







题外话: 最近受大语言模型的风潮影响,在准备换一份与微调/应用大模型的相关的工作。为了成功的实现这一个阶段性目标, 准备重新从开山之作Attention is all you need开始复习。同时也为了增加自己的理解和练习自己的输出能力,打算将所有的学习内容整理成文章,如果有同学觉得内容有用的话,那更是锦上添花啦 🫣。
好啦让我们进入正文
本文深入一下Self-Attention(自注意力机制)以及 Multi-head Attention(多头注意力机制)的原理以及计算过程,主要的参考资料是台大李宏毅教授的授课内容,同时增加了一些从其他文章那里参考的细节,以及一些些个人的理解和心得。
一、Attention(注意力)是干嘛用的嘞?
1.1 在Attention(注意力)之前
说到这个,就不得不提一提attention出现之前的风风雨雨。
首先,在Attention is all you need这篇论文出现之前,循环神经网络(RNN)还有它的变形是最常用的处理序列(序列在这种语境下可以理解为各种各样的不同长度的内容,比如说一段文字,一段语音音频,一段手写语段,等等)的基础深度神经网络架构,它主要长下面这个样子:
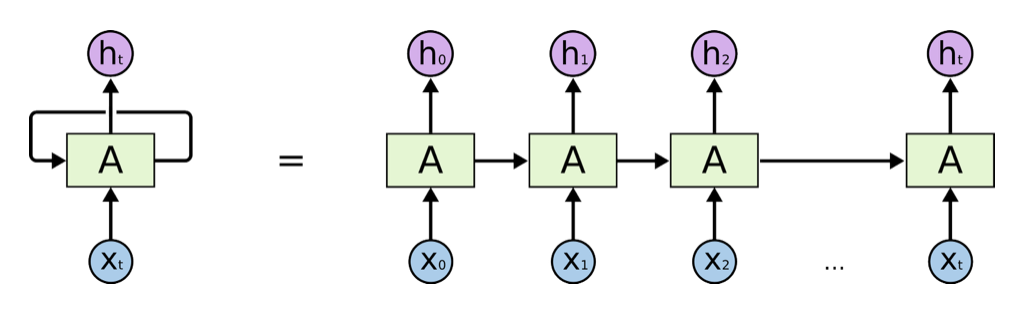
在处理自然语言的时候,这种架构通过吞入一个一个的token(分词,图中蓝色圆圈来表示)来进行对于序列信息的处理。
(例如,要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN会对前面的信息进行计算记忆并应用于当前输出的计算中,即每一个节点的输出(图中用粉色圆圈表示)不仅包括上一个节点的的信息,还包括所有前面节点信息的汇总。)
理论上,RNN能够对任何长度的序列数据进行处理。但是在实践中,RNN在处理长序列时暴露出一些问题,例如梯度消失/爆炸、信息传递延迟,计算时间复杂度高,无法并行运算等问题。
为了解决这些问题,注意力机制被引入神经网络领域。注意力机制完全消除了RNN需要一个词一个词吞入的流程,这意味着我们不需要等待架构一个token一个token吞入,而是可以直接一下子直接吞下一整个序列。
(注:本文讲述的自注意力机制只是注意力机制的一种,还有很多奇葩的注意力机制,之后也会写另一篇文章来介绍)
二、Self-Attention(自注意力)
2.1 Self-Attention(自注意力)怎么实现直接吞下一整个序列的?
比较教科书的解释:自注意力机制的核心思想是,对于输入序列中的每个位置,不是仅考虑前面的信息,而是通过一个权重分配机制(即注意力机制)将整个序列的信息进行加权平均,得到一个上下文向量,然后再将该向量作用于输入序列的每个位置,从而得到输出序列。
为了理解上面那段,我们还是拿预测句子的下一个单词这个问题来举例。
要预测句子的下一个单词是什么,一般需要用到前面的单词,然后判断前面单词跟要预测的下一个单词的关系是啥,关系大不大,比如说下面这句:
The cat, after eating fruit, canned food and cat food, ____ lazily on the carpet.
要预测空格中的词,与其相关的就是前面的'cat',以及表示时态的'after',其他的相关性都不太大。也就是说,我们需要将更多的注意力放在‘cat’和‘after’这两个词中,那么怎么让模型在预测的时候知道更多的注意力要放在这两个词中呢?那我们就需要计算这个要预测的词和其他词之间的注意力的分数,分数越大,在预测这个词的时候需要分配的注意力越高。
基于此,当我们需要决定一个词与所有其他词的关系时,可以用计算这个词和其他词之间的注意力的分数这个方法。
具体如下图所示:
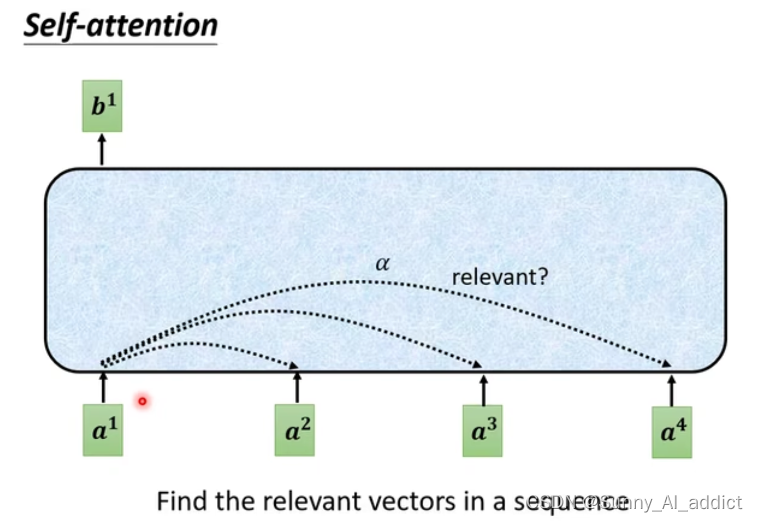
如果我们需要决定这个词与所有其他词的关系时,我们就要对
和其他所有
判断是否相关,然后将这些相关关系抽象到一个输出
中去。
那么怎么将这些相关关系抽象到中去呢?方法有很多种,比如计算距离,计算相似度,或者通过可学习的方式来学习向量参数。
面对这个问题,self-attention创新性地引入三个矩阵:Query (Q)/Key (Key)/V (Value)。
- 查询(Query): 指的是查询的范围,自主提示,即主观意识的特征向量
- 键(Key): 指的是被比对的项,非自主提示,即物体的突出特征信息向量
- 值(Value) : 则是代表物体本身的特征向量,通常和Key成对出现
注意力机制是通过Query与Key的注意力汇聚(给定一个 Query,计算Query与 Key的相关性,然后根据Query与Key的相关性去找到最合适的 Value)实现对Value的注意力权重分配,生成最终的输出结果。
为什么要引入三个矩阵而不是一个?总结概括是为了映射到不同的特征空间,增强模型的表示能力 (关于为什么引入三个矩阵,具体详细看为什么Self-Attention要通过线性变换计算Q K V,背后的原理或直观解释是什么? - 知乎)。
接下来我们仔细看看self-attention是怎么引入Query (Q)/Key (Key)/V (Value)的。
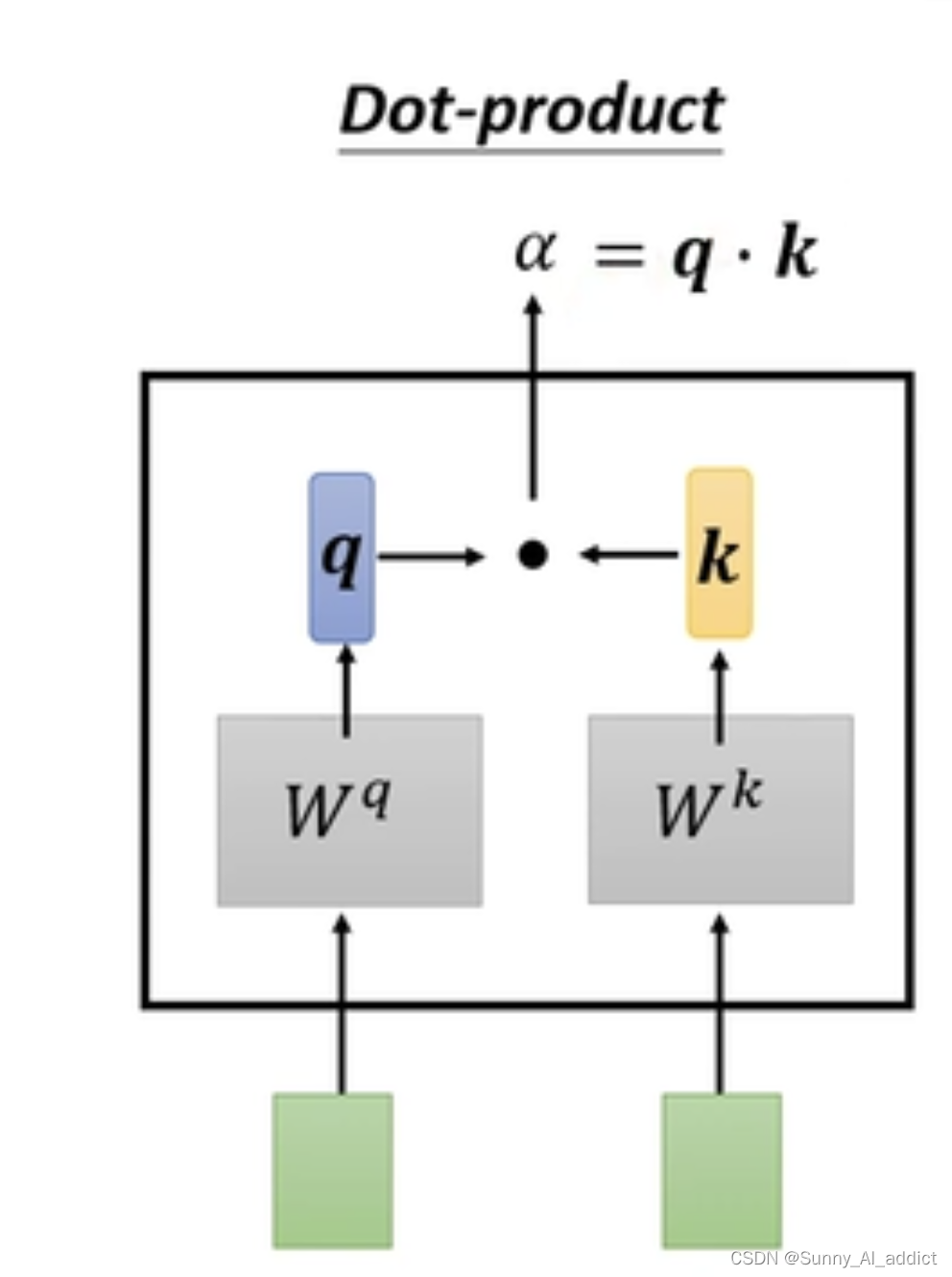
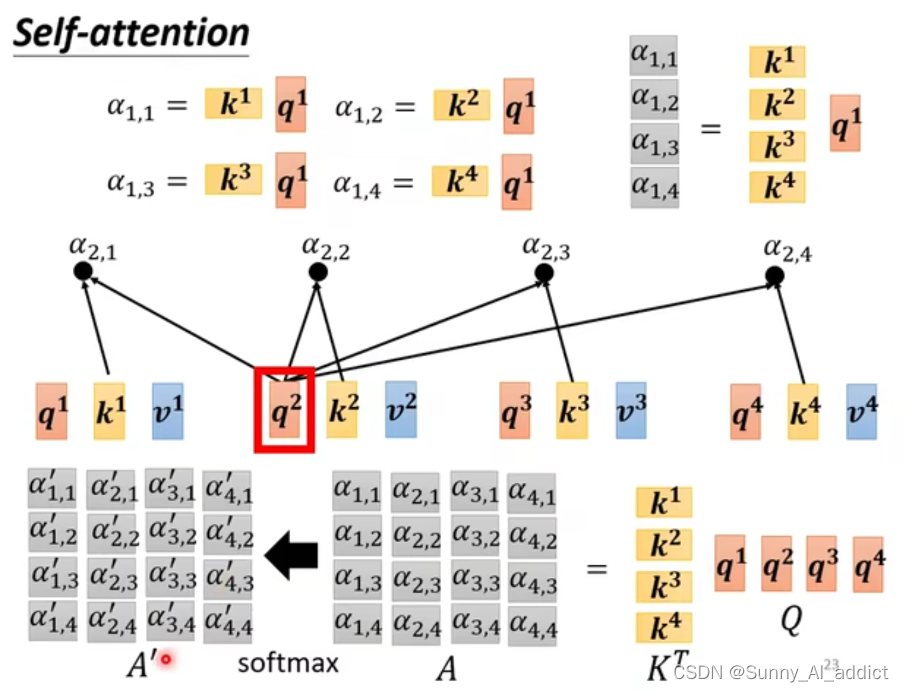
如下图所示,在计算和某一个
的相关性的时候,我们输入这两个token,将
与
相乘得到矩阵q(相当于是query vector),将某一个
与
相乘得到矩阵k(相当于是key vector),然后再将得到的矩阵q和矩阵k进行点积(dot product)得到
代表和某一个
的相关性矩阵
。
(点积:点积是一种常用的相似度度量。点积和余弦相似度是密切相关的概念)
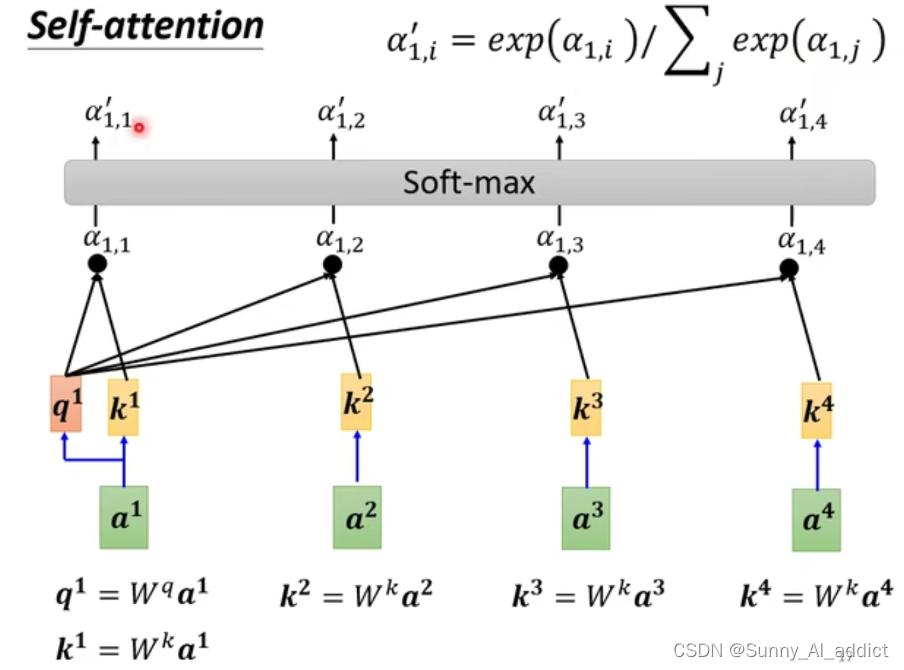
然后重复这个操作, 如下图所示:
(注意,当我们在计算和某一个
的相关性的时候,我们固定q为
,然后用
去与所有的
进行内积得到
,然后再对得到的
进行一个softmax转换,得到
。
但是等一下,不是所要把跟其他所有
的相关关系抽象到一个输出中吗?怎么还是那么多输出?
所以我们要在进行一步——将所有的再汇总至
。这时,我们要再引入一个额外的矩阵
,将这个矩阵
和所有的
相乘(注意是矩阵相乘操作,而不是点积),得到矩阵
。
然后,将和所有的
相乘,最后将得到的这些矩阵进行相加,就得到
啦,这时候的
已经是个汇总了
和其他所有
相关关系的大杂烩矩阵了 :0。
具体操作如下图所示:
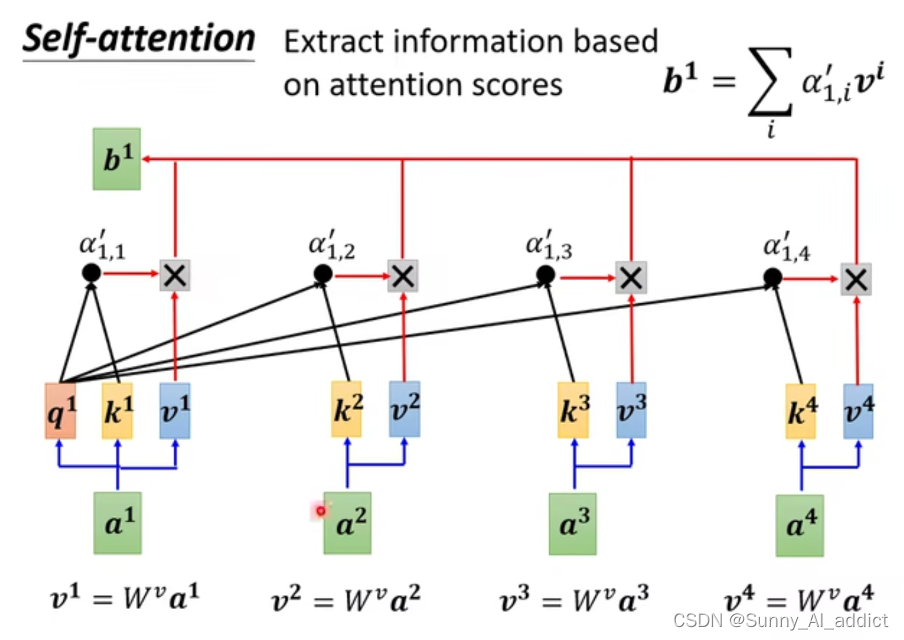
好啦,得到了之后,就对剩下的
进行同样的操作得到
就OK了。
2.2 Self-Attention怎么降低计算的复杂度?
看到这里,有些同学可能有疑问, 那么这个自注意力怎么解决计算复杂度高,无法并行运算的问题呢?
为了降低计算时间复杂度,这些并不是一个接一个计算出来的,而是同时计算出来的,原理是通过合并向量来进行矩阵运算。
具体来说,就是计算的时候,我们不需要将一个一个将
与
相乘,而是将所有的
合并成一个大矩阵然后做相乘就好了,这就避免了RNN一次只能吞入一个
的问题。
同样的,计算和
也是同样的合并操作。
具体如下图所示:
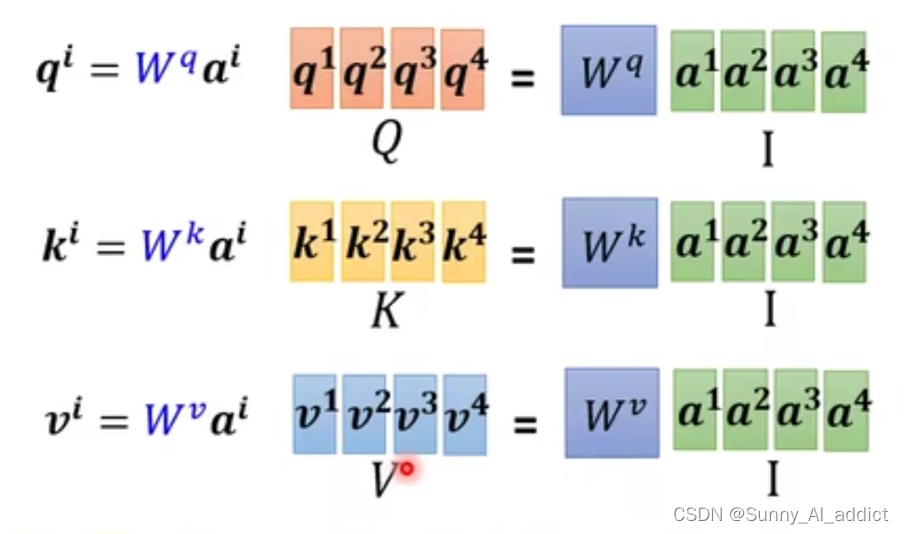
(有些同学可能不理解具体代表什么,
代表的是词嵌入,也就是对于一个词的向量表示,毕竟机器只能处理数字,例如‘cat’这个词的词嵌入可能是[0.23,0.45,0.64,....,0.18])
(在上图中,未知矩阵只有,那么这三个矩阵是怎么得到的呢?这里引用李宏毅老师的一句原话——“在做训练的时候learn出来的!”)
同样的,我们也可以把所有的再汇总至
的运算过程中的矩阵进行合并运算,如下图所示:
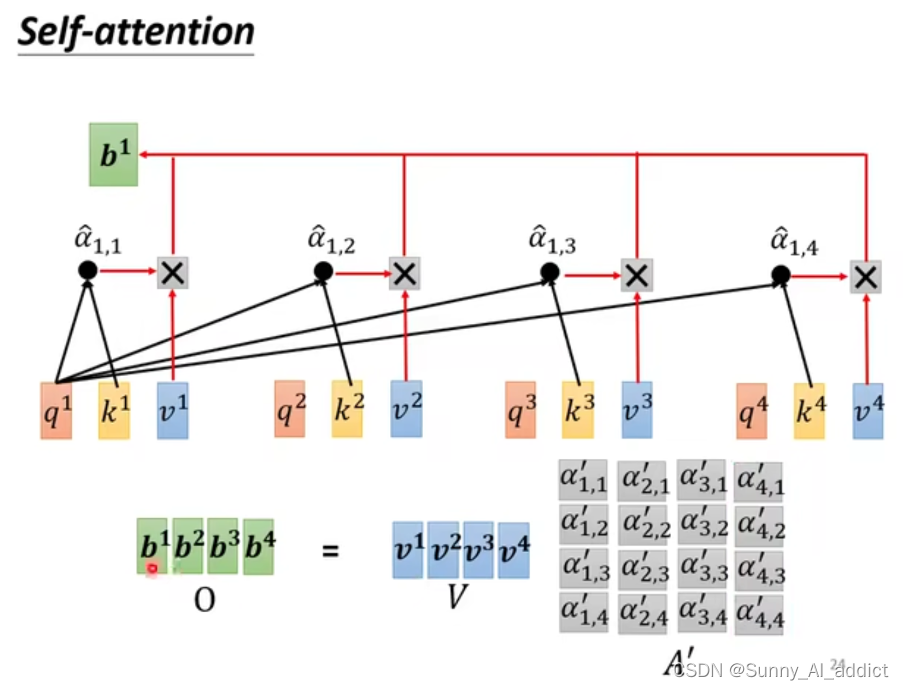
那么怎么来进行并行运算呢?以及两个词之间的相关关系,可能并不止一种啊(可以是时态之间的相关性,可以是语义之间的额相关性,也可能是语序之间的相关性等等)这就要引入接下来的Multi-head Attention(多头注意力机制)了。
温馨提醒:看到这里可以稍微休息一下 🤯
三、 Multi-head Attention(多头注意力机制)
3.1 不同的头对应不同类型的相关性
两个词之间的相关关系,可能并不止一种。我们希望模型可以基于相同的注意力机制学习到不同的关系, 然后将不同的关系作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
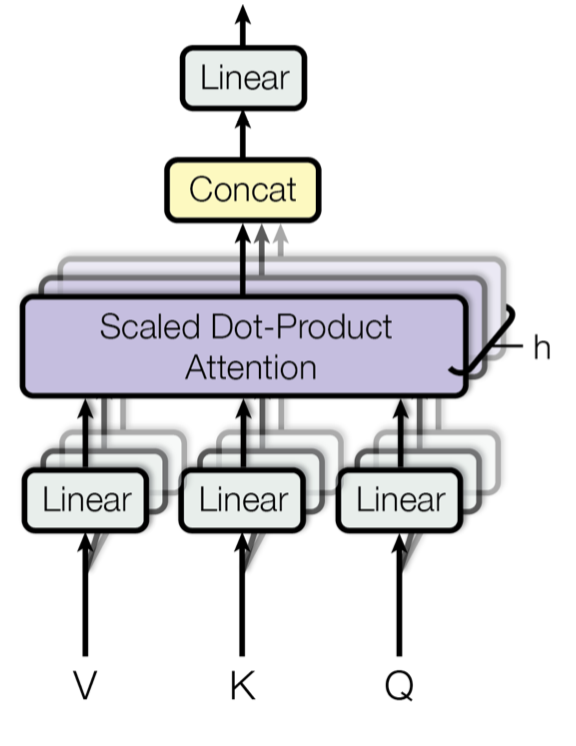
为此,与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的h组、不同的线性投影(linear projections)来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。
我们上栗子🌰:
如下图所示,假如我们现在有两个头,那么我们需要对每个头分别进行学习,得到每个头中的,然后再进行自注意力的计算。
在第一个头中,我们得到, 如下图所示:
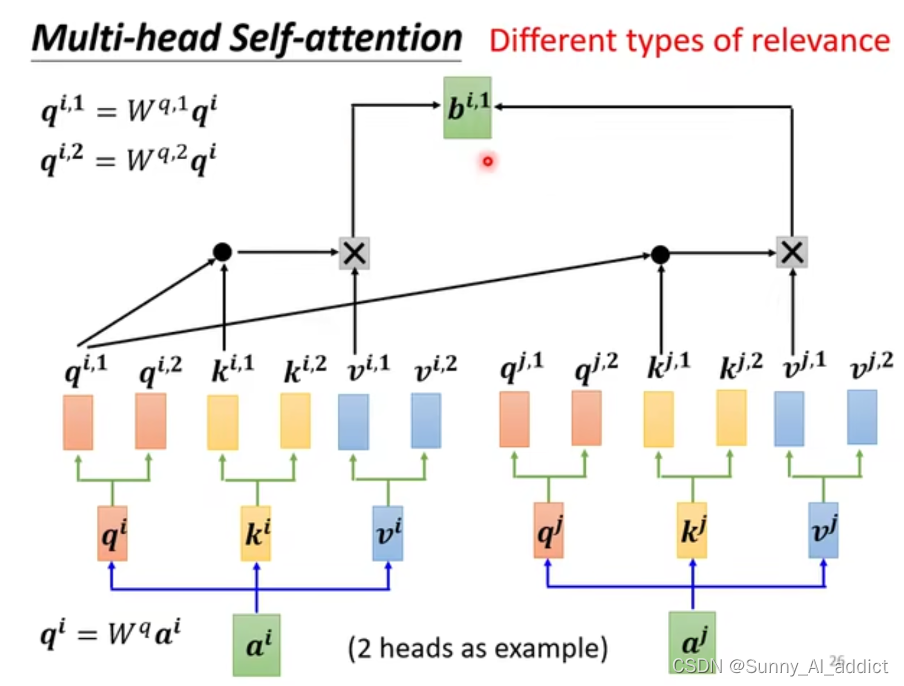
在第二个头中,我们得到, 如下图所示:

和
关注的是不同类型的相关性。
得到了 和
之后,我们还是合并
和
得到一个合并矩阵,然后与
相乘,得到汇总了两个不同相关性信息的
。如下图所示:

(有些同学可能并不理解为什么要用一个来与
和
的合并矩阵相乘再得到
,这里比较直观的解释是输入到下一层的注意力分数的矩阵形状是确定的,然而在multi-head attention的情况下,原始的
的合并矩阵的形状是[*,n],即是既定输入矩阵形状的n倍;然而对于这个合并矩阵,简单相加或者平均会造成信息损失,因此这里引入了一个
来转换,这个
也是learn出来的!)
3.2 多头并行计算
具体操作如下图:
参考资料:
https://arxiv.org/abs/1706.03762

















 2667
2667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









