







最近要看一些推理攻击的内容,把看过的都放过来吧
Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures
利用置信信息的模型反演攻击及其基本对策
ACM SIGSAC 2015
文章目录
一、论文信息
1. 题目
Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures
利用置信信息的模型反演攻击及其基本对策

2. 作者
Matt Fredrikson、Somesh Jha、Thomas Ristenpart
卡内基梅隆大学、威斯康星大学麦迪逊分校、康奈尔科技
3. 期刊年限
- ACM SIGSAC
- 计算机安全TOP
- 2015年
4. 关键词
model-inversion, GAN
二、背景
- 威胁是提供商可能对敏感数据管理不善,允许训练数据或查询日志成为内部攻击的牺牲品或通过系统妥协暴露
- 一种模型反转攻击,该攻击能够使用黑盒访问预测模型以估计某人的基因型,适用于任何设置,其中被推断的敏感特征是从一个小集合中提取的
- 文章引入 :新的攻击,可以推断用作决策树模型输入的敏感特征,从 API 访问恢复图像到面部识别服务攻击,构建利用 API 公开的置信值的攻击算法
- ML APIs and model inversion:将客户端访问分为黑盒或白盒。 黑盒中,对抗性客户端可针对模型预测查询,不会下载模型描述。 白盒中,客户可下载模型的描述 - 输入[x1,x2,…,xn],输出 Y = F(x1,x2,…xn) - 黑客使用黑盒访问 F 来推断一个敏感特征,比如x1,是一个敏感特征,通过一些其他相关特征和输出值y,模型的损失值,以及单个变量的边际先验。算法是一个最大后验(MAP)估计器,它选取的是的值,使观察到已知值的概率最大化。然而,这需要计算f(x1, …, xd)的每一个可能的x1值
- White-box decision tree attacks:模型描述所包含的信息比黑盒攻击所利用的在黑盒攻击中利用的更多信息。提供了训练集中符合决策树中每个决策树中的每个路径的实例数。除以实例总数实例的总数给出了分类的confidence。先验地看这个额外的信息似乎是无害的,但它实际上是可以被利用的
三、创新
- 提供新的模型反演算法,可用于从 ML 服务上的决策树推断敏感特征,从面部识别模型中提取训练对象的图像:
- 在决策树模型(BigML)和人脸识别的神经网络模型上实现了基于置信度信息的MI Attack
- 采用Amazon’s Mechanical-Turk对攻击效果进行量化评估
- 对提出的攻击,提出了对策
四、方法
4.1 威胁模型
- 重点关注敌对客户端试图滥用对 ML 模型 API 的访问的设置, 假设对手拥有 API 公开的任何信息。
- 白盒:可下载模型 , 黑盒:攻击者只能对对手选择的特征进行预测
- 敌手通过训练获得辅助信息aux的输出,敌手无法获得训练数据和联合先验的样本,只能通过ML API间接获得对数据的标识。
- 文章关注对手无法访问训练数据,也无法从联合先验中采样的能力的情况。 重点考虑具有保密风险的设置。
- 不考虑恶意服务提供商,也不考虑可能损害服务的敌对客户端,是一种尚未引起关注、潜在的风险攻击
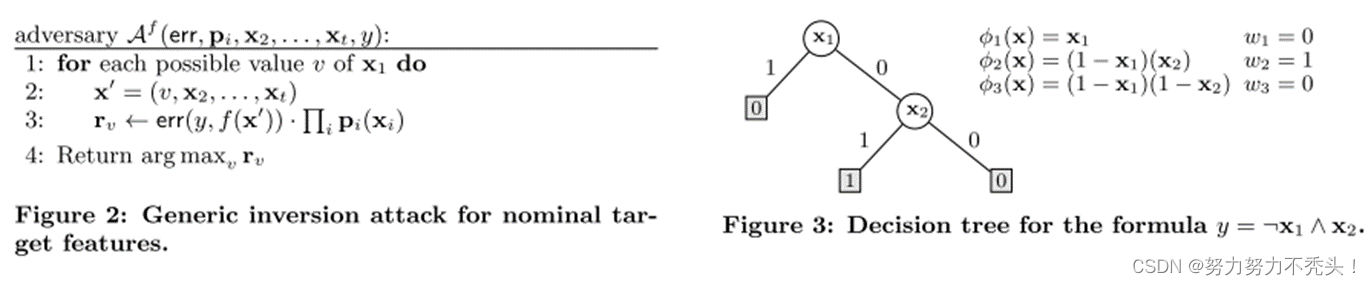
4.2 Fredrikson的攻击
- 考虑了一个线性回归模型 f,通过特征向量预测药物的实际值建议的初始剂量,其中基因标记表示隐私属性,也是MI Attack的逆向目标,攻击者取得f的白盒权限+除了基因隐私的属性和预测结果{x1,…,xt,y} 逆向推理隐私属性x1 的数据
- Figure 2:err 高斯误差模型,通过处罚使得预测值不准的 xi 使得预测值逼近实际值,最后得到的最接近的隐私属性当作x1的数据;p为边缘先验概率。
- 该算法简单地用x1的每个可能值完成目标特征向量,然后计算这是正确值的加权概率估计,是白盒,不符合黑盒,同时无法对高维特征进行还原
4.3 决策树的反演攻击
- 对于黑盒条件,用了Fredrikson的MI Attack算法,针对决策树做出了微调,
- 不同体现在:目标模型只能产生离散输出;误差模型信息不同,采用混淆矩阵C表示,而非高斯分布的方差

4.4 人脸识别
- 主要实现了两类模型逆向攻击:
4.1 重构攻击
- 假设敌手知道模型标签,利用标签重构图片,
- 攻击者若能够从一系列图片中识别出受害者图片,认为成功实现了攻击
4.2 去模糊攻击
- 假设敌手可获取不包含隐私的用户的模糊无法辨认的图像
- 对其进行去模糊操作,若恢复的图像在训练集中,认为成功实现了攻击
五、实验部分
5.1 数据集
FiveThirtyEight’s “How Americans Like Their Steak、a subset of the General Social Survey (GSS) focusing on responses re-lated to marital happiness、Cambridge
5.2 和MI有关的实验
- 3种预测策略:
- 随机敌手:对模型一无所知=掷硬币的随机猜测
- baseline敌手:只知道敏感属性的边缘概率分布,无法访问树/有关数据集的任何信息,根据边缘分布猜测最可能的值
- 理想敌手:可访问从原始数据集训练的决策树来预测敏感属性,给定已知特征的情况,使用树来进行预测















 4888
4888











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









