







最近要看一些推理攻击的内容,把看过的都放过来吧
Unstoppable Attack: Label-Only Model Inversion
无条件攻击:基于条件扩散模型的只有标签模型反演
TIFS 2024
文章目录
一、论文信息
1. 题目
Unstoppable Attack: Label-Only Model Inversion
无条件攻击:基于条件扩散模型的只有标签模型反演

2. 作者
Rongke Liu , Dong Wang , Yizhi Ren , Zhen Wang , Kaitian Guo, Qianqian Qin, and Xiaolei Liu
杭电
3. 期刊年限
- TIFS
- 6.8
- 2024
4. 关键词
Model inversion attacks, diffusion model, deep learning security and privacy, generative model-based attack model.
二、背景
- MIA专注于恢复与私有数据本身非常相似的数据
- 白盒:为了在CNN上获得更多语义和有意义的图像,最先进的方法通过将噪声向量馈送到用辅助数据集训练的GAN网中的生成器来生成图像,优化转向噪声向量和生成器
- 现有的黑盒攻击是通过SGD来优化生成器,以最小化生成图像和辅助图像之间的像素损失。所生成的图像由上述生成器基于目标模型对辅助数据的预测来产生。基于黑盒模型输出的置信度或标签,攻击可以分为:
- 数据重构:基于目标模型预测置信度向量来恢复输入样本
- 训练类推理:基于独热向量或标签来恢复目标代表性样本
- 文章研究的是纯标签场景,属于训练类推理。目前研究产生理想的生成结果主要集中在白盒场景。实际中,模型通常作为黑盒访问,仅输出预测的标签,可以防止白盒攻击中的生成器在梯度的帮助下进行优化
- 指出了一些现有黑盒攻击的缺陷:
- 生成的图像多为灰度,无法准确判断目标的肤色或瞳孔颜色等颜色特征
- 目前没有可以在仅标签场景中进行最佳训练的攻击模型,现有方法必须通过基于GAN的生成器设计额外的优化策略来达到攻击目标
- 只能为目标标签生成单个样本
- 基于生成器的目标标签的生成结果是次优的,并且评估指标缺乏全面性
三、创新
- 开发了一种新的标签模型反转攻击方法来解决上述限制。核心是训练一个由目标模型预测标签引导的条件扩散模型(CDM),在恢复阶段,可以根据目标标签引导恢复各种样本进行选择:
- 利用伽马校正来解决同一目标下辅助数据的差异而导致的生成质量下降
- 使用目标模型来过滤掉同一目标下的多个生成样本,具有更好的容错性和更大的优化空间
- 进行定性和定量评估,效果很好
四、方法
4.1 威胁模型
- 采用卷积神经网络图像分类模型作为目标模型
- 重点是在只有标签的场景下,对手只能访问标签预测Fw(x),通过输入图像x到目标模型FW
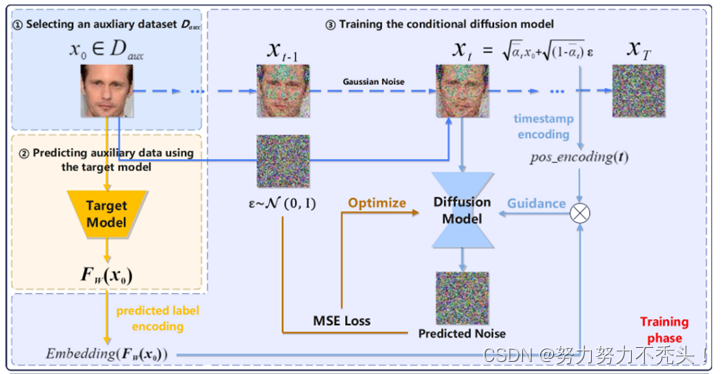
4.2 攻击模型
4.2.1 训练阶段
- 训练一个生成器来进行模型反演攻击:
- 选择与目标模型任务相关的辅助数据集Daux
- 将辅助数据集中的数据x0输入到目标模型Fw中产生预测标签Fw(x0)
- 使用来自1的辅助数据集Daux,采用来自2的预测标签Fw(x0)作为指导训练的条件,来训练用于攻击的条件扩散模型Gθ
- 通过在只有标签场景下,使用CDM攻击模型,改进了现有的MIA。使用目标模型的预测标签作为辅助数据的指导,将 预测标签下的辅助数据 与 目标模型对目标的决策 对齐,帮助攻击模型从数据中学习目标的一致特征
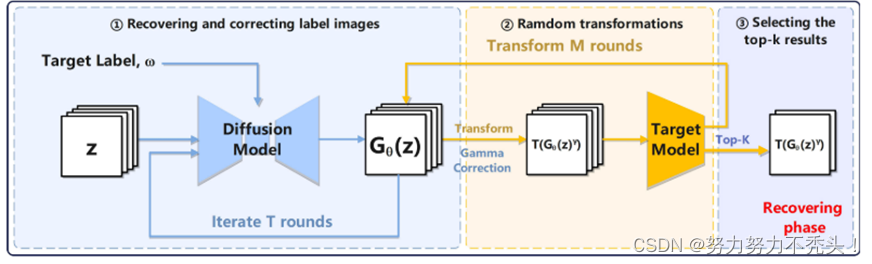
4.2.2 恢复阶段
- 使用经过训练的生成器来恢复目标标签数据:
- 将多个标准正态分布噪声图像z和目标攻击标签l输入到训练好的条件扩散模型中,以预定义的引导强度恢复该标签的图像Gθ(z),为了解决在相同指导下的数据不是同一个实体,对数据质量有影响的问题,我们使用伽马校正来将生成的图像校正为Gθ(z)γ。
- 将校正后的生成图像Gθ(z)γ随机变换为T(Gθ(z)γ)并输入到目标模型中进行预测,然后重复该步骤M次。
- 从T(Gθ(z)γ)中选择前k个鲁棒生成的(最高比率)图像,展现独特的优势
五、实验部分
5.1 数据集
FaceScrub、MNIST、CelebA
5.2 指标
- 认为定性更重要:使用学习感知图像块相似性(LPIPS)作为MIA的新评估指标
- Attack Accuracy (Attack Acc)、
- K-Nearest Neighbors Distance (KNN Dist)、
- Frechet Inception Distance (FID)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









