







最近要看一些推理攻击的内容,把看过的都放过来吧
Exploring Model Inversion Attacks in the Black-box Setting
黑盒环境下的模型反演攻击研究
PETS CCFC 2023
一、论文信息
1. 题目
Deep Models Under the GAN: Information Leakage from Collaborative Deep Learning
GAN下的深度模型:协作深度学习的信息泄漏

2. 作者
Antreas Dionysiou、Vassilis Vassiliades、Athanasopoulos
塞浦路斯大学
3. 期刊年限
- PETS
- CCFC
- 2023
4. 关键词
Model inversion, inference attack, security, privacy
二、背景
- 机器学习、深度学习不安全,隐私问题很大,文章关注模型反转攻击,目标是生成类似于训练目标模型的原始输入的输入
- MI 攻击的有效性和效率有很大差异,(对手可获得的有关目标模型的信息及其复杂程度、白盒黑盒的差异、模型复杂度) ,所展示算法的优点缺点各不相同
- 文章提出了关于黑盒环境中 MI 攻击的有效性和效率的可行性研究。
- 原因:
- 与该领域具有明确基线的其他攻击相比,MI 具有概率性质,对于 MI 攻击何时被认为有效,科学上尚未达成共识
- 引入的黑盒 MI 攻击在训练类推理设置中运行,被认为是困难的,在某些情况下是不可能的,工作旨在探索在中等复杂性目标上以最小的开销进行黑盒 MI 攻击的可行程度
- 原因:
- 提出了 Deep-BMI(深度黑盒模型反演),模块化 MI 框架,支持各种黑盒连续优化算法,以最大化目标模型的置信度得分
- 如何解决黑盒环境中的 MI 问题?
- 从随机像素开始并不断扰动它们,直到目标类别的置信度得分最大化。优点是简单且具有生成性,但是会生成欺骗图像。
- 根据对手的背景知识绘制更通用的数据集,用于训练生成反演模型。可以使用与目标模型的训练集描述性相似的公共数据集的图像。 优点在于假设两个集合中包含的图像共享特征,这将使公共集合中的某些图像可能最大化目标模型某一类的置信度得分,但是,无法充分利用训练类推理攻击设置中描述性相似数据集的全部潜力
三、创新
- 提出了 Deep-BMI(深度黑盒模型反演),模块化 MI 框架,支持各种黑盒连续优化算法,以最大化目标模型的置信度得分
- 在MIA中,第一个重建可识别图像的人,效率高
- Deep-BMI 支持多种黑盒优化器或对手类型,以攻击时间换取性能。
- 通过实验证明,为每个目标类别返回多个不同解决方案的优化器是对深度图像识别模型进行 MI 攻击的最有效的方法
四、方法
4.1 威胁模型
- 重点关注黑盒攻击, Deep-BMI 仅通过利用获胜类别的置信度分数来重建可识别的数字和面孔。
- 目标是在实施 MI 攻击时最大限度地减少对目标模型的查询数量。
- 具有过多查询需求的黑盒 MI 攻击:
- 效率低下
- 可能会引起目标系统的怀疑
- 具有无限查询的黑盒对手可以近似白盒对手的性能
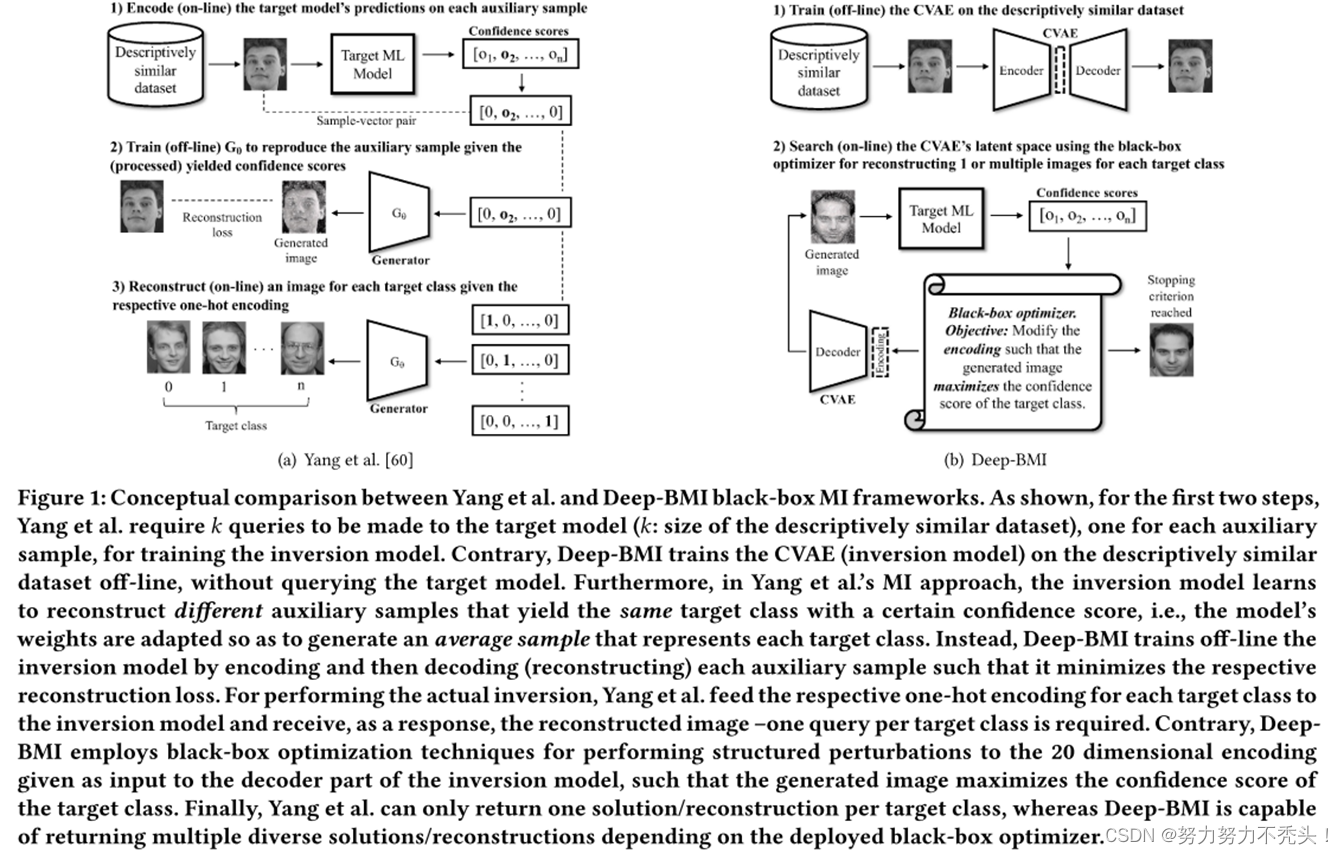
4.2 攻击模型
- 采用自动编码器,通过编码然后解码每个辅助样本来离线训练 CVAE,最大减少重建损失
- Deep-BMI 将目标模型的查询数量与描述性相似数据集的大小解耦;
- Deep-BMI是设计的模块化MI框架,支持多种黑盒优化方法
五、实验部分
5.1 数据集
MNIST、EMNIST-letters















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









