







机器学习实战
Scikit-Learn
Scikit-Learn非常易于使用,它有效地实现了许多机器学习算法,因此成为学习机器学习的重要切入点。

TensorFlow
·TensorFlow是用于分布式数值计算的更复杂的库。通过将计算分布在数百个GPU(图形处理单元)服务器上,它可以有效地训练和运行大型神经网络。TensorFlow(TF)是由Google创建的,并支持许多大型机器学习应用程序。
一、机器学习



深度学习也是按照这个流程,只不过用的是神经网络!
二、深度学习
1、人工神经网络(ANN)

2、感知器
感知器是最简单的ANN架构之一。
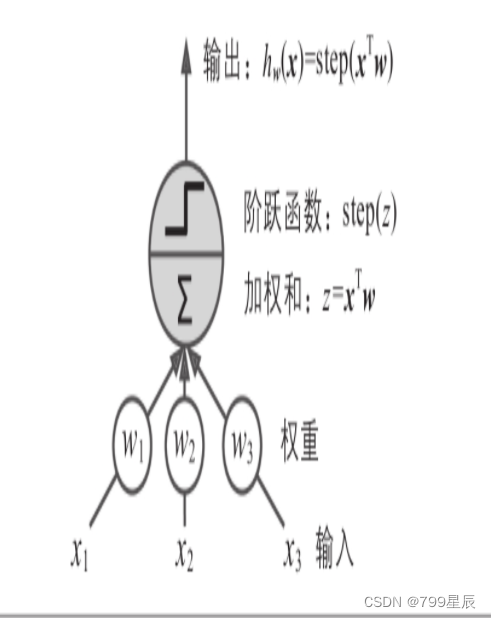
它基于稍微不同的人工神经元(见图10-4),称为阈值逻辑单元(TLU),有时也称为线性阈值单元(LTU)。输入和输出是数字(而不是二进制开/关值),并且每个输入连接都与权重相关联。TLU计算其输入的加权和(z=w1x1+w2x2+…+wnxn=xTw),然后将阶跃函数应用于该和并输出结果:hw(x)=step(z),其中z=xTw。
3、计算机视觉

0-255 值越小,图像越暗(黑色)
3001003–长* 宽 * 颜色通道(RGB)
4、K近邻

K近邻算法不能分清主体,而是将背景相似的归为一类
因为K近邻算法是根据对应两点像数的差值分类的。
5、神经网络
(1)线性函数/得分函数
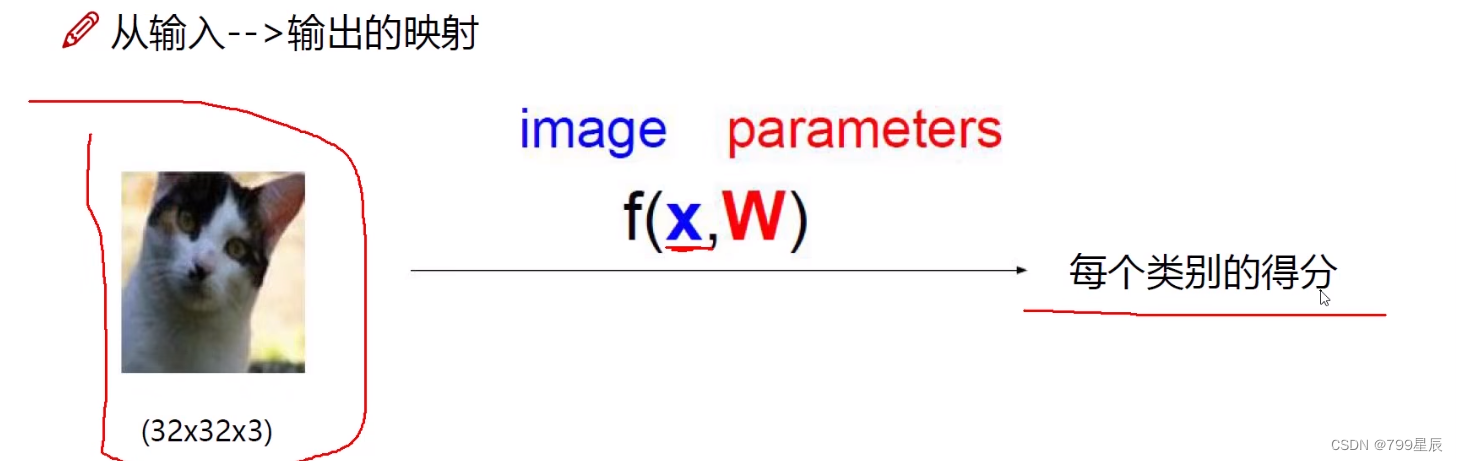
解释:每个特征x对应的权重W—得分
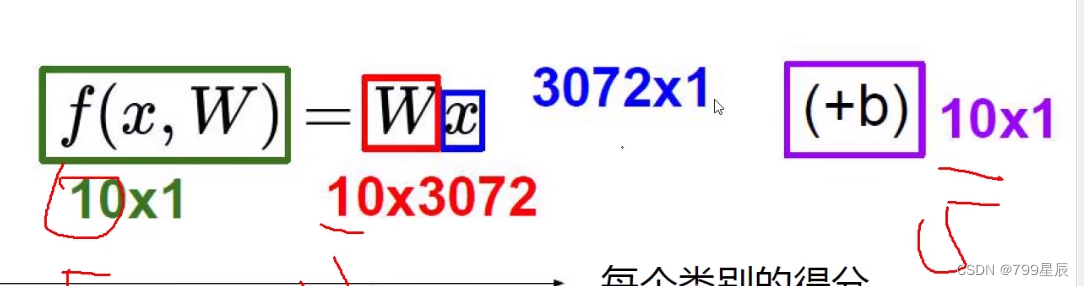
理解:10表示类别,有几类,x表示有几个像数点。相当于y=kx+b
其中W占主导,b是微调。
示例:
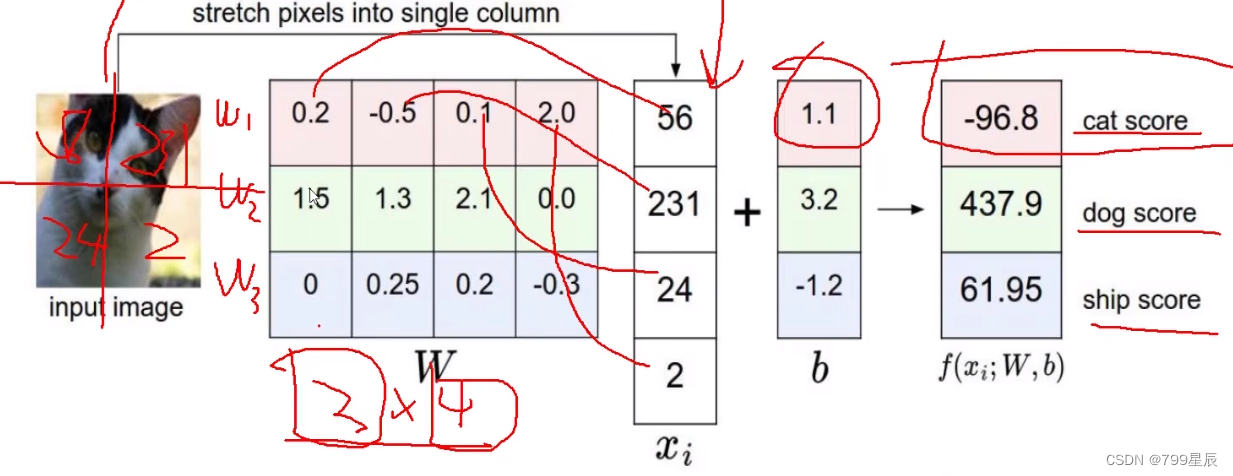
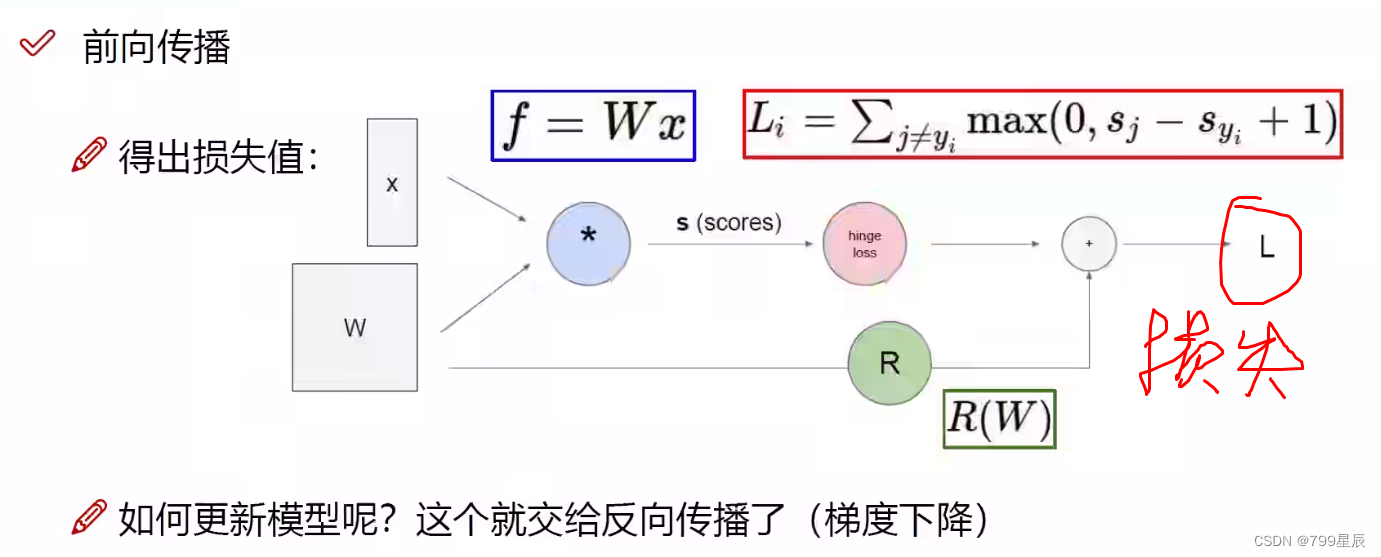
(3)损失函数

+1相当于+🔺,差值超过1,认为无损失

(3)Softmax分类器
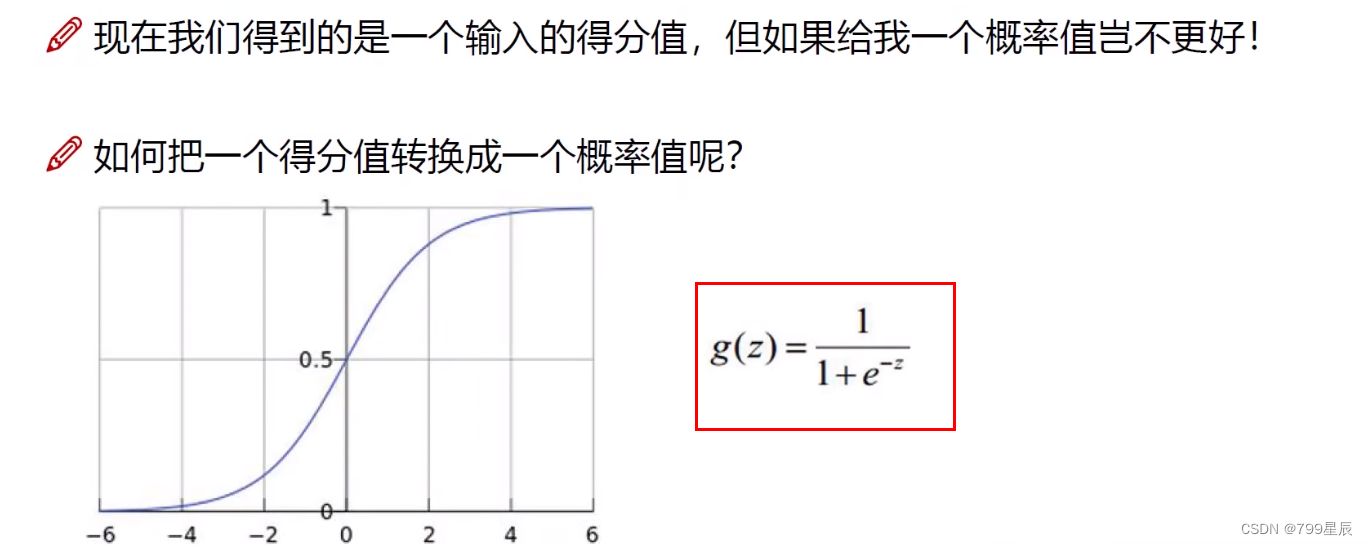
分类过程:输入数据----通过得分函数得到得分值—做一个e的x次幂的映射,扩大差距—进行归一化(即求概率)—通过对数函数求损失(越接近1损失越小,接近0损失大)

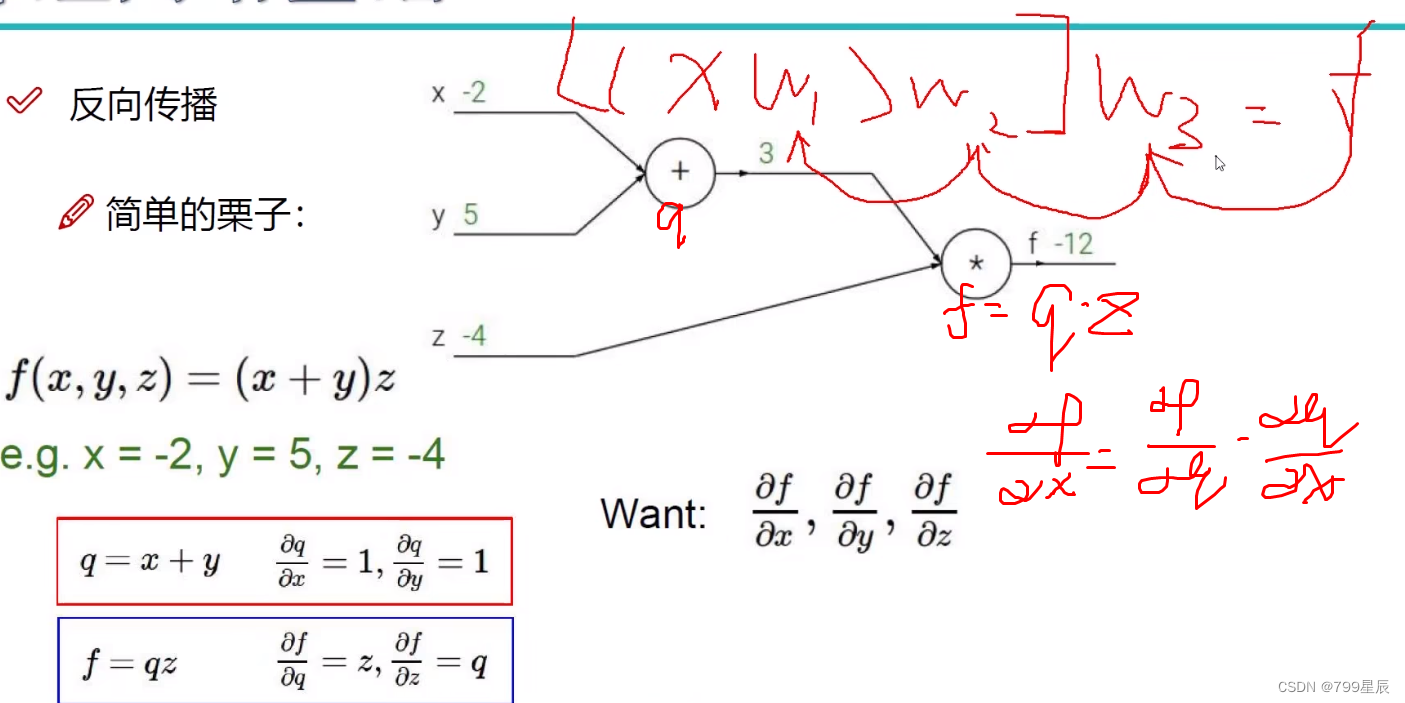
梯度是一步一步传的。
神经网络的整体架构
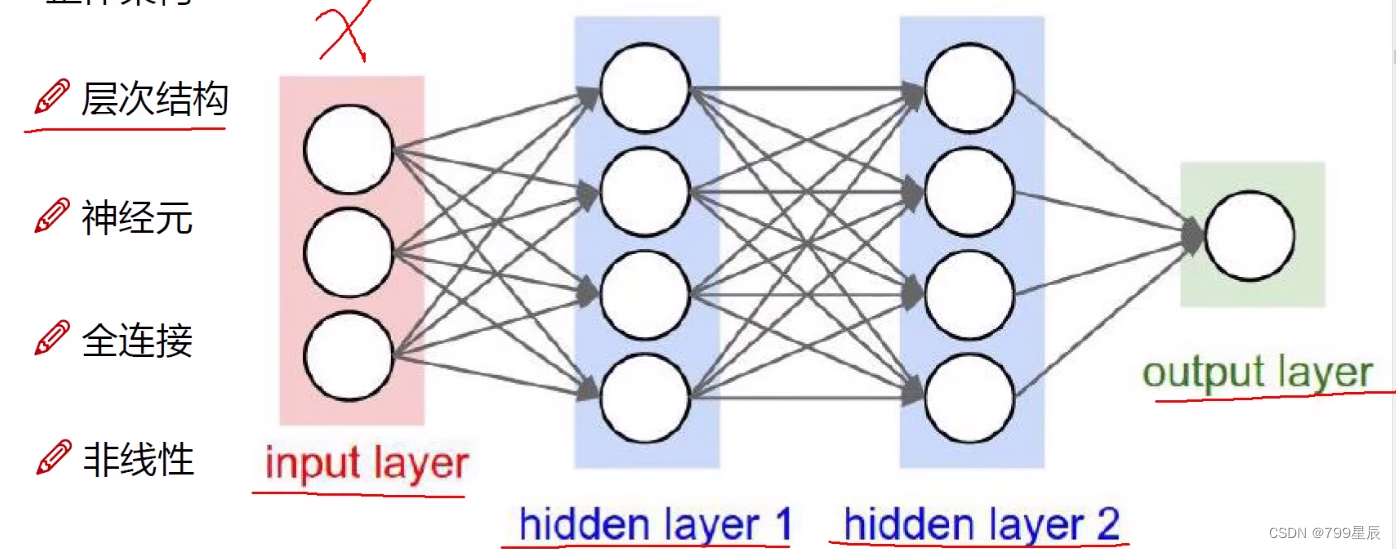
input layer: 输入数据的特征数
hidden layer 1:隐层1,对原始特征进行一个变换,使得数据更能让计算机识别
连接的线是一个3*4的权重参数矩阵。—特征提取
理论情况下,神经元越多分类越准确,但是存在过拟合问题。
过拟合:判断非常准确,不好判断出样本中那些可能异常的点,强行区分出来。过拟合导致泛化能力比较弱。惩罚力度越小,越过拟合。尽可能在不过拟合的情况下做好。
梯度:矩阵的导数。梯度为0,不进行更新、传播。
激活函数:Sigmoid、Relu















 5617
5617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









