







第五节t检验
计量资料的假设检验中,最为简单、常用的方法是t检验。实际应用中,应弄清各种检验方法的用途、适用条件和注意事项。
当σ未知且样本含量n较小时(如n<60),理论上要求t检验的样本随机地取自正态分布的总体,两独立小样本均数比较时还要求两样本所对应的两总体方差相等,即方差齐性(homogeneity of variance)。
当样本含量n较大时,t值近似于u值,称为u检验/z检验。
单样本t检验
即已知样本均数所代表的未知总体均数m和已知总体均数m0 (一般为理论值、标准值或经过大量观察的稳定值)的比较。
检验统计量按照下公式计算:
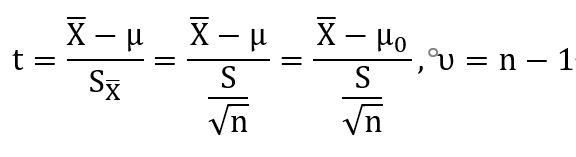
配对样本t检验
适用于配对设计或自身对照设计的计量资料的比较。配对设计是将受试对象按照某些重要特征(如性别)配成对子,再将每对中的两个受试对象随机分配到两处理组。在医学科研中,配对设计主要有以下情形:
1.两同质受试对象配成对子分别接受不同的处理;2.同一受试对象分别接受两种不同处理;3.同一受试对象接受(一种)处理前后,这种情形在设计上存在缺陷(见第12章,重复测量设计资料的方差分析)。
将配对数据求差值后,配对t检验的实质与单样本t检验相同。若两处理效应相同,配对数据的差值应围绕0上下波动,因此可将此类资料看成是差值的样本均数d ̅所代表的未知总体均数μ_d=0的比较检验统计量可按照公式构造如下:

两样本t检验
又称成组t检验,或两独立样本t检验,常见于完全随机设计两样本均数的比较,即将受试对象完全随机分配到两个不同处理组,研究两样本均数所代表的两总体均数是否不等。此外,也可以用于观察性研究中独立从两个总体中进行完全随机抽样。
当两总体均来自正态总体,且样本含量较小,如n1≤60/n2≤60,要根据两总体方差是否相等而采用不同检验方法。
(一)总体方差相等的t检验
方差相等,可将两样本方差合并,检验统计量按照μ=μ1-μ2=0条件下构造

(二)总体方差不等的近似t检验
进行两小样本总体均数比较,若总体服从正态分布,但总体方差不等,可采用数据变换(第七节)或下述近似t检验—t’检验或秩转换的非参数检验(第八章第二节)。


第六节假设检验的注意事项
I型错误和II型错误
假设检验采用小概率反证法的思想,根据P值做出的推断结论具有概率性,因此其结论不可能完全正确,可能发生两类错误。

I型错误(type I error):拒绝了实际上成立的H0,这类“弃真”的错误称为I型错误。检验水准就是预先规定的允许犯I型错误概率的最大值。I型错概率大小也用α表示,α可单侧(尾)可双侧(尾)。
假设检验时,研究者可根据不同研究目的来确定α值的大小。如α=0.05,当H0实际成立而拒绝H0时,则理论上每100次检验中,平均有5次发生这样的错误。
II型错误(type II error):“接受”实际上不成立的H0所犯的错误,这类“取伪”的错误称为II型错误。其概率大小用β表示。β只取单尾,β的大小难于确定,必须在知道两总体差值(如μ1-μ2),α及n时,才能算出。

检验效能(power of a test)
1-β称为检验效能,过去称把握度。它是指两总体确有差异,按规定的检验水准α所能发现该差异的能力。和β一样,1-β只取单尾。如1-β=0.90,意味着若两总体确有差别,则理论上平均每100次检验中,有90次能够得出差异有统计学意义的结论。
α越小,β越大;反之α越大,β越小。
若要同时减小Ⅰ型错误α以及Ⅱ型错误β,唯一的方法就是增加样本含量n。
若重点是减少Ⅰ型错误α(如一般假设检验),一般取α=0.05;
若重点是减少Ⅱ型错误β(如方差齐性检验,正态性检验或想用一种方法代替另一种方法的检验等),一般取α=0.10或0.20,甚至更高。
注:拒绝H0,只可能而且只能犯I型错误,不可能犯II型错误;
“接受”H0,只能而且只可能犯II型错误,不可能犯I型错误。
假设检验应注意的问题
**1.要有严密的研究设计。**这是假设检验的前提,对比组间应均衡,具有可比性。保证均衡性最好的方法是施加干预前的随机分组。
**2.不同类型资料应选用不同检验方法。**应根据分析目的、资料类型和分布、设计方案种类、样本含量大小及不同统计学方法的适用条件等,选用适当的检验方法。
**3.正确理解“显著性”的含义。**英文期刊关于假设检验最常见的表述是significant difference和no significant difference,中文理解为“有统计学差异”和“无统计学差异”更为恰当,并不说明差异有无显著性。
**4.结论不能绝对化。**因统计结论具有概率性质,故在报告结论时,不要使用“肯定”“一定”等词。应列出检验统计量的值,报告具体P值或P的确切范围,如写成
P=0.04/0.02<P<0.05
以便读者与同类研究进行分析比较或进行循证医学研究时采用meta分析。
5.置信区间与假设检验的区别和联系
置信区间用于说明量的大小即推断总体参数在哪个范围。
假设检验用于推断质的不同即两总体参数是否不同。
两者既相互联系,又有区别。
1)置信区间亦可回答假设检验的问题。
2)置信区间比假设检验可提供更多的信息。

注意:虽然置信区间也可回答假设检验的问题,并能提供更多的信息,但并不意味着置信区间能够完全代替假设检验。置信区间只能在预先规定的概率—置信度(1-α)的前提下进行计算,而假设检验能够获得较为确切的概率P,故将两者结合起来,才是完整的分析。
第七节正态性检验和两样本方差比较的F检验
正态性检验
一是图示法。
主要采用概率图(probability-probability plot,P-P plot)和分位数图(quantile-quantile plot,Q-Q plot),其中P-P图是以实际或观察的累积频率(X)对被检验分布(如正态分布等)的理论或期望累积频率(Y)作图,而Q-Q图则是以实际或观察的分位数(X)对被检验分布的理论或期望分位数(Y)作图,其中以Q-Q图的效率较高。

二是计算法。
(1)对偏度(skewness)和峰度(kurtosis)各用一个指标来评定,其中以矩法(method of moment,又称动差法)效率最高;
(2)仅用一个指标来综合评定。其中W/W’检验法效率最高,适用于样本含量少于100的资料。D检验法效率也高,适用于样本含量10~2000的资料。
矩法是利用数学上矩原理来检验偏度和峰度。
偏度指分布不对称的程度和方向,用偏度系数(coefficient of skewness)衡量,样本偏度系数用g1表示,总体偏度系数用γ_1表示;
峰度则指分布与正态曲线相比的冒尖程度或扁平程度,用峰度系数(coefficient of kurtosis)衡量,样本峰度系数用g2表示,总体峰度系数用γ2表示。
g1、g2的计算公式如下:

式中X为变量值,f为相同X的个数,n为样本含量。当用原始数据进行计算时,f=1。因此,上两式无论n的大小均适用。
理论上:
总体偏度系数γ1=0为对称;γ1>0为正偏态;γ1<0为负偏态。
总体峰度系数γ2=0为正态峰;γ2>0为尖峭峰;γ2<0为平阔峰。
两样本方差比较的F检验
尽管两个总体方差相同,但由于抽样误差,两样本方差不一定相等。判断两总体方差是否不等—采用方差齐性检验。
过去:多采用F检验(F test),要求正态分布
现在:Levene检验(Levene‘s test,1960),任意分布(第四章第七节)
Levene检验:将原始观测值转换为相应的离差(多方法可选),然后再作方差分析,它既可用于对两个总体方差进行齐性检验,也可用于对多个总体方差进行齐性检验。
下面介绍两样本方差比较的F检验:

检验统计量F为两个样本方差之比,如仅是抽样误差的影响,它一般不会偏离1太远。

变量变换
变量变换是将原始数据作某种函数转换,如转换为对数值等。变量变换作用:它可使各组方差齐同稳定,亦可使偏态资料正态化,以满足t检验或其它统计分析方法对资料的要求。
变量变换后,在结果解释上不如原始观测变量直观。
常用变量变换:对数变换、平方根变换、平方根反正弦变换、倒数变换等。应根据资料性质选择适当的变量变换方法。
1.对数变换(logarithmic transformation)
将原始数据 X 取常用对数或自然对数均可。
1)形式:

2)适用于:①对数正态分布资料,原始数据的效应是相乘时;②各样本标准差与均数成比例或变异系数是常数或接近某一常数时。
2.平方根变换(square root transformation)
将原始数据X开算数平方根。
1)形式:
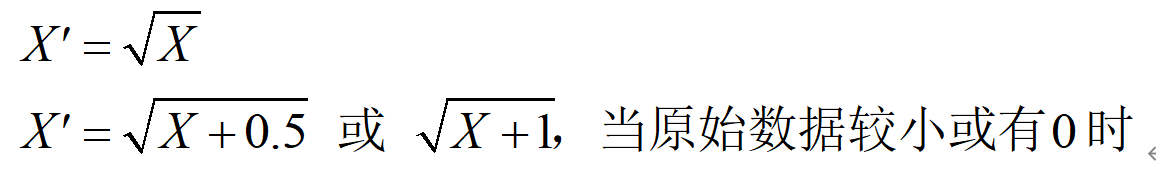
2)适用于:①服从Poisson分布资料,也即各样本方差与均数近似相等,如放射性物质在单位时间内的放射次数,某些发病率较低的疾病在时间或地域上的发病例数等资料;②轻度偏态分布资料。
3.平方根反正弦变换(arcsine transformation)
将原始数据X的平方根取反正弦变换。
1)形式:用角度表示
用弧度表示

2)适用于:个体观察指标为比值或百分比或率的资料,如淋巴细胞转变率(%)、白细胞分类计数百分比(%)等。
4.倒数变换(reciprocal transformation)
将原始数据X取倒数。
1)形式:X′=1/X
2)适用于:数据两端波动较大的资料。
总结
本章介绍了抽样误差,统计推断的参数估计和假设检验。t检验主要用于比较单一样本或两样本均数。通常从同一总体随机重复抽样所得的样本均数各不相同,我们将样本均数和总体均数之差称为抽样误差,也即均数的标准误。它表明用样本均数估计总体均数所期望的差异大小。
参数估计是指用随机样本统计量来说明总体参数。参数估计有两种:(1)点估计,简单用样本统计量值来说明总体参数;(2)区间估计,它基于总体参数的抽样误差计算出可信区间。
假设检验是使用样本数据推断出总体一般性结论的过程。假设检验有三步曲:(1)建立检验假设H0和H1,设定检验水准;(2)选择统计方法,计算检验统计量;(3)获得P值,作出结论。无论假设检验作出什么结论,总是会冒着犯错误的风险。通常会有两种类型的错误发生:I型错误是拒绝了真实的H0,II型错误是“接受”了错误的H0。t检验是构建其检验统计量和相应界值最为常用的方法,该检验统计量服从Student’s t分布。用于比较样本均数,包括单样本t检验,配对样本t检验,和两样本t检验。














 8817
8817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









