







目录
参考:
GPU/ CUDA/ cuDNN_哔哩哔哩_bilibili
gpu vs cpu
显卡就是一块负责承担输出图形任务的板卡
gpu就是显卡上的一块芯片,是显卡的核心
gpu能够减少显卡对cpu的依赖,分担部分cpu的工作
gpu是高度并行的结构,所以在部分情况下他更高效

通常来说cpu里只有几个算储单元(绿色+黄色+紫色)
但是gpu却有非常多(注意看gpu最左侧一列)
cuda
简单来说
cuda提供了一个能够让gpu高速并行计算的代码书写规范,使得我们可以将计算更加灵活地拆解成一个个子任务,然后分配到不同的线程上,提高并发性
例子:
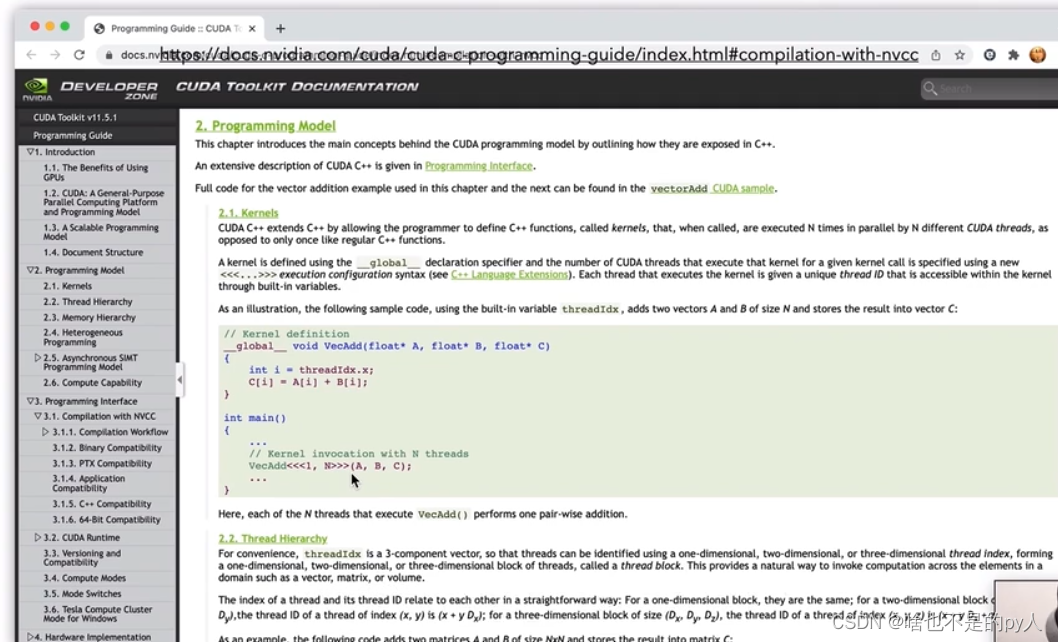
上面的例子是两部分
分别是kernel的定义和main函数
kernel的定义和普通的c++函数没有什么区别,除了加上了一个__global__的修饰符,这个修饰符就相当于告诉编译器这部分需要在gpu上完成
这部分就是把两个长度为N的向量,将其分配到N个线程上进行加法运算,那其实每个线程只需要计算相应位置上的一个加法运算就可以了
这里用到了threaddx.x这个内置变量,它是线程的一个标号N个线程的标号就是从0到N-1
刚好满足运算需求
<<<1,N>>>代表调用第一个到第N个线程来进行计算
补全代码

1.在host端初始化需要进行加法运算的两个向量
2.将host端的数据拷贝到device端
3.在device端进行计算
4.将device端的计算结果拷贝回host端

最后就可以用nvcc(也就是cuda编译器)
编译.cu文件 ,然后就会得到一个可执行文件
所以实际上数据是在host端产生,然后拷贝到gpu上进行计算的,最后再将数据拷贝回host端
cuDNN
为了让使用者不用实现底层的cuda编程,cuDNN就产生了

cuDNN就是cuda深度神经网络库,就是将一些基本的层结构进行封装
实现了在GPU上的高效并行计算
可理解为cv2库,对常用的图像处理算法封装成了库里的很多函数,用的时候直接调用,而不使用python从头写造轮子
pytorch
torch在此之上再次进行封装
torch利用cuda和cuDNN来利用gpu进行加速

经常能见到以下类似代码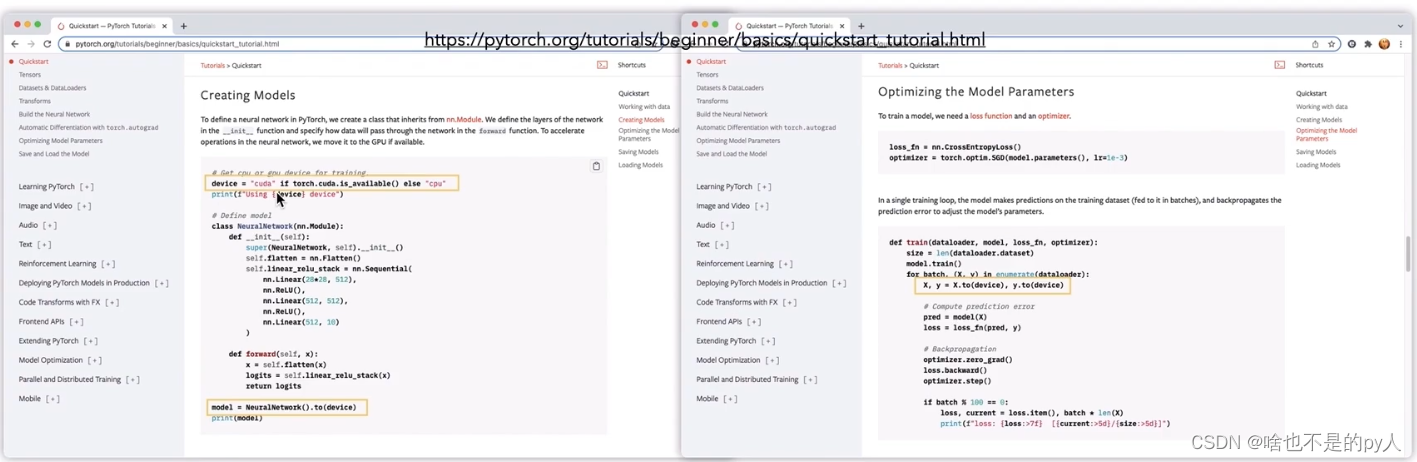
首先我们定义一个device
然后就会有net=model().to(device)
以及x.to(device)和y.to(device)
所以实际上这一步就是将host端的数据拷贝到GPU上进行运算
所以只要把.to(device)就可以加速
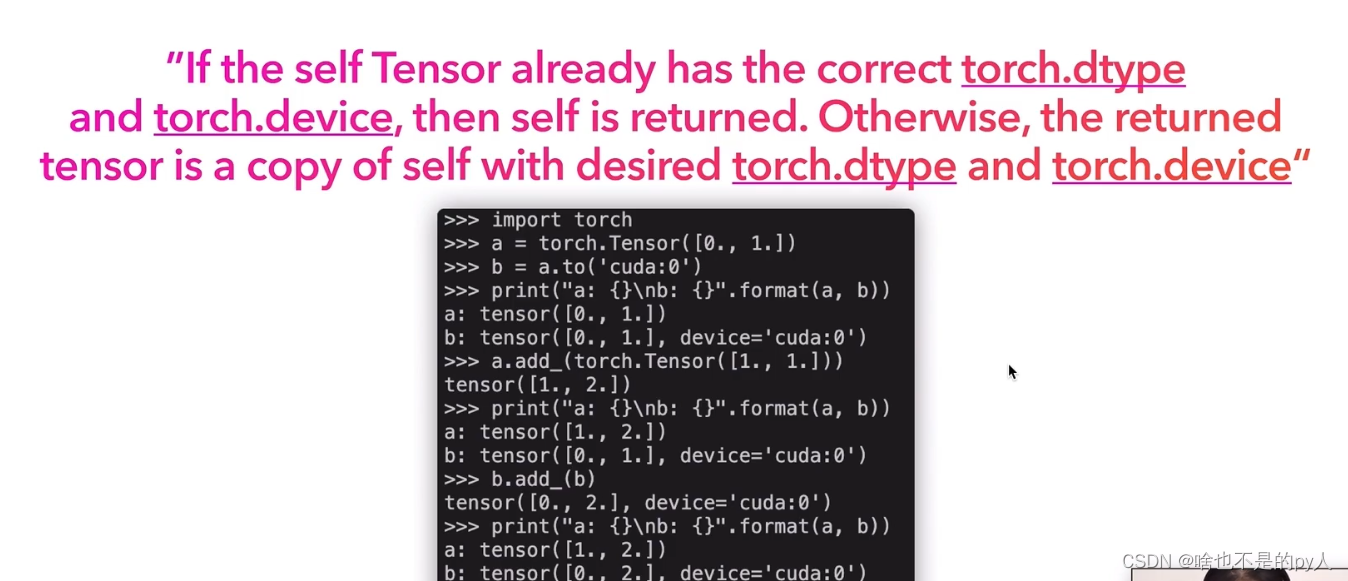
可以看到device端的数据和host端的数据互不干扰
b是a拷贝到gpu上的,然后改变a并不会改变b,说明是相互隔离的两个变量
更多相关的内容可以看以下文档
















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









