







文章链接:https://arxiv.org/abs/2303.11567
代码链接:GitHub - strongwolf/o2f: One-to-Few Label Assignment for End-to-End Dense DetectionGitHub - strongwolf/o2f: One-to-Few Label Assignment for End-to-End Dense DetectionGitHub - strongwolf/o2f: One-to-Few Label Assignment for End-to-End Dense Detection
研究背景
一对一(o2o)标签分配由于正样本数量有限,相似语义的标签会导致“标签冲突”,会降低特征学习效率。即使引入了额外的正样本来缓解这一问题,但依然受限于解码器中的自注意和交叉注意的计算复杂度。
一对多(o2m)标签赋值,它在训练过程中为每个GT对象分配多个正样本。这可能导致推理中的重复预测,并影响检测性能,因此需要NMS抑制多余正样本。
创新
一对多(o2f)标签分配策略除了为每个对象定义一个正锚和多个负锚外,还定义了几个软锚,它们同时作为正样本和负样本。在训练过程中动态调整这些软锚的正负权重,使其在训练早期(正样本多)更有利于“表示学习”,在训练后期(负样本多)更有利于“重复预测去除”。以这种方式训练的检测器不仅可以学习强特征表示,还可以进行端到端的密集检测。
这是一种高效的基于fcn的密集检测器,无nms,但可端到端训练。
如图1所示,与o2o将一个模棱两可的锚点(锚点B或C)设置为完全负样本不同,将每个模棱两可的锚点标记为部分正和部分负。在训练过程中自适应调整正样本和负样本标签的程度,以保持“表征学习”和“重复预测去除”之间的良好平衡。

目标检测方法回顾
CNN-based
主要分为一阶段和二阶段模型。两阶段检测器在第一阶段生成区域建议,在第二阶段细化这些建议的位置并预测类别,而单阶段检测器直接预测卷积特征图上密集锚点的类别和位置偏移量。早期的检测器大多使用预先定义的锚作为训练样本。锚的形状和大小的超参数必须仔细调优,因为不同数据集的合适设置各不相同。为了克服这一问题,提出了无锚检测器来简化检测管道。
大多数基于cnn的检测器在训练过程中采用一对多(o2m)标签分配方案。然而,o2m标签分配需要一个后处理步骤,即非最大抑制(NMS),以消除重复的预测。NMS引入了一个参数降低了所有实例的精度和召回率,这并不是最优的方法,尤其在拥挤的场景。
Transformer-based
以DETR 为例,它利用一组备用的可学习对象查询作为训练候选对象与图像特征进行交互,使用 o2o 双向匹配和全局注意机制实现了具有竞争力的端到端检测性能。然而,DETR 存在收敛速度慢和小物体性能差的问题。前者是因为正样本数量不足,后者与特征映射和对象查询之间的注意力建模机制有关。增加正样本数量的方法在密集预测场景会极大增加计算成本。
所提理论
模糊锚点的定义
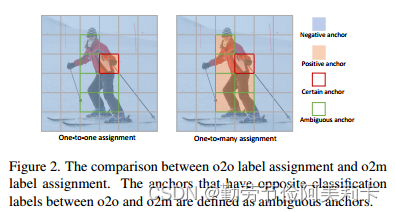
密集检测中的标签分配旨在为每个锚点分配一个分类标签以监督网络训练。图 2 说明了“人”实例的 o2o 和 o2m 标签分配。可以看出o2o标注方案只选择一个anchor作为正样本,而o2m则分配了多个正anchor。在o2o和o2m中,除了positive anchors之外的其余anchors都被定义为负样本。
o2f将在 o2o 和 o2m 中都为正的 anchor(用红色边框突出显示)命名为“certain anchor”(通常没有歧义)。相反,将在 o2m 中为正但在 o2o 中为负的锚框(用绿色边框突出显示)命名为“模糊锚框”,因为它们在 o2o 和 o2m 方案中具有冲突。
动态调整“模糊锚框”
为每个不明确的锚框分配一个软标签 t,其中 0 ≤ t ≤ 1 是其正度,因此 1 − t 是其负度。我们将正锚和负锚的分类损失分别定义为-log(p)和-log(1-p),其中p是预测的分类分数。分类损失将为
-t×log(p)-(1-t)×log(1-p)
选择 Certain Positive Anchor
每个实例选择一个特定的正锚点,使用预测感知选择指标,该指标考虑了分类和回归的成本以选择唯一的正样本,定义为
![]()
其中Si,j表示anchor i和实例j的匹配分数,cj是实例j的类别标签,pi,cj是属于类别cj的anchor i的预测分类分数,bi是anchor i的预测边界框坐标,bj表示实例j的坐标,α控制分类和回归的重要程度。1 [i ∈ Ωj ] 是空间指标,当锚点 i 的中心点在实例 j 的中心区域 Ωj 内时输出 1;否则它输出 0。本方法选择分数最高的锚点。
“模糊锚框”的标签分配
在第j次训练,锚框i的分类损失为(p为预测分数)
![]()
软标签t的定义为

其中T是时间相关变量,在第j次迭代对所有样本赋予相同的值,Tmax和Tmin分别控制第一次迭代和最后一次迭代中模糊锚框的正向程度,这样就能保证在训练早期增大正样本数量以强化“表示学习”,在训练后期提高负样本比例增强“重复预测去除”。
网络结构

网络结构(FCOS)如图3所示。由两个并行卷积分支组成的检测头连接到每个特征金字塔网络(FPN)层的输出。一个分支预测一个大小为 H × W × C 的分数图,其中 C 是数据集中的类别数,H 和 W 分别是特征图的高度和宽度。另一个分支预测大小为 H × W × 4 的位置偏移图和大小为 H × W × 1 的中心图,将中心图与分类得分图相乘作为最终的分类-IoU 联合得分。
对于每个实例,选择一个确定的正锚框 和 K 个模糊锚框。其余的锚框为负样本。每个实例的分类分支的训练目标被表述为

其中pc是单个某个锚框的分类得分,A和B分别表示模糊锚框和负锚框的集合。 BCE 表示二元交叉熵损失,FL 表示Focal loss。
regression loss定义为
![]()
GIoU 损失是位置损失,bi 是预测的位置, bgt是实际位置
实验
数据集和实现细节
COCO 和 CrowdHuman 数据集
使用 MMDetection 框架。
所有骨干都由在 ImageNet [9] 上预训练的权重进行初始化,并进行冻结批归一化。
消融研究基于带有 FPN 的 ResNet-50 主干。
调整输入图像的大小,使短边在“1×”时间表中为 800 像素。多尺度训练应用于“3×”时间表。在 8 个 GPU 上训练所有模型,小批量大小为 16。
当使用 CNN 作为主干,SGDM 优化器,初始学习率为 0.01,动量为 0.9,权重衰减为 10 -4 。当使用 Transformers 作为主干时, AdamW ,初始学习率为 0.0001,权重衰减为 0.05。在“1×”计划中,我们训练模型 12 个时期,并在第 8 个和第 11 个时期分别将学习率降低 10 倍。在“3×”时间表中,我们训练模型 36 次,并分别在第 24 次和第 33 次衰减学习率。
消融实验
1.模糊锚框的数量(best:7)

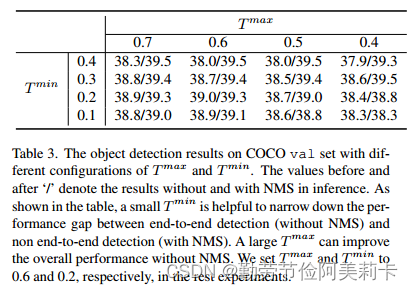
2.时间相关变量T的取值(best:0.6 0.2)
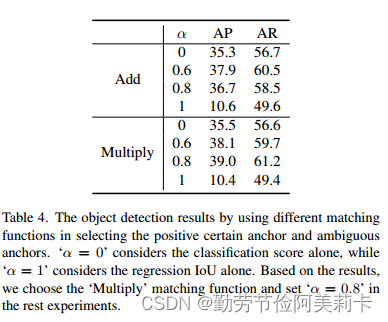
3.参数arfa取值(best:0.8)
对比实验
主要与 DeFCN 进行比较。
3D Max Filtering (3DMF);Prediction-aware One-to-One (POTO) ;conv( add to centerness
branch)

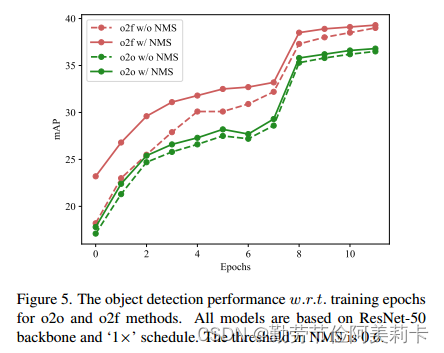
训练过程
其他主干

可视化

CrowdHuman数据集与实例分割结果(COCO)

感想:精度AP提升相对不大,速度也没有优势(相对于o2o方法倒是有点优势),但胜在实验充实,方法实现较方便,可以应用于其他模型做一个涨点。并且可以算是NMS的有效替代,进一步简化的检测模型的pipeline。















 2825
2825











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









