







简介
主页:http://waymo.com/research/block-nerf

Block-NeRF是一种通过使用多个紧凑的nerf(每个nerf都适合内存)来表示环境,从而实现大规模场景重建的方法。在推断时,Block-NeRF无缝结合给定区域的相关nerf的渲染。论文中,使用3个多月收集的数据(2.8w)重建了旧金山的Alamo广场社区。Block-NeRF可以更新环境的单个块,而无需对整个场景进行重新训练,正如右边的构造所示。

实现流程
block主要基于Mip-Nerf,Nerf in the wild
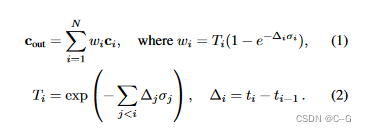
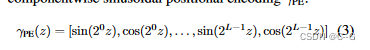
NeRF的MLP fσ采用一个3D点作为输入。然而,这既忽略了相应图像像素的相对足迹,也忽略了沿包含该点的光线r的间隔长度 [ti−1,ti],导致在呈现新的相机轨迹时产生混叠伪影。MipNeRF通过使用投影像素足迹沿射线采样conical frustums来解决这个问题,而不是间隔。为了将这些frustums输入MLP,mip-NeRF将每个frustums近似为参数µi、Σi的高斯分布,并用其对输入高斯的期望代替位置编码γPE
当试图代表像城市这样大的场景时,训练一个NeRF是不规模化的。相反,建议将环境分割成一组Block-NeRF,它们可以并行地独立训练,并在推理过程中进行组合。这种独立性允许使用额外的block-nerf来扩展环境或更新块,而无需对整个环境进行重新培训。动态地选择相关的Block-NeRF来进行渲染,然后在穿越场景时以平滑的方式进行合成。为了帮助这种合成,优化了外观代码以匹配照明条件,并使用基于每个Block-NeRF到新视图的距离计算的插值权值
Block Size and Placement
在每个十字路口放置一个Block-nerf,覆盖十字路口本身和任何连接街道的75%,直到它收敛到下一个十字路口
在连接街道段上的任何两个相邻街区之间有50%的重叠,使它们之间的外观对齐更容易
块大小可变;必要时,可引入其他块作为交叉点之间的连接器
应用一个地理过滤器,确保每个块的训练数据完全保持在其预期的范围内。这个过程可以被自动化,并且只依赖于基本的地图数据,如开放的街道地图
只要整个环境被至少一个Block-NeRF覆盖,也是可能的,如将一个街区以均匀的距离放置块,并将块大小定义为Block-NeRF原点周围的球体
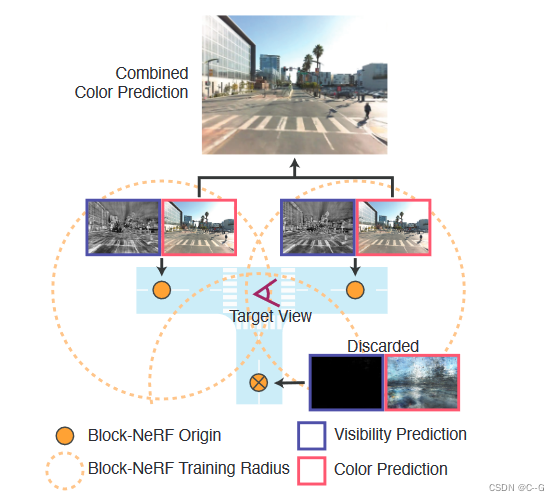
场景被分割成多个Block-NeRF,每个块都在一个特定的Block-NeRF原点坐标(橙色点)的某个半径(虚线橙色线)内的数据上进行训练。要在场景中渲染目标视图,将计算给定半径内的所有nerf的可见性贴图。具有低可见性的Block-NeRF将被丢弃(底部的Block-NeRF),并为其余的块呈现颜色输出。然后根据每个块原点到目标视图的距离合并渲染图
Training Individual Block-NeRFs
Appearance Embeddings
数据集记录于2021年6月、7月和8月,2.8w张图片,包含了不同的天气、时间变换,因此这里引用NeRF-W,使用生成潜在优化来优化周围图像外观嵌入向量
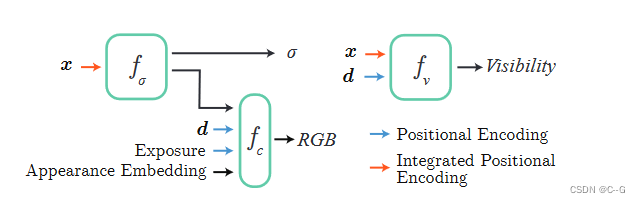
第一个MLP fσ预测了空间中一个位置x的密度σ。该网络还输出一个特征向量,它与观看方向d、曝光水平和一个外观嵌入连接起来。这些被输入到第二个MLP fc中,输出该点的颜色。此外,还训练了一个可见性网络fv来预测空间中的一个点是否在训练视图中可见,这是用于在推理过程中剔除Block-NeRF
通过图像外观嵌入向量,以在训练数据中观察到的不同条件之间进行插值,可以操纵这些外观嵌入,如不同的天气和照明

Learned Pose Refifinement
虽然论文假设提供了相机的姿态,但论文发现学习正则化的姿态偏移有利于进一步对齐。在以前的基于NeRF的模型中已经探索了姿态细化。这些偏移量由每个驱动段学习,并包括平移和旋转分量。与NeRF本身一起优化这些偏移,在训练的早期阶段显著地正则化偏移,以允许网络在修改姿态之前首先学习一个粗糙的结构。
Exposure Input
训练图像可以在广泛的曝光水平上被捕获,如果不考虑,这可能会影响NeRF训练。将相机曝光信息输入到模型的外观预测部分,可以让NeRF补偿视觉差异。具体来说,曝光信息被处理为γPE(shutter speed × analog gain/t 快门速度×模拟增益/t ),其中γPE是一个具有4个水平的正弦位置编码,t是一个比例因子(在实践中使用1000)。在中可以找到一个不同的学习暴露的例子。

Transient Objects
假设场景的几何形状在整个训练数据中是一致的。任何可移动的物体(如汽车、行人)通常都违反这一假设,使用语义分割模型来生成常见的可移动物体的掩模,并在训练过程中忽略掩模区域,这适应了最常见的几何不一致类型
同时因为数据时间跨图大,树木,建筑等一些变化也被认定为可移动物体,导致效果不理想
Visibility Prediction
当合并多个Block-NeRF时,训练过程中在一个特定的空间区域知道给定的NeRF是否可见是很有用的。用一个额外的小MLP fv来扩展模型,该模型被训练来学习一个采样点的可见性的近似值。对于沿着训练射线的每个样本,fv取位置和视图方向,并回归相应的点的透射率(Ti)
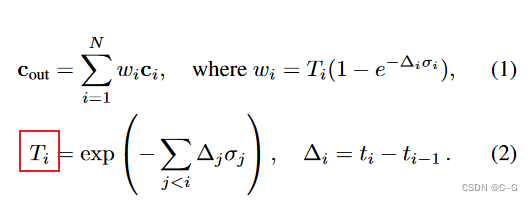
该模型与提供监督的fσ一起进行训练。透射率表示一个点对特定输入相机的可见程度:自由空间或第一个相交物体表面的点的透射率接近1,而第一个可见物体内部或后面的点的透射率接近0。如果一个点从某些角度能看到,而从其他角度不能,回归透射率值将是所有训练摄像机的平均值,在0到1之间,表明该点被部分观察到。能见度预测类似于能见度场。然而,能见度场使用MLP来预测环境照明的可见性,目的是恢复可恢复的NeRF模型,而这里则预测训练射线的可见性
可见性网络很小,可以独立于颜色和密度网络运行,它可以帮助确定特定的NeRF是否可能为给定位置产生有意义的输出,可见性预测还可以用于确定在两个nerf之间执行外观匹配的位置
Merging Multiple Block-NeRFs
Block-NeRF Selection
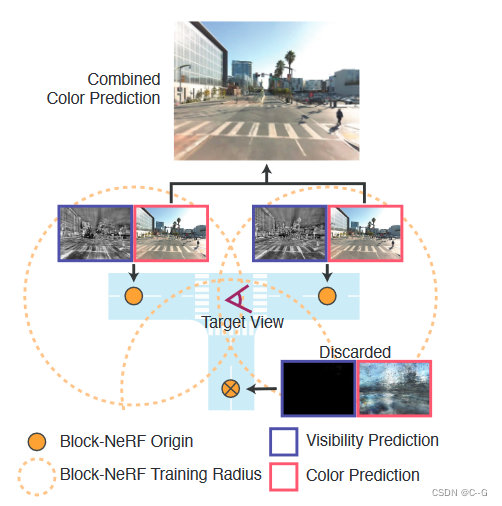
环境可以由任意数量的Block-NeRF组成。为了提高效率,使用两种过滤机制来只呈现给定目标视点的相关块。只考虑在目标视点的设定半径范围内的Block-NeRF。此外,对于每个候选项,计算相关的可见性。如果平均可见性低于一个阈值,将丢弃Block-NeRF。上图提供了一个可见性过滤的示例。可见性可以快速计算,因为它的网络独立于彩色网络,并且不需要在目标图像分辨率下进行渲染。在过滤之后,通常会有一到三个Block-NeRF有待合并
Block-NeRF Compositing
从每个过滤后的block-nerf中渲染彩色图像,并使用相机原点c和每个Block-NeRF的中心xi之间的逆距离加权 inverse distance weighting在它们之间进行插值。具体来说,计算各自的权重为

其中p影响Block-NeRF渲染之间的混合速率。插值是在二维图像空间中完成的,并在Block-NeRF之间产生平滑的过渡
Appearance Matching
上面提到,模型的外观(时间、天气等)可以通过外观潜在代码来控制,这些代码在训练过程中被随机初始化,因此,相同的代码在输入不同的Block-NeRF时,通常会导致不同的外观
给定一个在其中一个Block-NeRF中的目标外观,需要匹配它在其余块中的外观,首先在相邻的Block-NeRF对之间选择一个三维匹配位置,对于两个Block-NeRF,这个位置的能见度预测都应该很高
给定匹配位置,我们冻结Block-NeRF网络的权重,只优化目标的外观码,以减少各自区域呈现之间的l2损失,这种优化非常快速,可以在100次迭代内收敛,虽然不一定会产生完美的对齐,但这个过程会将场景的大多数全局和低频属性对齐,如一天中的时间、颜色平衡和天气
















 5214
5214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









