







目录
AdaGrad 自适应梯度 (Adaptive Gradient)
Stochastic Gradient Descent 随机梯度下降
感谢B站up主搬运的课程:
【李宏毅2020机器学习深度学习(完整版)国语】 https://www.bilibili.com/video/BV1JE411g7XF/?share_source=copy_web&vd_source=262e561fe1b31fc2fea4d09d310b466d
引_梯度下降法
假设使用两个“特征参数”,组成一个向量
。
我们随机地选择参数从
=
开始,
不断地进行
,
其中
即梯度(对各个参量的导数向量
,
直至求出最终的
,此即Gradient Descent
从坐标系上看
我们选取的点正不断往梯度的反方向更新

Gradient Descent 的优化
Tip1:小心地调节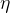 (Learning Rate)
(Learning Rate)
过大的 会导致Loss难以减小(绿色走向)、甚至不减反增(黄色走向);
过小的 则使迭代速度过慢。

一种主流又简单的做法——随着迭代次数将 变小(做得越多越接近结果,须放慢步伐);
同时,不同的参数情况不同,理应具有不同的 。
AdaGrad 自适应梯度 (Adaptive Gradient)
对每一个特征参量
取时变的学习速率
,梯度
(
指取其它参数在t次迭代时的值)

并且为 除上一个参数
:先前算出的所有微分值的RMS(所有参数的
都不同)

代入式中,我们发现式子上下其实可以约简去

最终的 AdaGrad 式子如上所示,相较于普通的 Gradient Descent 就是多了个分母。
“这个分母的意义?”
- 直觉上的解释:当某次迭代计算出的
骤大/骤小时,该因子足以显现
与过往梯度的反差
- 以二次函数模型解释:
从某一参数值走到最佳值
(二次函数顶点)的最佳步长为
。
能够发现恰为 |一阶导数 | /
二阶导数。
那么,我们可以看出AdaGrad新增的因子便是
使用一阶导数的样本采用平方和开根的方式对二阶导数的一个估计。

Tip2:让训练更快!
Stochastic Gradient Descent 随机梯度下降
普通的梯度下降呢,Loss是对所有的样本求和的(n为第n个样本,i为第n个样本的第i个特征)

![]()
Stochastic Gradient Descent 的做法则是每次迭代用的Loss只随机取一个样本(不再对n求和)

“真的快很多!”

Tip3:Feature Scaling 特征尺度缩放
是什么?
让不同的特征拥有相同尺度的操作。

为什么?
具有相同尺度的 Feature 会让参数更直接地往低 Loss 方向迭代。

上图中特征变量 的尺度较大,
有变动时 Loss 会变化很快,即迭代方向(梯度反方向)会更偏向
这边,走得会比较绕。
怎么做?
一种方法:
我们持有样本 、
、……
; 每个样本都具有特征
、
、……
;
我们对每一种特征都求他们的均值 和方差
,
对每个样本的特征值都减去均值再除以方差,最终该特征成为0均值、1方差的分布。

Formal Derivation 正式的推导
在参数空间中任选一点,然后我们在他的领域(红色圆圈)里寻找Loss值最低的那个点,再以它为中心重复这个操作,最终会找到最佳参数。

泰勒展开

当 接近于
时,高次项的
会很小,忽略
![]()
多参数泰勒展开 Multvariable

同样的,在接近 、
时我们只保留0次1次项,

所以,我们的领域选得足够小(红色圆圈足够小),Loss 就可以展开为上面的形式。

令 ,
,
观察后两项,由于梯度是有方向的,那我们也把 、
视为向量
。

------ 那我们如何让向量的 内积/点积/标量积 最小呢?
很显然,让夹角为 (
),即将向量
指向梯度的反方向;
再让 尽可能伸得更长,即顶到边缘。

那么我们就得到了一个关系式

反方向-,尽可能长的因子 (与圆圈大小成正比);
把它拆开,你会发现这不就是梯度下降的式子么?!

当然,理论上, 要足够小(圆圈足够小),我们最初的一级近似才成立。
Gradient Descent 的局限性

在局部最小停下来……
在驻点(导数为零)停下来……
在导数很小的点步履维艰……
当然我们实际操作时并无法知道我们找的 local min 到底是不是 global min ……















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









