






文章汇总
流程解读
预训练阶段
这阶段没有使用k-way n-shot这些训练方法,总体来看像是添了个DyCE模块的知识蒸馏。
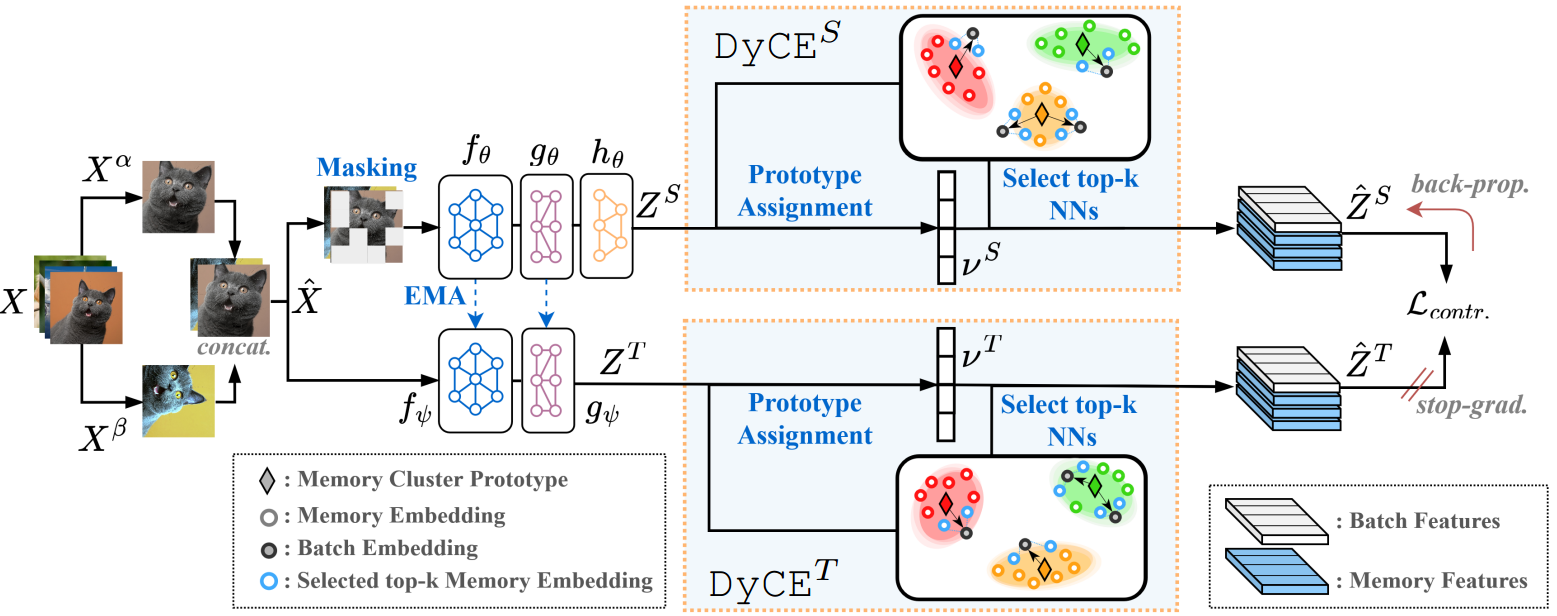
预训练阶段的目标是训练学生编码器(
f
θ
f_\theta
fθ)用于后续推理阶段。
f
(
⋅
)
f(\cdot)
f(⋅)为骨干特征提取器,
g
(
⋅
)
,
h
(
⋅
)
g(\cdot),h(\cdot)
g(⋅),h(⋅)分别为投影和预测多层感知器(MLP)。
如图所示,teacher没有MLP
h
(
⋅
)
h(\cdot)
h(⋅),
Z
S
=
h
θ
∘
g
θ
∘
f
θ
(
u
(
X
^
)
)
,
Z
T
=
g
ψ
∘
f
ψ
(
X
^
)
Z^S=h_\theta \circ g_\theta \circ f_\theta(u(\hat X)),Z^T= g_\psi \circ f_\psi(\hat X)
ZS=hθ∘gθ∘fθ(u(X^)),ZT=gψ∘fψ(X^)
u
(
X
^
)
u(\hat X)
u(X^)是指对
X
^
\hat X
X^进行了mask。
无监督的动态集群内存(DyCE)
(本人这段看得有点吃力,欢迎读者对这块解读进行指正)
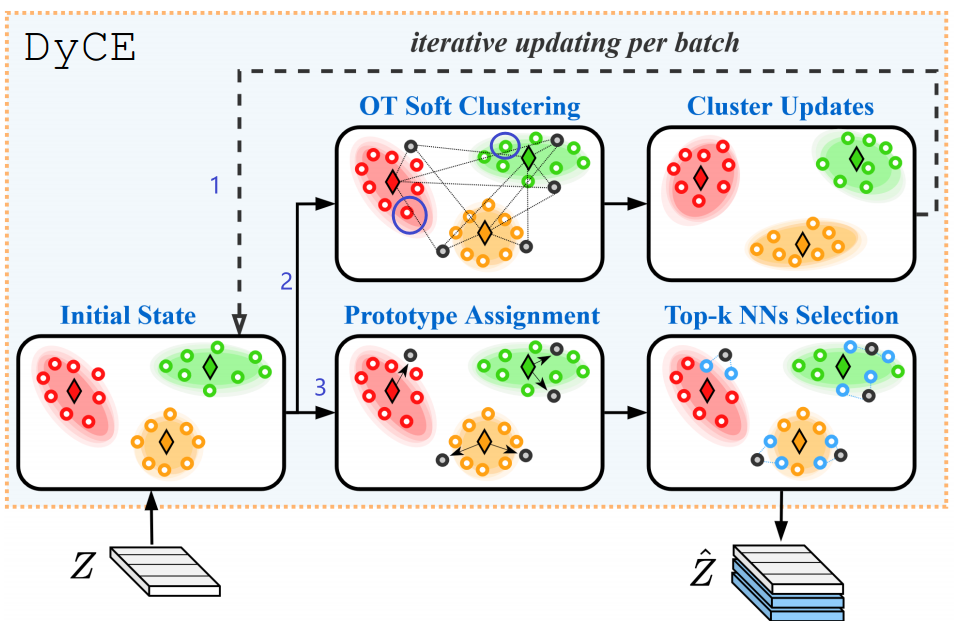
这里通过Top-K近邻算法,对一张图片总共有W个patch,一开始用前8个patch进行初始化得到Initial State(因为图中Initial State 每个群有8个点),之后不断循环"2->1这个过程"来更新状态图。
这里解释一下"2->1这个过程":如图采用的Top-3近邻算法,新来的patch经过线条2会选择离自己最近的群质心之后归于该群,而每个群最老的点(如图在被紫色圈圈住的点)会被淘汰,之后通过线条1来更新状态,之后不断该过程,直至过完这张图片所有patch。
最后通过线条3,将每个群的质心,这里总共3个群的质心的patch加入到
Z
Z
Z中,得到
Z
^
\hat Z
Z^。
一个疑问:DyCE的图中
Z
^
\hat Z
Z^应该画错了,应该是3个蓝色块Memory Features,图中只画出了2个,应该像上面预训练阶段那个图才对。
推理阶段(OpTA)

这里是3way 3shot,Q=8,通过
f
θ
f_\theta
fθ得到支持集每个way的质心,接着
π
∗
\pi^*
π∗将支持集原型映射到查询嵌入所占用的区域。
π
∗
\pi^*
π∗是在上面DyCE获得的一个最近距离计算函数。可以看到在Linear Classifer中查询集每张图片都归属于某个类的质心。
讨论的问题
该文章在OpTA用到了transductive的思想,但实验对比的是inductive的方法。
https://www.zhihu.com/question/639862915
关于transductive与inductive的解释:
一般我们都是inductive。
consider: a) “inductive few-shot”, where only a few labelled samples are available during training and prediction is performed on each test input independently, and b) “transductive few-shot”, where prediction is performed on a batch of (non-labelled) test inputs, allowing to take into account their joint distribution.
考虑以下两种情况:a)“归纳式少样本学习”,在训练过程中只有少量标记样本可用,预测是在每个测试输入独立地进行的;b)“传递式少样本学习”,预测是在一批(未标记)测试输入上进行的,允许考虑到它们的联合分布。
摘要
无监督的少样本学习(U-FSL)希望通过在训练时放弃对注释的依赖来弥合这一差距。对比学习方法在U-FSL领域的成功引起了我们的兴趣,我们从结构上探讨了它们在预训练和下游推理阶段的缺点。我们提出了一种新的动态聚类记忆(DyCE)模块,以促进高度可分离的潜在表示空间,以增强预训练阶段的正采样,并将隐式类水平的见解注入无监督对比学习中。然后,我们在少样本推理阶段处理样本偏差问题,这在某种程度上被忽视了,但很关键。我们提出了一种迭代的基于最优传输的分布对齐(OpTA)策略,并证明它有效地解决了这个问题,特别是在FSL方法受样本偏差影响最大的少样本场景下。我们稍后将讨论DyCE和OpTA是一种新颖的端到端方法(我们称之为BECLR)的两个相互交织的部分,它们建设性地放大了彼此的影响。然后,我们提出了一套广泛的定量和定性实验,以证实BECLR在所有现有的U-FSL基准中设置了一个新的最先进的技术(据我们所知),并且显著优于当前最好的基线(代码库可在GitHub上获得)。
1.介绍
在深度表示学习中获得可接受的性能是以大量数据收集、费力的注释和过度的监督为代价的。当我们转向更复杂的下游任务时,这变得越来越令人望而却步;换句话说,监督表示学习根本无法扩展。与之形成鲜明对比的是,人类可以在没有广泛监督的情况下,从少量样本中快速学习新任务。Few-shot学习(FSL)希望通过使用度量学习等一系列方法来弥合人与机器之间的根本差距(Wang等人,2019;Bateni et al ., 2020;Yang et al, 2020)、元学习(Finn et al, 2017;Rajeswaran等人,2019;Rusu等人,2018)和概率学习(Iakovleva等人,2020;Hu et al, 2019;Zhang et al, 2021)。到目前为止,FSL在许多基准测试中在监督设置中显示出有希望的结果(Hu et al, 2022;Singh & Jamali-Rad, 2022;Hu et al ., 2023b);然而,监管的必要性仍然存在。这导致了一种新的鸿沟的出现,称为无监督FSL (U-FSL)。U-FSL的阶段与有监督的相似之处是一样的:在一个大的基本类数据集上进行预训练,然后快速适应和推断未见过的少样本任务(新类)。这里的额外挑战是在预训练期间缺少标签。U-FSL方法由于其实际意义和与自我监督学习的密切联系,最近引起了人们的广泛关注。
U-FSL预训练的目标是学习一个特征提取器(即编码器)来捕获未标记数据的全局结构。接下来是冻结编码器的快速适应,通常通过简单的线性分类器(例如,逻辑回归分类器)来完成看不见的任务。这里的文献主体可以概括为两大类:(i)基于元学习的预训练,其中为编码器的情景训练生成类似下游推理的合成少镜头任务(Hsu等人,2018;Khodadadeh等人,2019;2020);(ii)(非情景)迁移学习方法,其中预训练归结为学习适合下游少量任务的最佳表示(Medina等人,2020;Chen等,2021b;2022;Jang et al ., 2022)。最近的研究表明,(更)复杂的元学习方法是数据效率低下的(Dhillon等人,2019;Tian etal ., 2020),并且基于迁移学习的方法优于元学习方法。更具体地说,这一领域的最新技术目前被基于迁移学习鸿沟的对比学习方法所占据,这些方法在各种基准测试中取得了最佳表现(Chen et al ., 2021a;Lu et al, 2022)。对比表征学习的基本思想(Chen et al ., 2020a;他等人,2020)的目的是在表示空间中吸引“正”样本,同时排斥“负”样本。为了有效地实现这一点,一些对比学习方法结合了内存队列,以减轻对更大批处理规模的需求(庄等人,2019;他等人,2020;Dwibedi等,2021;Jang et al ., 2022)。
核心理念1:超越实例级对比学习。在无监督设置下操作,对比FSL方法通常只在实例级别强制一致性,其中批处理中的每个图像及其扩展对应于一个唯一的类,这是一个不现实但似乎不可避免的假设。这里的陷阱是,在同一批中存在的潜在阳性样本可能会在表示空间中被排斥,从而阻碍整体性能。我们认为,在无监督对比范式中注入类(或成员)级别的洞察力是必不可少的。我们解决这个问题的关键思想是通过引入由动态更新原型表示的固有成员集群来扩展内存队列的概念,同时避免了对大批处理大小的需求。由于采用了一种新的动态聚类记忆(DyCE)模块,这使得所提出的预训练方法能够对更有意义的正对进行采样。在保持固定内存大小(与队列相同)的同时,DyCE有效地构建和动态更新可分离的内存集群。
核心思想二:解决FSL中固有的样本偏差。基础类(预训练)和新类(推理)要么是同一数据集的互斥类,要么来自不同的数据集,本文(第5节)研究了这两种情况。这种分布的变化在推理时对快速适应新类提出了重大挑战。由于支持样本通常不能代表较大的未标记(即查询)集,因此在few-shot任务中只能访问少数标记(即支持)样本,这进一步加剧了这种情况。我们将这种现象称为样本偏差,强调它被大多数(U-)FSL基线所忽视。为了解决这个问题,我们在监督推理步骤中引入了一个基于最优传输的分布对齐(OpTA)附加模块。OpTA没有施加额外的可学习参数,但在最后的监督推理步骤之前,有效地对齐标记支持和未标记查询集的表示。稍后在第5节中,我们将展示这两个新型模块(DyCE和OpTA)实际上是交织在一起并相互放大的。结合这两个关键思想,我们提出了一种端到端的U-FSL方法,称为批增强对比学习(BECLR)。我们的主要贡献可以概括如下
I。我们引入BECLR在结构上解决了U-FSL中现有技术在预训练和推理阶段的两个关键缺点。在预训练中,我们建议通过一种新的动态聚类记忆(DyCE)将内隐的类级洞察力注入到对比学习框架中。通过DyCE的迭代更新有助于建立高度可分离的分区潜在空间,从而促进更有意义的正采样。
2。然后,我们在BECLR的推理阶段通过一个新的附加模块(称为OpTA)阐明并解决U-FSL中固有的样本偏差。我们表明,这种策略有助于缓解查询集和支持集之间的分布转移。这体现了它在low-shot场景中的显著影响,其中FSL方法受样本偏差的影响最大。
3。我们进行了广泛的实验,以证明BECLR在所有已建立的U-FSL基准中设定了新的核心状态;例如miniImageNet(见图1)、tieredImageNet、CIFAR-FS、FC100,据我们所知,它们的表现明显优于所有现有的基线(在单次设置中分别高达14%、12%、15%和5.5%)。
2 相关工作
自我监督学习(SSL)
它已经从各种角度进行了探讨(Balestriero等人,2023)。深度度量学习方法(Chen et al ., 2020a;他等人,2020;Caron等,2020;Dwibedi等人,2021),建立在对比损失的原则之上,并鼓励图像的语义转换视图之间的相似性。冗余减少方法(Zbontar等,2021;Bardes等人,2021)通过分析它们的交叉协方差矩阵来推断输入之间的关系。自蒸馏方法(Grill等,2020;Chen & He, 2021;Oquab等人,2023)将不同的视图传递给两个独立的编码器,并通过预测器将一个映射到另一个。这些方法中的大多数构建了一个对比设置,其中对称或(更常见的)不对称Siamese网络(Koch等人,2015)使用infoNCE(Oord等人,2018)损失的变体进行训练。
无监督的少样本学习(U-FSL)
这里的目标是从大型未标记的基类数据集预训练模型,类似于SSL,但经过调整,以便它可以快速推广到看不见的下游FSL任务。元学习方法(Lee et al, 2020;Ye等人,2022)生成用于预训练的合成学习集,模拟下游FSL任务。在这里,PsCo (Jang等人,2022)利用学生-教师动量网络和最优传输从内存队列中创建伪监督情节。尽管形式优雅,但元学习在U-FSL中被证明是数据效率低下的(Dhillon等人,2019;田等人,2020)。另一方面,迁移学习方法(Li et al ., 2022;Antoniou & Storkey, 2019;Wang等人,2022a)遵循一种更简单的非情景预训练,专注于表征质量。值得注意的是,对比学习方法,如PDA-Net (Chen et al ., 2021a)和UniSiam (Lu et al ., 2022),目前是最先进的。我们提出的方法也在对比学习的前提下运行,但也采用了一个动态集群内存模块(DyCE),在实例级对比框架中注入成员/类级洞察力。在这里,SAMPTransfer (Shirekar等人,2023)采取了不同的路径,并试图通过图神经网络上的消息传递来嵌入隐含的全局成员级见解;然而,与Conv4相比,这种方法的计算负担严重阻碍了它在更深的主干上的性能(并扩展到更深的主干)。
(U-)FSL中的样本偏差
(U-)FSL的部分挑战在于基类和新类之间的域差异。更糟糕的是,仅从少数支持样本中估计类分布是有偏差的,我们称之为样本偏差。为了解决样本偏差,Chen等人(2021a)提出使用额外的基类图像来增强支持集,Xu等人(2022)项目支持样本远离任务质心,而Yang等人(2021)使用校准分布来绘制更多的支持样本,但所有这些方法都依赖于基类特征。另一方面,Ghaffari等人(2021);Wang等人(2022b)利用Firth偏倚减少来减轻逻辑分类器本身的偏倚,但容易过度拟合。相比之下,所提出的OpTA模块不需要微调,也不依赖于预训练数据集。
3 .问题陈述:无监督少样本学习
我们遵循文献中最常用的设置(Chen et al ., 2021a;b;Lu et al ., 2022;Jang等人,2022),其中包括:一个无监督的预训练,然后是一个有监督的推理(也称为微调)策略。形式上,我们考虑一个大型的未标记数据集 D t r = { x i } D_{tr}=\{x_i\} Dtr={xi},其中包含所谓的“基本”类,用于预训练模型。然后,推理阶段涉及将模型转移到看不见的少量下游任务 T i T_i Ti,从所谓的“新颖”类 D t s t = { ( x i , y i ) } D_{tst}=\{(x_i,y_i)\} Dtst={(xi,yi)}的较小标记测试数据集中提取,其中 y i y_i yi表示样本 x i x_i xi的标签。每个任务 T i T_i Ti由两部分组成 [ S , Q ] [S,Q] [S,Q]:(i)支持集 S S S,模型从中学习适应新类;(ii)查询集 Q Q Q,模型在此上进行评估。支持集 S = { x i s , y i s } i = 1 N K S=\{x^s_i,y_i^s\}^{NK}_{i=1} S={xis,yis}i=1NK是通过从 N N N个不同的类别中抽取 K K K个有标签的随机样本来构建的,从而得到所谓的(N-way, K-shot)设置。查询集 Q = { x j q } j = 1 N Q Q=\{x^q_j\}^{NQ}_{j=1} Q={xjq}j=1NQ包含 N Q NQ NQ(其中 Q > K Q>K Q>K)个未标记样本。基类和新类是互斥的,即 D t r D_{tr} Dtr和 D t s t D_{tst} Dtst的分布是不同的。
4 .提倡的方法:BECLR
4.1 无监督预训练
我们根据对比表征学习建立了BECLR的无监督预训练策略。这里的核心思想是在表示空间中有效地吸引“正”样本(即同一图像的增强),同时排斥“负”样本。然而,传统的对比学习方法在实例级别解决这个问题,其中批处理中的每个图像必须对应于一个独特的类(一个统计上不切实际的假设!)因此,批处理中存在的潜在阳性可能被视为阴性,这可能对性能产生不利影响。解决这个问题的一个常见策略是使用内存队列(Wu等人,2018;庄等,2019;他等人,2020)。例外的是,PsCo (Jang等人,2022)使用最优传输从先入先出的内存队列中进行采样,并在基于元学习的框架中生成伪监督的少样本任务,而NNCLR (Dwibedi等人,2021)使用最近邻方法在对比损失中生成更有意义的正对。然而,这些内存队列对潜在空间中的全局成员关系(即类级别信息)仍然是无关的。相反,我们建议在提出的端到端方法BECLR的预训练阶段通过一种新的记忆模块(DyCE)注入成员/类级洞察力。图2提供了在BECLR中提出的对比预训练框架的示意图,图3描述了DyCE的机制。
BECLR预训练策略。
在算法1中总结了BECLR的预训练管道,在附录e中可以找到一个类似pytorch的伪代码。现在让我们来介绍一下算法。设
ζ
a
,
ζ
b
∼
A
\zeta^a,\zeta^b \sim A
ζa,ζb∼A是来自所有可用增强集
A
A
A的两个随机抽样的数据增强,然后minibatch可以表示为
X
^
=
[
x
^
i
]
i
=
1
2
B
=
[
[
ζ
a
(
x
i
)
i
=
1
B
]
,
[
ζ
b
(
x
i
)
i
=
1
B
]
]
\hat X=[\hat x_i]^{2B}_{i=1}=[[\zeta^a(x_i)^B_{i=1}],[\zeta^b(x_i)^B_{i=1}]]
X^=[x^i]i=12B=[[ζa(xi)i=1B],[ζb(xi)i=1B]],其中
B
B
B为原始批大小(第一行,算法1)。如图2所示,我们采用类似于Grill等人(2020)的学生-教师(又名Siamese)不对称动量架构;Chen & He(2021)。设
u
(
⋅
)
u(\cdot)
u(⋅)为补丁屏蔽算子,
f
(
⋅
)
f(\cdot)
f(⋅)为骨干特征提取器(在我们的例子中是ResNets (He et al, 2016)),
g
(
⋅
)
,
h
(
⋅
)
g(\cdot),h(\cdot)
g(⋅),h(⋅)分别为投影和预测多层感知器(mlp)。教师权重参数(
ψ
\psi
ψ)是学生参数(
θ
\theta
θ)的指数移动平均(EMA)版本,即
ψ
←
m
ψ
+
(
1
−
m
)
θ
\psi \gets m\psi+(1-m)\theta
ψ←mψ+(1−m)θ,如Grill等人(2020),其中m是动量超参数,而
θ
\theta
θ是通过随机梯度下降(SGD)更新的。学生和教师表示
Z
S
,
Z
T
Z^S,Z^T
ZS,ZT大小均为
2
B
×
d
2B \times d
2B×d,其中d为潜在嵌入维数)可以如下得到:
Z
S
=
h
θ
∘
g
θ
∘
f
θ
(
u
(
X
^
)
)
,
Z
T
=
g
ψ
∘
f
ψ
(
X
^
)
Z^S=h_\theta \circ g_\theta \circ f_\theta(u(\hat X)),Z^T= g_\psi \circ f_\psi(\hat X)
ZS=hθ∘gθ∘fθ(u(X^)),ZT=gψ∘fψ(X^)(第2,3行)。
图2:提出的BECLR预训练框架概述。批处理图像
X
α
,
β
X^{\alpha,\beta}
Xα,β的两个增强视图都通过学生-教师网络,然后是DyCE内存模块。DyCE用有意义的正值增强原始批处理,并动态更新内存分区。
提取
Z
S
,
Z
T
Z^S,Z^T
ZS,ZT,他们被送入提出动态内存模块(DyCE),增强版本的批表示
Z
^
S
,
Z
^
T
\hat Z^S,\hat Z^T
Z^S,Z^T(这两个大小
2
B
(
k
+
1
)
2B(k+1)
2B(k+1)和
k
k
k表示的数量选择最近的邻居)生成(第4行)。最后,我们应用对比Eq。3在增强批表示
Z
^
S
,
Z
^
T
\hat Z^S,\hat Z^T
Z^S,Z^T(第5行)。在完成无监督pretraining,只有学生编码器(
f
θ
f_\theta
fθ)保存为后续推理阶段。
动态集群内存(DyCE)。
在没有标签的情况下,我们如何设法用有意义的真阳性来增强批次?我们引入DyCE:一种新的动态更新的聚类内存,在训练过程中调节表示空间,同时注入类似于分类识别的功能。我们在后面的第5节中演示了DyCE中的设计选择对预训练性能以及下游的少样本分类都有重大影响。
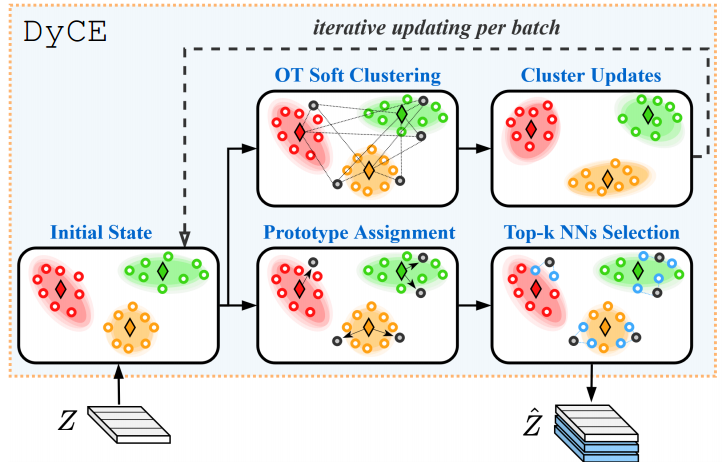
图3:提议的动态集群内存(DyCE)概述及其两条信息路径。
让我们先建立一些符号。我们考虑一个内存单元
M
M
M能够存储多达
M
M
M个潜在嵌入(每个大小为
d
d
d)。为了在DyCE中容纳集群成员,我们考虑多达
P
P
P个分区(或集群)
P
i
P_i
Pi在
M
=
[
P
1
,
.
.
.
,
P
p
]
M=[P_1,...,P_p]
M=[P1,...,Pp],每个都由存储在
Γ
=
[
y
1
,
.
.
.
,
y
p
]
\Gamma =[y_1,...,y_p]
Γ=[y1,...,yp]中的原型表示。每个原型
y
i
y_i
yi(大小为
1
×
d
1 \times d
1×d)是存储在分区
P
i
P_i
Pi中的潜在嵌入的平均值。如图3所示,在算法2中,DyCE由两条信息路径组成:(i) top-k邻居选择和批增强路径(图的底部分支),该路径使用
M
,
Γ
M,\Gamma
M,Γ的当前状态;(ii)通过动态聚类路径(顶部分支)迭代更新内存。DyCE将学生或教师嵌入作为输入(为了简洁,我们在这里使用
Z
Z
Z),并返回增强版本。我们还允许适应期
e
p
o
c
h
<
e
p
o
c
h
t
h
r
epoch < epoch_{thr}
epoch<epochthr(经验上为20-50 epoch),在此期间路径(i)未被激活,训练批次未被增强。

为了进一步详细说明,路径(i)首先根据欧几里得距离将
<
⋅
>
<\cdot>
<⋅>每个
z
i
∈
Z
z_i \in Z
zi∈Z分配给其最近的(
P
P
P之外的)内存原型
y
v
i
y_{v_i}
yvi。
v
v
v是一个索引向量(大小为2B×1),它包含所有批嵌入的这些原型分配(第4行,算法2)。接下来(在第5行),我们从与其分配的原型(
P
v
i
P_{v_i}
Pvi)对应的内存分区中选择
k
k
k个与
z
i
z_i
zi最相似的内存嵌入,并将它们存储在
Y
i
Y_i
Yi(大小为
k
×
d
k \times d
k×d)中。最后(在第6行),所有的
Y
i
,
∀
i
∈
[
2
B
]
Y_i,{\forall}i\in [2B]
Yi,∀i∈[2B]都被连接到增强的批处理中:
z
^
=
[
Z
,
Y
1
,
.
.
.
,
Y
2
B
]
\hat z=[Z,Y_1,...,Y_{2B}]
z^=[Z,Y1,...,Y2B]大小为
L
×
d
L \times d
L×d(其中
L
=
2
B
(
k
+
1
)
L=2B(k+1)
L=2B(k+1))。路径(ii)通过将其转换为最优运输问题(Cuturi, 2013)来解决迭代内存更新问题,给出:
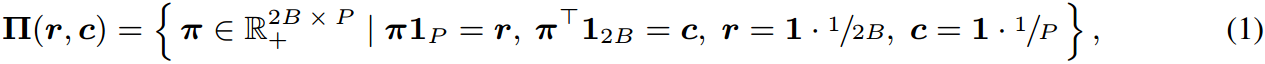
找到一个传输计划
π
\pi
π(从
Π
\Pi
Π)映射
Z
Z
Z到
Γ
\Gamma
Γ。其中,
r
∈
R
2
B
r \in R^{2B}
r∈R2B表示批嵌入
[
z
i
]
i
=
1
2
B
[z_i]^{2B}_{i=1}
[zi]i=12B的分布,
c
∈
R
p
c \in R^p
c∈Rp表示内存簇原型
[
γ
i
]
i
=
1
P
[\gamma_{i}]^P_{i=1}
[γi]i=1P的分布。Eq. 1中的最后两个条件强制
Z
Z
Z在
P
P
P个内存分区/集群中进行均衡分配(即统一分配)。得到最优运输计划
π
∗
\pi^*
π∗可表示为:
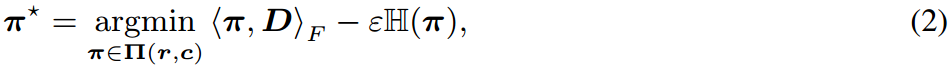
并使用Sinkhorn-Knopp (Cuturi, 2013)算法求解(第8行)。这里,
D
D
D是
Z
Z
Z和
Γ
\Gamma
Γ元素之间的配对距离矩阵(大小为2B × P),
<
⋅
>
<\cdot>
<⋅>F表示Frobenius点积,
ε
\varepsilon
ε是正则化项,
H
(
⋅
)
H(\cdot)
H(⋅)是香伦熵。接下来(在第9行),我们将当前批
Z
Z
Z的嵌入添加到M,并使用
π
∗
\pi^*
π∗更新分区
P
i
P_i
Pi和原型
Γ
\Gamma
Γ(使用EMA进行更新)。最后,我们丢弃2B个最老的内存嵌入(第10行)。
损失函数。
流行的infoNCE损失(Oord等人,2018)是我们损失函数的基础,但最近的研究(Poole等人,2019;Song & Ermon, 2019)已经表明,当批量规模较小时,它容易产生高偏差。为了解决这个问题,我们采用了infoNCE的一种变体,它最大化了相同的相互信息目标,但已被证明偏差较小(Lu et al, 2022):
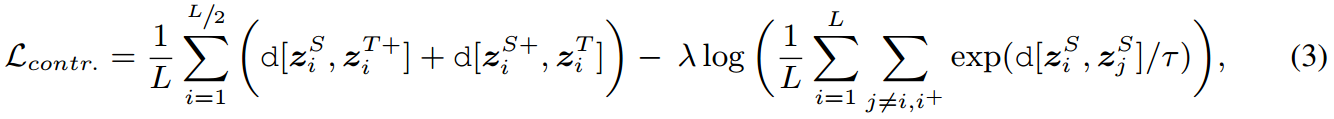
式中,
τ
\tau
τ为温度参数,
d
[
⋅
]
d[\cdot]
d[⋅]为负余弦相似度,
λ
\lambda
λ为加权超参数,
L
L
L为增强批大小,
z
i
+
z^+_i
zi+为正样本的潜在嵌入,接下来(Chen & He, 2021),为了进一步提升训练效果,我们通过学生和老师传递这两种观点。Eq. 3中的第一项在正对上操作,第二项将每个表示从所有其他批表示中推开。
4.2 监督推理
监督推理(又名微调)通常对抗训练和测试数据集之间的分布转移。然而,在测试时(在FSL任务中)有限的支持样本数量导致由于所谓的样本偏差而导致显著的性能下降(Cui & Guo, 2021;Xu et al, 2022)。在最近最先进的U-FSL基线中,这一问题大多被忽视(Chen等人,2021a;Lu et al ., 2022;Hu et al ., 2023a)。作为BECLR推理阶段的一部分,我们提出了一个简单但高效的附加模块(称为OpTA),用于对齐查询(Q)和支持(S)集的分布,以从结构上解决样本偏差。注意,OpTA不是一个可学习的模块,在BECLR的推理阶段没有模型更新,也没有任何微调。
图4:BECLR的推理策略概述。给定一个测试集,将支持集(
S
S
S)和查询集(
Q
Q
Q)传递给预训练的特征提取器(
f
θ
f_\theta
fθ)。OpTA使支持原型和查询特性保持一致。
基于运输的最优配送对齐(OpTA)。设
T
=
S
∪
Q
T=S\cup Q
T=S∪Q是一个下游少样本任务。我们首先提取支持
Z
S
=
f
θ
(
S
)
Z^S=f_\theta(S)
ZS=fθ(S)(大小为
N
K
×
d
NK \times d
NK×d)和查询
Z
Q
=
f
θ
(
Q
)
Z^Q=f_\theta(Q)
ZQ=fθ(Q))(大小为
N
Q
×
d
NQ \times d
NQ×d)嵌入,并计算支持集原型
P
S
P^S
PS(大小为
N
×
d
N \times d
N×d的类平均值)。接下来,我们使用Eq. 2找到
P
S
P^S
PS与
Z
Q
Z^Q
ZQ之间的最优传输计划(
π
∗
\pi^*
π∗),其中
r
∈
R
N
Q
r\in R^{NQ}
r∈RNQ为
Z
Q
Z^Q
ZQ的分布,
c
∈
R
N
c\in R^{N}
c∈RN为
P
S
P^S
PS的分布。最后,我们使用
π
∗
\pi^*
π∗将支持集原型映射到查询嵌入所占用的区域:
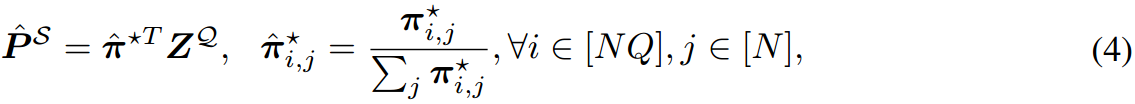
式中,
π
^
∗
\hat \pi^*
π^∗为归一化的运输计划,
P
^
S
\hat P^S
P^S为运输的支撑原型。最后,我们在
P
^
S
\hat P^S
P^S拟合逻辑回归分类器来对未标记的查询集进行推断。我们在第5节中展示了OpTA成功地最小化了分布转移(在支持集和查询集之间),并为BECLR提供的相对于最佳现有基线的总体显著性能边际做出了贡献。请注意,我们迭代地执行
δ
\delta
δ连续的OpTA,其中
P
^
S
\hat P^S
P^S作为下一遍的输入。值得注意的是,OpTA可以直接应用于任何U-FSL方法之上。OpTA的概述和提出的推理策略如图4所示。
5 实验
在本节中,我们通过解决以下三个主要问题,从定量和定性两方面严格研究了所提出方法的性能:
[Q1] BECLR在域内和跨域设置下的性能如何?
[Q2] DyCE是否通过建立可分离的内存分区影响预训练性能?
[Q3] OpTA是否通过提议的分布对齐策略来解决样本偏差?
我们使用PyTorch (Paszke等人,2019)来实现所有实现。详细的实施和培训细节在附录A的补充材料中进行了讨论。
基准数据集。我们根据BECLR在两种最广泛采用的少量图像分类数据集上的域内性能进行评估:miniImageNet (Vinyals等人,2016)和tieredImageNet (Ren等人,2018)。此外,对于域内设置,我们也对2求值针对FSL的CIFAR-100的策划版本(Krizhevsky et al ., 2009),即CIFAR-FS和FC100。接下来,我们在caltec - ucsd Birds (CUB)数据集(Welinder et al ., 2010)和最新的跨域FSL (CDFSL)基准(Guo et al ., 2020)上评估了跨域设置下的BECLR。对于跨域实验,使用miniImageNet作为预训练(源)数据集,使用ChestX (Wang et al ., 2017)、ISIC (Codella et al ., 2019)、EuroSAT (Helber et al ., 2019)和CropDiseases (Mohanty et al ., 2016)(表3)和CUB(附录表12)作为推理(目标)数据集。
5.1评价结果
我们报告了超过2000个测试集的95%置信区间的测试准确性,每个测试集每类Q = 15个查询镜头,对于所有数据集,这是文献中最常用的方法(Chen等人,2021a;2022;Lu et al, 2022)。miniImageNet、tieredImageNet、CIFAR-FS、FC100和miniImageNet→CUB的性能是在(5-way, {1,5}-shot)分类任务上进行评估的,而miniImageNet→CDFSL的性能是在(5-way, {5,20}-shot)任务上进行测试的,这在文献中是惯例的(Guo等人,2020;Ericsson et al, 2021)。我们根据各种基线评估BECLR的性能,包括:(i)已建立的SSL基线(Chen等人,2020a;Grill等,2020;Caron等,2020;Zbontar等,2021;Chen & He, 2021;Dwibedi等人,2021)到(ii)最新的U-FSL方法(Chen等人,2021a;Lu et al ., 2022;Shirekar等,2023;Chen et al ., 2022;Hu et al ., 2023a;Jang等人,2022),以及(iii)针对一组竞争性监督基线(Rusu等人,2018;Gidaris等人,2019;Lee et al, 2019;Bateni et al ., 2022)。
[A1-a]域内设置。(5-way, {1,5}-shot)设置下miniImageNet和tieredImageNet的结果如表1所示。无论骨干深度如何,BECLR在这两个数据集上都采用了最新技术,在1和5镜头设置上,miniImageNet分别比U-FSL的现有技术提高了14%和2.5%。在tieredImageNet上的结果也突出了相当大的性能裕度。有趣的是,BECLR甚至优于使用额外(合成)训练数据训练的U-FSL基线,这些数据有时是从更深层的主干提取出来的,也是引用的监督基线。表2提供了关于(不太常用的)CIFAR-FS和FC100基准测试的进一步见解,显示了类似的趋势,CIFAR-FS在1发和5发设置中分别高达15%和8%,FC100为5.5%和2%。
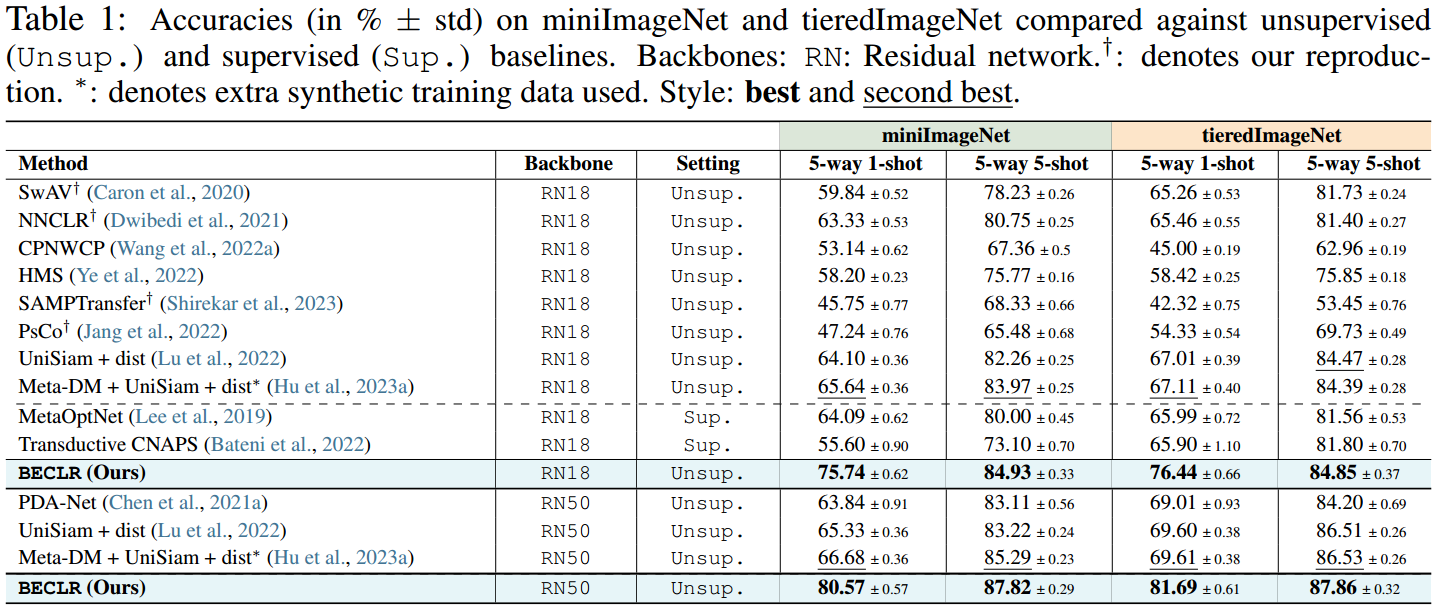
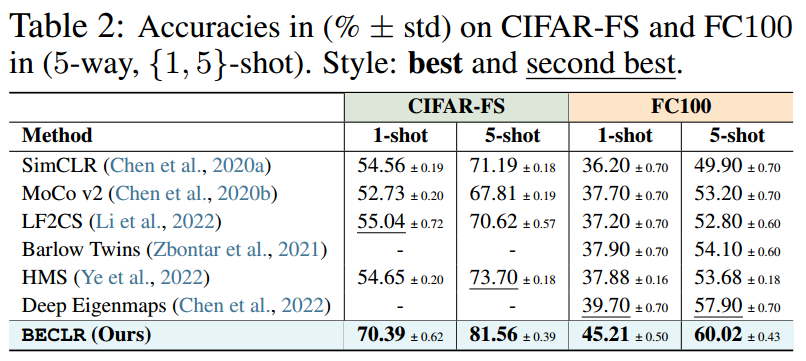
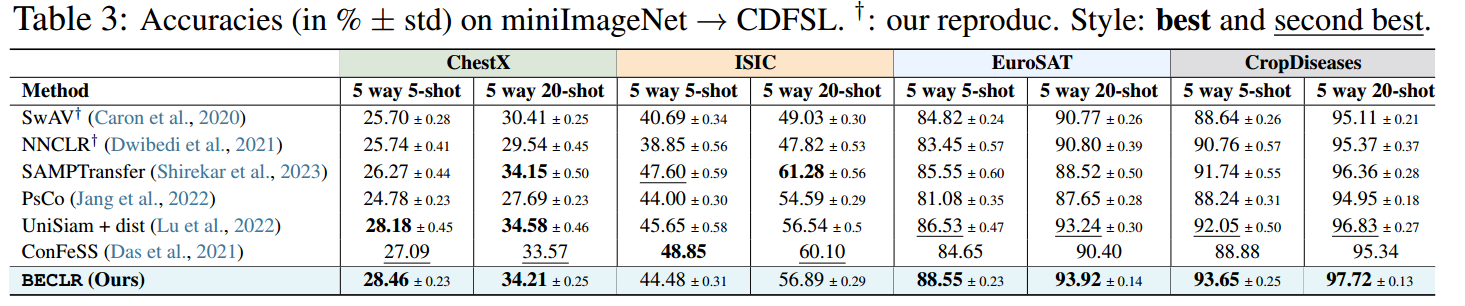
[A1-b]跨域设置。继Guo等人(2020)之后,我们在miniImageNet上进行预训练,并在CDFSL上进行评估,结果总结于表3。BECLR再次在ChestX, EuroSAT和作物病害方面树立了新的技术水平,并在ISIC方面保持竞争力。值得注意的是,ChestX和ISIC的数据分布与miniImageNet的数据分布有很大不同。我们认为这会影响下游推理的嵌入质量,从而影响OpTA在解决样本偏差方面的有效性。表1-3的扩展版本见附录C。
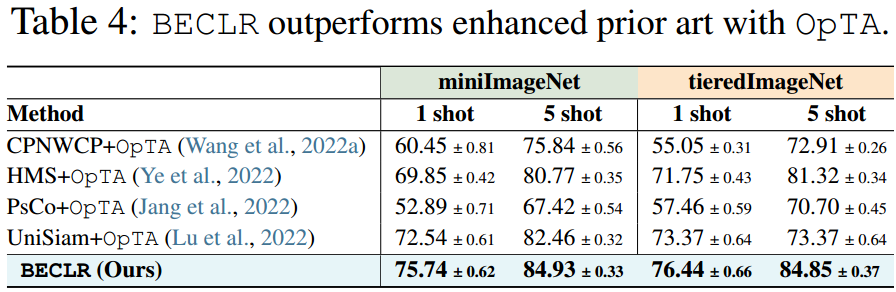
[A1-c]纯预训练与OpTA。为了证实BECLR中设计选择的影响,我们通过直接评估下游FSL任务(即无OpTA和无微调)上的预训练模型,比较了一些最具影响力的对比SSL方法:SwAV、SimSiam、NNCLR和先前的U-FSL技术:UniSiam (Lu et al ., 2022)的纯预训练性能。图5总结了miniImageNet在(5-way, {1,5}-shot)设置下不同网络深度的比较。即使没有OpTA, BECLR在所有主干网配置上的性能也优于所有U-FSL/SSL框架。作为一项额外的研究,在表4中,我们采取相反的步骤,在U-FSL的一套最新现有技术上插入OpTA。结果表明了两个重要的观点:(i) OpTA实际上与预训练方法的选择无关,对下游性能有相当大的影响;(ii)增强现有技术和BECLR之间仍然存在一定的差距,这证实了不仅OpTA有意义的影响,DyCE和我们的预训练方法也有意义。
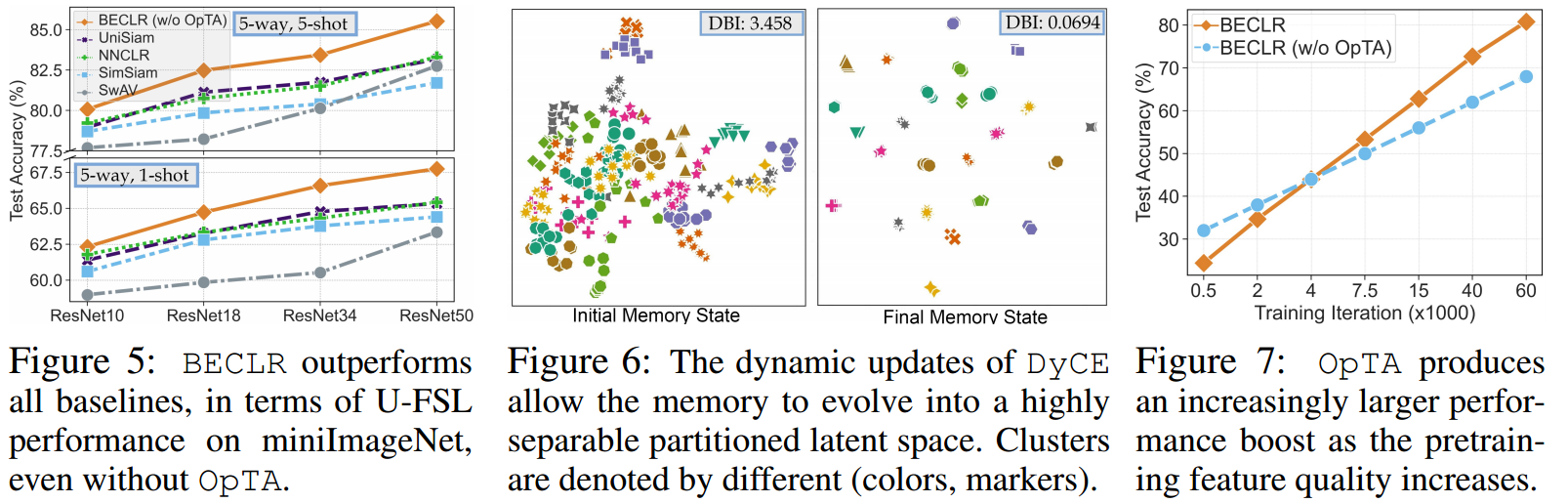
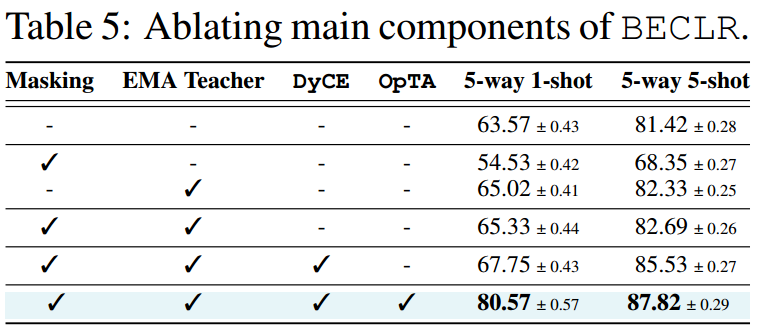
5.2 消融研究

6 结束语和更广泛的影响
在本文中,我们阐述了U-FSL现有技术的两个主要缺点,为了解决这两个缺点,我们提出了一种嵌入在拟议的端到端方法BECLR中的新颖解决方案。BECLR的第一个新颖的角度是它的动态聚类记忆模块(称为DyCE),以增强对比学习中的正抽样。新颖性的第二个角度是有效的分布对齐策略(称为OpTA),以解决(U-)FSL中固有的样本偏差。
尽管是为U-FSL量身定制的,但我们相信DyCE对通用的自监督学习技术具有潜在的更广泛的影响,正如我们已经证明的那样(在第5节中),即使不插OpTA, DyCE本身也使BECLR的表现优于SwaV、SimSiam和NNCLR。另一方面,OpTA是一种高效的附加模块,我们认为它必须成为所有(U-)FSL方法的组成部分,特别是在更具挑战性的少样本场景中。
参考资料
论文下载(ICLR 2024)
https://arxiv.org/abs/2402.02444

代码地址
https://github.com/stypoumic/BECLR
















 179
179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











