







今天小编给大家展示的主题是一种重要的回归方法:Lasso回归,在该篇博文中会讲解该方法的基本理论知识和实际应用,将理论和实际操作相结合来对该方法进行详细阐述。
我们先从传统的回归方法进行讲解,传统的回归方法是使用OLS(普通最小二乘法)通过最小目标变量和预测变量之间的残差平方和来获得最优的估计参数,传统的回归方式的损失函数为:
其中,y是实际观测到的目标变量,X是对应的特征矩阵,β是待求解的系数向量。
通过最小化残差平方和的损失函数,OLS试图找到一组最佳的系数β,使得预测值Xβ与真实值y之间的平方误差最小化。这样,OLS寻求的系数向量β能够最好地拟合样本数据,并产生最小的预测误差。
OLS是一种常用的回归分析方法,尤其适用于特征与目标变量之间具有线性关系的情况。它通过最小化残差平方和来确定最佳的系数估计,不涉及额外的正则化项或惩罚项。
但是使用OLS估计会出现两个问题,第一就是预测的准确率,OLS估计经常会出现较低的偏差和较高的方差。在机器学习中,偏差是指模型在不同样本集上真实值和预测值之间的差异,简单地说,偏差衡量了模型对真实关系的拟合能力,如果偏差较低,模型能够相对准确地拟合数据中的关系,在这种情况下,模型可能在训练集上表现得很好,但是在测试集上的性能还需要检验。方差是描述模型对不同训练数据敏感程度的指标。简单来说,方差衡量了模型在不同数据集上的预测波动结果和差异程度,具体来说,方差衡量了模型的过拟合情况。如果方差较高,说明模型对于数据中的噪声或者随机性过于敏感,导致模型在不同数据集上的预测结果产生较大差异。这种情况被称为过拟合,模型在训练集数据上表现得很好,但是在测试集或者新的数据上预测性能下降。
因此,在构建机器学习模型时,需要平衡偏差和方差之间的关系,以找到一个适当的模型复杂度,能够在模型中取得较低的偏差和方差,这被称为偏差与方差折衷。可以通过将特征系数降低或者设置为0来提高模型的预测精准率。通过牺牲一些偏差来降低模型的方差从而提升模型整体的预测精准率。第二就是模型的可解释性,我们经常需要的是对模型影响最大的特征来解释模型就可以,而不是将所有的因素都考虑进行。
于是产生了两种方法来提高OLS估计,分别是subset selection(子集选择)和ridge regression(岭回归)。subset selection受特征变化影响较大,一旦模型基于选择的特征集进行训练,新增的特征不会得到考虑,需要重新进行特征选择并且会降低模型预测的精准率。ridge regression会将特征的系数下降,但是却不会将系数降为0,因此模型的解释性相对缺乏。Lasso回归实现了两者的结合,既将特征的系数进行压缩同时通过将一些特征系数压缩到0,留下最重要的特征实现特征选择的效果。
Lasso回归和岭回归对OLS估计对损失函数发生了变化,添加正则化项,Lasso回归对损失函数添加了L1正则项,岭回归对损失函数添加了L2正则项,他们分别对应的损失函数如下:
Lasso回归损失函数:
其中,y是因变量,X是自变量矩阵,β是特征系数,λ是正则化参数。
损失函数由两部分组成:第一部分是普通最小二乘法的残差平方和,第二部分是L1范数(绝对值之和)的惩罚项;
L1惩罚项具有稀疏性,可以使得一些特征的系数变为零,实现特征选择。
岭回归损失函数:
其中,y是因变量,X是自变量矩阵,β是特征系数,λ是正则化参数。
损失函数同样由两部分组成:第一部分是普通最小二乘法的残差平方和,第二部分是L2范数(平方和)的惩罚项;
L2惩罚项有助于控制特征系数的大小,减小特征间的相关性,避免过拟合。
以上是关于Lasso回归的一些基础理论知识,如果大家对这一块的理论知识相深入研究的话,可以自行查阅相关的理论知识书籍,接下来,给大家分享一下Lasso回归在实际中的应用,Lasso回归在实际应用中主要侧重在以下几个方面:一、预测建模,Lasso回归可用于建立回归模型,对数据进行预测。通过降低模型复杂度和提高泛化能力,Lasso回归可以在预测模型中发挥重要作用。在经济领域经常可以见到使用Lasso回归来对某目标变量进行预测的实际应用场景;二、特征选择,Lasso回归非常适合用于特征选择,通过其L1正则化项的作用,可以将不相关或冗余的特征系数压缩为零,从而达到特征选择的效果。特征选择方面的应用在金融、医学等领域应用比较广泛,较常用的步骤是先通过Lasso回归选择出对目标变量影响最大的特征,然后再利用这些特征构建模型,在一定程度上降低了模型的过拟合,提升了模型的泛化能力同时提升了模型的可解释性。
接下来,我们将使用代码来对Lasso回归进行实际操作展示,涉及的内容是特征选择这一部分,回归模型的构建比较简单不进行展示。模型使用的数据来自于Kaggle网站中的Heart Attack Analysis & Prediction Dataset数据集,该数据结构如下:
| 特征 | 中文含义 |
| age | 患者的年龄 |
| sex | 患者的性别 |
| cp | 胸痛类型 数值1:典型心绞痛 数值2:非典型心绞痛 数值3:非心绞痛性疼痛 数值4:无症状 |
| trtbps | 静息血压(单位:毫米汞柱) |
| chol | 胆固醇含量(单位:mg/dl,通过BMI传感器获取) |
| fbs | (空腹血糖 > 120 毫克/分升)(1 = 是;0 = 否) |
| restecg | 静息心电图结果 数值0:正常 数值1:出现ST-T波异常(T波倒置和/或ST段抬高或压低 > 0.05 毫伏) 数值2:根据Estes标准显示可能或明确的左心室肥大 thalach:达到的最大心率 |
| thalachh | 0 = 心脏病发作几率较低;1 = 心脏病发作几率较高 |
| exng | 运动诱发型心绞痛(1 = 是;0 = 否) |
| oldpeak | 之前的峰值 |
| slp | 倾斜度 |
| caa | 主要血管数量(0-3) |
| thall | 血液病 |
| output | 0 = 心脏病发作几率较低;1 = 心脏病发作几率较高 |
数据展示如下,一共有300多条数据,无缺失值数据,因此不用进行其他处理
接下来我们将使用Lasso回归选择出这众多特征中对发病结果影响最大的特征,首先,我们先导入Lasso与画图相关的程序包
import pandas as pd
from sklearn.linear_model import Lasso
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LassoCV
import numpy as np
import matplotlib.pyplot as plt接下来,我们对数据进行读取,并对特征变量数据进行标准化处理,并且使用交叉验证训练验证模型确定最优的惩罚系数,具体代码如下
data = pd.read_csv('./data/heart.csv')
X=data[['age','sex','cp','trtbps','chol','fbs','restecg','thalachh','exng','oldpeak','slp','caa','thall']]
y = data[['output']]
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 创建LassoCV模型
lasso_cv = LassoCV(cv=10,random_state=0) # cv表示交叉验证折数
# 训练模型
lasso_cv.fit(X_scaled, y)
# 输出最佳alpha值
best_alpha = lasso_cv.alpha_
print("Best alpha value:", best_alpha)我们这边得出的最优参数为0.0050247586624487875

对于最优惩罚系数的确定,我们可以通过绘制Lasso回归路径图进行查看,具体代码如下
# 获取alpha路径和对应的系数
alphas = lasso_cv.alphas_
mse = np.mean(lasso_cv.mse_path_, axis=1)
# 绘制Lasso路径图
plt.figure(figsize=(10, 6))
plt.plot(np.log10(lasso_cv.alphas_), lasso_cv.mse_path_.mean(axis=1))
plt.axvline(np.log10(best_alpha), linestyle='--', color='r', label='Best Alpha')
plt.xlabel('log10(alpha)')
plt.ylabel('Mean Squared Error')
plt.title('Lasso Path')
plt.legend()
plt.grid(True)
plt.show()运行的结果如图所示:
在日常的学习和科研中我们在使用Lasso回归选择变量的时候,还需要看一下各个特征变量系数随着惩罚系数变化图,折线图显示会比较好看,并且直观,因此,我们这里使用折线图来绘制特征变量系数变化图
# 设置不同的alpha值范围
alpha_values = [0.001,0.002,0.005,0.008,0.01,0.1,1,10,50,100]
lasso = Lasso(max_iter=10000)
coefs = []
num_nonzero_coefs = []
for a in alpha_values:
lasso.set_params(alpha=a)
lasso.fit(X_scaled, y)
coefs.append(lasso.coef_)
num_nonzero_coefs.append(np.sum(lasso.coef_ != 0))
ax = plt.gca()
ax.plot(alpha_values, coefs)
ax.set_xscale('log')
plt.axis('tight')
plt.xlabel('Log(alpha)')
plt.ylabel('Coefficients')
plt.title('Lasso coefficients as a function of alpha');
plt.show()绘制结果如下图所示:
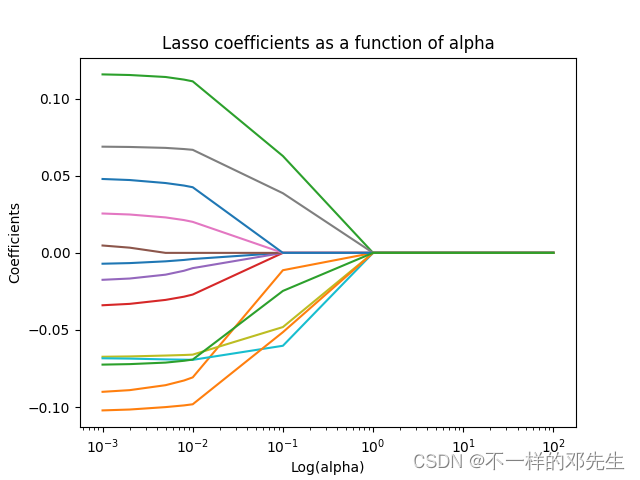
大家可以看见随着惩罚参数的变大,有很多特征变量的系数已经被压缩为0,最后我们还需要看一下最终选择出来的特征变量是哪些?在后续的操作中我们将会使用筛选出来的特征变量进行与研究主题相关的建模
# 创建Lasso回归模型
lasso = Lasso(alpha=0.0050247586624487875)
# 拟合模型并选择特征变量
lasso.fit(X_scaled, y)
# 获取特征变量的Lasso系数
coef = lasso.coef_
# 筛选被选择的变量
selected_features = [feature for feature, coef_value in zip(X.columns.tolist(), coef) if coef_value != 0]
# 输出选择的特征变量名称
print("Selected Features:")
for feature in selected_features:
print(feature)在本次案例中,我们筛选出来了一共筛选出来了12个对发病率影响最重要的特征,有一个特征已经被我们筛出去了,剩余的特征分别是:age、sex、cp、trtbps、chol、restecg、thalachh、exng、
oldpeak、slp、caa、thall,如果还有后续的研究,我们将会使用这些筛选出来的特征进行模型构建,大家可以看见,经过这样操作之后,后面构建的模型的解释性和准确性都会有一定程度的提升,对于特征数据的代码如下:
# 创建Lasso回归模型
lasso = Lasso(alpha=0.0050247586624487875)
# 拟合模型并选择特征变量
lasso.fit(X_scaled, y)
# 获取特征变量的Lasso系数
coef = lasso.coef_
# 筛选被选择的变量
selected_features = [feature for feature, coef_value in zip(X.columns.tolist(), coef) if coef_value != 0]
# 输出选择的特征变量名称
print("Selected Features:")
for feature in selected_features:
print(feature)以上就是Lasso回归的实践内容,大家想做相关的实践操作的话,可以按照我的这个代码仿照进行操作,对于实验数据集,大家如果不想去官网下载的话,可以关注我们的公众号“明天科技屋”,数据集会同步到公众号,希望大家多多关注和支持!
















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











