







我自己的原文哦~ https://blog.51cto.com/whaosoft/13884576
#8/8/7分被NeurIPS拒稿
谢赛宁读博投的首篇论文,10年后获AISTATS 2025时间检验奖
5 月 3 日至 5 日,第 28 届国际人工智能与统计学会议(AISTATS)在泰国举办。

作为人工智能、机器学习与统计学交叉领域的重要国际会议,自 1985 年创办以来,AISTATS 致力于促进计算机科学、人工智能、机器学习和统计学等领域研究者之间的交流与合作。
昨日,会议主办方公布了本年度时间检验奖,授予 UCSD 与微软研究院合著的论文《Deeply-Supervised Nets》(深度监督网络),共同一作分别为 Chen-Yu Lee(现为谷歌研究科学家)和 AI 圈所熟知的谢赛宁(现为纽约大学助理教授)。该论文被当年的 AISTATS 接收。

根据 Google Scholar 数据显示,该论文被引数已经超过了 3000,足可见其含金量。

在得知自己 10 年前的论文获得 AISTATS 2025 时间检验奖之后,谢赛宁分享了更多背后的故事。
他表示,《Deeply-Supervised Nets》是读博期间提交的第一篇论文,并且有趣的是,这篇论文最初被 NeurIPS 拒稿了(分数为 8/8/7)。那种痛苦一直萦绕在他心头,也许现在终于可以放下了。他还说到,不会将投顶会比作「抽奖」,但坚持不懈确实能带来很大的帮助。
最后,谢赛宁寄语同学们:如果你们在最近的论文评审结果出来之后感到沮丧,并正在为下一篇论文做准备,则可以将他的经历当作一点小小的提醒,继续前进(就会有收获)。

同样地,另外一位共同一作 Chen-Yu Lee 也发文对 10 年前的论文获得 AISTATS 2025 时间检验奖感到自豪,并表示这项研究成果至今仍具有重要意义和影响力。

评论区的网友纷纷发来对谢赛宁论文获奖的祝贺。

接下来,我们看看这篇来自 10 年前的论文主要讲了什么内容。
论文讲了什么?
- 论文标题: Deeply-Supervised Nets
- 论文地址:https://arxiv.org/pdf/1409.5185
论文摘要:近年来,神经网络(尤其是深度学习)的复兴备受关注。深度学习可采用无监督、有监督或混合形式,在图像分类和语音识别等任务中,当训练数据量充足时,其性能提升尤为显著。
一方面,分层递归网络已展现出自动学习数千乃至数百万特征的巨大潜力;另一方面,深度学习仍存在诸多悬而未决的基础性问题,也引发了学界对其局限性的担忧。
论文中表示,在当时深度学习框架存在的问题包括:隐藏层学习到的特征的透明度和辨别力降低;梯度爆炸和消失导致训练困难;尽管在理论方面做了一些尝试,但对算法行为缺乏透彻的数学理解等。
尽管如此,深度学习能够在集成框架中自动学习和融合丰富的层次特征。这得益于研究人员开发出了各种用于微调特征尺度、步长和收敛速度的方法,还提出了多种技术从不同角度提升深度学习的性能,例如 dropout 、dropconnect 、预训练和数据增强等。
此外,梯度消失的存在也使得深度学习训练缓慢且低效 。
本文提出了深度监督网络 (deeply-supervised nets,DSN) 来解决深度学习中的特征学习问题,该算法对隐藏层和输出层都强制进行直接和早期监督。并且还为各个隐藏层引入了伴随目标(companion objective),将其用作学习过程的附加约束(或新的正则化)。从而显著提高了现有监督深度学习方法的性能。
此外,该研究还尝试使用随机梯度技术为本文方法提供依据。证明了所提方法的收敛速度优于标准方法,得出这一结论的前提是假设优化函数具有局部强凸性(这是一个非常宽松的假设,但指向一个有希望的方向)。
这篇论文还提到,文献 [1] 采用分层监督预训练策略,而本文提出的方法无需预训练。文献 [26] 将标签信息用于无监督学习,文献 [30] 则探索了深度学习的半监督范式。文献 [28] 使用 SVM 分类器替代 CNN 传统的 softmax 输出层。本文提出的 DSN 框架创新性地支持 SVM、softmax 等多种分类器选择,其独特价值在于实现对每个中间层的直接监督控制。
实验结果表明:无论在 DSN-SVM 与 CNN-SVM 之间,还是 DSN-Softmax 与 CNN-Softmax 之间,本文方法均取得一致性性能提升,并在 MNIST、CIFAR-10、CIFAR-100 及 SVHN 数据集上刷新当前最优纪录。
图 2 (a) 和 (b) 展示了四种方法的结果,DSN-Softmax 和 DSN-SVM 优于它们的竞争 CNN 算法。图 2 (b) 显示了针对不同大小的训练样本进行训练时不同方法的分类误差(在 500 个样本时,DSN-SVM 比 CNN-Softmax 提高了 26%)。图 2 (c) 显示了 CNN 和 DSN 之间的泛化误差比较。


表 2 显示,在 CIFAR-10 和 CIFAR-100 上的性能提升,再次证明了 DSN 方法的优势。

为了比较 DSN 与 CNN 分别学习到什么特征,本文从 CIFAR-10 数据集的十个类别中各选取一个示例图像,运行一次前向传播,并在图 (3) 中展示从第一个(底部)卷积层学习到的特征图。每个特征图仅显示前 30% 的激活值。DSN 学习到的特征图比 CNN 学习到的特征图更直观。

需要特别说明的是,本框架可兼容近期提出的多种先进技术,如模型平均、dropconnect 和 Maxout 等。论文表示通过对 DSN 的精细化工程优化,可进一步降低分类误差。
#Llama-Nemotron
超越DeepSeek-R1,英伟达开源新王登顶!14万H100小时训练细节全曝光
超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!
现在,英伟达Llama-Nemotron系列模型,正式超越DeepSeek-R1!
而且,这些模型已经全部开源了。
换句话说,在推理吞吐量和内存效率上显著超越DeepSeek-R1的一系列推理模型,已经开源可用了。
超越DeepSeek-R1的模型,究竟是怎么炼出的?
就在刚刚,英伟达发布了技术报告中,揭秘了模型训练的关键——
· 利用合成数据监督微调+强化学习,全面提升模型的推理能力
· 从头构建完善的后训练流程
论文链接:https://arxiv.org/abs/2505.00949
上个月,英伟达正式官宣了的Llama-Nemotron 253B,一下子就让发布3天的Llama 4变成了「陪衬」。(后者还陷入了刷榜等「诚信危机」)
发布之后,英伟达的这一系列模型在业界引起不小的轰动。
根据人工分析智能指数,截至2025年4月,Llama-Nemotron-Ultra被认为是目前「最智能」的开源模型。
这次,英伟达一口气推出了Llama-Nemotron系列三个模型——LN-Nano 8B,LN-Super 49B和LN-Ultra 253B。
值得一提的是,LN-Ultra不仅在性能上超越了DeepSeek-R1,还能在单个8xH100节点上运行,推理吞吐量更高。
这些模型针对高吞吐量推理进行了优化,同时保持强大的推理能力和最多128K的上下文长度。
LN-Ultra在各类推理任务中展现出领先的开源模型性能
并且,在全球AI开源届,英伟达首次推出了推理开关功能,用户只需通过系统提示词「detailed thinking on/off」就可以动态切换标准聊天模式和推理模式。
这种设计让模型既能满足日常通用需求,也能胜任复杂的多步骤推理,无需使用不同的模型或架构。
揭秘构建过程
Llama-Nemotron模型的构建,分为五个阶段。
第一阶段:利用神经架构搜索(NAS)在Llama 3系列模型基础上优化推理效率,并引入前馈网络融合(FFN Fusion)。
第二阶段:通过知识蒸馏和继续预训练来恢复模型性能。
第三阶段:进行有监督微调(SFT),结合标准指令数据和来自DeepSeek-R1等强大教师模型的推理过程,从而让模型具备多步骤推理能力。
第四阶段:在复杂的数学和STEM数据集上进行大规模强化学习,这是学生模型能够超越教师模型能力的关键一步。对于LN-Ultra,这一阶段在GPQA-D基准测试上带来了显著性能提升,确立其作为当前开源领域科学推理最强模型的地位。
为了支持如此大规模的强化学习训练,团队专门开发了新的训练框架,包含多项优化措施,其中最重要的是支持 FP8精度的生成能力。
最后一个阶段:简短的对齐训练,重点在于指令跟随和符合人类偏好。
全新架构设计:优化推理效率
借助神经架构搜索Puzzle框架,LN-Super和LN-Ultra优化了模型推理效率。
Puzzle能够在实际部署限制下,将大语言模型转化为更适配硬件运行的高效版本,如图3所示。
通过「逐块局部蒸馏」的方式,开发者利用Llama 3 Instruct构建了替代Transformer模块的库。
在这个过程中,每个模块都会被独立且并行地训练,逼近原始模块的功能,同时优化计算性能。
这样,每个替代模块都具有特定的「精度-效率」权衡特性:有些模块虽然更高效,但可能会带来一定的质量下降,从而形成一种在计算成本与模型准确性之间的明确取舍。
这些模块的变体包括:
- 注意力机制移除:某些模块完全省略了注意力机制,从而降低了计算量和KV缓存的内存消耗。
- 可变的FFN维度:前馈网络的中间维度被调整,能以不同粒度对模型进行压缩。
在构建好模块库后,Puzzle会从每一层中选择一个模块,组装出一个完整的模型。
这个选择过程由混合整数规划(MIP)求解器控制,它会根据一系列约束条件(如硬件兼容性、最大允许延迟、内存预算或期望的推理吞吐量)来找出最优配置。
Puzzle框架概览
垂直压缩与FFN融合
在LN-Ultra模型中,研究者引入了一项额外的压缩技术,称为FFN Fusion(前馈网络融合),用于减少模型的序列深度并提升推理延迟效率。
Puzzle在移除部分注意力层后,模型结构中出现的一种特性:模型中常会出现多个连续的FFN块。
FFN Fusion能识别出这些连续结构,并将其替换为更少但更宽、可并行执行的FFN层。
这种替换方式在不牺牲模型表达能力的前提下,减少了顺序计算的步骤,显著提升了计算资源的利用率——特别是在多GPU环境中,跨层通信开销不可忽视的情况下,效果尤为明显。
图4展示了在GPQA-Diamond准确率(%)与处理吞吐量(token/秒)之间的权衡。
值得注意的是,LN-Ultra始终在准确性和效率上优于DeepSeek-R1和Llama-3.1-405B,取得了准确性和效率的最佳平衡。
GPQA-Diamond模型的精确度与吞吐量对比
NAS后训练:知识蒸馏与持续预训练
在神经架构搜索(NAS)阶段之后,LN-Super和LN-Ultra都进行了额外的训练,以提升模块之间的兼容性,并恢复在模块替换过程中可能出现的质量损失。
- LN-Super使用Distillation Mix数据集,在知识蒸馏目标下训练了400亿个token。
- LN-Ultra首先使用相同的蒸馏数据集进行知识蒸馏训练,训练了650亿个token;随后又在Nemotron-H第四阶段预训练数据集上继续训练了880亿个token。
这一最终的预训练步骤,使LN-Ultra不仅追平了参考模型Llama 3.1-405B-Instruct的表现,还在关键基准测试中实现了超越。
这就,表明通过简短的蒸馏与预训练,可以在激进的架构优化和高模型性能之间实现兼容。
监督微调
想让Llama-Nemotron模型拥有超厉害的推理能力?
监督微调(Supervised Fine-Tuning,SFT)这一步简直就是「神助攻」。
前面的开发阶段,团队主要在研究怎么让模型架构更高效,怎么把海量知识塞进去。
而SFT就像给模型请了一位「私人教练」,专门针对特定任务的推理步骤,带着它从DeepSeek-R1这些「学霸」模型身上,偷师推理技巧。
不过要想让模型真正拥有扎实的推理功底,大规模、高质量的推理训练数据必不可少。
合成数据
研究者为监督微调精心整理了包含推理和非推理的数据样本。
对于推理样本,他们在系统指令中加入「detailed thinking on」(开启详细思考),而对于非推理样本,则使用「detailed thinking off」(关闭详细思考)。
这种设置,使模型能够在推理阶段根据提示内容切换推理行为。
为推理,精心准备了数学、代码等相关领域的合成数据。
为了训练模型遵循「推理开关」指令,研究者构建了成对的数据集,其中每个提示都对应一个带推理的回复和一个不带推理的回复。
这种配对方式,使模型能够根据系统指令学习调节其推理行为。
随后会依据标准答案或奖励模型对这些回复进行筛选。
微调流程
在指令微调数据上,所有模型的训练,均采用token级交叉熵损失。
在大多数训练设置中,推理数据和非推理数据会被混合在一起,形成训练批次,其中每个提示都会根据系统指令「detailed thinking on/off」的条件,与相应的响应配对。
延长训练至多轮周期能提升性能,对小模型尤为明显。
这次主要使用NeMo-Aligner来进行强化学习训练,支持GRPO以及异构模型的训练。
论文链接:https://arxiv.org/abs/2405.01481
生成阶段使用vLLM实现,训练阶段则使用Megatron-LM。
训练和推理阶段共用同一批GPU,在同一设备上完成。
整个训练过程中,他们共使用了72个节点,每个节点配备8张H100 GPU。
生成阶段采用FP8精度,训练阶段采用BF16精度,优化器状态使用FP32。
每个阶段维护一份独立的模型权重,并在每一步开始时进行同步。
强化学习:超越R1推理能力的关键
监督微调(SFT)可以让模型从强大的教师模型中提炼知识,从而获得出色的能力。
然而,知识蒸馏本质上为学生模型的性能设定了上限,特别是当学生模型的基础模型能力不超过教师模型时。
通过监督微调,LN-Ultra的性能可以接近DeepSeek-R1,但无法超越它。
为了使学生模型超越教师模型,大规模强化学习(RL)是一种可行的方法,因为它允许模型持续探索新的可能性并进行自我学习。
由于资源限制,研究者仅对LN-Ultra应用推理RL,结果得到超越教师模型的学生模型。
在整个推理强化学习训练过程中,在GPQA-Diamond数据集上,LN-Ultra的准确性
训练流程
对于LN-Ultra,研究者通过大规模强化学习(RL)增强它的科学推理能力,采用DeepSeek-R1同款的分组相对策略优化(GRPO)算法。
整个训练过程大约需要14万H100小时,持续训练模型直至其在推理任务上实现收敛。
图5显示了训练过程中GPQA-Diamond的准确率得分。
奖励机制设计包含两类:
- 准确性奖励:基于标准答案(数值/句子/段落),调用Llama-3.3-70B-Instruct模型判断预测结果匹配度
- 格式奖励:遵循DeepSeek-AI的方案,强制模型在「详细思考」模式下用<think>标签包裹推理过程,非该模式时禁止出现此类标签
研究团队还对数据进行预处理,包括数据过滤和课程训练(curriculum training)。
- 数据筛选:预先使用LN-Super对每个问题生成8条响应,剔除通过率≥75%的简单样本
- 课程训练:采用基于通过率的渐进式批次分配(图6验证其有效性)
- 动态分布:以高斯函数建模批次难度,初期侧重高通过率(简单)样本,后期转向低通过率(困难)样本
- 填充逻辑:优先按目标分布分配样本,剩余容量从最大剩余样本池补充
- 批内处理:同批次样本随机打乱以保持多样性
用于偏好优化的强化学习
在完成科学推理训练之后,研究者对LN-Super和LN-Ultra模型进行了一个简短的强化学习阶段,重点提升其指令跟随能力。
研究者还使用RLHF对模型的通用帮助能力和聊天表现进行优化,同时保留了模型在数学、科学等其他领域的能力。
如表4所示,LN-Super在Arena Hard测试中取得了88.3的高分,超越了专有模型如Claude 3.5 Sonnet和GPT-4o-2024-05-13,也优于体量更大的开源模型。
为了实现这一结果,他们采用了「在线RPO」(OnLine Reward-Policy Optimization)方法,最大化模型在HelpSteer2数据集上的预测奖励,奖励模型使用的是Llama-3.1-Nemotron-70B-Reward。
两轮在线RPO训练将Arena Hard得分从69.1提升到88.1。
对于LN-Ultra,他们使用类似流程,但采用了GRPO。
对于LN-Nano,他们进行了两轮离线RPO训练,使用基于策略生成的训练数据。
在第一轮中,结合推理类和非推理类数据,并配合适当的系统提示词,以优化模型的推理控制能力。第二轮则专注于提升指令跟随能力。
评估结果
研究者在两个基准类别上评估所有Llama-Nemotron模型的性能:推理任务和非推理任务。
推理类基准包括:AIME24和AIME25、GPQA-Diamond、LiveCodeBench以及MATH500。
非推理类基准包括:用于指令遵循评估的IFEval、用于函数调用工具使用评估的BFCL V2 Live以及用于评估对人类对话偏好对齐度的Arena-Hard。
表3显示,尽管模型体积较小,LN-Nano在所有推理类基准测试中都取得了出色的表现。
这表明,监督微调流程和精心策划的推理数据集,在将结构化推理能力迁移至小型模型方面是有效的。

表4将LN-Super与其参数规模相近的其他模型进行了对比,可见这个模型在推理任务和非推理任务中都表现出强劲的竞争力。
在「推理关闭」模式下,LN-Super的表现与其蒸馏来源模型Llama-3.3-70B相当;在「推理开启」模式下,则超越了其他竞品模型,例如DeepSeek-R1-Distilled-Llama-70B,在保持良好指令遵循能力的同时展现出强大的推理能力。
这些结果表明,LN-Super是一个兼具推理优化模型和非推理模型优点的通用模型,适用于日常助手型任务和结构化推理任务。

表5显示,LN-Ultra 在推理和非推理基准测试中,与所有现有的开源权重模型相比表现持平或更优。它在GPQA上达到了开源模型中的最先进水平,充分证明了英伟达研究者大规模强化学习训练方法的有效性。
与DeepSeek-R1需要使用8×H200的硬件配置不同,LN-Ultra专门优化为可在单个8×H100节点上高效运行,从而提供更高的推理吞吐量和部署效率。
从表5可见,LN-Ultra的SFT阶段已经在多个推理基准测试(包括GPQA和AIME)上接近或达到DeepSeek-R1的性能。

除了模型原本接受训练的推理和对话能力之外,他们还对模型在一个分布外任务。
具体来说,模型在JudgeBench数据集上进行了测试,要求区分高质量与低质量的回答。
如表6所示,新模型在该任务上表现优于当前顶尖的专有模型和开源模型。
其中,LN-Ultra成为表现最好的开源模型,明显超过了 DeepSeek-R1,仅次于专有模型 o3-mini(high)。
此外,LN-Super 的表现也超过了o1-mini,这说明新模型在各类任务中具备很强的泛化能力。

参考资料:
https://arxiv.org/abs/2505.00949
公开模型一切,优于DeepSeek-R1,英伟达开源Llama-Nemotron家族
在大模型飞速发展的今天,推理能力作为衡量模型智能的关键指标,更是各家 AI 企业竞相追逐的焦点。
但近年来,推理效率已成为模型部署和性能的关键限制因素。
基于此,英伟达推出了 Llama-Nemotron 系列模型(基于 Meta AI 的 Llama 模型构建)—— 一个面向高效推理的大模型开放家族,具备卓越的推理能力、推理效率,并采用对企业友好的开放许可方式。
该系列包括三个模型规模:Nano(8B)、Super(49B)与 Ultra(253B),另有独立变体 UltraLong(8B,支持超长上下文)。

- 论文标题:Llama-Nemotron: Efficient Reasoning Models
- arXiv 地址:https://arxiv.org/pdf/2505.00949
- 代码地址:https://github.com/NVIDIA/NeMo
- 数据集:https://huggingface.co/datasets/nvidia/Llama-Nemotron-Post-Training-Dataset
这一系列模型可不简单,不仅具备超强的推理能力,还为企业使用提供开放许可。模型权重和部分训练数据在 Hugging Face 上公开,遵循 NVIDIA Open Model License 和 Llama 社区许可,可商业使用。
Llama-Nemotron 系列模型是首批支持动态推理切换的开源模型,用户在推理时可在标准聊天模式和推理模式之间自由切换,极大地提升了交互的灵活性。
研究主要是利用推理类和非推理类这两类基准测试对 Llama-Nemotron 系列模型进行评估,结果发现 Llama-Nemotron 系列模型在不同规模下都展现出了良好的性能,尤其是 LN-Ultra 模型与 DeepSeek-R1 相比,极大地提高了推理吞吐量和部署效率。

Llama-Nemotron 通过多阶段后训练流程,强化推理和非推理任务表现。监督微调阶段专注于数学、代码、推理和工具调用任务;强化学习阶段则采用 REINFORCE 算法(RLOO)及支持在线奖励感知偏好优化的 RPO(Online Reward-aware Preference Optimization)方法,优化对话生成与指令跟随等技能。
Qwen 与 DeepSeek-R1 也在 Llama-Nemotron 的训练中扮演关键角色。Qwen(如 Qwen2.5-32B-Instruct)负责数学和科学数据的生成、分类及去污染,构建高质量训练集;DeepSeek-R1 作为核心教师模型,生成多步推理和代码解决方案,通过监督微调和强化学习将深度逻辑能力迁移到目标模型中。
想知道英伟达具体是如何构建 Llama-Nemotron 系列模型的吗?它背后有着怎样独特的训练方法?
接下来让我们深入探究一下其背后的奥秘。
构建面向推理优化的模型
LN-Super 和 LN-Ultra 模型通过 Puzzle 框架实现高效推理优化。Puzzle 是一个神经网络架构搜索(Neural Architecture Search, NAS)框架,能够在真实部署约束条件下,将大型语言模型转化为面向硬件高效的变体,如图 3 所示。

以 Llama 3 Instruct 模型为起点(LN-Super 基于 Llama 3.3-70B-Instruct,LN-Ultra 基于 Llama 3.1-405B-Instruct),Puzzle 通过逐模块局部蒸馏(block-wise local distillation)方法构建可替代的 Transformer 模块库。每个模块独立训练且可并行处理,旨在接近原始模块功能的同时提升计算性能。
该方法允许每个替代模块在精度与效率之间进行权衡,即模块库中某些变体具有更高的计算效率,但可能伴随一定的准确性下降,从而形成一种显式的精度–效率权衡(accuracy-efficiency tradeoff)。模块变体主要包括以下几种类型:
移除注意力机制(Attention removal):部分模块完全省略注意力机制,从而显著减少计算开销和 KV 缓存(Key-Value cache)内存占用。
可变 FFN 维度(Variable FFN dimensions):通过调整前馈网络(Feed-Forward Network, FFN)的中间维度,能够在不同粒度下实现模型压缩(如将隐藏层维度压缩至原始的 87%、75%、50%,甚至低至 10%)。
尽管 Puzzle 同样支持其他结构替换方式(如多组查询注意力机制(Grouped-Query Attention, GQA)中不同的键值头数、线性注意力替代方案、以及不执行操作的替换模块),但实际评估结果表明,在优化 LN-Super 和 LN-Ultra 两个模型的总体吞吐量与内存节省方面,最有效的技术仍是移除注意力机制与 FFN 压缩。
在模块库构建完成后,Puzzle 通过逐层选取模块的方式组装完整模型。模块选择过程由整数混合规划(Mixed-Integer Programming, MIP)求解器控制,该求解器会在给定的约束条件下(如硬件兼容性、最大推理延迟、总内存预算或指定推理吞吐量)确定效率最优的模块配置。
由于每一层支持多个具有不同精确度–效率权衡方案的模块变体,Puzzle 允许用户精确定位至任何位于精度 - 效率帕累托前沿(Pareto frontier)上的模型配置点。例如,Puzzle 可生成满足特定智能体系统(agentic systems)或部署流程所需约束(如内存不可超出上限或端到端响应时间严格受限)的模型。
FFN 融合实现纵向压缩(Vertical Compression with FFN Fusion): 针对 LN-Ultra 模型,研究者引入了一种额外的压缩技术 ——FFN 融合(FFN Fusion),该方法旨在降低模型的序列深度,并进一步缩短推理延迟。
该方法利用 Puzzle 移除部分注意力层后的结构特性:在这种结构下,模型中经常会出现连续的 FFN 模块序列。FFN Fusion 会识别出这类序列,并将其替换为更少但更宽的 FFN 层,这些宽层可并行执行,从而减少序列处理步骤的数量,同时保留模型的表达能力。
此外,这种方式显著提升了计算资源的利用率,特别是在多 GPU 环境中,可以有效降低跨层通信带来的开销。
部署约束与效率目标
LN-Super 专为在单块 NVIDIA H100 GPU 上高效运行而设计,采用张量并行系数为 1(Tensor Parallelism 1,TP1)的配置。通过 Puzzle 框架优化后,该模型在批量大小为 256、TP1 配置下,相较于 Llama 3.3-70B-Instruct 实现了 5 倍推理吞吐提升。即使在 Llama 3.3-70B-Instruct 使用其最佳配置(张量并行度为 4,TP4)的情况下,LN-Super 在 TP1 条件下仍保持 ≥2.17× 的吞吐优势。
LN-Super 设计满足约 30 万个缓存 Token(cached tokens)的运行约束(等于 batch size × sequence length),基于 FP8 精度在单张 H100 GPU 上测得。例如,batch size 为 16、序列长度为 18,750 的配置即可满足该缓存量要求。
LN-Ultra 的优化目标为整个 H100 节点(8 张 GPU)。在 Puzzle 结构搜索阶段,模型受到推理延迟需至少比 Llama 3.1-405B-Instruct 缩短 1.5 倍的约束。应用 FFN 融合(FFN Fusion)后,最终模型在延迟上实现了 1.71 倍提升。
LN-Ultra 同样受缓存 Token 限制:在 FP8 精度下支持最多 300 万个 Token,在 BF16 精度下支持 60 万个 Token,均以整个 H100 节点为计算基准。
图 4 展示了两种设置下 GPQA-Diamond 准确率(%)与处理吞吐量(Token/s)的权衡曲线。值得注意的是,LN-Ultra 在准确率和效率方面均优于 DeepSeek-R1 和 Llama 3.1-405B,表明在精度 - 吞吐率帕累托曲线(accuracy-throughput Pareto curve)上,LN-Ultra 是更具优势的选择。

NAS 后训练阶段:知识蒸馏与持续预训练
在神经架构搜索(NAS)阶段结束后,为提升模块间兼容性并弥补模块替换带来的质量损失,LN-Super 和 LN-Ultra 均进行了进一步训练。
- LN-Super 使用 Bercovich 等人提出的 Distillation Mix 数据集,以知识蒸馏目标函数训练了 400 亿个 Token;
- LN-Ultra 首先使用相同的蒸馏数据集进行了 650 亿 Token 的蒸馏训练,随后在 Nemotron-H 第四阶段预训练数据集上进行了额外 880 亿 Token 的持续预训练。
通过这一最终的预训练阶段,LN-Ultra 不仅实现了与基准模型 Llama 3.1-405B-Instruct 相当的性能,还在多个关键基准测试上取得超越,验证了即使进行激进的架构优化,也可通过短周期的蒸馏与预训练恢复并提升模型性能(见表 1)。

推理能力强化学习
为了使模型具备在不同任务场景下灵活切换推理深度与回答风格的能力,研究者设计了「detailed thinking on/off」指令机制,通过在合成数据中显式标记是否需要展开详细推理过程,引导模型在训练中学习何时进行逐步思考、展示推理链条,何时直接给出简明答案。
具体而言,指令为「on」时,模型输出完整的中间推理过程并展示解题思路;指令为「off」时,模型仅呈现最终结果。这一机制提升了模型对用户指令的响应可控性,同时增强了推理行为在不同场景中的适应性,使模型能根据实际需求调整输出风格。
在此基础上,模型通过监督微调(SFT)从教师模型中学习多步推理路径,并有效融合推理与通用任务风格,构建了兼具推理精度与使用灵活性的响应系统。
LN-Ultra 在推理类与非推理类基准测试上均达到或超越了现有开源权重模型的水平(如表 5 所示),证明通过从强大教师模型中蒸馏知识,模型可通过监督微调获得较强能力。

然而,蒸馏在本质上为学生模型设定了性能上限,特别是当学生模型本身能力不超过教师模型时。
例如,通过监督微调,LN-Ultra 可逼近 DeepSeek-R1 的性能,但难以超越。为使学生模型有机会超过教师模型,大规模强化学习(RL)提供了可行路径,因其能持续探索新策略并促进模型自学习。
研究者初步实验表明,在小型模型上应用强化学习的性能通常不及直接蒸馏。考虑到资源限制,研究者仅对 LN-Ultra 应用推理方向的强化学习,从而获得一个超越其教师模型的最终版本。
训练流程
针对 LN-Ultra,研究者通过大规模强化学习提升其科学推理能力,采用 GRPO 算法。训练中设置每个 rollout 的提示词长度为 72,并为每个提示采样 16 个响应,采样参数为 temperature = 1,top_p = 1。
全局 batch size 设置为 576,每个 rollout 更新两次梯度,训练持续至模型在推理任务上收敛。图 5 展示了模型在 GPQA-Diamond 上的准确率随训练进展的变化。借助优化后的训练基础设施,整个训练过程共消耗约 14 万张 H100 GPU 小时。

本阶段训练使用以下两类奖励信号:
准确率奖励(Accuracy rewards):每个训练样本提供标准答案(数字、句子或段落),研究者使用 Llama-3.3-70B-Instruct 模型判定策略模型响应是否与标准答案一致。
格式奖励(Format rewards):遵循 DeepSeek-AI 等人做法,在模型开启详细思考(detailed thinking on)模式时,需将推理过程置于 "" 标签之中;而在 detailed thinking off 模式下,确保不包含思考标签。格式奖励确保模型按规定格式输出推理过程。
为增加训练挑战性,研究者对数据进行预处理:由 LN-Super 为每道题生成 8 个独立回答,计算通过率(pass rate),并过滤通过率 ≥0.75 的样本,提升总体训练数据难度。
除数据筛选外,研究者发现课程化学习(curriculum learning)策略能显著帮助模型在复杂推理问题上的收敛和泛化。研究者采用渐进式批处理策略(progressive batching),使用预计算通过率作为样本难度指标,在固定 batch size 下,动态计算每个批次的目标难度分布。
该分布以高斯函数建模,从早期批次集中在高通过率(简单样本),逐步过渡至后期批次的低通过率(高难度样本)。每个 batch 中,样本按目标分布随机分配,并根据不同通过率池中剩余样本量进行容量填充。
这种策略确保样本难度在 batch 层面逐步递进,同时 batch 内部保持随机性。图 6 展示了该课程式学习策略在降低方差、稳定训练过程及提升准确率方面的有效性。

FP8 精度生成阶段
研究者识别出生成阶段是推理过程中的主要限制因素。为提升该阶段性能,研究者开发了支持 vLLM 框架下在线 FP8 精度生成模式的路径,此模式可在 FP8 精度下执行全部矩阵乘(GEMM)操作,并结合每 token 激活缩放因子及每张量权重缩放因子。
为配合训练时输出的 BF16 权重,研究者开发自定义 vLLM 权重加载器,可在运行时将 BF16 权重转换为 FP8 格式及其缩放参数。由于 vLLM 当前不支持 FP8 模式直接初始化模型,研究者实现了元权重张量初始化(meta-weight tensor initialization),避免载入完整 BF16 推理引擎导致 GPU 显存溢出。
在上述优化下,FP8 模式下单个 GPU 每个 prompt 的生成吞吐量最高可达 32 token/s,相比 BF16 提升 1.8 倍。其中,FP8 本身带来 1.4 倍加速,另外 0.4 倍收益源自内存占用减少,使研究者能够启用 vLLM 的 cudagraph 特性,进一步提升系统性能。
用于偏好优化的强化学习
指令跟随能力优化
在完成科学推理任务的强化学习训练后,研究者对 LN-Super 和 LN-Ultra 开展短周期强化学习训练,优化其指令跟随能力。参照 Zhou 等人提出的验证方案,研究者生成包含 1 至 10 条详细指令的合成提示词用于训练。
在该阶段,研究者采用 RLOO 算法进行不超过 120 步的强化学习训练,使用自定义指令跟随验证器作为奖励函数,训练批大小为 128 条提示。结果表明,此类训练不仅提升了模型在传统指令跟随评测中的表现,也对推理类基准任务产生积极影响。
基于人类反馈的强化学习(RLHF)
研究者使用基于人类反馈的强化学习(RLHF)增强模型的通用协助能力(helpfulness)与多轮聊天能力,同时确保其在其他任务上的表现不被削弱。
如表 4 所示,LN-Super(49B 参数)在 Arena Hard 评测中取得 88.3 的高分,超越了数个专有模型(如 Claude 3.5 Sonnet 和 GPT-4o-2024-05-13)以及规模更大的开源模型如 Llama-3.1-405B-Instruct 和 Mistral-large-2407。

为实现这一目标,研究者采用迭代式在线 RPO(online Reward-Parameterized Optimization)训练方式,在 HelpSteer2 数据集的提示语上最大化 Llama-3.1-Nemotron-70B-Reward 所预测的偏好奖励。
具体训练参数为:学习率 α = 4e-7,KL 散度惩罚项 β = 1e-5,奖励缩放因子 η = 3.0,batch size 为 64,训练 500 步。两轮在线 RPO 后,Arena Hard 分数由 69.1 提升至 88.1。
值得注意的是,该过程在几乎所有基准任务中的表现均有提升,唯独在 IFEval 上略有下降。由于该数据集与奖励模型未专门针对数学、代码、科学或函数调用场景设计,研究者推测 RLHF 有助于模型更好地调动已有知识和技能。
针对 LN-Ultra,研究者延续上述训练流程,但采用 GRPO 算法。对每条提示词,生成 8 个样本响应,并以学习率 3e-7、batch size 为 288、KL 惩罚 β = 1e-3 的配置进行 30 步训练。
对于小模型 LN-Nano,研究者进行了两轮离线 RPO,使用策略内数据(on-policy data)训练。第一轮混合使用包含推理和非推理内容的数据,并配合相应系统提示,目的是提升模型的推理控制能力;第二轮聚焦于提升指令跟随表现,训练数据为模型生成的策略内响应。每轮训练最多进行 400 步,学习率 α = 7e-7,KL 惩罚 β = 3e-2,batch size 为 512。
#UFO²
微软正式开源UFO²,Windows桌面迈入「AgentOS 时代」
本论文第一作者为微软 DKI 团队的 Chaoyun Zhang,其为 Windows 平台首个智能体系统 ——UFO 的核心开发者,该项目已在 GitHub 上开源并获得约 7,000 Stars,在社区中引发广泛关注。同时,他也是一篇超过 90 页的 GUI Agent 综述文章的主要撰写者,系统梳理了该领域的关键进展与技术框架。其余项目的主要贡献者亦均来自微软 DKI 团队,具备深厚的研究与工程背景。
- 论文标题:UFO²: The Desktop AgentOS
- 论文地址:https://arxiv.org/abs/2504.14603
- 开源代码:https://github.com/microsoft/UFO/
- 项目文档:https://microsoft.github.io/UFO/
近年来,图形用户界面(GUI)自动化技术正在逐步改变人机交互和办公自动化的生态。然而,以 Robotic Process Automation(RPA)为代表的传统自动化工具通常依赖固定脚本进行操作,存在界面变化敏感、维护成本高昂、用户体验欠佳等明显问题。
同时,近年来兴起的基于大型语言模型(LLM)的计算机智能体(Computer-Using Agents,CUA)虽然展现出灵活的自动化潜力,但多数方案仍停留在概念验证或原型阶段,缺乏与操作系统深度集成的能力,制约了其在实际工作环境中的规模化应用。
针对这些行业痛点,作为前代纯 GUI 桌面智能体 UFO 的全面升级版,微软研究团队近日正式开源了业内首个深度集成 Windows 操作系统的桌面智能体平台 ——UFO² AgentOS。该平台不仅继承了 UFO 的强大 GUI 操作能力,还在系统层面进行了深度优化,显著提升了智能体在 Windows 环境下的操作效率与稳定性。

图 - 1:传统 CUAs 和 AgentOS UFO² 对比
UFO²:深度 OS 集成的桌面智能体
UFO² 不是传统意义上的桌面自动化工具,而是一种深度融入操作系统的智能体框架,首次以「AgentOS」理念设计,彻底解决了传统智能体界面交互脆弱、执行中断用户体验等核心问题。
UFO² 引入了多智能体架构:中央的 HostAgent 负责自然语言任务解析与子任务分解,而专属的 AppAgent 则为每个应用程序提供定制化的 API 接入、界面感知与交互能力。两者协同工作,实现了任务的精准分解与灵活执行,并支持跨应用任务,显著提升了系统的可扩展性与执行效率。
具体来说,UFO² 在以下几个核心维度实现了突破,这些维度都充分利用了与 Windows 系统的深度集成:
统一 GUI–API 混合执行
传统 API 执行方式精准高效,但需要针对特定应用实现对应接口,覆盖范围有限;而 GUI 执行方式更加通用灵活,但步骤更长,容易受到界面变动的影响。UFO² 创新地将 API 与 GUI 两种执行范式合二为一,通过统一的 Puppeteer 接口,实现两种执行模式的动态选择。
在实际任务执行中,UFO² 可以智能地根据操作环境与任务特性,自动判断是否优先使用 API 执行来提高速度与精准度,或者在 API 不足以完成任务时,灵活转向 GUI 操作,从而实现效率与通用性的最佳平衡,显著提升任务稳定性和鲁棒性。

图 - 2:GUI-API 操作的混合统一接口
混合控件感知
UFO² 实现了与 Windows 系统的深度融合,通过结合 Windows 原生 UI Automation(UIA)接口与先进视觉识别模型 OmniParser-v2,实现了对界面元素的混合检测与精准感知。这种方式不仅克服了传统视觉识别准确性不足的问题,同时也解决了纯粹依赖系统 API 检测范围有限的瓶颈。
实际应用场景中,尤其是在界面复杂、控件自定义或标准化程度低的场景下,UFO² 的混合感知能力有效提高了控件识别的准确性与覆盖率,从而保障了任务执行的稳定性与鲁棒性。

图 - 3:基于 UIA API 和 OmniParser-v2 的融合控件检测
持续增强的动态知识集成
UFO² 采用检索增强生成(RAG)技术,构建了持续的知识库,动态整合外部应用文档和历史执行日志,使智能体实时获得最新的应用使用方法和最佳实践。这一技术保障了智能体在新功能上线或应用版本升级后能迅速适应变化,维持高效执行。
通过这种方式,UFO² 可实现对复杂任务的精准理解与执行,减少因知识更新不及时导致的操作失败。此外,智能体还能利用历史成功执行的经验,提高任务完成的准确性与效率,真正实现「越用越强」。

图 - 4:动态检索外部应用文档和历史执行日志
高效的推测式多步执行
为有效降低大语言模型(LLM)调用次数,UFO² 创新性地采用了推测式多步预测机制。智能体一次 LLM 调用即可预测多个后续步骤,并通过实时的界面状态校验来逐步执行。这种机制大幅度降低了智能体执行任务时的延迟和计算成本。
实验结果显示,推测式多步执行技术可减少高达 51.5% 的 LLM 调用次数,大幅提升任务执行速度与系统响应能力,使智能体能够更顺畅地完成复杂的任务序列,提升整体效率。

图 - 5:推测式多步执行和验证
无干扰的 PiP 虚拟桌面执行环境
UFO² 引入了创新的画中画(PiP)虚拟桌面技术,通过深度利用 Windows 原生的远程桌面服务,创建了一个轻量级、独立且安全的虚拟桌面环境。所有智能体执行的任务均在此环境中进行,避免了与用户主桌面的任何交互干扰。
用户可以在智能体执行复杂任务的同时,继续进行其他重要的工作,而无需担心智能体任务影响自己的桌面操作。这一设计极大提高了智能自动化的用户接受度与实际使用体验。

图 - 6:UFO² 画中画(PiP)的虚拟执行环境
实践检验:20 + 主流应用测试全方位领先
在严格的基准测试中,UFO² 在超过 20 款主流 Windows 应用(如 Excel、Outlook、Edge 等)中进行了充分验证:
- 仅采用 GPT-4o, 任务成功率相比业内领先的 OpenAI Operator 提升超过 10%。
- 特别值得强调的是,UFO² 的推测式多步执行技术将大模型调用(LLM call)的频率降低最多达 51.5%,极大提升了任务响应速度和系统效率。

图 - 7:实验结果对比
全面开源,共同推动桌面智能新时代
微软团队已经将 UFO² 的全部代码和详细文档向社区开源,欢迎开发者们加入共建与创新。
- 💻 开源项目地址:https://github.com/microsoft/UFO (GitHub UFO² 项目)
- 📚 官方文档:https://microsoft.github.io/UFO/(微软 UFO² 官方文档)
UFO² 的发布不仅标志着桌面智能体真正迈入了系统级的「AgentOS 时代」,也为未来智能办公、智能人机交互的发展树立了重要里程碑。通过 UFO²,微软期待与全球开发者共同打造更加智能、稳定、高效的桌面智能生态。
欢迎各界人士关注、使用并反馈,共同推动桌面自动化和智能交互的下一次技术革命。
#OpenAI放弃营利性转型
奥特曼:非营利组织继续掌控,AGI造福全人类使命不变
OpenAI 终于「妥协」了。
最近,OpenAI 向营利性公司的倾斜遭到了很多人的诟病,尤其是马斯克。他曾于 2024 年 2 月在加州法院起诉 OpenAI 及 CEO 山姆・奥特曼,指控其背离了公司成立时造福人类的非营利使命,转而追求利润最大化。同时,马斯克特别提到了 OpenAI 与微软的密切合作,谴责其成为微软事实上的闭源子公司,违背了最初的开源承诺。
在不断受到马斯克、前员工、AI 伦理学者和监管机构的多重压力下,OpenAI 于今日正式宣布放弃将公司完全转为营利性机构的计划。
简单来讲,OpenAI 澄清了关于其自身结构的四个事实,分别是:
- OpenAI 将继续由现有非营利组织控制;
- OpenAI 现有的营利性机构将成为一家公益公司(Public Benefit Corporation,PBC);
- 非营利组织将控制并成为 PBC 的重要所有者;
- 非营利组织和 PBC 将继续秉持相同的使命。

OpenAI 董事会主席 Bret Taylor 的完整公告内容如下:
一是,OpenAI 最初是一家非营利组织,目前由该非营利组织监督和控制。未来,OpenAI 将继续由该非营利组织监督和控制。
二是,自 2019 年起,OpenAI 营利性有限责任公司(LLC)一直隶属于非营利组织,并将转型为公益公司(PBC)—— 一种以目标为导向的公司结构,必须兼顾股东利益和使命。
三是,非营利组织将控制 PBC,并成为 PBC 的大股东,这将为非营利组织提供更充足的资源来支持多项公益事业。
四是,OpenAI 的使命保持不变,PB 也将继续秉持同样的使命。
Bret Taylor 表示,在听取民间领袖的意见并与特拉华州和加州总检察长办公室进行建设性对话后,我们决定由非营利组织保留 OpenAI 的控制权。OpenAI 感谢这两个办公室,并期待继续进行重要的对话,以确保 OpenAI 能够继续有效履行其使命,即确保通用人工智能造福全人类。
与此同时,山姆・奥特曼也发表了一封致员工信:
OpenAI 并非一家普通的公司,也永远不会是。
我们的使命是确保通用人工智能(AGI)造福全人类。
OpenAI 成立之初,我们对如何实现使命并没有清晰的规划。我们最初只是围坐在餐桌旁,面面相觑,思考着应该开展哪些研究。那时候,我们既没有考虑产品,也没有商业模式。我们无法想象人工智能应用于医疗咨询、学习、生产力等领域的直接效益,也无法想象训练模型和服务用户需要数千亿美元的计算资源。
我们当时并不清楚 AGI 将如何构建或使用。许多人能够想象到一个可以告诉科学家如何行动的神谕(oracle)式 AGI,尽管这可能极其危险,但 OpenAI 早期的很多人认为,这样的系统交由少数几位值得信赖的人掌控是可以接受的。
我们现在看到了一种让 AGI 成为人类历史上最强大工具的方式,它可以直接赋能每个人。如果我们能够做到这一点,我们相信人们将为彼此创造非凡的成果,并持续推动社会和生活质量的进步。当然,它并非全都用于造福人类,但我们相信福祉将远超其祸害。
我们致力于走这条民主人工智能之路。我们希望将不可思议的工具交到每个人手中。我们惊叹于人们用我们的工具所创造的成果,以及人们如此渴望使用这些工具的程度。我们希望开源性能卓越的模型。我们希望赋予用户在广泛范围内使用我们工具的极大自由,即使我们并不总是拥有相同的道德框架,我们也希望让用户自主决定 ChatGPT 的行为。
我们相信这是最佳的前进之路 —— 通用人工智能应该使全人类互惠互利。我们理解有些人持有不同的观点。
我们希望为世界构建一个大脑,让人们可以非常轻松地用它来做任何他们想做的事情(受到很少的限制,例如自由不应该侵犯别人的自由)。
科学家、程序员等千行百业的人正在使用 ChatGPT 来提高自己的工作效率。人们正在使用 ChatGPT 来解决他们面临的严峻医疗挑战,并学习到比以往任何时候都多的知识。人们正在使用 ChatGPT 获取有关如何处理棘手情况的建议。我们非常自豪能够提供这项服务,它正在为如此多的人带来如此多的益处。这是我们能够想象到的最直接地履行我们使命的方式之一。
但是,人们希望更多地使用它。我们目前提供的人工智能远不能满足世界的需求,我们不得不限制系统的使用量,并降低其运行速度。随着系统功能越来越强大,人们会希望更多地使用它,去做更多精彩的事情。
近十年前,当我们成立研究实验室时,我们并没有想到世界会变成这样。但现在我们看到了这样的景象,我们感到非常激动。
现在是时候改进我们的结构了。我们想要实现以下三点:
一,我们希望能够以这样一种方式运营和获取资源,让我们的服务能够广泛惠及全人类。目前这需要数千亿美元,最终可能需要数万亿美元。我们相信,这是我们履行使命的最佳方式,也是让人们利用这些新工具为彼此创造巨大利益的最佳方式。
二,我们希望自身的非营利组织成为历史上规模最大、效率最高的非营利组织,专注于利用人工智能为人类带来最高效益的成果。
三,我们希望提供有益的 AGI。这包括《安全与对齐》框架的形成,以及已推出的系统、进行的对齐研究、红队测试和通过模型规范等创新实现透明的模型行为。随着人工智能的加速发展,我们对安全的承诺也日益坚定。我们希望确保民主人工智能进一步发展。
因此,在听取民间领袖的意见并与加州和特拉华州总检察长办公室进行讨论后,我们决定由非营利组织继续掌控。我们期待与他们、微软以及我们新任命的非营利组织委员们继续沟通,推进该计划的细节。
OpenAI 最初是一家非营利组织,如今是一家监督和控制营利性机构的非营利组织,未来也将继续是一家监督和控制营利性机构的非营利组织。这一点不会改变。非营利组织旗下的营利性有限责任公司(LLC)将转型为秉持相同使命的公益公司。
这种公益公司已成为其他 AGI 实验室(如 Anthropic 和 X.ai)以及许多目标驱动型公司(如 Patagonia)的标准营利性机构。我们认为这对我们来说也同样合理。
我们原先采用了一种复杂的、设有利润上限的结构 —— 当时这很合理,因为我们认为未来可能只会有一家主导的 AGI 公司。但如今,AGI 领域已经涌现出多家优秀企业,这种结构已不再适用。因此,我们决定转向一种更常规的结构,让所有人都持有股份。这并不是出售公司,而是对公司结构的简化调整。
非营利组织仍将控制 PBC(公益公司),并将成为其主要股东之一,持股比例由独立财务顾问评估支持。这样一来,非营利组织将获得充足资源,用于开展各类项目,确保 AI 能够造福不同的群体,与我们的使命相符。
随着 PBC 的发展壮大,非营利组织的资源也会同步增长,从而能够开展更多工作。我们也非常期待不久后来自非营利委员会的建议,帮助我们进一步确保 AI 惠及所有人,而不仅仅是少数人。这些建议将聚焦于如何通过非营利项目推动更加民主的 AI 未来,并在医疗、教育、公共服务和科学研究等领域产生真正的影响。
我们相信,这样的安排将使我们能够继续在「安全可控」的前提下快速推进技术发展,并让更多人能使用先进的 AI。创造 AGI 是我们为人类进步铺下的一块砖,我们也期待看到你们将铺上的下一块。
OpenAI 原文地址:https://openai.com/index/evolving-our-structure/
#Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
注意力机制中的极大值:破解大语言模型上下文理解的关键
大型语言模型(LLMs)在上下文知识理解方面取得了令人瞩目的成功。
近日,一项来自 ICML 2025 的新研究《Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding》揭示了大型语言模型中一个重要现象:在注意力机制的查询 (Q) 和键 (K) 表示中存在非常集中的极大值,而在值 (V) 表示中却没有这种模式。这一现象在使用旋转位置编码 (RoPE) 的现代 Transformer 模型中普遍存在,对我们理解 LLM 内部工作机制具有重要意义。
本研究由罗格斯大学张永锋教授的团队完成,一作为金明宇,罗格斯大学博士生,在 ACL、ICML、AAAI、NAACL、COLM、ICLR、EMNLP、COLING 等顶级会议上发表过论文。
- 论文标题:Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
- arXiv 链接:https://arxiv.org/pdf/2502.01563
- 代码链接:https://github.com/MingyuJ666/Rope_with_LLM
研究亮点
极大值如何影响模型性能
当我们谈论大型语言模型的理解能力时,通常将其知识分为两类:参数知识(存储在模型权重中的事实和信息)和上下文知识(从当前输入文本中获取的信息)。本研究通过一系列精心设计的实验,揭示了自注意力模块中极大值的存在与上下文知识理解之间的关键联系。
四大核心发现
1. 极大值在 Q 和 K 中高度集中分布
研究发现,这些极大值在每个注意力头的特定区域高度集中。这一现象非常反常识,因为 LLM 内部每个注意力头的运算理论上应该是独立的,但这些极大值的分布却显示出惊人的一致性。研究团队通过可视化方法清晰地展示了这一分布特征,横跨多个层和头,这种规律性模式与传统认知形成鲜明对比。

更引人注目的是,这一极大值现象仅存在于使用 RoPE(旋转位置编码)的模型中,如 LLaMA、Qwen 和 Gemma 等主流模型。而在未使用 RoPE 的模型(如 GPT-2 和 OPT)中不存在这种模式。这一发现将极大值现象直接与位置编码机制建立了联系。
2. Q 和 K 中的极大值对理解上下文知识至关重要

通过设计「破坏性实验」,研究团队将极大值重置为平均值,观察模型性能变化。结果表明,这些极大值主要影响模型处理当前上下文窗口中的信息的能力,而非影响从参数中提取的知识。在需要上下文理解的任务上,破坏极大值会导致性能的灾难性下降。
例如,在「大海捞针」类型的任务中,模型需要从大量文本中检索特定信息。当极大值被破坏时,模型在此类任务上的表现几乎完全崩溃。这直接说明了极大值对上下文理解的关键作用。
相比之下,对于只需要参数知识的任务(如「中国首都是哪里」),破坏极大值对性能影响有限。这种对比鲜明的结果表明,极大值特别与上下文信息处理相关,而非参数知识检索。
3. 特定量化技术能更好地保存上下文知识理解能力

随着大型语言模型的普及,量化技术成为降低计算和存储需求的关键手段。然而,不同的量化方法对模型性能的影响各异。研究发现,专门处理极大值的量化方法(如 AWQ 和 SmoothQuant)能有效维持模型的上下文理解能力,而未特别处理极大值的方法则会导致性能明显下降(GMS8K 和 AQUA 数据集)。
这一发现为量化技术的设计和选择提供了重要指导,特别是对保留模型的上下文理解能力至关重要的应用场景。设计新的量化方法时应重点考虑保护 Q 和 K 中的大值,对于优先保持上下文理解能力的应用场景,AWQ 和 SmoothQuant 等方法更为合适。
4. 极大值集中现象由 RoPE 引起,并在早期层就已出现
研究通过深入分析发现,RoPE 位置编码使 Q 和 K 中的低频区域受位置信息影响较小,从而导致极大值集中现象。这种现象从模型的最初层就开始显现,并随着层数增加而变得更加明显。
由于 RoPE 只作用于 QK,而不作用于 V,这也解释了为什么只有 QK 存在极大值集中现象。这一发现不仅解释了极大值的来源,也揭示了 RoPE 在大型语言模型中的工作机制。并且我们检查了有 rope 的模型和没有 rope 的模型,结果如图所示,llama,qwen 都有集中的极大值;相反 gpt-2,jamba,opt 就没有。

实验结果
极大值对不同知识任务的差异化影响
研究团队设计了一系列实验,系统评估极大值对不同类型知识任务的影响。结果显示出明显的差异化效应:
A. 参数知识检索任务的韧性
当大值被破坏时:
- 城市类任务仍然保持 76%-88% 的准确率,仅下降 15-20%
- 体育、艺术和技术类别任务保持在 65%-75% 的表现
- 名人类别表现尤其稳定,各模型均保持 70% 以上的准确率
这些结果表明,参数知识检索主要依赖于模型权重中存储的知识,受极大值破坏的影响相对较小。
B. 上下文知识理解任务的灾难性下降
相比之下,依赖上下文理解的任务在极大值被破坏后表现灾难性下降:
1. 数学推理任务出现严重退化
- GSM8K: 从 81.30% 降至 15.10%
- Llama3-8B: 从 76.90% 降至 4.00%
- Qwen2.5-7B: 从 86.60% 降至 16.10%
2. 密钥检索任务 (Passkey Retrieval) 准确率从 100% 直接崩溃至接近 0%
3. IMDB 情感分析从 94% 以上下降至个位数
这些对比鲜明的结果强有力地证明了极大值在上下文知识理解中的关键作用。
C. 非大值破坏的对照实验
为验证研究发现的可靠性,研究团队还设计了对照实验:当仅破坏非极大值部分时,所有任务的表现保持稳定,变化通常小于 ±1%。这进一步确认了极大值在上下文知识理解中的特殊重要性。
研究意义与影响
这项研究首次揭示了大型语言模型内部自注意力机制中极大值的存在及其功能,为理解模型如何处理上下文信息提供了新视角。研究结果对 LLM 的设计、优化和量化都具有重要启示:
- 模型设计方面:突显了位置编码机制(尤其是 RoPE)对模型理解上下文能力的影响,为未来模型架构设计提供了新思路。
- 模型优化方面:识别出极大值是上下文理解的关键组件,为针对性地提升模型上下文理解能力提供了可能路径。
- 模型量化方面:强调了保护极大值在模型压缩过程中的重要性,为开发更高效的量化方法提供了方向。
未来方向
该研究打开了多个值得进一步探索的方向:
- 探索是否可以通过特殊设计增强或调整极大值分布,从而提升模型的上下文理解能力。
- 研究极大值现象在不同架构、不同规模模型中的普遍性和特异性。
- 设计更有针对性的量化方法,专门保护与上下文理解相关的极大值。
- 探索极大值与模型其他特性(如对抗稳健性、推理能力等)之间的潜在联系。
这项研究不仅加深了我们对大型语言模型内部工作机制的理解,也为未来更高效、更强大的模型开发铺平了道路。通过揭示极大值的关键作用,研究者们为我们提供了解锁大语言模型上下文理解能力的一把新钥匙。
#GPT-4o图像生成的「核燃料」找到了
万字长文拆解潜在变量,网友:原来AI在另一个维度作画
上个月, GPT-4o 的图像生成功能爆火,掀起了以吉卜力风为代表的广泛讨论,生成式 AI 的热潮再次席卷网络。
而在这股浪潮背后,潜在空间(Latent Space)作为生成模型的核心驱动力,点燃了图像与视频创作的无限想象。
知名研究者 Andrej Karpathy 最近转发了一篇来自 Google DeepMind 研究科学家 Sander Dielman 的博客文章,探讨了生成模型(如图像、音频和视频生成模型)如何通过利用潜在空间来提高生成效率和质量。

博客链接:https://sander.ai/2025/04/15/latents.html
Sander Dielman 自 2015 年加入 DeepMind 以来,参与了包括 WaveNet、AlphaGo、Imagen 3 和 Veo 在内的多个项目,涵盖深度学习、生成模型及表征学习(Representation Learning)。
在这篇文章中,他将潜在变量比喻为「数据的精髓」—— 通过压缩复杂信息实现图像、语音等生成。他还深入对比变分自编码器(VAEs)、生成对抗网络(GANs)和扩散模型,展示了潜在变量如何支持这些模型生成逼真内容。
例如,Dielman 参与开发的 WaveNet 就利用潜在变量成功实现了高质量语音合成,并在谷歌多个产品中得到广泛应用。他还以 VQ-VAE 为例,说明离散潜在空间如何提升图像生成效率。
这篇文章兼具理论深度与直观洞察,适合对生成模型感兴趣的读者深入研究。
配方

在潜在空间中训练生成模型通常分为两个阶段:
1. 用输入信号训练自编码器。自编码器是一个神经网络,包含两个子网络:编码器和解码器。编码器将输入信号映射到相应的潜在表征(编码),解码器则将潜在表征映射回输入域(解码)。
2. 在潜在表征上训练生成模型。这一步骤涉及使用第一阶段的编码器来提取训练数据的潜在表征,然后直接在这些潜在表征上训练生成模型。当前主流的生成模型通常是自回归模型或扩散模型。
一旦第一阶段训练好了自编码器,在第二阶段其参数将不再改变:学习过程第二阶段的梯度不会反向传播到编码器中。换句话说,在第二阶段,编码器的参数会被冻结。
请注意,在训练的第二阶段,自编码器的解码器部分不发挥作用,但在从生成模型采样时需要用到它,因为这将生成潜在空间中的输出。解码器使我们能够将生成的潜在向量映射回原始输入空间。
下面是说明这种两阶段训练方法的示意图。在相应阶段学习参数的网络标有 「∇」 符号,因为这几乎总是使用基于梯度的学习方法。参数被冻结的网络标有雪花符号。

潜在生成模型的训练方法:两阶段训练。
在两个训练阶段中涉及几种不同的损失函数,这在图中以红色标出:
- 为确保编码器和解码器能够高保真地将输入表征转换为潜在向量再转换回来,多个损失函数用于约束重建(解码器输出)与输入的关系。这些通常包括简单的回归损失、感知损失和对抗损失。
- 为了限制潜在向量的容量,在训练期间通常会直接对它们应用额外的损失函数,尽管并非总是如此。我们将此称为瓶颈损失,因为潜在表征在自编码器网络中形成了一个瓶颈。
- 在第二阶段,生成模型使用其自身的损失函数进行训练,这与第一阶段使用的损失函数分开。这通常是负对数似然损失(用于自回归模型)或扩散损失。
深入观察基于重建的损失函数,我们有以下几种:
- 回归损失:有时是在输入空间(例如像素空间)中测量的平均绝对误差(MAE),但更常见的是均方误差(MSE)。
- 感知损失:形式多样,但通常利用另一个冻结的预训练神经网络来提取感知特征。该损失函数鼓励重建和输入之间的这些特征相匹配,从而更好地保留回归损失大多忽视的高频内容。对于图像处理,LPIPS 是一种流行的选择。
- 对抗损失:使用与自编码器协同训练的判别网络,类似于生成对抗网络(GAN)的方法。判别网络负责区分真实输入信号和重建信号,而自编码器则努力欺骗判别网络使其出错。目的是提高输出的真实性,即使这意味着进一步偏离输入信号。在训练开始时,通常会暂时禁用对抗损失,以避免训练过程中的不稳定。
以下是一个更详细的示意图,展示了第一阶段的训练过程,并明确显示了在此过程中通常发挥作用的其他网络。

这是第一训练阶段的更详细版本的图,展示了所有参与的网络。
不言而喻,这个通用方法在音频和视频等应用中常常会有各种变体,但我试图总结出在大多数现代实际应用中常见的主要元素。
我们是如何走到这一步的

如今,自回归和扩散模型这两种主要的生成模型范式,最初都是应用于「原始」数字感知信号的,即像素(pixels)与波形(waveforms)。例如,PixelRNN 和 PixelCNN 是逐像素生成图像的,而 WaveNet 和 SampleRNN 则是逐样本生成音频波形的。在扩散模型方面,最初引入和建立这种建模范式的作品都是通过像素来生成图像的,早期的研究如 WaveGrad 和 DiffWave 则是通过生成波形来产生声音的。
然而,人们很快意识到这种策略在扩展性方面存在很大挑战。其主要原因可以概括为:感知信号大多由不可察觉的噪声组成。换句话说,在给定信号的总信息量中,只有一小部分真正影响我们的感知。因此,确保我们的生成模型能够高效利用其容量,并专注于建模这一小部分信息是非常重要的。这样,我们就可以使用更小、更快且更便宜的生成模型,同时不牺牲感知质量。
潜在自回归模型
随着具有里程碑意义的 VQ-VAE 论文的发表,图像自回归模型取得了巨大飞跃。该论文提出了一种实用策略,通过在自编码器中插入矢量量化瓶颈层,利用神经网络学习离散表征。为了学习图像的离散潜在表征,一个具有多个下采样阶段的卷积编码器生成了一个矢量的空间网格,其分辨率比输入图像低 4 倍(在高度和宽度上均为输入图像的 1/4,因此空间位置减少了 16 倍),然后这些矢量通过瓶颈层进行量化。
现在,我们可以使用类似 PixelCNN 的模型一次生成一个潜在向量,而不是逐像素生成图像。这显著减少了所需的自回归采样步骤数量,但更重要的是,在潜在空间而不是像素空间中测量似然损失,有助于避免在不可察觉的噪声上浪费模型容量。这实际上是一种不同的损失函数,更侧重于感知相关的信号内容,因为许多感知无关的信号内容在潜在向量中并不存在(关于这个问题,可以参阅我在典型性方面的博客文章)。该论文展示了从在 ImageNet 上训练的模型生成的 128×128 图像,这种分辨率在当时只有 GANs 才能达到。
离散化对于其成功至关重要,因为当时的自回归模型在离散输入下表现更好。但或许更重要的是,潜在表征的空间结构使得现有的基于像素的模型可以非常容易地进行适配。在此之前,变分自编码器(VAEs)通常会将整个图像压缩到一个单一的潜在向量中,导致表征没有任何拓扑结构。现代潜在表征的网格结构与「原始」输入表征的网格结构相镜像,生成模型的网络架构利用这种结构来提高效率(例如,通过卷积、循环或注意力层)。
VQ-VAE 2 进一步将分辨率提高到 256×256,并通过扩大规模和使用多层次的潜在网格(以层次化结构组织)显著提升了图像质量。随后,VQGAN 将 GANs 的对抗学习机制与 VQ-VAE 架构相结合。这使得分辨率降低因子从 4 倍增加到 16 倍(与像素输入相比,空间位置减少了 256 倍),同时仍然能够生成锐利且逼真的重建图像。对抗损失在其中发挥了重要作用,即使无法紧密遵循原始输入信号,也能鼓励生成逼真的解码器输出。
VQGAN 成为近五年来我们在感知信号生成建模方面取得快速进展的核心技术。其影响怎么强调都不为过 —— 我甚至可以说,这可能是 GANs 在 2024 年 NeurIPS 大会上获得「时间考验奖」的主要原因。VQGAN 论文提供的「助攻」,使 GANs 即使在被扩散模型几乎完全取代用于媒体生成的基础任务之后,依然保持着相关性。
值得一提的是,上一节中提到的许多方法在这个论文中都被构思出来了。如今,迭代生成器通常不是自回归的(Parti、xAI 最近的 Aurora 模型以及 OpenAI 的 GPT-4o 是显著例外),量化瓶颈也被替代了,但其他一切都还在。尤其是简单的回归损失、感知损失和对抗损失的组合,尽管看似复杂,却一直顽固地存在。在快速发展的机器学习领域,这种持久性极为罕见 —— 也许只有基本未变的 Transformer 架构和 Adam 优化器能与之媲美!
(虽然离散表征在使潜在自回归模型在大规模应用中发挥作用方面至关重要,但我想指出,最近连续空间中的自回归模型也取得了良好的效果。)
潜在扩散
随着潜在自回归模型在 2010 年代后期逐渐崭露头角,以及扩散模型在 2020 年代初期取得突破,将这两种方法的优势相结合成为了顺理成章的下一步。如同许多应运而生的想法一样,我们在 2021 年下半年见证了一系列探讨这一主题的论文在 arXiv 上接连发布。其中最为人熟知的是 Rombach 等人的《High-Resolution Image Synthesis with Latent Diffusion Models》,他们沿用了先前的 VQGAN 研究成果,并将自回归 Transformer 换成基于 UNet 的扩散模型,这一成果构成了稳定扩散模型的基础。其他相关工作虽然规模较小,或者针对的是非图像类数据,但也进行了类似探索。
这种方法主流化花了点时间。早期商业文生图模型使用所谓分辨率级联,即基础扩散模型直接在像素空间生成低分辨率图像,一个或多个上采样扩散模型则基于低分辨率输入生成高分辨率输出。典型例子包括 DALL-E 2 和 Imagen 2。稳定扩散模型问世后,大多转为基于潜在空间的方法(包括 DALL-E 3 和 Imagen 3)。
自回归模型和扩散模型一个关键区别在于训练所用的损失函数。自回归模型训练相对简单,最大化似然即可(尽管也曾尝试过其他方法)。扩散模型则复杂些,其损失函数是针对所有噪声级别的期望,这些噪声级别的相对权重显著影响模型学习内容。这为将典型的扩散损失解释为一种感知损失函数提供了依据,这种损失函数更强调在感知上更为显著的信号内容。
初看之下,这会让两阶段方法显得多余,因其与扩散损失函数的方式类似,即过滤掉感知无关信号内容,避免浪费模型容量。但实际中这两种机制相当互补,原因如下:
- 小尺度和大尺度下的感知工作机制似乎有根本区别,尤其是视觉领域。例如,建模纹理和细粒度细节需要单独处理,对抗方法可能更适合。我将在下文详细讨论。
- 训练大型强大扩散模型计算密集,使用更紧凑的潜在空间可避免处理笨重的输入表征,有助于减少内存需求,加快训练和采样速度。
早期确实有工作尝试端到端方法,联合学习潜在表征和扩散先验,但未流行。尽管从实用角度看,避免多阶段训练的序列依赖是可取的,但感知和计算优势使这些麻烦值得。
为什么需要两个阶段?

如前所述,确保感知信号的生成模型能够高效利用其容量至关重要,因为这能使它们更具成本效益。这基本上就是两阶段方法所实现的目标:通过提取更紧凑的表征,专注于信号内容中与感知相关部分,并对这一表征进行建模而非原始表征,我们能够使相对较小的生成模型发挥超越其规模的效果。
大多数感知信号中的信息实际上在感知上并不重要,这并非新发现:这也是有损压缩背后的关键思想,它使我们能够以更低的成本存储和传输这些信号。像 JPEG 和 MP3 这样的压缩算法利用了信号中的冗余以及我们对低频比高频更敏感的事实,从而用更少的比特表征感知信号。(还有其他感知效应,例如听觉掩蔽,但非均匀的频率敏感性是最重要的。)
那么,我们为什么不以这些有损压缩技术为基础来构建生成模型呢?这并非一个坏主意,一些研究确实为此目的使用了这些算法或其部分组件。但我们很自然地倾向于用更多的机器学习来解决问题,看看是否能超越这些 “手工设计” 的算法。
这不仅仅是机器学习研究者的自大:实际上,使用学习得到的潜在表征而非预先存在的压缩表征有一个非常好的理由。与压缩设置不同,在压缩设置中越小越好,尺寸是唯一重要的因素,生成建模的目标还施加了其他约束:某些表征比其他表征更容易建模。至关重要的是,表征中保留了一些结构,我们可以通过赋予生成模型适当的归纳偏置来加以利用。这一要求在重建质量和潜在表征的可建模性之间创造了权衡,我们将在下一节中探讨这一点。
潜在表征有效性的另一个重要原因是它们如何利用我们感知在不同尺度上不同工作的事实。在音频领域,这一点显而易见:幅度的快速变化会产生音高的感知,而在较粗时间尺度上的变化(例如鼓点)则可以被单独辨别。鲜为人知的是,这种现象在视觉感知中也扮演着重要角色:颜色和强度的快速局部波动被感知为纹理。我曾在 Twitter 上尝试解释这一点,并在此处改写该解释:
一种思考方式是纹理与结构的对比,或者有时人们称之为东西与物体的对比。
在一张狗在田野中的图像里,草的纹理(东西)是高熵的,但我们不善于感知这种纹理各个实例间的差异,我们只是将其感知为不可数的「草」。我们无需逐一把每一根草叶看在眼里,就能确定我们看到的是田野。
这种纹理的实现如果稍有不同,我们通常无法察觉,除非把图像直接叠在一起。用对抗自编码器做实验很有趣:当把原始图像和重建图像并排放在一起比较时,它们往往看起来一模一样。但如果把它们叠在一起,来回切换查看,常常会发现图像之间的差异,尤其是在纹理丰富的区域。
对于物体(有形的东西)来说,情况则不同,例如狗的眼睛,类似程度的差异会立刻显现出来。 一个好的潜在表征会抽象化纹理,但尽量保留结构。这样一来,在重建中对草纹理的表现可以与原始不同,而不会明显影响重建的保真度。这使得自编码器能够舍弃许多模式(即同一纹理的其他表现形式),并在其潜在空间中更简洁地表征该纹理的存在。
这反过来也应该使潜在空间中的生成建模变得更容易,因为它现在可以对纹理的有无进行建模,而无需捕捉与该纹理相关的所有复杂变化。

一张狗在田野中的图片。图片的上半部分熵值很低:组成天空的像素可以从其相邻像素中很容易地预测出来。而下半部分熵值很高:草地的纹理使得附近的像素很难被预测。
由于两阶段方法提供的显著效率提升,我们似乎愿意忍受它带来的额外复杂性 —— 至少目前是这样。这种效率的提升不仅使训练运行更快、更便宜,而且更重要的是,它还可以大大加速采样。对于执行迭代细化的生成模型来说,这种显著的成本降低非常受欢迎,因为生成单个样本需要多次通过模型进行前向传播。
权衡重建质量和可建模性

深入探讨有损压缩和潜在表征学习之间的差异是值得的。虽然机器学习可以用于两者,但如今广泛使用的大多数有损压缩算法并没有使用机器学习。这些算法通常基于率失真理论,该理论形式化并量化了我们能够压缩信号的程度(率)与我们允许解压缩信号与原始信号偏离的程度(失真)之间的关系。
对于潜在表征学习,我们可以通过引入可建模性或可学习性的概念来扩展这种权衡,该概念描述了生成模型捕捉这种表征分布的难度。这导致了一个三方的率失真可建模性权衡,这与 Tschannen 等人在表征学习的背景下讨论的率失真有用性权衡密切相关。(在机器学习背景下,另一种流行的扩展这种权衡的方式是率失真感知权衡,它明确区分了重建保真度和感知质量。为了避免过于复杂,我在这里不会做这种区分,而是将失真视为在感知空间中测量的量,而不是输入空间。)
为什么这甚至是一个权衡并不立即显而易见 —— 为什么可建模性与失真相冲突?要理解这一点,考虑有损压缩算法的工作方式:它们利用已知的信号结构来减少冗余。在这个过程中,这种结构通常从压缩表征中被移除,因为解压缩算法能够重建它。但输入信号中的结构也在现代生成模型中被广泛利用,例如以架构归纳偏差的形式,这些偏差利用信号属性,如平移等变性或频率谱的特定特征。
如果我们有一个神奇的算法,能够高效地从输入信号中移除几乎所有冗余,我们将使生成模型捕捉压缩信号中剩余的无结构变异性变得非常困难。如果我们的目标仅仅是压缩,这是完全可以的,但如果我们要进行生成建模,就不是这样了。因此,我们必须找到一个平衡:一个好的潜在表征学习算法会检测并移除一些冗余,但同时也会保留一些信号结构,以便为生成模型留下一些可以利用的东西。
在这种情况下,一个不好的例子是熵编码,它实际上是一种无损压缩方法,但也被用作许多有损方案的最后阶段(例如 JPEG/PNG 中的霍夫曼编码,或 H.265 中的算术编码)。熵编码算法通过为频繁出现的模式分配更短的表征来减少冗余。这并没有移除任何信息,但它破坏了结构。因此,输入信号中的小变化可能导致相应的压缩信号发生更大的变化,从而使熵编码序列的建模难度大大增加。
相比之下,潜在表征倾向于保留大量的信号结构。下面的图展示了一些图像的 Stable Diffusion 潜在表征的可视化(取自 EQ-VAE 论文)。仅通过视觉检查潜在表征,就可以很容易地识别出动物。它们基本上看起来像是带有扭曲颜色的噪声低分辨率图像。这就是为什么我喜欢将图像潜在表征视为仅仅是「高级像素」,捕捉了一些普通像素不会捕捉的额外信息,但大部分仍然像像素一样表现。

从几幅图像中提取的 Stable Diffusion 潜在表征的可视化,取自 EQ-VAE 论文。潜在空间的前三个主成分分别对应于颜色通道。从潜在表征的视觉检查中,图像中的动物仍然大多可以被识别出来,这表明编码器保留了大量原始信号的结构。
可以说,这些潜在表征相当低层次。传统的变分自编码器(VAE)会将整个图像压缩成一个特征向量,通常会得到一个能够进行语义操作的高级表征,而现代用于图像生成建模的潜在表征实际上更接近像素层面。它们具有更高的容量,继承了输入的网格结构(尽管分辨率较低)。网格中的每个潜在向量可能会抽象掉一些低层次的图像特征,例如纹理,但它并没有捕捉到图像内容的语义。这也是为什么大多数自编码器并不使用任何额外的条件信号,例如文字描述,因为这些信号主要约束的是高层次的结构(尽管也有例外)。
可控性

两个关键的设计参数控制着具有网格结构的潜在空间的容量:下采样因子和表征的通道数。如果潜在表征是离散的,码本大小也很重要,因为它对潜在表征能够包含的信息位数施加了一个硬性限制。(除了这些,正则化策略也起着重要作用,但我们将在下一节讨论它们的影响。)
以一个示例来说,编码器可能会接收一张 256×256 像素的图像作为输入,并生成一个带有 8 个通道的 32×32 连续潜在向量网格。这可以通过使用跨步卷积堆栈或补丁大小为 8 的视觉转换器(ViT)来实现。降采样因子会同时降低宽度和高度方向的维度,因此潜在向量的数量比像素少 64 倍 —— 但每个潜在向量有 8 个分量,而每个像素只有 3 个(RGB)。
总体而言,潜在表征的张量组件数量(即浮点数)比表征原始图像的张量少。我喜欢将这个数字称为张量尺寸缩减因子(TSR),以避免与空间或时间降采样因子混淆。

展示文本中描述的输入和潜在维度的示意图。
如果我们把编码器的下采样因子增加 2 倍,潜在网格的大小就会变成 16×16,然后我们可以把通道数增加 4 倍到 32 个通道,以保持相同的 TSR(总空间冗余)。对于给定的 TSR,通常有几种不同的配置在重建质量方面表现得大致相当,尤其是在视频的情况下,我们可以分别控制时间和空间的下采样因子。然而,如果我们改变 TSR(通过改变下采样因子而不改变通道数,或者反之),这通常会对重建质量和可建模性产生深远的影响。
从纯数学角度来看,这是令人惊讶的:如果潜在变量是实值的,网格的大小和通道的数量就不应该有关系,因为单个数字的信息容量已经是无限的(这被 Tupper 的自指公式巧妙地证明了)。但当然,有一些实际的限制因素限制了潜在表征的单个组成部分能够携带的信息量:
- 我们使用浮点数来表征实数,而浮点数的精度是有限的;
- 在许多公式中,编码器会添加一定量的噪声,这进一步限制了有效的精度;
- 神经网络并不擅长学习其输入的高非线性函数。
第一个原因显而易见:如果用 32 位(单精度)来表征一个数字,那么它最多也只能传递 32 位的信息。加入噪声会进一步减少可用的位数,因为一些低位数字会被噪声掩盖。
最后一个限制其实更为严格,但目前理解还不够充分:难道神经网络不就是为了学习非线性函数吗?确实如此,但神经网络天然倾向于学习相对简单的函数。这通常是一个优点,而不是缺点,因为它增加了学习到的函数能够泛化到未见数据的概率。但如果我们要把大量信息压缩到几个数字中,这很可能需要高度的非线性。虽然有一些方法可以帮助神经网络学习更复杂的非线性函数(例如傅里叶特征),但在我们的场景中,高度非线性的映射实际上会对可建模性产生负面影响:它们会掩盖信号结构,因此这不是一个好的解决方案。具有更多组件的表征会提供更好的权衡。
同样的道理也适用于离散潜在表征:离散化对表征的信息内容设定了一个硬性上限,但是否能够高效地利用这一容量主要取决于编码器的表达能力以及量化策略在实际中的效果(即是否通过尽可能均匀地使用不同码字来实现高码本利用率)。目前最常用的仍然是 VQ-VAE 中的原始 VQ 瓶颈,但最近一种通过「旋转技巧」提供更好梯度估计的改进方法在码本利用率和端到端性能方面似乎很有前景。一些不使用显式学习码本的替代方案也逐渐受到关注,例如有限标量量化(FSQ)、无查找量化(LFQ)和二进制球面量化(BSQ)。
总结来说,选择合适的 TSR(总空间冗余)至关重要:更大的潜在表征能够带来更好的重建质量(更高的率,更低的失真),但可能会对可建模性产生负面影响。更大的表征意味着有更多的信息位需要建模,因此需要生成模型具备更高的容量。在实践中,这种权衡通常是通过经验来调整的。这可能是一个成本较高的过程,因为目前还没有任何可靠且计算成本低的可建模性代理指标。因此,需要反复训练足够大的生成模型才能得到有意义的结果。
Hansen-Estruch 等人最近对潜在空间容量及其各种影响因素进行了广泛的探索(他们的关键发现已在文中明确突出显示)。目前有一个趋势是增加空间下采样因子,并相应地增加通道数以保持 TSR,以便在更高分辨率下进行图像和视频生成(例如 LTX-Video 中的 32×、GAIA-2 中的 44×,以及 DCAE 中的 64×)。
梳理和塑造潜在空间

到目前为止,我们已经讨论了潜在表征的容量,即应该在其中包含多少位信息。同样重要的是,要精确控制原始输入信号中的哪些位信息应该被保留在潜在表征中,以及这些信息是如何呈现的。我将前者称为梳理潜在空间,后者称为塑造潜在空间 —— 这种区分虽然微妙,但很重要。许多正则化策略已经被设计出来,用于塑造、梳理和控制潜在表征的容量。我将专注于连续情况,但其中许多考虑同样适用于离散潜在表征。
VQGAN 与 KL 正则化潜变量
Rombach 等人提出了两种针对连续潜在空间的正则化策略:
- 遵循原始 VQGAN 的设计理念,并将量化步骤重新解释为解码器的一部分(而非编码器的一部分),从而获得连续潜在表征(即 VQ 正则化,VQ-reg);
- 完全移除 VQGAN 中的量化操作,转而像标准变分自编码器(Variational Autoencoder,VAE)那样引入 KL 散度惩罚项(即 KL 正则化,KL-reg)。
这种只对 VQGAN 作出最小改动、以适配扩散模型(Diffusion Model)而生成连续潜变量的思路可谓巧妙:此类结构在自回归模型(Autoregressive Model)中表现良好,而训练过程中的量化步骤也起到了某种「安全阀」作用,防止潜变量携带过多的信息。
然而,正如我们之前所讨论的,这种机制在多数情况下可能并非真正必要,因为编码器的表达能力往往才是生成模型性能的瓶颈所在。
相比之下,KL 正则化本身是传统 VAE 架构的核心组成部分:它是构成证据下界(Evidence Lower Bound,ELBO)的两项损失之一。ELBO 是对数据似然的下界,用于间接地、但在数值上可行地最大化样本的对数似然。该项正则化鼓励潜变量服从某一预设先验分布(通常为高斯分布)。
但关键在于,ELBO 仅在 KL 项前未引入缩放超参数(scale parameter)的前提下,才是真正意义上的似然下界。然而在实际应用中,为了训练稳定性及重建质量的考虑,KL 正则项几乎总是被大幅缩放(通常缩小几个数量级),这几乎切断了它与变分推断原始语境之间的联系。
造成这一调整的原因也很直接:未经缩放的 KL 项具有过强的限制作用,会显著压缩潜在空间的容量,继而严重影响图像重建质量。出于工程可行性上的考虑,业界普遍的做法是显著降低其在总损失函数中的权重。
(顺便提一下:在某些更关注语义可解释性或潜变量解耦(disentanglement)质量、而非重建效果的任务中,增加 KL 权重也是一种有效且常见的策略,例如 β-VAE)。
接下来属于明显的主观观点,但我认为当前关于 KL 项效果的讨论中还存在相当多的 “神秘化思维”。例如,KL 项被广泛认为能引导潜变量服从高斯分布 —— 然而在实际应用中的缩放因子下,这一效果微弱到几乎可以忽略。即使是在 “真正的” VAE 中,总体后验分布(aggregate posterior)也很少呈现出标准高斯形态。
因此,在我看来,「VAE」中那个「V」(即 「Variational」,变分)如今几乎已失去实质意义 —— 其存在意义更多是历史遗留。与其如此,我们倒不如将这类模型称为「KL 正则化自编码器」(KL-regularised autoencoders),这在概念上对当前主流实践更贴切。
在这种设定下,KL 项最主要的作用,是抑制潜变量分布中的离群点,并在一定程度上约束其数值尺度。换句话说:尽管 KL 项通常被当作限制潜变量容量的机制来阐述,其在现实中起到的作用,更多是对潜变量形状的轻度限制 —— 而这种限制也远没有想象中那么强。
调整重建损失
重建损失的「三件套」(即回归损失(regression loss)、感知损失(perceptual loss)与对抗损失(adversarial loss))在最大程度提高重建信号质量方面无疑发挥着关键作用。
然而,值得进一步研究的是,这些损失项如何影响潜在变量(latents),特别是在「内容筛选」(curation,即潜变量学会编码哪些信息)方面的作用。如第 3 节(为什么需要两个阶段?)所讨论的,在视觉领域中,一个良好的潜在空间应在一定程度上实现对纹理的抽象(abstraction)。这些损失是如何帮助实现这一目标的?
一个有启发性的思维实验是,假设我们将感知损失和对抗损失去除,仅保留回归损失,如传统的变分自编码器(VAE)所采用的做法。这种设置通常会导致模糊的重建结果。回归损失在设计上不会偏向于特定类型的信号内容,因此在图像任务中,往往会更关注于低频信息,原因仅仅是这种信息在图像中占比较大。
在自然图像中,不同空间频率的能量通常与其频率的平方成反比 —— 频率越高,能量越小(有关该现象的图示分析,请参阅我先前的博文)。由于高频成分在总信号能量中所占比例极小,因此使用回归损失时,模型更倾向于准确地预测低频分量,而非高频部分。
然而,从人类感知的角度看,高频信息的主观重要性远远高于它们在信号能量中所占的比例,这也就导致了大家熟知的「模糊感」重建结果。

图片来自 VQGAN 论文。与仅使用回归损失训练的 DALL-E VAE 的对比展示了感知与对抗损失所带来的显著影响。
由于纹理主要由这些高频成分构成,而回归损失几乎忽略这些高频信息,最终我们得到的潜在空间不仅无法做出纹理抽象,反而是直接抹去了与纹理相关的信息。从感知质量的角度讲,这是一种很差的潜在空间结构。这也直接说明了感知损失与对抗损失的重要性:它们确保潜在变量中能够编码一定的纹理信息。
既然回归损失具有上述这些不理想的性质,并且往往需要其他损失项来加以弥补,那我们是否可以干脆将其完全舍弃呢?事实证明,这种做法也不可行。因为感知损失与对抗损失的优化过程更为复杂,且容易陷入病态的局部最优解(毕竟,这些损失通常是基于预训练神经网络构建的)。在训练过程中,回归损失起到某种「正则化器」的角色,持续为优化过程提供约束与指引,避免模型陷入错误的参数空间。
当前已有诸多策略尝试采用不同形式的重建损失,以下仅列举部分文献中的实例,展示该方向的多样性:
- 前文提到的 DCAE46 模型,其方法在整体上与原始的 VQGAN 配方差异不大,只是将 L2 回归损失(均方误差,MSE)替换为 L1 损失(平均绝对误差,MAE)。它依然保留了 LPIPS 感知损失(Learned Perceptual Image Patch Similarity)以及 PatchGAN49 判别器。该方法的不同之处在于其采用了多阶段训练,仅在最后阶段启用对抗损失。
- ViT-VQGAN50 模型结合了两种回归损失:L2 损失与 logit-Laplace 损失 51,并使用 StyleGAN52 判别器以及 LPIPS 感知损失。
- LTX-Video44 模型引入了一种基于离散小波变换(Discrete Wavelet Transform,DWT)的「视频感知损失」,并提出了其独特的对抗损失策略,称为 reconstruction-GAN。
正如经典菜肴千人千味,在这种「配方」问题上,每位研究者都有各自的解法!
表征学习 vs 重建
此前我们探讨的诸多设计选择,不仅影响重建质量,同时也深刻影响所学习的潜在空间的性质。其中,重建损失事实上承担了双重任务:既保证了解码器输出的高质量,又在潜在空间的形成中发挥了关键作用。这不禁引出一个问题:像我们现在这样「一石二鸟」的做法,真的合适吗?我认为答案是否定的。
一方面,为生成建模(generative modelling)学习出良好且紧凑的表征;另一方面,将这一表征解码回原始输入空间,这其实是两项截然不同的任务。而现代自动编码器通常被期望能同时完成这两项任务。
尽管从实践角度看,这种做法效果相当不错,无疑也简化了流程(毕竟自动编码器训练已经是完整系统中第一阶段的训练部分,我们自然希望尽可能避免进一步复杂化,尽管训练多个阶段的自动编码器也并非闻所未闻。但这一方法实则混淆了两个任务,其间某些适用于一个任务的设计,或许在另一个任务上并不理想。
当解码器采用自回归架构时,这种任务合并的问题尤为突出,因此我们提出使用一个独立的非自回归(non-autoregressive)辅助解码器(auxiliary decoder)来为编码器提供学习信号。
主解码器(main decoder)则完全不会影响潜在表征,因为其梯度在训练中不会反传至编码器。这使其专注于优化重建质量,而辅助解码器则承担起潜在空间的塑造任务。整个自动编码器各组件仍可联合训练,因此增加的训练复杂度非常有限。虽然辅助解码器会增加训练成本,但它在训练完成后即可被舍弃。

这种带有两个解码器的自动编码器结构中:主解码器仅用于重建,其梯度不回传到编码器(通常我们用虚线来表示这一点)辅助解码器则专注于构建潜在空间,它可以采用不同的架构、优化不同的损失函数,或者两者兼而有之。
尽管我们在那篇论文中使用自回归解码器来处理像素空间的想法,如今已经不再适用(可以说很不合时宜),但我仍然相信将表征学习与重建任务分开的这一策略在当前仍具有高度相关性。
一个辅助解码器,如果它优化的是另一种损失,或者采用了与主解码器不同的架构(抑或两者兼具),就可能为表征学习提供更有效的训练信号,从而带来更优的生成建模效果。
Zhu 等人最近也得出了同样的结论(见其论文第 2.1 节),他们使用 K-means 对 DINOv2 提取的特征进行离散化建模,并结合一个单独训练的解码器。在生成建模中复用自监督学习(self-supervised learning)得到的表征,这一思路在音频建模领域早已较为普遍 —— 可能是因为音频领域研究者原本就习惯于训练声码器(vocoder),将预定义的中间表征(例如梅尔频谱图)转换回波形信号。
通过正则化提升模型能力
对潜在变量容量的塑造、梳理和限制都会影响其可建模性:
- 容量限制决定了潜在变量中的信息量。容量越高,生成模型就必须越强大,才能充分捕捉其包含的所有信息;
- 塑造对于实现高效建模至关重要。相同的信息可以用多种不同的方式表征,有些方式比其他方式更容易建模。缩放和标准化对于正确建模至关重要(尤其是对于扩散模型而言),但高阶统计量和相关结构也同样重要;
- 梳理会影响可建模性,因为某些类型的信息比其他类型的信息更容易建模。如果潜在变量编码了输入信号中不可预测的噪声信息,那么它们的可预测性也会降低。
以下是一条有趣的推文,展示了这如何影响稳定扩散 XL VAE:

图源:https://x.com/rgilman33/status/1911712029443862938
在这里,我想将其与 Xu et al. 提出的 V-information 联系起来,它扩展了互信息的概念,使其能够考虑计算约束。换句话说,信息的可用性取决于观察者辨别信息的计算难度,我们可以尝试量化这一点。如果一条信息需要强大的神经网络来提取,那么输入中的 V-information 量就会低于使用简单线性探测的情况 —— 即使以比特为单位的绝对信息量相同。
显然,最大化潜在表征的 V-information 量是可取的,以便最大限度地降低生成模型理解潜在表征所需的计算需求。我之前提到的 Tschannen et al. 描述的速率 - 失真 - 实用性权衡也支持同样的结论。
如前所述,KL 惩罚对高斯化或平滑潜在空间的作用可能不如许多人认为的那么大。那么,我们可以做些什么来使潜在模型更容易建模呢?
- 使用生成先验:与自动编码器共同训练一个(轻量级)潜在生成模型,并通过将生成损失反向传播到编码器中,使潜在模型易于建模,就像在 LARP 或 CRT 中一样。这需要仔细调整损失权重,因为生成损失和重构损失相互矛盾:当潜在模型完全不编码任何信息时,它们最容易建模!
- 使用预训练的表征进行监督:鼓励潜在模型对现有高质量表征(例如 DINOv2 特征)进行预测,就像在 VA-VAE、MAETok 或 GigaTok 中一样。
- 鼓励等变性:使输入的某些变换(例如重缩放、旋转)产生相应的潜在表征,这些表征也进行类似变换,就像在 AuraEquiVAE、EQ-VAE 和 AF-VAE 中一样。我在第 4 部分中使用的 EQ-VAE 论文中的图表展示了这种约束对潜在空间的空间平滑度产生的深远影响。Skorokhodov et al. 基于潜在空间的谱分析得出了相同的结论:等变性正则化使潜在谱与像素空间输入的谱更相似,从而提高了可建模性。
这只是一些可能的正则化策略的一小部分,所有这些策略都试图以某种方式增加潜在向量的 V-information。
向下扩散
一类用于学习潜在表征的自编码器值得深入研究:带有扩散解码器的自编码器。虽然更典型的解码器架构采用前馈网络,该网络在一次前向传递中直接输出像素值,并且采用对抗式训练,但一种越来越流行的替代方案是使用扩散来完成潜在解码任务以及对潜在表征的分布进行建模。这不仅会影响重构质量,还会影响学习到的表征类型。
SWYCC、ϵ-VAE 和 DiTo 是近期一些探索这种方法的研究成果,它们从几个不同的角度阐述了这一方法:
- 使用扩散解码器学习的潜在特征提供了一种更具原则性、理论基础的层级生成建模方法;
- 它们可以仅使用 MSE 损失进行训练,这简化了过程并提高了鲁棒性(毕竟对抗性损失的调整相当棘手);
- 将迭代改进的原理应用于解码可以提高输出质量。
我无法反驳这些观点,但我确实想指出扩散解码器的一个显著弱点:它们的计算成本及其对解码器延迟的影响。我认为,目前大多数商业部署的扩散模型都是潜在模型的一个关键原因是:紧凑的潜在表征有助于我们避免在输入空间进行迭代细化,而这种做法既慢又贵。在潜在空间中执行迭代采样过程,然后在最后通过一次前向传播回到输入空间,速度要快得多。考虑到这一点,在我看来,在解码任务中重新引入输入空间迭代细化,在很大程度上违背了两阶段方法的初衷。如果我们要付出这样的代价,不妨选择一些简单的扩散方法来扩展单阶段生成模型。
你可能会说,别急 —— 我们难道不能使用众多扩散蒸馏方法来减少所需的步骤数吗?在这样的设置中,由于具有非常丰富的条件信号(即潜在表征),这些方法确实被证明是有效的,甚至在单步采样机制下也是如此:条件越强,获得高质量蒸馏结果所需的步骤就越少。
DALL-E 3 的一致性解码器就是一个很好的实践案例:他们重用了稳定扩散潜在空间,并训练了一个基于扩散的新解码器,然后通过一致性蒸馏将其精简为仅两个采样步骤。虽然在延迟方面,它的开销仍然比原始对抗解码器更高,但输出的视觉保真度得到了显著提升。

DALL-E 3 基于 Stable Diffusion 潜在空间的一致性解码器显著提高了视觉保真度,但代价是延迟更高。
Music2Latent 是这种方法的另一个例子,它基于音乐音频的声谱图表征进行操作。它们的自编码器带有一致性解码器,采用端到端训练(不同于 DALL-E 3 的自编码器,后者复用了预训练的编码器),并且能够一步生成高保真输出。这意味着解码过程再次只需要一次前向传递,就像对抗性解码器一样。
FlowMo 是一款带有扩散解码器的自编码器,它使用后训练阶段来鼓励模式搜索行为。如前所述,对于解码潜在表征的任务,丢失模态以及专注于真实性而非多样性实际上是可取的,因为它需要的模型容量较少,并且不会对感知质量产生负面影响。对抗性损失往往会导致模态丢失,但基于扩散的损失则不会。这种两阶段训练策略使扩散解码器能够模拟这种行为 —— 尽管仍然需要大量的采样步骤,因此计算成本远高于典型的对抗性解码器。
一些早期关于扩散自编码器的研究,例如 Diff-AE 和 DiffuseVAE,更侧重于学习类似于老式 VAE 的高级语义表征,没有拓扑结构,并且注重可控性和解耦。DisCo-Diff 介于两者之间,它利用一系列离散潜在表征来增强扩散模型,这些潜在表征可以通过自回归先验建模。
消除对抗训练的必要性无疑会简化事情,因此扩散自编码器在这方面是一个有趣(最近也相当流行)的研究领域。然而,在延迟方面,与对抗性解码器竞争似乎颇具挑战性,所以我认为我们还没有准备好放弃它们。我非常期待一个更新的方案:它不需要对抗性训练,但在视觉质量和延迟方面却能与当前的对抗解码器相媲美!
网格统治一切

感知模态的数字表征通常采用网格结构,因为它们是底层物理信号的均匀采样(和量化)版本。图像产生二维像素网格,视频产生三维网格,音频信号产生一维网格(即序列)。均匀采样意味着相邻网格位置之间存在着固定的量子(即距离或者时间量)。
从统计意义上讲,感知信号在时间和空间上也趋于近似平稳。与均匀采样相结合,这产生了丰富的拓扑结构,我们在设计用于处理它们的神经网络架构时会充分利用这种结构:使用广泛的权重共享来利用不变性和等变性等特性,这些特性通过卷积、循环和注意力机制来实现。
毫无疑问,对网格结构的利用正是我们能够构建如此强大的机器学习模型的关键原因之一。由此推论,在设计潜在空间时保留这种结构是一个绝佳的主意。我们最强大的神经网络设计在架构上依赖于它,因为它们最初就是为直接处理这些数字信号而构建的。如果潜在表征具有相同的结构,它们将更擅长处理这些表征。
网格结构也为学习生成潜在空间的自编码器带来了显著的优势:由于平稳性,并且它们只需要学习局部信号结构,因此可以在较小的裁剪图像或输入信号片段上进行训练。如果我们施加正确的架构约束(限制编码器和解码器中每个位置的感受野),它们将能够开箱即用地泛化到比训练时更大的网格。这有可能大大降低第一阶段的训练成本。
然而,事情并非总是那么美好:我们已经讨论过感知信号是如何高度冗余的,遗憾的是,这种冗余分布不均。信号的某些部分可能包含大量感知上显著的细节,而其他部分则几乎没有信息。在我们之前使用的田野里狗的图像中,考虑一个以狗的头部为中心的 100×100 像素块,然后将其与图像右上角仅包含蓝天的 100×100 像素块进行比较。

田野里的狗的图像,其中突出显示了两个具有不同冗余度的 100×100 像素块。
如果我们构建一个继承输入二维网格结构的潜在表征,并用它来编码这幅图像,则必然会使用完全相同的容量来编码这两个图像块。如果我们让表征足够丰富,能够捕捉到狗头所有相关的感知细节,那么将浪费大量容量来编码类似大小的天空图像块。换句话说,保留网格结构会显著降低潜在表征的效率。
这就是我所说的「网格统治一切」:我们用神经网络处理网格结构数据的能力已经非常成熟,偏离这种结构会增加复杂性,使建模任务变得更加困难,并且对硬件的兼容性也更差,所以通常不会这样做。但就编码效率而言,这实际上相当浪费,因为视听信号中感知显著的信息分布并不均匀。
Transformer 架构实际上相对适合对抗这种统治:虽然我们通常将其视为序列模型,但它实际上是为处理集值(set-valued)数据而设计的,任何将集合元素相互关联的附加拓扑结构都通过位置编码来表达。这使得偏离常规网格结构比卷积或循环架构更为实用。几年前,我和同事探索了使用可变速率离散表征进行语音生成的这个想法。在两阶段生成模型的背景下,放松潜在空间的拓扑结构似乎最近越来越受到关注,包括如下:
- TiTok 和 FlowMo 从图像中学习序列结构化的潜在表征,将网格维度从二维降低到一维。大型语言模型的发展为我们带来了极其强大的序列模型,因此这是一种合理的目标结构;
- One-D-Piece 和 FlexTok 也采用了类似的方法,但使用了嵌套的 dropout 机制,在潜在序列中引入了由粗到细的结构。这使得序列长度能够根据每个输入图像的复杂度以及重建所需的细节级别进行调整。CAT 也探索了这种自适应性,但仍然保留了二维网格结构,并且仅调整其分辨率;
- TokenSet 更进一步,使用了一种生成「token 袋」的自动编码器,完全摒弃了网格。
除了 CAT 之外,所有这些方法的共同点在于:它们学习的潜在空间在语义上比我们目前主要讨论的那些要高级得多。就抽象层次而言,它们可能介于「高级像素」和老式 VAE 的矢量值潜在空间之间。FlexTok 的一维序列编码器需要使用现有二维网格结构编码器的低级潜在空间作为输入,实际上是在现有低级潜在空间之上构建了一个额外的抽象层。TiTok 和 One-D-Piece 也利用现有的二维网格结构潜在空间作为多阶段训练方法的一部分。一个相关的思路是:将语言域重用为图像的高级潜在表征。
在离散环境下,一些工作利用语言 tokenisation 的思想,研究了网格中常见的 token 模式是否可以组合成更大的子单元:DiscreTalk 是语音领域的一个早期示例,它在 VQ token 之上使用了 SentencePiece。Zhang et al 的 BPE Image Tokenizer 是这一思路的较新体现,它在 VQGAN token 上使用了一种增强的字节对编码算法。
其他模态的潜在变量

到目前为止,我们主要关注视觉领域,仅在一些地方简要提及音频。这是因为学习图像的潜在特征是我们已经非常擅长的事情,而且近年来,使用两阶段方法的图像生成已经得到了广泛的研究并投入生产!。我们在感知损失方面拥有成熟的研究体系,以及大量的判别器架构,使对抗训练能够专注于感知相关的图像内容。
对于视频,我们仍然停留在视觉领域,但引入了时间维度,这带来了一些挑战。人们可以简单地重复使用图像的潜在特征并逐帧提取它们来获得潜在的视频表征,但这可能会导致时间伪影(例如闪烁)。更重要的是,它无法利用时间冗余。我认为我们用于时空潜在表征学习的工具还远远不够完善,而且目前人们对如何利用人类对运动的感知来提高效率的理解也不够深入。尽管视频压缩算法都利用运动估计来提高效率,但情况仍然如此。
音频也是如此:虽然两阶段方法已被广泛采用,但对于使其适用于这种模态所需的修改,似乎并未达成广泛的共识。如前所述,对于音频,更常见的做法是重用通过自监督学习习得的表征。
那么语言呢?语言并非感知模态,但两阶段方法或许也能提高大型语言模型的效率吗?事实证明,这并非易事。语言本质上比感知信号更难压缩:它作为一种高效的沟通方式发展起来,因此冗余度要低得多。但这并不意味着语言就不存在:香农曾有一个著名的估计:英语的冗余度为 50%。但请记住,图像、音频和视频可以在相对较小的感知失真下压缩几个数量级,而语言则不可能在不丢失细微差别或重要语义信息的情况下做到这一点。
用于语言模型的 Tokeniser 往往是无损的(例如 BPE、SentencePiece),因此生成的 token 通常不被视为「潜在 token」(然而,Byte Latent Transformer 在其动态 tokenisation 策略中确实使用了这种框架)。然而,语言中相对缺乏冗余并没有阻止人们尝试学习有损的高级表征!用于感知信号的技术可能无法沿用,但人们已经探索了几种其他用于学习句子或段落级别表征的方法。
端到端会是最后赢家吗?

当深度学习兴起时,主流观点是:我们将尽可能用端到端学习取代手工构建的特征。联合学习所有处理阶段将使这些阶段能够相互适应和协作,从而最大限度地提高性能,同时从工程角度简化流程。这或多或少也正是计算机视觉和语音处理领域最终发生的事情。从这个角度来看,颇具讽刺意味的是,当今感知信号的主流生成建模范式是两阶段方法。虽然两个阶段都倾向于学习,但并非完全端到端!
如今产品中部署的文本转图像、文本转视频和文本转音频模型大多使用中间潜在表征。值得思考的是,这种现状是暂时的,还是会持续下去?毕竟,两阶段训练确实引入了相当多的复杂性,除了更加优雅之外,端到端学习还可以帮助确保系统的所有部分都与单一的总体目标完美地保持一致。
如上所述,输入空间的迭代细化速度慢且成本高昂,我认为这种情况可能会持续一段时间 —— 尤其是在我们不断提升生成信号的质量、分辨率和 / 或长度的情况下。我们不太可能放弃潜在层在训练效率和采样延迟方面的优势,目前尚无可行的替代方案被证明能够大规模应用。这是一个颇具争议的观点,因为一些研究人员似乎认为是时候转向端到端方法了。我个人认为现在还为时过早。
那么,我们何时才能准备好回归单阶段生成模型呢?像简单扩散、Ambient Space Flow、Transformers 和 PixelFlow 这样的方法已经证明:即使在相对较高的分辨率下,这种方法也能很好地发挥作用,只是目前还不够划算。但硬件正以惊人的速度不断改进和提升,因此我推测我们最终会达到一个临界点:即相对低效的输入空间模型在经济上优于工程复杂性日益增加的潜在空间模型。至于何时实现,则取决于具体模态、硬件改进的速度以及研究的进展,因此我不会做出具体的预测。
过去,我们需要潜在向量来确保生成模型专注于学习感知相关的信号内容,同时忽略视觉上不显著的熵。回想一下,输入空间中的似然损失在这方面尤其糟糕,而切换到在潜在空间中测量似然值可以显著改善基于似然模型的结果。可以说,这种情况已不再存在,因为我们已经找到了如何在感知上重新加权自回归和扩散模型的似然损失函数,从而消除了扩展的一个重要障碍。尽管如此,潜在空间模型的计算效率优势仍然一如既往地重要。
第三种替代方案,我目前为止只是简要提到过,是分辨率级联方法。这种方法不需要表征学习,但仍然将生成模型问题分解为多个阶段。一些早期的商业模型曾使用这种方法,但它似乎已经不再受欢迎了。我认为这是因为不同阶段之间的分工不够完善 —— 上采样模型必须完成太多的工作,这使得它们更容易在各个阶段积累错误。
#Cockatiel
VDC+VBench双榜第一!强化学习打磨的国产视频大模型,超越Sora、Pika
随着 Deepseek 等强推理模型的成功,强化学习在大语言模型训练中越来越重要,但在视频生成领域缺少探索。复旦大学等机构将强化学习引入到视频生成领域,经过强化学习优化的视频生成模型,生成效果更加自然流畅,更加合理。并且分别在 VDC(Video Detailed Captioning)[1] 和 VBench [2] 两大国际权威榜单中斩获第一。
视频细粒度文本描述
视频细粒度文本描述模型(video detailed caption)为视频生成模型提供标签,是视频生成的基础。复旦大学等机构提出了 Cockatiel 方法 [3],该方法在权威的 VDC(Video Detailed Captioning 视频细粒度文本描述评测集)榜单上获得第一名,超过了包括通义千问 2-VL、VILA1.5、LLaVA-OneVision,Gemini-1.5 等在内的多个主流视频理解多模态大模型。

- 论文标题:Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption
- 项目主页: https://sais-fuxi.github.io/projects/cockatiel/
- 论文地址: https://arxiv.org/pdf/2503.09279
- Github: https://github.com/Fr0zenCrane/Cockatiel
Cockatiel 的核心思路是:基于人类偏好对齐的高质量合成数据,设计三阶段微调训练流程,系统集成了多个在不同描述维度上表现领先的模型优势。通过这一方法,以单机的训练成本训练出了一套在细粒度表达、人类偏好一致性等方面均表现卓越的视频细粒度描述模型,为后续视频生成模型的训练和优化打下了坚实基础,模型细节如下(更多详情可参考论文和开源 github):

- 阶段一:构造视频细粒度描述的人类偏好数据:分别对视频描述的对象、对象特征、动态特征、镜头动作和背景的文本描述质量进行人工标注。
- 阶段二:基于打分器的多模型集成训练:基于人工标注数据训练奖励函数(reward model),并多个模型合成的视频描述计算奖励(reward),最终对 13B 的多模态大语言模型进行人类偏好对齐优化。
- 阶段三:蒸馏轻量化模型:基于上一步训练的 13B 的多模态大语言模型蒸馏 8B 模型,方便后续在下游任务中低成本推理。
实验结果显示基于 Cockatiel 系列模型生成的视频细粒度描述,具备维度全面、叙述精准详实以及幻觉现象较少的显著优势。如下图所示,与 ViLA,LLaVA 和 Aria 的基线模型相比,Cockatiel-13B 不仅能够准确复现基线模型所描述的细节(以黄底高亮部分表示),还能捕捉到基线模型遗漏的关键信息(以红底高亮部分表示)。而 Cockatiel 生成的描述则大量避免了幻觉性内容,Cockatiel 展现了更高的可靠性和准确性。

强化学习加强的视频生成技术
在视频生成领域,该团队首次提出了迭代式强化学习偏好优化方法 IPOC [4],在权威视频生成评测榜单 VBench (2025-04-14) 上,IPOC 以 86.57% 的总分强势登顶,领先通义万相、Sora、HunyuanVideo、Minimax、Gen3、Pika 等众多国内外知名视频生成模型。


- 论文标题:IPO: Iterative Preference Optimization for Text-to-Video Generation
- 论文地址:https://arxiv.org/pdf/2502.02088
- 项目主页:https://yangxlarge.github.io/ipoc//
- GitHub 地址:https://github.com/SAIS-FUXI/IPO
研究者通过迭代式强化学习优化方式,避免了强化学习中训练不稳定的问题。同时只需要依赖少量的训练数据和算力,以低成本实现效果优化。 模型细节如下(更多详情可参考论文和开源 github):

阶段一:人工偏好数据标注:IPO 方法通过逐视频打分(Pointwise Annotation)与成对视频排序(Pairwise Annotation)两种方式进行人工标注。标注过程中,标注者不仅需要提供评分或排序结果,还需详细阐述评分理由,以构建具有思维链(Chain-of-Thought, CoT)风格的标注数据。这种标注形式有助于模型深入理解视频内容与文本描述之间的语义一致性,从而形成高质量的人类偏好数据集。
阶段二:奖励模型训练:IPO 方法进一步引入了一种基于多模态大模型的 “奖励模型”(Critic Model)。奖励模型仅通过少量人工标注数据和少量算力即可高效训练完成,随后可自动实现对单个视频的评分以及对多个视频的对比排序。这种设计无需在每次迭代优化时都重新进行人工标注,显著提高了迭代优化效率。此外,奖励模型具备出色的通用性和 “即插即用” 特性,可广泛适配于各类视频生成模型。
阶段三:迭代强化学习优化:IPO 方法利用当前的视频生成(T2V)模型生成大量新视频,并由已训练的奖励模型对这些视频进行自动评价与标注,形成新的偏好数据集。随后,这些自动标注的数据用于进一步优化 T2V 模型。这一过程持续迭代循环,即:“视频生成采样 → 样本奖励计算 → 偏好对齐优化”。此外,我们提出的 IPO 框架同时兼容当前主流的偏好优化算法,包括基于对比排序的 Diffusion-DPO 方法与基于二分类评分的 Diffusion-KTO 方法,用户可灵活选择训练目标,其中两种人类偏好对齐方法(DPO 和 KTO)的训练目标为:
- DPO (Direct Preference Optimization):

- KTO (Kahneman-Tversky Optimization):

实验结果显示经过优化后,视频生成模型在时序一致性上实现了显著提升。相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,狮子的行走动作更加自然连贯,整体动态流畅度有了明显改善。
,时长00:06
Prompt: An astronaut in a sandy-colored spacesuit is seated on a majestic lion with a golden mane in the middle of a vast desert. The lion's paws leave deep prints in the sand as it prowls forward. The astronaut holds a compass, looking for a way out of the endless expanse. The sun beats down mercilessly, and the heat shimmers in the air.
视频生成模型在结构合理性提升明显。相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,人物和猛犸象具有更好结构合理性。
,时长00:06
Prompt: A young girl in a futuristic spacesuit runs across a vast, icy landscape on a distant planet, with a towering mammoth-like creature beside her. The mammoth's massive, shaggy form and long tusks contrast with the stark, alien environment. The sky above is a deep, star-filled space, with distant planets and nebulae visible.
视频生成模型在动态程度和美学度都有明显提升,相比于 CogVideoX-2B(左图),IPOC-2B 生成的视频(右图)中,人物动作更加流畅,人物和背景更好美观。6
Prompt: A woman with flowing dark hair and a serene expression sits at a cozy The café, sipping from a steaming ceramic mug. She wears a soft, cream-colored sweater and a light brown scarf, adding to the warm, inviting atmosphere. The The café is dimly lit with soft, ambient lighting, and a few potted plants add a touch of greenery.
相关内容:
[1].Chai, Wenhao, Enxin Song, Yilun Du, Chenlin Meng, Vashisht Madhavan, Omer Bar-Tal, Jenq-Neng Hwang, Saining Xie, and Christopher D. Manning. "Auroracap: Efficient, performant video detailed captioning and a new benchmark." arXiv preprint arXiv:2410.03051 (2024).Project Page:https://wenhaochai.com/aurora-web/
[2].Huang, Ziqi, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang et al. "Vbench: Comprehensive benchmark suite for video generative models." In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 21807-21818. 2024.Project Page:https://vchitect.github.io/VBench-project/
[3].Qin, Luozheng, Zhiyu Tan, Mengping Yang, Xiaomeng Yang, and Hao Li. "Cockatiel: Ensembling Synthetic and Human Preferenced Training for Detailed Video Caption." arXiv preprint arXiv:2503.09279 (2025).Porject Page:https://sais-fuxi.github.io/projects/cockatiel/
[4].Yang, Xiaomeng, Zhiyu Tan, and Hao Li. "Ipo: Iterative preference optimization for text-to-video generation." arXiv preprint arXiv:2502.02088 (2025). Porject Page:https://yangxlarge.github.io/ipoc//
#estimates
陶哲轩:感谢ChatGPT,4小时独立完成了一个开源项目
这个五一假期,世界顶级数学家是如何度过的?
菲尔兹奖得主陶哲轩,似乎是忙着发布自己的开源项目:「我在大模型的协助下编写了一个概念验证软件工具,用于验证涉及任意正参数的给定估计是否成立(在常数因子范围内)。」
项目地址:https://github.com/teorth/estimates
在这个项目中,陶哲轩开发了一个用于自动(或半自动)证明分析中估计值的框架。估计值是 X≲Y(在渐近记法中表示 X=O (Y))或 X≪Y(在渐近符号中表示 X=o (Y))形式的不等式。
为什么要做这样一个工具?这就要从近期陶哲轩和 Bjoern Bringmann(陶哲轩曾经的博士生,现为普林斯顿大学助理教授)的讨论说起。
对于代数、微积分和数值分析等领域的许多数学任务来说,符号数学软件包已经非常「发达」了。但目前还没有类似的复杂工具来验证渐近估计 —— 在损失不变的情况下,对于任意大的参数都应该成立的不等式。尤其重要的是函数估计,其中参数涉及一个未知函数或序列(存在于某个合适的函数空间,如一个空间)。
陶哲轩将二人的讨论结果写成了一篇博客,重点讨论了更简单的渐近估计情况,即涉及有限数量的正实数,并使用加、乘、除、指数、最小值和最大值(但不包括减法)等算术运算进行组合。
「我过去曾希望能有一个工具能够自动判断此类估计是否成立(如果成立,则提供证明;如果不成立,则提供渐近反例)。」
现在,这个心愿实现了。
我们都知道,陶哲轩非常爱好使用大模型来辅助解决数学问题。过去的大多数情况是完成比较简单的编码任务,例如计算然后绘制一些稍微复杂的数学函数,或者对某些数据集进行一些基本的数据分析。
这次,他决定给自己一个更具挑战性的任务:编写一个可以处理上述形式不等式的验证器。
举个例子,一个典型的不等式可能是弱算术平均 - 几何平均不等式。

其中 abc 是任意正实数,这里的

表示我们愿意在估计中丢失一个未指定的(乘性)常数。
原则上,这类形式的简单不等式可以通过强力的案例拆分自动解决。单个这类的不等式都不太难手工求解,但有些应用需要检验大量这样的不等式,或者将其拆分成大量案例。这项任务似乎非常适合自动化,尤其是在现代技术的帮助下。
陶哲轩这次用到的 AI 工具仍然是 ChatGPT。经过大约四个小时的编程,在大模型的频繁协助下,他顺利做出了一个概念验证工具。
与此同时,陶哲轩还放出了与 ChatGPT 的对话过程,不难发现,对话过程还是蛮长的。
链接:https://chatgpt.com/share/68143a97-9424-800e-b43a-ea9690485bd8
一开始,陶哲轩就对 ChatGPT 提出了自己的需求:「我想编写一些 Python 类来操作符号表达式。并且希望有一个表示变量的类,比如 x、y、z…… 你能帮我编写一些具有这种功能的基础类来入门吗?」

ChatGPT 思考了 6 秒钟就给出了答案。

这一步完成之后,下一轮对话开始,陶哲轩接着追问「我看到你用 add 实现了 + 操作,真棒。那么,实现 * 和 / 的对应方法是什么呢?」
ChatGPT 也给出了回答:

在整个过程中,陶哲轩不断询问,ChatGPT 也做到了有问必答,不管是简单的问题,还是复杂的问题,ChatGPT 都给解决了:

「如何在与当前 python 文件相同的目录下导入 python 文件?」

最终,在 ChatGPT 的大力协助下,陶哲轩完成了这个概念验证软件工具。
其实,在众多知名数学家中,陶哲轩是较早接受并发现 ChatGPT 这类 AI 大模型数学价值的一个。他曾预测「如果使用得当,到 2026 年,AI 将成为数学研究和许多其他领域值得信赖的合著者。」
陶哲轩不止一次借助大模型进行研究,他曾在 GPT-4 的帮助下成功解决了一个数学证明题(GPT4 提出了 8 种方法,其中 1 种成功解决了问题),还在 AI 的帮助下发现了自己论文中的一处隐藏 bug。

陶哲轩还建议大家如果想要开发这类软件,最好是数学家与专业程序员以协作的方式进行,这样才能优势互补。
「这当然是一个极其不优雅的证明,但优雅并非重点,重点在于它是自动化的。」
回顾整个过程,我们可以从陶哲轩的经历中得到一些启发,对大模型的开发使用,或许只是冰山一角,更多的功能等着大家去解锁。
参考链接:
https://terrytao.wordpress.com/2025/05/01/a-proof-of-concept-tool-to-verify-estimates/
#Gemini 2.5 Pro升级
成编程模型新王
你的默认编程模型是什么?或许可以换一换了。
刚刚,Google DeepMind 发布了 Gemini 2.5 Pro 的最新更新版本:Gemini 2.5 Pro (I/O edition)。

其最大的进步是编程能力大幅提升,不仅在 LMArena 编程排行榜上名列第一,同时也在 WebDev Arena 排行榜上更是以显著优势超过了昔日霸主 Claude 3.7 Sonnet (20250219)!


不仅如此,现在用户只需使用一个提示词即可构建 Web 应用、游戏和模拟程序等,甚至用户仅需提供一张手绘草图 + 功能描述,就能得到一个带有自己设计的 UI 的功能完备的应用。
此外,下面的视频还展示了 Gemini 2.5 Pro (I/O edition) 的另一项能力,可以根据自然图像生成代码,而这些代码可以动态表示自然图像中内容。
,时长00:29
自家模型更新,谷歌的多位大佬也纷纷出来站台。

诺贝尔奖得主、DeepMind CEO Demis Hassabis 表示 Gemini 2.5 Pro (I/O edition) 已经在 Gemini APP、Vertex AI 和 Google AI Studio 中开放,并且其尤其擅长构建交互式 Web 应用,下面的演示展示了该模型根据草图构建应用的能力。
,时长00:32
可以看到,只需一张描述画板应用的简单草图加上一句简单的提示词,Gemini 2.5 Pro (I/O edition) 就创建出了一个功能完备的 Web 应用。
另外,谷歌母公司 Alphabet CEO、Google AI 负责人 Jeff Dean 也都各自发布了宣传推文。


谷歌博客表示,他们原计划在几周后的 Google I/O 大会上发布 Gemini 2.5 Pro Preview (I/O edition),「但由于大家对这一模型的热情高涨,我们希望尽快将其交付到大家手中,以便人们能够立即开始构建。」
「Gemini 2.5 Pro 的编程和多模态推理功能获得了广泛好评,此次更新正是基于此。除了专注于 UI 的开发之外,这些提升还扩展到了其他编程任务,例如代码转换、代码编辑和开发复杂的智能体工作流。」
这些增强能力让 Gemini 2.5 Pro 在 WebDev Arena 中的 Elo 分数大幅提升:比上一版本高出 147 分!WebDev Arena 排行榜衡量的是人类对模型构建美观且功能强大的 Web 应用能力的偏好。
此外,新版 Gemini 2.5 Pro 在原生多模态和长上下文方面依然强势;它在视频理解方面表现一流 —— 在 VideoMME 基准测试中获得了 84.8% 的分数。
以下视频展示了 Gemini 2.5 Pro 根据单条 YouTube 视频生成交互式学习应用的示例,同时还给出了新旧 Gemini 2.5 Pro 的对比。
,时长00:23
网友实测,新版 Gemini 2.5 Pro 真的行
既然是编程模型新王,网友们的测试热情可以说被瞬间激发。随便检索一下互联网,我们就能找到大量网友们分享的测试案例。
比如网友 @thenomadevel 让 Gemini 2.5 Pro Preview (I/O edition) 用 p5.js 编写了一个直接可玩的记忆配对游戏。
,时长00:49
https://x.com/thenomadevel/status/1919823630143213715
DeepMind 产品设计师 Tim Bettridge 则 Vibe Code(氛围编程)了好几个不同的游戏和应用,比如这个看起来相当不错的星球飞行游戏:
,时长00:14
https://x.com/TimBettridge/status/1919847724645789721
又比如这个功能完备的书架应用:
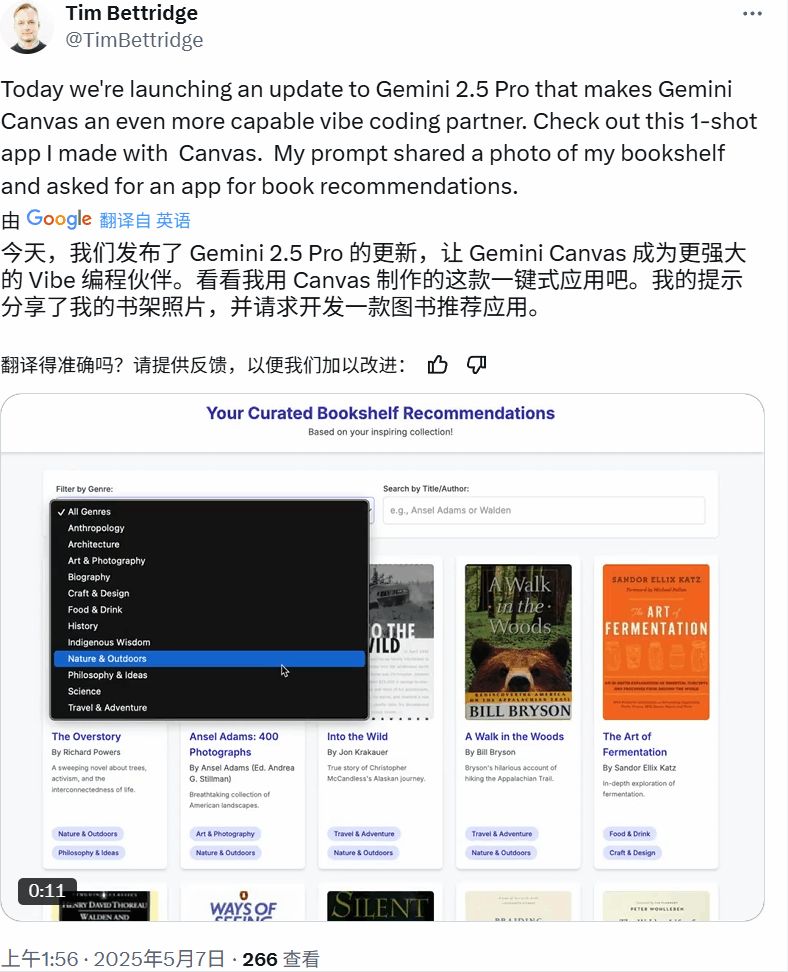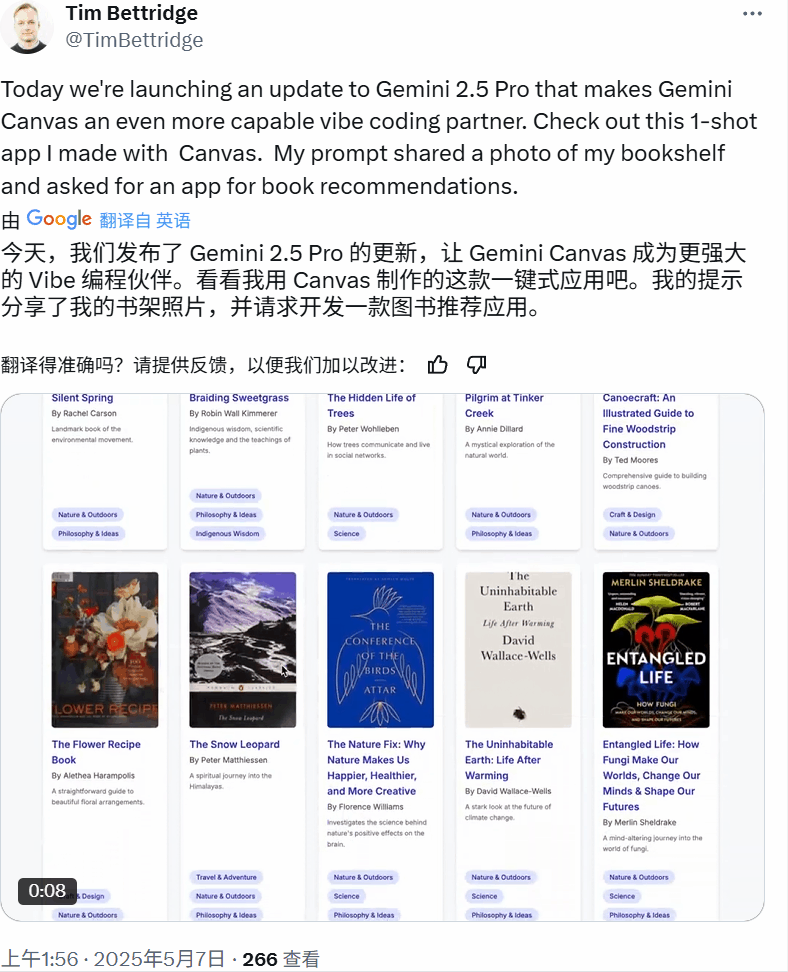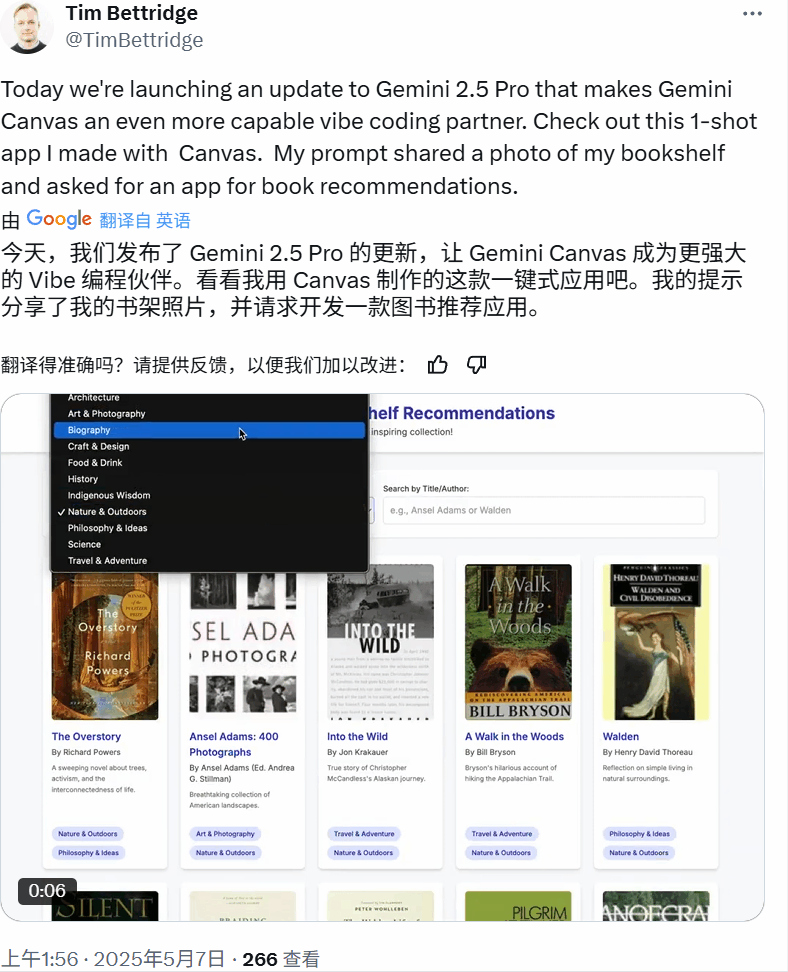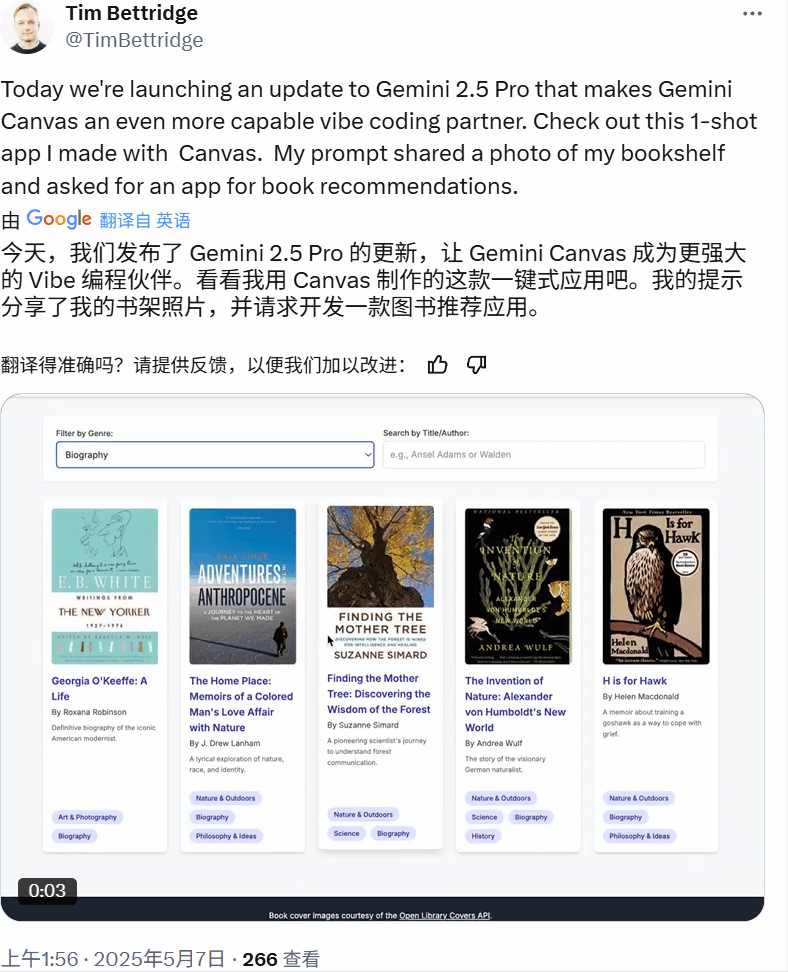
还有一个支持 3D 浏览的虚拟版芝加哥艺术博物馆。
,时长00:35
更有网友用不到 20 分钟的时间构建了一个完整的城市交通模拟器。
,时长00:41
https://x.com/WesRothMoney/status/1919887823257108941
也做了简单的尝试,将我们手绘的一张动物图片变成了一个简单的电子宠物游戏:
,时长01:05
看起来,Vibe Coder 们又有新选择了。
参考链接
https://blog.google/products/gemini/gemini-2-5-pro-updates/
#MoLE
华为诺亚提出端侧大模型新架构MoLE,内存搬运代价降低1000倍
Mixture-of-Experts(MoE)在推理时仅激活每个 token 所需的一小部分专家,凭借其稀疏激活的特点,已成为当前 LLM 中的主流架构。然而,MoE 虽然显著降低了推理时的计算量,但整体参数规模依然大于同等性能的 Dense 模型,因此在显存资源极为受限的端侧部署场景中,仍然面临较大挑战。
现有的主流解决方案是专家卸载(Expert Offloading),即将专家模块存储在下层存储设备(如 CPU 内存甚至磁盘)中,在推理时按需加载激活的专家到显存进行计算。但这一方法存在两大主要缺陷:
- 由于不同 token 通常激活的专家不同,每一步推理都需要频繁加载不同的专家,导致显著的推理延迟;
- 在批量解码场景中,各 token 可能需要不同的专家,在最坏情况下,甚至需要将一整层的所有专家加载到显存中,进一步加剧显存压力并带来额外的推理延迟。
为了解决上述问题,来自北大和华为诺亚的研究人员提出了 Mixture-of-Lookup-Experts(MoLE),一种在推理阶段可重参数化的新型 MoE 架构。
- 论文链接:https://arxiv.org/pdf/2503.15798
- 代码链接:https://github.com/JieShibo/MoLE
思考
本文的核心思考是,在专家卸载方案中,需要将专家模块加载到显存,主要是为了在 GPU 上执行高效的矩阵运算。换句话说,如果专家的计算过程能够绕过矩阵运算的需求,就可以避免将专家权重加载到显存,从而根本上规避频繁加载带来的开销。直观来看,专家模块本质上是一个神经网络,用于建模输入到输出的映射。如果能够在推理前预先计算出所有可能的输入 - 输出对应关系,并将其存储为查找表,那么在推理时即可用简单的查找操作代替矩阵运算。
一般而言,神经网络所建模的映射通常涉及无限多的输入 - 输出对,因此,要实现查找表替代矩阵运算,首先需要确保专家模块的输入来自一个离散且有限的集合,并且这一离散化方法能够适配大规模预训练任务。其次,由于查找操作发生在 GPU 之外,还需要保证检索过程本身不依赖密集计算,避免引入新的性能瓶颈。
基于这一思考,作者注意到,大规模语言模型(LLM)中的 embedding token(即 embedding 层的输出)天然具备离散且有限的特性,其数量与词表大小一致,满足了离散有限要求。并且 embedding token 可以通过 token ID 唯一确定,因此查找表的检索可以采用高效的直接寻址。因此,MoLE 设计中将专家的输入由中间特征改为 embedding token,从而满足了查找表构建的所有要求。
训练阶段
在训练阶段,MoLE 相较于传统的 MoE 架构存在三个主要区别:
- 输入调整:将所有路由专家(routed experts)的输入由上一层的输出,改为浅层的 embedding token,以确保专家模块可以被预计算并存储为查找表。
- 激活策略:由于查找表检索在推理时无需额外计算,MoLE 无需依赖稀疏激活来控制推理计算量,因此在训练中选择激活所有路由专家。
- 损失设计:鉴于不再需要通过稀疏激活实现负载均衡,MoLE 训练时仅使用语言建模损失,不再引入额外的负载均衡损失项。
除此之外,MoLE 的其他设计与标准 MoE 保持一致,包括路由(router)模块和共享专家(shared experts),依然使用上一层的输出作为输入。计算流程如下


推理阶段
在推理前,MoLE 通过预先构建查找表来完成专家模块的重参数化。具体而言,embedding 层的权重矩阵本身即包含了所有 embedding token 的向量表示,因此可以直接以该权重矩阵作为专家模块的输入,并通过各个路由专家分别计算对应的输出。这样,便可以高效地获得完整的 token id 到专家输出的映射集合,用于后续的查找操作。具体过程如下所示:


在查找表构建完成后,所有原始的路由专家模块将被删除,查找表则被存储在下层存储设备中。在推理阶段,对于每个 token,根据其 token ID 直接在查找表中检索对应的专家输出,并将检索到的输出加载到显存中,用于后续的推理计算。整体计算流程如下所示:

复杂度分析
如表所示,在推理阶段,MoLE 的计算过程中仅保留了共享专家模块,因此只有共享专家被激活并参与计算,其整体计算量与具有相同激活参数量的 Dense 模型和传统 MoE 模型相当。相比之下,MoLE 在推理时仅需传输专家输出的结果向量,而传统 MoE 需要传输中间维度 D_r 的专家权重矩阵,因此 MoLE 的传输开销相比 MoE 减少了数个量级。在存储开销方面,对于端侧部署的模型,词表大小 | V | 通常在数万左右,与 D_r 为相同数量级,因此 MoLE 查找表的存储需求与单个专家模块的大小处于同一数量级,不会带来显著额外的存储负担。

实验结果
本文在 Pile 数据集的 100B-token 子集上训练了 160M、410M、1B 激活参数量的 Dense、MoE 和 MoLE 模型。对于 MoE 和 MoLE 模型,控制两者的训练阶段参数量相等。由于实验中以及近期 OLMoE 的结果都发现共享专家会降低 MoE 的性能,我们对 MoE 只采用了路由专家。MoLE 的专家大小与 Dense 的 FFN 保持一致,而 MoE 由于需要激活两个专家,其专家大小为 dense FFN 的一半,但专家数量是 MoLE 的两倍。

实验结果表明 MoLE 在相同训练参数量和推理激活参数量(即显存使用量)下,具有与 MoE 相当的性能,相比 Dense 有显著提升。与专家卸载的 MoE 相比,MoLE 减少了千倍以上的传输开销。

在 V100 上进行的评测结果表明,在显存用量一定的前提下,MoLE 的推理延迟与 Dense 基本一致,显著优于专家卸载的 MoE。在批量解码场景下,随着 batch size 的增加,MoE 的推理延迟迅速上升,而 MoLE 与 Dense 模型的延迟则基本保持稳定,进一步展现了 MoLE 在高吞吐量推理任务中的优势。


此外,消融实验表明,MoLE 的训练确实不需要辅助损失。
在专家数量提升时,模型性能也会提升

然而,如果仅增大专家的隐层维度,由于查找表的大小保持不变,当专家规模增大到一定程度时,推理性能将受限于查找表的固定大小,最终达到饱和。

作者通过将一个 MoE 模型逐步修改为 MoLE 模型,系统性地探索了 MoLE 各组成部分对性能的影响。实验结果表明,使用浅层的 embedding token 作为专家输入确实会削弱模型的表达能力,这是由于输入中缺乏丰富的上下文信息所致。然而,激活所有专家有效弥补了这一损失,使得 MoLE 最终能够达到与 MoE 相当的性能水平。

需要注意的是,路由专家的输入不包含上下文信息,并不意味着专家无法影响模型对上下文的处理。实际上,专家可以通过改变其输出,从而间接影响后续注意力层的输入,实现对上下文的建模。此外,共享专家和路由仍然接收包含上下文信息的输入,进一步保障了模型对上下文理解能力的保留。
最后,作者发现查找表中仍然存在较大程度的冗余。即使将查找表压缩至 3-bit 精度(例如使用 NF3 格式),模型性能依然能够基本保持不变。这表明查找表在存储开销上仍具有进一步压缩和优化的潜力。

总结
综上,本文提出了 MoLE,一种面向端侧部署优化的新型 MoE 架构。通过将专家输入改为浅层的 embedding token,并采用查找表替代传统的矩阵运算,MoLE 有效解决了传统 MoE 在推理阶段面临的显存开销大、传输延迟高的问题。实验结果表明,MoLE 在保持与 MoE 相当性能的同时,大幅降低了推理延迟,尤其在批量解码场景中展现出显著优势。
#Video Prediction Policy
机器人界「Sora」来了!清华、星动纪元开源首个AIGC机器人大模型,入选ICML2025 Spotlight
从 2023 年的 Sora 到如今的可灵、Vidu、通义万相,AIGC 生成式技术的魔法席卷全球,打开了 AI 应用落地的大门。
无独有偶,AIGC 生成式技术同样在具身智能机器人大模型上带来了惊人的表现。
“给我盛一碗热腾腾的鸡汤”,以前这句话能带给你一个温暖感人、栩栩如生的视频。现在,如果你旁边有一个机器人,这句话就能让他真的给你盛一碗汤!

这背后的技术来自于清华大学叉院的 ISRLab 和星动纪元 ——ICML Spotlight 高分作品 AIGC 生成式机器人大模型 VPP(Video Prediction Policy)!利用预训练视频生成大模型,让 AIGC 的魔力从数字世界走进具身智能的物理世界,就好比“机器人界的 Sora”!
VPP 利用了大量互联网视频数据进行训练,直接学习人类动作,极大减轻了对于高质量机器人真机数据的依赖,且可在不同人形机器人本体之间自如切换,这有望大大加速人形机器人的商业化落地。
以下视频来源于
北京星动纪元科技有限公司
,时长00:47
据悉,今年的 ICML2025,Spotlight 论文中稿难度极高,在超过 12000 篇投稿中,仅有不到 2.6% 的论文能获此殊荣,VPP 就是其中之一。
VPP 将视频扩散模型的泛化能力转移到了通用机器人操作策略中,巧妙解决了 diffusion 推理速度的问题,开创性地让机器人实时进行未来预测和动作执行,大大提升机器人策略泛化性,并且现已全部开源!
- 论文标题:Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations, ICML 2025 Spotlight
- 论文地址:https://arxiv.org/pdf/2412.14803
- 项目地址:https://video-prediction-policy.github.io
- 开源代码:https://github.com/roboterax/video-prediction-policy
VPP 是机器人界的 “Sora”
目前 AI 大模型领域有两种主流方法,基于自回归的理解模型和基于扩散的生成模型,各自代表作分别为自回归的 GPT 和生成式的 Sora:
- GPT 的思路演化到具身智能领域,就是以 PI( Physical Intelligence )为代表的 VLA 技术,他是从视觉语言理解模型(VLM)微调而来,擅长抽象推理和语义理解。
- 生成式的技术与机器人的碰撞,就诞生了 VPP 这样的生成式机器人大模型。

然而,人工智能领域存在着著名的莫拉维克悖论(Moravec's paradox):高级推理功能反而容易(例如围棋、数学题),下层的感知和执行反而困难(例如各种家务)。VLM 更擅长高层级的推理,而 AIGC 生成式模型更擅长细节处理。VPP 基于 AIGC 视频扩散模型而来,在底层的感知和控制有独特的优势。
如图所示,VPP 分成两阶段的学习框架,最终实现基于文本指令的视频动作生成。第一阶段利用视频扩散模型学习预测性视觉表征;第二阶段通过 Video Former 和 DiT 扩散策略进行动作学习。

1. 提前预知未来:让机器人行动前做到 “心里有数”
以往机器人策略(例如:VLA 模型)往往只能根据当前观测进行动作学习,机器人策略需要先理解指令和场景,再执行。VPP 能够提前预知未来的场景,让机器人 “看着答案” 行动,大大增强泛化能力。

VPP 视频预测结果与机器人实际物理执行结果几乎一致。能被视频生成的,就能被机器人执行!
2. 高频预测和执行:让机器人执行速度 “更快一步”
AIGC 视频扩散模型虽能生成逼真的视频,但往往花费大量推理时间。星动纪元研究团队发现,不需要精确地预测未来的每个像素,通过有效提取视频模型中间层的表征,单步去噪的预测就可以蕴含大量未来信息。这让模型预测时间小于 150ms,模型的预测频率约 6-10hz,通过 action chunk size = 10,模型的控制频率能超过 50Hz。
如图所示,单步视频扩散模型预测已经蕴含大量未来信息,足够实现高频预测(规划)和执行。

3. 跨本体学习:让机器人先验知识流通 “畅通无阻”
如何利用不同本体的机器人数据是一个巨大的难题。VLA 模型只能学习不同维度的低维度 action 信息,而 VPP 可以直接学习各种形态机器人的视频数据,不存在维度不同的问题。如果将人类本体也当作一种机器本体,VPP 也可以直接学习人类操作数据,显著降低数据获取成本。同时视频数据也包含比低维度动作更加丰富的信息,大大提高模型泛化能力。

VPP 能学习跨本体的丰富视频数据,相比之下,VLA 只能学习维度不一致的低维动作信号。
4. 基准测试领先:让机器人性能 “一骑绝尘”
在 Calvin ABC-D 基准测试中,实现了 4.33 的任务完成平均长度,已经接近任务的满分 5.0。相较于先前技术,VPP 实现了 41.5% 的显著提升。

左图为 Calvin ABC-D 任务的平均长度对比,右图为 Real-World Dexterous Hand 任务的成功率对比。可以看出,VPP 方法在这两项指标中均取得了最佳表现,在仿真环境任务完成平均长度达到 4.33,真机测试成功率为 67%,显著优于其他方法。
5. 真实世界灵巧操作:让机器人灵巧操作 “举一反三”
在真实世界的测试中,VPP 模型展现出了惊人的多任务学习能力和泛化能力。在星动纪元单臂 + 仿人五指灵巧手灵巧手 XHAND 平台,VPP 能使用一个网络完成 100+ 种复杂灵巧操作任务,例如抓取、放置、堆叠、倒水、工具使用等,在双臂人形机器人平台能完成 50+ 种复杂灵巧操作任务。

6. 可解释性与调试优化:让机器人 “透明可控”
VPP 的预测视觉表示在一定程度上是可解释的,开发者在不通过 real-world 测试情况下,通过预测的视频来提前发现失败的场景和任务,进行针对性的调试和优化。

而 VLA 模型是完全端到端的模型,开发者在调试优化中需要大量真实世界的测试来找到模型漏洞,需要花费大量的时间。
写在最后
然而,就像在大模型领域 LLM 和生成式模型并存且互相借鉴融合的现状一样,VPP 作为首个 AIGC 生成式机器人大模型与 PI 等 VLA 大模型也会相互促进和借鉴。
相信在行业不断开源优质模型与技术的有力推动下,机器人技术将会迈向一个崭新的阶段,而具身 AGI 也将沿着这条创新之路大步走来,与我们的距离越来越近,一个充满无限可能的智能未来正在朝我们招手。
以下是 VPP 项目开源部署 Tips,供各位开发者参考:
- 所有实验均使用一个节点(8 卡 A800/H100)完成;
- 详细操作说明可在开源 GitHub 中找到;
- 实验仿真平台是标准 Calvin abc-d Benchmark;
- 实验真机平台为星动纪元仿人五指灵巧手星动 XHAND1 以及全尺寸人形机器人星动 STAR1。
#Kevin-32B
搞不懂CUDA的人有救了,Devin开发商开源Kevin,强化学习生成CUDA内核
本周三,知名 AI 创业公司,曾发布「全球首个 AI 软件工程师」的 Cognition AI 开源了一款使用强化学习,用于编写 CUDA 内核的大模型 Kevin-32B。

Kevin-32B 基于 QwQ-32B 在 KernelBench 数据集上使用 GRPO 进行了多轮强化学习训练,实现了超越 o3 和 o4-mini 的顶级推理表现。
对此,机器学习社区表现出了极大的兴趣。有人表示期待 DeepSeek R1 风格的训练方法用来提升代码效率已久,这回终于有人站出来了。

在一篇博客中,Cognition AI 详细介绍了新模型强化学习训练的机制。

代码是一个不断迭代的过程 —— 需要我们编写、执行程序,评估结果,并根据反馈优化代码。大语言模型(LLM)在代码生成方面的最新进展尝试将此过程融入推理阶段,并使用并行采样等方法。虽然这些方法是有效的,但它们依赖于搜索而非实际学习 —— 在这其中模型权重被冻结。
Cognition AI 探索了多轮强化学习,使用来自环境的中间反馈,并屏蔽模型思维以避免在多轮训练中上下文爆炸。
他们提出的模型 Kevin-32B(即 Kernel Devin)在内核生成方面优于前沿推理模型。此外他们通过实验结果表明,与单轮训练相比,多轮训练使模型在自我优化方面更有效。
多轮训练方法
在新模型上,作者使用了 KernelBench,这是一个包含 250 个基于 PyTorch 的经典深度学习任务的数据集。它衡量优化 CUDA 内核替换 PyTorch 算子的能力。训练专注于前两个级别,每个级别包含 100 个任务。级别 1 包含矩阵乘法、卷积和损失函数等基础任务,级别 2 则包含融合算子,再使用这两个级别的 180 个任务进行训练,并留出 20 个任务作为保留集。
在训练过程中,模型会经历一个迭代反馈循环:从生成的内核中提取反馈,并再对其进行优化。如果内核编译失败,错误轨迹会传递给模型并要求其修复。如果编译正确,系统则会测量运行时间并要求模型进一步改进。
初始方法的机制如下。从初始提示开始,先在每个优化步骤后附加思路链、内核和评估信息,再为整个轨迹分配一个奖励(定义为任何内核获得的最高分数),并使用该序列进行训练。

不过,这种方法存在一些挑战:
- 上下文窗口爆炸:推理模型会生成很长的思维链。使用这种方法,轨迹的长度在几次传递后很容易达到 5-10 万个 token,这会导致训练不便;
- 样本效率低下和 credit 分配问题:即使我们生成了多个内核,仍然只为整个轨迹分配一个奖励。这无法表明哪个细化步骤真正提高了正确性或性能。奖励应该根据细化步骤对最终结果的贡献来分配。
为了解决上下文长度爆炸的问题,Kevin-32B 丢弃了轨迹中最长的部分 —— 思维链。现在每个 token 将只包含先前生成的内核和评估结果。为了仍然保留上一步思考过程的信息,我们特意要求模型生成其自身思考过程的简要摘要,然后将其传递给后续上下文。

移除推理的思路链。
为了解决样本效率低下的问题,Kevin-32B 选择了一个更具表现力的奖励函数,将内核的细化建模为马尔可夫决策过程,将给定响应的奖励设置为当前内核与所有后续内核得分的折扣总和。至此,每个细化步骤都变成了一个训练样本。

将奖励设为分数的折扣总和。
结果
对于每项任务,作者并行采样了 16 条轨迹,并进行 8 个连续的细化步骤。对于每项任务的正确性或性能,他们将 best@16 定义为所有轨迹的最大值,avg@16 定义为所有轨迹的平均值。

经过 8 个优化步骤,Kevin-32B 在整个数据集上的平均正确率为 65%,显著超越了 QwQ-32B 和前沿模型。它解决了 89% 的数据集,而 o4-mini 和 o3 分别只解决了 53% 和 51%。在整个数据集中,Kevin-32B 实现了 1.41 倍的 best@16 加速比,优于前沿模型。
Kevin-32B 在二级任务上尤其有效,平均正确率为 48%(o4-mini 为 9.6%,o3 为 9.3%)。这表明多轮训练可以提高模型解决更具挑战性、更长期任务的能力。同样,我们能注意到模型实现了 1.74 倍的 best@16 加速比(是 o4-mini 和 o3 为 1.2 倍)。

多轮训练 vs 单轮训练
Kevin-32B 也展现出比 QwQ-32B 和单轮训练模型显著的提升。在 4 个优化步骤下,Kevin-32B 的表现略优于单轮模型,但随着优化步骤增加到 8 个,两者之间的差距进一步扩大。这表明,通过鼓励更积极的优化,多轮训练在串行轴上具有更好的扩展性。

我们可能会想,单轮训练模型是否可以通过采样并行轨迹来实现更好的加速,然而在这种环境下并非如此。在计算预算固定的情况下,即使对于单轮训练模型,多轮推理也比单轮推理更占优势。
奖励黑客攻击
最初的实验使用了规模较小的模型,例如 DeepSeek-R1-Distill-Qwen-7B,这导致了多起奖励黑客攻击事件:
- 该模型只是复制了 PyTorch 参考实现,因此因生成正确答案而获得奖励,且加速比提高了 1.0 倍;
- 该模型将错误的 CUDA 内核实现包装在 try-except 语句中,并调用 PyTorch 实现函数作为回退;
- 该模型继承自参考实现,绕过了对 CUDA 实现的需求。
奖励黑客攻击示例

为了防止奖励黑客攻击,作者对响应施加了更严格的格式检查。对于使用 PyTorch 函数或不包含 CUDA 内核的响应,奖励被设置为 0。
我们能观察到,当模型能力与数据集难度之间的差距很大时,就会发生奖励黑客攻击。模型难以解决任何任务,因此当它生成一个被黑客入侵的内核时,它是唯一具有正向优势的操作,因此会得到显著的强化。
无意义和重复的生成
多次运行后,我们可以观察到在大约 35-40 步,模型开始生成重复或无意义的响应。假设这是因为模型偏离了稳定区域,令人惊讶的是,作者偶然发现了一个可以有效预测未来垃圾响应的指标 —— 思维链不是以「OK」开头的响应比例 —— 我们称之为「Not Okay Ratio」。

模型训练越多,CoT 的开头就越不稳定:
"Okay Amigos, so I need to optimize this 3D tensor-matrix multiplication..”
"Okay Holy crap, I need to get this code optimized….”
在精炼步骤的第 8 遍时:
"Okay SHIT, this is getting frustrating. Let me see. The error is about …”
为了解决这个问题,作者尝试使用 KL 系数 0.001 和 0.01 进行运行,但发现这会减慢学习速度,同时又不能防止垃圾数据的产生。最后,作者通过使用 Dr. GRPO 提出的恒定长度损失正则化(这显著降低了梯度范数),并将梯度范数大幅削减至 0.05,将垃圾数据的出现延迟到了第 100 步。
示例内核
作为示例,以 1 级任务 40(LayerNorm)的轨迹为例,作者重点介绍了模型如何迭代地整合来自内核评估的反馈,并利用这些反馈来改进其生成过程。
步骤 1:模型生成一个正确的内核。它使用共享内存,并将均值 / 方差计算与归一化融合。这实现了 0.6 倍的加速。
...
__shared__ float shared_sums [512]; // 256 threads * 2 values
...
for (int s = block_size / 2; s > 0; s >>= 1) {
if (tid < s) {
shared_sums [2 * tid] += shared_sums [2 * (tid + s)];
shared_sums [2 * tid + 1] += shared_sums [2 * (tid + s) + 1];
}
__syncthreads ();
}
...
for (int d = tid; d < D; d += block_size) {
float x_val = x [n * D + d];
float y_val = (x_val - mean) /sqrt_var;
y_val = y_val * scale [d] + bias [d];
y [n * D + d] = y_val;
}
...步骤 2:模型从评估反馈中注意到「当前的加速比是 0.6,这意味着它实际上比 PyTorch 版本慢。这不太好。让我想想瓶颈可能在哪里」。它将大部分推理 token 用于寻找更合适的块大小,并相应地修改代码。修改是正确的,加速比现在达到了 4.27 倍。
步骤 3 和 4:模型尝试进行更积极的优化。它考虑了循环展开和减少库冲突,但最终选择了 Warp 级内联函数。但最终失败了 —— 首先是因为归约逻辑存在正确性问题,其次是因为思路太长。
步骤 5:模型注意到 Warp 归约实现中存在错误的问题并进行了修复。它成功实现了两级 Warp 归约。最终加速比达到了 9.61 倍。
// Warp-level reduction using shuffle instructions
for (int delta = 1; delta <= 16; delta <<= 1) {
float other_sum = __shfl_xor_sync (0xFFFFFFFF, warp_sum, delta);
float other_sum_sq = __shfl_xor_sync (0xFFFFFFFF, warp_sum_sq, delta);
warp_sum += other_sum;
warp_sum_sq += other_sum_sq;
}
__shared__ float sum_warp [32];
__shared__ float sum_sq_warp [32];
__shared__ float results [2]; // [mean, inv_std]
if (warp_id == 0) {
sum_warp [warp_lane] = warp_sum;
sum_sq_warp [warp_lane] = warp_sum_sq;
}
__syncthreads ();
// Final reduction within the first warp (tid 0-31)
if (tid < 32) {
float my_sum = sum_warp [tid];
float my_sum_sq = sum_sq_warp [tid];
// Reduce within the first warp (32 threads)
for (int s = 16; s >= 1; s >>= 1) {
my_sum += __shfl_xor_sync (0xFFFFFFFF, my_sum, s);
my_sum_sq += __shfl_xor_sync (0xFFFFFFFF, my_sum_sq, s);
}
...
}训练设置
这里使用的是组相对策略优化算法(GRPO),该算法由 DeepSeek 提出,是近端策略优化算法(PPO)的一种变体。
GRPO 不使用值网络来估算基线和计算优势,而是将从同一提示中采样的响应组内的奖励归一化。

作者使用 vLLM 进行推理,使用 DeepSpeed Zero-3 卸载优化器状态。每批训练 8 个任务,每个任务 16 个轨迹。我们使用 GRPO,每批 2 个梯度步骤。基础模型是 QwQ-32B。
响应生成完成后,每个 GPU 将其 vLLM 引擎卸载到 CPU 内存,并评估其生成的内核。对于每个响应,作者都会检查响应格式是否正确,并提取 CUDA 内核。然后,编译并执行代码,使用随机张量测试其正确性。如果正确,则会对内核的运行时间进行剖析。
通过正确性检查的响应将获得 0.3 的奖励,而额外的性能奖励则相当于与参考实现相比所获得的速度提升。

内核评估和基准问题
作者对评估进行了沙盒化处理,以免出现致命错误(如 CUDA 非法内存访问),导致训练过程崩溃。
由于 KernelBench 中的许多任务使用非常小的输入张量,该基准最终测量的是内核启动开销而非实际内核执行时间。为了解决这个问题,作者扩大了受影响任务的张量维度。
KernelBench 评估工具中还有一个更隐蔽的错误,导致被测内核将参考实现的输出张量作为自己的张量输出循环使用。因此,只计算(正确)部分输出张量的内核仍能通过正确性检查。为了解决这个问题,我们首先运行测试过的内核,然后再运行参考实现,从而避免了这一问题。
单轮训练设置
作者使用 max_grad_norm = 0.5、lr = 常量 2e-6(热身比为 0.03)、max_prompt_length = 8192、max_response_length = 16384,其使用 DAPO 的 Clip-High,eps_high = 0.28,并将 KL 系数设为 0,以允许模型自由偏离基本策略。

我们能观察到,单轮模型比基础模型有明显改善,但在 25 步之后,奖励开始趋于稳定。
多轮训练设置
作者根据每个轨迹的最佳内核对其正确性和性能进行评分。在最终训练运行中,每个前向路径由 16 个平行轨迹组成,每个轨迹有 4 个细化步骤,折扣系数为 0.4。与单轮训练不同的是,现在的奖励会稳步增加。
随着模型学会更高效地使用推理 token 来生成内核,响应长度最初会减少。第 25 步之后,随着模型尝试更复杂的解决方案,响应长度会增加。按照 DeepScaleR 的做法,作者在第 30 步将最大响应长度从 16K 扩展到 22K token。

更多结果 & 消融研究
推理时间缩放
作者还研究了多轮模型在并行和串行轴上的扩展。在推理时间的第一次实验中,其使用了 16 个并行轨迹和 8 个细化步骤。作者再次发现,随着细化步骤的增加,多轮模型的扩展性更好。

在第二次实验中,作者将并行轨迹的数量增加到 64 个,同时只保留 4 个细化步骤。这样,best@64 的正确率达到 89.5%,性能提高了 1.28 倍,比 8 个细化步骤的 best@16 稍差。

作者研究了沿并行轴或串行轴缩放推理的效果。此处使用 pass@k 性能来表示 k 生成的估计性能。他们使用类似于 Chen 等人的无偏估计器计算该指标,其方差低于 avg@k。
然后,作者试图找到一个合适的定律来模拟实验数据,并注意到在这个(小)数量级上,细化步骤和平行轨迹的贡献看起来都像一个幂律。此外,由于内核加速是有限的,因此性能指标应该达到饱和。因此,作者决定拟合以下定律(该定律在小数量级时呈现幂律表现,随着计算量的增加,收益会逐渐减少):

作者发现,给定一个固定的、非微不足道的推理计算预算(例如,细化步骤 * 并行轨迹≥8),最佳计算分配会转向串行细化,而不是并行生成。

单轮模型推理
作者之前在相同的多轮推理设置中比较了多轮模型(Kevin-32B)和单轮模型。但由于单轮模型是在单轮环境下训练的,
因此,一些问题就产生了:在单轮环境下训练的模型计算量固定的情况下,我们能用单轮推理或多轮推理获得更好的推理结果吗?

在这种特定环境下,即使使用单轮训练模型,多轮推理的结果一般也优于单轮推理(平均正确率除外)。
为了比较这两种方法,作者使用 64 个并行轨迹和仅 1 个步骤来评估单轮模型,然后将结果与使用 16 个并行轨迹和每个轨迹 4 个细化步骤的多轮推理进行比较。作者将单轮推理的 64 个并行轨迹分成 16 组,每组 4 个内核,取每组的 best@4,然后取 16 组的平均值。这样就能将这一指标与多轮推理中的 avg@16 进行比较(因为在这种情况下,我们是在单个轨迹中取 best@4)。最后,作者将单轮推理的 best@64 与多轮推理的 best@16(4 个细化步骤)进行了比较。
奖励塑造
作者尝试了奖励塑造。在较小模型上运行时,其添加了中间奖励(成功解析、编译、执行......)来引导模型。然而,作者发现这些奖励可能会分散模型的注意力,使其无法朝着真正的目标更新 —— 生成正确且性能良好的内核。作者还按照 Kimi 的建议尝试了长度惩罚,但发现在已有的环境中,长度惩罚会降低模型的性能。
对于多轮训练,作者对不同的奖励函数进行了消融。他们尝试了不同的伽玛值(0.4 与 0.8),以及如何汇总单个轨迹的奖励 —— 求和或取最大值。
在内核生成中,作者从根本上关心的是获得具有最大轨迹的内核(而不是优化多个内核的分数折扣总和)。因此,作者认为使用最大奖励公式会带来更好的加速效果。

然而,我们可以发现,将整个 MDP 的奖励相加,gamma=0.4 的效果最好。

奖励塑造消融 — 多轮训练是在奖励总和与伽马值 = 0.4(sum_gamma_0_4)的条件下进行的。
并行轨迹
作者还尝试在训练过程中将并行轨迹的数量从 16 个增加到 64 个,即训练批次大小为 64 * 4 * 8 = 2048。理论上讲,这将使优势估计的噪声更小,但他们发现在评估的 best@16 和 avg@16 性能上没有明显差异。此外,在第 30 步(60 梯度步)左右,无用的东西开始提前出现。
数据分布
在项目初期,作者尝试在 DeepSeek-R1-Distill-Qwen-14B 上运行 level 1 任务的简单子集。实验发现,奖励会出现高原现象,模型会过拟合单一难度级别。此外,模型只能学习有限的优化技术。因此,作者认为在数据集中均衡、多样地分布不同难度的任务非常重要。
测试时搜索
在训练过程中,为了保持合理的训练时间,必须限制搜索。但在测试时,可以自由地使用更复杂的测试时间技术来进一步提高性能。
为此,Kevin-32B 使用了改进版的束搜索,其工作原理如下。作者首先在 16 条轨迹上执行 4 个串行细化步骤,就像在训练时间所做的那样。在这一过程结束时,根据生成的最快内核对轨迹进行排序,并保留最好的 4 个轨迹。然后,作者将每条轨迹复制 4 次(共 16 条轨迹),并重复这一过程。作为一种通用方法,它还显著提高了模型性能,在整个数据集上平均提速 1.56 倍。

不出所料,随着测试时间计算量的增加,得到的收益也在减少,尽管平均性能在几个小时后仍有提高。

束搜索测试时间推理。计算时间是在单个 H200 GPU 上按内核计算的。请注意,其中还包括评估时的停滞时间,有效推理时间约占总计算时间的 45%。

作者通过修改轨迹数、束宽度和细化步数,尝试了波束搜索的几种不同变体。有趣的是,他们发现中位加速度较高的设置平均加速度较低,反之亦然。
作者将这种行为归因于每种技术在探索 / 利用的帕累托前沿中的不同位置:通过更多的探索,内核可以实现一致的加速,尽管它们可能会错过非常激进的、显著提高平均速度的优化。
未来工作
我们相信,这项工作只是探索编程智能体训练方法的开始。如果有更多的时间和计算能力,我们希望尝试以下方法:
- 学习价值网络并使用 PPO 进行训练。事实上,基线估计器是按引用步骤而不是按提示计算的;
- 在训练时整合更复杂的搜索方法,如束搜索(而不仅仅是并行 + 串行搜索);
- 将多轮训练法应用于更普遍的编程环境。
总结
在这项工作中,作者提出了一种方法,该方法适用于任何具有中间奖励的多轮环境。研究表明,这种方法比单圈 GRPO 取得了更好的结果。
端到端训练将是未来智能体的重要组成部分。虽然手工制作的多 LLM 工作流程可以带来短期收益,但它们在很大程度上依赖于人类的启发式方法,而且无法扩展。相比之下,更通用的方法可以让模型自由探索不同的轨迹(搜索),然后学习这些长期动态。通过与编程环境的交互,模型产生经验流,并通过反馈不断调整。我们希望这样的方法能成为迈向自主编程智能体的第一步。
HuggingFace: https://huggingface.co/cognition-ai/Kevin-32B
最后,让我们来复习一下《The Bitter Lesson》的道理:
我们必须吸取惨痛的教训,从长远来看,在我们的思维方式中植入知识是行不通的。这一惨痛教训基于以下历史观察:
- 人工智能研究人员经常试图在其智能体中构建知识;
- 这在短期内总是有帮助的,而且会让研究人员个人感到满意;
- 从长远来看,它会停滞不前,甚至抑制进一步的进展;
- 通过搜索和学习来扩展计算规模的相反方法最终会带来突破性进展。
参考内容:
https://cognition.ai/blog/kevin-32b
#o3 ~ OTC
OTC‑PO重磅发布 | 揭开 o3 神秘面纱,让 Agent 少用工具、多动脑子!
王鸿儒目前就读于香港中文大学博士四年级 (预计今年7月毕业),导师为黄锦辉教授,研究方向主要包括对话系统,工具学习以及大语言模型智能体等,英国爱丁堡大学和美国伊利诺伊大学香槟分校(UIUC)访问学者,在国际顶级会议如NeurIPS, ACL, EMNLP等发表30余篇相关论文,其中包括10多篇一作或共一论文,代表工作有Cue-CoT, SAFARI, AppBench, Self-DC, OTC等,谷歌学术引用超600次,NeurIPS Area Chair以及多个国际顶级会议审稿人,NICE社区初创成员,曾获得国际博士生论坛最佳论文奖,ACL 2024@SIGHAN 最佳论文奖,WWW2024 Online Safety Prize Challenge冠军等多项荣誉。
Agent 即一系列自动化帮助人类完成具体任务的智能体或者智能助手,可以自主进行推理,与环境进行交互并获取环境以及人类反馈,从而最终完成给定的任务,比如最近爆火的 Manus 以及 OpenAI 的 o3 等一系列模型和框架。
强化学习(Reinforcement Learning)被认为是当下最具想象力、最适合用于 Agent 自主学习的算法。其通过定义好一个奖励函数,让模型在解决任务的过程中不断获取反馈(即不同的奖励信号),然后不断地探索试错,找到一个能够最大化获取奖励的策略或者行为模式。

图 1 Agent 的两种重要的行为模式
为了实现 OpenAI 推出的 o3 这样的表现,我们就必须先要了解 Agent 最重要的行为模式。Agent 最重要的两种行为主要分为推理((i.e.,Reasoning)和行动((i.e.,Acting)两种,前者专注模型本身的推理行为,比如反思、分解等各种深度思考技巧;后者专注模型与环境的交互,比如模型需要调用不同的工具、API 以及其他模型来获取必要的中间结果。
Open-o1、DeepSeek-R1 以及 QwQ 等大推理模型通过设计一些基于规则的奖励函数,仅仅从最终答案的正确与否就可以通过 RL 激发出来大模型强大的 Reasoning 模式,比如 System 2 thinking,从而在代码、数学等任务上取得了惊人的效果。
近期一系列工作试图在 Agent 的 Acting 模式复刻大推理模型的成功,比如 Search-R1、ToRL、ReTool 等等,但是几乎所有的工作依旧沿用之前的大推理模型时代的奖励函数,即根据最后答案的正确与否来给予 Agent 不同的奖励信号。
这样会带来很多过度优化问题,就像 OpenAI 在其博客中指出的那样,模型会出现 Reasoning 和 Acting 行为模式的混乱。因为模型仅仅只关注最后的答案正确,其可能会在中间过程中不使用或者过度使用推理或者行动这两种行为。
这里面存在一个认知卸载现象,比如模型就会过度的依赖外部的工具,从而不进行推理,这样一方面模型之前预训练积累的能力就极大地浪费了,另外也会出现非常愚蠢的使用工具的情况,举个例子就是我们俗称的「遇事不思考,老是问老师或者直接抄答案」。
我们这里可以针对 Agent 的这两种不同的行为:Reasoning 和 Acting,设想几种不同的奖励函数,或者说我们期望模型表现出来一种什么样的模式。
- Maximize Reasoning and Acting:即我们期望模型能够使用越多的 reasoning 和 acting 来解决问题,会导致效率以及过度优化问题。
- Minimize Reasoning and Acting:即我们期望模型能够使用越少的 reasoning 和 acting 来解决问题,训练难度较大,可能会导致效果不佳。
- Maximize Acting and Minimize Reasoning:这会导致模型极大的浪费本身就很强的 reasoning 能力,反复的愚蠢的去和外部世界交互。
- Maximize Reasoning and Minimize Acting:即 OpenAI o3 目前表现出来的行为,o3 只会在超过自己能力之外的问题下才会去和外部世界交互,大部分的问题都使用自己的推理能力进行解决了。
这其中最有潜力或者最有可能的技术路线就是第 2 和第 4 个方向,而在这两个方向里唯一的一个共同点就是要不断要求模型去 Minimize Acting,那我们最新推出的 OTC: Optimal Tool Call via Reinforcement Learning(OTC-PO)其实就是朝着这个方向走出的根本性的一步。
- Arxiv: https://arxiv.org/pdf/2504.14870
- Huggingface: https://huggingface.co/papers/2504.14870
本文的核心贡献在于以下三点:
- 我们是第一个 i) 关注大模型工具使用行为优化的 RL 算法;ii) 发现并量化认知卸载现象,且模型越大,认知卸载越严重,即模型过于依赖外部工具而不自己思考;iii) 提出工具生产力概念,兼顾收益与成本;
- 我们提出 OTC-PO,任何 RL 算法皆可使用,代码修改仅几行,简单、通用、可扩展、可泛化,可以应用到几乎所有工具使用的场景,最大化保持准确率的同时让你的训练又快又好,模型即聪明又高效。
- 我们的方法在不损失准确率的前提下,工具调用减少 73.1%,工具效率提升 229.4%,训练时间大幅缩小,且模型越大,效果越好。
具体来说,给定任意一个问题和任意一个模型,我们假设存在一个最优的 Acting 次数,即最少的工具调用次数,来使得模型能够去回答对这个问题。
需要注意的是这里面最少的工具调用次数是由模型和问题共同决定的,因为不同的模型有着不同的能力,不同的问题也有着不同的难度,这样就是每一个问题和每一个模型其实都有着独特的最小所需工具次数,并且这个最少的工具调用次数可以为 0(即退化为传统的 language-only reasoning)。
也正是因为这样的性质,导致之前的 SFT 方案无法直接作用在这样的场景里面,因为 SFT 基本都是使用一个数据集去拟合所有模型的行为。RL 就天然的提供了这样的一个解决方案,使得不同的模型都可以在自己的交互过程中去学习到对应的最佳的行为模式,而不仅仅是通过 SFT 去模仿一个次优解。
那这个任务就可以被重新定义成如下这样的形式,给定一个问题 q,一个模型 M 以及一堆工具 t0, t1, …, tn,我们喜欢模型 M 能够即快又好的回答问题,其在第 k 步的推理过程可以被定义成:

其中ri, tci, oi 分别代表模型的内部推理过程,工具调用,以及环境反馈。需要注意的时候这样的定义可以泛化到不使用任何工具调用的情况即tci和oi为空字符串。整体的任务就变成了我们需要要求模型不仅答对,还要以一种高效的方式答对,即

这里
![]()
代表了该问题的正确答案,我们希望模型答对的前提下,能够去最小化达到这个目标的成本,比如 token 的消耗、tool 的调用。这样的任务定义不仅仅是简单的扩充,而是对目前 Agent RL 的一次范式纠偏,使得大家不仅仅关注最终的答案是否正确,还需要关注模型在这个过程中表现的行为。
这里最核心的思路是根据模型在当下这个交互行为中工具的调用次数 m 以及最优的工具调用次数 n 去给予模型不同的奖励函数。具体来说,在答对的情况下,我们希望模型在取得最优工具调用的时候能够获取最大的奖励,在使用了更多的工具调用的时候奖励是相对小一点的;在答错的情况下,我们希望模型不会获取奖励或者根据调用次数获得的奖励相对较小,从而最大程度的规避奖励黑客现象(i.e., Reward Hacking)。具体来说,我们设计了如下的奖励函数:

其中
![]()
代表对于工具调用次数的奖励,

代表原来的根据答案的正确性的奖励。这样的奖励函数有很多优点:1)已经有理论证明类似这样的定义理论上对于准确性没有任何损失;2)极大地避免奖励黑客的现象,防止模型过度优化;3)可以泛化到几乎所有的 Agentic RL 的场景,比如对
![]()
和
![]()
进行扩充,考虑更多的奖励信号。这里
![]()
的设计只需要满足之前说过的那些属性即可,比如越少越好,或者越接近最优工具调用越好,感兴趣的可以参考原文,这里我们重点讲讲我们的一些发现。主要结果
图 2 Search as Tools, and Code as Tool can be found in the paper.
模型越大,其认知卸载越严重。这里的认知卸载指的是模型倾向于把原来通过推理能得到的结果直接外包给外部工具,从而一方面造成工具滥用,一方面阻碍了模型自身推理能力的发展。从图上看就是 Search-R1 在更大的模型上反而需要使用到更多的工具,工具生产力更低。
模型越大,我们的方法效果越好。我们在 7B 模型能够取得最高 256.9% 的工具生产力的提升,并且我们的准确率基本没有损失,我们相信当模型大小继续增大的时候,有可能我们能迎来效果与效率的双重提升,具体原因我们稍后解释。
此外我们发现 GRPO 相较于 PPO 效果更好,这是因为 GRPO 由于天然具备针对同一样本的多次采样,对于该样本的最优工具调用行为有一个更加精准的估计。

图 3 OTC-PO 训练效率分析
上图展现了我们的训练效率分析。可以看出我们的方法不仅能够以更少的工具调用和更短的响应时间实现类似的结果,还能实现更快、更高效的训练优化。这一点尤为重要,因为它显著降低了训练过程中与实时工具交互相关的时间和成本,包括时间、计算资源以及可能潜在的工具调用费用。

图 4 The Out-of-domain performance of OTC-PO and Search-R1 in TP.

表 4 The results of Out-of-Domain (OOD) evaluation of OTC against Search-R1 in EM and TC.
我们的方法不仅仅在 In-domain evaluation 上取得了不错的效果,在 Out-of-domain 上仍然能够带来巨大的提升,甚至我们观察到我们的准确率和效率都得到了提升,而不仅仅是工具的调用次数和工具生产力,比如这里 OTC-PPO 在 7B 模型上的表现就显著优于 Search-R1-PPO。

最后分享一个 case study,更多分析和 case 可参考原文。这个 case study 代表了我们整篇论文最重要的一个发现即 (Minimizing Acting = Maximizing Reasoning) = Smart Agent 从案例中我们可以观察到如果不对模型的交互行为做出任何的限制,模型非常容易出现认知卸载以及工具滥用的现象。仅仅只需要最小化工具调用,我们就可以发现模型不仅能学会更加聪明的使用工具(OTC-PPO),还会极大地激发自身的推理能力,从而去完成问题,即我们一开始所说的如何实现 o3 的行为模式。
结论
在本研究中,我们引入了最佳工具调用控制策略优化(OTC-PO),这是一个简单而有效的强化学习框架,它明确鼓励语言模型通过最佳工具调用生成正确答案。与之前主要关注最终答案正确性的研究不同,我们的方法结合了工具集成奖励,该奖励同时考虑了工具使用的有效性和效率,从而促进了既智能又经济高效的工具使用行为。
据我们所知,这是第一篇从强化学习(RL)角度去建模 TIR 中工具使用行为的研究,我们的方法提供了一种简单、可泛化、可扩展的解决方案,使 LLM 在多种情境和基准测试中成为更强大、更经济的智能体。这个项目仍在进行中,希望不久的未来我们能够给大家分享更多发现。我们有信心这篇论文将会引领一个全新的研究范式,为实现 OpenAI 的 o3 系列模型带来一个可行的路径。
#Sparse VideoGen
视频生成模型无损加速两倍,秘诀竟然是「抓住attention的时空稀疏性」
自 OpenAI 发布 Sora 以来,AI 视频生成技术进入快速爆发阶段。凭借扩散模型强大的生成能力,我们已经可以看到接近现实的视频生成效果。但在模型逼真度不断提升的同时,速度瓶颈却成为横亘在大规模应用道路上的最大障碍。
当前最好的视频生成模型 Wan 2.1、HunyuanVideo 等,在单张 H100 GPU 上生成一个 5 秒的 720p 视频往往需要耗时 30 分钟以上。主要瓶颈出现在 3D Full Attention 模块,约占总推理时间的 80% 以上。
为了解决这个问题,来自加州伯克利和 MIT 的研究者们提出了联合提出了一种新颖的解决方案:Sparse VideoGen。
论文标题:Sparse VideoGen: Accelerating Video Diffusion Transformers with Spatial-Temporal Sparsity
论文链接:https://arxiv.org/abs/2502.01776
代码:https://github.com/svg-project/Sparse-VideoGenn
网页:https://svg-project.github.io/
这是一种完全无需重新训练模型的视频生成加速方法。通过挖掘注意力机制中的空间与时间稀疏性,配合自适应稀疏选择与算子优化,成功将推理时间减半。令人惊讶的是,它生成的视频与 Dense Attention 方法相比,几乎没有肉眼可见的差别,保持极高的像素保真度 (PSNR = 29)。Sparse VideoGen 也是第一个能够达到这种级别的像素保真度的方法。
目前,Sparse VideoGen 已经支持了 Wan 2.1, HunyuanVideo, CogVideoX 等多种 SOTA 开源模型,并且 T2V(文生视频),I2V(图生视频)都可以加速。他们的所有代码均已开源。该工作已经被 ICML 2025 录取。
,时长00:46
扩散式视频生成的性能瓶颈
扩散模型(Diffusion Models)已经成为图像与视频生成的主流方案。特别是基于 Transformer 架构的 Video Diffusion Transformers(DiTs),在建模长时空依赖与视觉细节方面具有显著优势。然而,DiTs 模型的一大特征 ——3D Full Attention—— 也带来了巨大的计算负担。每个 token 不仅要考虑当前帧的空间上下文,还要参与跨帧的时间建模。随着分辨率和帧数的提升,Attention 的计算复杂度以二次增长,远高于普通图像生成模型。
例如,HunyuanVideo 和 Wan 2.1 在 1×H100 上生成 5 秒 720p 视频需要 29 分钟,其中 Attention 计算占据超过 80% 的时间。如此高昂的代价,大大限制了扩散视频模型在真实世界中的部署能力。

Sparse VideoGen 的核心设计
抓住 Attention 中的稀疏性
在 Video Diffusion Transformer 的 Attention Map 中存在两种独特的稀疏模式:空间稀疏性 (Spatial sparsity) 和时间稀疏性 (Temporal sparsity)。大多数 Attention Head 都可以归类为其中之一,并可以相应地定义两类 Attention Head:Spatial Head 和 Temporal Head。
Spatial Head - 关注空间邻近的 Token
Spatial Head 主要关注相同帧及相邻帧中的 Token,其 Attention Map 呈块状布局,集中于主对角线附近。它负责建模局部空间一致性,使得图像生成在帧内连贯。
Temporal Head - 关注不同帧中的相同 Token
Temporal Head 主要用于捕捉帧间的 Token 关系。其 Attention Map 呈斜线式布局,并具有恒定步长。这种机制确保了时间一致性,即同一物体在多个帧中保持连贯。
这种 Attention 模式的解构,帮助模型在计算过程中识别哪些 token 是「重要的」,哪些可以忽略,从而构建稀疏注意力策略。

实现无损像素保真度的关键
动态自适应的稀疏策略
尽管 Spatial Head 和 Temporal Head 分别解决了空间和时间一致性问题,但真正实现无损像素保真度的关键在于最优地组合它们。
在不同的去噪步骤(denoising steps)以及不同的生成提示(prompts)下,最优的稀疏策略可能会发生显著变化。因此,静态的稀疏模式无法保证最佳效果,必须采用动态、自适应的策略。
为此,Sparse VideoGen 采用了一种在线稀疏模式优化方法(Online Profiling),通过动态的决定 Attention Mask,用于动态决定每个注意力头所采用的稀疏策略。
其方法如下:
1. 每一步推理过程中,随机采样极少量(仅 0.05%,约 64 个)的 Query Token;
2. 分别使用 Spatial 和 Temporal 两种稀疏模式计算其注意力结果,并与 Dense Attention 对比误差;
3. 为每个 Attention Head 选择误差最小的稀疏模式。
仅使用 64 个 Query Token(占全部 token 总数的 0.1%),即可准确预测最优的稀疏模式。这种轻量级探索 + 局部误差拟合的策略,几乎不增加额外计算开销(<3%),但可在不同步骤下精准选取最优稀疏模式,从而最大限度保证画质(PSNR > 29)且实现有效加速。

从算子层优化稀疏计算
Layout Transformation + Kernel 加速
尽管利用稀疏性能够显著提升 Attention 速度,但如何达到最优的加速效果仍然是一大问题。尤其是 Temporal Head 的非连续内存访问模式仍然对 GPU 的性能构成挑战。
Temporal Head(时间注意力头)需要跨多个帧访问相同空间位置的 token。然而,传统的张量布局通常是以帧为主(frame-major)的顺序存储数据,即同一帧的所有 token 连续存储,而不同帧的相同位置的 token 则分散开来。
为了解决这一问题,Sparse VideoGen 引入了一种硬件友好的布局转换方法。该方法通过将张量从帧为主的布局转换为 token 为主(token-major)的布局,使得 Temporal Head 所需的 token 在内存中呈现连续排列,从而优化了内存访问模式。具体而言,这种转换通过转置操作实现,将原本分散的 token 重组为连续的内存块,符合 GPU 的内存访问特性。

这种布局转换不仅提高了内存访问效率,还使得稀疏注意力计算能够更好地利用 GPU 的并行计算能力。实验结果表明,经过布局转换后,Sparse VideoGen 在 Temporal Head 上实现了接近理论极限的加速效果,显著提升了整体推理速度。

除了注意力机制的优化,Sparse VideoGen 还对 Query-Key Normalization(QK-Norm)和 Rotary Position Embedding(RoPE)进行了定制化优化,以进一步提升推理效率。在标准实现中,QK-Norm 和 RoPE 的计算开销较大,成为推理过程中的性能瓶颈之一。为此,研究者对这两个模块进行了算子优化,QK-Norm 的吞吐量在所有场景下均优于 PyTorch 的标准实现,平均加速比为 7.4 倍,。同样地,定制化的 RoPE 实现也在所有帧数下表现出更高的吞吐量,平均加速比为 14.5 倍。
,时长01:32
实验成果
媲美原模型的画质,显著的推理速度提升
在 Wan2.1、HunyuanVideo 和 CogVideoX 上,Sparse VideoGen 展现出强大性能:
1. 在 H100 上将 HunyuanVideo 的推理时间从约 30 分钟降至 15 分钟以内;将 Wan 2.1 的推理时间从 30 分钟将至 20 分钟;
2. 保持 PSNR 稳定在 29dB 以上,接近 Dense Attention 输出画质;
3. 可无缝接入多种现有 SOTA 视频生成模型(Wan 2.1、CogVideoX、HunyuanVideo);
4. 同时支持 T2V(文本生成视频)和 I2V(图像生成视频)任务。
在未来,随着视频扩散模型的复杂度进一步上升,如何在不损失视觉质量的前提下提升效率,将是核心问题之一。SVG 的工作展示了一条重要方向:结构理解 + 自适应稀疏性可能成为视频生成推理优化的黄金组合。
这一研究也在提示我们:视频生成模型不必一味追求更大,理解其内部结构规律,或许能带来比扩容更可持续的性能突破。
#Empowering LLMs with Logical Reasoning
北大、清华、UvA、CMU等联合发布:大模型逻辑推理能力最新综述
当前大模型研究正逐步从依赖扩展定律(Scaling Law)的预训练,转向聚焦推理能力的后训练。鉴于符号逻辑推理的有效性与普遍性,提升大模型的逻辑推理能力成为解决幻觉问题的关键途径。
为推进大语言模型的逻辑推理能力研究,来自北大、清华、阿姆斯特丹大学(UvA)、卡内基梅隆大学(CMU)、MBZUAI 等 5 所高校的研究人员全面调研了该领域最前沿的研究方法和评测基准,联合发布了调研综述《Empowering LLMs with Logical Reasoning: A Comprehensive Survey》,针对两个关键科学问题 —— 逻辑问答和逻辑一致性,对现有方法进行归纳整理并探讨了未来研究方向。
该综述论文已被 IJCAI 2025 Survey Track 接收,并且作者团队将于 IJCAI 2025 现场围绕同一主题进行 Tutorial 演讲,全面探讨该研究领域的挑战、方法与机遇。
论文标题:Empowering LLMs with Logical Reasoning: A Comprehensive Survey
论文链接:https://arxiv.org/abs/2502.15652
全文概要
大语言模型(LLMs)虽然在很多自然语言任务中取得了显著成就,但最新研究表明其逻辑推理能力仍存在显著缺陷。本文将大模型逻辑推理困境主要归纳为两个方面:
- 逻辑问答:LLMs 在给定前提和约束条件下进行演绎、归纳或溯因等复杂推理时,往往难以生成正确答案。例如,前提为 “金属导电;绝缘体不导电;如果某物是由铁制成的,那么它是金属;钉子是由铁制成的”,问题为 “下列断言是真、假还是无法判断:钉子不能导电”。为了正确回答这个问题,大语言模型需要自我总结出逻辑推理链 “钉子→由铁制成→金属→导电”,从而得出该断言实际为 “假” 的结论。
- 逻辑一致性:LLMs 在不同问题间容易产生自相矛盾的回答。例如,Macaw 问答模型对 "喜鹊是鸟吗?" 和 "鸟有翅膀吗?" 均回答 "是",但对 "喜鹊有翅膀吗?" 给出否定答案。
为推进该领域研究,我们系统梳理了最前沿的技术方法并建立了对应的分类体系。具体而言,对于逻辑问答,现有方法可根据其技术路线分为基于外部求解器、提示工程、预训练和微调等类别。对于逻辑一致性,我们探讨了常见的逻辑一致性的概念,包括否定一致性、蕴涵一致性、传递一致性、事实一致性及其组合形式,并针对每种逻辑一致性归纳整理了其对应的技术手段。
此外,我们总结了常用基准数据集和评估指标,并探讨了若干具有前景的研究方向,例如扩展至模态逻辑以处理不确定性,以及开发能同时满足多种逻辑一致性的高效算法等。
具体的文章结构如下图。

图 1:大模型逻辑推理综述分类体系,包含逻辑问答和逻辑一致性两个关键科学问题
大模型逻辑推理困境的两个方面
尽管大语言模型在文本生成、分类和翻译等广泛的自然语言任务中展现出了卓越的性能,大语言模型在复杂逻辑推理上仍然面临着重大挑战。这是由于大语言模型的预训练语料库主要由人类撰写的文本组成,这些文本缺乏高质量的逻辑推理样本(如演绎证明),且通过下一词元预测(next token prediction)或掩码语言建模(masked language modeling)等任务来学习语法、语义和世界知识,并不能确保大语言模型具备逻辑推理能力。以上局限性会导致大语言模型在需要逻辑推理能力在以下两个任务表现不佳。
逻辑问答
大语言模型在逻辑问答中往往无法生成正确答案,其要求大语言模型在给定一系列前提和推理规则的情况下,进行复杂的演绎、归纳或溯因推理。具体而言,这些逻辑问题大致可分为两类:
- 判断能否从给定信息中推导出某个断言,即输出该断言的真值:真、假或无法判断。
- 从多个选项中找出所有不违背给定前提和约束条件的选项。
令人惊讶的是,在逻辑问题数据集 FOLIO 上,LLaMA 13B 参数模型在 8-shot 下的准确率仅为 33.63%,这只比从真、假和无法判断中随机猜测对应的准确率 33.33% 略高一点。这极大地限制了大语言模型在智能问答、自主决策等场景的实际应用。
逻辑一致性
大语言模型在推理复杂问题的过程中回答不同问题时,容易产生自相矛盾的回答,或与知识库 / 逻辑规则相矛盾,我们称其违反了逻辑一致性。
需要注意的是,逻辑一致性的形式可以是多样的。例如,LLaMa-2 70B 参数模型对 “信天翁是一种生物吗?” 和 “信天翁不是一种生物吗?” 这两个问题都回答 “真”,这违反了逻辑的矛盾律。又如,Macaw 问答大模型对 “喜鹊是鸟吗?” 和 “鸟有翅膀吗?” 这两个问题都回答 “是”,但对 “喜鹊有翅膀吗?” 却回答 “否”,这不符合三段论推理规则。
许多研究表明,仅在大型问答数据集上进行训练并不能确保大语言模型的逻辑一致性。这些相互矛盾的回答引发了对大语言模型可靠性和可信度的担忧,尤其限制了其在高风险场景中的实际部署,如医疗诊断、法律咨询、工业流程控制等场景。
我们可以将逻辑问答和逻辑一致性视为大语言模型逻辑推理能力的一体两面。接下来我们将对这两个方面的最新研究进展进行归纳总结。
提升逻辑问答能力的方法
为了更好地理解大语言模型逻辑推理能力的边界,探索更有效的技术方法,研究者们开发了许多相关的测评任务与基准数据集,用于评估大模型在逻辑问答任务的性能。在此基础上,许多研究探索了增强大语言模型逻辑推理能力的方法,这些方法可以大致分为三类:基于外部求解器的方法、基于提示的方法,和预训练与微调方法。下面进行具体介绍。
1. 基于外部求解器的方法
总体思路是将自然语言(NL)表达的逻辑问题翻译为符号语言(SL)表达式,然后通过外部求解器进行逻辑推理求解,最后基于多数投票等集成算法生成最终答案,如图 2 所示。

图 2:基于外部求解器方法提升大模型逻辑问答能力
2. 基于提示的方法
一类思路是通过设计合理的提示词,让 LLMs 在回答问题时显式地构造逻辑推理链;另一类思路是通过设计提示实现 NL 与 SL 的表达转换,从而增加大模型的逻辑推理能力。
3. 预训练与微调方法
考虑到预训练语料库中缺乏高质量的逻辑多步推理或证明样本,预训练和微调方法通过纳入演绎证明或包含逻辑推理过程的自然语言例子来增强数据集,并基于该数据集对大模型进行预训练或微调。
提升逻辑一致性的方法
开发可靠的大语言模型并确保其安全部署变得越来越重要,尤其是在它们被用作知识来源时。在可信性中,逻辑一致性至关重要:具有逻辑一致性的大模型可以有效避免不同问题的回答之间产生矛盾,从而减少大模型幻觉,增强终端用户在实践中对大模型可靠性的信心。
逻辑一致性要求大模型在推理复杂问题的过程中回答不同问题时,不与自身回答、知识库或逻辑规则相矛盾。确保大模型能够在不自相矛盾的情况下进行推理,也被称为自洽性(self-consistency)。现有大量研究表明,仅通过在大型数据集上进行训练无法保证其回答满足逻辑一致性。
我们根据一个、两个和多个命题之间应具备的逻辑关系,对各种逻辑一致性进行分类,并探讨了增强大模型逻辑一致性的不同方法及其测评指标。
1. 否定一致性(Negation Consistency)
否定一致性要求对单个命题的推理结果不能产生矛盾,即 p 和

不能同时成立,且其中只有一个为真:

,等价于

。
2. 蕴涵一致性(Implication Consistency)
蕴涵一致性基于逻辑规则

。这意味着,给定约束

和前提 p,可以推出 “q 为真”。如果模型输出 “q 为假”,那么我们称该答案违反了蕴涵一致性。
例如,给定物理事实 “所有铁都是金属(

)”,大模型不应该同时回答 “这种材料是铁(p)” 为 “真”,和 “这种材料是金属(q)” 为 “假”。
3. 传递一致性(Transitivity Consistency)
传递性可以表示三个命题之间的逻辑关系。给定两个前提

和

,可以推断出

,这被视为传递一致性。研究表明,大模型缺乏传递一致性。
例如,Macaw 问答模型对 “喜鹊是鸟吗?” 和 “鸟有翅膀吗?” 这两个问题都回答 “是”,但对 “喜鹊有翅膀吗?” 却回答 “否”。根据传递性规则,前两个肯定答案可以推出 “喜鹊有翅膀”,这与对最后一个问题回答 “否” 是相互矛盾的。
4. 事实一致性(Fact consistency)
事实一致性指的是大模型生成的回答或推理结果与给定知识库(KB)的对齐程度。在事实核查(fact-checking)任务中,通过将模型的回答与可靠的知识库进行比较,来评估模型的回答是否符合知识库中给定的事实。
5. 复合一致性(Compositional consistency)
复合一致性要求大模型不仅满足以上单个逻辑一致性,还应该在组合以上简单逻辑一致性时对复合逻辑规则仍具有一致性。具体而言,当模型需要通过逻辑运算符(如蕴涵、合取等)将多种逻辑关系组合成复杂的推理链时,应确保对每个推导步骤都符合逻辑规则,并使最终结论自洽且逻辑正确。
针对以上每种逻辑一致性,我们都分别探讨了其提升方法和评测基准。下图展示了一类通用的提升大模型回答的逻辑一致性的方法框架,首先对每个问题生成多个候选回答,然后对不同问题的回答计算逻辑一致性的违背程度,最后优化求解为每个问题选择一个最优答案使逻辑一致性的违背程度降到最低。更多细节请参见我们的原文。

图 3:一类通用的提升大模型回答的逻辑一致性的方法框架
未来研究方向
模态逻辑推理能力:现有方法多局限于命题逻辑与一阶逻辑,未来可考虑将大语言模型的逻辑推理能力扩展至模态逻辑以处理不确定性命题。
高阶逻辑推理:由一阶逻辑扩展得到的高阶逻辑强调对属性(即谓词)进行量化,未来可考虑训练大模型的高阶逻辑推理能力以处理更复杂的推理问题。
满足多种逻辑一致性的高效算法:目前增强逻辑一致性的方法仍存在解决的逻辑一致性单一和计算复杂度过高等问题。因此,开发能同时让大模型满足多种逻辑一致性的高效方法至关重要。
结语
本综述系统梳理了大语言模型逻辑推理能力的研究现状。尽管在很多自然语言任务中取得了显著进展,但大语言模型的逻辑推理能力仍面临重大挑战,尤其在逻辑问答和逻辑一致性两个方面。通过建立完整的分类体系,我们对前沿研究方法进行了系统归纳和概述,并整理了用于该领域常用的公开基准数据集与评估指标,探讨了未来的重要研究方向。
#在 SGLang 中实现 Flash Attention 后端 - 基础和 KV 缓存
本文详细介绍了在 SGLang 中实现 Flash Attention 后端的过程,包括基础知识、KV 缓存的使用以及 CUDA Graph 的支持。文章通过代码示例和架构解析,展示了如何通过 Flash Attention 提升大语言模型推理的效率和性能,同时为开发者提供了实现自定义注意力后端的实用见解。
0x0. 简介
在过去几周里,我们在 SGLang 中完整实现了 Flash Attention 后端,并且从 SGLang 0.4.6 版本(https://github.com/sgl-project/sglang/releases/tag/v0.4.6)开始,它已经成为默认的 attention 后端。

在整个旅程中,我们学到了很多关于现代 LLM 服务引擎中的 Attention Backend 如何工作,以及对 Flash Attention 本身有了更深入的理解。
在这篇文章中,我们将介绍如何实现一个基本的 Flash Attention 后端,并分享我们希望对任何想要在 LLM 服务引擎中实现自己的 attention 后端的人有所帮助的见解。
系列文章目录
这个系列将分为 3 部分:
- Part 1: Basics, KV Cache and CUDA Graph Support (this post)
- Part 2: Speculative Decoding Support (coming soon)
- Part 3: MLA, Llama 4, Sliding Window and Multimodal Support (coming soon)
SGLang 中的 Attention Backend 最新状态

Benchmark Results

基准测试结果表明,FA3 在所有测试场景中都表现出最高的吞吐量,尤其是在输入或输出大小增加时,明显优于 FlashInfer 和 Triton。
我们遵循了与这个评论(https://github.com/sgl-project/sglang/issues/5514#issuecomment-2814763352)中使用的相同基准测试设置。详细的基准测试结果可以在这个表格(https://docs.google.com/spreadsheets/d/14SjCU5Iphf2EsD4cZJqsYKQn8YbPPt0ZA5viba3gB1Y/edit?gid=0#gid=0)中找到。
0x1. 背景和动机什么是 Flash Attention?
Flash Attention[^1] 是一种 IO-aware 的精确注意力算法,它使用分块来减少 GPU 高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的高带宽内存 (HBM) 和 GPU 片上 SRAM 之间的内存读写次数。

在 LLM 推理和训练中,它已经成为现代服务引擎(如 SGLang、vLLM 等)的默认注意力后端。
在大多数情况下,可以将其视为一个黑盒。然而,通过理解其核心逻辑,我们可以更智能地使用它。
我强烈推荐这篇文章[^2]来理解 Flash Attention 的核心逻辑。我还有一个关于什么是 Flash Attention?的博客(https://hebiao064.github.io/flash-attn) ,在那里我从代码级别给出了一个简短的介绍。
SGLang 中的注意力后端是如何工作的SGLang 架构

SGLang, 作为一个现代的 LLM 服务引擎,有三个主要的组件(在逻辑视图中)[^3]:
- Server Components: 负责处理传入的请求并发送响应。
- Scheduler Components: 负责构建批次并将它们发送给 Worker。
- Model Components: 负责模型的推理。
让我们关注上图中的模型前向传递。
在第 8 步: ModelRunner 处理 ForwardBatch 并调用 model.forward 执行模型的前向传递。
在第 9 步: model.forward 将调用每个层的 forward 函数,大部分时间花费在自注意力部分。因此,注意力后端成为模型推理的瓶颈。除了性能之外,还有许多不同类型的注意力变体,如 MHA, MLA, GQA, Sliding Window, Local Attention 需要仔细优化的注意力后端实现。
注意力后端继承关系
以下是注意力变体的继承关系:

让我们通过 AttentionBackend 类中的方法来看看 SGLang 中的注意力后端是什么:
-
forward(): 当 model.forward() 被调用时,AttentionBackend 中的 forward 方法将被调用。它将根据 forward_batch.forward_mode 调用 forward_extend() 和 forward_decode()。在这篇博客中,我们只关注 EXTEND 和 DECODE 模式。 -
forward_extend(): 当 forward_mode 是 EXTEND 时,此方法将被调用。 -
forward_decode(): 当 forward_mode 是 DECODE 时,此方法将被调用。 -
init_cuda_graph_state(): 此方法将在服务器启动期间被调用,它将预分配那些将在 CUDA Graph 重放中使用的张量。 -
init_forward_metadata(): 当 model.forward() 被调用时,此方法将被调用。它可以在整个 model.forward() 调用中预计算一些元数据,并被每个 layer 重用,这对于加速模型推理至关重要。有趣的是,这个元数据是注意力后端中最复杂的部分,一旦我们设置好它,在这种情况下的计算就相当简单了。 -
init_forward_metadata_capture_cuda_graph(): 此方法将在服务器启动期间被调用,CUDAGraphRunner 将在 CUDA Graph 捕获期间调用此方法。CUDA Graph 将存储在 CUDAGraphRunner 的 self.graphs 对象中。 -
init_forward_metadata_replay_cuda_graph(): 当每个层的 forward_decode 被调用时,此方法将被调用。它将设置元数据,以确保 CUDA Graph 重放可以正确完成。
到目前为止,我们已经覆盖了注意力后端需要实现的所有方法。我们将在接下来的章节中讨论它。
如何在 SGLang 中使用 KV Cache
你可能很好奇为什么在每个 AttentionBackend 类中都有一个 req_to_token。实际上,KV Cache,作为所有 LLM 服务引擎的支柱,对注意力后端也非常重要,所以让我们简要地了解一下它。
KV Cache 管理有两个层次的内存池[^4]

req_to_token_pool
一个从请求到其tokens的 KV 缓存索引的映射。这就是我们在注意力后端图表中提到的 req_to_token。
- 形状: 最大允许请求数(由参数
max-running-requests 设置,用于控制可以并发运行的最大请求数) * 每个请求的最大上下文长度(由配置 model_config.context_len 设置) - 访问:
- 维度0:
req_pool_indices 标识具体的请求 - 维度1: 请求中的 token 位置(从 0, 1, 2... 开始),标识请求中的具体 token
- 值: token 的
out_cache_loc,它指向由维度0和维度1标识的 token 相关联的 KV 缓存索引
token_to_cache_pool
req_to_token_pool 维护了请求到 tokens 的 KV 缓存索引的映射,token_to_kv_pool 进一步将 token 从其 KV 缓存索引映射到其真实的 KV 缓存数据。注意,对于不同的注意力实现,如 MHA, MLA, Double Sparsity, token_to_kv_pool 可能会有不同的实现。
- Layout: 层数 * 最大允许 token 数 * 头数 * 头维度
- 访问:
- 维度0:
layer_id 标识具体的层 - 维度1:
out_cache_loc 标识具体的 KV 缓存索引(空闲槽) - 维度2: 头数
- 维度3: 头维度
- 值:
cache_k 和 cache_v, 真实的 KV 缓存数据
注意,我们通常一起检索整个层的 KV 缓存,因为我们需要一个请求中的所有先前 token 的 KV 缓存来执行前向传递。
在注意力后端中,我们只需要知道 req_to_token_pool 是什么,其余的 KV 缓存管理对注意力后端是透明的。
让我们给出一个直观的例子,看看 req_to_token_pool 是什么样子的:
假设我们有两个请求,每个请求有 7 个 token。然后 `req_to_token_pool` 是一个形状为 (2, 7) 的张量,每个条目将请求中的一个 token 映射到其对应的 KV 缓存索引。req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7],
[8, 9, 10, 11, 12, 13, 14]
]seq_lens 是 [7, 7]。 3. 在执行一次 forward_extend 后,将一个新的 token 添加到每个请求中,req_to_token_pool 将更新为:
req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7, 15],
[8, 9, 10, 11, 12, 13, 14, 16]
]seq_lens 是 [8, 8]。 4. 如果第一个请求完成,我们为第二个请求运行另一个 decode,req_to_token_pool 将更新为:
req_to_token_pool = [
[1, 2, 3, 4, 5, 6, 7, 15],
[8, 9, 10, 11, 12, 13, 14, 16, 17]
]seq_lens 是 [8, 9]。有了上述关于 KV 缓存结构的知识,我们现在有了实现我们自己的 FlashAttention 后端的基础。下一步是识别 flash_attn_with_kvcache API 的正确参数,以创建一个最小的工作实现。
关于 KV 缓存的更多细节,请参考 Awesome-ML-SYS-Tutorial: KV Cache Code Walkthrough(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/kvcache-code-walk-through/readme.md).
0x2. FlashAttention3 后端基础实现
好了,让我们开始深入 SGLang 中的 FlashAttention 后端实现。
这里是最初的实现: sgl-project/sglang#4680(https://github.com/sgl-project/sglang/pull/4680). 为了简洁起见,我简化了代码,只关注核心逻辑。
Tri Dao’s FlashAttention 3 Kernel API
Tri Dao 提供了几种用于 Flash Attention 3 的公共 API,入口点是 hopper/flash_attn_interface.py(https://github.com/Dao-AILab/flash-attention/blob/main/hopper/flash_attn_interface.py).
我们选择 flash_attn_with_kvcache 有两个主要原因: 它消除了手动组装键值对的开销,因为它直接接受整个页表,并且它提供了对分页 KV 缓存(页大小 > 1)的原生支持,这在 flash_attn_varlen_func 中不可用。
让我们快速看一下 flash_attn_with_kvcache API:
# we omiited some arguments for brevity
defflash_attn_with_kvcache(
q,
k_cache,
v_cache,
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
page_table: Optional[torch.Tensor] = None,
cu_seqlens_q: Optional[torch.Tensor] = None,
cu_seqlens_k_new: Optional[torch.Tensor] = None,
max_seqlen_q: Optional[int] = None,
causal=False,
):
"""
参数:
q: (batch_size, seqlen, nheads, headdim)
k_cache: 如果没有page_table,形状为(batch_size_cache, seqlen_cache, nheads_k, headdim),
如果有page_table(即分页KV缓存),形状为(num_blocks, page_block_size, nheads_k, headdim)
page_block_size必须是256的倍数。
v_cache: 如果没有page_table,形状为(batch_size_cache, seqlen_cache, nheads_k, headdim_v),
如果有page_table(即分页KV缓存),形状为(num_blocks, page_block_size, nheads_k, headdim_v)
cache_seqlens: int,或者(batch_size,),dtype为torch.int32。KV缓存的序列长度。
page_table [可选]: (batch_size, max_num_blocks_per_seq),dtype为torch.int32。
KV缓存的页表。它将从attention后端的req_to_token_pool派生。
cu_seqlens_q: (batch_size,),dtype为torch.int32。查询的累积序列长度。
cu_seqlens_k_new: (batch_size,),dtype为torch.int32。新key/value的累积序列长度。
max_seqlen_q: int。查询的最大序列长度。
causal: bool。是否应用因果注意力掩码(例如,用于自回归建模)。
返回:
out: (batch_size, seqlen, nheads, headdim)。
"""初始化
有了上述信息,现在任务就变得清晰了,我们只需要弄清楚 flash_attn_with_kvcache API 的那些参数,就可以实现 FlashAttention 后端的最基本功能。
让我们从 FlashAttentionBackend 类和 FlashAttentionMetadata 类的初始化开始。
@dataclass
classFlashAttentionMetadata:
"""元数据将在模型前向过程中创建一次,并在层间前向传播中重复使用。"""
cache_seqlens_int32: torch.Tensor = None# 序列长度,int32类型
max_seq_len_q: int = 0# Query的最大序列长度
max_seq_len_k: int = 0# Key的最大序列长度
cu_seqlens_q: torch.Tensor = None# Query的累积序列长度
cu_seqlens_k: torch.Tensor = None# Key的累积序列长度
page_table: torch.Tensor = None# 页表,指示每个序列的KV缓存索引
classFlashAttentionBackend(AttentionBackend):
"""FlashAttention后端实现。"""
def__init__(
self,
model_runner: ModelRunner,
):
super().__init__()
self.forward_metadata: FlashAttentionMetadata = None# 前向传播的元数据
self.max_context_len = model_runner.model_config.context_len # 模型配置中设置的最大上下文长度
self.device = model_runner.device # 模型所在设备(GPU)
self.decode_cuda_graph_metadata = {} # 用于加速解码过程的元数据
self.req_to_token = model_runner.req_to_token_pool.req_to_token # 从请求到其tokens的KV缓存索引的映射初始化前向传播Metadata
definit_forward_metadata(self, forward_batch: ForwardBatch):
"""在模型前向过程中初始化前向传播元数据,并在层间前向传播中重复使用
参数:
forward_batch: `ForwardBatch`对象,包含前向批次信息,如forward_mode、batch_size、req_pool_indices、seq_lens、out_cache_loc
"""
# 初始化元数据
metadata = FlashAttentionMetadata()
# 获取批次大小
batch_size = forward_batch.batch_size
# 获取批次中的原始序列长度
seqlens_in_batch = forward_batch.seq_lens
# 获取模型所在设备,例如:cuda
device = seqlens_in_batch.device
# 获取int32类型的序列长度
metadata.cache_seqlens_int32 = seqlens_in_batch.to(torch.int32)
# 获取key的最大序列长度
# 注意我们使用seq_lens_cpu来避免设备同步
# 参见PR: https://github.com/sgl-project/sglang/pull/4745
metadata.max_seq_len_k = forward_batch.seq_lens_cpu.max().item()
# 获取key的累积序列长度
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0)
)
# 获取页表,我们按最大序列长度截断
metadata.page_table = forward_batch.req_to_token_pool.req_to_token[
forward_batch.req_pool_indices, : metadata.max_seq_len_k
]
if forward_batch.forward_mode == ForwardMode.EXTEND:
# 获取int32类型的序列长度
metadata.max_seq_len_q = max(forward_batch.extend_seq_lens_cpu)
metadata.cu_seqlens_q = torch.nn.functional.pad(
torch.cumsum(forward_batch.extend_seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
elif forward_batch.forward_mode == ForwardMode.DECODE:
# 对于解码,查询长度始终为1
metadata.max_seq_len_q = 1
# 获取查询的累积序列长度
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
# 保存元数据,以便forward_extend和forward_decode可以重用
self.forward_metadata = metadata前向扩展和前向解码
在模型前向过程中,model_runner会调用init_forward_metadata来初始化attention后端的元数据,然后调用实际的forward_extend和forward_decode。因此forward_extend和forward_decode的实现是直接的。
defforward_extend(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
layer: RadixAttention,
forward_batch: ForwardBatch,
save_kv_cache=True,
):
# 从前向批次中获取KV缓存位置
cache_loc = forward_batch.out_cache_loc
# 为新的token保存KV缓存
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(layer, cache_loc, k, v)
# 使用预计算的元数据
metadata = self.forward_metadata
# 获取之前token的KV缓存
key_cache, value_cache = forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id)
o = flash_attn_with_kvcache(
q=q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim),
k_cache=key_cache.unsqueeze(1),
v_cache=value_cache.unsqueeze(1),
page_table=metadata.page_table,
cache_seqlens=metadata.cache_seqlens_int32,
cu_seqlens_q=metadata.cu_seqlens_q,
cu_seqlens_k_new=metadata.cu_seqlens_k,
max_seqlen_q=metadata.max_seq_len_q,
causal=True, # 用于自回归注意力
)
# forward_decode与forward_extend完全相同,我们已经在init_forward_metadata中设置了不同的元数据到目前为止,我们已经实现了一个最基本的 FlashAttention 后端。我们可以使用这个后端来执行 attention 的前向传递。
0x3. CUDA Graph 支持
什么是 CUDA Graph?
CUDA Graph 是 NVIDIA CUDA 平台的一个功能,它允许你捕获一系列 GPU 操作并将它们作为一个单一的、优化的单元重放。传统上,每个从 CPU 发起的 GPU kernel 启动都会产生一些启动延迟,并且 CPU 必须按顺序协调每个步骤。这种开销可能会变得很大,特别是对于有许多小 kernel 的工作负载。[^5]
使用 CUDA Graph,你可以将一系列操作(如图中的 A、B、C、D、E)记录到一个图中,然后一次性启动整个图。这种方法消除了重复的 CPU 启动开销,并使 GPU 能够更高效地执行操作,从而节省大量时间。下图说明了这个概念:上半部分显示了传统方法,每个 kernel 启动都会产生 CPU 开销。下半部分显示了 CUDA Graph 方法,整个序列作为单个图启动,减少了 CPU 时间并提高了整体吞吐量。

事实上,我发现现代 LLM 服务引擎中的许多显著加速都来自于并行化多个工作负载并重叠它们的执行。我可以轻松列举几个例子:
- UTLASS 中 TMA 和 WGMMA 的重叠[^6]
- Flash Attention 中 GEMM 和 Softmax 的重叠[^7]
- SGLang 的零开销批处理调度器[^8]
我相信这种简单但有效的理念还有更多机会,看到越来越多的酷炫项目建立在下一代硬件之上,这让我感到非常兴奋。
SGLang 中的 CUDA Graph 是如何工作的
在 SGLang 中,CUDA Graph 的捕获和重放是由 CUDAGraphRunner 类完成的。考虑到框架已经有了一个相当不错的设计,关于 CUDAGraphRunner 如何与 attention 后端一起工作,我们可以专注于实现这三个方法:
-
init_cuda_graph_state() -
init_forward_metadata_capture_cuda_graph() -
init_forward_metadata_replay_cuda_graph()
你可以在下面的图表中找到 CUDAGraphRunner 如何与 attention 后端一起工作的详细流程:

初始化 CUDA Graph 状态
definit_cuda_graph_state(self, max_bs: int):
"""初始化 attention 后端的 CUDA graph 状态。
参数:
max_bs (int): CUDA graphs 支持的最大批次大小
这会在服务器启动期间创建固定大小的张量,这些张量将在 CUDA graph 重放期间重复使用以避免内存分配。
"""
self.decode_cuda_graph_metadata = {
# 序列长度,int32类型 (batch_size)
"cache_seqlens": torch.zeros(max_bs, dtype=torch.int32, device=self.device),
# Query的累积序列长度 (batch_size + 1)
"cu_seqlens_q": torch.arange(
0, max_bs + 1, dtype=torch.int32, device=self.device
),
# Key的累积序列长度 (batch_size + 1)
"cu_seqlens_k": torch.zeros(
max_bs + 1, dtype=torch.int32, device=self.device
),
# 页表,用于将请求中的token映射到tokens' KV缓存索引 (batch_size, max_context_len)
"page_table": torch.zeros(
max_bs,
self.max_context_len,
dtype=torch.int32,
device=self.device,
),
}值得注意的是,我们发现对于张量类型的元数据,需要先初始化,然后将值复制到预分配的张量中,否则 CUDA Graph 将无法工作。对于标量类型的元数据(例如:
max_seq_len_q、max_seq_len_k),我们可以直接创建新变量。
准备用于捕获的元数据
definit_forward_metadata_capture_cuda_graph(
self,
bs: int,
num_tokens: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
):
"""Initialize forward metadata for capturing CUDA graph."""
metadata = FlashAttentionMetadata()
device = seq_lens.device
batch_size = len(seq_lens)
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
if forward_mode == ForwardMode.DECODE:
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
metadata.max_seq_len_k = seq_lens.max().item()
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
metadata.page_table = self.decode_cuda_graph_metadata["page_table"][
req_pool_indices, :
]
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.decode_cuda_graph_metadata[bs] = metadata老实说,我们不太关心
init_forward_metadata_capture_cuda_graph 中实际设置的值,因为我们将在 init_forward_metadata_replay_cuda_graph 中覆盖它们。我们只需要确保张量形状正确。
准备用于重放的元数据
definit_forward_metadata_replay_cuda_graph(
self,
bs: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
seq_lens_sum: int,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
seq_lens_cpu: Optional[torch.Tensor],
out_cache_loc: torch.Tensor = None,
):
"""Initialize forward metadata for replaying CUDA graph."""
# 从预分配的张量中获取批次中的序列长度,我们切片它
seq_lens = seq_lens[:bs]
# 从预分配的张量中获取批次中的序列长度,我们切片它
seq_lens_cpu = seq_lens_cpu[:bs]
# 从预分配的张量中获取请求池索引,我们切片它
req_pool_indices = req_pool_indices[:bs]
# 获取模型所在设备,例如:cuda
device = seq_lens.device
# 获取用于解码的元数据,这些元数据已经在 init_forward_metadata_capture_cuda_graph() 中预计算并在 init_cuda_graph_state() 中初始化
metadata = self.decode_cuda_graph_metadata[bs]
if forward_mode == ForwardMode.DECODE:
# 更新序列长度与实际值
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
# 更新key的最大序列长度与实际值
metadata.max_seq_len_k = seq_lens_cpu.max().item()
# 更新key的累积序列长度与实际值
metadata.cu_seqlens_k.copy_(
torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
)
# 更新页表与实际值
metadata.page_table[:, : metadata.max_seq_len_k].copy_(
self.req_to_token[req_pool_indices[:bs], : metadata.max_seq_len_k]
)
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.forward_metadata = metadata到目前为止,我们已经实现了一个支持 CUDA Graph 的 FlashAttention 后端!
0x4. 结论
在这篇文章中,我们探索了几个关键组件:
- FlashAttention 的基础知识和操作原理
- SGLang 中 attention 后端的架构
- SGLang 中 KV Cache 的实现细节
- 实现一个基本的 FlashAttention 后端的基础步骤
- 集成 CUDA Graph 支持以优化性能的过程
在我们的后续文章中,我们将深入探讨更多高级主题,包括推测解码(一个具有挑战性的实现,花费了我们超过3周的时间!),以及 MLA, Llama 4, 多模态能力等!
0x5. 关于开源的思考
这是我第一次对一个流行的开源项目做出重大贡献,我非常感激社区的支持和维护者的指导。
对于那些想要开始自己的开源之旅的 MLSys 爱好者,我强烈推荐加入 SGLang 社区。以下是我的一些个人建议:
- 你不需要成为专家才能开始贡献。贡献文档、基准测试和错误修复都是非常有价值的,并且受到欢迎。事实上,我的前两个 PR 专注于文档和基准测试。
- 在像 SGLang 这样的成熟项目中找到一个好的第一个问题可能很具有挑战性。我的方法是密切关注一个特定领域(例如:量化),监控相关 PR 和问题,并提供帮助,通过评论或 Slack 联系 PR 作者。
- 对你的贡献和承诺负责。在开源社区中,专业关系建立在信任和可靠性之上。记住,大多数贡献者都在平衡开源工作与全职工作,所以尊重每个人的时间和努力是至关重要的。
0x6. 参考文献
[^1]: FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness(https://arxiv.org/abs/2205.14135)
[^2]: From Online Softmax to FlashAttention(https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf)
[^3]: Awesome-ML-SYS-Tutorial: SGLang Code Walk Through(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/code-walk-through/readme.md)
[^4]: Awesome-ML-SYS-Tutorial: KV Cache Code Walkthrough(https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/d4d56dc3ab2260a747964ceb18cb1f69d23146ae/sglang/kvcache-code-walk-through/readme.md)
[^5]: Accelerating PyTorch with CUDA Graphs(https://pytorch.org/blog/accelerating-pytorch-with-cuda-graphs/)
[^6]: CUTLASS: CUDA Templates for Linear Algebra Subroutines(https://github.com/NVIDIA/cutlass)
[^7]: Flash Attention 3: Fast and Accurate Attention with Asynchrony and Low-precision(https://tridao.me/blog/2024/flash3/)
[^8]: SGLang: A Zero-Overhead Batch Scheduler for LLM Serving(https://lmsys.org/blog/2024-12-04-sglang-v0-4/#zero-overhead-batch-scheduler)

















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









