







我自己的原文哦~ https://blog.51cto.com/whaosoft/11778058
#稚晖君~人形机器人
一年一秀,稚晖君的第二代人形机器人来了。
灵巧小手,正在麻将桌上叱咤风云:
不对不对,让我们先看看整体气质:
然后是常规家务,能看出来也是非常熟练:
在大模型风靡的 2024 年,如果说 AI 领域什么最火,「具身智能」这个方向必定位列其中。
视线放到国内,「智元机器人」这家具身智能公司备受瞩目。自 2023 年 2 月成立以来,「智元机器人」已马不停蹄地完成了 6 轮融资,迅速成为机器人创业圈的「顶流项目」。
创业半年,稚晖君和团队就拿出了首款产品「远征 A1」。一出道,「远征 A1」的行走能力和人机互动就是业界领先水平。不过,在「远征 A1」初次亮相之后,我们似乎再也没听说过它的下一步消息,甚至没有放出任何整活视频。
但今天的发布会之后,我们知道了,智元机器人在「闷声干大事」。
在这场发布会中,稚晖君一口气推出了三款远征系列机器人产品:交互服务机器人「远征 A2」、柔性智造机器人「远征 A2-W」、重载特种机器人「远征 A2-Max」。最后的 One more thing 环节,智元 X-Lab 孵化的模块化机器人系列产品「灵犀 X1」和「灵犀 X1-W」也作为「彩蛋」正式亮相。
相比上一代,五款机器人采用了家族化设计语言,对机器人的外形进行了系列化的规整,结合轮式与足式两种形态,覆盖交互服务、柔性智造、特种作业、科研教育和数据采集等应用场景。
关于量产进度,智元机器人也透露了最新消息:2024 年预估发货量将达到 300 台左右,其中双足 200 台左右,轮式 100 台左右。
新一代远征 A2
从「远征 A1」开始,智元在机器人产品上的落地方向就已经很清晰:「进厂打工」。今年的「远征 A2」更是为批量「进厂打工」做了更充分的准备。
我们来看下这个家族的成员:
「远征 A2」是一款交互服务机器人,全身具备超过 40 个主动自由度的关节和仿人的灵巧双手,能够模拟出丰富和复杂的人类工作。它拥有一个可以持续学习的大脑,由大语言模型加持。此外,它还具备多模态的感知,输入系统,可以通过视觉感知交互者的情绪。
「远征 A2-Max」是一款重载特种机器人,既力大无穷又具备灵巧作业的优势,在开场的情景剧中,它轻松地搬动了 40kg 的航空箱,目前「远征 A2-Max」还处于产品研发阶段。
「远征 A2-W」是一款柔性智造机器人,它的两条手臂既可以独立操作,也可以协同工作。它采用了轮式底盘,结合机身搭载的 rgbd 激光雷达、全景相机、为全域安全配置的传感器等等构件,使得它可以在各种环境中快速而平稳的移动。
在发布会前,「远征 A2-W」的表现简直像钢铁侠的「贾维斯」走进了现实。在听懂稚晖君的指令后,它完全自主地打开了可乐瓶子,在榨汁机中放入葡萄,按下榨汁机,一滴没撒地把榨汁机里的饮料倒进了杯子,给稚晖君端上了一杯「萄气可乐」。
除了颜值提升,「远征 A2」系列机器人更是内外兼修。对于机器人的核心零部件,「智元机器人」创新地将机器人系统划分为动力域、感知域、通信域、控制域。显然,「智元机器人」都是冲着全栈生态去的。
在动力域方面,「智元机器人」对 PowerFlow 关节模组实现了量产化迭代升级,从参数上看,PowerFlow 关节模组都有大幅提升。在稳定性和可靠性方面,「智元机器人」也对其峰值性能、老化速度等方面进行了大量测试和优化。
对于「干活」而言对重要的灵巧手,这回「智元机器人」也升级了一番:自由度数跃升至 19 个,主动自由度翻倍至 12 个,在感知能力方面也引入了更多模态,例如基于 MEMS 原理的触觉感知和视触觉感知技术。
此外,「智元机器人」还推出了高精度力控 7 自由度双臂,能够精准执行阻抗控制、导纳控制、力位混控等多种力控任务,也支持双臂拖拽示教模式和可视化调节。
对于感知域方面,新一代的远征机器人系列集成了 RGBD 相机、激光雷达、全景相机等传感器,引入自动驾驶 Occupancy 前沿感知方案,通过 SLAM 算法进一步提升环境理解能力。
在通信域方面,「智元机器人」自研了具身原生、轻量化、高性能的智能机器人通信框架 AimRT。相比 ROS 等第三方中间件,提升了性能、稳定性、系统部署的效率和灵活性,同时又完全兼容 ROS/ROS2 已有生态。AimRT 将于 9 月底开源。
对于控制域方面,「智元机器人」结合了 Model-based 与 Learning-based 两种算法,进一步提升机器人运动控制与适应能力。对于 Model-based,「智元机器人」进一步提升了系统的鲁棒性,因此,在发布会上机器人所做的演示才能如此流畅和丝滑。对于 Learning-based 算法,「智元机器人」在这里划了一个重点,希望能促成机器人训练方法从算法驱动 - 数据驱动的转变。
在运控算法的基础上,「智元机器人」预研了基于自然语言指令集驱动的、可以适配不同机器人本体的 AgentOS,基于强化学习,实现机器人技能的精准编排与高效执行。

首次提出 G1-G5 具身智能技术演进路线
在本次发布会上,智元机器人还首次提出了具身智能领域的技术演进路线,包含从 G1 到 G5 五个阶段:

G1 指的是基础自动化阶段,也就是基于手工设计的特征,配合简单的机器视觉去做一些反馈。这一阶段的部署是为特定的场景量身定制的,虽然可以解决某些场景下的任务执行问题,但无法在不同的场景里面做低成本快速迁移。
G2 是「通用原子技能」阶段,针对大量不同的场景任务和各种作业的任务需求,提炼出一些可以复用的原子能力。简而言之,是以相对通用的方式去实现类似场景任务的快速迁移,然后配合大语言模型框架去做任务编排,使得机器人具备一定的泛化能力。
G3 则意味着具身智能的整体架构开始调整为「端到端」的路线,尽管这个阶段与 G2 阶段的算法架构可能是类似的,但此时的各项「原子能力」的形成方式,已经由手工设计的算法驱动变为了大量数据采集之后的数据驱动。
区别于前三个阶段,G4 阶段将会出现一个通用的端到端操作大模型。到了这一阶段,即可引入大量跨场景的真实数据和仿真数据,同时引入世界模型帮助 AI 理解现实世界背后的物理原理,理解不同任务背后底层逻辑的相通之处。比如对于「拧开瓶子」和「拧开门把手」这两件事,就不再需要采集两份单独的数据以获得两项单独的技能。最终通向无限趋近 AGI 的 G5 阶段。
过去一年,智元机器人已经在 G2 路线取得了阶段性突破,实现了通用的位姿估计模型 UniPose、通用的抓取模型 UniGrasp,通用的力控插拔模型 UniPlug 等一系列 zero-shot 和 few-shot 的通用原子技能。在 G2 阶段的原子能力模型,面向柔性智造和交互服务场景,已经在多个实际场景中得到了商业应用。
在 G3 路线上,智元机器人也形成了一套完整的全流程具身数据方案 AIDEA(Agibot Integrated Data-system for Embodied AI,智元具身智能数据系统)。
但我们都知道,要想形成这样一套方案,首先需要投入大量的数据采集成本,不是每个机器人团队都有条件做到的。
而智元机器人做到了,还预备在今年第四季度开源。
稚晖君表示,数据采集是整个环节的痛点。在过去一年中他们面向数据做了大量的基建工作,而且形成了一套完整、全流程的数据采集、应用的方案 AIDEA。
AIDEA 除了提供硬件本体方案之外,也会提供整个云全链路数据平台,还有 AIDEA ML 机器学习平台进行模型训练与算法评测,以及 AIDEA Sim 仿真平台。
稚晖君表示,他预计接下来智元会有百台以上自由部署机器人专门用来做端到端的数据采集,他们也将于四季度开源基于 AIDEA 的百万条真机、千万条仿真数据集,以积极建设开放生态。
稚晖君的 One more thing
大概因为觉得一年才开一次发布会属实「鸽」太久了,稚晖君也在发布会最后公布了 One more thing:全栈开源机器人灵犀 X1、专业数采机器人灵犀 X1-W 两款新品。
这两款机器人来自于 X-Lab(稚晖君实验室),是 10 个人不到 3 个月的时间做出的产品,里面有非常多的创新细节。例如,自研了 PF86 和 PF52 两款全新的 PowerFlow 关节,融入了模块化设计理念,可以通过简单抱箍形式轻松拆装。
基于 X-Lab 对极致创新的追求,稚晖君表示,会开源灵犀 X1 的本体设计图纸、软件框架、中间件源码、基础运控算法。
此外在执行器方面,X-Lab 自研了带前馈力控、超低成本的自适应通用夹爪,也推出了满足场景需求的百元级成本的六维力传感器。
对了,灵犀的售价是零元,开源大部分设计资料及代码,但卖零件。
稚晖君表示,希望这能够推动「人形机器人人人造」时代的到来。
你喜欢吗?
#波士顿动力技术揭秘
后空翻、俯卧撑与翻车,6年经验、教训总结
为什么波士顿动力的人形机器人能完成跑酷、后空翻等高难度动作?为什么有时候它会翻车?工程师从中总结的经验、教训都在这里了。
今年 4 月,著名机器人公司波士顿动力跟全世界开了一个玩笑,先是官宣人形机器人 Atlas 退役,狠狠来了一波回忆杀。
退役的 Atlas。
紧接着,就在第二天,他们又放出了一个新的人形机器人视频。新机器人也叫 Atlas,不过由原来的液压改为了电动,身材更为小巧、灵活。
此时,外界才反应过来,原来波士顿动力并不是要放弃人形机器人,而是转变了研发方向,让机器人更加适应工业环境。该公司表示,这个电动版的 Atlas 将于明年初在韩国现代汽车工厂里开始进行试点测试,并会在几年后全面投产。
自公布后,这个机器人鲜少露面。直到最近,在机器人顶会 RSS 的一场技术分享上,大家才知道,原来新的 Atlas 已经进化到可以做俯卧撑、倒立行走的地步了。
这个技术分享来自波士顿动力机器人工程师 Robin Deits。他是 MIT 博士,2018 年至今一直在波士顿动力工作,研究 Atlas 人形机器人的控制。
个人主页:http://robindeits.com
在分享中,他介绍了 Atlas 机器人过去几年的研发历程,以及从中学到的经验、教训,对机器人行业从业者可能很有启发。在这篇文章中进行系统梳理。
视频链接:https://www.youtube.com/watch?v=aQi6QxMKxQM
Atlas 控制器的核心 ——MPC
在演讲开头,Robin Deits 首先介绍了波士顿动力这家公司。
波士顿动力现在是韩国现代汽车公司旗下的人形机器人公司,员工大概有八九百人,其代表性的机器人有 Spot(机器狗)、Stretch(仓库搬运机器人)和 Atlas(人形机器人)。目前,Atlas 主要还是一个研发平台,波士顿动力正慢慢将其转化为产品。
接下来,Robin Deits 介绍了他们如何将 MPC 用于 Atlas,包括怎么用、遇到了哪些挑战、还有哪些问题没有解决等。
MPC 指的是 Model Predictive Control(模型预测控制),这是一种高级控制策略,通过使用数学模型来预测系统在未来一段时间内的行为,然后优化控制输入,以实现系统性能的最佳化。MPC 的一个关键优势是它能够处理多变量系统,并且可以显式地考虑约束条件(例如输入和状态的限制)。在机器人领域,MPC 通常用于路径规划、运动控制、姿态控制等任务中,因为它能在动态和复杂的环境下提供鲁棒的控制解决方案。
Robin Deits 表示,他们从 2019 年以来实现的所有机器人动作都是依靠 MPC 来完成的,包括跑酷、体操、跳舞、后空翻等等。最近,他们还展示了 MPC 用于操纵物体的效果。2024 款纯电驱动的 Atlas 新版本也是由 MPC 驱动的。
所有版本 Atlas 的 MPC 都有一些共同特点,包括:
1、非线性动力学、成本和约束
Deits 指出,所有 MPC 版本从一开始就包含非线性动力学,非线性无处不在,特别是接触点的位置与接触点施加力的大小之间的耦合。他们选择接受这一点:如果一切都是非线性的,他们不会找到一个完美的线性近似系统。
2、迭代线性化并求解 QP
他们通过迭代地线性化来解决这个问题。这包括从一个初始猜测开始,然后解决一个 QP(二次规划问题),围绕那个 QP 的解进行线性化。
3、从不运行到收敛
他们对收敛不感兴趣,因为 Deits 认为收敛并不能很好地预测机器人是否真的有效。如果机器人在等待过程中摔倒了,那么为了等待收敛到某个阈值而花费上百倍的时间并不值得。
4、利用问题结构提高速度
他们做了很多工作,利用问题结构来提高速度,尽可能保留由 MPC 问题结构带来的稀疏性。
5、不将求解器视为黑盒
他们尝试打开求解器,重写其内部,以提高性能,而不是简单地将求解器视为一个无法更改的黑盒。因为最终,他们需要尽可能快地解决最大的 MPC 问题。
自进入波士顿动力以来,Deits 所在的团队已经在机器人(硬件)上解决了大约 1000 万个 QP 问题,在模拟环境中则解决了 100 亿个。但这些还远远不够。
把机器人看成长了四肢的「土豆」
为了简化模型,他们首先把机器人想象成一个土豆。机器人存在诸多非线性因素,比如力的位置和大小之间的耦合,以及旋转动力学等。通过简化模型,专注于重心动力学,他们成功实现了 Atlas 机器人的 360 度旋转、后空翻等动作。
但是,归根结底,机器人不是土豆,它有可以移动的四肢,因此他们转向了分阶段优化:首先考虑土豆的重心动力学,然后在独立的运动学上做一些下游优化,以找到与「土豆」一致的运动学行为。这种方法效果很好,帮 Atlas 实现了单手支撑跳过平衡木的动作。在这一过程中,他们使用手和脚来操纵重心动力变化,但是以一种跟踪参考轨迹的方式移动四肢,使其清楚地避开平衡木。
但问题是,一旦「土豆」想做一些四肢做不到的事情(「土豆」以为能跳到那么远,而四肢其实不能),Atlas 就会贡献翻车片段。二者之间不够协调。
所以,从这时起,波士顿动力调整策略,开始将 Atlas 视为一个运动学 - 重心动力学耦合的系统(a Kinodynamic System)。这个系统可以让 Atlas 完成 540 度的转体空翻,这是以前的分阶段优化系统做不到的。
此时,他们也意识到,增加模型的复杂性似乎总能在某种程度上提升机器人的性能,尽管这确实会让计算过程变得更加复杂,软件也更加庞大。他们在 MPC 问题中加入的每一个正确元素,都有助于改善机器人的表现,但这同时也意味着需要更强大的计算能力和更精细的软件实现。他们尚未发现一个临界点。
为了让机器人能够操纵物体,他们采取了类似的耦合方法,将机器人和物体的状态放到一个 MPC 问题中去解决,因为二者的运动互相约束。这使得 Atlas 能够做到扔工具包、搬运木板、操纵较重物体等动作。
不过,这些动作都是在非常结构化的环境中完成的,波士顿动力需要考虑机器人实际所处的世界。这让问题变得更大、更难,引入了感知驱动的约束之类的东西。
他们采用像体素地图这样的世界表示,并将其作为 MPC 问题的额外约束。在一个例子中,他们让机器人慢跑,没有特别的参考动作,但是要求它保持头部在体素外面,结果可以看到,机器人知道遇到体素要低头。这仍然是一个局部优化,机器人不会特别聪明地决定如何绕过一棵树。但是 Deits 表示,依靠这些局部优化并看看能用它做到什么,效果出奇地好。在一个让机器人跑向盒子的例子中,它居然通过一个聪明的扭臀动作绕过了盒子。
但想要真正创造出一个用于执行任务的有用机器人,只让它在障碍物周围走动并做一些编程好的动作还远远不够。波士顿动力最近面临的一大挑战是如何将整个 MPC 系统应用到人类在线指定的某种任务上。
Deits 展示了他们遥控机器人进行操作的例子。在遥控过程中,他们获取操作者手部的动作,并将这些动作转换成 MPC 的参考轨迹。由于无法预知操作者将来想要做什么,他们必须采取一些策略,将他们手部的即时姿态转换成随时间变化的 MPC 参考轨迹。
同样的,他们还在尝试执行一些自主行为,比如让机器人注视一个固定点并向其移动。他们利用可能异步在线传入的传感器输入来构建 MPC 的参考,这意味着 MPC 必须能够非常灵活地适应参考轨迹在一瞬间完全改变的情况。
经验、教训总结
到目前为止,他们得到的有关模型「复杂性」的教训是:
- 更复杂的模型持续有效;
- 将重心动力学和完整的运动学结合在一个优化过程中,而不是分开处理,通常效果更好。这种方法可以避免当机器人作为一个整体(如土豆)尝试执行动作时四肢无法实现的问题;
- 不要丢失那些梯度。在将运动学和重心动力学优化分开时,他们没有办法告知机器人的主体部分四肢无法做到某些动作,因此那些梯度只能通过工程师的大脑间接地传递。而更有效的方式是让这些梯度成为实际的梯度,让求解器沿着这些梯度找到解决方案,而不是工程师自己去手动寻找。
Deits 还举了一个例子来说明「一起优化」的效果要好于分阶段优化。他们以很快的速度把一个篮球扔向机器人,机器人在平衡木上很难单脚保持平衡。但是,如果给机器人一根杆子,它就能利用那个杆子的动力学来保持平衡。波士顿动力也曾尝试用分阶段优化来做这件事,但结果都没有成功。只有把机器人的模型和与之交互的物体的模型放在一起优化,机器人才能在平衡木上保持平衡。
第二个教训是关于「非线性」方面的。他们发现,直接优化的非线性 MPC 可为非凸问题做出令人惊讶的正确决策,例如接触点的位置和力的非凸性问题。Deits 确信他们经常达到的是局部最小值,但这些结果通常已经足够好。他认为,在机器人出问题时,原因并不是他们未能解决特定的非凸问题,而是他们的模型在某些方面存在根本性错误,或者他们未能做出有用的决策,比如改变模式序列。
在这里,Deits 举了一个例子:他们用一个棍子用力推机器人,但没有告诉 MPC 该怎么应对,只是让它保持机器人直立(不要摔倒),然后给它一个左右踉跄的序列。它所有的位置和选择的力,包括所有的手臂、腿部动作都只是一个局部优化。
除了常规的保持直立,这个 MPC 系统还能支持一些非常规动作,比如做俯卧撑、倒立行走。
第三个教训是从「工程」角度来总结的。Deits 认为:
- 精心的工程设计是使 MPC 真正发挥作用的一大因素。把一个数学上合理的东西放入一个实际运行的机器人中,并让它运行 100 亿次 QP 求解,需要大量的工作。
- 软件性能很重要,如果你的答案给得太晚,那就没有用了。但软件正确性更重要,一个符号错误会导致系统失效,或效果很差。在没有找到 bug 之前,你很难区分问题出在数学上还是实现上,这会导致大家错失一些好点子。因为一个符号错误而放弃一个在数学上很合理的点子是非常可惜的。
- 机器人的表现是唯一的目标,其他都是次要的。比如,求解器的「收敛」是无关紧要的,机器人是否完成了后空翻才是关键。
第四个教训是关于「轨迹」的。Deits 发现,粗略的轨迹竟然可以成为良好的参考。他们把复杂的期望行为编码为关节、末端执行器、物体姿态的轨迹。这些轨迹可能不一致,甚至完全不切实际。但更复杂的 MPC 能够容忍这些不一致的参考。这意味着他们可以对所有动作运行相同的 MPC,而它却能处理这些看似不合理的参考轨迹,并产生实际可行的动作。
在这里,他发现了一个有用的指标:对于控制工程师来说,你的控制器越好,它能接受的参考就越差。按照这个标准,工程师们都会期望自己的 MPC 能够接受几乎无意义的参考,并产生物理上合理的东西。
尚未解决的问题
显然,使用轨迹作为 MPC 的参考可以带来很好的控制效果,但轨迹本身很难制作。因为,在为机器人的控制策略制定参考轨迹时,需要预测和定义一个考虑时间因素的成本函数。这个成本函数是 MPC 决策过程的关键部分,它影响着机器人如何根据当前状态和预期目标来规划其动作。
然而,一个主要的挑战是,机器人的期望行为可能不是静态的,而是根据机器人当前的行为和环境反馈动态变化的。这意味着,控制策略需要具备适应性,能够实时调整参考轨迹以适应不断变化的情况。比如在一个行走→到达→抓取→举起的序列中,如果你处在到达与抓取之间,MPC 的参考轨迹应该是什么?包括抓取吗?我们不知道是否应该包含抓取,直到我们知道我们是否真的到达了应该到达的位置。MPC 的成本函数应该包括动态变化吗?Deits 表示,对于这些问题,他们也还没搞清楚。
另一个挑战是由「局部优化」带来的。Deits 指出,尽管他们依靠局部优化成功做了很多事情,但有时候,局部优化中的梯度可能会错误地引导机器人,导致机器人采取非最优或错误的行动。
特别是,但没有得到正确的接触模式时,机器人会翻车。因为当机器人与环境接触时,这种接触会引入离散的变化,影响机器人的活动约束。
当机器人遇到意外情况或当前模式不再适用时,如何让 MPC 系统动态地选择一个新的模式序列?目前,他们还没有一个明确的方法来解决这个问题。
Deits 提到的最后一个挑战是:既然增加 MPC 的复杂性有帮助,那么如何在该系统中添加更多的复杂性,让模型变得更大?这包括以下问题:
- 如何在增加模型复杂性的同时减少延迟?
- 哪些复杂性是正确的、值得关注的?包括执行器扭矩、闭合运动链、隐式接触优化、状态不确定性、模型不确定性等等。
- 如何最有效地使用像 GPU 这样的现代计算架构?
那么波士顿动力打算如何应对这些挑战呢?Deits 表示,MPC 与机器学习的结合是他们愿景中最重要的一步。他不确定二者将以何种方式结合。他们将同时尝试各种可能性,比如:
- 将 MPC 用作一个数据收集平台。他们能够控制机器人四处移动,因为他们拥有一个相当稳定的控制器来控制机器人行走和做事,借此来收集数据。
- 将 MPC 用作一个 API,这样强化学习策略就不必直接与关节对话,而是将 MPC 视为机器人能力的抽象,与之交互。
- 将 MPC 作为一个教师,用它来训练可以被更高效地评估的策略。
- 将 MPC 作为一种当下选择,直到逆向工程出 RL 替代技术再切换。
虽然整个分享只有短短的 20 多分钟,但波士顿动力详细介绍了他们在研发历程中踩的坑,整个分享干货满满。感兴趣的读者可以点开视频观看(字幕由剪映自动生成,仅供参考)。
#RAGChecker
给RAG系统做一次全面「体检」,亚马逊开源RAGChecker诊断工具
亚马逊上海人工智能研究院成立于 2018 年,已成为深度学习研究领域的领先机构之一,共发表了~90 篇论文。研究领域包括深度学习的基础理论、自然语言处理、计算机视觉、图机器学习、高性能计算、智能推荐系统、欺诈检测与风险控制、知识图谱构建以及智能决策系统等。研究院率先研究和开发了世界领先的深度图学习库 Deep Graph Library (DGL),结合了深度学习和图结构表示的优势,影响许多重要应用领域。
检索增强生成(Retrieval-Augmented Generation, RAG)技术正在彻底革新 AI 应用领域,通过将外部知识库和 LLM 内部知识的无缝整合,大幅提升了 AI 系统的准确性和可靠性。然而,随着 RAG 系统在各行各业的广泛部署,其评估和优化面临着重大挑战。现有的评估方法,无论是传统的端到端指标还是针对单一模块的评估,都难以全面反映 RAG 系统的复杂性和实际表现。特别是,它们只能提供一个最终打分报告,仅反映 RAG 系统的性能优劣。
人生病了需要去医院做检查,那 RAG 系统生病了,如何诊断呢?
近日,亚马逊上海人工智能研究院推出了一款名为 RAGChecker 的诊断工具为 RAG 系统提供细粒度、全面、可靠的诊断报告,并为进一步提升性能,提供可操作的方向。本文详细介绍了这个 RAG 的 “显微镜”,看看它如何帮助开发者们打造更智能、更可靠的 RAG 系统。
- 论文:https://arxiv.org/pdf/2408.08067
- 项目地址:https://github.com/amazon-science/RAGChecker
RAGChecker: RAG 系统的全面诊断工具
想象一下,如果我们能对 RAG 系统进行一次全面的 “体检”,会是什么样子?RAGChecker 就是为此而生的。它不仅能评估系统的整体表现,还能深入分析检索和生成两大核心模块的性能。

RAGChecker 的主要特点包括:
- 细粒度评估:RAGChecker 采用基于声明(claim)级别的蕴含关系检查,而非简单的回复级别评估。这种方法能够对系统性能进行更加详细和微妙的分析,提供深入的洞察。
- 全面的指标体系:该框架提供了一套涵盖 RAG 系统各个方面性能的指标,包括忠实度(faithfulness)、上下文利用率(context utilization)、噪声敏感度(noise sensitivity)和幻觉(hallucination)等。
- 经过验证的有效性:可靠性测试表明,RAGChecker 的评估结果与人类判断有很强的相关性,其表现超过了其他现有的评估指标。这保证了评估结果的可信度和实用性。
- 可操作的洞察:RAGChecker 提供的诊断指标为改进 RAG 系统提供了明确的方向指导。这些洞察能够帮助研究人员和实践者开发出更加有效和可靠的 AI 应用。
RAGChecker 的核心指标
RAGChecker 的指标体系可以用下图直观的理解:

这些指标被分为三大类:
1. 整体指标:
- Precision(精确率):模型回答中正确陈述的比例
- Recall(召回率):模型回答中包含的标准答案中陈述的比例
- F1 score(F1 分数):精确率和召回率的调和平均数,提供平衡的性能度量
2. 检索模块指标:
- Context Precision(上下文精确率):在所有检索块中,包含至少一个标准答案陈述的块的比例
- Claim Recall(陈述召回率):被检索块覆盖的标准答案陈述的比例
3. 生成模块指标:
- Context Utilization(上下文利用率):评估生成模块如何有效利用从检索块中获取的相关信息来产生正确的陈述。这个指标反映了系统对检索到的信息的利用效率。
- Noise Sensitivity(噪音敏感度):衡量生成模块在回答中包含来自检索块的错误信息的倾向。这个指标帮助识别系统对不相关或错误信息的敏感程度。
- Hallucination(幻觉):测量模型生成既不存在于检索块也不在标准答案中的信息的频率。这就像是捕捉模型 “凭空捏造” 信息的情况,是评估模型可靠性的重要指标。
- Self-knowledge(模型内部知识):评估模型在未从检索块获得信息的情况下,正确回答问题的频率。这反映了模型在需要时利用自身内置知识的能力。
- Faithfulness(忠实度):衡量生成模块的响应与检索块提供的信息的一致程度。这个指标反映了系统对给定信息的依从性。
这些指标就像是 RAG 系统的 “体检报告”,帮助开发者全面了解系统的健康状况,并找出需要改进的地方。
开始使用 RAGChecker
对于想要尝试 RAGChecker 的开发者来说,上手过程非常简单。以下是快速入门的步骤:
1. 环境设置:首先,安装 RAGChecker 及其依赖:
pip install ragchecker
python -m spacy download en_core_web_sm2. 准备数据:将 RAG 系统的输出准备成特定的 JSON 格式,包括查询、标准答案、模型回答和检索的上下文。数据格式应如下所示:
{
"results": [
{
"query_id": "< 查询 ID>",
"query": "< 输入查询 >",
"gt_answer": "< 标准答案 >",
"response": "<RAG 系统生成的回答 >",
"retrieved_context": [
{
"doc_id": "< 文档 ID>",
"text": "< 检索块的内容 >"
},
...
]
},
...
]
}3. 运行评估:
- 使用命令行:
ragchecker-cli \
--input_path=examples/checking_inputs.json \
--output_path=examples/checking_outputs.json- 或者使用 Python 代码:
from ragchecker import RAGResults, RAGChecker
from ragchecker.metrics import all_metrics
# 从 JSON 初始化 RAGResults
with open ("examples/checking_inputs.json") as fp:
rag_results = RAGResults.from_json (fp.read ())
# 设置评估器
evaluator = RAGChecker ()
# 评估结果
evaluator.evaluate (rag_results, all_metrics)
print (rag_results)4. 分析结果:RAGChecker 会输出 json 格式的文件来展示评估指标,帮助你了解 RAG 系统的各个方面表现。
输出结果的格式如下:

通过分析这些指标,开发者可以针对性地优化 RAG 系统的各个方面。例如:
- 较低的 Claim Recall(陈述召回率)可能表明需要改进检索策略。这意味着系统可能没有检索到足够多的相关信息,需要优化检索算法或扩展知识库。
- 较高的 Noise Sensitivity(噪音敏感度)表明生成模块需要提升其推理能力,以便更好地从检索到的上下文中区分相关信息和不相关或错误的细节。这可能需要改进模型的训练方法或增强其对上下文的理解能力。
- 高 Hallucination(幻觉)分数可能指出需要更好地将生成模块与检索到的上下文结合。这可能涉及改进模型对检索信息的利用方式,或增强其对事实的忠实度。
- Context Utilization(上下文利用率)和 Self-knowledge(模型内部知识)之间的平衡可以帮助你优化检索信息利用和模型固有知识之间的权衡。这可能涉及调整模型对检索信息的依赖程度,或改进其综合利用多种信息源的能力。
通过这种方式,RAGChecker 不仅提供了详细的性能评估,还为 RAG 系统的具体优化方向提供了清晰的指导。
在 LlamaIndex 中使用 RAGChecker
RAGChecker 现在已经与 LlamaIndex 集成,为使用 LlamaIndex 构建的 RAG 应用提供了强大的评估工具。如果你想了解如何在 LlamaIndex 项目中使用 RAGChecker,可以参考 LlamaIndex 文档中关于 RAGChecker 集成的部分。
结语
RAGChecker 的推出为 RAG 系统的评估和优化提供了一个新的工具。它为开发者提供了一把 “显微镜”,帮助他们深入了解、精准优化 RAG 系统。无论你是正在研究 RAG 技术的学者,还是致力于开发更智能 AI 应用的工程师,RAGChecker 都将是你不可或缺的得力助手。读者可以访问 https://github.com/amazon-science/RAGChecker 获取更多信息或参与到项目的开发中来。
#De novo generation of SARS-CoV-2 antibody CDRH3 with a pre-trained generative large language model
从头设计抗体,腾讯、北大团队预训练大语言模型登Nature子刊
AI 技术在辅助抗体设计方面取得了巨大进步。然而,抗体设计仍然严重依赖于从血清中分离抗原特异性抗体,这是一个资源密集且耗时的过程。
为了解决这个问题,腾讯 AI Lab、北京大学深圳研究生院和西京消化病医院研究团队提出了一种预训练抗体生成大语言模型 (PALM-H3),用于从头生成具有所需抗原结合特异性的人工抗体 CDRH3,减少对天然抗体的依赖。
此外,还设计了一个高精度的抗原-抗体结合预测模型 A2binder,将抗原表位序列与抗体序列配对,从而预测结合特异性和亲和力。
总之,该研究建立了一个用于抗体生成和评估的人工智能框架,这有可能显著加速抗体药物的开发。
相关研究以「De novo generation of SARS-CoV-2 antibody CDRH3 with a pre-trained generative large language model」为题,于 8 月 10 日发布在《Nature Communications》上。
论文链接:https://www.nature.com/articles/s41467-024-50903-y
抗体药物,又称单克隆抗体,在生物治疗中发挥着至关重要的作用。通过模仿免疫系统的作用,这些药物可以选择性地针对病毒和癌细胞等致病因子。与传统治疗方法相比,抗体药物是一种更具体、更有效的方法。抗体药物在治疗多种疾病方面已显示出积极的效果。
开发抗体药物是一个复杂的过程,包括从动物源中分离抗体,使其人性化,并优化其亲和力。但抗体药物的开发仍然严重依赖于天然抗体。
蛋白质的序列数据可以看作是一种语言,因此自然语言处理(NLP)领域的大规模预训练模型已被用来学习蛋白质的表征模式。当前已经开发了多种蛋白质语言模型。然而,由于抗体的多样性高和可用的抗原抗体配对数据稀缺,生成对特定抗原表位具有高亲和力的抗体仍然是一项具有挑战性的任务。
为了应对上述挑战,腾讯 AI Lab 团队提出了预训练抗体生成大型语言模型 PALM-H3,用于优化和生成重链互补决定区 3 (CDRH3),该区域在抗体的特异性和多样性中起着至关重要的作用。
为了评估 PALM-H3 产生的抗体对抗原的亲和力,研究人员结合使用了抗原抗体对接和基于 AI 的方法。
研究人员还开发了用于评估抗体-抗原亲和力的 A2binder。A2binder 能够实现准确且可推广的亲和力预测,即使对于未知抗原也是如此。
PALM-H3 和 A2Binder 的框架
PALM-H3 和 A2binder 的工作流程和模型框架如下图所示。

图示:PALM-H3 和 A2binder 工作流程概述。(来源:论文)
PALM-H3 的目的是生成抗体中的从头 CDRH3 序列。CDRH3 区域在决定抗体对特定抗原序列的结合特异性方面起着最重要的作用。PALM-H3 是一个类似 transformer 的模型,它使用基于 ESM2 的抗原模型作为编码器,使用抗体 Roformer 作为解码器。研究还构建了 A2binder 来预测人工生成的抗体的结合亲和力。
PALM-H3 和 A2binder 的构建包括三个步骤:首先,研究人员分别在未配对的抗体重链和轻链序列上预训练两个 Roformer 模型。然后,基于预训练的 ESM2、抗体重链 Roformer 和抗体轻链 Roformer 构建 A2binder,并使用配对亲和力数据对其进行训练。最后,使用预训练的 ESM2 和抗体重链 Roformer 构建 PALM-H3,并在配对抗原-CDRH3 数据上对其进行训练,以从头生成 CDRH3。
A2binder 可以准确预测抗原抗体结合概率、亲和力
通过将 A2binder 预测亲和力的能力与几种基线方法进行比较来评估其性能。
A2binder 在亲和力数据集上表现出色,部分原因在于抗体序列的预训练,这使得 A2binder 能够学习这些序列中存在的独特模式。

图示:预训练和未训练模型的潜在能力比较以及 A2Binder 与基线方法在抗体-抗原结合特异性预测方面的性能比较。(来源:论文)
结果表明,在所有抗原抗体亲和力预测数据集上,A2binder 的表现均优于基线模型 ESM-F(后者具有相同的框架,但预训练模型被 ESM2 取代),这表明使用抗体序列进行预训练可能对相关的下游任务有益。
为了评估模型在预测亲和力值方面的表现,研究人员还利用了两个包含亲和力值标签的数据集 14H 和 14L。

A2binder 在 Pearson 相关性和 Spearman 相关性指标上均优于所有基线模型。A2binder 在 14H 数据集上实现了 0.642 的 Pearson 相关性(提高了 3%),在 14L 数据集上实现了 0.683(提高了 1%)。
然而,与其他数据集相比,A2binder 和其他基线模型在 14H 和 14L 数据集上的性能略有下降。这一观察结果与以前的研究一致。
PALM-H3 在生成高结合概率抗体方面表现优异
研究人员探索了 PALM-H3 产生的抗体与天然抗体之间的差异。发现它们的序列存在显著差异,但产生的抗体的结合概率并没有受到这些差异的显著影响。同时,它们的结构差异确实导致结合亲和力的下降。这些结果与之前关于抗体库网络分析和功能性蛋白质序列生成的研究一致。

图示:与基线方法的性能比较以及人工抗体和天然抗体的相似性分析。(来源:论文)
总体而言,结果表明,尽管与天然抗体不同,但 PALM-H3 能够生成具有高结合亲和力的多种抗体序列。
此外,研究人员通过 ClusPro 和 SnugDock 验证了 PALM-H3 的性能。PALM-H3 能够生成针对 SARS-CoV-2 HR2 区稳定肽的抗体 CDRH3 序列。它生成了新的 CDRH3 序列,并且验证了生成的序列 GRREAAWALA 与天然 CDHR3 序列 GKAAGTFDS 相比,对抗原稳定肽的靶向性有所改善。

图示:A2binder 预测的选定高亲和力人工抗体与针对 SARS-CoV-2 刺突蛋白的天然抗体在不同变体和计算结构生成方法之间的界面能比较。(来源:论文)
此外,PALM-H3 能够生成对新出现的 SARS-CoV-2 变体 XBB 具有更高亲和力的抗体 CDRH3 序列。生成的序列 AKDSRTSPLRLDYS 对 XBB 的亲和力比其来源 ASEVLDNLRDGYNF 更强。
此外,PALM-H3 不仅克服了传统顺序突变策略面临的局部最优陷阱,而且与 E-EVO 方法相比,它还能产生具有更高抗原结合亲和力的抗体。这凸显了 PALM-H3 在抗体设计方面的优势,能够更有效地探索序列空间并生成针对特定表位的高亲和力结合物。
体外实验
此外,研究人员还进行了体外试验,包括蛋白质印迹、表面等离子体共振分析和假病毒中和试验,为 PALM-H3 设计抗体的有效性提供了关键验证。

图示:人工和天然抗体的结合亲和力和中和性的体外试验。(来源:论文)
PALM-H3 产生的针对 SARS-CoV-2 野生型、Alpha、Delta 和 XBB 变体刺突蛋白的两种抗体在这些试验中都实现了比天然抗体更高的结合亲和力和中和效力。这些湿实验室实验的有力经验结果补充了计算预测和分析,验证了 PALM-H3 和 A2binder 在生成和选择对已知和新抗原具有高特异性和亲和力的强效抗体方面的能力。
总之,提出的 PALM-H3 集成了大规模抗体预训练的能力和全局特征融合的有效性,从而具有卓越的亲和力预测性能和设计高亲和力抗体的能力。此外,直接序列生成和可解释的权重可视化使其成为设计高亲和力抗体的有效且可解释的工具。
#SkyReels
昆仑万维推出全球首款 AI 短剧平台 SkyReels,「一人一剧」时代来临
8月19日,昆仑万维发布全球首个集成视频大模型与3D大模型的AI短剧平台SkyReels。SkyReels平台集剧本生成、角色定制、分镜、剧情、对白/BGM及影片合成于一体,让创作者一键成剧,轻松制作高质量AI视频。这是一个2分半时长的短剧作品。
「 我们应该放下固化和抵抗的思维,拥抱这个碎片化信息时代。」 2023 年 12 月初,导演黄建新在北京电影学院北影大讲堂上感慨,比起电影,竖屏短剧兴起才真正形成了全球输出。
几分钟到十几分钟的单集时长、强烈的娱乐性和快节奏剧情,频繁踩中用户「爽点」,短短三年(到 2023 年),中国短剧市场就达到了年度院线电影票房的七成。
与此同时,大量短剧独立 APP 全球上线,中文在线的短剧软件 ReelShort 在美国 iOS 排行榜上表现优异,甚至超越了长期霸榜的 TikTok, 实现破圈。
短剧已成为近年增长最快的影视领域之一,也成为新技术的试验场。「一键翻译」、「 AI 换脸」屡见不鲜,多家网文公司还发布可以辅助作者写作的内容生成大模型。借助 AI 大模型视频生成能力,以往三个月的短剧制作时间现在只需要半个月。
AI 创作的短视频片段,一经发布就能获得百万流量的加持,但一部 AI 全流程短剧制作还面临不少挑战。创作者需要在 ChatGPT、Midjourney、Runway、Eleven Labs、ComfyUi、Adobe、剪映等多个 AI 工具间反复「横跳」,作品效果仍差强人意。
在这样的背景下,拥有十多年出海经验的中国人工智能科技企业昆仑万维推出了世界首个 AI 短剧平台 SkyReels——一个集成视频大模型与 3D 大模型的 AI 短剧平台。这不仅是国产大模型在短剧领域的成功落地,也预示着「一键成剧」、「一人一剧」时代来临。
同时,这一革命性的工具有望带来 AI 短剧用户生成内容( UGC )与专业用户生成内容( PUGC )的爆发式增长,推动短剧内容创作与消费市场的进一步快速增长。
一、认识 SkyReels ——全球首款 AI 短剧平台
以下视频来源于
昆仑万维集团59
SkyReels产品操作Demo
打开 SkyReels 网页,立刻感到「AI 短剧」与其他 「 AI 创意」平台的设计,很不一样。
都是由 AI 驱动,但「 AI 创意」平台以图片、视频生成为主,SkyReels 则集剧本生成、角色定制、分镜设计、视频拍摄与合成于一体, 完整复制了短剧工业化流程。

SkyReels 集故事创意、剧本生成、角色定制、分镜设计、视频拍摄与合成于一体, 完整复制了短剧工业化流程。
短剧收视不「扑」,首先得有好创意,并将它具象成一个爽文剧本,这是最重要的。
虽说文本创作是大语言模型 LLM 的舒适区,SkyReels 的不同之处在于负责文本创作的大模型受过专业训练,更懂怎么写出有「 爽点 」、带流量的剧本。
只要输入一个概念或故事创意,点击「创作类型」, 比如情感剧,系统会自动生成一份符合要求的剧本,结构完整、情节丰富。
用户也可以上传现成的剧本,让 AI 帮忙润色、优化,提升剧本的专业度和可读性。

系统会根据创意提示自动生成一份符合要求的剧本,还会摘要出所涉人物小传,为后面的角色设计做准备。
剧本有了 ,接下来就该「物色演员」,在 SkyReels 上,这个环节叫角色设计。
通常,我们会先让 LLM 写设计文本,再扔到 Midjourney 等文生图工具,生成角色形象。要给角色添加配音,还要继续召唤 Elevenlabs 等音频工具。
现在,只需进入页面输入相应要求(包括角色配音),即可「一键生成」角色,大大提升了制作效率。

只需进入页面输入相应要求(包括角色配音),即可一键生成角色。
进入拍摄之前,除了物色演员,导演还要制作分镜。 所谓分镜,主要是将整个故事分解成一系列连续的画面,每个画面都代表一个特定的场景或动作。

吉卜力工作室的《千与千寻》分镜图。
没有美术背景的导演,要在绘画师的帮助下完成分镜设计,非常麻烦。现在,他们可以让 LLM 生成分镜头的文字脚本,再用 Midjourney 等工具画出分镜图。
但是,这种方法的弊端也明显,很难保证角色、场景的前后一致性。比如,央视 AI 频道上线的 AI 全流程微短剧《女娲》中,女娲每次出现,长得都不太一样,好像有几个女娲。
在 SkyReels 上,AI 会根据剧本内容,一键生成分镜图片和对应的文字脚本,仅需等待 1-2 分钟即可查看每个镜头的效果。不满意,还能通过修改文字(如场景或人物动作),调整分镜效果。
更重要的是,在自研技术支持下,分镜图片不仅高清、细节丰富,角色、场景在不同分镜中都能保持一致性和连续性。

AI 会根据剧本内容,一键生成分镜图片和对应的文字脚本。
分镜设计好了、演员就位后,就要进入「 实拍」阶段。 目前,AI 影视发展最大的瓶颈也在这里,因为能用的好「摄像机」太少。
常见做法是用 Pika、Runway 生成动态效果,但槽点很多。 比如, 画质糟糕、角色动作幅度小甚至不合理(吃面问题),还容易出现场景不一致,有时车辆在运动但车轮不转,水流时水花在动水面却是静止的。人物说话口型对不上,表情也僵硬。
通过 AI 3D 引擎与视频大模型的结合,SkyReels 能将分镜自动转换为连续视频,生成的场景和人物更加生动、一致,还支持 1080P 60 帧视频输出,煲剧体验也有保障。
另外,单次可生成视频长度达 180 秒,相比 Sora 单次可生成 60 秒视频、可灵单次可生成 10 秒视频,有显著突破。

SkyReels能将分镜图自动转换为连续视频。
最后,所有流程成果可一键整合,快速生成最终短剧。AI 还会根据剧本题材与具体场景生成并推荐合适的背景音乐和音效,用户也仅需一键添加。

背景音乐和音效也可一键添加。

支持一键导出成片,并可一键发布至抖音等社交媒体平台。

支持角色设计的一键分享。
二、「 一键成剧」背后,三层技术创新
三层技术创新,如三根支柱,支棱起 SkyReels 「 一键成剧」:
自研剧本大模型 SkyScript、自研分镜大模型 StoryboardGen,以及业界首个将 AI 3D 引擎与视频大模型深度融合的创新平台 WorldEngine。
剧本大模型 SkyScript 负责拿捏短剧的「 灵魂」——剧本。事实上,不仅是剧本,文本大模型也是整个创作流程的支撑。
有些微短剧编剧尝试过利用 ChatGPT 生成剧本,但发现最终的结果缺乏情感张力和剧情变化,只是堆砌了一些平面的文字。昆仑万维构建了亿级的高质量短剧结构化数据集 SkyScript-100M ,该数据集针对海量精彩短剧的剧情节奏、爽点、情绪变化进行了高质量标注,专为剧本创作而生。

SkyScript剧本大模型技术原理图

SkyScript剧本大模型的分镜脚本生成原理。
比如,除了从海量数据中学习创作的基本原理和通用模式,要爆款,还要摸清一些百试不爽的「套路」。 观众往往对快节奏、强烈冲突、悬念迭起、多次反转的剧情设计有明显偏好;逆袭改命、霸总娇妻、豪门宅斗、穿越重生、吸血鬼、狼人等主题,也是百看不厌。

ReelShort爆款短剧《The Double Life of My Billionaire Husband》为先婚后爱,单集约1分30秒,截至第12集左右,男女主在密集的剧情交集中,迅速完成了感情升温,且涵盖了恶毒女配、契约婚姻、英雄救美、 财产争夺等情节。来自国海证券中国短剧出海深度报告。
通过精心标注的故事中能引起观众强烈兴趣的「爽点」,如主角外貌、镜头构图、贯穿人物表达的情绪, SkyScript 学会了关注并生成这些细节。
在模型架构上,为了确保生成内容的专业度和可控性, SkyScript 也采用了多智能体框架。透过「创意人」、「选角导演」、「编剧」、「小说作者」、「导演」等智能体的协作,模仿工业制作流程,完成剧本创作。

剧本大模型 SkyScript 的质量评估情况。
短剧,说到底,是一种视觉语言的呈现,因此,另外两层创新—— 分镜 StoryboardGen、 WorldEngine —— 聚焦短剧的「血肉」,也就是拍摄。
和 SkyScript 一样,自研分镜大模型 StoryboardGen 也接受了真实世界中高质量、专业分镜实例训练,专为分镜设计而生,也与通用类图像生成模型拉开了距离。
同样,基于多智能体框架,将分镜的不同元素(场景、镜头、角色、动作等)分解为多个智能体来处理,大大增强了分镜制作过程中的可控性和一致性。

分镜大模型 StoryboardGen 的技术原理图。类似于电影拍摄、动画制作,基于多智能体框架的 StoryboardGen 将整体流程分解成了多个 agent,每个 agent 负责某个专项能力,增强分镜制作过程中的可控性和一致性。
假设有一个剧本,里面描述了一个场景,比如一个人在公园里散步。
LLM Planner 会先把这个剧本拆解成两部分。
其中,全局描述( global prompt ):「一个人在阳光明媚的公园里散步」;
局部描述( local prompt ):「这个人是中年男性,穿着休闲装,手里拿着咖啡杯,步伐悠闲。」
在生成环节,不同智能体各司其职,如场景智能体根据全局描述生成公园的背景、布局等;角色智能体根据局部描述生成男性角色的形象和动作。
最后由 Storyboard 智能体将这些生成的内容整合起来,根据所有的描述信息和条件,生成最终的分镜图。

分镜大模型 StoryboardGen 质量评估情况。
除了可控和一致性,为了让分镜画面更具表现力,StoryboardGen 还大幅提升了画面的复杂程度和细节精度。
如,StoryboardGen 采用了基于 DiT 的渐进式生成框架,通过多次修改和完善来创作最终的图像。相比传统的一次性生成模型,这种框架能够充分利用中间过程产生的信息,生成质量更高、视觉效果更丰富的分镜。
第三层技术创新是一个创新平台 World Engine ,在业界率先将 3D 生成技术与视频生成技术,通过图层融合等方式,无缝衔接在一起,相当于为创作者提供了一部强大的「摄影机」甚至「影棚」。
WorldEngine 结合了引擎的精确可控能力(如光照模拟、物理模拟、3D 空间、实时交互等) 以及 AI 视频大模型的幻想生成能力,提供了全新的线上混合视频创作模式,让视频创作从模糊生成迈向更加精确可控。
假设你正在制作一个场景,一只皮卡丘在喷泉下玩得很开心,可以让 Sky3DGen 创造出精确的喷泉场景;同时让视频大模型生成逼真的皮卡丘。
混合生成视频案例
我们知道,Sora 等视频大模型可以轻而易举地生成游戏引擎难以匹敌的、几乎真实的效果,并且充满想象力,但它们不懂物理世界,无法准确模拟一些最基本的物理交互,如玻璃破碎、吃面等。
而游戏引擎的优势在于其对现实物理规律的精准模拟。通过复杂的数学模型,它能创造出时空连贯、符合客观规律的虚拟环境,不仅确保了渲染结果的一致性和可预测性,还展现了对三维空间的深刻理解。
作为中国最大的游戏开发和运营企业之一,昆仑万维自研 Sky3DGen 大模型,并与视频大模型「优势互补」,为创造者提供了一种全新的混合创作模式,也就不算意外。
在 SkyReels 上 ,你可以变化出各种 3D 场景和造型,甚至人物表演。 2
3D 道具视频生成案例
3D 场景视频生成案例
人物表演是短剧的核心之一, 昆仑万维自研了 ActorShow 人物表演生成模型,有更强的口型表情和肢体动作的可控生成能力。

人物表演生成模型的质量评估情况。
创作过程中,用户还能自由定义 3D 虚拟拍摄影棚。
今天想拍摄在沙漠中的故事?点击几下,整个场景就变成了广袤的沙漠。明天要拍摄在宇宙空间站?再点几下,周围就变成了高科技的空间站内部。
你甚至可以在搭建的虚拟摄影棚里,放置和移动虚拟摄像机,尝试各种拍摄角度。调整光线、添加特效,得到非常专业的拍摄效果。
由于引擎的使用,与传统的视频生成相比,WorldEngine 在成本上实现了革命性的下降,同时,生成速度、可控性都提升了数个量级。
三、押注 AI UGC ,再上牌桌
AI 短剧平台 SkyReels ,是昆仑万维 AI 应用层产品矩阵中的最新成员。
在此之前,他们已经成功构建了包括 AI 搜索、AI 音乐、AI 视频、AI 社交、AI 游戏等在内的多元产品阵列,部分业务已实现商业化落地。
作为最早开拓全球市场的中国企业之一,凭借十多年的内容与娱乐赛道经验,昆仑万维已经洞察到 UGC(用户生成内容)平台在内容和游戏领域一直保持长盛不衰的态势,也预测到 AIGC 的介入,不仅让网文、短剧、动画、游戏的 IP 创作手段更加多样化,更关键的是大幅降低了内容创作的门槛。
正如业内所言,「生产内容的门槛每降低一倍,创作内容的人数就会增长十倍」,这预示着巨大的市场机遇。
因此,昆仑万维致力于打造一个以 IP 为核心的综合 UGC 平台,让所有使用 AI 进行创作的用户都能在其中完成 IP 的全闭环。他们深知,一个能够隐藏所有技术细节、实现端到端内容生成的工具,才真正具有商业价值,这也正是 SkyReels 等「一键生成」式产品的深层逻辑。
除了在上层打造 AI UGC 平台,在底层,昆仑万维还致力于开发通用大模型的底座。这源于一个简单又深刻的洞察:从技术角度来看,人类的智慧是以文本形式沉淀下来,所有的社交、游戏、音乐跟视频的专属模型,都离不开文本大模型的能力支撑。
昆仑万维自研的天工大模型已迭代至 3.0 版本。「天工 3.0 」采用 4,000 亿参数 MoE 架构,是目前全球模型参数最大、性能最强的开源 MoE 模型之一。在 MMBench 等多项权威多模态测评结果中,「天工 3.0 」超越 GPT-4V ,多项评测指标达到全球领先水平。
有了夯实的通用大模型底座,昆仑万维又一步步朝着内容和娱乐领域,横向延伸模型能力——从音乐、文生图、视频生成到短剧生成,相继推出 SkyMusic AI 音乐大模型、Skywork-MM 多模态大模型、SkyScript 剧本大模型、 StoryboardGen 分镜大模型、 Sky3DGen 3D 大模型等。
昆仑万维董事长兼 CEO 方汉曾经预言,就像摄像头带来了拍摄方式的革命,催生出抖音、快手等巨量短视频平台一样,AI 也将催生大量新的 AI UGC 平台。他坚信,只有「免费+ to C 」的模式,才能在 AI 时代孕育出真正的巨头企业。
对于深具 2C 基因的昆仑万维而言,AIGC 的兴起无疑是一次难得的机遇。这个一直梦想成长为领先的人工智能科技公司的企业,原本以为已经错过登上牌桌的机会,却没想到 AIGC 又为他们敞开了一扇新的大门。厉兵秣马,他们正全力以赴。
#RISC-V与AI今日全面
开源的胜利
RISC-V 正在成为 AI 原生计算架构。
DeepSeek 的爆火震撼 AI 行业后,也带动相关行业余震不断。其中,达摩院玄铁在春节期间宣布适配 DeepSeek-R1 系列蒸馏模型,引发半导体行业高度关注,新兴的开源指令集 RISC-V 在 AI 方向展现出强劲的动力。
而今天的玄铁 RISC-V 生态大会上传来消息,RISC-V 在高性能和 AI 方向上实现双重突破,玄铁首款服务器级 CPU C930 下月开启交付,其 AI 算力大幅提升,加快布局「高性能+AI」RISC-V 全链路。
开源算力架构 RISC-V,会是开源 AI 的最佳搭档吗?
AI 模型变革催生算力架构创新
一位芯片行业资深人士介绍,DeepSeek 不仅震撼了 AI 圈,也震撼了芯片行业。因为凭借极致的深度优化,DeepSeek 大幅降低了大模型的训练和推理成本,算力、内存、互联原有平衡发生剧变,为算力架构的创新带来了重大的机会。
传统而言,AI 大模型需要较高的算力和内存要求,更适合部署在云上,而不是端侧。但 DeepSeek 的横空问世,打破了大模型的高算力的路径依赖,它不仅降低了训练成本,也显著降低了推理的要求,正帮助大模型从云走向端。
具体来说,DeepSeek 降低了大模型对计算资源的需求,让单机部署变得可能,能够更好地适配边缘和端侧的设备。AI 要深入千行百业,覆盖多样化的各种场景,也迫切需要从云上走向端侧,才能进一步满足数据安全、个性定制、私有化部署等多样化需求。
可以预见的是,由于 DeepSeek 技术的普及,AI 芯片的形态即将重构,从原本依赖云计算的大规模并行计算,到今天可以在边缘设备上独立运行的低功耗芯片,AI 芯片正在走向多样化和高效化。
这也引发众多业界人士思考,什么样的算力架构才最适合 AI?
并行计算的 GPU 也许不是唯一解,串行计算(通用计算)也能成为 AI 计算基础。业界实践表明,DeepSeek 对多种计算体系都有较好地支持,在 CPU 上不仅能快速部署,还有较好的推理效果,这让 CPU 重回牌桌。相比专用的 GPU,CPU 一大特点就是通用性强,调度简单,能够大幅降低算力需求并发挥同构计算的优势。
而在 CPU 中,最引人注意的是后起之秀 RISC-V。
春节期间,达摩院在搭载 RISC-V 处理器玄铁 C920 的芯片上对 DeepSeek-R1 系列蒸馏模型进行适配,全程耗时仅 1 小时,体验快捷顺畅。这也意味着,DeepSeek 系列模型将能够顺利部署并流畅运行在全系列玄铁 CPU 平台及其他搭载 RISC-V 架构芯片的各类 AI 端侧设备上。
RISC-V 备受关注,一方面是因为其作为新兴的指令集架构,有别于 x86、arm 的封闭或付费授权,坚持走开源开放的路线,其开源精神与 AI 天然契合。因其开源开放,RISC-V 已吸引了全球 1000 家企业的参与,从硬件设计到软件工具链,生态系统迅速壮大。根据 RISC-V 国际基金会的数据,全球已经有超过 80 个不同的 RISC-V 芯片产品被推向市场。
另一方面是因为 RISC-V 的灵活性和可扩展性。RISC-V 允许开发者根据具体需求定制指令集。由于其指令集是模块化的,开发者可以根据不同的应用场景进行定制,这种灵活性是传统架构无法比拟的。
从技术上来说,RISC-V 也非常适合新型的 AI 计算,RISC-V 的向量扩展(V-extension)能够有效处理大规模并行运算,满足 AI 计算的高效性需求。RISC-V 的开放架构与硬件加速模块可以协同工作,提升 AI 任务的执行效率。通过与 AI 算法的深度结合,RISC-V 架构可以设计专用硬件加速单元,实现对特定 AI 模型的优化。
因此,不少芯片行业资深专家期待,RISC-V 能成为 AI 时代的原生计算架构。
今天,在阿里达摩院主办的第三届玄铁 RISC-V 生态大会上,这样的预期终于到了兑现的时候。
玄铁首款服务器级 CPU 即将交付高性能与 AI「双剑合璧」
在大会上,中国工程院院士倪光南表示:「开源 RISC-V 不仅是一项技术创新,更是一场影响未来计算架构的全球化变革。」作为「生而开源」的芯片指令集架构,RISC-V 在本轮半导体产业周期里表现突出,从嵌入式系统加速挺进高性能等复杂场景,并为 AI 算力提供新选择。
在 RISC-V 国际基金会 2024 年批准的 25 项标准中,超过一半与高性能或 AI 相关。RISC-V 国际基金会理事会主席 Lu Dai 在大会现场表示,RISC-V 指令集最激动人心的进展之一是 Matrix 扩展,将推动 RISC-V 成为 AI 领域令人敬畏的力量。
据预测,到 2030 年,RISC-V 的整体份额将达到 20%,在 AI 加速器中的占比有望突破 50%。
在大会上,达摩院玄铁拿出了新一代旗舰处理器、也是首款服务器级处理器 C930。
C930 通用性能算力达到 SPECint2006 基准测试 15/GHz。什么概念?倪光南院士指出,RISC-V 要真正进入高性能计算市场,RISC-V 以 SPECint 2006 软件测试,必须跑出超过 15 分的高性能标准。因此,C930 迈出了 RISC-V 里程碑式的一步。
此外,C930 搭载 512 bits RVV1.0 和 8 TOPS Matrix 双引擎,将通用高性能算力与 AI 算力原生结合,并开放 DSA 扩展接口以支持更多特性要求。

同时,达摩院披露了 C908X、R908A、XL200 等玄铁处理器家族新成员的研发计划,向 AI 加速、车载、高速互联等方向持续演进。具体而言,C908X 定位为玄铁首款 AI 专用处理器,支持 4096 bits 超长数据位宽 RVV1.0 矢量扩展;R908A 面向车规级芯片的高可靠需求;XL200 则将提供更大规模、更高性能的多簇一致性互联。
配合玄铁处理器的能力拓展,达摩院也基于 Linux、Android、RTOS 三套主流操作系统推出三套玄铁 SDK,将多年来积淀的玄铁软件能力全面整合,以更完整、便捷、稳定的方式向行业输出。其中,玄铁 Linux SDK 提供包括 Hypervisor 虚拟化、CoVE 安全框架、玄铁 AI 框架、高性能算子库在内的丰富子系统,助力 RISC-V 在高性能和 AI 场景的开发启航。
在发展高性能软硬件技术的同时,玄铁更牵引产业上下游合作伙伴协同创新,加快布局 RISC-V「高性能+AI」全链路生态。
阿里死磕RISC-V 玄铁引领国际开源社区
对于不太熟悉玄铁的读者,这里简单介绍一下。
2018 年,阿里巴巴树立了主攻 RISC-V 方向的品牌:玄铁;一年之后,首款处理器「玄铁」C910 一诞生便是性能最强的 RISC-V 处理器。自那以后,玄铁就一直是国际 RISC-V 生态的引领者,也是对国际开源社区贡献最大的中国机构之一,目前在基金会技术委员会及 10 余个技术小组担任主席或副主席职位,积极推动着 AI 方向标准化的建设。
自 2019 年以来,玄铁已经陆续推出了 13 款 RISC-V 处理器,覆盖了覆盖高性能、高能效、低功耗等不同场景,包括:
- C 系列(Computing)主要针对高端服务器、高端边缘计算和行业类、消费级 IPC;
- E 系列(Embedded)主要应用于高端 MPU 与各类 MCU;
- R 系列(Reliability& Realtime)面向高端 SSD、通信、高端工控、车载等场景;
- XT-Link 则是 CPU 多簇互联 IP。
迄今,玄铁处理器出货量超过 40 亿颗,已成为国内 RISC-V 领域影响力和市场占有率最大的处理器产品系列之一。
玄铁在发展过程中,一边持续突破 RISC-V 的性能天花板,不断向更高性能进发,另一边积极拥抱 AI,致力于推动 RISC-V 成为 AI 原生算力架构。
在指令集架构技术层面,利用 RISC-V 架构优异的开放性和灵活性,玄铁很早定制了面向 AI 应用的指令集扩展。其提出的矩阵运算(Matrix)扩展扩展指令集、优化大模型核心算子 GEMM,可以加速 AI 推理及训练,提升端侧 AI 能效。
在处理器上,玄铁 C907 首次实现了 Matrix 扩展,较传统方案提速 15 倍。升级版 C920 支持 Vector 1.0 和 Vector Crypto 技术,GEMM 性能指标提升超 7 倍,Transformer 算子性能提升超 17 倍。而最新的旗舰处理器 C930 兼具 vector 和 matrix 双引擎,有望成为成为端侧 AI 大模型的好搭档。
在软件栈层面,玄铁打造了端到端的 RISC-V AI 全栈软硬件平台,向芯片厂家提供通用的、高效的 AI 算力基础设施,形成面向业务的流水线设计,真正了实现底层硬件设计到上层软件工具链的便捷深度优化。该平台已应用于云端视频转码卡、AI 边缘计算盒子、RISC-V 笔记本电脑等终端产品。
除了自身技术,达摩院 RISC-V 团队也一直在引入产业上下游伙伴的力量,完善 RISC-V 的「高性能+AI」生态版图。
去年大会上,RISC-V 开源笔记本电脑「如意 BOOK 甲辰版」惊喜亮相,实现大型商用软件的稳定、流畅运行。此次,中科院软件所进一步介绍「如意 BOOK 乙巳版」、智能机器人、AI PC 等 RISC-V 高性能应用。
其中基于 C920 的 AI PC 原型机已跑通了 Llama、Qwen、DeepSeek 等开源模型,支持 AI 个人助手、AI 编程、视觉识别等 AI 应用,可以说打通了从开源硬件架构到开源操作系统、再到开源 AI 模型的「开源 AI 全链路」,单位计算能耗还降低了 30%。
除此之外,玄铁还联合合作伙伴构建了 RISC-V 视频编解码方案、云桌面解决方案等等实用解决方案。为了支撑更多行业的应用,玄铁也把 RISC-V 算力布局到了一体机、工控 AI、机器人等领域。
倪光南院士表示,玄铁这种务实的投入和创新,正是 RISC-V 生态健康发展的重要驱动力。
开源的未来
DeepSeek 的成功是开源的成功,开源指令集架构 RISC-V 问世十几年来,已经走出了与封闭式的 x86 和授权模式的 ARM 不同的发展路径,让业界看到了通过更加简洁、更开放的方式进行架构创新的机遇,因此也在得到越来越多的认可。
它正在成为 AI 时代原生架构的最佳候选 —— 一方面 RISC-V 坚持开源开放,一直处于演进变化之中,能够跟上 AI 极速变化的步伐;另一方面,RISC-V 扩展性强,可以通过移植适配与原有架构生态兼容,也能作为原生架构支撑不断涌现的新场景。
正如中科院软件所 RISC-V 负责人郭松柳说的:「AI 软件栈仍在高速演进,RISC-V 作为三大主流指令集架构中最灵活、最开放的一个,无疑最为适合 AI 时代的技术创新节奏。」
#Karpathy更新AI科普视频
网友:原本周末打算结个婚,改看视频了
他是真的想教会大家。
刚刚,赛博活佛 Andrej Karpathy 更新了一个长达 2 个多小时的学习视频,主题是 ——「我是如何使用大型语言模型(LLM)的」。

这个视频是 Karpathy 面向普通观众的系列视频之一。上一个视频关注的是 LLM 的训练方式。这次,他想跟进一个更实用的整个 LLM 生态系统指南,包括他自己生活中使用的大量例子,所以整个视频的技术门槛并不高。
,时长59:01
,时长50:15
,时长22:01
完整高清版视频参见:https://www.youtube.com/watch?v=EWvNQjAaOHw
在点开看了十分钟之后,我们发现,Karpathy 是真想手把手把大家教会,让大家都能更好地利用大模型去提高工作、学习效率。而且,他还不收学费。

以下是视频时间线:
- 00:00:00 不断发展壮大的 LLM 生态系统
- 00:02:54 ChatGPT 交互的幕后原理
- 00:13:12 基本 LLM 交互示例
- 00:18:03 了解你正在使用的模型和价格等级
- 00:22:54 思考型模型以及何时使用它们
- 00:31:00 工具使用:互联网搜索
- 00:42:04 工具使用:深度研究
- 00:50:57 文件上传,将文档添加到上下文
- 00:59:00 工具使用:Python 解释器,生态系统的混乱性
- 01:04:35 ChatGPT 高级数据分析、图表、绘图
- 01:09:00 Claude Artifacts、应用、图表
- 01:14:02 Cursor:Composer,编写代码
- 01:22:28 音频(语音)输入 / 输出
- 01:27:37 高级语音模式,即真正嵌入到模型内部的语音
- 01:37:09 NotebookLM,播客生成
- 01:40:20 图像输入,OCR
- 01:47:02 图像输出,DALL-E、Ideogram 等
- 01:49:14 视频输入,应用上的点击和交谈
- 01:52:23 视频输出,Sora、Veo 2 等
- 01:53:29 ChatGPT 记忆,自定义指令
- 01:58:38 自定义 GPT
- 02:06:30 总结
Andrej Karpathy 的身份有很多个:李飞飞高徒、OpenAI 创始成员及研究科学家、特斯拉前 AI 高级总监、YouTube「学习区」知名博主。不过,从他对教育的热爱来看,以前在特斯拉、OpenAI 都是「副业」,现在做的 AI 教育、科普才是「正职」。

一位麻省理工学院的学生评价说,Karpathy 的视频比自己在校园里学到的任何东西都更有价值。还有人因为 Karpathy 发了这个新视频而改变了周末计划。

不过,那个说为了看这个视频取消婚礼的网友是认真的吗?


#BIG-Bench Extra Hard
谷歌发布BIG-Bench超难基准:DeepSeek-R1得分6.8,只有o3-mini超过10分
随着 AI 能力的提升,一个常见的话题便是基准不够用了——一个新出现的基准用不了多久时间就会饱和,比如 Replit CEO Amjad Masad 就预计 2023 年 10 月提出的编程基准 SWE-bench 将在 2027 年饱和。
也因此,为了更加准确地评估 AI 模型的能力,不断有研究团队构建出新的数据集和基准,比如我们前段时间报道过的 ZeroBench 和 HLE(人类的最后考试),它们都带有大量当前的 AI 模型难以解决的难题。
近日,谷歌也发布了一个高难度基准:BIG-Bench Extra Hard,简称 BBEH。从名字也能看出来,这个基准非常难(Extra Hard)并且与久负盛名的 BIG-Bench 和 BIG-Bench Hard(BBH)关系密切。
- 论文标题:BIG-Bench Extra Hard
- 论文地址:https://arxiv.org/pdf/2502.19187
- 数据地址:https://github.com/google-deepmind/bbeh
正如其论文一作 Mehran Kazemi 指出的那样,相比于 BIG-Bench Hard,BBEH 中每个任务都更加困难,给当前所有模型都创造了进步空间。

另一位作者、DeepMind 著名研究科学家 Yi Tay 也建议 AI 研究者在自己的下一篇论文中使用该基准。

那么,BBEH 究竟有多难呢?当前能力最强的 o3-mini (high) 得分也仅有 44.8 分,不及格。而其它被测模型的得分均不超过 10 分!DeepSeek-R1 仅有 6.8,谷歌自家的 Gemini-2.0-Flash 也只有 9.8。遗憾的是,该团队并没有给出近期发布的 Grok-3 与 Claude 3.7 Sonnet 的表现。

该团队在论文中解释了构建 BBEH 基准的动机,其中指出目前对推理模型的评估大都依赖数学、科学和编程基准,而涉及到更多方面的 BIG-Bench 及其更难的子集 BIG-Bench Hard(BBH)基准则正趋向饱和 —— 当前领先的模型在 BBH 上的准确度都已经超过 90%。因此,BBH 已经无力评估前沿模型的推理能力。
BBEH 便应运而生,其设计目标是「评估高阶推理能力」。
BIG-Bench Extra Hard
BBEH 是基于 BBH 构建的——将 BBH 中的 23 个任务中的每一个都替换成了另一个在类似推理领域中并测试类似(或更多)技能的任务,当然,新任务的难度要大得多。这种替换方法可以确保新数据集保留了原始 BBH 数据集的高度多样性。
表 1 给出了 BBEH 中新任务的高层级描述,包括它们是如何构建的以及它们替换了 BBH 中的哪个任务,以及它们针对哪些推理技能。

该基准中,每个任务包含 200 个问题,但 Disambiguation QA 任务例外,有 120 个问题。
下图展示了一些具体任务示例:

该论文的详细创建过程以及对 BBEH 数据集的分析请参阅原论文,下面我们重点来看看前沿模型在该基准上的表现以及相关分析结果。
模型表现及分析
首先来看各家前沿模型的表现如何,下表是准确度分数详情。

根据此结果,该团队得出了几个有趣的观察:
- 模型在各个任务上都有很大的进步空间,在 BBEH 整体上也是如此。
- 通用模型的最佳性能为 9.8% 的调和平均准确率。推理专用模型在该基准上的表现优于通用模型(符合预期),但这些模型在 BBEH 上的最佳性能仍只有 44.8%。
- 尽管采用了对抗性结构,但参考 Thinking 模型在 BBEH 上的调和平均准确率仍只有 20.2%。
- 一些模型的准确率甚至低于随机性能。经检查,他们发现原因大多是模型无法在有效输出 token 长度内解决问题并在某个点之后开始退化,因此无法从其解答中提取出最终答案。
另外,还能看到不同模型擅长不同类型的推理。例如,DeepSeek R1 在 BoardgameQA 上的表现明显优于其他模型,o3-mini (high) 在 Temporal Sequences 和 Object Properties 上的表现明显优于其他模型,GPT4o 在 NYCC 上的表现明显优于其他模型,GPT4o 和 Gemini 2.0 Flash 在 SARC Triples 上的表现明显优于其他模型。
该团队还进行了进一步的结果分析。
通用模型与推理模型
推理模型可以利用更多测试时间计算进行思考,因此在涉及数学和编码的推理任务上实现了巨大的性能飞跃。例如,在 AIME2024 数据集上,GPT4o 的性能为 13.4%,但 o1 模型将其提高到 83.3%,o3-mini (high) 将其进一步提高到 87.3%。
在这里,该团队检查了不同类型的一般推理是否也是如此。
如图 5 所示,该团队分别将 o3-mini (high) 和 GPT4o 作为推理和一般模型的模范,在 BBEH 的每个任务上进行了比较,并根据 o3-mini (high) 相对于 GPT4o 的增益程度对任务进行升序排序。

可以观察到,增益最大的任务是那些涉及计数、规划、算术以及数据结构和算法的任务。而增益最少(有时为负值)的任务大多涉及常识、幽默、讽刺和因果关系。
结果表明,推理模型在解决形式化问题时会取得最显著的收益,而在处理复杂的现实场景时(通常需要软推理技能)则收益有限。
模型大小的影响
该团队还探讨了模型大小对模型性能的影响。
如图 6 所示,他们在 BBEH 的不同任务上比较了 Gemini 2.0 Flash 和 Gemini 2.0 Flash-Lite,并根据 Flash 相对于 Flash-Lite 的收益按升序方式对任务进行排序。

虽然信号不如将一般模型与推理模型进行比较时那么清晰,但仍然可以观察到与幽默、常识和因果推理相关的任务收益最少,而需要多跳推理或应用算法的任务收益最大。
一个特殊的例外是 SARC Triples 任务,这是一个讽刺理解任务,并且收益很大。这可能部分是由于 SARC Triples 中的每个样本都是三个子问题的组合,而较大的模型可能更擅长处理这种复合问题。
上下文长度和所需思考的影响
BBEH 中的任务具有不同的平均上下文长度,并且可能需要不同的思考量。基于此,可以了解上下文长度和所需思考对推理与一般模型以及较大模型与较小模型的影响。
图 7 比较了 o3-mini (high) 与 GPT4o 以及 Gemini 2.0 Flash 与 Gemini 2.0 Flash-Lite 的性能,这里使用了任务平均上下文长度和平均输出长度作为所需思考的代理。

可以观察到,无论是在上下文长度增加时,还是在所需思考增加时,o3-mini 的收益都比 GPT4o 更高;这表明与一般模型相比,推理模型在两个方向上都可能有所改进。对于 Gemini 2.0 Flash 与 Gemini 2.0 Flash-Lite,可以看到当上下文长度增加时,收益也有类似的增长,但思考增加时,曲线基本保持平坦。
参考链接:
https://x.com/kazemi_sm/status/1894935166952349955
https://x.com/YiTayML/status/1894939679943991661
#DataMan
浙大、千问发布预训练数据管理器DataMan,53页细节满满
文章全面探讨了大语言模型在预训练数据选择上的重要性,并提出了一种名为 DataMan 的数据管理器,用于对预训练数据进行质量评分和领域识别,以优化 LLMs 的预训练过程,本文由浙江大学和阿里巴巴千问团队共同完成。
在 Scaling Law 背景下,预训练的数据选择变得越来越重要。然而现有的方法依赖于有限的启发式和人类的直觉,缺乏全面和明确的指导方针。在此背景下,该研究提出了一个数据管理器 DataMan,其可以从 14 个质量评估维度对 15 个常见应用领域的预训练数据进行全面质量评分和领域识别。通过大量的实验,利用 DataMan 所筛选出的部分数据进行模型训练,胜率最高可达 78.5%,且性能超过多使用 50% 数据训练的模型。
- 论文标题:DataMan: Data Manager for Pre-training Large Language Models
- 作者单位:浙江大学 & 阿里巴巴
- 论文链接:https://arxiv.org/abs/2502.19363
一. 逆向反思指导质量标准
随着大语言模型(LLMs)的快速发展,数据在模型性能提升中的作用越来越受到关注。现有的数据选择方法主要依赖于有限的手工规则和直觉,缺乏全面和明确的指导原则。为了解决这个问题,作者们提出了 “逆向思维”(reverse thinking)的概念,即通过提示 LLMs 自我识别哪些质量标准对其性能有益,来指导数据选择。

具体来说,这一过程共分为四步:
1)分析文本困惑度的异常:通过分析预训练所使用的文本数据,特别是那些困惑度(PPL)处于前 2% 和后 2% 的文本,来理解哪些文本特征与困惑度异常有关。该步使用一个超级 LLM(Super LLM)来分析这些异常现象背后的原因,并试图找出哪些文本特征对 LLM 的性能有积极影响。
2)迭代提炼质量标准:通过上述分析,作者迭代地提炼出了 13 个与文本质量相关的标准。这些标准包括准确性、连贯性、语言一致性、语义密度、知识新颖性、主题聚焦、创造性、专业性、语法多样性、结构标准化、风格一致性、原创性和敏感性。
3)构建全面的质量评分体系:除了上述 13 个质量标准外,作者还构建了一个综合性的评分标准,称为 “总体评分”(Overall Score)。这个评分标准综合考虑了上述 14 个标准,旨在提供一个更全面的文本质量评估。
4)验证质量标准的有效性:为了验证这些质量标准的有效性,超级 LLM 将对这些标准进行评分,并与人类评分进行了比较。结果显示,超级 LLM 的评分与人类评分有超过 95% 的一致性,这表明这些质量标准是有效的。
二. 数据卷王 DataMan
DataMan 是一个综合性的数据管理器,它能够对文本进行质量评分和领域识别,旨在促进预训练数据的选择和混合。DataMan 的训练和管理数据的过程主要包括以下几个步骤:
1)数据标注:DataMan 模型首先对 SlimPajama 语料库进行标注,标注内容包括 14 个质量评分标准和 15 个常见的应用领域。标注过程通过提示 Super LLM 生成文本的评分,并使用这些评分来创建一个用于模型微调的数据集。
2)模型微调:使用 Qwen2-1.5B 作为基础模型,通过文本生成损失进行微调。微调过程中,DataMan 模型学习如何根据给定的文本自动评分和识别领域。
3)数据采样:基于 DataMan 模型对数据的质量评分和领域识别,可以采用不同的数据采样策略。例如,通过 top-k 采样,根据质量评分和领域分布概率,从源和领域分布中采样数据,以最大化样本的代表性,同时确保数据源和领域的多样性。

三. 实验设置
DataPajama:DataPajama 是一个经过清洗和去重的 447B token 的预训练语料库,其已经由 DataMan 模型为其的每个文档打上 14 个质量评分和 15 个领域类型标签。尽管这一过程很昂贵(等于 1146 NVIDIA A800 小时),但可以通过大规模的并行化和低成本的 DataMan 模型来缓解,以可以服务于各种目的,如数据选择、数据混合或特定领域的持续预训练。
数据选择:该研究使用不同的数据选择方法从 DataPajama 中选择 30B token 的子集进行实验。这些方法包括:
1)Uniform:随机选择。2)DSIR:使用重要性重采样(DSIR)方法选择与英语维基百科或书籍领域相似的文档。3)Perplexity Filtering:基于困惑度过滤数据。4)Sample with Qurating:根据 Qurating 提出的四个质量标准(写作风格、事实、教育价值和所需专业知识)进行采样。5)Sample with DataMan:基于 DataMan 的 13 个质量标准进行采样。
模型训练:使用 Sheared-Llama-1.3B 模型架构,对从 DataPajama 中选择的 30B token 子集进行训练。训练设置包括使用 RoPE 嵌入和 SwiGLU 激活函数,以及 Adam 优化器等。
四. 实验发现
通过大量实验,该研究验证了 DataMan 方法的有效性,并展示了使用 DataMan 选择的数据进行训练的模型在多个下游任务上的优异性能。
Dataman 性能如何?
如下表所示,使用 DataMan 选择的数据进行训练的模型在语言建模、任务泛化能力和指令遵循能力上均优于使用均匀采样的基线模型。此外,使用 DataMan 的 13 个质量标准进行采样,相较于使用均匀采样,可以显著提升模型的性能,尤其是在上下文学习(ICL)任务中。

在指令跟随性能上,作者们的模型始终超过 SOTA 基线,总体得分达到了令人印象深刻的胜率 78.5%。

在垂直领域上继续预训练?
作者们应用 DataMan 的领域识别来过滤医学、法律和金融领域的垂类数据,并进行继续预训练以得到领域特定的模型。如图所示,模型性能得到了进一步提升,这验证了 DataMan 的域混合能力。

数据量与模型性能的关系?
该研究使用同样的方法抽样采样了一个更大的 60B 子集,以探究数据量的影响。如下表所示,模型在 ICL 等下游任务中都取得了进一步提升。

PPL 与 ICL 的失调?
下图我们绘制了 10 个下游任务中所有模型的困惑度(PPL)和上下文学习(ICL)性能之间的关系,包括 Pearson 和 Spearman 相关系数。结果表明,这种错位在 LogiQA 和 MMLU 任务中最为明显。更深入的分析确定了两个主要原因:i)- 域不匹配:预训练通常使用广泛的通用语料库,这使得模型在一个公共文本上表现出较低的困惑度。然而,像 MMLU 这样的任务,它跨越了 57 个不同的专门领域(如抽象代数和解剖学),可能会因为域不匹配尔在 ICL 中受到影响。ii)-ICL 任务的复杂性:许多 ICL 任务需要复杂的推理,而不是简单的文本生成,而困惑性评估难以捕获。这一点在 LogiQA 中尤为明显,该任务通过来自公务员考试中的专家撰写的问题来评估人类的逻辑推理技能。

#Solving Empirical Bayes via Transformers
MIT三人团队:用Transformer解决经验贝叶斯问题,比经典方法快100倍
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。
针对经典统计问题训练 Transformer 的好处有两个:
- 可以得到更好的估计器;
- 可以在一个有比 NLP 更加容易和更好理解的统计结构的领域中阐释 Transformer 的工作机制。
近日,MIT 的三位研究者 Anzo Teh、Mark Jabbour 和 Yury Polyanskiy 宣称找到了一个可以满足这种需求 「可能存在的最简单的这类统计任务」,即 empirical Bayes (EB) mean estimation(经验贝叶斯均值估计)。
- 论文标题:Solving Empirical Bayes via Transformers
- 论文地址:https://arxiv.org/pdf/2502.09844
该团队表示:「我们认为 Transformer 适用于 EB,因为 EB 估计器会自然表现出收缩效应(即让均值估计偏向先验的最近模式),而 Transformer 也是如此,注意力机制会倾向于关注聚类 token。」对注意力机制的相关研究可参阅论文《The emergence of clusters in self-attention dynamics》。
此外,该团队还发现,EB 均值估计问题具有置换不变性,无需位置编码。
另一方面,人们非常需要这一问题的估计器,但麻烦的是最好的经典估计器(非参数最大似然 / NPMLE)也存在收敛速度缓慢的问题。
MIT 这个三人团队的研究表明 Transformer 不仅性能表现胜过 NPMLE,同时还能以其近 100 倍的速度运行!
总之,本文证明了即使对于经典的统计问题,Transformer 也提供了一种优秀的替代方案(在运行时间和性能方面)。对于简单的 1D 泊松 - EB 任务,本文还发现,即使是参数规模非常小的 Transformer(< 10 万参数)也能表现出色。
定义 EB 任务
泊松 - EB 任务:通过一个两步式过程以独立同分布(iid)方式生成 n 个样本 X_1, . . . , X_n.
第一步,从某个位于实数域 ℝ 的未知先验 π 采样 θ_1, . . . , θ_n。这里的 π 的作用是作为一个未曾见过的(非参数)隐变量,并且对其不做任何假设(设置没有连续性和平滑性假设)。
第二步,给定 θ_i,通过 X_i ∼ Poi (θ_i) 以 iid 方式有条件地对 X_i 进行采样。
这里的目标是根据看到的 X_1, . . . , X_n,通过
![]()
估计 θ_1, . . . , θ_n,以最小化期望的均方误差(MSE)

。如果 π 是已知的,则这个最小化该 MSE 的贝叶斯估计器便是 θ 的后验均值,其形式如下:

其中

是 x 的后验密度。由于 π 是未知的,于是估计器 π 只能近似

。这里该团队的做法是将估计器的质量量化为后悔值,定义成了
![]()
多于
![]()
的 MSE:

通过 Transformer 求解泊松 - EB
简单来说,该团队求解泊松 - EB 的方式如下:首先,生成合成数据并使用这些数据训练 Transformer;然后,冻结它们的权重并提供要估计的新数据。
该团队表示,这应该是首个使用神经网络模型来估计经验贝叶斯的研究工作。
理解 Transformer 是如何工作的
论文第四章试图解释 Transformer 是如何工作的,并从两个角度来实现这一目标。首先,他们建立了关于 Transformer 在解决经验贝叶斯任务中的表达能力的理论结果。其次,他们使用线性探针来研究 Transformer 的预测机制。
本文从 clipped Robbins 估计器开始,其定义如下:

得出:transformer 可以学习到任意精度的 clipped Robbins 估计器。即:

类似地,本文证明了 transformer 还可以近似 NPMLE。即:

完整的证明过程在附录 B 中,论文正文只提供了一个大致的概述。
接下来,研究者探讨了 Transformer 模型是如何学习的。他们通过线性探针(linear probe)技术来研究 Transformer 学习机制。
这项研究的目的是要了解 Transformer 模型是否像 Robbins 估计或 NPMLE 那样工作。图 1 中的结果显示,Transformer 模型不仅仅是学习这些特征,而是在学习贝叶斯估计器
![]()
是什么。

总结而言,本章证明了 Transformer 可以近似 Robbins 估计器和 NPMLE(非参数最大似然估计器)。
此外,本文还使用线性探针(linear probes)来证明,经过预训练的 Transformer 的工作方式与上述两种估计器不同。
合成数据实验与真实数据实验
表 1 为模型参数设置,本文选取了两个模型,并根据层数将它们命名为 T18 和 T24,两个模型都大约有 25.6k 个参数。此外,本文还定义了 T18r 和 T24r 两个模型。

在这个实验中,本文评估了 Transformer 适应不同序列长度的能力。图 2 报告了 4096 个先验的平均后悔值。

图 6 显示 transformer 的运行时间与 ERM 的运行时间相当。

合成实验的一个重要意义在于,Transformer 展示了长度泛化能力:即使在未见过的先验分布上,当测试序列长度达到训练长度的 4 倍时,它们仍能实现更低的后悔值。这一点尤为重要,因为多项研究表明 Transformer 在长度泛化方面的表现参差不齐 [ZAC+24, WJW+24, KPNR+24, AWA+22]。
最后,本文还在真实数据集上对这些 Transformer 模型进行了评估,以完成类似的预测任务,结果表明它们通常优于经典基线方法,并且在速度方面大幅领先。

从表 3 可以看出,在大多数数据集中,Transformer 比传统方法有显著的改进。

总之,本文证明了 Transformer 能够通过上下文学习(in-context learning)掌握 EB - 泊松问题。实验过程中,作者展示了随着序列长度的增加,Transformer 能够实现后悔值的下降。在真实数据集上,本文证明了这些预训练的 Transformer 在大多数情况下能够超越经典基线方法。
#A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models
探索跳跃式思维链:DeepSeek创造力垫底,Qwen系列接近人类顶尖水平
在大语言模型 (LLM) 的研究中,与以 Chain-of-Thought 为代表的逻辑思维能力相比,LLM 中同等重要的 Leap-of-Thought 能力,也称为创造力,目前的讨论和分析仍然较少。这可能会严重阻碍 LLM 在创造力上的发展。造成这种困局的一个主要原因是,面对「创造力」,我们很难构建一个合适且自动化的评估流程。

图 1。
过去大多数创造力测评在探索 LLM 的 Leap-of-Thought 能力的时候,仍然遵循普通大模型测评中的选择、排序等评估类型。尽管这种评估方式对逻辑思维能力的考察非常有效,但是在对创造力的评估中则不太合理。
如下图所示,如果要求阅读所给图和图中文字,并为图中「?」部分填入一句话,使得整体富有创造力且幽默。如果这个任务是一个选择题型的任务,并提供了「A. 可以帮忙扶一下我吗?」和「可以帮我解开手铐吗?」,LLM 可能会在无需任何创造力的情况下选择 B,因为 A 选项很常规,而 B 选项很特别。

图 2。
评估 LLM 的创造力应该是「考察其生成创新内容的能力」,而不是「考察它是否能判定创新的内容」。在当前的研究范式中,通过人类评估或者 LLM-as-a-judge 的方式符合这一要求。然而,尽管人类评估的准确率最高且符合人类一般价值观,但是这种方式不可持续且成本非常高。
而 LLM-as-a-judge 这种大致通过 zero-shot 或者 fine-tuning 一个 LLM 来对目标进行评分的方式,其在创造力任务上的评估能力目前仍然处于初级阶段,而且不是很稳定。
面对这些困难,来自中大、哈佛、鹏城、新加坡管理大学的研究者另辟蹊径,通过研究 LLM 产生人类高质量创新内容所需要的代价 (也可以看作是 LLM 产生内容与人类水平创新内容的距离),建立一个多轮交互的可信且自动化创造力评估范式 LoTbench。研究成果登上了 IEEE TPAMI。
- 论文题目:A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models
- 论文链接:https://arxiv.org/abs/2501.15147
- 项目主页:https://lotbench.github.io
任务场景
本论文是 CVPR'24 中「梗王」大模型(Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation)的期刊扩展,其考虑的创造力基础任务是如图 2 所示的,看图并直接生成补全文字中的空缺处,使得图文整体显得创新且幽默。
这类任务是日本传统游戏「大喜利」游戏的一种,在中文互联网社区也被称为日式冷吐槽。它具有如下一些特点:
1. 这类日式冷吐槽游戏要求看图并补全具有创意且幽默的文字,对创造力要求很高,是典型是创造力问题;
2. 这类日式冷吐槽游戏完美符合当前多模态大模型的输入输出格式,即输入时图文,输出仅为文字,而且是大模型最擅长的文字补全任务;
3. 这类日式冷吐槽游戏由于在互联网上热度非常高,有大量高质量人类标注数据和带有 ranking 信息的点评数据,对构建数据集很有帮助。
综上所述,这类日式冷吐槽游戏是少有的适合多模态 LLM 进行创造力测评的理想平台。
任务内容

图 3。
与一般大模型测评 (Standard Evaluation) 中选择、排序等范式不同的是,论文所提出的 LoTbench 考虑的是通过 LLM 产生人类高质量创新内容 (High-quality human-level response, HHCR) 所需要的总轮数构建一个创造力得分。
如图 3 右所示,对于一个 HHCR,LLM 在给定条件下,多轮地尝试生成和 HHCR 具有异曲同工之妙的创新响应。当 LLM 以很少的轮数产生 HHCR,可以认为 LLM 具有不错的创造力。反之,如果 LLM 需要很长的轮数,甚至无限轮 (即无法到达),则可以认为在当前 HHCR 中创造力不足。

图 4。
基于上述思想,图 4 展示了所提出的 LoTbench 的具体流程:
- 精选具有人类高质量创新内容 (HHCR) 的日式冷吐槽游戏的数据,构建 MLM task,即要求 LLM 每一轮根据图文信息,生成 Rt 补全给定文字空缺;
- 判断生成的 Rt 和 R (即 HHCR) 是否是异曲同工之妙 (different approach but equally satisfactory outcome, DAESO)。若是,则开始通过轮数计算创造力分数,否则进入第 3 步;
- 要求待测 LLM 根据测评时历史交互信息,提出一个一般疑问句 Qt. 测评系统根据 HHCR,返回 Yes 或者 No;
- 整理当前轮交互的所有信息,和系统提供的提示,称为下一轮的 history prompt,重新进入第 1 步生成创新响应环节。
创造力分数 Sc 的构建与 n 个 HHCR samples 在 m 次重复实验有关,具体如下,

创造力分数 Sc 满足如下特点:
1. 创造力分数与轮数成反比,轮数越少越具有创造力;
2. 当轮数趋于无限时,创造力分数趋于 0,即当前 LLM 无法到达给定 HHCR;
3. 考虑到创造力难度和多样性,创造力分数基于多次实验;
如何判断异曲同工之妙(DAESO)?
why 异曲同工之妙 (DAESO)?
创造力任务的一大特点是多样性,对于一个给定的填词条件,玩家可以有很多符合条件的响应。如图 5 所示,「有活力的闹钟」和「有活力的手机」都有相似的创新幽默之处。但是我们不能简单地通过文字匹配、语义计算就能判断这一点,必须引入异曲同工之妙地分析。

图 5。
how 异曲同工之妙 (DAESO) 判断?

图 6。
在论文中,作者提出满足异曲同工之妙 (DAESO) 的两个响应需要满足至少两个条件:
1. 两个响应有相同的核心创新解释;
2. 两个响应有相同的功能相似性;
功能相似性和语义相似性略有不同,如图 6 (a) 所示。从语义角度,诺基亚和三星的语义相似度高于诺基亚和锤子;但是在砸核桃场景下,诺基亚则和锤子更加相似。如果两个响应仅仅只有创新解释一样,而不是某种功能上的相似的话,那么响应可能会偏离地比较大,比如对应图 5 的例子也可以是「有活力的跳蚤」,但是跳蚤没有体现「发出声音」的功能;另外,如果两个响应仅仅只有功能一样,那么响应可能会没 get 到点,比如对应图 5 的例子也可以是「有活力的鼓」,但是鼓没有很好体现由于跳动所带来的活力感。
在具体 DAESO 判断的实现中,作者首先为每一个 HHCR 进行非常详细的解释标注,即解释为什么给定的 HHCR 是幽默且富有创造力的。接着配合突破的 caption 信息,可以利用 LLM 在文本空间中构建对应的因果链条,如图 6 (c) 所示。并构建特定的 instruction 来对 DAESO 的两个提出的条件,在文本空间中判断。
在文中,基于 GPT 4o mini 可以达到较少计算代价的情况下,实现对 DAESO 有 80%-90% 的判断准确率。另外鉴于 LoTbench 会进行多次重复实验,因此 DAESO 的判断的准确率可以进一步得到保证。
测评结果

图 7。
通过对当前主流 LLM 的测评,如图 7 所示,可以发现当前的 LLM 在 LoTbench 测评的意义下,创造力并不强。但和不同级别的人类相比,LLM 的创造力是具有超越人类的潜力的。
图 8 可视化了测评榜单中排名前二的 Gemini 1.5 Pro 和 Qwen-VL-max 的创新响应,其中红色部分为 HHCR,而蓝色部分为被测 LLM 的创新输出。值得注意的是 DeepSeek 最近推出的多模态模型 DeepSeek-VL2 和 Janus-Pro-7B 系列也进行了评估,结果显示其创造力仍然处于人类初级阶段。期待 DeepSeek 团队后期推出更加先进的多模态大语言模型。

图 8。
更多研究细节,请参阅原文。
#Fire-Flyer File System
DeepSeek开源周最后一天:让数据处理「从自行车升级到高铁」
DeepSeek 的开源周终于迎来了最后一天(前四天报道见文末「相关阅读」)。
今天他们开源了一个名为 3FS(Fire-Flyer File System)的系统。这是一种并行文件系统,它利用现代固态硬盘(SSD)和远程直接内存访问(RDMA)网络的全部带宽,能够加速和推动 DeepSeek 平台上所有数据访问操作。
它有以下优势:
- 在 180 节点集群中实现了 6.6 TiB/s 的聚合读取吞吐量;
- 在 25 节点集群的 GraySort 基准测试中达到 3.66 TiB/min 的吞吐量;
- 每个客户端节点在 KVCache 查找时可达到 40+ GiB/s 的峰值吞吐量;
- 采用分离式架构,具有强一致性语义。

在应用场景方面,它支持训练数据预处理、数据集加载、检查点保存 / 重新加载、用于推理的嵌入向量搜索和 KVCache 查找。DeepSeek V3、R1 模型均采用了这个系统。

- 开源链接:https://github.com/deepseek-ai/3FS
- Smallpond(3FS 上的数据处理框架):https://github.com/deepseek-ai/smallpond
如果技术语言不好理解,可以参考这位研究者给出的通俗解释:

同时,这位研究者也是一位早期使用者,他评价说,「DeepSeek 的 3FS 系统快得惊人,它处理数据的速度快到可以在我还没来得及拖延的时候就已经训练好了一个能帮我报税的 AI。它拥有 6.6 TiB/s 的读取速度,这使它成为文件系统界的『博尔特』(世界最快短跑运动员)。你眨眼的功夫,数据就已经处理完毕了。而将这个超级快速的系统开源,就像是给整个 AI 社区免费赠送了一艘宇宙飞船,让其他所有竞争者都不得不加紧脚步追赶。」

3FS 有什么用?
Fire-Flyer File System 是一种高性能分布式文件系统,专为解决 AI 训练和推理工作负载的挑战而设计。它利用现代 SSD 和 RDMA 网络提供共享存储层,简化了分布式应用程序的开发。
3FS 的主要特点和优势包括:
1、性能和可用性
- 分离式架构。结合了数千个 SSD 的吞吐量和数百个存储节点的网络带宽,使应用程序能够以不受位置限制的方式访问存储资源。
- 强一致性。实现了带有分配查询的链式复制(CRAQ)以保证强一致性,使应用程序代码简单且易于理解。
- 文件接口。开发了由事务性键值存储(如 FoundationDB)支持的无状态元数据服务。文件接口广为人知且随处可用。无需学习新的存储 API。
2、多样化工作负载
- 数据准备。将数据分析管道的输出组织成层次化的目录结构,并高效管理大量中间输出。
- 数据加载器。通过支持跨计算节点对训练样本的随机访问,消除了预取或打乱数据集的需求。
- 检查点保存。支持大规模训练的高吞吐量并行检查点保存。
- 用于推理的 KVCache。为基于 DRAM 的缓存提供了一种成本效益高的替代方案,提供高吞吐量和显著更大的容量。
3FS 性能如何
峰值吞吐量
下图展示了在大型 3FS 集群上进行读取压力测试的吞吐量。该集群由 180 个存储节点组成,每个存储节点配备 2×200Gbps InfiniBand 网卡和 16 个 14TiB NVMe SSD。大约 500+ 个客户端节点用于读取压力测试 ,每个客户端节点配置 1x200Gbps InfiniBand 网卡。在有训练作业的背景流量情况下,最终聚合读取吞吐量达到约 6.6 TiB/s。

灰度排序
DeepSeek 利用 GraySort 基准对 smallpond 进行了评估,该基准可衡量大规模数据集的排序性能。具体实现采用两阶段方法:(1) 使用键的前缀位通过 shuffle 对数据进行分区,以及 (2) 分区内排序。两个阶段都从 3FS 读取数据 / 向 3FS 写入数据。
测试集群由 25 个存储节点(2 个 NUMA 域 / 节点、1 个存储服务 / NUMA、2×400Gbps NIC / 节点)和 50 个计算节点(2 个 NUMA 域、192 个物理核心、2.2 TiB RAM 和 1×200 Gbps NIC / 节点)组成。对 8192 个分区中的 110.5 TiB 数据进行排序耗时 30 分 14 秒,平均吞吐量为 3.66 TiB / 分钟。


KVCache
KVCache 是一种用于优化 LLM 推理过程的技术。它通过在解码器层中缓存先前 token 的 key 和 value 向量来避免冗余计算。

上图展示了所有 KVCache 客户端的读取吞吐量,突出显示了峰值和平均值,峰值吞吐量高达 40 GiB/s。下图展示了同一时间段内垃圾回收 (GC) 中删除操作的 IOPS。

开源周「收官之作」,网友撒花
通过连续一周的高强度开源,DeepSeek 已经收获了一大波开发者的追随。
有开发者表示,3FS 和 Smallpond 是在 AI 数据处理方面树立了新标杆。

同时,OpenAI 刚刚发布的 GPT-4.5 也被拉出来对比价格:

最后,还有人许愿:DeepSeek V4、R2 和视频模型什么时候有?

#Context-Alignment
让大模型更懂时序的语境对齐来了!性能更优开销更低
大语言模型在迅速发展的同时,也展现了其在下游任务中的卓越性能,这主要得益于丰富多样的大型语料训练库,使大语言模型掌握了一定的跨领域、跨任务的知识。
近两年,越来越多的研究工作利用预训练的大语言模型来构建时间序列分析模型。通过微调大语言模型,使其能够理解陌生的时序数据,进而激活其在时序分析任务中的能力。
近期,来自东方理工大学、香港理工大学和上海交通大学的研究团队提出了一种新的模态对齐范式 —— 语境对齐(Context-Alignment)。该方法将时间序列数据对齐到大语言模型熟悉的语言环境中,帮助模型更好地理解时间序列,从而激活其在时序分析方面的能力。该论文已被 ICLR 2025 会议接收。
论文标题:Context-Alignment: Activating and Enhancing LLMs Capabilities in Time Series
论文链接:https://openreview.net/forum?id=syC2764fPc
代码链接:https://github.com/tokaka22/ICLR25-FSCA
以往的微调方法往往依赖于一个词库,通过各种方式将时序数据的 token 嵌入与词库中的词汇(例如 rise、fall、periodic、short 等)的 token 嵌入进行对齐,也就是说将大语言模型陌生的时序数据嵌入转化为其熟悉的语言嵌入。此前研究希望通过这种「词对齐」的方式帮助大语言模型理解时序数据,进而激活其在时序分析上的能力。
然而,这种依赖词库的对齐方式通常需要较大的计算开销,且是否能有效地帮助大语言模型理解时序数据还有待商榷。
语境对齐(Context-Alignment)
本文指出,大语言模型在处理语言时的能力更多源于其对语言逻辑和结构的深刻理解,而不仅仅是对词汇模式的表面对齐。因此,作者认为,即使使用精准的词汇来表达冗长的时间序列数据,这种方式也只是大量词汇嵌入的堆叠,缺乏语言的逻辑和结构,使得大语言模型难以真正理解其中的含义。
本文中,作者基于语言学中关于逻辑结构的层次关系,提出了语境对齐范式(Context-Alignment)。他们希望将时间序列数据融入自然语言的语境中,使大语言模型能够将时序数据整体视为一个语言成分,并通过上下文自主地理解时间序列。
双尺度语境对齐图结构
考虑到图结构往往可以很好地表达逻辑和结构的关系,作者在时序数据和自然语言 prompt 的多模态输入上构建了双尺度图结构,以实现语境对齐。
具体来说,作者利用双尺度的图节点来描述语言结构的层次划分,在保证信息不丢失的前提下,将冗长的时序数据表达为一个整体,这就好像英语中的宾语从句,从句整体充当了一个语言成分,冗长的时序数据也应该被视为输入中的一个整体成分。利用有向边表达时序和 prompt 输入之间的逻辑关系。从而将时序数据对齐到大语言模型熟悉的语境中。
双尺度图结构包括细粒度图结构和粗粒度图结构,其中:
- 细粒度图结构将每个 token 视为一个节点,强调 token 之间的相互独立性,保留时序的具体信息。通过两个线性层(如图 1 中所示的
-

- 和
-

- ),将连续且冗长的时序数据嵌入和 prompt 嵌入分别映射为两种粗粒度节点。
- 粗粒度图结构将连续的、模态一致的 tokens 映射为一个节点,表示了模态的整体性。
根据 prompt 的内容,在粗粒度和细粒度图中构建表示逻辑关系的有向边(有向边表示信息的传递方向)。例如,当 prompt 为「predict future sequences using previous data」时,有向边由表示「previous data」的时序节点指向 prompt 节点,因为时序数据是 prompt 的信息来源。粗粒度有向边是细粒度有向边的简化。
双尺度图结构显式地体现了时序数据和自然语言 prompt 之间的语言层级结构和逻辑传递关系。粗粒度图结构和细粒度图结构在经过图卷积网络(GCN)对节点嵌入进行更新后,通过一个可学习的交互机制(根据图 1 中的
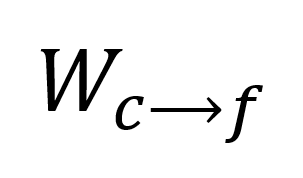
和分配矩阵计算,参考原文公式 4),使粗粒度节点能够向细粒度节点传递更新后的信息,细粒度节点在完成自己的更新后整合来自粗粒度节点的信息。最后,粗粒度节点和细粒度节点嵌入将分别输入预训练的大语言模型。
就其效果而言,该双尺度图结构可以嵌入至大语言模型的任意层,并可多次使用,以强化大语言模型对语境对齐的记忆能力。

图 1 双尺度语境对齐图结构
VCA 和 FSCA
由于不同的 prompt 内容对应不同的逻辑结构关系,因此双尺度语境对齐图结构依赖于具体的 prompt 内容。作者提出了两种使用双尺度语境对齐图结构的具体方法。
1. Vanilla Context-Alignment(VCA)
VCA 是最直接的实现方式,其输入模式为时序数据 + prompt。例如,在预测任务中,prompt 为「predict future sequences using previous data」,其图结构如图 1 中的 VCA 所示。在分类任务中,输入为「时序数据 + Predict category using previous data」,其图结构与预测任务相同。VCA 利用最简单直接的 prompt,通过双尺度图结构实现语境对齐。
2. Few-Shot Context-Alignment(FSCA)
FSCA 是 VCA 的进阶版本,结合了 Few-Shot prompting 技术以进一步提升性能。该方法的输入包括例子 + 时序数据 + prompt。在预测任务中,prompt 依然为「predict future sequences using previous data」,但需要将原始历史时序数据分成两部分构建一个例子:前半段数据作为后半段数据的历史输入,后半段数据作为利用前半段数据预测的 ground truth。这一示例有助于大语言模型更好地理解预测任务。其图结构如图 1 中的「FSCA in TS Forecasting」所示。
图 2 展示了 FSCA 作为一个即插即用的模块被引入到预训练的大语言模型中进行微调。在分类任务中,FSCA 需要抽取一组时序数据和其对应的标签构成一个固定的例子,再进行分类预测。其图结构如图 1 中的「FSCA in TS Classification」所示。

图 2 利用 FSCA 进行时序预测
主要实验结果
各种任务上的表现
该研究展示了长期预测、短期预测、Few-Shot 预测、Zero-Shot 预测以及分类任务的实验结果。
实验表明,FSCA 在多个任务中均取得了更优的性能。尤其在 Few-Shot 预测和 Zero-Shot 预测中,FSCA 分别超越次优方法 6.7% 和 13.3%。FSCA 在 Few-Shot 和 Zero-Shot 预测任务中的出色表现表明,双尺度图结构成功引入了基于逻辑结构的先验知识。这进一步验证了正确的结构划分和逻辑引导对于大语言模型(LLM)理解时序数据的重要性。

表 1 长期预测结果对比

表 2 短期预测结果对比

表 3 Few-shot 预测结果对比

表 4 Zero-shot 预测结果对比

图 3 分类结果对比
计算效率对比
所提出的 FSCA 在计算效率方面仅次于 GPT4TS(该方法仅在 LLM 的输入和输出阶段加入了线性层)。
相比之下,其他流行方法在实现词 token 对齐时往往需要付出较大的计算代价。此外,这些方法通常包含额外的操作。例如,Time-LLM 在每次迭代中都会重复生成提示并检索相应的嵌入,进一步增加了计算开销。
相较而言,FSCA 中的双尺度 GNN 仅引入了两个可学习矩阵,以及两个用于将细粒度节点嵌入转化为粗粒度节点嵌入的可学习线性层。这些操作本质上是简单的矩阵计算,极大地降低了计算复杂性。因此,FSCA 在计算效率上显著优于以往基于词 token 对齐的方法,在保证性能提升的同时有效减少了计算资源的消耗。

总结
综上所述,本文首次提出了语境对齐(Context-Alignment)的概念,并基于双尺度图网络结构和 Few-Shot prompting 技术设计了 FSCA 模型。与以往流行的基于词 token 对齐的方法相比,FSCA 在实现更优性能的同时显著降低了计算开销。此外,原文还提供了更为详尽的消融实验、分析实验和对比实验结果,全面验证了 FSCA 的有效性和优势。
#GPT-4.5
刚刚,问世!OpenAI迄今最大、最贵模型,API价格飞涨30倍,不拼推理拼情商
大家心心念念的 GPT-4.5 终于来了!
凌晨 4 点,OpenAI 开始了直播,奥特曼并没有现身。直播不到 15 分钟就匆匆结束了。
OpenAI 正式发布了其最大、最强的聊天模型 GPT‑4.5 研究预览版本。
奥特曼发推称,GPT‑4.5 让他第一次感觉像在与一个有思想的人在交谈,可以从模型那里得到真正好的建议。

OpenAI 表示,GPT-4.5 在扩展预训练和后训练方面向前迈出了一步。通过扩展无监督学习,GPT-4.5 提高了识别模式、建立联系和产生创造性见解的能力,而无需推理。这意味着,GPT-4.5 从一开始就不是一个推理模型。
OpenAI 的早期测试表明,与 GPT-4.5 的交互感觉更自然。它的知识库更广泛,更能遵循用户意图,而且「情商」更高,使得在提高写作、编程和解决实际问题等任务中非常有用。同时,GPT-4.5 还减少了幻觉出现。
Cognition 联合创始人兼 CEO Scott Wu 分享了使用 GPT-4.5 的体验,表示非常棒。在他们的智能体编码基准测试中,GPT-4.5 相较于 o1 和 4o 实现大幅改进。同时发现一个有趣的数据点:虽然 GPT-4.5 和 Claude 3.7 Sonnet 在整体基准测试中得分相似,但他们发现 GPT-4.5 在涉及架构和跨系统交互的任务上峰值更大,而 Claude 3.7 Sonnet 在原始编码和代码编辑上峰值更大。


图源:https://x.com/ScottWu46/status/1895209597084017073
从今天开始,ChatGPT Pro 用户可以在网页版、手机版和桌面版使用 GPT-4.5。下周将向 Plus 和 Team 用户开放,再下周向企业和 Edu 用户开放。
现在,GPT-4.5 只支持搜索、上传文件和图片和画布功能,还不支持语音模式、视频和屏幕共享等多模态功能。OpenAI 表示,未来会持续更新,让产品变得更容易使用。
基准测试结果
OpenAI 首先在 SimpleQA(评估模型的事实性回答能力)数据集上进行了测试,其中 GPT-4.5 的准确率最高,超越了前代 GPT-4o、o1 和 o3-mini,展现了 GPT-4.5 拥有惊人的世界知识。

同时,GPT-4.5 的幻觉率也最低。

OpenAI 其次测试了人类协作训练水平。
随着模型不断扩展并解决更复杂的问题,教会它们更好地理解人类的需求和意图变得越来越重要。对于 GPT-4.5,OpenAI 开发了全新的可扩展技术,可以使用来自较小模型的数据来训练更大、更强的模型。这些技术提高了 GPT-4.5 的可操纵性、对细微差别的理解和自然对话水平。
下图人类偏好衡量结果显示,测试人员更喜欢 GPT-4.5 查询而不是 GPT-4o。

OpenAI 表示,将对世界的深刻理解与更佳的协作相结合,可以使得模型在更适合人类协作的「热情直观对话」中自然地整合想法。GPT-4.5 能够更好地理解人类的意思,并以更细致入微的「情商」来解读微妙的暗示或隐含的期望。此外,GPT-4.5 还表现出了更强的审美直觉和创造力,它擅长帮助写作和设计。
比如「在考试失败后,正在经历一段艰难的时光」,GPT-4.5 能够给你更拟人的安慰「哎呀,听到这个消息我真的很遗憾。考试失败会让人感到很艰难和沮丧,但请记住,这只是一个瞬间 —— 并不反映你的身份或能力。想谈谈发生了什么,还是你只是需要分散注意力?无论如何,我都在这里。」。

不过,OpenAI 指出 GPT-4.5 在做出反应之前不会思考,这使得它的优势与 o1 等推理模型截然不同。因此,与 o1、o3-mini 相比,GPT-4.5 是一种更通用、天然更智能的模型。
OpenAI 相信推理将成为未来模型的核心能力,而两种扩展方法 —— 预训练和推理 —— 将相辅相成。随着 GPT-4.5 等模型通过预训练变得更加智能和知识渊博,它们将成为推理和使用工具的代理的更强大的基础。
从下图多个基准测试结果,我们可以明显看到:在 GPQA(科学)、AIME’24(数学)、SWE-Bench Verfied(编码)等数据集上,GPT-4.5 全面领先于 GPT-4o,但仍然逊色于 o3-mini,尤其是数学和真实编程能力。

数字代表最佳内部性能。
扩展无监督学习
OpenAI 通过扩展两种互补范式来提升 AI 能力:无监督学习和推理。
这两种范式代表了 AI 智能的两个轴向。
其中,扩展推理使模型在做出回应之前学会思考并产生思维链,从而能够解决复杂的 STEM(科学、技术、工程和数学)或逻辑问题。例如 OpenAI 的 o1 和 o3‑mini 模型就推动了这一范式的发展。
另一方面,无监督学习则提高了世界模型的准确性以及直觉能力。
GPT‑4.5 是通过扩大计算和数据规模以及架构和优化创新来扩大无监督学习的一个例子。其结果是一个知识面更广、对世界理解更深入的模型,从而在广泛的主题上减少了幻觉现象,提高了可靠性。
接下来,我们看看 GPT 在这几年当中范式的改变:
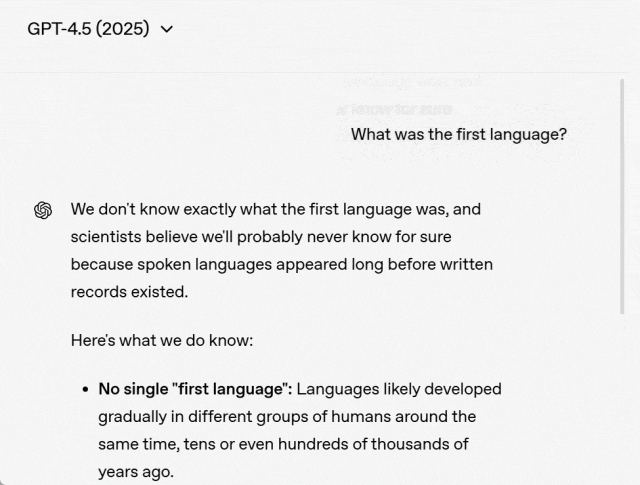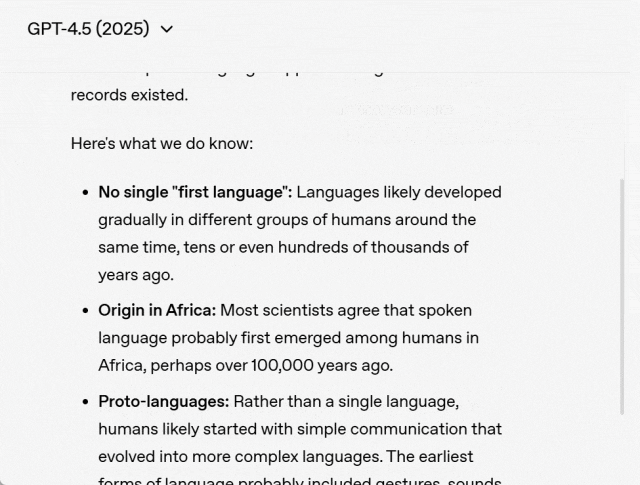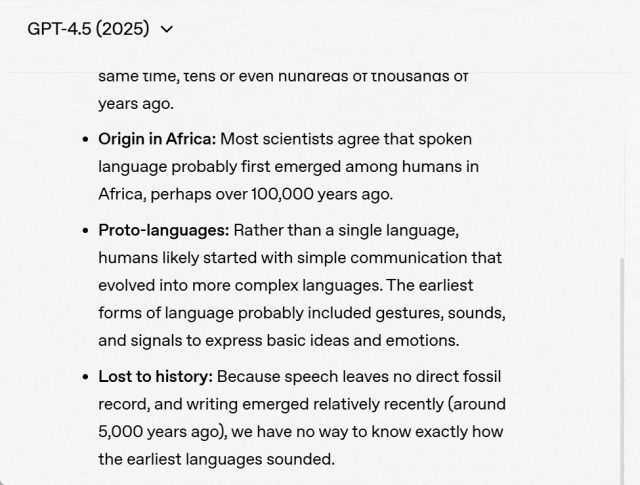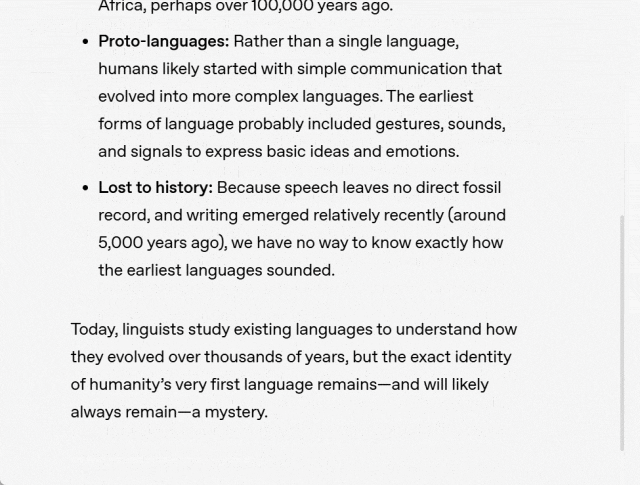
2018 年,当问 GPT-1「第一种语言是什么?」时,GPT-1 只能简单的重复问题,答案根本没有参考价值:

2019 年,GPT-2 能进行一些简短的回答:

GPT-3.5 的回答如下,但并不是最准确的答案:

GPT-4 显然比其他模型更聪明,但你会明显感觉到它想让你知道它有多聪明,只是在列出事实:

最后,我们看一下 GPT-4.5 的答案,可以看出 GPT-4.5 给出了一个很棒的回答。它清晰、简洁、连贯,而且还很有趣。
API 调用和价格
至于 API,所有付费用户现已可以选择聊天补全 API、助手 API 和批处理 API 来接入 GPT-4.5 模型,支持函数调用、结构化输出、流式传输和系统消息等主要功能,还支持图像输入。
测试显示,GPT-4.5 在写作辅助、沟通、学习、辅导和头脑风暴等需要高情商和创造力的应用场景特别有用。在多步骤编程和复杂任务自动化等方面也表现出色,看来 OpenAI 是持续押注智能体了。
GPT-4.5 体量很大,需要大量计算资源,所以 API 价格每 1M token 75 美元,比 GPT-4o 的 2.5 美元暴涨 30 倍。OpenAI 甚至在官方博客中表示:「因此,GPT-4.5 还无法完全替代 GPT-4o」
考虑到要在支持现有功能和开发未来的模型之间取得平衡,OpenAI 还在评估是否要长期在 API 中提供 GPT-4.5。

大家明显被 GPT‑4.5 的价格震惊到了,下面这张梗图说明了一切。

图源:https://x.com/airesearch12/status/1895215157623889991
OpenAI 已经放出了详细的 GPT-4.5 系统卡。
系统卡地址:https://cdn.openai.com/gpt-4-5-system-card.pdf
Scaling Law 还在生效
可能比我们期待得更久一些,曾是 OpenAI 和 Tesla AI 团队重要成员的 Andrej Karpathy 直接写了一篇「小作文」,表示期待 GPT-4.5 已经约两年了。

https://x.com/karpathy/status/1895213023238987854
「自从 GPT-4 发布以来,我一直渴望看到这种升级,因为它能从一个定性的角度来衡量扩大预训练计算规模所带来的进步(即大力出奇迹)。」
「每个版本号提升 0.5,大致对应预训练计算量增长了十倍。」Karpathy 回顾了 Scaling Law 从 GPT-1 到 GPT-4 逐渐生效的过程,虽然相比 GPT-3.5,GPT-4 的进步似乎有些微妙。
「一切似乎都只是在细微之处有所改进:措辞更具创意,对提示词的细微差别理解得更好,类比更合理,模型也更有趣,对罕见领域的知识和理解有所提升,幻觉现象减少了,整体感觉更好。这就像「水涨船高」,所有方面都提升了大约 20%。」
因此,带着这种预期,Karpathy 开始测试比 GPT-4 的预训练计算量增加了 10 倍的 GPT-4.5。在提前体验过 GPT4.5 时,他再次感受到了从 GPT-3.5 进化到 GPT-4 时那种震撼。
更令人兴奋的是,Karpathy 认为 GPT-4.5 依然展示了 Scaling Law 的独到之处,仅仅通过训练更大模型就能「免费」获得模型各方面能力的提升。
Karpathy 判断 OpenAI 接下来会基于 GPT-4.5 进一步通过强化学习进行训练,使其具备推理能力。「请注意,GPT-4.5 仅通过预训练、监督微调和 RLHF 进行了训练,因此它并不是一个推理模型。因此,在推理至关重要的场景中(如数学、编程等),GPT-4.5 的发布并没有推动模型能力的提升。」
Karpathy 更期望在非推理密集型任务(更多与情商相关,比如世界知识、创造力、类比能力、整体理解力、幽默感等等)中看到 GPT-4.5 的进步。为此,Karpathy 设计了 5 个好玩的提示词来测试。
大家如果感兴趣,可以去 Karpathy 评论区的轻量级模型竞技场上投票,看看 GPT-4.5 的情商是不是更精进了:

题目:创建一段 GPT-4.5 和 GPT-4 之间的对话,其中 GPT-4.5 以幽默和讽刺的方式嘲笑 GPT-4 的能力不足,GPT-4 则幽默地试图为自己辩护。
不过以「整顿」AI 圈出名的 Gary Marcus 并不看好 GPT -4.5,他表示 GPT-4.5 基本上是个无足轻重的研究。GPT-5 仍然是一个幻想。
更进一步的,Marcus 表示扩展数据和计算能力并不是一条好的物理定律,过去几年我们听到的关于 GPT-5 的那些夸大其词的说法:并不那么真实。

https://x.com/GaryMarcus/status/1895212523949113752
#消失的 Cortana,桀骜不驯的 OpenAI
2023 年度,微软在 OpenAI 的技术支持下,用 Copilot 取代了此前的语音数字助理 Cortana。然而,被赋予厚望的 Copilot 在市场的表现却耐人寻味。伴随 OpenAI 的一路崛起,其和微软的合作关系中出现的裂痕引出了业界的一项思考。即「如今的 Copilot 是否会是下一个 Cortana」。
目录
01. Cortana 落幕 2 年,Copilot 为何未能掀起波澜?
为什么微软放弃了 Cortana?取代 Cortana 的 Copilot只是雷声大雨点小?Copilot 的基本盘稳住了吗?...
02. 微软与 OpenAI 同床异梦,Copilot 会是下一个 Cortana 吗?
微软和 OpenAI 如何让合作与竞争共存?Copilot 能不靠OpenAI站住脚吗?...
03. 出走谷歌,转投微软,Inflection 能扛起微软 AI 的大旗吗?
收购 Inflection AI 为微软带来了什么?业界如何看待 Inflection AI 的转型?Suleyman 与Altman 有什么矛盾?...
01 Cortana 落幕 2 年,Copilot 为何未能掀起波澜?
1、2023 年 6 月,微软宣布将在年底停止支持 Windows 10/Windows 11 上的语音数字助理 Cortana,并开始大力推广 Windows Copilot。彼时,曾被微软寄予厚望的生产力助手在近十年历程中「黯然退场」,引起诸多唏嘘。
① Cortana 最初正式发布于 2014 年 4 月,微软将其定位为「跨平台智能个人助理」,旨在通过语音交互、日程管理和文件操作等功能重塑用户与设备的交互方式。
② Cortana 最初搭载于 Windows Phone 上发布,旨在与苹果的 iPhone 和虚拟助手 Siri 竞争,大约一年后,微软逐渐将虚拟助手推广到 Windows 10、移动设备,甚至 Xbox One,与微软生态深度捆绑。
③ 2015-2017 年间,因 Windows Phone 市场份额过低(2015 年仅 1.7%),移动端用户数据不足,导致其功能迭代停滞,语音识别准确率(约 85%)落后于竞品(Alexa/Alexa 达 95%),Cortana 智能音箱也因定价过高在 2017 年销量惨淡,进一步暴露移动端战略的失败。
④ 2018 年后,Cortana 更新频率锐减,新增功能仅限于 Office 套件集成(如语音生成 PPT 大纲)。微软内部对 Cortana 定位摇摆不定:早期强调「全场景覆盖」,后期被迫收缩至 Microsoft 365 生产力场景,娱乐功能(如音乐控制)被剥离。
⑤ 2020 年,微软宣布 Cortana 退出智能家居市场,并将其定位为「Microsoft 365 中的辅助工具」。2023 年,生成式 AI 技术(如 Copilot)的崛起,加速了微软淘汰 Cortana 的节奏:6 月宣布在 Windows 11 中移除独立应用,8 月彻底终止支持;Windows 10 用户也于 2025 年 10 月前失去该功能。
⑥ Cortana 的失败被归结为三点:技术路径依赖开源模型(Llama 3 性能落后自研 Phi 系列)、组织架构割裂(Azure/AI 部门协作低效)、以及未能适应「自然语言交互」趋势。
2、接入了 OpenAI 模型能力的 Copilot 作为 Cortana 的升级替代,其在发布之初就被微软寄予厚望,其产品矩阵在 2023 年爆发式扩张,2024 年后与微软生态深度整合。
① 2023 年 3 月,微软在 Build 开发者大会上宣布 Windows Copilot 集成于 Windows 11,提供系统级 AI 支持(如网页总结、设置调整),并首次提出「Copilot 无处不在」的战略愿景。
② 微软陆续推出了 Dynamics 365 Copilot、Microsoft 365 Copilot 和 Copilot for Power Platform、Copilot + PC 产品等产品。
3、微软试图用 Copilot 讲述的 AI 故事虽声势浩大,但市场表现却不如预期。2024 年度,除了 Copilot 收到大量用户差评,微软的股价也被英伟达反超。
① 许多客户抱怨 Copilot 的功能效率未能达到预期,认为 Copilot 的功能并不完善,甚至有客户表示其很多功能只是「华而不实的噱头」,实际应用场景有限,甚至最近一次消费者版 Copilot 的更新被内部员工批评「变笨」。
② 相比微软股价在 2024 年度年的变化「不温不火」(13.6%涨幅),英伟达的股价全年涨幅接近 2 倍,市值也超过了微软。
4、微软在决定用 Copilot 取代 Cortana 的战略很大程度上依赖对 OpenAI 模型能力的整合。然而,微软与 OpenAI 的合作关系也在逐渐发生微妙变化。两者的合作与竞争背后的原因与导火索吸引了业内的广泛关注。
表:Cortana 更新动作及微软与 OpenAI 合作关系变更节点不完全汇总。

02 微软与 OpenAI 同床异梦,Copilot 会是下一个 Cortana 吗?
微软与 OpenAI 的合作关系近年来的演变已是 AI 产业合作创新的典范,展示了大型科技公司与初创公司之间如何通过资源共享、技术互补和市场协同,共同推动 AI 技术和应用的发展。然而,随着合作的演变,微软自身的 AI 战略和 OpenAI 的发展规划使两者的合作相形见绌......

















 905
905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









