









在SCI发表上,往往分数越高的SCI配图也越精美,但如何绘制美化图形呢?今天教大家一招。
彩色lasso图,使整个图形更加的美观,此外十折交叉验证的图可以根据不同的方差标注不同的颜色,使整个图形更加的便于理解,更加的直观表达出模型结果所包含的信息
以下为整个流程的R语言,所有代码
ggplot包,众所周知的绘图工具包
ggsci包主要用于图形的配色,其中Lancet,JAMA等著名期刊的配色
glmnet主要用于lasso模型的拟合,family参数主要用于定义所要拟合的模型,这次教学主要采用的是cox的生存分析,所以family=“cox”
survival包是生存分析的关键包
library(ggplot2)
library(ggsci)
library(glmnet)
library(survival)
rt=read.table("coxdata.txt", header=T, sep="\t")
rt$futime[rt$futime<=0]=0.003
x=as.matrix(rt[,c(3:ncol(rt))])
y=data.matrix(Surv(rt$futime, rt$fustat))
set.seed(56)
fit=glmnet(x, y, family="cox", maxit=1000)
plot(fit, xvar = "lambda", label = TRUE)
cvfit=cv.glmnet(x, y, family="cox", maxit=10000)
plot(cvfit)
abline(v=log(c(cvfit$lambda.min,cvfit$lambda.1se)),lty="dashed")
#美化
x <- coef(fit)
tmp <- as.data.frame(as.matrix(x))
tmp$coef <- row.names(tmp)
tmp <- reshape::melt(tmp, id = "coef")
tmp$variable <- as.numeric(gsub("s", "", tmp$variable))
tmp$coef <- gsub('_','-',tmp$coef)
tmp$lambda <- fit$lambda[tmp$variable+1]
# extract the lambda values
tmp$norm <- apply(abs(x[-1,]), 2, sum)[tmp$variable+1]
# compute L1 norm
head(tmp)
pdf("lambda.pdf",15,10)
ggplot(tmp,aes(log(lambda),value,color = coef)) +
geom_vline(xintercept = log(cvfit$lambda.min),
size=0.8,color='grey60',
alpha=0.8,linetype=2)+
geom_line(size=1) +
xlab("Lambda (log scale)") +
ylab('Coefficients')+
theme_bw(base_rect_size = 2)+
scale_color_manual(values= c(pal_npg()(10),
pal_d3()(10),
pal_jco()(3),
pal_lancet()(10),
pal_aaas()(10),
pal_simpsons()(10),
pal_gsea()(10),
pal_jama()(10)))+
scale_x_continuous(expand = c(0.01,0.01))+
scale_y_continuous(expand = c(0.01,0.01))+
theme(panel.grid = element_blank(),
axis.title = element_text(size=15,color='black'),
axis.text = element_text(size=12,color='black'),
legend.title = element_blank(),
legend.text = element_text(size=12,color='black'),
legend.position = 'right')+
annotate('text',x = -3.3,y=0.26,
label='Optimal Lambda = 0.0351',
color='black')+
guides(col=guide_legend(ncol = 2))
dev.off()
xx <- data.frame(lambda=cvfit[["lambda"]],
cvm=cvfit[["cvm"]],
cvsd=cvfit[["cvsd"]],
cvup=cvfit[["cvup"]],
cvlo=cvfit[["cvlo"]],
nozezo=cvfit[["nzero"]])
xx$ll<- log(xx$lambda)
xx$NZERO<- paste0(xx$nozezo,' vars')
pdf("cvlasso.pdf",7,7)
ggplot(xx,aes(ll,cvm,color=NZERO))+
geom_errorbar(aes(x=ll,ymin=cvlo,ymax=cvup),
width=0.05,size=1)+
geom_vline(xintercept = xx$ll[which.min(xx$cvm)],
size=0.8,color='grey60',alpha=0.8,
linetype=2)+
geom_point(size=2)+
xlab("Log Lambda")+
ylab('Partial Likelihood Deviance')+
theme_bw(base_rect_size = 1.5)+
scale_color_manual(values= c(pal_npg()(10),
pal_d3()(10),
pal_lancet()(10),
pal_aaas()(10)))+
scale_x_continuous(expand = c(0.02,0.02))+
scale_y_continuous(expand = c(0.02,0.02))+
theme(panel.grid = element_blank(),
axis.title = element_text(size=15,
color='black'),
axis.text = element_text(size=12,
color='black'),
legend.title = element_blank(),
legend.text = element_text(size=12,
color='black'),
legend.position = 'bottom')+
annotate('text',x= -5.3,y=12.4,
label='Optimal Lambda = 0.0351',
color='black')+
guides(col=guide_legend(ncol = 6))
dev.off()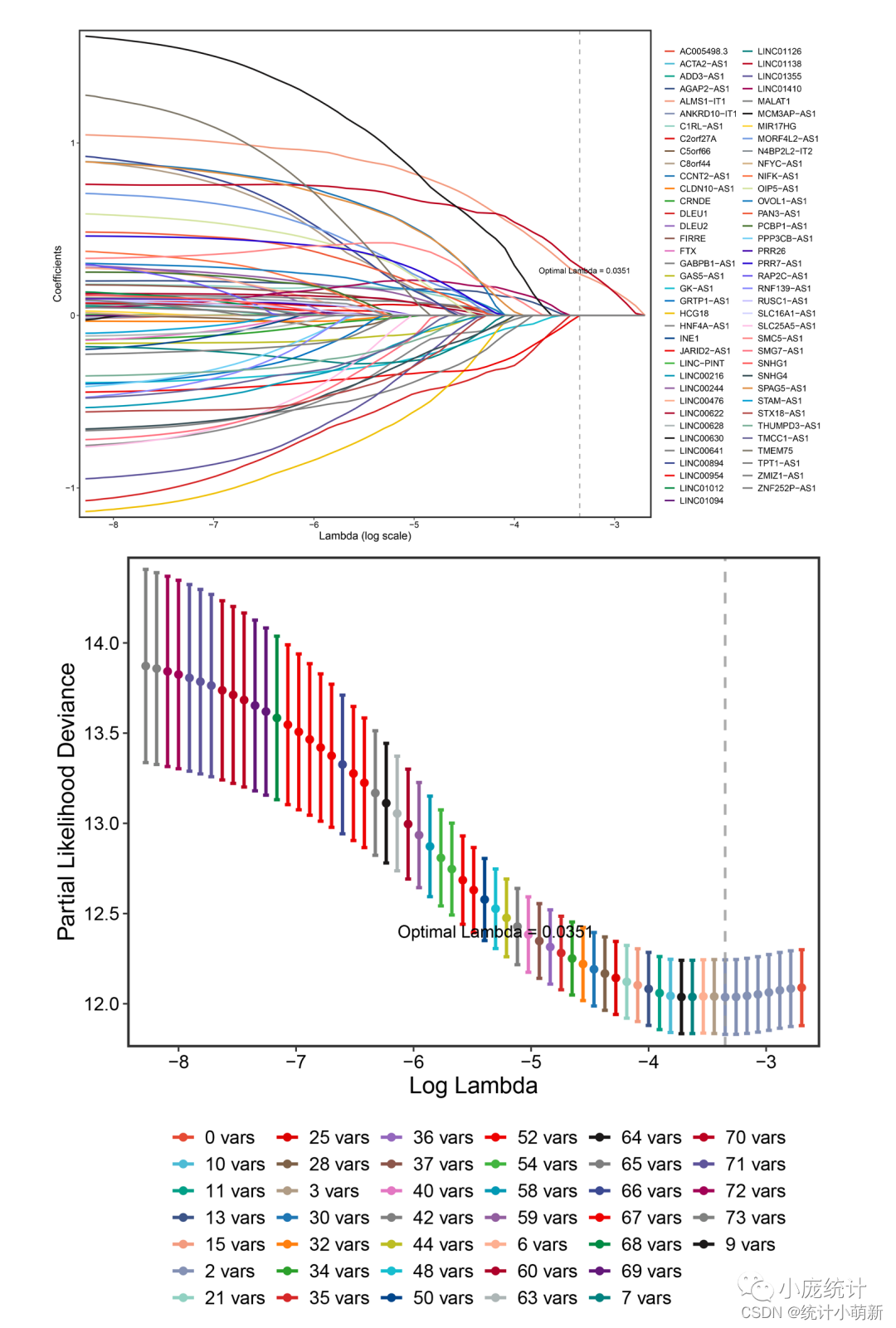
喜欢的朋友可以点击收藏
也可以关注公众号:小庞统计


















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











