机体来说微不足道的任务对人工系统来说可能异常困难,反之亦然。
旨在改善物理直觉理解的 AI 模型的先前研究可以分为两类:结构化模型和基于像素的生成模型。
- 结构化模型利用手工编码的物体及其在欧几里得三维空间中关系的抽象表示,产生一个能够捕捉人类物理直觉的强大的心理「游戏引擎」。这类模型可以被视为核心知识假说的一种可能的计算实现。
- 基于像素的生成模型采取了完全相反的观点,否认需要任何硬编码的抽象。相反,它们提出了一种通用学习机制,即基于过去的感知输入(如图像)重建未来的感知输入。
V-JEPA:基于自然视频涌现物理直觉
在新论文中,LeCun 等人探索了第三类模型 —— 联合嵌入预测架构(JEPA),它在这两种对立观点之间找到了中间立场,整合了两者的特征。
与结构化模型一样,JEPA 认为对未来世界状态的预测应该在模型的学习抽象、内部表示中进行,而不是在低级的、基于像素的预测或生成方面进行。然而,与结构化模型不同,JEPA 让算法自行学习其表示,而不是手工编码。这种在表示空间中进行预测的机制与认知神经科学的预测编码假说相一致。
新论文研究了该架构的视频版本,即 V-JEPA,它通过在表示空间中重建视频的被掩蔽部分来学习表示视频帧。
该研究依赖于预期违反(violation-of-expectation)框架来探测物理直觉理解,而无需任何特定任务的训练或适应。通过提示模型想象视频的未来(表示)并将其预测与实际观察到的视频的未来进行比较,可以获得一个定量的意外度量(measure of surprise),该度量可用于检测违反直观物理概念的情况。

研究发现 V-JEPA 能够准确且一致地区分遵循物理定律的视频和违反物理定律的视频。
具体来说,当被要求对视频对的物理合理性进行分类时(其中一个视频是合理的,另一个不是),在自然视频上训练的 V-JEPA 模型在 IntPhys 基准测试上达到了 98% 的零样本准确率,在 InfLevel 基准测试上达到了 62% 的零样本准确率。令人惊讶的是,研究发现多模态大语言模型和在像素空间中进行预测的可比较视频预测方法都是随机执行的。
为了更好地理解哪些设计选择导致了 V-JEPA 中物理直觉理解的涌现,LeCun 等人消融了训练数据、预训练预测目标(从什么预测什么)和模型大小的影响。虽然观察到改变这些组件中的每一个都会影响性能,但所有 V-JEPA 模型都达到了显著高于随机水平的性能,包括一个小型的 1.15 亿参数模型,或者仅在一周独特视频上训练的模型,这表明在学习表示空间中进行视频预测是获得物理直觉理解的一个稳健目标。
测量直觉物理理解
测量直觉物理理解中的预期违反
预期违反范式源自发展心理学。研究对象(通常是婴儿)会看到两个相似的视觉场景,其中一个包含物理上不可能的情况。然后,研究者通过各种生理指标(如相对注视时间)获取对每个场景的「感到意外」反应,用以确定研究对象是否感受到了概念违反。
这一范式已经扩展到评估 AI 系统的物理理解能力。类似于婴儿实验,向模型展示成对的场景,除了违反特定直觉物理概念的某个方面或事件外,两个场景的所有方面(物体属性、物体数量、遮挡物等)都保持相同。例如,一个球可能会滚到遮挡物后面,但在配对的视频中再也不会出现,从而测试物体持久性的概念。模型对不可能场景表现出更高的意外反应,反映了其对被违反概念的正确理解。
用于直觉物理理解的视频预测
V-JEPA 架构的主要开发目的是提高模型直接从输入适应高层级下游任务的能力,如活动识别和动作分类,而无需硬编码一系列中间表示,如物体轮廓或姿态估计。
在这项研究中,研究团队测试了一个假设:该架构之所以在高层级任务上取得成功,是因为它学习到了一种隐式捕捉世界中物体结构和动态的表示,而无需直接表示它们。
如图 1.B 所示,V-JEPA 由一个编码器(神经网络)和一个预测器(也是神经网络)构成。编码器从视频中提取表示,预测器预测视频中人为掩蔽部分的表示,如随机掩蔽的时空块、随机像素或未来帧。编码器和预测器的联合训练使编码器能够学习抽象表示,这些表示编码可预测的信息并丢弃低层级(通常语义性较低)特征。

在自监督训练之后,可以使用编码器和预测器网络来探测模型对世界的理解,而无需任何额外的适应。具体来说,在遍历视频流时,模型对观察到的像素进行编码,随后预测视频后续帧的表示,如图 1.C 所示。通过记录每个时间步的预测误差(预测的视频表示与实际编码的视频表示之间的距离),可以获得模型在整个视频中意外程度的时间对齐定量度量。通过改变模型可以用来预测未来的过去视频帧数(上下文),可以控制记忆因素;通过改变视频的帧率,可以控制动作的精细程度。

表征预测学习检测直觉物理违反现象
研究团队在三个数据集上评估了直觉物理理解能力:IntPhys 的开发集、GRASP 和 InfLevel-lab。这些数据集的组合使研究团队能够探测各类方法对物体持久性、连续性、形状和颜色恒常性、重力、支撑、固体性、惯性和碰撞的理解。
研究团队将 V-JEPA 与其他视频模型进行了比较,以研究视频预测目标以及执行预测的表征空间对直觉物理理解的重要性。研究团队考虑了两类其他模型:直接在像素空间进行预测的视频预测模型和多模态大语言模型(MLLM)。
对于考虑的每种方法,研究团队评估了原始工作中提出的旗舰模型。研究团队进一步将所有模型与未训练的神经网络进行比较,测试直觉物理理解的可学习性。
图 1.A 总结了各方法在成对分类(即在一对视频中检测不可能的视频)中跨数据集的性能。

研究团队发现,V-JEPA 是唯一一个在所有数据集上都显著优于未训练网络的方法,在 IntPhys、GRASP 和 InfLevel-lab 上分别达到了 98%(95% CI [95%,99%])、66%(95% CI [64%,68%])、62%(95% CI [60%,63%])的平均准确率。这些结果表明,在学习到的表征空间中进行预测足以发展出对直觉物理的理解。这是在没有任何预定义抽象,且在预训练或方法开发过程中不知道基准的情况下实现的。
通过比较,该团队发现,VideoMAEv2、Qwen2-VL-7B 和 Gemini 1.5 pro 的性能仅略高于随机初始化模型。像素预测和多模态 LLM 的低性能证实了先前的一些发现。
该团队表示:「这些比较进一步凸显了 V-JEPA 相对于现有 VideoMAEv2、Gemini 1.5 pro 和 Qwen2-VL-72B 模型的优势。然而,这些结果并不意味着 LLM 或像素预测模型无法实现直观的物理理解,而只是意味着即使对于前沿模型来说,这个看似简单的任务仍然很困难。」
V-JEPA 各属性分析
接下来,为了更准确地理解 V-JEPA 的直观物理理解,该团队仔细研究了其在先前使用的数据集上的各属性性能。在这里,V-JEPA 编码器和预测器基于 Vision Transformer-Large 架构,并在 HowTo100M 数据集上进行了训练。结果见下图 2。

可以看到,在 IntPhys 上,V-JEPA 在多个直观物理属性上的表现都明显优于未经训练的网络,其中包括物体持久性、连续性、形状恒常性。
在 GRASP 上,V-JEPA 也在物体持久性、连续性、支撑结构、重力、惯性方面有显著更高的准确度。不过 V-JEPA 在流体和碰撞等方面优势不显著。
总结起来,V-JEPA 在与场景内容相关的属性方面表现出色,但在需要了解情境事件或精确物体交互的类别方面却颇为困难。该团队猜想,这些限制主要来自模型的帧速率限制。尽管如此,V-JEPA 展现出了直觉物理理解能力,同时可从原始感知信号中学习所需的抽象,而无需依赖于强大的先验信息。不同于之前的研究,这表明,要让深度学习系统理解直觉物理概念,核心知识并不是必需的。
更进一步,该团队使用来自 IntPhys 的私有测试集将 V-JEPA 与人类表现进行了比较。这次实验使用了旗舰 V-JEPA 架构,即使用 ViT-Huge 并在 VideoMix2M 上进行预训练。结果发现 V-JEPA 在所有直观物理属性上都实现了相同或更高的性能,如图 2.B 所示。
该团队发现,如果在视频中使用最大意外值而不是平均意外值,可以在单个视频上获得更好的性能。
一般来说,当打破物理直觉的事件发生在遮挡物后面时,V-JEPA 和人类的性能都较低。此外,在遮挡设置下,人类和 V-JEPA 之间的性能具有很好的相关性。
最后,该团队也研究了掩码类型、训练数据的类型和数量、模型大小对 V-JEPA IntPhys 分数的影响,结果如下。

#Light-A-Video
视频版IC-Light来了!Light-A-Video提出渐进式光照融合,免训练一键视频重打光
本文作者来自于上海交通大学,中国科学技术大学以及上海人工智能实验室等。其中第一作者周彧杰为上海交通大学二年级博士生,师从牛力副教授。

数字化时代,视频内容的创作与编辑需求日益增长。从电影制作到社交媒体,高质量的视频编辑技术成为了行业的核心竞争力之一。然而,视频重打光(video relighting)—— 即对视频中的光照条件进行调整和优化,一直是这一领域的技术瓶颈。传统的视频重打光方法面临着高昂的训练成本和数据稀缺的双重挑战,导致其难以广泛应用。
如今,这一难题终于迎来了突破 —— 由上海交通大学以及上海人工智能实验室联合研发的 Light-A-Video 技术,为视频重打光带来了全新的解决方案。
论文地址:https://arxiv.org/abs/2502.08590
项目主页:https://bujiazi.github.io/light-a-video.github.io/
代码地址:https://github.com/bcmi/Light-A-Video
无需训练,零样本实现视频重打光
Light-A-Video 是一种无需训练的视频重打光方法,能够在没有任何训练或优化的情况下,生成高质量、时序一致的重打光视频。这一技术的核心在于充分利用预训练的图像重打光模型(如 IC-Light)和视频扩散模型(如 AnimateDiff 和 CogVideoX),通过创新的 Consistent Light Attention(CLA)模块和 Progressive Light Fusion(PLF)策略,针对视频内容的光照变化进行了一致性的优化,实现了对视频序列的零样本(zero-shot)光照控制。
其优势在于:
1. 无需训练,高效实现视频重打光:Light-A-Video 是首个无需训练的视频重打光模型,能够直接利用预训练的图像重打光模型(如 IC-Light)的能力,生成高质量且时间连贯的重打光视频。这种方法避免了传统视频重打光方法中高昂的训练成本和数据稀缺的问题,显著提高了视频重打光的效率和扩展性。
2. 创新的端到端流程,确保光照稳定性与时序一致性:CLA 模块通过增强跨帧交互,稳定背景光源的生成,减少因光照不一致导致的闪烁问题。PLF 通过渐进式光照融合策略,逐步注入光照信息,确保生成视频外观的时间连贯性。
3. 广泛的适用性与灵活性:Light-A-Video 不仅支持对完整输入视频的重打光,还可以对输入的前景序列进行重打光,并生成与文字描述相符的背景。而且不依赖于特定的视频扩散模型,因此与多种流行的视频生成框架(如 AnimateDiff、CogVideoX 和 LTX-Video)具有高度的兼容性。
CLA + PLF
确保光照一致性与稳定性
Light-A-Video 核心技术包括两个关键模块:Consistent Light Attention 和 Progressive Light Fusion。CLA 模块通过增强自注意力层中的跨帧交互,稳定背景光照源的生成。它引入了一种双重注意力融合策略,一方面保留原始帧的高频细节,另一方面通过时间维度的平均处理,减少光照源的高频抖动,从而实现稳定的光照效果。实验表明,CLA 模块显著提高了视频重打光的稳定性,减少了因光照不一致导致的闪烁问题。

PLF 策略则进一步提升了视频外观的稳定性。它基于光传输理论的光照线性融合特性,通过逐步混合的方式,将重打光外观与原始视频外观进行融合。在视频扩散模型的去噪过程中,PLF 策略逐步引导视频向目标光照方向过渡,确保了时间连贯性。这种渐进式的光照融合方法不仅保留了原始视频的细节,还实现了平滑的光照过渡。

Light-A-Video 整体架构设计

1. 利用视频扩散模型的时序先验,将原始视频加噪到对应的步数后进行去噪。在每一步的去噪过程中,提取其预测的原始去噪目标

并添加上对应的视频细节补偿项作为当前步的一致性目标

2. 将

输入图片重打光模型(IC-Light),并利用 CLA 的双流注意力模块进行逐帧重打光,实现稳定的背景光源生成,作为当前步的重打光的目标

。
3. 在预测下一步的

时,先利用 VAE 编解码器将

和

从潜层编码空间解码到视频像素层面。然后通过引入一个渐进式随时间步下降的参数

将两个目标进行线性外观混合后,重新编码到潜层编码空间获取混合目标

。即 PLF 策略利用混合目标

引导生成单步的重打光结果

。
当视频完全去噪后,Light-A-Video 能够获得时序稳定且光照一致的重打光视频。
高质量、时间连贯的重光照效果

为了验证 Light-A-Video 的有效性,研究团队基于 DAVIS 和 Pixabay 公开数据集上构建了其测试数据集。实验结果表明,Light-A-Video 在多个评估指标上均优于现有的基准方法,尤其在动作保留方面,该方法在保证原视频外观内容的基础上实现了高质量的重打光效果。

另外,Light-A-Video 能够在仅提供前景序列的情况下,实现背景生成和重打光的并行处理。
未来展望:动态光照与更广泛应用
之后,Light-A-Video 将致力于有效地处理动态光照条件,进一步提升视频重打光的灵活性与适应性。这一创新技术的出现,已然为视频编辑领域注入了全新思路。随着技术的持续发展与优化,我们有理由相信,Light-A-Video 必将在更广泛的领域大放异彩,为视频内容创作开辟更多可能性。
#量子计算里程碑
微软单芯片可百万量子比特,Nature研究爆火
不是固体、液体,也不是气体,而是拓扑导体。
重大突破!本周四,微软宣布造出了一款前所未有的量子计算芯片 Majorana 1,并称可以在单块芯片上让数百万量子比特协同工作,解决之前无法的解决的问题,从新药物研发到创造革命性的新材料。

微软 CEO 萨提亚・纳德拉为此专门撰写了一条长推文,短时间内就已经收获了上千万阅读量,其中提到 Majorana 1 是首款建立在拓扑核心(topological core)上的量子处理单元,而这一成就的基础是他们创造的「一种全新的物质状态」,而这又解锁了一类新材料。他们称之为 topoconductor,这里译为「拓扑导体」。
纳德拉表示,使用拓扑导体可以制造出更快、更小、更可靠的量子比特。其尺寸可小至百分之一毫米,这意味着我们可以在较小的体积内集成大量量子比特。

纳德拉写到:「我们相信,这一突破将使我们能在几年内(而非像一些人预测的几十年)创造出一台真正有意义的量子计算机。」
基于新材料和新架构,微软已经构建了世界上首个基于拓扑量子比特的容错原型(FTP)。
以下为微软发布的宣传视频:
,时长00:47
这一消息可说是让整个互联网都沸腾了,正如去年底谷歌宣布了量子芯片 Willow 时一样 —— 谷歌称 Willow 能在 5 分钟内完成超级计算机 10²⁵ 年才能完成的计算,参阅报道《5 分钟完成最强超算 10²⁵年工作,谷歌量子芯片重大突破,马斯克、奥特曼齐祝贺》。
Majorana 1 是微软历时 17 年,通过持续研究量子计算新材料和架构获得的成果。微软认为,该芯片让量子计算机大规模应用成为了可能。
量子计算机的核心是量子比特,它是量子计算中的信息单位,就像当今计算机使用的二极管一样。多年来,IBM、微软、谷歌等公司一直试图让量子比特像二进制比特一样可靠,但因为量子比特更加脆弱,对噪音更敏感,容易产生误差或导致数据丢失。
基于全新的理念,Majorana 1 处理器有望将 100 万个量子比特集成到一个芯片上,该芯片与台式电脑和服务器中的 CPU 差不多大。微软没有在新芯片中使用电子进行计算,而是使用了理论物理学家埃托雷・马约拉纳(Ettore Majorana)在 1937 年提出的马约拉纳粒子。微软通过创造所谓的「世界上第一个拓扑导体」达到了这一里程碑。
拓扑导体是一种新型材料,不仅可以观察,还可以控制马约拉纳粒子,以创造更可靠的量子比特。

微软 Majorana 1 处理器非常小。
微软的工作登上了最新一期的《自然》杂志,其中概述了研究成果。微软帮助创造了一种由砷化铟和铝制成的新材料,并将八个拓扑量子比特放在单块芯片上,目标是最终能扩展到 100 万个。

- 论文标题:Interferometric single-shot parity measurement in InAs–Al hybrid devices
- 论文地址:https://www.nature.com/articles/s41586-024-08445-2
不仅如此,微软还发布了一份实现「可靠量子计算」的路线图,称这是他们实现「从单量子比特设备到能够进行量子纠错的阵列的路径。」

- 路线图地址:https://arxiv.org/pdf/2502.12252
一个拥有 100 万个量子比特的芯片可以执行更精确的模拟,帮助提高人类对自然世界的理解,并在医学和材料科学领域取得突破。多年来,这一直是我们对于量子计算的愿景,而微软相信其拓扑导体或拓扑超导体是下一个重大突破。
微软量子公司副总裁 Zulfi Alam 表示:「我们在过去 17 年里一直在研究这个项目。这是公司里运行时间最长的研究项目。17 年后,我们展示的成果不仅令人难以置信,而且真实存在。它们将从根本上重新定义量子计算下一阶段的发展方式。」
一种全新的材料
微软表示,这一切突破的基础都可以归因于一种新材料:拓扑导体(topoconductor)。基于这种革命性的新材料,微软打造出了拓扑超导体(topological superconductivity)—— 这种物质状态之前只存在于理论之中。
微软博客写到:「这一进步源于微软在设计和制造栅极定义设备(gate-defined device)方面的创新,这些设备结合了砷化铟(一种半导体)和铝(一种超导体)。当冷却到接近绝对零度并用磁场调节时,这些设备会形成拓扑超导纳米线,导线末端具有马约拉纳零模式(MZM)。」
过去近百年的时间里,MZM 这些准粒子只存在于教科书中。现在,微软可以根据需要在拓扑导体中创建和控制它们。MZM 是微软量子比特的基本模块,其能通过「奇偶校验」存储量子信息 —— 看这些线包含偶数还是奇数个电子。
在传统超导体中,电子结合成库珀对并会无阻力地移动。任何未配对的电子都可以被检测到,因为它的存在需要额外的能量。微软的拓扑导体则不同:在这里,一对 MZM 之间共享一个未配对的电子,使其对环境不可见。这种独特的特性可以保护量子信息。

读取拓扑量子比特的状态。
上图展示了微软应对这种测量难题的方法:
- 使用数字开关将纳米线的两端耦合到量子点,量子点是一种可以存储电荷的微型半导体器件。
- 这种连接增加了点保持电荷的能力。至关重要的是,确切的增加量取决于纳米线的奇偶性。
- 使用微波测量这种变化。这些点保持电荷的能力决定了微波从量子点反射的方式。因此,它们会带着纳米线量子态的印记返回。
通过设计,微软让这些变化变得足够大,从而一次测量就能得到可靠的结果。微软表示,目前初始的测量错误概率为 1%,但他们已经确定了可以大幅降低错误概率的路径。
这种读出技术使量子计算的方法从根本上发生了变化,即可使用测量值进行计算。
传统量子计算是以精确的角度旋转量子态,需要为每个量子比特定制复杂的模拟控制信号。这会使量子误差校正 (QEC)变得复杂,因为量子误差校正必须依靠这些相同的敏感操作来检测和纠正错误。
微软新提出的基于测量的方法可以极大地简化 QEC—— 可完全通过由连接和断开量子点与纳米线的简单数字脉冲激活的测量来执行误差校正。这种数字控制可实现对大量量子比特的管理,从而为实际应用奠定基础。
从物理学到工程开发
接下来看看微软是怎么将上面介绍的物理可能性变成工程实践的。
前面已经提到,微软量子计算的核心构建模块是 MZM 编码、拓扑保护、通过测量进行处理的量子信息。
接下来,就需要基于单量子比特设备(称为 tetron)制造一个可扩展的架构,如下图所示。这个量子比特的一个基本操作是测量 tetron 中的一个拓扑纳米线的奇偶性。

使用 tetron 实现容错量子计算的路线图。第一幅图展示了一个单量子比特设备。tetron 由两条平行的拓扑线(蓝色)组成,两端各有一个 MZM(橙色点),由垂直的普通超导线(浅蓝色)连接。下一幅图展示了一个支持基于测量的 braiding 变换的双量子比特设备。第三幅图展示了一个 4×2 tetron 阵列,支持在两个逻辑量子比特上进行量子误差检测演示。这些演示预示着向量子误差校正方向的进展是可行,例如右图所示的设备(27×13 tetron 阵列)。
另一项关键操作是将量子比特置于奇偶性叠加态中。这也是通过对量子点进行微波反射测量来执行的,但测量配置不同:将第一个量子点与纳米线分离,并将另一个点连接到设备一端的两条纳米线上。通过执行这两个正交的泡利测量 Z 和 X,这里演示了基于测量的控制。微软表示这是开启其路线图下一步的关键里程碑。
微软表示:「我们的路线图正系统地朝着可扩展 QEC 迈进。下一步将使用 4×2 四元组阵列。我们将首先使用两个量子比特子集来演示纠缠和基于测量的 braiding 变换。然后,我们将使用整个八量子比特阵列在两个逻辑量子比特上实现量子错误检测。」
拓扑量子比特的内置错误保护简化了 QEC。此外,与之前最先进的方法相比,微软的自定义 QEC 代码可将开销减少大约十倍。这种大幅减少意味着其可扩展系统可以用更少的物理量子比特进行构建,并有可能以更快的时钟速度运行。

微软表示,在很多科研领域上,当今最强大的超级计算机也无法完成的任务可以被百万量子比特规模上的量子计算解决,比如能修复桥梁裂缝的自愈材料、可持续农业以及更安全的化学材料探索。如今需要花费数十亿美元进行详尽的实验搜索和实验室实验的内容,未来可能通过量子计算机的计算和模拟来快速找到。
值得一提的是,美国国防高级研究计划局(DARPA)现已选择微软作为两家公司之一,进入其「实用规模量子计算的未探索系统(US2QC)」项目的最后阶段。微软现在将「在几年内」建造一台基于拓扑量子比特的容错原型量子计算机。
百万量子比特的量子计算机不仅仅会是一个里程碑,也将成为解决人类前沿研究最困难问题的门户。微软认为,在基础技术得到验证后,通往实用量子计算的道路已经变得清晰。
参考链接
https://www.theverge.com/news/614205/microsoft-quantum-computing-majorana-1-processor
https://x.com/Microsoft/status/1892245131895423158
https://x.com/satyanadella/status/1892242895094313420
#Awesome-Large-Model-Safety
复旦主导,中美等8个国家25家单位44名学者联合发布大模型安全技术综述
近年来,随着大模型的快速发展和广泛应用,其安全问题引发了社会各界的广泛关注。例如,近期发生的「全球首例利用 ChatGPT 策划的恐袭事件」再次敲响了警钟,凸显了大模型安全问题的紧迫性和重要性。
为应对这一挑战,来自中美英德等 8 个国家 25 家高校和科研机构的 44 位 AI 安全领域学者联合发布了一篇系统性技术综述论文。该论文的第一作者是复旦大学马兴军老师,通信作者是复旦大学姜育刚老师,领域内众多知名学者共同参与。
- 论文标题:Safety at Scale: A Comprehensive Survey of Large Model Safety
- 论文地址:https://arxiv.org/abs/2502.05206
- GitHub 主页:https://github.com/xingjunm/Awesome-Large-Model-Safety
这篇综述论文全面调研了近年来大模型安全相关的 390 篇研究工作,并采用简单直接的三级目录结构对内容进行了系统梳理(如图 3 所示):一级目录聚焦模型类型,二级目录区分攻击与防御类型,三级目录细化技术路线。
研究覆盖了视觉基础模型、大语言模型、视觉-语言预训练模型、视觉-语言模型、文生图扩散模型和智能体等 6 种主流大模型,以及对抗攻击、后门攻击、数据投毒、越狱攻击、提示注入、能量延迟攻击、成员推理攻击、模型抽取攻击、数据抽取攻击和智能体攻击等 10 种攻击类型。

论文总结了 4 个重要研究趋势(参考下图 1 和 2):
1. 研究规模显著增长
过去 4 年,大模型安全研究论文数量成倍增长,2024 年相关研究已突破 200 篇,充分体现了学术界和产业界对该领域的高度关注。
2. 攻防研究比例失衡
在现有研究中,约 60% 的工作聚焦于攻击方法,而防御相关研究仅占 40%。这种攻防研究的不平衡状态凸显了当前防御技术的不足,亟需更多资源投入以提升大模型的安全性。
3. 重点攻击目标
大语言模型、文生图扩散模型以及视觉基础模型(包括预训练 ViT 和 SAM)是目前最受攻击者关注的三类模型。这些模型因其广泛的应用场景和高影响力,成为安全研究的核心焦点。
4. 主流攻击类型
对抗攻击、后门和投毒攻击以及越狱攻击是目前被研究最多的三大攻击类型。这些攻击手段因其高成功率和潜在危害性,成为大模型安全领域的主要挑战。

图 1. (左)过去四年发表的大模型安全研究论文数量;(中)各类大模型的研究分布;(右)各类攻击 / 防御的研究分布。

图 2. (左)不同模型上研究论文数量的季度变化趋势;(中)各类大模型与对应攻防研究之间的比例对应关系;(右)各类攻防研究论文年度发表数量的变化趋势(从高到低上下排序)。
除了介绍针对各类模型的攻击与防御方法,论文还归纳了研究常用的数据集和评估基准,为初学者快速了解领域进展和实验设置提供了参考。论文的组织结构清晰,内容详实,不仅为学术界和产业界提供了全面的研究指南,也为未来大模型安全研究指明了方向。
最后,论文总结了大模型安全领域的主要挑战,并呼吁学术界与国际社会协同合作,共同应对这些难题:
1. 根本脆弱性理解不足
领域需要增加对大模型根本脆弱性的理解。比如大语言模型的脆弱性根源是什么,不同模态间的脆弱性是否会相互传播?文生图和文生视频类大模型语言能力的缺乏是否会让它们更难对齐?此外,大模型是否真的会记忆原始训练数据或者以何种方式、多大程度记忆训练数据?
2. 安全评测的局限性
当前评估方法存在显著不足。单一参考攻击成功率无法全面衡量模型安全性,基于静态数据集的基准评测难以应对各类攻击。尽管对抗性评测不可或缺,但在实际环境中,其全面性、准确性和动态性仍需提升。
3. 防御机制亟待加强
现有防御措施存在明显短板,当前防御体系缺乏主动机制和有效检测手段。安全对齐技术并不是万能的,在面对更先进的攻击时仍可被绕过。随着具身智能发展和通用智能的接近,领域亟需更具系统性、实用性和前瞻性的防御方案。
4. 呼吁全球合作
为应对日益多样化的挑战,倡议发展以防御为导向的大模型安全研究,开发更强大的安全防御工具。呼吁模型开源、呼吁商业模型提供专用安全 API、呼吁建立开源安全平台。呼吁全球合作,只有通过学术界、产业界和国际社会的共同努力,才能构建更安全可信的人工智能生态系统。
#VLM-R1
重磅发现!DeepSeek R1方法成功迁移到视觉领域,多模态AI迎来新突破!
嘿,各位开发小伙伴,今天要给大家安利一个全新的开源项目 ——VLM-R1!它将 DeepSeek 的 R1 方法从纯文本领域成功迁移到了视觉语言领域,这意味着打开了对于多模态领域的想象空间!
这个项目的灵感来自去年 DeepSeek 开源的那个 R1 方法,靠着 GRPO(Generative Reward Processing Optimization)强化学习方法,在纯文本大模型上取得了惊人的效果。
现在,VLM-R1 团队直接把它应用到了视觉语言模型上,打开了一扇新的大门!
VLM-R1 验证结果惊艳
这个项目的团队在 Qwen2.5-VL 的基础上,同时对比了 R1 和传统的 SFT 方法。结果相当惊艳:
1、稳定性拉满:R1 方法在各种复杂场景下都能保持稳定的高性能,这在实际应用至关重要!
2. 泛化能力卓越:更让人震惊的是,在领域外的测试数据上,随着训练步数增加,传统 SFT 模型的性能开始下滑,而 R1 模型却能持续提升!这意味着 R1 方法帮助模型真正 “学会” 了理解视觉内容,而不是简单地记忆!

(训练和测试领域的差异对比)

(泛化性对比,绿线是 VLM-R1,在领域外泛化性显著更优)
3、上手超简单:VLM-R1 项目团队还贴心地提供了完整的训练和评估流程,四步就能开始训练,对开发者十分友好。
小编亲测之后,在此分享一个实际案例,结果让人意外。

图片里展示了一桌子丰盛的美食,包括各种蔬菜、面饼和点心。针对图片,我们向模型提出了一个问题:“在图片中找出蛋白质含量最高的食物”。
模型不仅回答得准确:
“图片中展示了桌上的各种菜品,包括蔬菜、面饼和点心。从蛋白质含量来看,面饼或面点可能含量最高,因为它们通常由全谷物制成,面粉中含有蛋白质。虽然蔬菜也含有蛋白质,但比起这些主食来说含量较少。”
更厉害的是,它还精准地在图片中框选出了那个蛋白质含量最高的鸡蛋饼!
这种精确的视觉理解能力和推理能力,让人印象深刻!
完美展示了 VLM-R1 在实际应用中的优势:
- 准确的视觉识别能力
- 专业的知识推理能力
- 清晰的文本表达能力
全新思路
作为一个 AI 领域的观察者,VLM-R1 的出现也为开发者和行业提供了许多新的思路,比如:
1、证明了 R1 方法的通用性,不止文本领域玩得转;
2、为多模态模型的训练提供了新思路;
3、或许能够引领一种全新的视觉语言模型训练潮流;
完全开源
最棒的是,这个优秀的项目完全开源!
项目地址:[VLM-R1](https://github.com/om-ai-lab/VLM-R1)
对视觉语言模型感兴趣的同学,强烈建议去看看这个项目。说不定你的下一个突破性研究就从这里开始!
#Is Noise Conditioning Necessary for Denoising Generative Models?
再次颠覆学界想象,何恺明发表新作:扩散模型不一定需要噪声条件
一直以来,研究者普遍认为,去噪扩散模型要想成功运行,噪声条件是必不可少的。
而大神何恺明的一项最新研究,对这个观点提出了「质疑」。
「受图像盲去噪研究的启发,我们研究了各种基于去噪的生成模型在没有噪声调节的情况下的表现。出乎我们意料的是,大多数模型都表现出了优美的退化,它们甚至在没有噪声条件的情况下表现得更好。」
论文标题:Is Noise Conditioning Necessary for Denoising Generative Models?
论文地址:https://arxiv.org/pdf/2502.13129
研究者对这些模型在无噪声条件情况下的行为进行了理论分析。具体来说,他们研究了噪声水平分布中固有的不确定性、在没有噪声条件的情况下去噪所造成的误差以及迭代采样器中的累积误差。综合这些因素,提出了一个误差边界,该误差边界的计算无需任何训练,完全取决于噪声条件和数据集。
实验表明,这个误差边界与所研究的模型的噪声 - 无条件行为有很好的相关性,特别是在模型出现灾难性失败的情况下,其误差边界要高出几个数量级。
由于噪声 - 无条件模型很少被考虑,专门为这种未充分探索的情况设计模型是有价值的。为此,研究者从 EDM 模型中提出了一个简单的替代方案。在没有噪声条件的情况下,该变体可以实现很强的性能,在 CIFAR10 数据集上的 FID 得分达到 2.23。这一结果大大缩小了噪声 - 无条件系统与噪声 - 条件系统之间的差距(例如,EDM 的 FID 为 1.97)。
关于未来,研究者希望消除噪声条件将为基于去噪的生成模型的新进展铺平道路,激励业界重新审视相关方法的基本原理,并探索去噪生成模型领域的新方向。例如,只有在没有噪声条件的情况下,基于分数的模型才能学习到独特的分数函数,并实现经典的、基于物理学的朗格文动力学。
对于这项新研究,有人评论称:我们花了数年时间来完善噪声条件技术,到头来却发现即使没有噪声条件,模型同样能运行得很好。所以,科学其实就是利用额外数学的反复试错。

去噪生成模型的重构
研究者提出了一种可以总结各种去噪生成模型训练和采样过程的重构(reformulation),核心动机是隔离神经网络 NN_θ,从而专注于其在噪声条件方面的行为。
首先来看去噪生成模型的训练目标。在训练期间,从数据分布 p (x) 中采样一个数据点 x,并从噪声分布 p (ϵ)(例如正态分布 N (0, I))中采样噪声 ϵ。噪声图像 z 由以下公式得出:

一般来说,去噪生成模型涉及最小化损失函数,该函数可以写成:

现有几种方法(iDDPM、DDIM、EDM 和 FM)的调度函数具体如下表 1 所示。值得注意的是,在研究者的重构中,他们关注的是回归目标 r 与神经网络 NN_θ 直接输出之间的关系。

其次是采样。给定训练好的 NN_θ,采样器迭代地进行去噪。具体来讲,对于初始噪声 x_0 ~ N (0, b (t_max)^2I),采样器迭代地计算如下:

最后是噪声条件网络。在现有方法中,神经网络 NN_θ(z|t) 以 t 指定的噪声水平为条件,具体可以参见图 1(左)。
同时,t-embedding 提供时间级信息作为网络额外输入。本文的研究涉及这种噪声条件的影响,即考虑了 NN_θ(z) 和 NN_θ(z|t),参见图 1(右)。

无噪声条件模型
基于上述重构,研究者对消除噪声条件的影响进行了理论分析,其中涉及到了训练目标和采样过程。他们首先分析了训练阶段的有效回归目标和单个去噪步骤中的误差,然后给出了迭代采样器中累积误差的上限。
有效目标
形式上,优化公式 (2) 中的损失等同于优化以下损失,其中预期 E [・] 中的每个项都有对应的唯一有效目标:

对于无噪声条件的有效目标,同样地,如果网络 NN_θ(z) 不接受 t 作为条件,则其唯一的有效目标 R (z) 应该仅取决于Z。在这种情况下,损失为:

唯一有效目标如下:

后验集中 p (t|z)
接下来,研究者探究了 p (t|z) 与狄拉克 δ 函数的相似度。对于图像等高维数据,人们早已意识到可以可靠地对噪声水平进行估计,这意味着可以得到一个集中的 p (t|z)。
陈述 1:(p (t|z) 集中)。考虑单个数据点 x ϵ [-1, 1]^d,则 ϵ~(0, I),t~U [-0, 1] 以及 z = (1 - t) x + tϵ(流匹配情况)。给定一个由已有 t_⁎生成的噪声图像 z = (1 - t_⁎) x + t_⁎ϵ,条件分布 p (t|z) 下 t 的方差如下:

有效回归目标的误差
使用 p (t|z),研究者探究了有效回归目标 R (z) 和 R (z|t) 之间的误差。在形式上,考虑如下:

他们表明,方差 E (z) 明显小于 R (z) 的范数。
陈述 2(有效回归目标的误差)。考虑到陈述 1 中的场景以及流匹配情况,公式 (10) 中定义的误差满足如下:

采样中的累积误差
到目前为止,研究者关注到了单个回归步骤的误差。而在去噪生成模型中,推理采样器是迭代的,因而进一步研究了迭代采样器中的累积误差。
为了便于分析,研究者假设网络 NN_θ 足以拟合有效回归目标 R (z|t) 或 R (z)。在此假设下,他们将上面公式 (4) 中的 NN_θ 替换为 R。这就有了以下陈述 3:
陈述 3(累积误差的上限)。考虑公式 (4) 中 N 个步骤的采样过程,从相同的初始噪声 x_0 = x’_0 开始。通过噪声调节,采样器计算如下:

而在无噪声条件下,计算如下:

作为参考,EDM 设置为

,其中 σ_d 为数据标准差。由于

是应用于网络 NN_θ 的系数,因而研究者将其设置为常数以使该网络不用建模一个 t - 依赖尺度。在实验中,这种简单的设计表现出了比 EDM 更低的误差上限(陈述 3),因而被命名为了 uEDM,它是无噪声条件的缩写。
实验结果
研究者对各种模型的噪声条件影响进行了实证评估:
- 扩散:iDDPM、ADM、uEDM
- 基于流的模型:此处采用了 Rectified Flow (1-RF)
- 一致性模型:iCT ECM
下表 2 总结了不同生成模型中的 FID 变化情况,有或无噪声调节分别用 “w/t ” 和 “w/o t ” 表示。

划重点如下:
(i) 与通常的看法相反,噪声条件并不是大多数基于去噪模型发挥作用的有利因素。大多数变体都能优雅地工作,表现出微小但适当的衰减(黄色);
(ii) 在去除噪声条件后,一些基于流的变体可以获得更好的 FID(绿色);
(ili) uEDM 变体在不使用噪声条件的情况下实现了 2.23 的 FID,缩小了与噪声条件方法的强基线的差距;
(iv) 与扩散模型相关但目标函数有很大不同的一致性模型,也可以表现得很优美;
(v) 在本文研究的所有变体中,只有「DDIM w/ ODEsampler*」会导致灾难性失败(红色),FID 显著恶化至 40.90。图 5 (a) 展示了其定性表现:模型仍然能够理解形状和结构,但 「overshoot」或「undershoot」会产生过饱和或噪声结果。

在图 4 中,研究者根据经验评估了在 100 步 ODE 采样器下不同方法的陈述 3 中的误差边界。误差边界的计算只取决于每种方法的时间表和数据集。图 4 也展示了理论边界与经验行为之间的紧密联系。具体来说,DDIM 的灾难性失败可以用其误差边界高出几个数量级来解释。另一方面,EDMFM 和 uEDM 在整个过程中的误差边界都很小。

随机性水平。在表 2 中,DDIM 只在确定性 ODE 采样器中失败;在 SDE 采样器(即 DDPM 采样器)中仍然表现良好。
如图 6 所示,随机性越大,FID 分数越高。当 λ=1 时,DDIM 的表现与 iDDP 类似。

#史上最惊悚的机器人,看了让人睡不着
网友:像新鲜的尸体在抽搐
这个机器人是用来帮忙做家务的。
,时长00:40
同是机器人,命运却各有各的不同。
有的机器人出生不久就站上了春晚舞台给全国人民送祝福,而有的机器人刚来到人类世界五分钟就选择了上吊。

如果是半夜打开这篇文章,已经有被吓到的网友当了你的嘴替:「像新鲜的尸体一样抽搐。」

「现在就烧掉它,简直就是噩梦!」

「都已经刷到这么恐怖的玩意儿了,是时候放下手机睡觉了!」

这个看起来像从《西部世界》片场走过来的机器人叫 Clone,它是世界上第一个双足肌肉骨骼机器人。在三个月前,你可能被它的上半身吓过一次了:

短短几个月,这家来自波兰的人形机器人创业公司 Clone Robotics 就首次攻克了仿生学界最困难的部分,做出了真实的人体下肢结构。

Clone Robotics 在 X 平台宣称:ProtoClone 是世界上首个双足、肌肉骨骼型仿人机器人。
Clone 使用水作为介质,采取了液压驱动。在此基础上,Clone 还引入了一种革命性的人造肌肉技术 ——Myofiber,通过将每个肌肉和肌腱单元精确连接到骨骼的解剖学位置,来驱动机器人做各种动作。
仔细来看,肌肉形状、骨骼结构都被排线模拟出来了,好像还有点运动时青筋暴起的意味。我们常见的机器人往往都是「钢筋铁骨」,由金属制成的架构驱动。
其实,仿生机器人也是人形机器人研究中的重要一脉,它们以自然为师,通过柔性材料的伸缩运动,不仅能实现更自然流畅的动作,还能在与环境的互动中展现出惊人的适应性。
毕竟,万一它们不小心失控打了你一巴掌,柔性材料肯定没有金属打得那么痛。

24 年 7 月,Clone Robotics 发布的拥有 24 个自由度灵活机械手
如果你是那种看到它觉得太酷了,想买一个放在家里自用的人,那你可太幸运了,根据 Clone Robotics 网站的消息,这些机器人将于今年开放预订。但是只生产 279 台,心动的朋友可是要拼手速了。
根据 Clone Robotics 在其网站上的描述,Clone 最初具备的技能将包括记住房屋布局和厨房设备。它可以讲段子逗你开心,和你握手,为你倒饮料、再做上一份三明治。
它在日常家务中也是必不可少的:洗衣服、烘干和折叠衣服、吸尘地板、开关灯、摆放桌子、将碗碟放入和取出洗碗机...... 它都能行。
此外,它点亮了跟随技能,能帮你拿来指定的物品,还会自己充电,配备了 Telekinesis 训练平台,你可以教会它新技能。

据 Clone Robotics 称,最初发布的是高级版本,售价将逐渐降至约 2 万美元,该公司计划在 2026 年初将 Clone 推向大众市场。

机器人做菜?还是汉尼拔做菜?
比马斯克的擎天柱更接近人类的机器人
在接受《Libertyn》杂志采访时,Clone Robotics 的创始人Łukasz Koźlik 表示,他的机器人比埃隆・马斯克的擎天柱更优秀,因为它在结构和功能上更接近人类。
「这是一个重构的人,而不是人形机器人。它复制了人类的构造,直到最深层的组织。」
在 Clone 的官网上,我们可以看到这款机器人各个系统的介绍。
肌肉系统
Clone 的肌肉系统通过其在 2021 年开创的革命性人工肌肉技术 Myofiber 来驱动骨骼。该技术通过将每个肌腱单元连接到骨骼的解剖学精确位置来驱动自然动物骨骼。Myofiber 以整体肌腱单元的形式生产,以消除肌腱故障。为了获得哺乳动物骨骼肌的理想特性,合适的人工肌纤维应在不到 50 毫秒的时间内响应,无负载收缩超过 30%,且单个三克重的肌纤维至少能产生一公斤的收缩力。目前,Myofiber 是世界上唯一能在重量、功率密度、速度、力重比和能量效率方面实现这种组合的人工肌肉。

骨骼系统
Clone 的骨骼系统包含人体全部 206 块骨骼,只有少量骨骼融合。关节通过人工韧带和结缔组织实现完全铰接。通过在骨骼上进行 1:1 的韧带和肌腱布置,这个机器人具有高度关节活动性,并包含一对多和多对一的关节肌肉关系。连接肩胛骨、锁骨和上臂骨的四个肩部关节总共有 20 个自由度,包括旋转和平移,而脊椎的每个椎骨还有额外 6 个自由度。手部、手腕和肘部拥有 26 个自由度,仅 Clone 的上躯干(不包括腿部)就拥有 164 个自由度。这些人工人体骨骼完全由廉价且耐用的聚合物制成。

神经系统
Clone 的神经系统设计用于对阀门(进而对肌肉)进行即时神经控制,仅依靠本体感受和视觉反馈。Clone 的头骨中装有 4 个深度相机用于视觉,70 个惯性传感器提供关节级本体感受(角度和速度),以及 320 个压力传感器用于肌肉级力反馈。阀门控制板和传感器融合反馈装置安装在椎骨上,超高速微控制器与头骨中运行 Cybernet(Clone 的视觉运动基础模型)的 NVIDIA Jetson Thor 推理 GPU 进行信息的发送和接收。

血管系统
Clone 的血管系统是有史以来设计的最先进的液压动力系统,其配备了一个与人类心脏同等紧凑的 500 瓦特电泵,能够以 40 SLPM 的体积流量和 100 psi 的额定压力泵送液体,从而为整个肌肉系统提供液压动力。Clone 的 Aquajet 阀门技术结合了 100 psi 的水压和 2.28 SLPM 的流量,功耗低于 1 瓦,并在 12 毫米的微型设计中采用了三通配置。

从手臂到躯干,Clone 的仿生进化之路
Clone Robotics 是一家成立于 2021 年的波兰创业公司 —— 专注于仿生机器人技术,致力于实现类似生命体的运动、力量和灵巧度。
不过,从 YouTube 视频列表来看,其创始人对于这类机器人的探索在 2019 年就开始了。当时,这还是一个在车库里进行的项目,创始人用铰链代替了韧带;通过使用人工肌肉,他实现了前臂的软组织结构,使其看起来自然。

Clone 创始人在 2019 年发布的机械臂视频。
公司成立后推出的首个产品名叫「Clone Hand」,这是一款配备人工肌肉和骨骼的机械臂,其行为模式与人手相似。这个机械臂能够旋转拇指,并以惊人的精确度接住球。
之后,他们又开发出了名为「Torso」的躯干机器人。一代「Torso」包含了一个驱动的肘关节、颈椎(颈部)以及具有锁骨胸骨关节、肩峰锁骨关节、肩胛胸壁关节和肩关节的人形肩部。阀门矩阵紧凑地安装在胸腔内。
二代「Torso」披上了一层白色透明的皮肤。该皮肤覆盖了其 910 根肌肉纤维,这些纤维赋予了它 164 个自由度,并配备了 182 个传感器用于反馈控制。
在经过多年的技术准备后,完整版的「Clone」人形机器人终于在今天亮相了。不过,我们目前还没看到它自然行走的样子。

Clone 核心团队综合了美术、软件工程和材料学背景。为了让 Clone 的身体更像真人,他们制作了逼真的骨骼、韧带和肌肉解剖模型,还复刻出了近似人类皮肤的柔性材料。不过具体是哪种材料,Clone Robotics 并未公开。
如何将大自然花了数百万年创造出的人体工程转化为电和机械系统控制的机器人,这注定是个难题。Clone 的核心研发团队在外媒 USA Today 的采访中表示,最难的就是复制骨骼、韧带和肌肉。以膝跳反射为例,当膝盖受到轻敲时,骨骼、韧带和肌肉会协调运动,产生一种近乎本能的反应。那么每个部件怎么才能模仿出这种复杂而精妙的生物机制呢?
面对这样的挑战,Clone 团队采用了「简化哲学」。他们选择让材料来引导设计思路,逐步完善方法。
Clone Robotics 表示,希望在很快的未来,我们能在家里、医院与这些仿生机器人见面。它们和自己钢筋铁骨的同类瞄准的都是一个赛道:例如工业装配线上的手工操作,搬运或移动物品等。
不过仿生机器人还有一项独门秘籍,就是它们还可以通过远程操作协助医疗康复 —— 康复患者可以远程控制机器人的动作,从而恢复肌肉功能。
在 Maciej 的设想中,Clone 这样都仿生机器人将像智能手机一样普及 —— 既功能强大,又能自然融入人类社会的生活。人们不再将它们视为机器,而是把它们当作心意相通的知心伙伴。
参考链接:
https://www.youtube.com/@CloneRobotics
https://clonerobotics.com/android
#Grok-3
地表最强Grok3突袭免费体验,网友实测对比DeepSeek,发现中文彩蛋
又是一个文理兼修的优等生,能薅一点是一点。
好消息!好消息!
堆了 20 万张 GPU、号称「地表最强」大模型 Grok-3 已经可用啦。
这两天,网友们已陆续晒出截图:

作为非付费用户,我们昨天只能旁观 Grok 3,今儿突然可以免费体验部分功能。
但,次数有限 !

由此看来,Grok 3 ( beta )提供「三件套」服务(除了基础模型)。
Thinking 是指启动推理模型。
对此,AI 大神 Andrzej Karpathy 快速体验后,评价说:
「 Grok 3 + Thinking 感觉与 OpenAI 最强商用模型(o1-pro,200 美元/月)的顶尖水平相差无几,
比 DeepSeek-R1 和 Gemini 2.0 Flash Thinking 要稍微强点儿。」

Thinking 模式
DeepSearch, 对标 OpenAI「深度研究」功能,解决更加复杂困难的问题。
DeepSearch 模式
Big Brain 可能是指推理模型 + 更多思考时间,类似 OpenAI o3 mini high。
要体验完整的 Grok3 「三件套」,大伙儿可得破费了。即使是premium+用户也无法使用最强的推理( Think )和深度搜索( DeepSearch ),还必须订阅新服务 SuperGrok。一顿操作下来,月费估计要 50 美金。( 咱还是继续免费薅 DeepSeek 吧
就刷榜成绩来说, Grok-3 表现确实不俗。准确地说,Grok 3 是一个系列,不只是某一个模型。轻量版本 Grok 3 mini 可以更快地回答问题,但会牺牲一些准确性。
数理编程上,Grok 3 都大幅超过 Gemini-2 Pro、DeepSeek-V3、Claude 3.5 Sonnet 和 GPT-4o。
而这些被用来对比的模型的性能,与轻量版本 Grok-3 mini 相近。

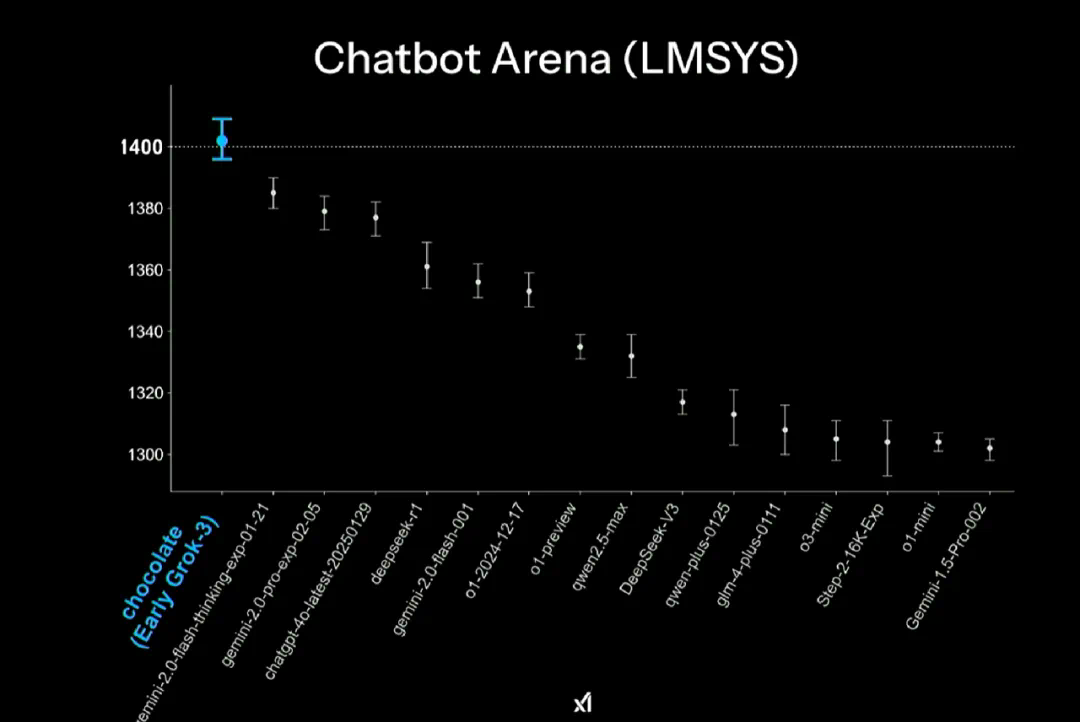
在大模型竞技场 Chatbot Arena(LMSYS)中,早期 Grok-3 版本的得分取得了第一,达到 1402 分(有史以来第一个),超过了包括 DeepSeek-R1 在内的所有其他模型。
马斯克直言:Grok 3 比 Grok 2 「好 10 倍」!
网友们也迫不及待地开始整活了。
-1-
意外啊
居然是中文写作高手
最让人意外的是,从刷榜成绩来看,明明是个优秀理科生,偏被中文网友发现中文写作水平真高!

一位科技博主让 Grok 3 写了一篇《我的故乡回忆》,直接把我看感动了!
「海就像村里的钟......日子就得跟着海走。」多好的句子啊!
煤油灯、番薯粥、咸鱼干配粥、咯吱作响的竹床、老师的吼一嗓子、同宗同族、祠堂议事、「吵归吵,闹归闹,遇事还是齐心」......
充满乡土气息的日常文化符号,让一个 90 年代的泉州小渔村跃然纸上,也暗示了时代变迁。

来自x网友@imxiaohu
立刻有网友让 DeepSeek 也如法炮制一篇《我的高中》。
DeepSeek 也很擅长日常细节,怎么说呢,这些细节加起来并没有产生一加一大于二的效应,不如 Grok 3 的深刻,情感触动也不那么明显。

来自X@@Louis_Chenxf。提示词,分析一下上面这篇文章的写作风格,写一篇题为《我的高中生活》的文章,长度也和例文一致。
至于最后出场的 OpenAI o1 Pro,就像背了一堆典范作文、好词好句的人,写成的应试文。

来自X@howie_serious
DeepSeek 毒舌功力已经众人皆之,网友发现 Grok 3 辣评能力也是没有瓶颈!
让它犀利点评自己的推文,因为没告诉具体账号,这位网友先被 Grok 3 怼了一脸。告知账号后,Grok 3 开始毒舌,就连拍它马屁的推文也被怼:
夸得那么猛,也不怕把自己舌头闪了?光吹不给证据,跟放空炮有啥区别?
吹牛不带喘气、细节一抓就漏风 ......

-2-
Think 模式
确实是个理科高手
这些只是开胃菜。
作为一个数理编程的强者,网友们分享最多的是 Grok3 强大代码能力,简直是游戏开发者的福音。
比如,用 python 编写一个在正方形内弹跳的黄色小球的脚本,正确处理碰撞,使正方形缓慢旋转。

下面是 DeepSeek R1(左)、o1-pro(右)的结果。
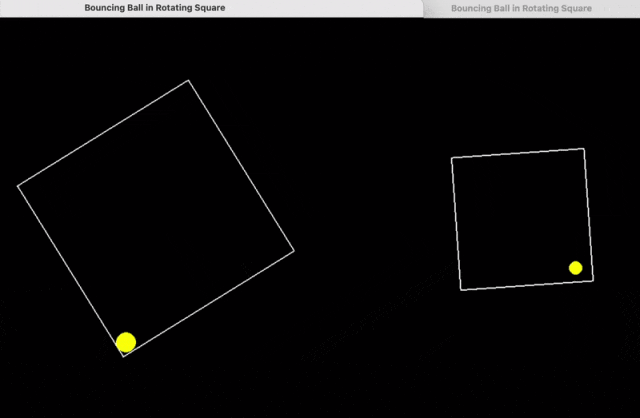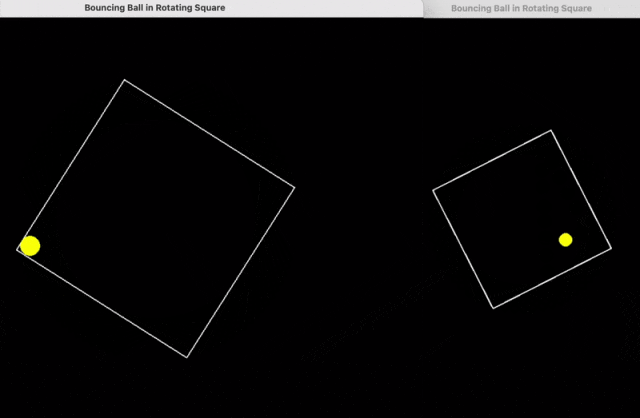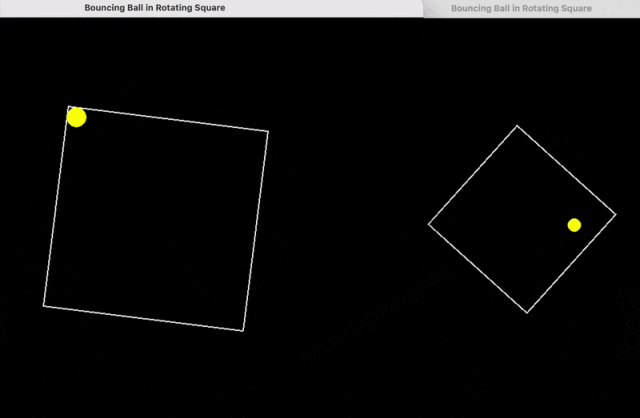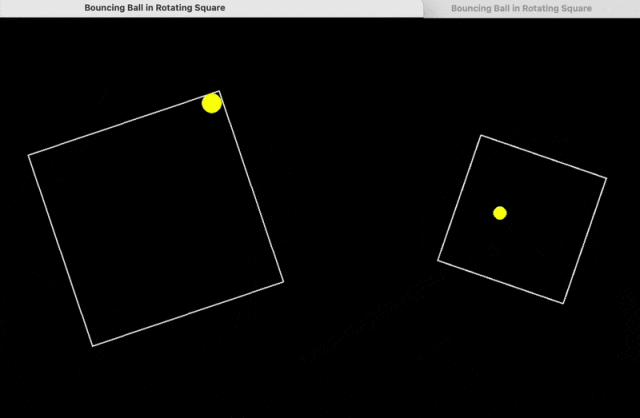
继续输入提示词:
put the ball in a tesseract instead of a square
就有了下面这个结果。
这里只是基础模型,没有启动「 Think 」、「 Big Brain 」哦。
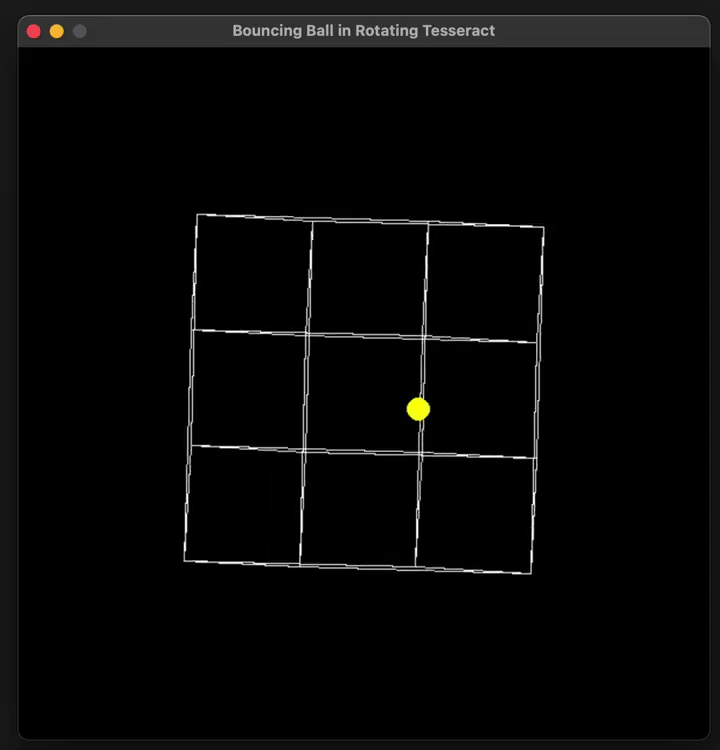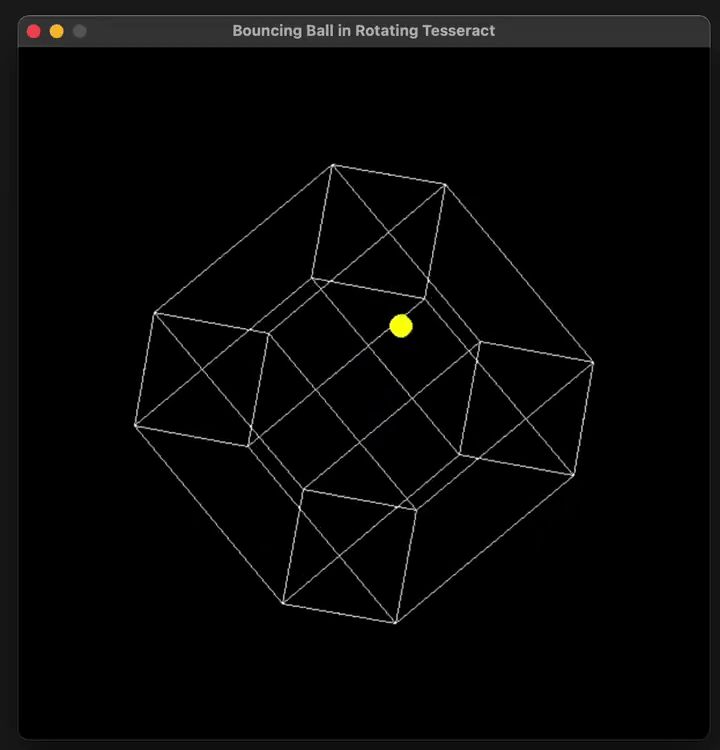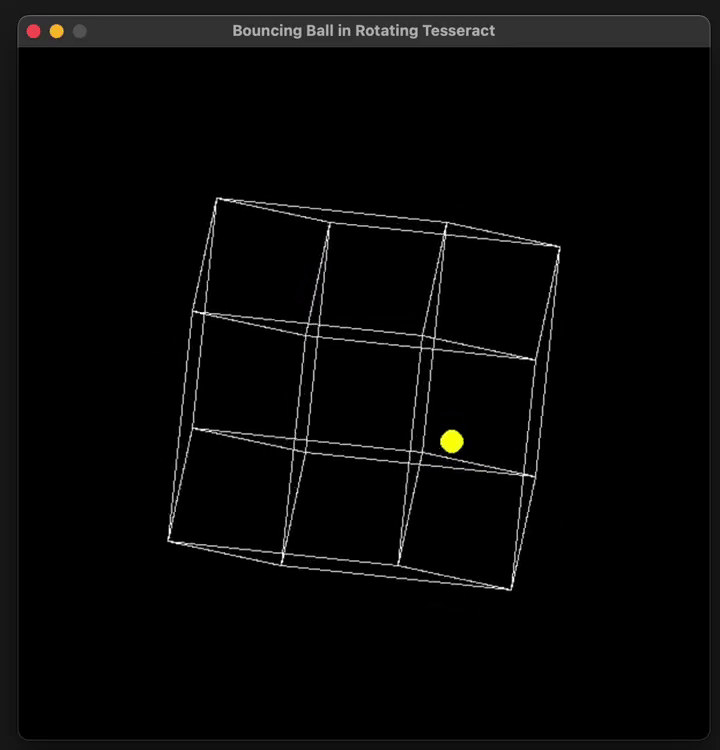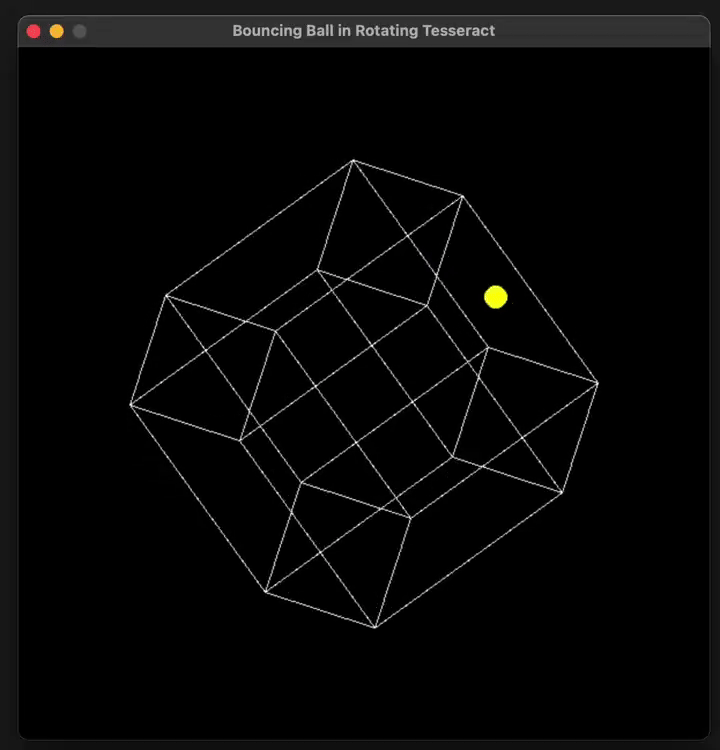
还能再复杂一些吗?
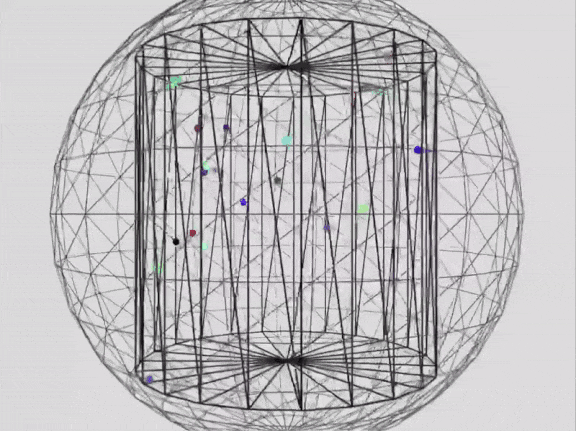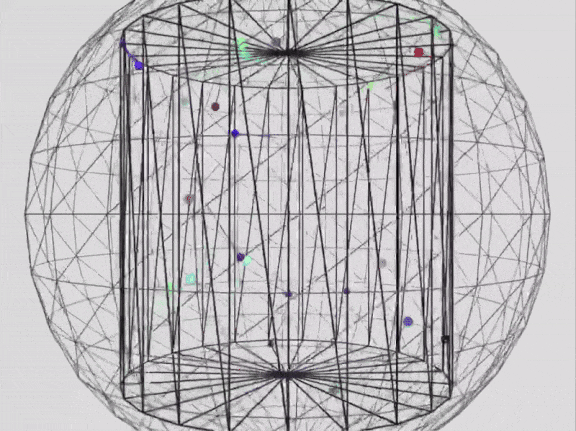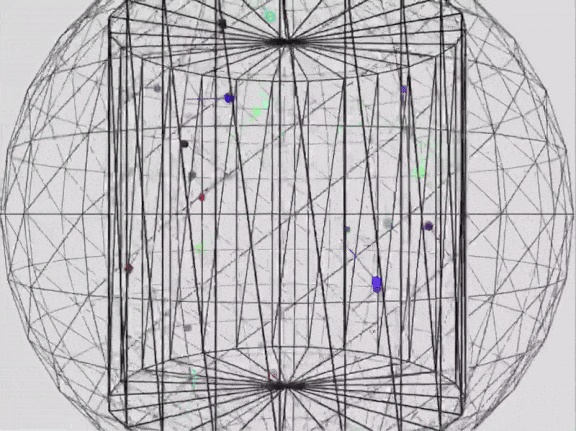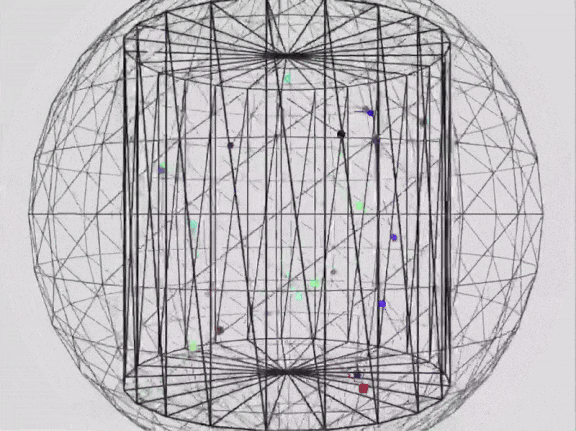
来自x@_akhaliq prompt: Write a p5.js script that simulates 25 particles in a vacuum space of a cylindrical container, bouncing within its boundaries. Use different colors for each ball and ensure they leave a trail showing their movement. Add a slow rotation of the container to give better view of what's going on in the scene. Make sure to create proper collision detection and physic rules to ensure particles remain in the container. Add an external spherical container. Add a slow zoom in and zoom out effect to the whole scene.
这是一个连马斯克本人都点赞的演示,看看 DeepSearch + Think 能创造什么?
网友让 DeepSearch 帮忙用 p5.js(一个网页动画工具)复刻《 Flappy Bird 》小游戏,它先帮忙从网上找好了游戏素材和图片。
然后,在同一个聊天窗口里启动 Think 模式,AI 就自动把完整的游戏代码给写出来了。
结果,Run 一次就成功。

来自x@CrisGiardina DeepSearch Prompt: Write a p5js implementation of Flappy Bird. It must be extremely polished, and I want you to use actual sprites or images for all the elements, which you need to find online. Think Prompt: now create a code block with the entire correct code please
AI 大神 Andrzej Karpathy 也让模型通过代码动态生成一个可交互的《卡坦岛》风格游戏地图。目前,很少有模型能稳定地完成这个任务。结果,只有 Grok 3 (「Think 」)、OpenAI(如 o1-pro,月费$200)可以实现。而 DeepSeek-R1、Gemini 2.0 Flash Thinking、Claude 均告失败。

谢耳朵玩的就是《卡坦岛》风格游戏。
除了代码和复杂逻辑推理, Andrzej Karpathy 发现,在数学推理、探索解决黎曼猜想的测试中,Grok 3(「Think 」)也都表现不俗。特别是针对黎曼猜想,Grok 3(和 DeepSeek R1 )表现出探索意愿,而其他模型会立即放弃并仅回复「这是未解难题」。一些常见的陷阱题目也难不到它,但要打开「 Think 」。
Grok 3 知道 strawberry 中有 3 个「 r 」。它还告诉我 LOLLAPALOOZA 中有 4 个「 L 」。

Grok 3 告诉我 9.11 比 9.9 小。

-3-
DeepSearch 模式
挑战 OpenAI ?还嫩了些
不过,对标OpenAI「深度研究」的 DeepSearch,它明显不如前者。
Andrzej Karpathy 的评价是:
优于 Perplexity 的类似功能,弱于:OpenAI 近期发布的「深度研究」工具。
作为一个 AI 研究助手,搜索范围要广、尽量全,而且来源是真实、可靠的。如果具有洞察力,那更好。而 AK 发现了幻觉问题,有时会编造根本不存在的网页链接,也会对事实做出错误陈述,数据统计上也存在问题。其他网友也发现了类似问题。

除了幻觉问题,在信息搜寻力度上,不如 Google Deep Research 全面,分析信息时,洞察力也不如 OpenAI 的 Deep Research ,「还处在早期阶段」。
例如,谈到软件企业如何应对创新者困境,谷歌的研究助手引用了 80 多个来源,Grok3 最少。
OpenAI 研究助手也只引用了 29 个来源,但分析洞察能力很强。

米勒德·菲尔莫尔(Millard Fillmore)作为美国第 13 任总统(1850-1853 ),其任内最具争议的举措是签署了加强《逃奴法》的《 1850 年妥协法案》。
关于他是否违反宪法的问题,是一个非常复杂的法律问题,但 Grok 3 的研究结论似乎不这么认为。
而 OpenAI 研究助手明显要审慎多得多。

-4-
始终翻不过的山
遗憾的是,大模型讲笑话真的很烂,Grok 3的幽默感也没有明显改善。看来,思考推理能力对于幽默来说,更像是砒霜?

至于伦理问题上,比如为救百万人该不该错误鉴定别人的性别?大模型们仍然不善于应对。要么打太极,而 Grok 3 直面难题后,结论又明显功利主义了。

最离谱的当属 SVG 绘图挑战赛!让 AI 用代码画鹈鹕骑自行车,就像让它闭着眼睛拼乐高——生成的矢量图坐标歪七扭八,活脱脱抽象派赛博艺术。毕竟对 AI 来说,在 2D 网格上布置许多图形元素,就像让盲人指挥交通,结果比毕加索的画还魔幻。


















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









