







商品评论情感分析
已知商品评论数据,根据数据进行情感分类(好评、差评)
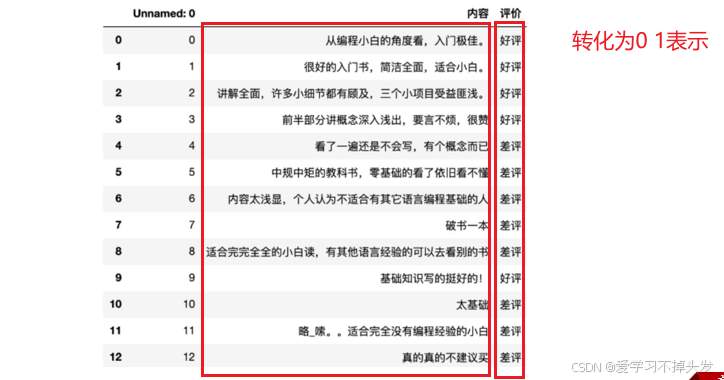
1.数据以及需求
2. 分析流程
- 获取数据
- 数据基本处理
2-1 处理数据y
2-2 加载停用词
2-3 处理数据x 把文档分词
2-4 统计词频矩阵 作为句子特征 - 准备训练集测试集
- 模型训练
4-1 实例化贝叶斯 添加拉普拉斯平滑参数
4-2 模型预测 - 模型评估
3. 代码
import pandas as pd
import numpy as np
import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
# 1.读取数据
data =pd.read_csv('书籍评价.csv',encoding='gbk')
# print(data)
# 将标签值转换为0,1表示
data['labels']=np.where(data['评价']=='好评',1,0)
# print(data)
y = data['labels']
# 读取停用词表,并将停用词加入到停用词表当中
stop_words = []
with open('stopwords.txt',encoding='utf-8') as file:
lines=file.readlines()
stop_words = [line.strip() for line in lines]
stop_words = list(set(stop_words))
# print(stop_words)
# 分词
# 数据进行分词之后,使用,进行拼接为字符串
word_list=[','.join(jieba.lcut(line)) for line in data['内容']]
# print(word_list)
# 词频统计
# 创建对象的时候,传入停用词表
transform =CountVectorizer(stop_words=stop_words)
# 进行文本向量化的时候,传入一个字符串列表,其中的字符串以逗号或空格进行分割
x =transform.fit_transform(word_list)
names = transform.get_feature_names()
# print(names)
# print(len(names))
x = x.toarray()
# print(x)
# 取前10条数据作为训练集
# 11到最后的数据作为测试集
x_train=x[:10,:]
y_train=y.values[0:10]
x_test=x[10:,:]
y_test=y.values[10:]
# print(x_train.shape)
# print(y_train.shape)
# 模型训练
model =MultinomialNB(alpha=1)
model.fit(x_train,y_train)
y_predict=model.predict(x_test)
print(y_predict)
print(model.score(x_test,y_test))

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









